文章目录
一、准备环境
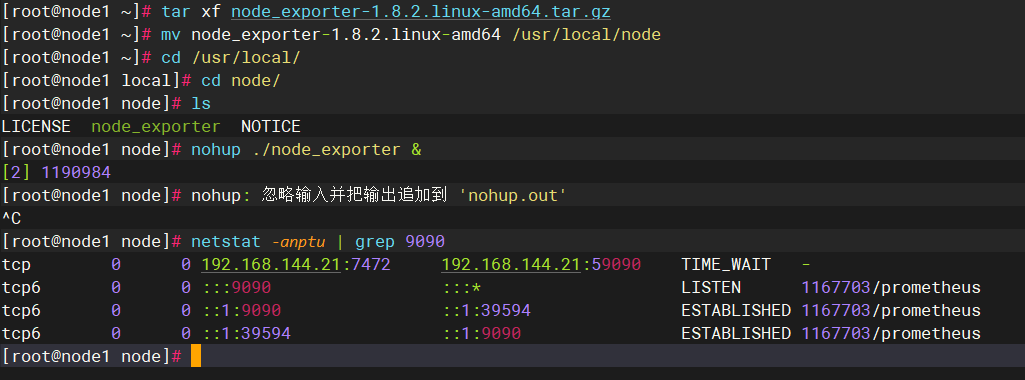
这个可以从github官网下载

查看9090端口号是否被占用,没有的话,解压后可以做链接优化下
并放在后台启动
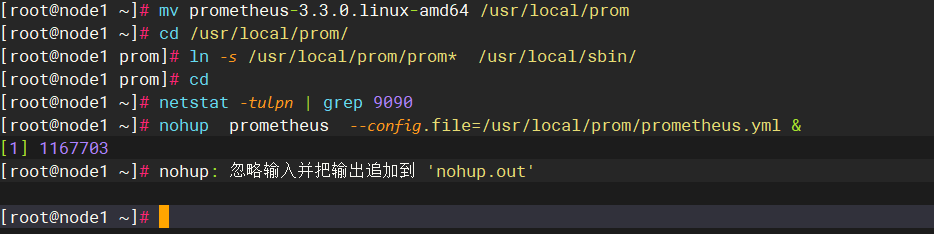
查看内容:会在终端生成文件
二、部署prometheus服务监控端
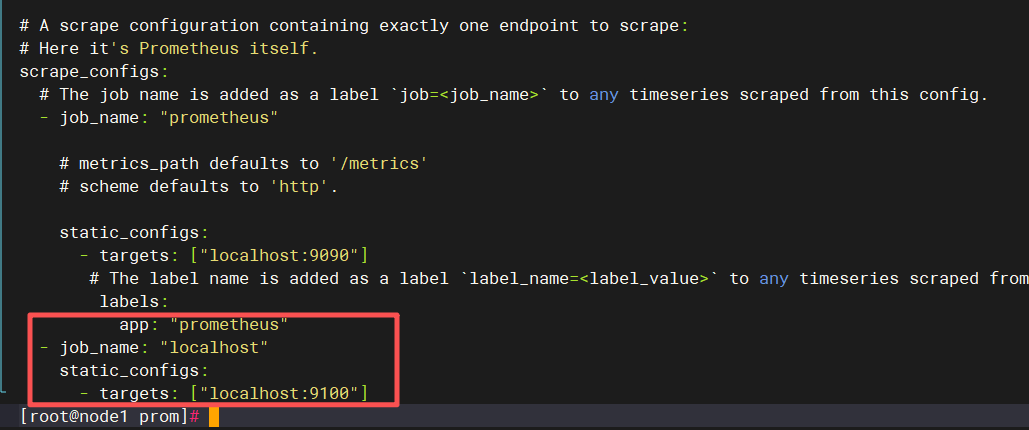
导入node这个包,

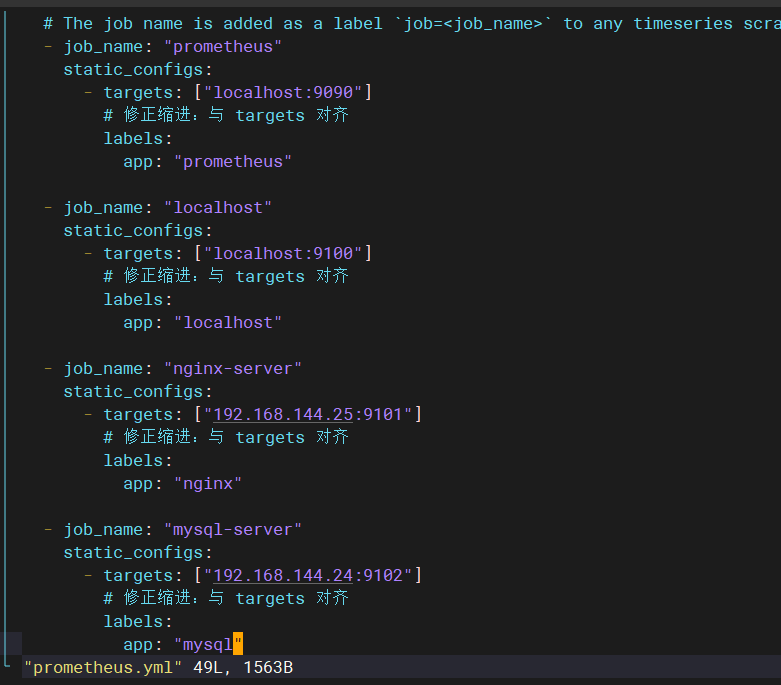
添加监控信息:
prometheus.yml 文件中添加
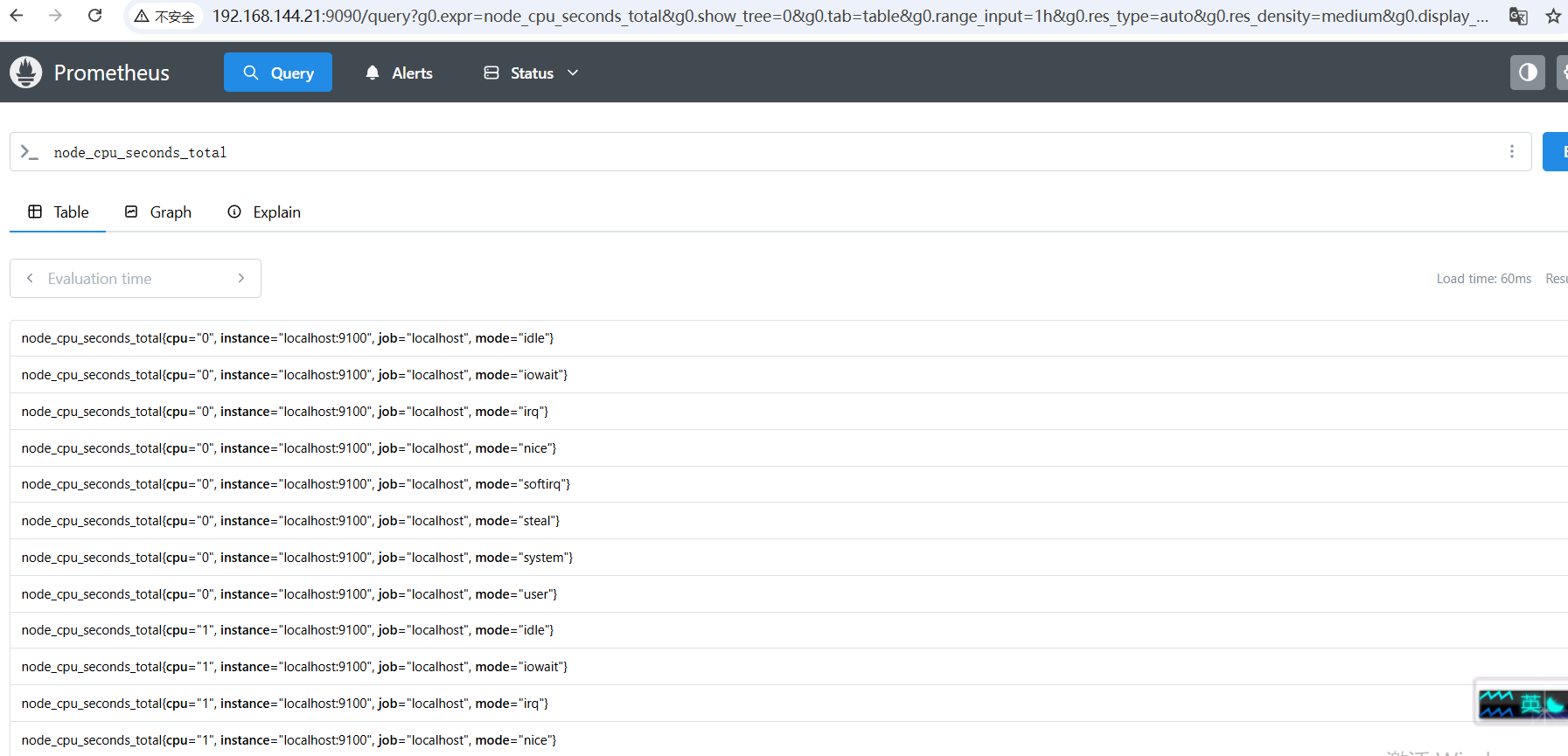
重新启动:

访问:
三、监控本地主机
在当前主机上解压 grafana这个软件包
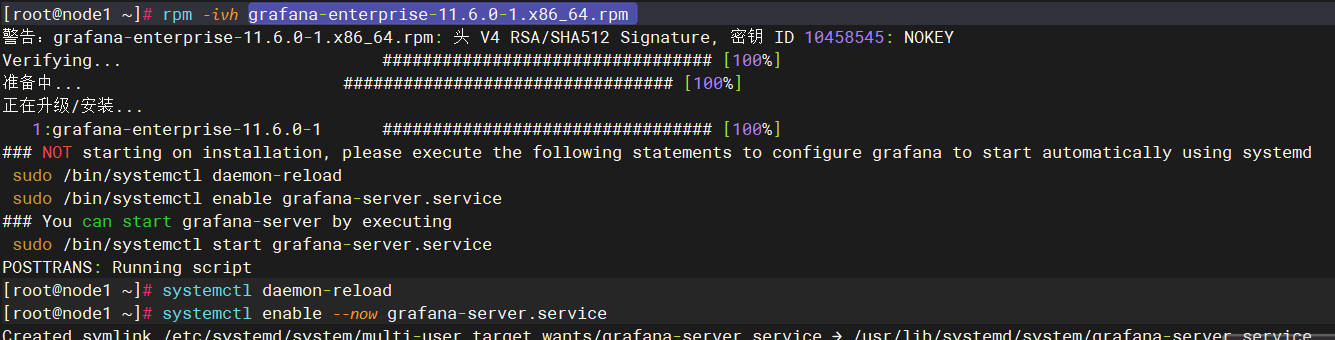
访问:

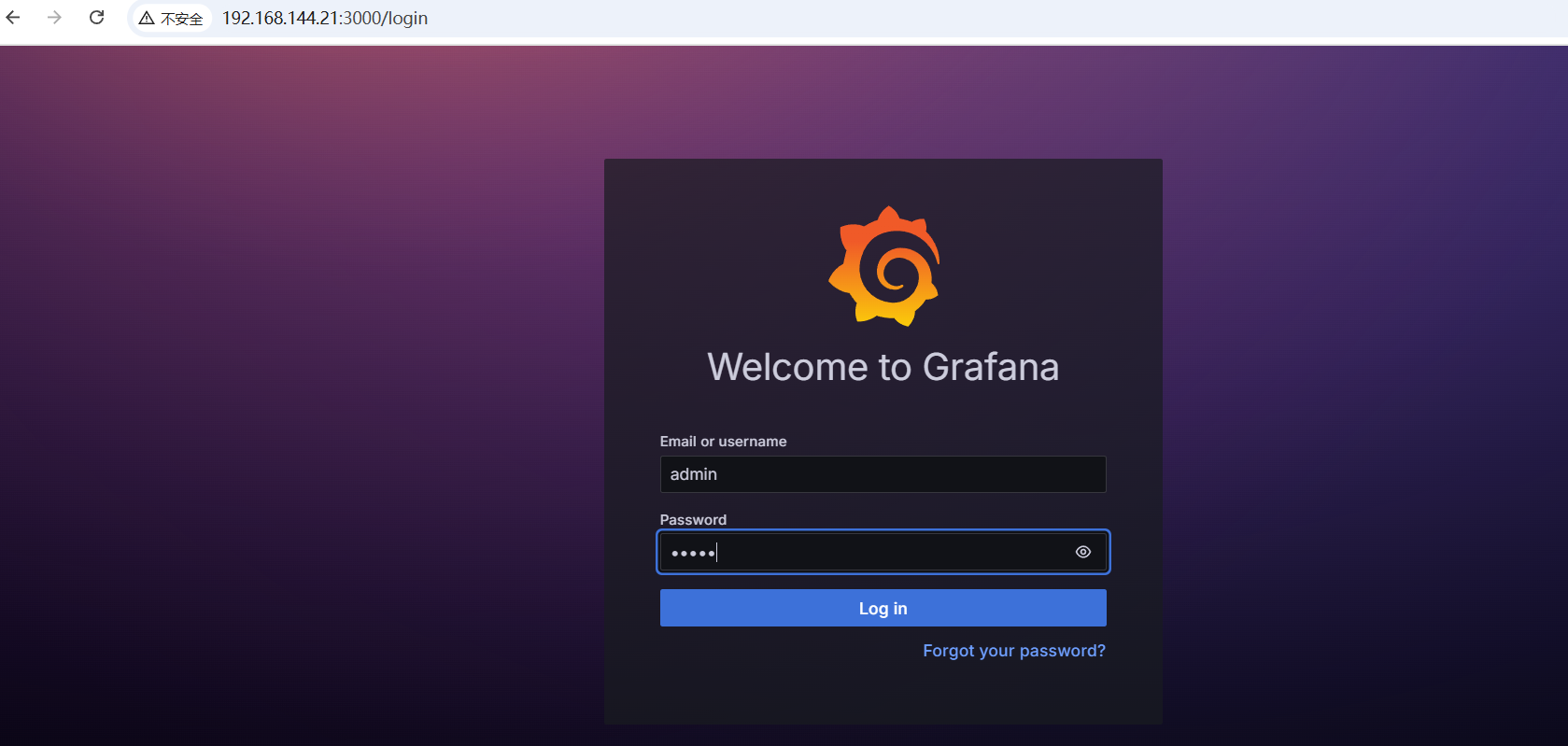
添加数据源:
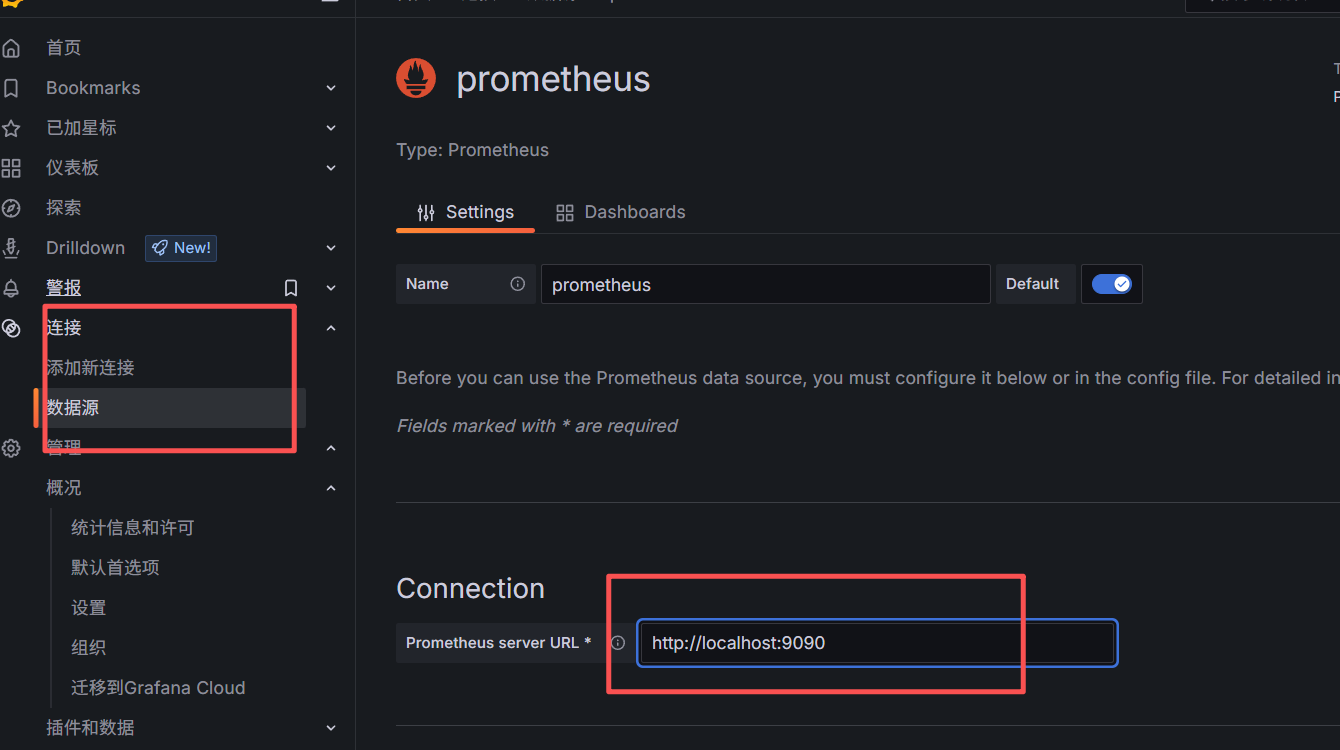
仪表板:
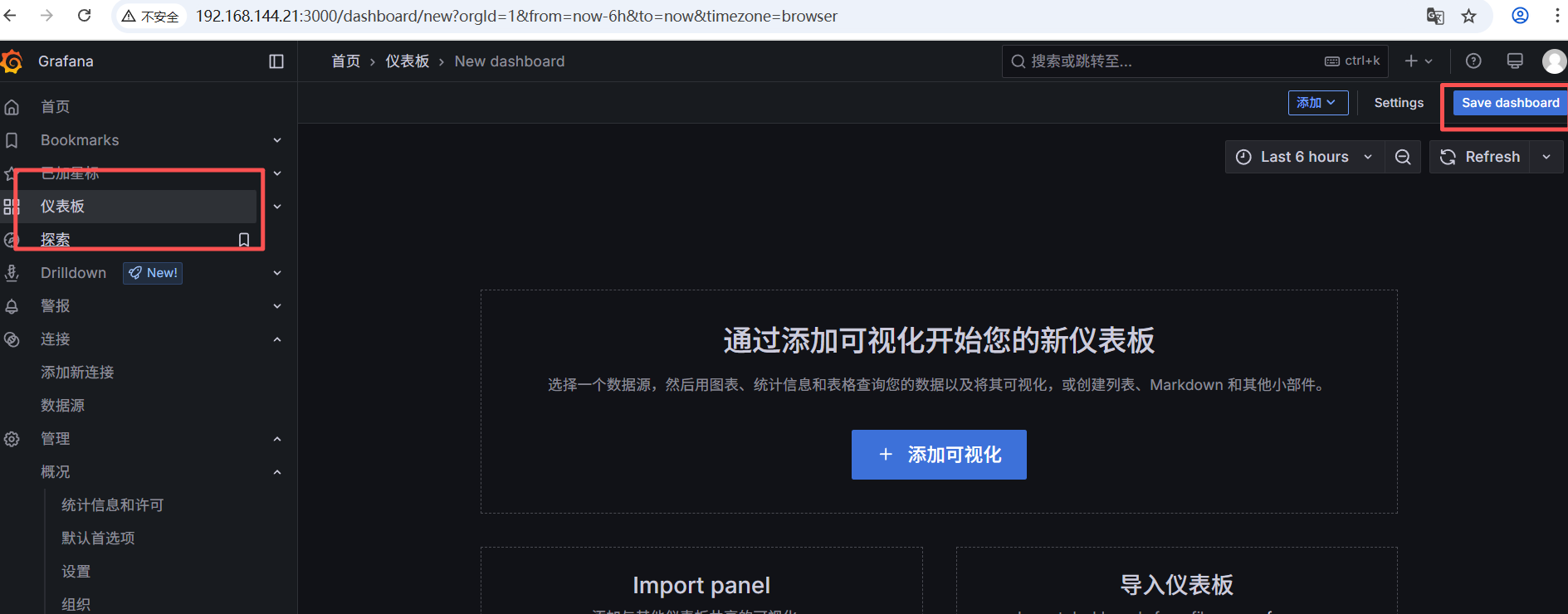
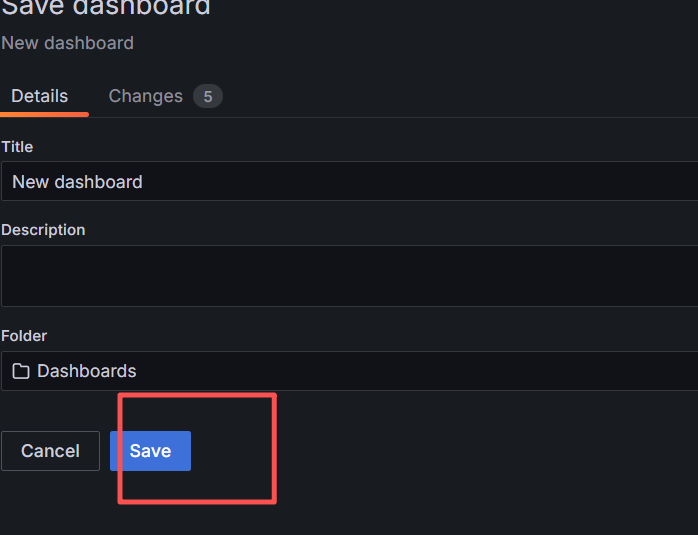
相关的数据信息都可以从github上下载
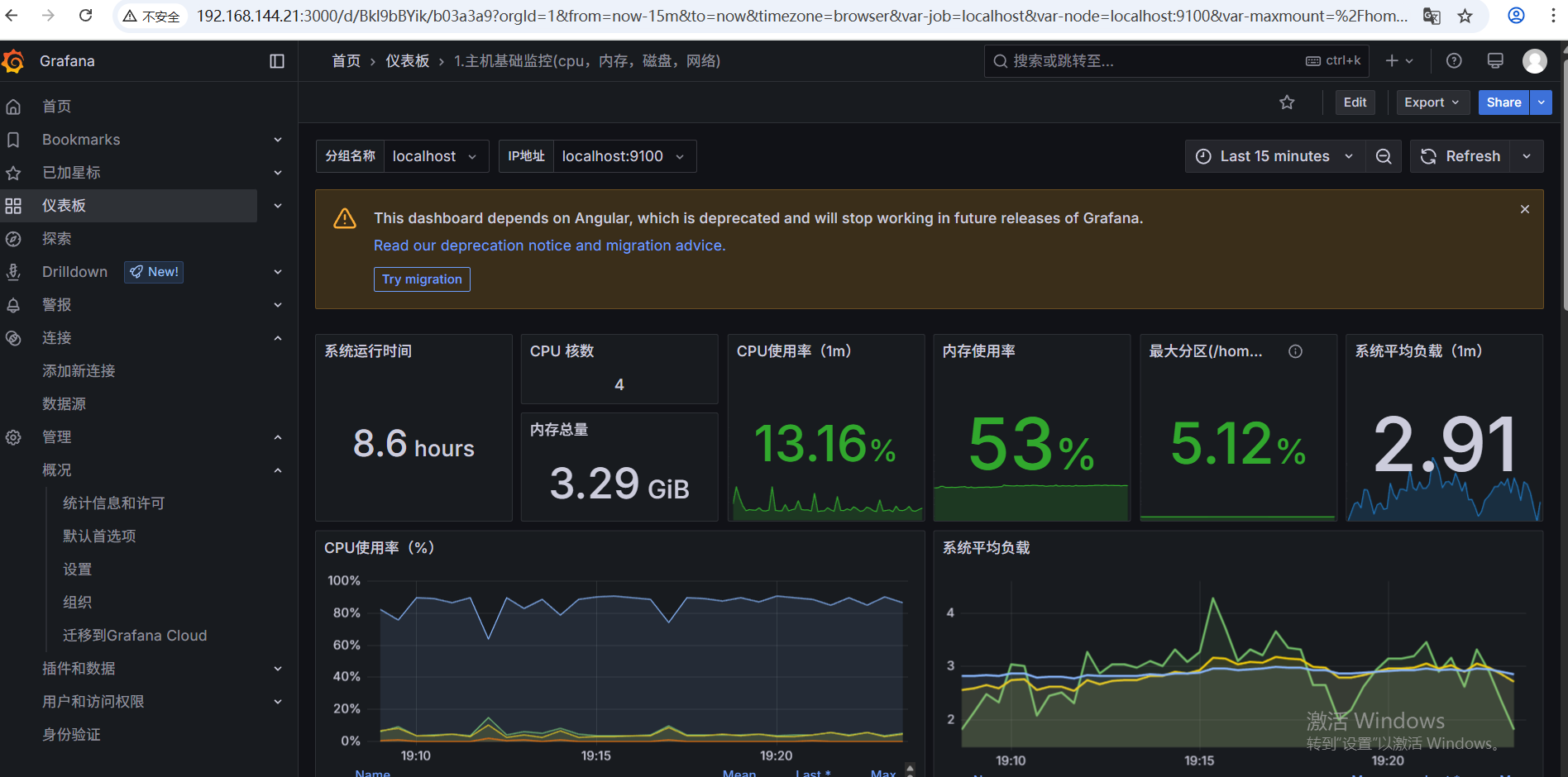
四、监控其他主机
在你想监控的主机上也要导入这个包,还是把他放在后台运行


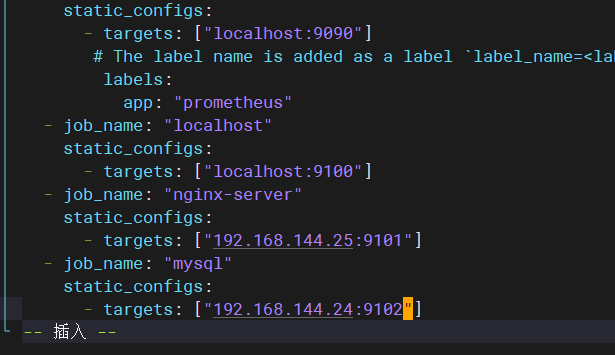
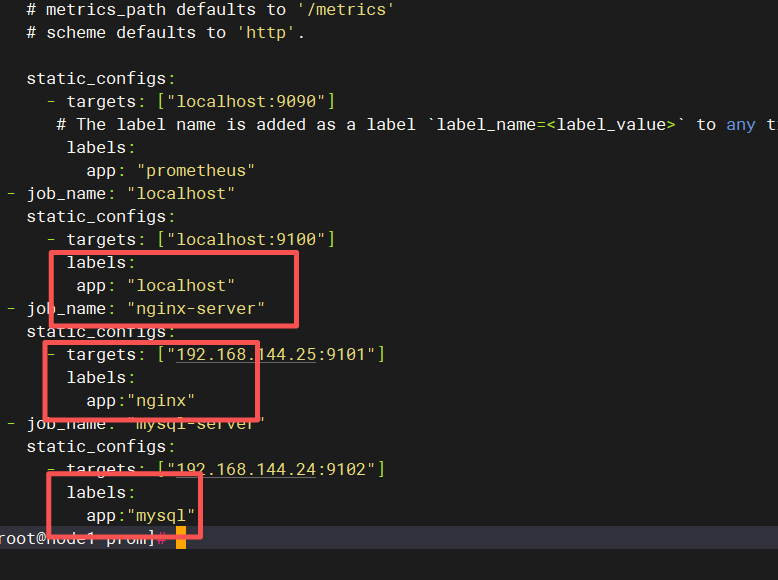
编写配置文件:(我的9100端口号被占用了,就换成9101了)
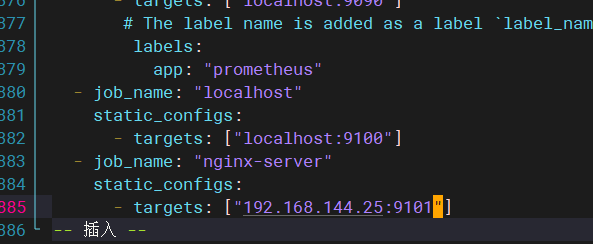
重启:
访问:
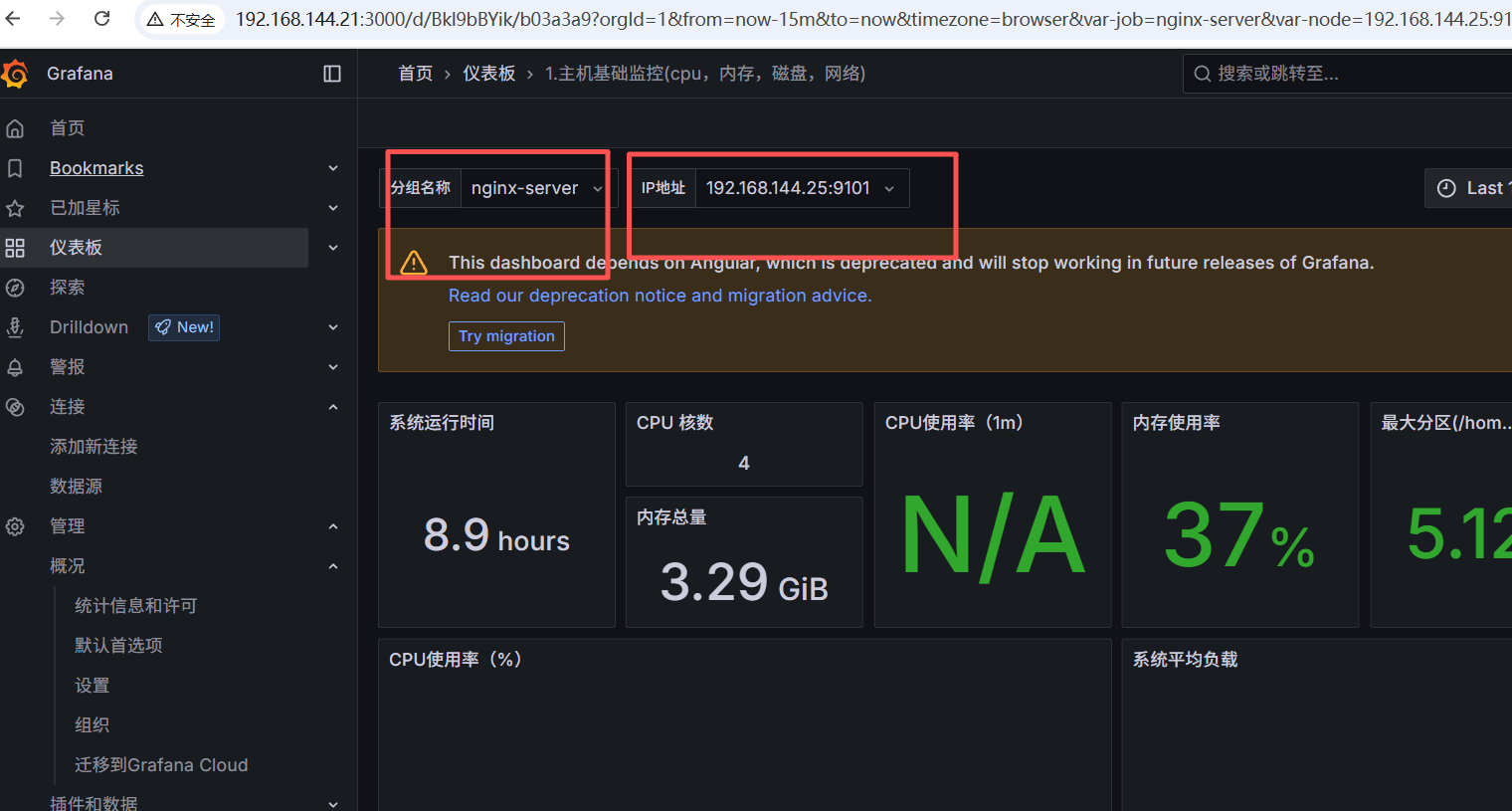
五、监控数据库
在你想监控的主机上安装mysql:
yum install -y mysql-server
导入mysql安装包:

创建用户并赋予权限:
编写cnf文件:文件应该是 .my.cnf

启动:

添加mysql信息:
再次重启:
导入mysql的json文件:
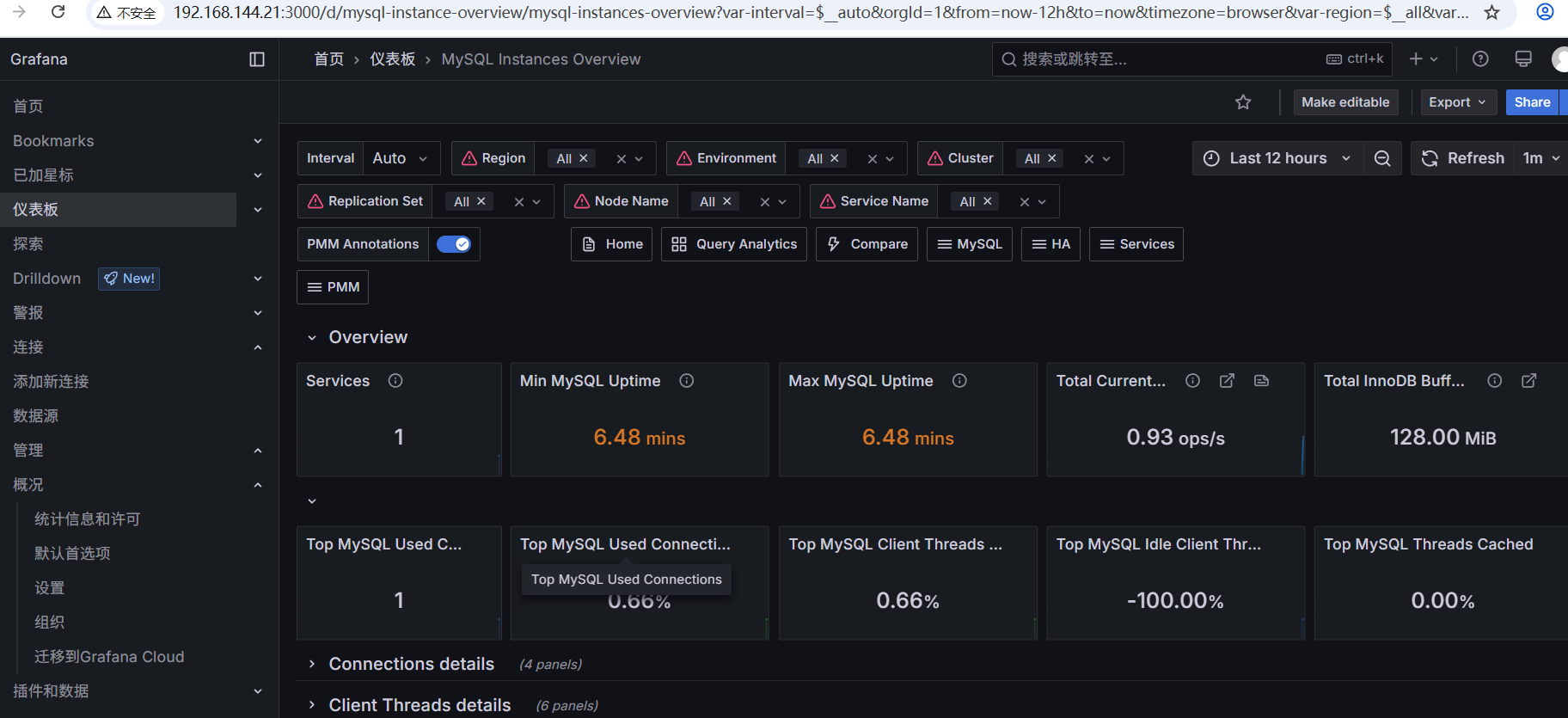
六、设置grafana告警
修改文件配置
alertmanager.yml:
bash
global:
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'z13516052620@163.com'
smtp_auth_username: 'z13516052620@163.com'
smtp_auth_password: 'XBTi7jHQRHre6tUm'
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'default'
receivers:
- name: 'default'
email_configs:
- to: '2191950432@qq.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']启动服务:

修改配置文件:
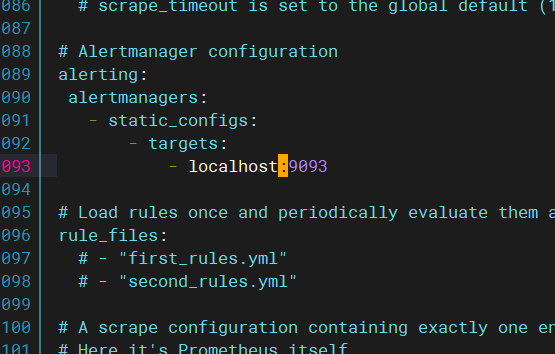
定义告警规则:
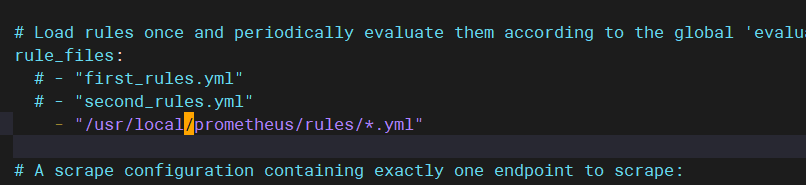
添加标签:
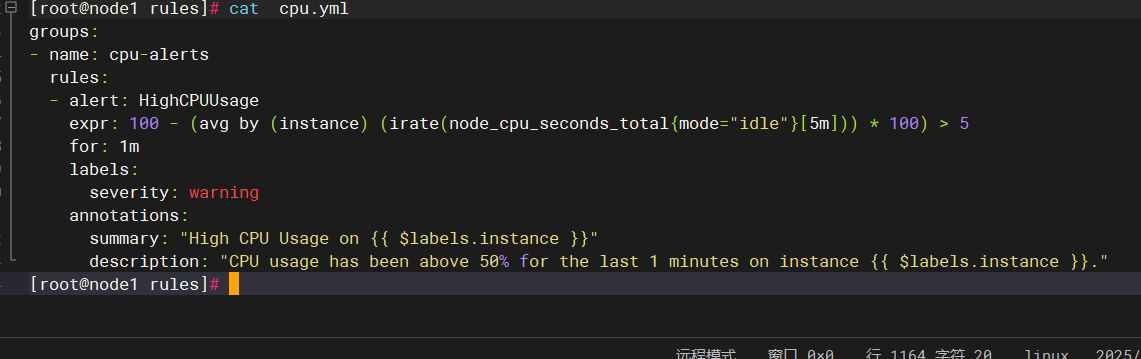
查看告警规则:
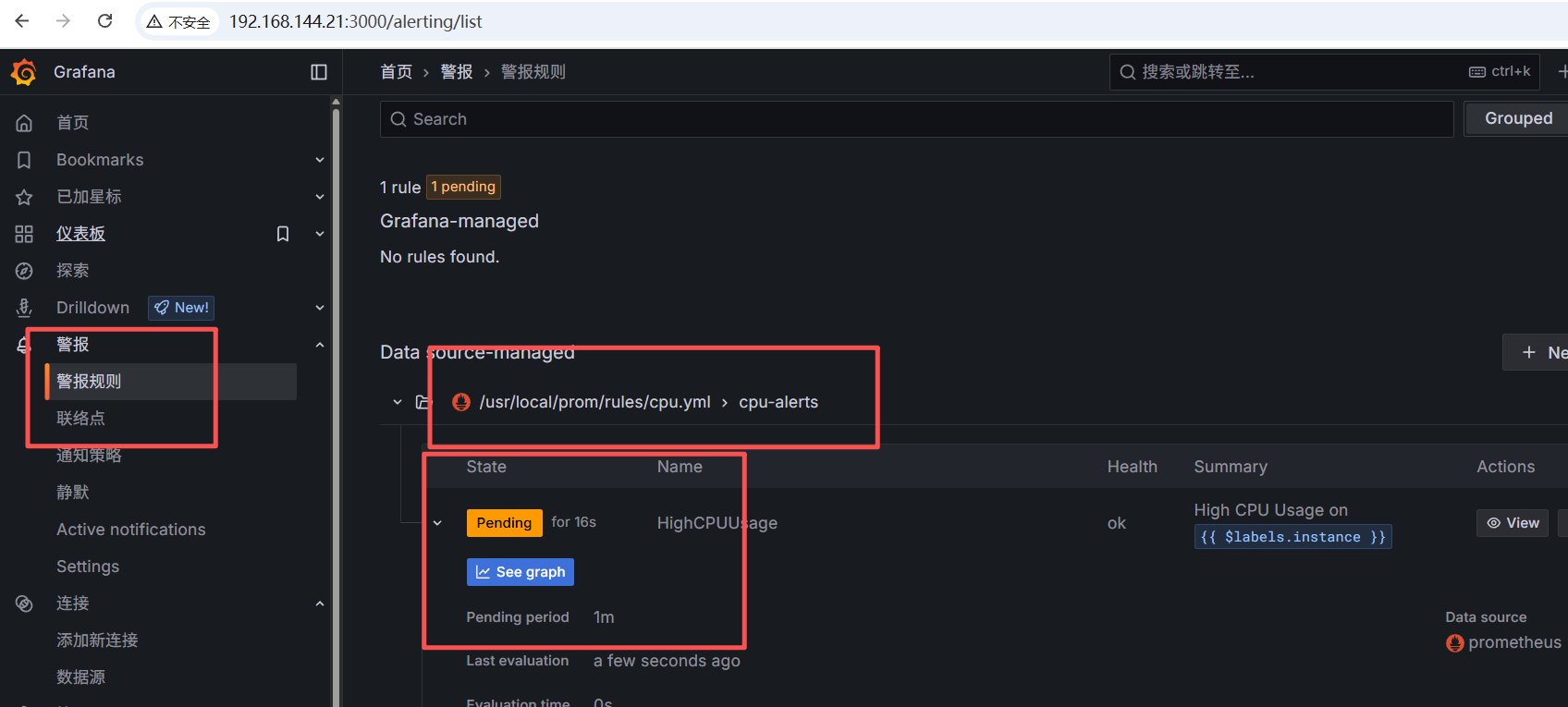
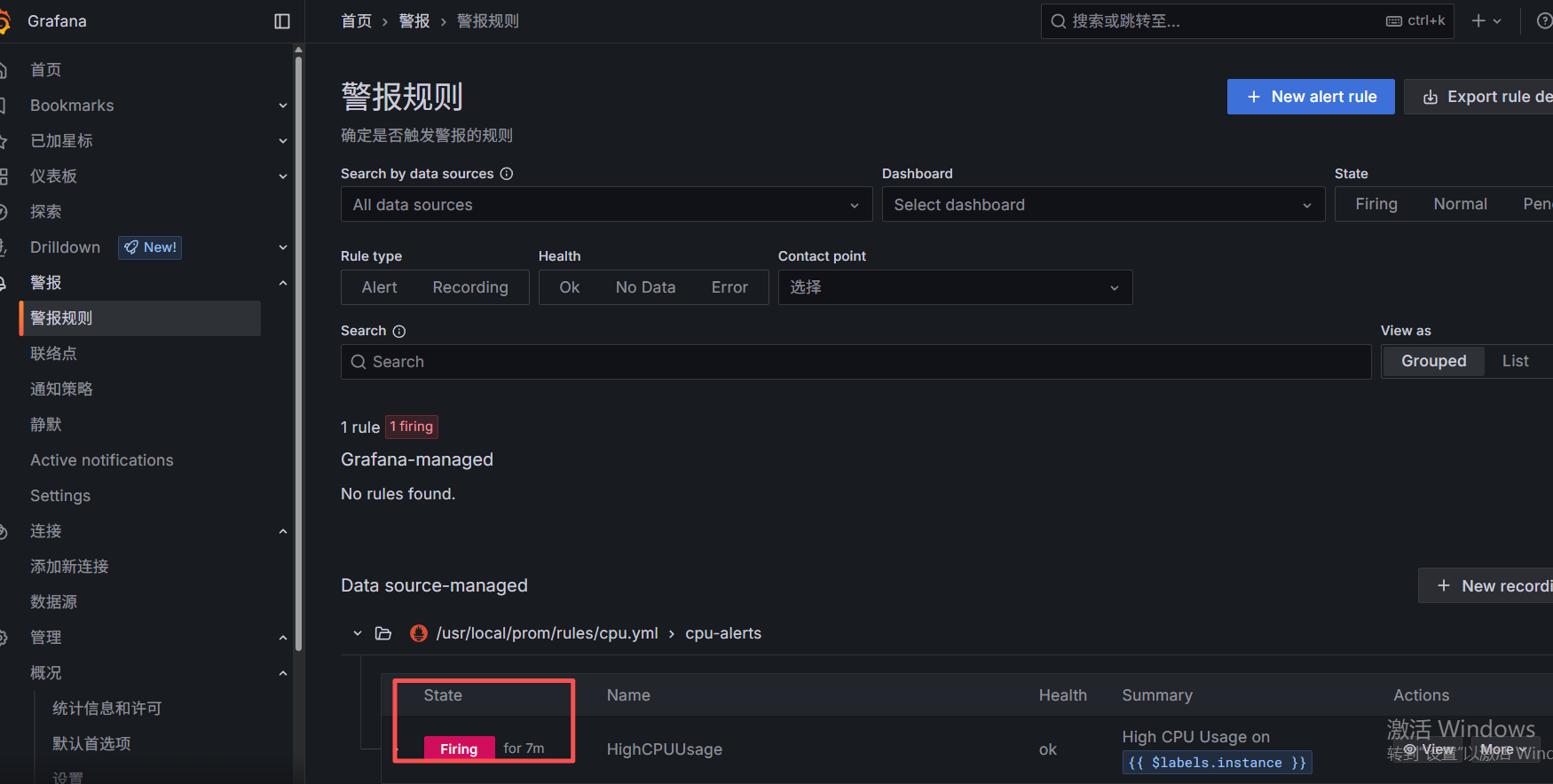
现在触发规则:关于cpu的:使cpu占用率过高
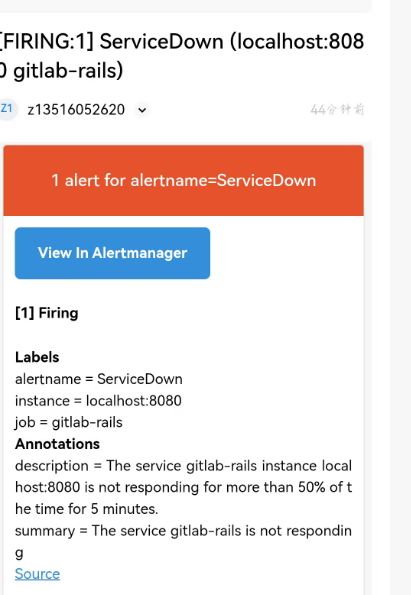
验证收到邮件:
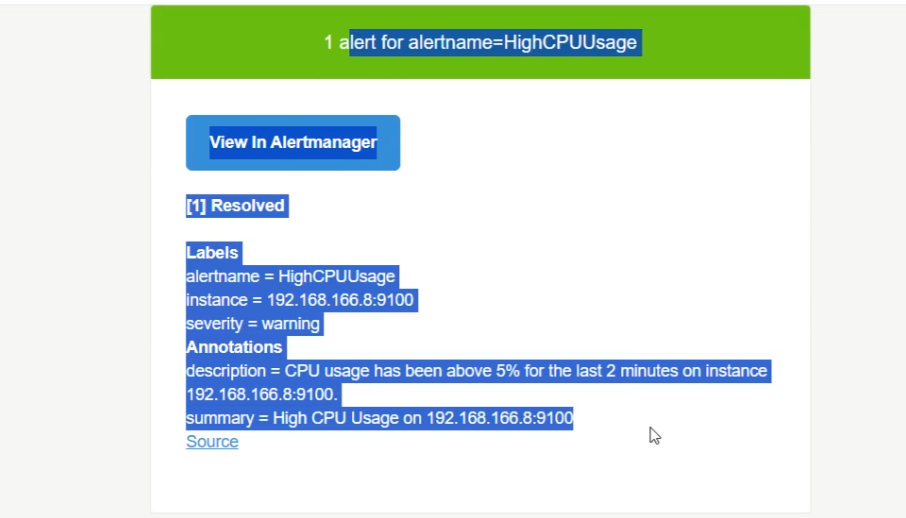
降低cpu使用率后:
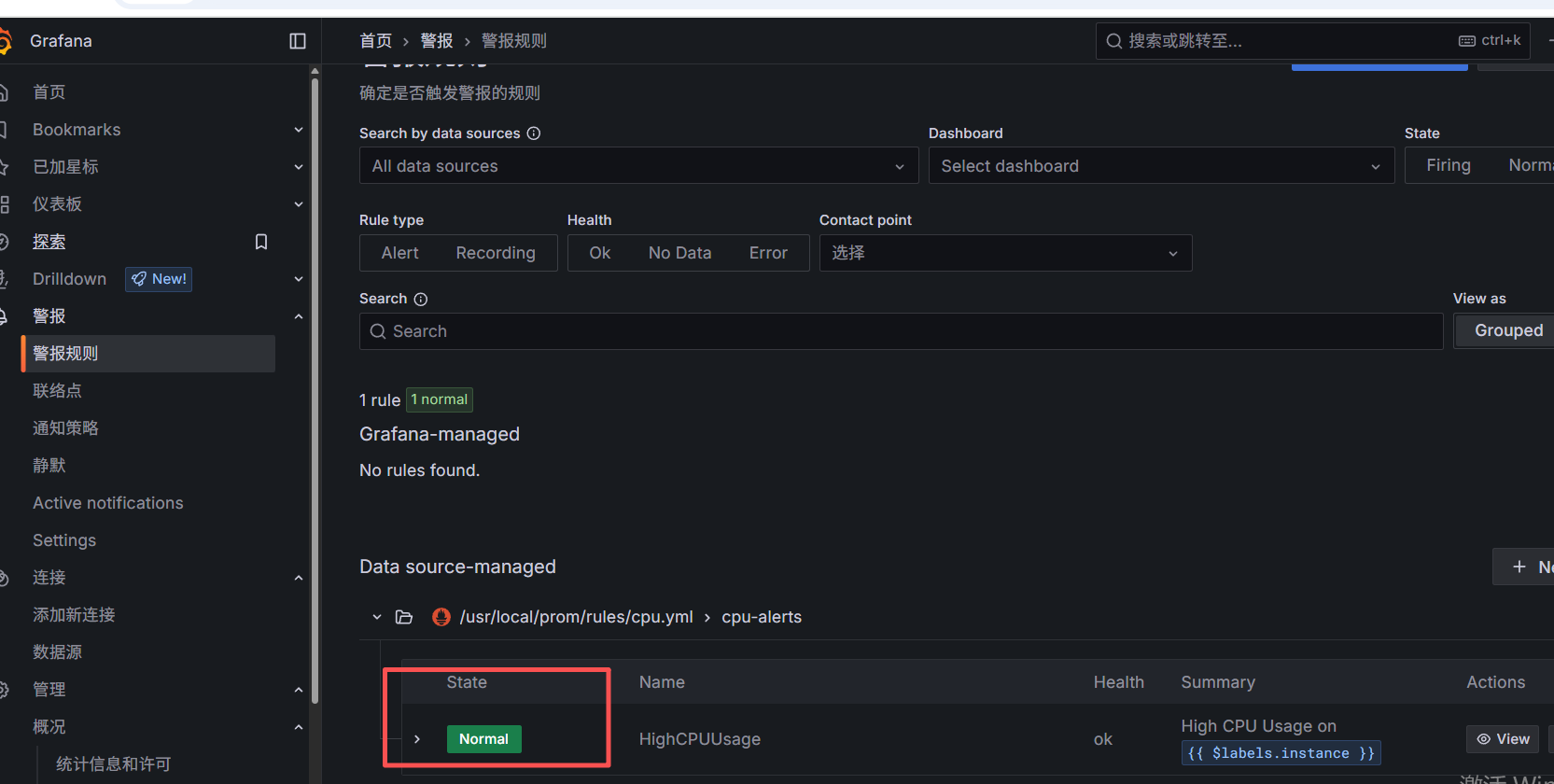
当前HighCPUUsage告警规则处于Normal状态,因为 CPU 使用率没有超过定义的阈值,所以不会发送告警邮件。如果需要测试邮件发送功能,可以手动触发告警或者检查邮件配置。
比如写个死循环触发告警后在停止循环:就会发送恢复正常的邮件
总结
1.后台进程启动后自动退出可以使用如下命令查看报错
prometheus --config.file=/usr/local/prom/prometheus.yml --web.enable-lifecycle
2.prometheus.yml文件格式要正确缩进