我们有一个业务场景,需要从复杂的文本中,提取关键信息,整理成结构化数据,即:将非结构化数据,提取成结构化的数据。
尽管当前的LLM已经具备了通识领域非常强大的自然语言理解能力,且具备结构化输出能力(大部分LLM)。但直接让 LLM "读文本吐结构" 仍然存在诸多痛点:不同领域(医疗、法律、金融、舆情等)的抽取需求各异,直接让模型覆盖所有领域往往力不从心,细调模型代价高昂。
Google最近发布的开源框架LangExtract,就是为了解决上述问题而生的。
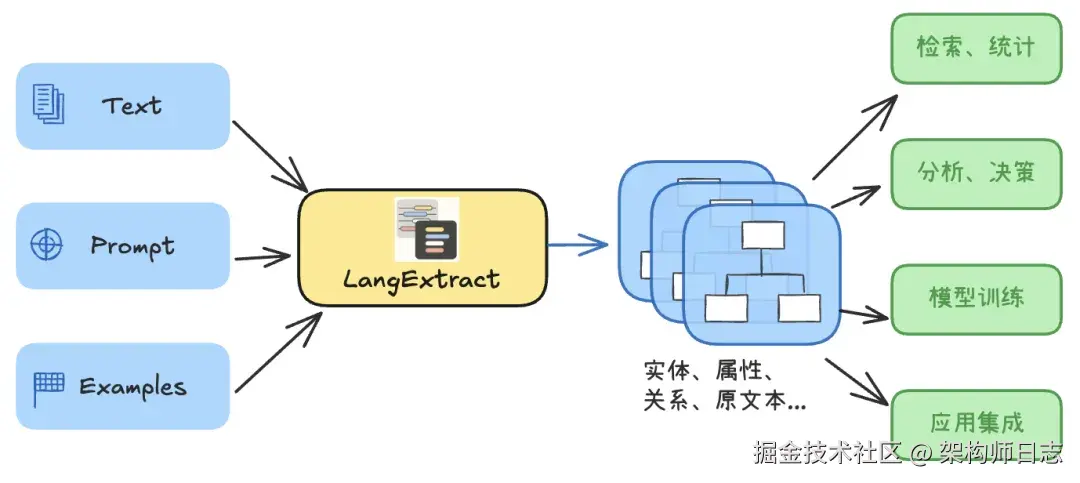
相关LangExtract的基础介绍(核心特性和代码结构等)可以看这篇文章:LangExtract:基于LLM的信息抽取框架|附项目解析与实战代码
LangExtract有很多部署方式,我选择了使用docker去运行,即在docker内部调用远程大模型免费API。因为这样的地不需要占用太多资源,又可以方便切换模型,以便对比不同模型的效果,快速验证。
一、准备镜像
从github上面拉取代码仓库之后,进入目录
shell
git clone https://github.com/google/langextract.gitcd langextract自己打docker镜像
打镜像之前先看一下官方的Dockerfile文件:
Dockerfile
# Production Dockerfile for LangExtract
FROM python:3.10-slim
# Set working directory
WORKDIR /app
# Install LangExtract from PyPI
RUN pip install --no-cache-dir langextract
# Set default command
CMD ["python"]LangExtract官方提供了openai、gemini、ollama三种模型的方式来运行。
不过网上有很多文章是使用gemini和ollama模型方式来运行的,考虑到使用openai的模型兼容性比较好,因此我使用了openai provider(provider可以理解为调用模型的实现)。
因此我对Dockerfile做了几处改造,改造后的Dockerfile如下:
Dockerfile
# Production Dockerfile for LangExtract
FROM docker.m.daocloud.io/python:3.10-slim
# Set working directory
WORKDIR /app
# Install LangExtract from PyPI
# 第二处改造:pip install默认超时时间
RUN pip install --default-timeout=100 --no-cache-dir -i https://pypi.tuna.tsinghua.edu.cn/simple langextract[openai]
# Set default command
CMD ["python"]改造说明(可以比对官方原始Dockerfile):
- 第一处改造:docker的镜像使用了docker.m.daocloud.io镜像服务,因为很多镜像在国外,就算科学上网有时候也连不上。现在还能提供国内免费docker镜像服务的真是良心企业啊!
- 第二处改造:pip install默认超时时间设置为100秒(非必要,超时被害妄想症使用)
- 第三处改造:pip install试用了清华大学的镜像
- 第四处改造:使用openai依赖
langextract[openai]
改造完之后打镜像,在langextract目录下执行命令docker build -t langextract-openai . (注意命令末尾的点(".")不要丢了)
接下来是短暂的等待,等打好包之后,看一下镜像情况,执行命令:docker images

二、运行示例
我从网上找了两个例子,使用openai的provider,对代码进行了修改,已验证,可以正常运行。
实战一:从 中文新闻段落抽"经济指标信息"
我们自造一段新闻式文本(非引用任何媒体)来演示抽取流程:
原文(示例数据):
8月15日(周五)09:30 将公布中国7月CPI(同比)与核心CPI。 市场预测CPI同比上涨 3.0% ,上月实际为 2.9% 。部分机构认为,食品分项涨幅扩大可能推高读数。
目标结构(你可以按需调整):
- 指标名(如"中国7月CPI(同比)")
- 发布时间(如"8月15日(周五)09:30")
- 预测值(如"3.0%")
- 上月实际值(如"2.9%")
- 备注/依据(可选,如"食品分项涨幅扩大...")
创建一个python文件,文件名:example_01.py,代码如下:
python
import textwrap
import langextract as lx
news_text = textwrap.dedent("""\
8月15日(周五)09:30 将公布中国7月CPI(同比)与核心CPI。
市场预测CPI同比上涨 3.0%,上月实际为 2.9%。
部分机构认为,食品分项涨幅扩大可能推高读数。
""")
prompt = textwrap.dedent("""\
请从输入的中文新闻段落中抽取与"经济指标发布"相关的信息:
- 指标名
- 发布时间
- 预测值
- 上月实际值
- 备注(若有)
要求:
- 使用输入中的原文片段作为 extraction_text
- 信息缺失时可以跳过该字段
""")
examples = [
lx.data.ExampleData(
text="将公布美国7月核心CPI,市场预测同比上涨 3.0%,上月为 2.9%。",
extractions=[
lx.data.Extraction("指标名", "美国7月核心CPI", attributes={"指标": "美国7月核心CPI"}),
lx.data.Extraction("预测值", "3.0%", attributes={"预测值": "3.0%"}),
lx.data.Extraction("上月实际值", "2.9%", attributes={"上月实际值": "2.9%"}),
]
)
]
model_config = lx.factory.ModelConfig(
#model_id="qwen/qwen3-30b-a3b",
model_id="qwen/qwen3-coder",
#model_id="qwen/qwen3-14b",
#model_id="qwen/qwen2.5-7b",
#model_id="deepseek/deepseek-v3-0324",
provider="OpenAILanguageModel",
provider_kwargs={
"base_url": "https://platform.aitools.cfd/api/v1", # 这里的不能使用下面的URL,要用base_url
#"model_url": "https://platform.aitools.cfd/api/v1/chat/completions",
"format_type": lx.data.FormatType.JSON,
"temperature": 0.1,
"api_key": "sk-b891a5d021********faf0a781",
},
)
model = lx.factory.create_model(model_config)
result = lx.extract(
text_or_documents=news_text,
prompt_description=prompt,
examples=examples,
model=model,
fence_output=False,
use_schema_constraints=False)
for e in result.extractions:
print(e.extraction_class, e.extraction_text, e.attributes)注意,这里使用了一个免费的大模型API,如果你也使用这个网站,需要自己去申请api key(免费,免注册)。详见这篇文章:免费大模型API,完美兼容OpenAI接口(零门槛,免注册)。不过由于是免费的大模型API,有时候有的模型会不可用,等过一阵或者换其他模型就好了。如果使用你自己部署的openai大模型,注意修改url和api_key。
执行代码使用如下命令:
shell
docker run --rm -v $(pwd):/app langextract-openai python example_01.py可以看到执行效果:

我尝试了几个qwen的模型,发现qwen/qwen3-coder这个模型最聪明。
实战二:从 销售日报抽"客户/合同/金额/日期/备注"
原文(示例数据):
【08-12】华东区------客户"晨光文具"签订补货单;金额 ¥189,990 ; 销售代表:王敏;备注:渠道促销返利至 9 月底有效。
创建一个python文件,文件名:example_02.py,代码如下:
python
import textwrap
import langextract as lx
sales_text = textwrap.dedent("""\
【08-12】华东区------客户"晨光文具"签订补货单;金额 ¥189,990;
销售代表:王敏;备注:渠道促销返利至 9 月底有效。
""")
prompt = textwrap.dedent("""\
请从销售日报中抽取以下字段:
- 客户名
- 金额(原文片段)
- 日期(原文片段)
- 销售代表
- 备注(如有)
要求:extraction_text 必须取自原文,并给出尽可能多的条目。
""")
examples = [
lx.data.ExampleData(
text="【08-01】华北区------客户"良品铺子"复购;金额 ¥50,000;销售代表:李雷;备注:季度冲量。",
extractions=[
lx.data.Extraction("客户名", "良品铺子"),
lx.data.Extraction("金额", "¥50,000"),
lx.data.Extraction("日期", "【08-01】"),
lx.data.Extraction("销售代表", "李雷"),
lx.data.Extraction("备注", "季度冲量"),
]
)
]
model_config = lx.factory.ModelConfig(
model_id="qwen/qwen3-14b",
provider="OpenAILanguageModel",
provider_kwargs={
"base_url": "https://platform.aitools.cfd/api/v1", # 这里的不能使用下面的后缀,要用base_url
#"model_url": "https://platform.aitools.cfd/api/v1/chat/completions",
# "format_type": lx.data.FormatType.JSON,
"temperature": 0.1,
"api_key": "sk-b891a5d021d44416b93390fbfaf0a781",
},
)
model = lx.factory.create_model(model_config)
result = lx.extract(
text_or_documents=sales_text,
prompt_description=prompt,
examples=examples,
model=model,
fence_output=False,
use_schema_constraints=False)
for e in result.extractions:
print(e.extraction_class, e.extraction_text, e.attributes)执行效果

到这里,一个仅使用Docker、不需要使用GPU、使用免费大模型API、可尝试不同大模型进行LangExtract验证的"低碳"方案就完成了(不是GPU、付费API用不起,而是免费低碳更有性价比)
特别感谢:
-
提供免费大模型API的组织,如:免费大模型API,完美兼容OpenAI接口(零门槛,免注册)
-
提供docker镜像的组织,如:daocloud;
-
提供pypi镜像的组织,如:清华大学。
正因为有了你们无私的提供资源,我们做技术预研时,丝滑般的体验才不逊于付费服务。
本篇是第一篇LangExtract的实战,下一篇我会结合实际业务场景中的案例做分享。