Easysearch 三年版本进化全图:从 ES 国产替代到 AI Native 搜索数据库
一句话结论:Easysearch 从 2023 年 4 月 1.0 首发到 2026 年 5 月的 2.2,三年完成了从"ES 内核可替代"→"分析与治理一体化"→"AI 原生 + 国密 + 开箱即用"的三级跳。
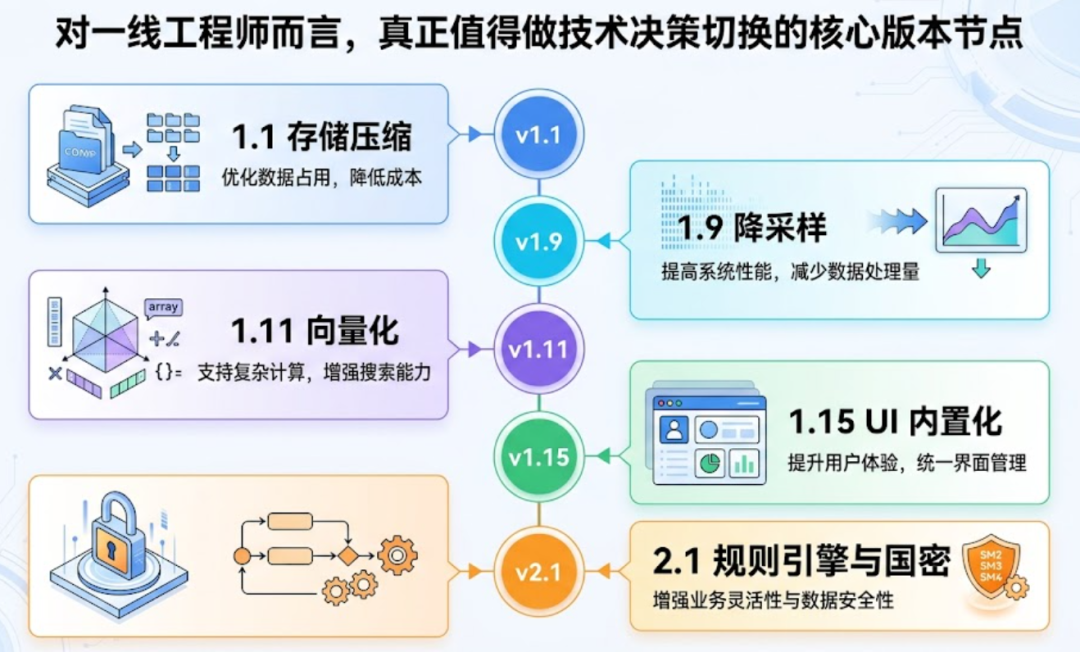
下面用一张主表 + 三阶段拆解 + 升级路径建议讲清楚,每条都对得上官方 release-notes 原文,不掺水分。
Easysearch 官方版本发布日志
一、版本时间线总表(按发布日倒序,只列里程碑版本)
| 版本 | 发布日 | 解决场景 | 关键能力(首次引入) |
|---|---|---|---|
| 2.2.0 | 2026-05-06 | 多集群/多 Agent 统一治理、程序化访问 | Agent UI、API Token(X-API-TOKEN)认证、大模型供应商管理 API、规则引擎 UI |
| 2.1.0 | 2026-03-16 | 风控/合规/多语种检索/信创合规 | Rules 规则引擎(百万级规则) 、国密 SM2/SM3/SM4 + TLCP、形态学分析(俄/英词形还原)、ZSTD 进阶(JNI+level) |
| 2.0.0 | 2025-11-21 | 集群"开箱可用"、摆脱 Kibana 依赖 | Lucene 升级至 9.12.2 、UI 插件随核心发布、range/数字排序大幅提速 |
| 1.15.0 | 2025-09-08 | RAG/电商搜索相关性 | 混合搜索(关键词+语义)正式 GA 、UI 插件首发、License 引入 |
| 1.14.0 | 2025-07-25 | 语义检索一站式落地 | 文本嵌入模型集成(OpenAI/Ollama) 、语义检索 API、Search Pipelines、IK reload API |
| 1.11.1 | 2025-03-14 | 私有化向量生成 | AI 模块(Ollama embedding)、KNN / CCR 从插件改为内置 |
| 1.11.0 | 2025-02-28 | 日志/APM/分页深翻 | wildcard 类型 、Point in time API 、异步搜索 API、数值/日期 doc-values 搜索 |
| 1.10.0 | 2025-01-11 | 文本类大字段提速 | flattened_text 、match_only_text 字段类型;Rollup 并发限制+失败重启 |
| 1.9.0 | 2024-10-17 | 监控指标/IoT 时序降本 | Rollup 降采样正式 GA (支持 avg/sum/max/min + pipeline 聚合) |
| 1.8.0 | 2024-04-30 | 写入风暴/突发流量保护 | 节点级 + 分片级写入限流 |
| 1.7.0 | 2023-12-15 | 冷数据归档直接可查 | Searchable Snapshot(快照搜索)Beta (S3/Azure/GCS) |
| 1.6.0 | 2023-09-22 | mapping 治理 / 字段瘦身 | _field_usage_stats 、_disk_usage API、flattened 类型 |
| 1.5.0 | 2023-09-08 | BI/分析人员低门槛接入 | SQL 插件 (REST + JDBC,可嵌入全文检索) |
| 1.4.0 | 2023-07-21 | 中文检索精度 | hanlp、jieba 分词插件 ;ILM wait_for_snapshot |
| 1.3.0 | 2023-06-30 | 推荐/相似图片 | kNN 检索插件 、dense_vector 字段类型、Docker 镜像 |
| 1.2.0 | 2023-06-08 | 容灾/同城双活 | 跨集群复制 CCR 、SLM 快照生命周期管理 |
| 1.1.0 | 2023-05-12 | 存储成本/索引治理 | ZSTD 压缩 、index.source_reuse、ILM 索引生命周期管理、Lucene 升至 8.11.2 |
| 1.0.0 | 2023-04-06 | ES 国产替代首发 | 兼容 ES 7.x 索引;内置安全模块(RBAC、加密传输);轻量级内核 |
数据来源:
Easysearch 官方 Release Notes https://docs.infinilabs.com/easysearch/main/docs/release-notes/easysearch/
INFINI Labs 官方博客
https://infinilabs.cn/blog/2024/release-20240301
二、三大阶段:从内核夯实到 AI 原生
阶段一(2023.04 -- 2024.04):把 ES 内核"做减法 + 做加固"
核心命题:业务代码零改造,用 Easysearch 替掉 Elasticsearch 7.x,并且要更省、更稳、更安全。
这个阶段的所有发布逻辑都指向一个问题:Elastic 7.x 用户最痛的点是什么?
答案是------存储贵、生命周期管不动、跨地域同步难、中文分词弱、缺一个原生 SQL。
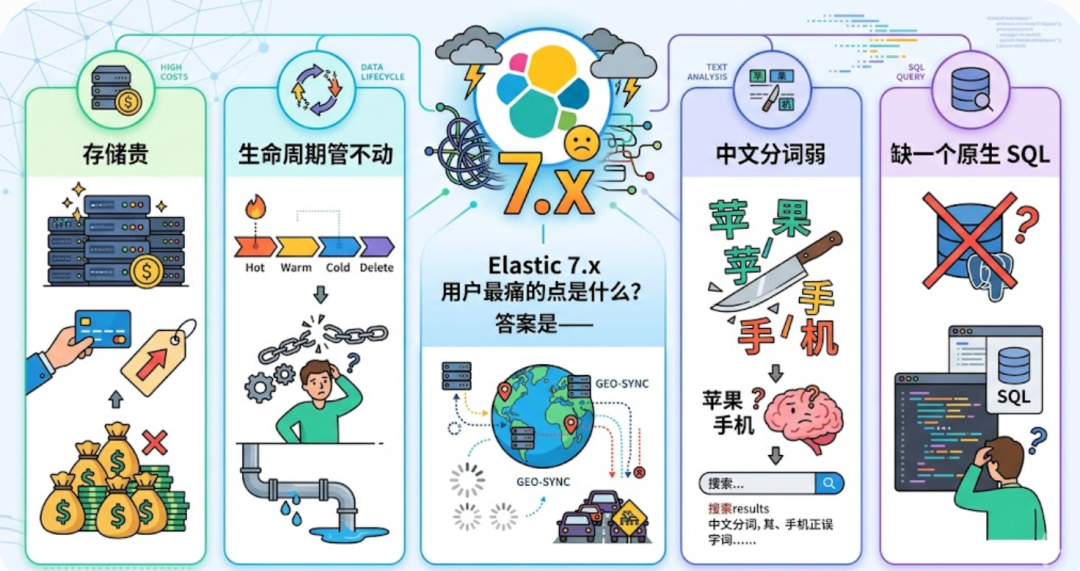
Easysearch 在 1.0 → 1.8 用 18 个月把这些坑一个一个补完:
- 存储贵 →
1.1 的 ZSTD 编解码 + source_reuse,对 _source、doc_values、词典三层压缩。这是后来所有"降本宣传"的物理基础。索引压缩文档
- 生命周期管不动 →
1.1 提供 ILM 模块,1.2 补上 SLM,1.4 增加 wait_for_snapshot 守护 delete action。
- 跨地域同步 →
1.2 引入 CCR,主从异地双活有了官方方案。
- 中文分词弱 →
1.4 集成 hanlp、jieba,1.6.1 加 analysis-icu,配合后续的 IK 企业版形成"中文检索套件"。
- 缺原生 SQL →
1.5 一次性给齐 REST + JDBC,让 BI 工具/数仓体系可以直接对接。
- 冷数据成本 →
1.7 Beta 推出 Searchable Snapshot,直接查 S3/OSS 上的快照,相当于把"归档"和"在线检索"打通。
- 写入风暴 →
1.8 推出 节点级和分片级的写入限流,解决"一个错误调用打爆整个集群"的经典事故。
这一阶段对工程师的实际意义:1.8 是 1.x 第一波"生产可信赖"分水岭。在此之前的版本,建议只在新项目或 PoC 上使用。
阶段二(2024.10 -- 2025.07):从搜索引擎走向"分析 + 向量"双形态
核心命题:Elastic 8.x 在做的事情(降采样、向量检索、PIT、异步搜索),Easysearch 必须有自己的解法,且要更省。
| 痛点 | 对应版本 | 解决方案 |
|---|---|---|
| 监控指标几个月就上 PB,查询又慢又贵 | 1.9.0 / 1.10.0 / 1.12.0 / 1.13.0 | Rollup 降采样从 GA 到生产级(并发限制、失败重启、断点续跑、write_optimization、参数热更新) |
| 大字段聚合慢、动态字段爆炸 | 1.10.0 | flattened_text 、match_only_text 字段类型 |
| 高基数日志要做模糊匹配但 keyword 太重 | 1.11.0 | wildcard 类型 (ES 7.9 才有,Easysearch 一次性补上) |
| 翻页几万条之后排序漂移 | 1.11.0 | Point in time 搜索快照 |
| 大查询阻塞业务 | 1.11.0 | 异步搜索 API ,长查询挂后台跑 |
| RAG/语义检索要落地,但不想自己写 embedding 流水线 | 1.11.1 → 1.14.0 | AI 模块 → 嵌入模型集成(OpenAI + Ollama 私有化 )→ 语义检索 API → Search Pipelines |
| KNN/CCR 安装麻烦、版本兼容性差 | 1.11.1 | KNN 与 CCR 从插件升格为内核内置 |
这一阶段对工程师的实际意义:
做 RAG / 语义搜索的,直接从 1.14.0 起步;
做日志/可观测性的,1.11.0 是必上的版本------三件套(PIT + async search + wildcard)一次到位。
阶段三(2025.09 -- 2026.05):UI 内置、混合搜索、规则引擎、国密合规
核心命题:搜索数据库不是只给 Elastic 老用户用的------它要直接服务信创、政企、风控、AI 应用开发者。
1)2.0.0(2025-11-21):开箱即用的分水岭
-
Lucene 底座升级到 9.12.2,是历代最大幅度的内核升级;
-
UI 插件随核心发布,从此装完 Easysearch 不需要再装 Kibana/Console 就能管集群、看节点、查分片、监控;
-
兼容 1.15.x 索引,1.x → 2.x 无缝升级,这点对存量集群是巨大的友好信号。
2)2.1.0(2026-03-16):本年度最重要的功能更新
| 模块 | 能力 | 场景 |
|---|---|---|
| Rules 规则引擎插件 | 百万级规则、AND/OR/NOT/near/正则/数值范围、Ingest Pipeline 集成、节点启动自动同步 | 反欺诈、内容审核、APT 检测、日志告警 |
| 形态学分析插件 | 俄/英词形还原(went → go、runner → run),原词+词根双索引 | 多语种全文检索、跨境业务召回率提升 |
| ZSTD 进阶 | 新增 index.compression.zstd.jni、index.compression.zstd.level |
更高压缩比,进一步降本 |
| 国密能力集成 | TLS 套件支持 SM2/SM3/SM4、TLCP 协议、国密双证书双向认证 | 党政、金融、央国企信创合规 |
| UI 插件 | 审计日志在线查看、数据探索页面、菜单级权限 | 运维/审计自助化 |
评价:2.1.0 是 Easysearch 在 2026 年最值得点名的版本------它把"国产替代"从"内核可替代"推进到"合规可替代 + 风控可替代"。 规则引擎尤其值得深挖,百万级规则 + 自动广播同步,过去做这件事要单独搭 Drools/Flink CEP,现在搜索数据库直接给你做了。
Easysearch 2.1.0 发布解读 https://www.cnblogs.com/infinilabs/p/19772872
3)2.2.0(2026-05-06):治理面板与 Agent 化
- API Token 认证:
用 X-API-TOKEN 替代脚本里的明文用户名密码,按 cluster / indices 粒度授权------这个对 CI/CD 与运维脚本是刚需。
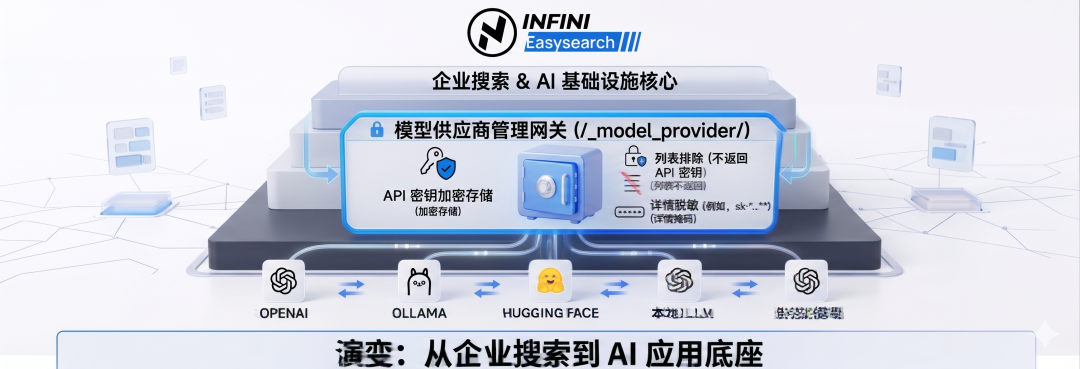
- 大模型供应商管理 API + UI:`
/_model_provider/ 统一管理 OpenAI、Ollama 等模型配置,api_key` 加密存储、列表不返回、详情掩码。这意味着 Easysearch 已经把自己定位成"AI 应用底座",而不只是搜索引擎。
- Agent UI:
主机级节点统一管理 + 巡检模块,运维体感对齐云厂商控制台。
- 规则引擎 UI
- 调试 API(
_simulate),让规则可视化运营成为可能。
三、能力首次引入的"考据表"(避免你被市场材料绕晕)
下面这张表回答的是一个高频问题------某某能力到底是哪个版本第一次有的?"
| 能力 | 首次引入版本 | 备注 |
|---|---|---|
| ZSTD 压缩 | 1.1.0 (2023-05) | Easysearch 最经典差异化能力 |
| ILM 生命周期 | 1.1.0 | 与 ZSTD 同版本 |
| SLM 快照生命周期 | 1.2.0 (2023-06) | |
| CCR 跨集群复制 | 1.2.0;1.11.1 改为内置 | 2025-03 起免插件 |
| kNN 向量检索 | 1.3.0 (2023-06);1.11.1 改为内置 | 早期是插件 |
| SQL | 1.5.0 (2023-09) | REST + JDBC |
| flattened 类型 | 1.6.0 (2023-09) | |
字段访问统计 _field_usage_stats |
1.6.0 | |
| Searchable Snapshot | 1.7.0 (2023-12) Beta | |
| 写入限流 | 1.8.0 (2024-04) | 节点级 + 分片级 |
| Rollup 降采样 | 1.9.0 (2024-10) GA | |
| wildcard / PIT / async search | 1.11.0 (2025-02) | 三连发 |
| AI 模块 / 嵌入模型集成 | 1.11.1 → 1.14.0 | OpenAI + Ollama |
| Search Pipelines | 1.14.0 (2025-07) | |
| 混合搜索 GA | 1.15.0 (2025-09) | |
| UI 插件 | 1.15.0 引入 → 2.0.0 标配 | |
| Lucene 9.12.2 | 2.0.0 (2025-11) | |
| Rules 规则引擎 | 2.1.0 (2026-03) | 百万级规则 |
| 国密 SM2/SM3/SM4 + TLCP | 2.1.0 | 信创合规 |
| 形态学分析(俄/英) | 2.1.0 | |
| API Token 认证 | 2.2.0 (2026-05) | X-API-TOKEN |
| 大模型供应商管理 API | 2.2.0 | /_model_provider/ |
四、落地建议:选哪个版本?
按场景给出最小可信版本(Minimum Trust Version):
- 纯替代 ES 7.x,存量集群迁移
→ 1.15.x 或 2.0.x。
2.0.0 的"UI 随核心发布"让运维心智成本最低,且兼容 1.15.x 索引可无缝升。
- 新建可观测性/日志平台
→ 直接 2.1.x。理由:
Rollup(1.9+)、wildcard/PIT/async(1.11)、写入限流(1.8)全都在;2.1 还带规则引擎可以做告警。
- 做 RAG / 语义搜索
→ 2.1.x 起步。
AI 模块、Search Pipelines、混合搜索一套齐活,且 2.2 带 API Token 和模型供应商管理。
- 党政信创、金融合规
→ 2.1.x 必选。
国密 SM2/SM3/SM4 + TLCP 是这一版本独有。
- 风控/反欺诈/内容审核
→ 2.1.x 。规则引擎百万级规则、自动同步是亮点。
- 想要稳定+保守
→ 选 1.15.6(2025-10-31)或 2.0.2(2025-12-17),都是各自分支末尾的稳定收口版本。
最新稳定包下载位(2.0.2-2499):
easysearch.cn/download](https://easysearch.cn/download
五、一句话总结
Easysearch 的演进节奏可以用一个公式概括:
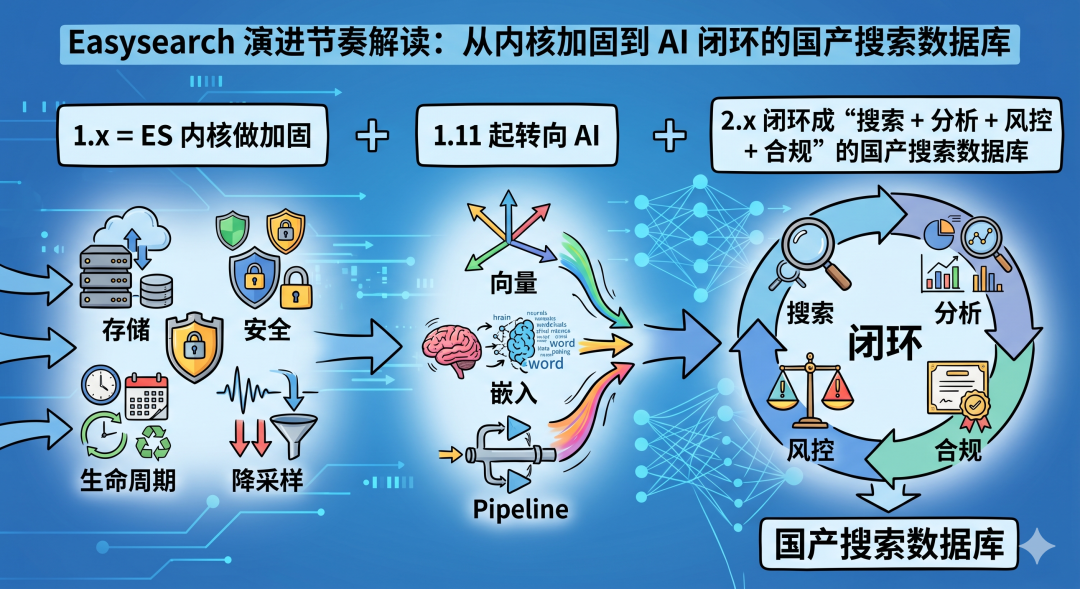
1.x = ES 内核做加固(存储、安全、生命周期、降采样)
+ 1.11 起转向 AI(向量、嵌入、Pipeline)
+ 2.x 闭环成"搜索 + 分析 + 风控 + 合规"的国产搜索数据库
三年走完这条路,节奏算得上克制------

对一线团队,今年的选型就盯 2.1.x:内核稳、UI 内置、规则引擎能省一套中间件、国密能过合规审查,是目前性价比最高的窗口期版本。
参考资料:
-
官方版本发布日志(最权威,逐版本可对照):docs.infinilabs.com/easysearch/main/docs/release-notes/easysearch
-
Easysearch 产品主页与下载:easysearch.cn | easysearch.cn/download
-
1.1 ZSTD 压缩官方文档:infinilabs.cn/docs/latest/easysearch/references/document/index-compression
-
2.1.0 发布解读:cnblogs.com/infinilabs/p/19772872
-
2.0 与 Coco AI 联动解读:cnblogs.com/infinilabs/p/19275020
-
1.11 异步搜索新特性:zhuanlan.zhihu.com/p/29049675143
-
1.8 写入限流发布说明:modb.pro/db/1787315109949411328
-
1.7.1 发布说明:infinilabs.cn/blog/2024/release-20240301