锋哥原创的Scikit-learn Python机器学习视频教程:
https://www.bilibili.com/video/BV11reUzEEPH
课程介绍

本课程主要讲解基于Scikit-learn的Python机器学习知识,包括机器学习概述,特征工程(数据集,特征抽取,特征预处理,特征降维等),分类算法(K-临近算法,朴素贝叶斯算法,决策树等),回归与聚类算法(线性回归,欠拟合,逻辑回归与二分类,K-means算法)等。
Scikit-learn Python机器学习 - 分类算法 - K-近邻(KNN)算法
K近邻(K-Nearest Neighbors, KNN)是一种非常直观和简单的监督学习 算法,既可用于分类 ,也可用于回归 。它的核心思想可以用一句老话概括:"物以类聚,人以群分"。
1. 核心思想
一个样本的类别或值,由其在特征空间中最相邻的K个样本(邻居)的多数投票(分类)或平均值(回归)来决定。
2. 工作原理 (以分类为例)
-
存储数据 :KNN是一种"惰性学习"(lazy learning)算法。它不会从训练数据中学习一个判别函数,而是简单地把所有的训练样本存储起来。
-
计算距离 :当需要预测一个新数据点(查询点)时,KNN计算该点与训练集中每一个点的距离。
-
寻找邻居 :选取距离最近的K个训练样本(这就是K的由来)。
-
投票决策:对于分类任务,统计这K个邻居中哪个类别最多,就将新数据点预测为那个类别。
3. 关键参数与概念
-
K值:邻居的数量。
-
K值过小 (如K=1):模型变得复杂,容易受到噪声数据的干扰,即过拟合。
-
K值过大 :模型变得简单,学习的近似误差增大,容易忽略训练数据中的细节,即欠拟合。
-
如何选择K :通常通过交叉验证来选择,一般取一个较小的奇数(为了避免平票),具体值需要根据数据实验决定。
-
-
距离度量:如何计算两个点之间的"远近"。
-
欧氏距离:最常用,
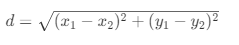
-
曼哈顿距离 :
d = |x₂ - x₁| + |y₂ - y₁| -
闵可夫斯基距离:欧氏和曼哈顿距离的泛化形式。
-
-
决策规则:
-
分类:多数投票法。可以引入距离加权投票(距离越近的邻居权重越大),以提高准确性。
-
回归:取K个邻居目标值的平均值。同样可以引入距离加权。
-
4. 算法特点
-
优点:
-
原理简单,易于理解和实现。
-
无需训练过程(惰性学习),只需存储数据。
-
对数据的分布没有假设,适用于各种复杂数据。
-
-
缺点:
-
计算成本高:预测时需要计算与所有训练样本的距离,当数据集很大时,预测速度非常慢。
-
对不平衡数据敏感:如果某个类的样本数量过多,会对投票结果产生过大影响。
-
维度灾难:在高维特征空间中,点与点之间的距离会变得很不明显,导致性能下降。
-
对特征尺度敏感 :如果特征量纲不一,距离计算会被大尺度的特征主导。因此,使用KNN前通常需要做数据标准化/归一化。
-
KNeighborsClassifier 是实现 K 最近邻 (K-NN) 算法的核心类,其预测规则非常简单:通过测量新样本与训练集中所有样本的距离,找出最相似的 K 个样本(邻居),然后通过这 K 个邻居的类别投票来决定新样本的类别。
它的构造函数包含多个关键参数,用于灵活地定制算法的行为。下面是所有参数的详细介绍:
sklearn.neighbors.KNeighborsClassifier(
n_neighbors=5,
*,
weights='uniform',
algorithm='auto',
leaf_size=30,
p=2,
metric='minkowski',
metric_params=None,
n_jobs=None
)KNeighborsClassifier 的主要参数如下表所示:
| 参数名 | 默认值 | 可选值/类型 | 描述 | 调优建议 |
|---|---|---|---|---|
| n_neighbors | 5 | int | 确定用于查询的邻居数量 (k值) 较小的k值 :模型更复杂,可能对噪声敏感较大的k值:模型更简单,决策边界更平滑 | 需要调优 通常通过交叉验证选择,一般从3-10开始尝试 |
| weights | 'uniform' | 'uniform', 'distance', 或 callable | 'uniform' :所有近邻权重相等**'distance'** :权重为距离的倒数,近邻影响更大callable:用户自定义的函数(接收距离数组,返回权重数组) | 需要调优 尝试 'distance' 往往能提升模型性能 |
| algorithm | 'auto' | {'auto', 'ball_tree', 'kd_tree', 'brute'} | 计算最近邻的算法**'auto'** :自动选择**'ball_tree'** /'kd_tree' :树结构算法,适用于数据量较大或维数适中(如维数小于20时kd_tree效率高)'brute':暴力搜索,适用于小数据集或高维稀疏数据 | 通常使用 'auto' 即可 |
| leaf_size | 30 | int | 传递给 BallTree 或 KDTree 的叶子大小。影响树的构建和查询速度以及内存存储。 | 对性能影响小,通常保持默认 |
| p | 2 | int | 距离度量公式的超参数***p=1 :曼哈顿距离p=2* :欧氏距离 (默认) p=其他值:相应的闵可夫斯基距离 | 对于大多数情况,使用默认的 p=2 (欧氏距离) 即可 |
| metric | 'minkowski' | str or callable | 用于距离计算的度量。默认为 'minkowski'(当 p=2 时即欧氏距离)。其他可选如 'euclidean'、'manhattan'、'chebyshev'、'cosine' 或自定义可调用对象 | 对于数值型数据,默认的欧氏距离通常足够 |
| metric_params | None | dict | 传递给距离度量函数的额外关键字参数 | 多数情况下无需设置 |
| n_jobs | None | int | 并行运行的任务数。None :1**-1**:使用所有处理器 | 大数据集且核多时可设置为 -1 以加速搜索 |
5. 具体示例
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
# 1,加载数据
iris = load_iris()
X = iris.data # 特征矩阵 (150个样本,4个特征:萼长、萼宽、瓣长、瓣宽)
y = iris.target # 特征值 目标向量 (3类鸢尾花:0, 1, 2)
# 2,数据预处理
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # 划分训练集和测试集
scaler = StandardScaler() # 数据标准化:消除不同特征量纲的影响
X_train_scaled = scaler.fit_transform(X_train) # fit计算生成模型,transform通过模型转换数据
X_test_scaled = scaler.transform(X_test) # # 使用训练集的参数转换测试集
# 3,创建和训练KNN模型
knn = KNeighborsClassifier(n_neighbors=3) # 创建KNN分类器实例,选择K=3
knn.fit(X_train_scaled, y_train) # "训练"模型(惰性学习,这里实际上只是存储数据)
# 4,进行预测并评估模型
y_pred = knn.predict(X_test_scaled) # 在测试集上进行预测
print('knn预测值:', y_pred)
print('正确值 :', y_test)
accuracy = accuracy_score(y_test, y_pred) # 计算准确率
print(f'测试集准确率:{accuracy:.2f}')
print('分类报告:\n', classification_report(y_test, y_pred, target_names=iris.target_names))运行结果:
knn预测值: [2 1 2 0 2 2 2 0 0 1 0 1 1 1 1 2 0 2 1 1 0 2 0 0 1 2 0 1 0 0]
正确值 : [2 1 1 0 2 2 2 0 0 1 0 1 1 1 1 2 0 2 1 1 0 1 0 0 1 2 0 1 0 0]
测试集准确率:0.93
分类报告:
precision recall f1-score support
setosa 1.00 1.00 1.00 11
versicolor 1.00 0.83 0.91 12
virginica 0.78 1.00 0.88 7
accuracy 0.93 30
macro avg 0.93 0.94 0.93 30
weighted avg 0.95 0.93 0.93 30数学知识:拟合
形象的说,拟合就是把平面上一系列的点,用一条光滑的曲线连接起来。因为这条曲线有无数种可能,从而有各种拟合方法。拟合的曲线一般可以用函数表示,根据这个函数的不同有不同的拟合名字。