一、EvalScope 压测工具简介
EvalScope 是 ModelScope倾力打造的官方模型评估与性能基准测试框架,专为满足多样化的模型评测需求而设计,为开发者提供一站式解决方案。无论是前沿的大语言模型、多模态模型,还是专注于语义理解的 Embedding 模型、Reranker 模型等,EvalScope 均能提供全面支持,覆盖从基础能力到复杂场景的评估维度。
整体架构
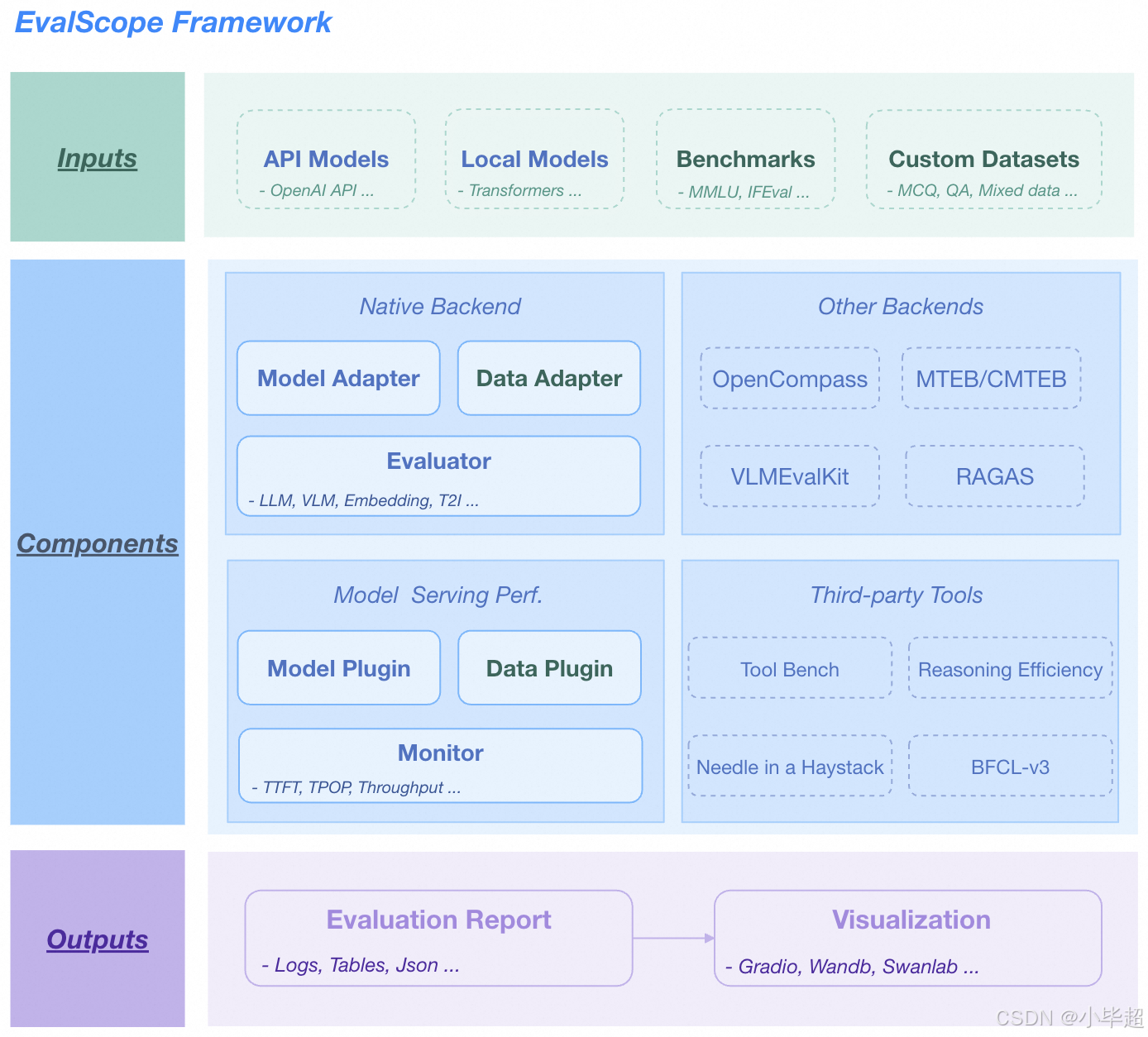
官方文档地址:
https://evalscope.readthedocs.io/zh-cn/latest/get_started/introduction.html
安装:
建议使用 python 3.10+ 版本
shell
pip install evalscope uvicorn fastapi sse_starlette安装完成后,可查看当前版本:
shell
evalscope -v
下面开始私有模型的部署和测试,测试机器:GPU(A6000 48G) x 2 共 96G 显存。
二、Qwen3-30B-A3B 测试模型部署
使用 modelscope 下载 Qwen3-30B-A3B 模型到本地:
shell
modelscope download --model="Qwen/Qwen3-30B-A3B" --local_dir Qwen3-30B-A3B
下载结束后,使用vLLM 启动API服务:
shell
export CUDA_VISIBLE_DEVICES=0,1
vllm serve "Qwen3-30B-A3B" \
--host 0.0.0.0 \
--port 8060 \
--dtype bfloat16 \
--cpu-offload-gb 0 \
--gpu-memory-utilization 0.8 \
--tensor-parallel-size 2 \
--api-key sk-abcdefxxx \
--enable-prefix-caching \
--enable-reasoning \
--reasoning-parser deepseek_r1\
--trust-remote-code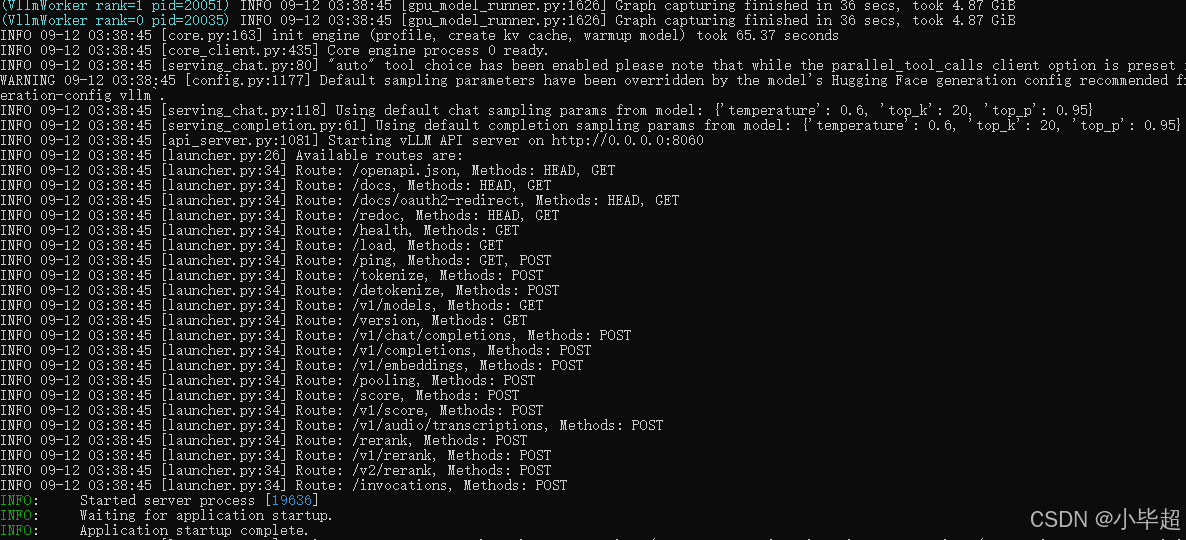
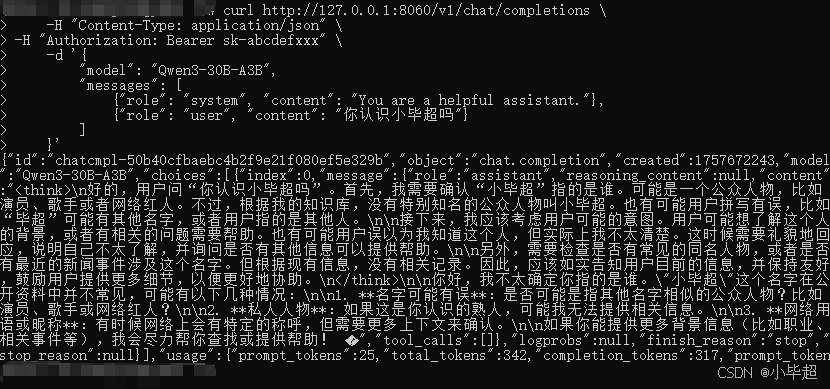
启动成功后,测试API请求,验证是否部署成功:
shell
curl http://127.0.0.1:8060/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-abcdefxxx" \
-d '{
"model": "Qwen3-30B-A3B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你认识小毕超吗"}
]
}'
三、EvalScope 性能压测
这里使用 AI-ModelScope/HC3-Chinese 数据集进行压测,ModelScope 地址如下:
https://www.modelscope.cn/datasets/AI-ModelScope/HC3-Chinese/files
数据集内容样例:
json
{"question":"盗贼天赋盗贼怎么加天赋?知道告诉一下下啦~~ ","human_answers":["搞匕首还加出血(楼上)?\r\n天赋看你喜爱了,31 8 12 和 21 8 22 PK都好,\r\n17 34 是团队副本贼,玩输出的,武器建议1匕首1剑。"],"chatgpt_answers":["如果你在玩角色扮演游戏(RPG),那么你可能是在问如何在游戏中给你的盗贼角色加天赋。具体方法可能因游戏而异,但通常有以下几种方法: \n1. 在游戏开始时选择盗贼天赋:在游戏开始时,你可以选择你想要的天赋。这通常是通过选择不同的角色种族或职业来实现的。 \n2. 在游戏进程中获得天赋:在游戏进程中,你可能会获得一些与盗贼相关的天赋。这可能是通过完成任务、升级或解锁新的技能来实现的。 \n3. 使用道具或装备获得天赋:你可能会发现一些道具或装备,它们可以赋予你一些盗贼天赋。这些道具或装备通常是随机生成的,或者是你在游戏进程中获得的奖励。 \n希望这些信息对你有所帮助!"]}
{"question":"Ps2比 画面好吗?差距很大吗? Ps2比psp画面好吗?差距很大吗? ","human_answers":["毕竟显示媒介一个大,另一个只是小屏幕,所以单凭肉眼观察我觉得差距不大的,而且psp有些技术领先一点点。\r\n比起画面,我觉得流畅度是关键,在掌机上画面"卡"的危险似乎更严重,呃......"],"chatgpt_answers":["PlayStation 2 (PS2) 的画面质量通常要高于 PlayStation Portable (PSP)。PS2 是一款游戏机,而 PSP 是一款掌上游戏机,因此 PS2 有更强大的处理能力和更大的显示屏,这使得它能够提供更高分辨率和更流畅的画面。 \n但是,这并不意味着 PSP 的画面质量差得很多。在当时,PSP 的画面质量也是相当不错的,而且由于它是便携式游戏机,因此可以在任何地方玩游戏。 \n总的来说,PS2 的画面质量要优于 PSP,但这并不意味着 PSP 的画面质量很差。希望这能帮到你。"]}
{"question":"加装方向助力我有一普桑想加装一套方向助力可以吗??怎么改? ","human_answers":["普桑想加装一套方向助力可以的.\r\n首先要换方向机,曲轴皮带盘.\r\n加装助力泵油管,助力泵油壶,助力泵皮带,助力泵,助力泵支架等.两个工时不行,一般需要3000\/6000元左右.\r\n"],"chatgpt_answers":["是的,您可以尝试在您的普桑车辆上安装方向助力系统。但是,在安装前,您需要考虑几个因素: \n1. 您的车辆是否有预留的电缆和插头,可以用于安装方向助力系统。 \n2. 您是否具有适当的技能和工具来安装方向助力系统。 \n3. 您是否已经获得了厂家或经销商的许可,并购买了适用于您的车辆的正确的方向助力系统。 \n如果您确定您的车辆符合以上要求,并且您有适当的技能和工具来安装方向助力系统,那么您可以尝试自行安装。否则,建议您寻求专业的汽车维修机构的帮助。","如果您想在您的普桑车辆上安装方向助力系统,那么您需要首先评估这个任务的难度和您的技能水平。 如果您没有汽车维修经验或者不熟悉您的车辆,那么我建议您向专业技师寻求帮助。 \n如果您决定自己安装方向助力系统,那么您需要准备一些工具,包括扳手、马达拆装工具、涂层测厚仪、冷媒收回器、冷媒灭火器和保险丝刀。 \n安装方向助力系统的步骤大致如下: \n1. 关闭车辆的电源,确保车辆安全。 \n2. 打开车辆的引擎盖,找到方向助力泵。 \n3. 使用扳手将泵固定螺栓拆下。 \n4. 使用马达拆装工具将泵与电机解开。 \n5. 将新的方向助力泵安装到原来的位置上。 \n6. 使用涂层测厚仪测量车辆的涂层厚度,确保新的方向助力泵的安装位置不会受到损坏。 \n7. 将冷媒收回器连接到泵上,并使用冷媒灭火器将泵内的空气放出。 \n8. 安装好泵后,使用保险丝刀将泵固定螺栓拧紧。 \n9. 将引擎"]}
{"question":"比斯巨兽的皮干什么用的?多少钱? ","human_answers":["做史诗装备用的~~把比斯巨兽(黑石塔上层的一个BOSS)的皮拨了(很小几率出比斯巨兽皮~大部分是厚皮)不管是不是出比斯巨兽的皮都会出现一个地精(从巨兽肚子中出来的)会给你一个任务这个任务要去冬泉交(交给冬泉瑟银会的NPC)~交完之后他身后有本书上面写着3件史诗装备所需要的原料(都需要比斯巨兽皮和其他物品)\r\n忘记说多少钱了~我们服是600G~700G不一样的服价格也不一样~"],"chatgpt_answers":["比斯巨兽是什么?我不知道这是什么东西。您可以告诉我更多关于比斯巨兽的信息吗?我将尽力帮助您。"]}
{"question":"神州行手机号码成为空号了怎么办,卡里还有几十圆钱,还可以再用吗 ","human_answers":["如果停机时间不长,可以到移动公司营业厅办理余额转移的。"],"chatgpt_answers":["如果您的神州行手机号码已经成为空号,您可以尝试联系神州行客服进行处理。神州行客服通常会帮助您转移到新的号码或者退还您卡内剩余的余额。 \n如果您无法联系到神州行客服或者无法解决问题,您可以考虑向当地电信主管部门投诉或者寻求帮助。通常,电信主管部门会有专门的投诉处理机构,可以帮助您解决相关问题。 \n在此之前,建议您先查看神州行的相关服务条款,了解有关退还余额的规定。一般来说,如果您的卡内余额较少,可能无法退还。 \n希望以上信息能帮助到您!","如果您的神州行手机号码成为空号,您可以联系神州行的客服进行处理。如果您的卡内还有剩余的话题,可以尝试联系神州行的客服询问是否可以将剩余的余额退还给您。但是,如果您的卡已经过期或者已经停用,则可能无法使用剩余的余额。建议您联系神州行的客服进行咨询,以确定您的具体情况。"]}
{"question":"最近脸上长了好多脂肪粒,这个该怎么破? 记得前段时间你好像也有~","human_answers":["脂肪粒是因为肌肤没有清洁干净导致营养过剩,和内分泌失调所导致形成的,你首先要做好清洁,给肌肤做好按摩这个最基本的方法就是要好好的护理了,把所以的面霜系列的擦的都换成比较清爽的,慢慢的就会有所改变了,诚心为你解答,麻烦给好评哦,谢谢亲!"],"chatgpt_answers":["脂肪粒通常是由于皮肤内脂肪堆积而形成的小圆点。它们通常出现在面部、背部和手臂等地方。脂肪粒并不是疾病,但它们可能会让人感觉不舒服或不美观。如果你想要消除脂肪粒,建议你考虑以下几种方法: \n1. 使用含有果酸的护肤品:果酸有助于去除死皮细胞,促进肌肤新陈代谢。 \n2. 定期使用磨砂膏或去角质产品:磨砂膏和去角质产品可以帮助脱落死皮细胞,促进新陈代谢。 \n3. 使用美容仪器:如电子美容仪、毛孔清洁仪等。这些仪器可以帮助清除脂肪粒和毛孔堵塞物,改善肌肤状态。 \n4. 合理饮食:适当的饮食习惯可以帮助改善皮肤状况,减少脂肪粒的形成。 \n5. 考虑使用医学美容方法:如激光去角质、微针疗法等。这些方法可以帮助去除脂肪粒,但需要在专业医疗机构进行。 \n总的来说,预防脂肪粒的形成比治疗脂肪粒更为有效。建议你注","脂肪粒通常是由角质层堆积形成的小硬块,常见于面部、手臂和腿部。通常情况下,脂肪粒是比较容易清除的,但是如果不慎挤压或挑剔,可能会导致感染、红肿或疤痕。 \n如果你想清除脂肪粒,最好的方法是使用专业的清洁产品和方法,或者寻求专业的医疗机构的帮助。这些方法包括: \n1. 补水和保湿:使用含有维生素A、C和E的保湿霜或乳液,可以帮助软化角质层并提升皮肤弹性。 \n2. 去角质:使用去角质产品,如磨砂膏或去角质水,可以帮助脱落老旧角质层。 \n3. 真皮细胞修复:使用含有胶原蛋白、弹性蛋白和尿素的真皮细胞修复产品,可以帮助修复皮肤组织并减少角质层生成。 \n4. 医疗美容:可以寻求专业的医疗美容机构的帮助,使用吸脂、激光去角质或微针等方法,可以有效地清除脂肪粒。 \n在使用任何清洁产品或接受任何医疗美容服务之前,最好咨"]}
{"question":"菠营养很丰富,那每天吃多少为益? 菠菜能多吃吗?菠菜营养很丰富,那每天吃多少为益? ","human_answers":["菠菜营养丰富,味道鲜美。但据营养学家分析,菠菜中的草酸,会使饮食中的宝贵元素锌和钙与草酸结合而排出体外,引起人体缺锌、缺钙,因而妨碍身体健康。故营养学家指出,菠菜不宜多吃。"],"chatgpt_answers":["菠菜是一种非常健康的蔬菜,它含有大量的维生素和矿物质,并且很少含有卡路里和脂肪。然而,每个人的营养需要是不同的,所以建议你与医生或营养师询问关于你个人每天摄入菠菜的建议量。 \n一般来说,建议每天摄入蔬菜的量为2-3杯,其中一杯相当于1杯(80克)新鲜或冷冻蔬菜,或者1\/2杯(80克)煮熟的蔬菜。这样可以帮助你满足每天推荐的蔬菜摄入量。 \n同时,建议你尽量多吃不同种类的蔬菜,以获得多样的营养。也可以尝试使用不同的烹饪方法,例如蒸、煮、炒、烤等,以增加蔬菜的口感和风味。"]}
{"question":"哈尔滨院附近的旅店多吗?价位大概是什么样的 哈尔滨金融学院附近的旅店多吗?价位大概是什么样的 ","human_answers":["单间80多,如果住的天数多70多。里面有一个单独的卫生间,是隔出来的那种。其他的不是很清楚。另外德强那边有一个新开的巧克力时钟旅馆,听干净的,价格和相约谷差不多。你可以去看看。便宜点的还有恒久附近的,50多,但是没有单独的卫生间。都有电脑可以上网的。学校附近的小宾馆 旅社很多 学校里面也有非常多基本60-80左右"],"chatgpt_answers":["哈尔滨院附近的旅店应该有很多种选择。价位的大小可能会因为你选择的旅店的星级、地理位置和其他因素而有所不同。通常来说,哈尔滨市中心的旅店价格会比市郊的旅店价格略高。 \n哈尔滨金融学院附近也应该有很多旅店可供选择。价格可能会因为旅店的星级、地理位置和其他因素而有所不同。如果你想要查找附近的旅店,你可以使用在线旅游网站或手机应用来比较不同旅店的价格和设施,并作出决策。","哈尔滨院附近和哈尔滨金融学院附近可能会有很多旅店,但我无法提供具体的信息。价位可能会因为季节、需求和其他因素而有所不同。如果您想要找到适合您的旅店,建议您使用旅游网站或酒店预订网站进行查询,或者直接联系酒店进行咨询。"]}
{"question":"天津大悦城附近有什么好吃的?3个人吃 ","human_answers":["天津食品街就在大悦城附近,里面不少天津特色食品,选择余地很大。大悦城里的"鹿港小镇"不错。"],"chatgpt_answers":["天津大悦城周边有很多不同风味的餐馆和美食店。这里是一些可能值得一试的地方: \n1. 沈阳烤鸭:这是一家著名的烤鸭店,提供传统的沈阳烤鸭和其他烤肉美食。 \n2. 老麻婆豆腐:这是一家著名的川菜餐馆,提供各种美味的川菜和豆腐美食。 \n3. 日本料理:这是一家日本料理店,提供各种传统的日本料理,包括寿司、生鱼片、拉面和握寿司。 \n4. 杜莎夫人蜡像馆餐厅:这是一家位于天津大悦城内的餐厅,提供英式美食和饮料,并有杜莎夫人蜡像馆的模型展览。 \n5. 意大利餐厅:这是一家提供意大利菜肴的餐厅,包括意大利面、比萨、意式海鲜和甜点。 \n希望这些建议能帮到你。"]}
{"question":"怎样向中的女孩子说出第一句话?说什么? 怎样向暗恋中的女孩子说出第一句话?说什么? ","human_answers":["要看你们的认识的程度而定。\n如果她还不认识你,你可以大方点,去介绍自己,以便让她知道有你这个人。\n如果你们已经认识或是同班同学,有空的时候多关注点她喜欢什么,那样比较好找话题说。 女生嘛,只要你说的话,点到了她热忱的那个点,话匣子也就打开了。最重要的是真诚,大方,自然。\n(竭力为您解答,希望给予【好评】,非常感谢~~)"],"chatgpt_answers":["当你想向中国女孩子说出第一句话时,你应该先考虑一些基本的礼貌,例如问她的名字或者问她是否愿意和你交谈。你也可以先说出你自己的名字,然后问她是否愿意认识你。你可以说:\"你好,我叫XXX,你叫什么名字?你愿意和我聊一聊吗?\" \n如果你暗恋中的女孩子是你的朋友,你可以先尝试着和她更多地交流,看看她对你有没有兴趣。如果你想向她表白,你可以说:\"我很喜欢你,我希望我们能够在一起。你愿意跟我约会吗?\" 你也可以试着先询问她的感受,看看她对你有没有感觉。你可以说:\"我近来常常想起你,你对我有什么感觉?\" \n请注意,这些都只是建议,并不能保证一定会成功。重要的是要自信,并且尊重女孩子的感受和选择。","当你想向一个女孩子说出第一句话时,重要的是要保持自信并尽量自然。你可以先说一句问候,例如"你好!"或"嗨!"然后你可以问她的名字,或者谈谈你们两个人的共同兴趣。例如,如果你们在一个社交活动中,你可以说"你对这个活动有什么看法?"或"你最喜欢什么音乐?" \n如果你暗恋一个女孩子,你可以考虑给她发一条信息,告诉她你对她有感觉。但是,在这样做之前,你应该先想清楚你为什么要告诉她,并且要准备好接受可能的后果。你可以说:"我知道这可能是我们俩之间的第一次谈话,但我想告诉你,我对你有感觉。我想了解你更多,并且希望能有机会跟你在一起。"重要的是要表达出你真实的感受,并且尊重对方的感受。"]}
{"question":"我想买一辆童车,请问什么牌子的好?济南的专卖童车的地方在那儿? ","human_answers":["是小推车吗?还是三轮车?新世界商城一楼有个专卖柜台.但是因为店主怕压货,所以现货不多,你要从他的购车指南中选好,定货.老板才给你进货.稍麻烦了些,但质量有保证,价格比银座要便宜多了,品种也全,是好孩子的."],"chatgpt_answers":["童车是一种重要的交通工具,在选择童车时,您应该考虑质量、安全性和适用年龄段。市场上有很多不同的童车品牌,其中一些较受欢迎的品牌包括:捷安特、哈雷、威海、捷成、沃尔沃、自行车、拜单车等。 \n如果您住在济南,您可以在当地的自行车店或童车专卖店购买童车。您也可以在线搜索并在网上购买童车。在购买之前,建议您询问有关童车的信息,并在购买前进行调查。","童车市场上有许多不同的品牌,包括捷安特、儿童天地、沃尔沃、拜耳、特步等。这些品牌的童车都有其独特的优点,因此在选择童车时,建议您根据自己的需求和预算来选择合适的品牌。 \n如果您在济南,可以尝试在当地的商场或家用电器店寻找童车。您也可以在网上搜索"济南童车专卖店",可能会有更多选择。建议您去多家店看看,了解不同品牌的童车,然后再做出决定。"]}
{"question":"小伙伴们 这个叫什么名字 求科普[玫瑰][玫瑰][玫瑰]","human_answers":["这个是紫薇花。。是中间那个粉色的吗?这是紫薇花,正是花季,开得灿烂着呢。这个是紫薇花,呵呵这个就是藤类植物紫薇花五。这是紫薇花,多年生木本这是紫薇花这是漂亮的紫薇花。"],"chatgpt_answers":["这个符号叫玫瑰(Rose)。玫瑰是一种常见的花卉植物,原产于欧洲、亚洲和非洲。它有着象征爱情和美丽的花朵,常被用作节日礼物或装饰品。在网络上,玫瑰也常被用作表情符号,用来表达爱意或友好。"]}下载数据集到本地:
shell
modelscope download --dataset AI-ModelScope/HC3-Chinese --local_dir AI-ModelScope/HC3-Chinese
下面开始性能压测:分三组测试,每组 100 个用例,发起 2、5、10 个并发请求的测试场景,用于观察系统在不同负载下的表现。
python
from evalscope.perf.main import run_perf_benchmark
from evalscope.perf.arguments import Arguments
task_cfg = Arguments(
parallel=[2, 5, 10], ## 请求的并发数
number=[100, 100, 100], ## 发出的请求的总数量
model='Qwen3-30B-A3B', ## 测试模型的名称
url='http://127.0.0.1:8060/v1/chat/completions', ## vLLM 部署后 openai规范的 URL地址
api_key="sk-abcdefxxx", ## api key
api='openai', ## 使用的API服务
dataset='openqa', ## 测试数据集模式
dataset_path="AI-ModelScope/HC3-Chinese/open_qa.jsonl", ## 测试数据集地址
temperature=0.6, ## 模型温度
max_tokens=1024, ## 最大token数量
prefix_length=0, ## promt的前缀长度,仅对于random数据集有效。
min_prompt_length=8, ## 最小输入prompt长度,小于该值时,将丢弃prompt。
max_prompt_length=1024, ## 最大输入prompt长度,大于该值时,将丢弃prompt。
tokenizer_path='Qwen/Qwen3-30B-A3B', ## 模型的tokenizer路径,用于计算token数量
extra_args={'ignore_eos': True}, ## 求中的额外的参数,传入json格式的字符串
connect_timeout=30, ## 连接超时时间,单位 s
read_timeout=60, ## 读取超时时间,单位 s
outputs_dir="outputs" ## 测试记录保存目录
)
results = run_perf_benchmark(task_cfg)其中参数的含义都已注释说明,更多参数的说明,可参考下面地址:
https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/parameters.html
压测过程输出:
第一组测试结果:
shell
Benchmarking summary:
+-----------------------------------+-----------+
| Key | Value |
+===================================+===========+
| Time taken for tests (s) | 675.359 |
+-----------------------------------+-----------+
| Number of concurrency | 2 |
+-----------------------------------+-----------+
| Total requests | 100 |
+-----------------------------------+-----------+
| Succeed requests | 100 |
+-----------------------------------+-----------+
| Failed requests | 0 |
+-----------------------------------+-----------+
| Output token throughput (tok/s) | 151.623 |
+-----------------------------------+-----------+
| Total token throughput (tok/s) | 155.901 |
+-----------------------------------+-----------+
| Request throughput (req/s) | 0.1481 |
+-----------------------------------+-----------+
| Average latency (s) | 13.5064 |
+-----------------------------------+-----------+
| Average time to first token (s) | 0.0623 |
+-----------------------------------+-----------+
| Average time per output token (s) | 0.0131 |
+-----------------------------------+-----------+
| Average inter-token latency (s) | 0.0131 |
+-----------------------------------+-----------+
| Average input tokens per request | 28.89 |
+-----------------------------------+-----------+
| Average output tokens per request | 1024 |
+-----------------------------------+-----------+
Percentile results:
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+
| Percentiles | TTFT (s) | ITL (s) | TPOT (s) | Latency (s) | Input tokens | Output tokens | Output (tok/s) | Total (tok/s) |
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+
| 10% | 0.0411 | 0.01 | 0.013 | 13.3838 | 19 | 1024 | 75.2313 | 76.9197 |
| 25% | 0.0455 | 0.0123 | 0.0131 | 13.4552 | 23 | 1024 | 75.4796 | 77.4364 |
| 50% | 0.0533 | 0.0131 | 0.0132 | 13.5113 | 28 | 1024 | 75.7962 | 77.8522 |
| 66% | 0.0587 | 0.0135 | 0.0132 | 13.559 | 31 | 1024 | 75.9294 | 78.2307 |
| 75% | 0.0637 | 0.0138 | 0.0132 | 13.5712 | 34 | 1024 | 76.1169 | 78.5374 |
| 80% | 0.0666 | 0.0141 | 0.0132 | 13.5798 | 36 | 1024 | 76.1874 | 78.6722 |
| 90% | 0.0795 | 0.0158 | 0.0132 | 13.6136 | 40 | 1024 | 76.5128 | 79.0602 |
| 95% | 0.093 | 0.018 | 0.0133 | 13.6852 | 43 | 1024 | 76.8528 | 79.2871 |
| 98% | 0.3761 | 0.0218 | 0.0133 | 13.7594 | 45 | 1024 | 77.9405 | 79.8028 |
| 99% | 0.4263 | 0.0252 | 0.0133 | 13.7725 | 48 | 1024 | 78.0498 | 80.3 |
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+第二组测试结果:
shell
Benchmarking summary:
+-----------------------------------+-----------+
| Key | Value |
+===================================+===========+
| Time taken for tests (s) | 472.911 |
+-----------------------------------+-----------+
| Number of concurrency | 5 |
+-----------------------------------+-----------+
| Total requests | 100 |
+-----------------------------------+-----------+
| Succeed requests | 100 |
+-----------------------------------+-----------+
| Failed requests | 0 |
+-----------------------------------+-----------+
| Output token throughput (tok/s) | 216.531 |
+-----------------------------------+-----------+
| Total token throughput (tok/s) | 222.64 |
+-----------------------------------+-----------+
| Request throughput (req/s) | 0.2115 |
+-----------------------------------+-----------+
| Average latency (s) | 23.6354 |
+-----------------------------------+-----------+
| Average time to first token (s) | 0.0745 |
+-----------------------------------+-----------+
| Average time per output token (s) | 0.023 |
+-----------------------------------+-----------+
| Average inter-token latency (s) | 0.023 |
+-----------------------------------+-----------+
| Average input tokens per request | 28.89 |
+-----------------------------------+-----------+
| Average output tokens per request | 1024 |
+-----------------------------------+-----------+
2025-09-12 16:51:23 - evalscope - INFO:
Percentile results:
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+
| Percentiles | TTFT (s) | ITL (s) | TPOT (s) | Latency (s) | Input tokens | Output tokens | Output (tok/s) | Total (tok/s) |
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+
| 10% | 0.0573 | 0.0184 | 0.0227 | 23.3292 | 19 | 1024 | 42.5017 | 43.7297 |
| 25% | 0.0617 | 0.0214 | 0.0228 | 23.3948 | 23 | 1024 | 43.0261 | 44.1576 |
| 50% | 0.0739 | 0.023 | 0.023 | 23.6245 | 28 | 1024 | 43.3658 | 44.6715 |
| 66% | 0.0805 | 0.0239 | 0.0231 | 23.6949 | 31 | 1024 | 43.597 | 44.8576 |
| 75% | 0.0852 | 0.0245 | 0.0232 | 23.8011 | 34 | 1024 | 43.7712 | 44.9967 |
| 80% | 0.0874 | 0.025 | 0.0232 | 23.8186 | 36 | 1024 | 43.7761 | 45.0526 |
| 90% | 0.099 | 0.027 | 0.0235 | 24.1089 | 40 | 1024 | 43.8945 | 45.3096 |
| 95% | 0.101 | 0.0295 | 0.0236 | 24.1704 | 43 | 1024 | 43.9496 | 45.481 |
| 98% | 0.1075 | 0.0338 | 0.0236 | 24.1859 | 45 | 1024 | 44.001 | 45.6114 |
| 99% | 0.11 | 0.0377 | 0.0236 | 24.1864 | 48 | 1024 | 44.032 | 45.8234 |
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+第三组测试结果:
shell
Benchmarking summary:
+-----------------------------------+-----------+
| Key | Value |
+===================================+===========+
| Time taken for tests (s) | 295.101 |
+-----------------------------------+-----------+
| Number of concurrency | 10 |
+-----------------------------------+-----------+
| Total requests | 100 |
+-----------------------------------+-----------+
| Succeed requests | 100 |
+-----------------------------------+-----------+
| Failed requests | 0 |
+-----------------------------------+-----------+
| Output token throughput (tok/s) | 346.999 |
+-----------------------------------+-----------+
| Total token throughput (tok/s) | 356.789 |
+-----------------------------------+-----------+
| Request throughput (req/s) | 0.3389 |
+-----------------------------------+-----------+
| Average latency (s) | 29.4908 |
+-----------------------------------+-----------+
| Average time to first token (s) | 0.1014 |
+-----------------------------------+-----------+
| Average time per output token (s) | 0.0287 |
+-----------------------------------+-----------+
| Average inter-token latency (s) | 0.0287 |
+-----------------------------------+-----------+
| Average input tokens per request | 28.89 |
+-----------------------------------+-----------+
| Average output tokens per request | 1024 |
+-----------------------------------+-----------+
2025-09-12 16:56:26 - evalscope - INFO:
Percentile results:
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+
| Percentiles | TTFT (s) | ITL (s) | TPOT (s) | Latency (s) | Input tokens | Output tokens | Output (tok/s) | Total (tok/s) |
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+
| 10% | 0.074 | 0.023 | 0.0281 | 28.9072 | 19 | 1024 | 34.1526 | 34.89 |
| 25% | 0.0805 | 0.0263 | 0.0283 | 29.0776 | 23 | 1024 | 34.257 | 35.2821 |
| 50% | 0.0953 | 0.0287 | 0.0287 | 29.4917 | 28 | 1024 | 34.7387 | 35.6845 |
| 66% | 0.1097 | 0.0301 | 0.029 | 29.808 | 31 | 1024 | 35.121 | 36.0233 |
| 75% | 0.113 | 0.031 | 0.0291 | 29.894 | 34 | 1024 | 35.2205 | 36.2242 |
| 80% | 0.1199 | 0.0316 | 0.0292 | 29.921 | 36 | 1024 | 35.2986 | 36.2731 |
| 90% | 0.1414 | 0.0338 | 0.0294 | 30.1177 | 40 | 1024 | 35.4454 | 36.4915 |
| 95% | 0.1588 | 0.0363 | 0.0294 | 30.2217 | 43 | 1024 | 35.4746 | 36.5809 |
| 98% | 0.1656 | 0.0412 | 0.0294 | 30.2226 | 45 | 1024 | 35.4989 | 36.8805 |
| 99% | 0.1683 | 0.0468 | 0.0294 | 30.2229 | 48 | 1024 | 35.5187 | 36.97 |
+-------------+----------+---------+----------+-------------+--------------+---------------+----------------+---------------+最后测试报告:
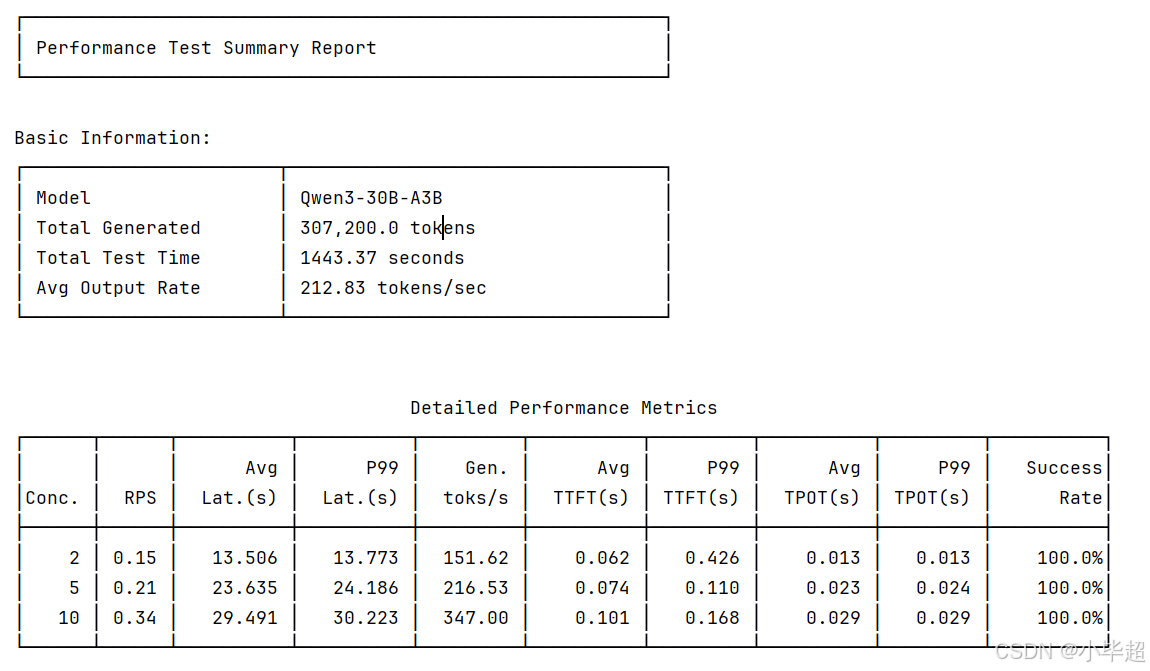
整体看下来,Qwen3-30B-A3B 性能还是比较好的,随着并发数从2增至10,输出token吞吐量从151.6 tok/s提升至 347.0 tok/s,当然延迟也发生了相应的增长从13.5s 涨到 29.5s 。但首包延迟始终保持在极低的毫秒级别,其次 P99 延迟与平均延迟基本表现一致,整体看下来该模型在该测试机器上的性能是较优异的。
以下是对压测结果中指标计算方式的解释:
| 指标 | 英文名称 | 解释 | 公式 |
|---|---|---|---|
| 测试总时长 | Time taken for tests | 整个测试过程从开始到结束所花费的总时间 | 最后一个请求结束时间 - 第一个请求开始时间 |
| 并发数 | Number of concurrency | 同时发送请求的客户端数量 | 预设值 |
| 总请求数 | Total requests | 在整个测试过程中发送的所有请求的数量 | 成功请求数 + 失败请求数 |
| 成功请求数 | Succeed requests | 成功完成并返回预期结果的请求数量 | 直接统计 |
| 失败请求数 | Failed requests | 由于各种原因未能成功完成的请求数量 | 直接统计 |
| 输出吞吐量 | Output token throughput | 每秒钟处理的平均标记(token)数 | 总输出token数 / 测试总时长 |
| 总吞吐量 | Total token throughput | 每秒钟处理的平均标记(token)数 | (总输入token数 + 总输出token数) / 测试总时长 |
| 请求吞吐量 | Request throughput | 每秒钟成功处理的平均请求数 | 成功请求数 / 测试总时长 |
| 总延迟时间 | Total latency | 所有成功请求的延迟时间总和 | 所有成功请求的延迟时间之和 |
| 平均延迟 | Average latency | 从发送请求到接收完整响应的平均时间 | 总延迟时间 / 成功请求数 |
| 平均首token时间 | Average time to first token | 从发送请求到接收到第一个响应标记的平均时间 | 总首chunk延迟 / 成功请求数 |
| 平均每输出token时间 | Average time per output token | 生成每个输出标记所需的平均时间(不包含首token) | 总每输出token时间 / 成功请求数 |
| 平均输出token间时延 | Average inter-token latency | 生成每个输出token之间的平均间隔时间 | 总输出token间时延 / 成功请求数 |
| 平均输入token数 | Average input tokens per request | 每个请求的平均输入标记数 | 总输入token数 / 成功请求数 |
| 平均输出token数 | Average output tokens per request | 每个请求的平均输出标记数 | 总输出token数 / 成功请求数 |
百分位指标 (Percentile)
以单个请求为单位进行统计,数据被分为 100 个相等部分,第 n 百分位表示有 n% 的数据点在此值以下。
| 指标 | 英文名称 | 解释 |
|---|---|---|
| 首次生成token时间 | TTFT | 从发送请求到生成第一个 token 的时间(以秒为单位),评估首包延迟。 |
| 输出token间时延 | ITL | 生成每个输出 token 之间的间隔时间(以秒为单位),用于评估输出是否平稳。 |
| 每token延迟 | TPOT | 生成每个输出 token 所需的时间(不包含首 token,以秒为单位),用于评估解码速度。 |
| 端到端延迟时间 | Latency | 从发送请求到接收完整响应的时间(以秒为单位);计算公式为:TFT + TPOT × Output tokens。 |
| 输入token数 | Input tokens | 请求中输入的 token 数量。 |
| 输出token数 | Output tokens | 响应中生成的 token 数量。 |
| 输出吞吐量 | Output Throughput | 每秒输出的 token 数量,计算方式为:输出 tokens / 端到端延迟时间。 |
| 总吞吐量 | Total throughput | 每秒处理的 token 数量,计算方式为:(输入 tokens + 输出 tokens) / 端到端延迟时间。 |