4.2.1MySQL的基本知识
SQL语句
用于存取数据以及查询、更新和管理关系数据库系统。包括:DQL(select)、DML(insert,update,delete)、DDL(create,alter,drop)、DCL(grant,revoke)权限验证。
MySQL体系结构
MySQL内部分层。
在最外层是server层,有几个组件组成。其中SQL Interface用于对用户发送来的sql进行词法句法分析,生成语法树。再由Parser对语法树进行过滤,比如要查询的字段在表中没有,进行报错。过滤后,由Optimizer制定执行计划,选择一个最佳的执行方案执行sql
在server层执行后,是存储引擎层,用于具体执行server层传入的执行方案。常用的存储引擎是InnoDB。
在存储引擎层下面,是文件系统层,存储着物理数据。
MySQL内部连接池
mysql会为每一个连接分配一个线程,每一个线程以阻塞io的方式进行read、do_command,各线程的处理是并发的。
MySQL执行一条select语句的过程
在网络层面,连接器接收连接,为连接分配线程。再先查询缓存(mysql8.0后已经删除这一步),若缓存没有啊,通过SQL Interface分析器组件进行词法句法分析生成语法树,再通过优化器组件制定执行方案,执行器根据执行计划,从存储引擎获取数据返回。
如果是预处理语句,比如有很多select,就可以写成select * from user where id = ?;?用来接收参数,避免重复解析。会跳过连接器、分析器、优化器,直接进入到执行器执行计划这一步。
数据库设计的三范式
目的:避免数据冗余、允许空间占用
三范式内容:每一个列的字段,都是最简的,不可再分的。如果有多个主键,那么表中其他键都需要完全依赖主键,且与主键直接相关,而不是间接相关。如果某表不能满足上述要求,那么说明表中有冗余数据存在,需要对表进行拆分,以编号替代冗余部分。
反范式:范式可以简单理解为 "时间换空间",牺牲多张表跳转查询的时间来避免数据冗余空间浪费。但是如果冗余字段较少且追求查询效率,可以用反范式。
MySQL删除数据的几种方式
1.drop(DDL):完全删除表,包括数据和结构,表将不存在,不可回滚
2.truncate(DDL):只删除表中数据,变成空表,其中自增约束置为初始值。不可回滚,以页为单位删除
3.delete(DML):删除部分或全部数据,可以回滚,以行为单位删除。
MySQL的高级查询
1.分组+聚合查询:通过group by对表分组后,计算sum()、avg()、max()、min()、count(),都是对分组后的各组内进行操作。
比如:select `gender`,count(*) as num from `student` group by `gender`;
2.联表查询
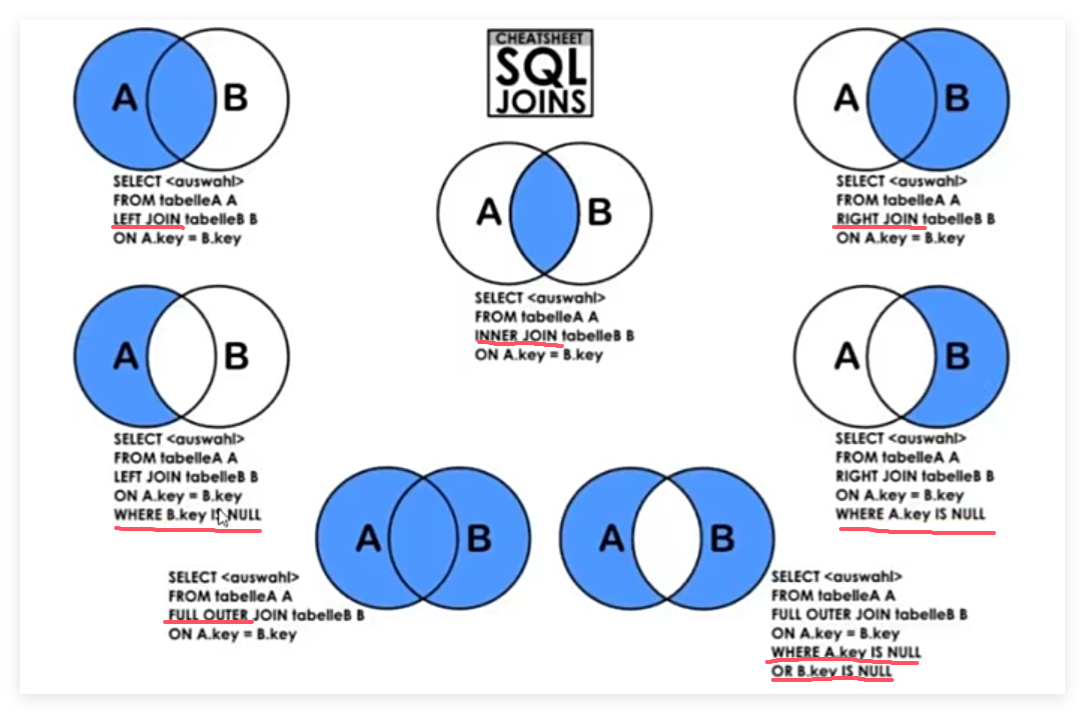
举例:查询 '数学'课程比'语文'课程成绩高的所有学生的学号;
分析:涉及两张表,一个是分数表,一个是课程表。需要先从课程表中,通过课程名称cname = '数学' 查询出课程对应的cid,然后再到分数表中查询对应课程的学生id以及分数num,这样就构成了两个表A与B,分别意味着报了数学的集合,报了语文的集合,表中只有两个字段:sid与num。
再通过inner join取两张表的交集,即数学语文都报了的人,构成一张新表,最后select 数学分数高于语文分数的学生学号即可。
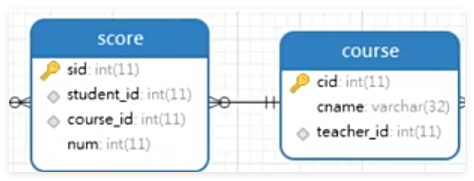
sql
select A.student_id from
(select student_id,num from score where course_id =
(select cid from course where cname = `数学`)) as A
inner join
(select student_id,num from score where course_id =
(select cid from course where cname = `语文`))as B
on A.student_id = B.student_id
where A.num > B.num;
如果没报语文课程的人也算在内,那就改成left join
最后一行改成where A.num > IFNULL(B.num,0);视图是什么?
是一种虚拟存在的表,是一个逻辑表,其内容由查询定义,本身并不包含数据。
优点:向上面例子中的表构建比较麻烦,如果每次都要写这么多sql很冗余,可以直接构建一个视图,且视图的结构不会受原表的影响。
4.2.2MySQL索引原理以及SQL优化
索引是什么?
索引是一种有序的数据结构,按照单个或者多个列的值进行排序,用于提升搜索的效率。比如主键索引(非空+唯一)、唯一索引(可空)、普通索引(可空+可不唯一),组合索引(对表中多个列进行索引)。
索引常用的数据结构是B+树:
在course表中的主键索引cid,作用就相当于一个map<int , course>,根据cid找到course,其中索引cid就是聚集索引B+树中的非叶子节点,用于查找,叶子节点中存储的就是course(数据)+cid(索引)
在course表中的普通索引tid,作用就相当于一个 multimap<int ,pairs<int,int>> ,根据tid找到键值对 <索引信息,主键信息>。其中索引tid就是辅助索引B+树 中的非叶子节点,用于查找,叶子节点中存储的就是索引信息 + 主键信息,要拿到完整的数据要拿到主键信息,再到聚集索引B+树中取出。但是如果要查询的信息只有主键信息,或者其他辅助索引B+树中本身就有的信息,则为覆盖查询,可以直接返回,速度很快,这也是不建议用select *,而具体写出字段名的原因,可以避免回表查询。
主键的选择
有设置primary key则当然其为主键;如果没设置则选一个非空唯一索引作为主键;如果非空唯一索引也没有,则创建一个6字节的_rowid作为主键。
MySQL是磁盘IO,索引如何保证业务高效?
1.叶子节点的连续
在通过非叶子索引节点查找到目标数据所在的页后,由于叶子节点间是有序且直接连接的,可以减少磁盘的寻道时间,直接把页从磁盘读入内存。
2.一次从磁盘中读取多个页到内存中缓存
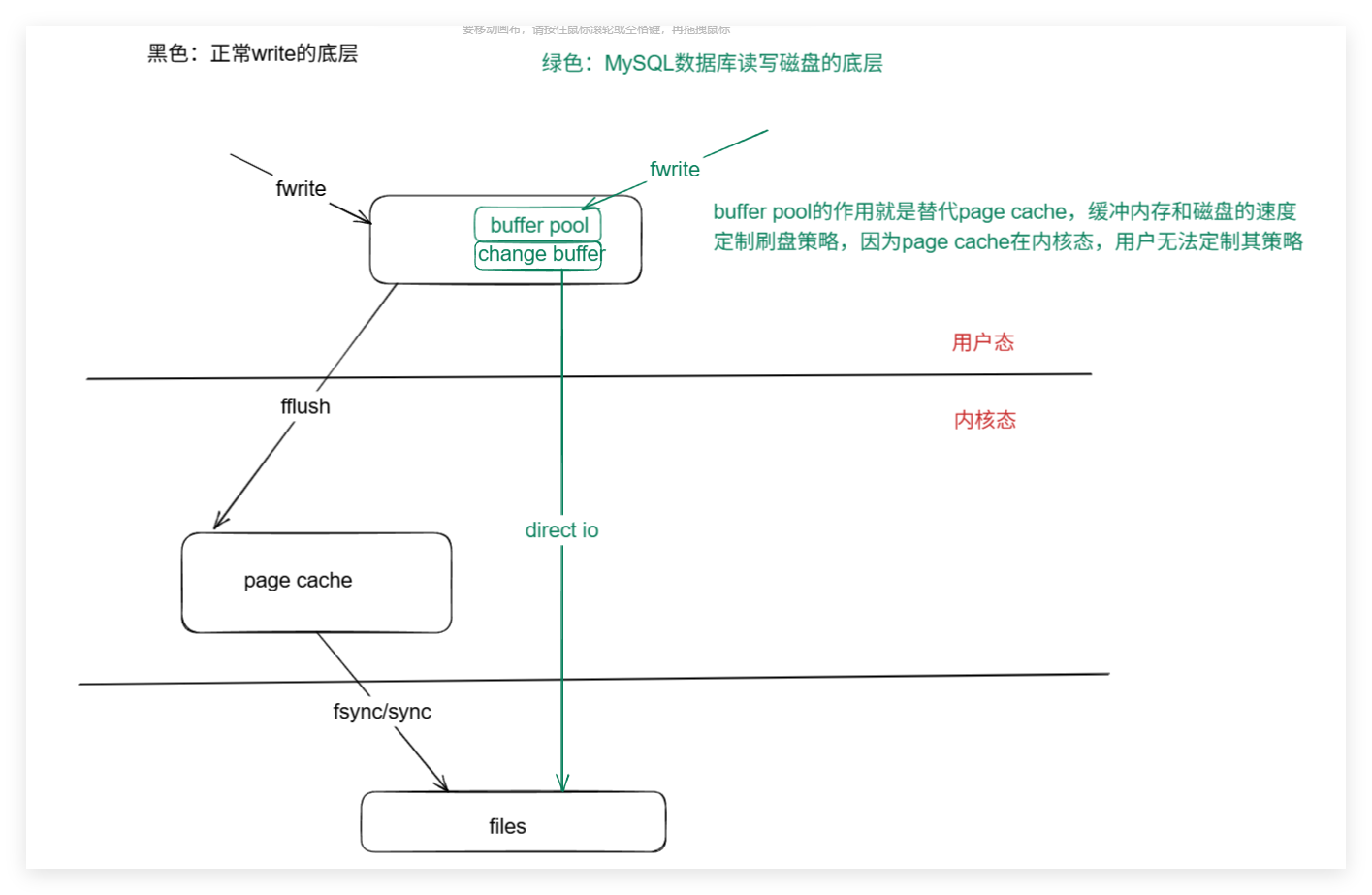
对B+树的操作,也不会马上写回磁盘,对于change buffer,会定期合并到buffer pool中,而buffer pool中的被修改后的脏数据,会集中direct io到磁盘中
MySQL的内存安全保证
在MySQL对磁盘的操作,如果是操作的聚集索引B+树,则是先对buffer pool中的节点进行操作,如果操作的是辅助索引B+树,则是对Change buffer中的节点操作。但是如果出现断电,也不用担心内存数据丢失,没有及时刷盘导致数据错误,因为有Redo Log,aof型日志,记录buffer中的变化信息,可以恢复buffer。
组合索引在查询时候的规则:最左匹配原则
组合索引算作辅助索引。
如果将两个索引(A,B)结合成一个索引,那么在select查询的时候,会按照最左匹配原则进行查询,即select中有没有where带上A的相关限定信息,如果有,则会按照其进行排序,如果没有或者只有B的限定信息,则会进行全表查询。
索引下推是什么?
对象是辅助索引,普通索引和联合索引场景居多。
原本是在server层获得存储引擎层的数据后,根据索引条件过滤数据
索引下推机制,即将部分索引条件判断下推到存储引擎中过滤数据,最终返回给server层。
索引的作用是加速sql执行,有没有索引失效的情况?
1.select ... where A and B 若A和B中,有一个字段不是索引,则会索引失效
2.如果让索引字段参与运算,则会索引失效,如 where cid -1 = 2;
3.like 模糊查询,以 %开头,会进行全表查询,索引失效,因为B+树读取到%不知道怎么查。
4.没有遵循最左匹配原则
出现了sql比较慢的排查思路
先开启慢查询日志,找到SQL语句,然后通过explain字段,通过分析器看where、group by、order by后面的字段有没有踩索引,如果没有,看看是没有创建索引还是索引失效。如果有踩索引但是速度慢,看看能否用in 或者 not in优化成联表查询,或者如果SQL语句太大了,考虑拆分,减少联合查询。
4.2.3MySQL事务原理
事务的特性和Redis中的事务有共同性,也是在有多条连接的情况下,利用事务性保证单个连接上用户操作的不可分割。只需要在多条sql前加上 begin; 末尾加上 commit;事务的特征有:
1.原子性:undolog辅助实现原子性
2.一致性:体现在与数据表结构的一致性。用户执行的sql操作必须要满足数据库表中字段的完整约束,如果有令非空约束为空的操作,要及时回滚事务,返回失败指令。在逻辑上也体现在用户定义的操作在MySQL中为一个整体的一致性。
3.隔离性:指并发连接间的隔离性,适当的破坏一致性。有四个隔离级别,对应着四种并发程度。
4.持久性:redolog实现持久性
四个隔离级别(由低到高)
1.读未提交:对读操作不做任何处理,对写操作自动加锁
分析:存在脏读问题。A事务写还未结束,B事务因为读无限制,看到A事务的中间结果,为脏读。
2.读已提交(RC):读操作采用MVCC策略。读到的是最新的数据,写操作自动加锁
分析:避免了脏读,A没有结束,B读不到他修改的结果。但是存在"不可重复读"问题,A事务要是在B事务结束前结束了,那么B事务会看到最新的结果,即两次B事务中的查询结果不一致。
3.可重复读(RR):读操作采用MVCC策略。读到的是事务开始前版本的数据,写操作自动加锁
分析:避免了不可重复读问题,两次查询的结果都是一样的。但是存在"幻读"问题,A事务和B事务都在执行过程中,B事务查询到没有ID为3的行数据,但紧接着A事务插入了一个ID为3的行数据,那么B事务在插入ID为3的行数据的时候,就会因为违反唯一约束而返回错误。
4.可串行化:读写都加锁
分析:解决了幻读的问题,即在B事务查询是否有ID为3的行数据的时候,加上for update字段(x锁)或者lock in share mode(S锁/共享锁)加锁,这时候A事务想要添加ID为3的行数据会阻塞,知道B事务添加ID为3的行数据并且commit后,A事务会报错。
MVCC策略
MVCC的核心思想:不加锁,为每行数据保存多个版本(快照)。当一个事务需要读取数据时,MVCC会提供一个符合该事务开始时间点的"数据快照",而不是直接读取当前最新的、可能正在被其他事务修改的数据。 这样就实现了读不加锁,读写操作通常不会互相阻塞,极大地提升了并发性能。
Read View 是事务在进行快照读(普通SELECT语句)时产生的数据结构,它定义了当前事务能看到哪个版本的数据。
"读已提交"是在每次读取数据的时候,生成新的read_view
"可重复读"是在启动事务的时候,生成新的read view,一直使用到事务提交或者回滚
read view中有trx_id 、min_trx_id 、max_trx_id 、m_ids,事务间可见的情况只有:
trx_id < min_trx_id 和 min_trx_id < trx_id < max_trx_id && trx_id 不属于 m_ids
事务隔离级别的实现
利用锁机制实现,锁的类型有:行级锁(共享锁、排他锁),表级锁(意向共享锁、意向排他锁)。
锁算法有:Record记录锁(单个行记录上的锁),Gap间隙锁(锁定一个范围,全开区间),Next-Key Lock(记录所 + 间隙锁,左开右闭)
锁的对象:在RC和RR两种隔离级别下
1.行级锁是针对表的索引加锁,包括聚合索引和辅助索引
2.表级锁是针对页或者表进行加锁
3.Gap锁通常是加在RR隔离级的情况下
举例:
聚集索引,查询命中,RC和RR两种隔离级别都会对命中行加锁。
聚集索引,查询未命中,RC不加锁,RR在未命中字段的左右区间加一个gap锁
辅助非唯一索引,查询命中,RC把辅助表命中的行锁定,并且把聚合数据表中相关的行也锁定。
RR在RC的基础上,还在辅助表中,命中的两个字段,产生的三个间隙,都加gap锁。
死锁的产生
情况1:相同表不同行加锁顺序相反,比如A事务update id1 id2 ,B事务update id2 id1;update和delete操作是会自动加上锁的。解决:调整执行顺序。
情况2:锁冲突,在RR隔离级别下面,如果先持有了gap锁,再想加意向锁,就会产生锁冲突。解决:降为RC隔离级别,这样就没有gap锁了。
4.2.4MySQL缓存策略
在MySQL中,也会采用缓存,不同于buffer pool,而是一种类似Redis的内存缓存,他不仅有更快的速度,而且不像buffer pool受限于MySQL,虽然缓存中的数据必须在MySQL中存在,但是可以根据业务自定义热点数据存入缓存。可以大大降低数据库的读压力,对写压力没有什么缓解,因为如果频繁写的话,我们用一个缓存还需要多考虑一致性的问题。
弊端是redis不支持事务的回滚,不能rollback,还有就是存在缓存和MySQL不一致的可能。
在引入Redis缓存后的写操作如何实现?
1.追求安全
在每次DML写操作,都先在Redis缓存中,删除对应的行(比如要修改 id = 1的年龄,先在缓存中删除id =1的行数据)。然后再到MySQL中进行操作,操作后,利用一个伪装从数据库的节点,从MySQL中拉取数据到Redis缓存中。这样可以保证在修改期间,其余用户不会读到脏数据,但是在修改前还要额外操作缓存影响效率。
2.追求效率
DML操作也对Redis执行,但是加上一个pexpire,设置过期时间如200ms,这样缓存中id=1的年龄就先被修改,随后再修改MySQL中id=1的年龄。如果MySQL中修改失败,那么Redis在200ms后也会删除这个错误的数据,如果MySQL成功,那么就会通过伪造从数据库进行数据同步。
此处的过期时间实际上 = MySQL传输时间 + MySQL处理时间 + MySQL同步时间
在这个期间内,别的用户可能会读到Redis中的脏数据。
MySQL到Redis的同步是如何实现的?
1.修改配置文件使transfer工具与MySQL和Redis建立连接。
2.配置热点数据,只拉取热点数据表的内容
3.用lua脚本设定同步的规则:怎么把MySQL的结构改成Redis的结构?transfer工具启动连接到MySQL的bin.log文件,按行读取里面的内容,改成Hash结构。获取各列的字段值,设置key后再通过Redis中的命令将各值直接HSET写入key对应的value。
还有哪些方式能提升MySQL的访问性能?
1.读写分离
MySQL也有很多salve从数据库用作备份,他们会不断的主动读取主数据库的二进制log,保持数据一致性。这样我们可以将业务的DML操作交给主数据库,而读操作提交给从数据库,分担主数据库的读压力。但是从数据库读取的数据没有强一致性,会有延迟存在,如果有强一致性需求,需要从主数据库读取。
2.数据库连接池
MySQL内部用的是select,阻塞io模型,一个连接对应一个线程,所以我们可以开启数据库连接池创建多条连接,提升并发度
3.异步连接
MySQL是阻塞IO,只会一个请求一个请求的执行,但是在服务器端我们可以设置非阻塞io,不断的给MySQL发请求,不等他连接后再发下一个。节省网络传输时间,解放服务器端核心线程。
MySQL缓存可能遇到的问题:都是源于大量请求进入到MySQL
1.缓存穿透
如果持续访问Redis和MySQL中都不存在的的数据,造成MySQL性能急剧下降
解决:
(1)对目标访问的数据在Redis中设置对应的key,nil;避免其再进一步访问MySQL
(2)在Redis上配置布隆过滤器,他能判断访问的数据是否在MySQL数据库中,如果不在拒绝访问
2.缓存击穿
比如在百亿秒杀开始前1s,Redis中的热点数据过期了,那么大量的访问就会并发进入到MySQL,造成MySQL性能急剧下降
解决:
(1)设置热点数据不过时
(2)设置分布式锁,访问Redis发现数据不存在的请求,先获取分布式锁(例如使用Redis的 SETNX 命令),成功获取的线程才能访问MySQL,这样获得锁的线程就能重建缓存,其他等待的线程也能从缓存中获取数据。
3.缓存雪崩
Redis中大量的key在同一时间内过期,大量的请求也就无法命中,导致MySQL的压力过大。相比较于缓存击穿的范围更大
解决:
(1)间隔设置过期时间
(2)在重启系统或者流量低峰期将高频访问的数据预热到缓存中