算法PK:LMS与RLS的对比研究 - 自适应滤波器的双雄对决
文章目录
- 算法PK:LMS与RLS的对比研究 - 自适应滤波器的双雄对决
-
-
- 引言
-
- LMS算法详解
-
- 2.1 什么是LMS算法
- 2.2 数学原理与推导
-
- RLS算法详解
-
- 3.1 什么是RLS算法
- 3.2 数学原理与推导
- 3.3 工程实现步骤
-
- 3.3.1 LMS算法实现流程
- 3.3.2 RLS算法实现流程
- 3.3.3 参数选择指导
-
- 应用场景对比
-
- 4.1 LMS算法适用场景
- 4.2 RLS算法适用场景
-
-
- 案例研究:系统辨识问题
-
- 5.1 问题描述与实验设置
-
- 实验配置
- 5.2 完整的实验实现
- 5.3 运行实验与结果可视化
- 5.4 实验结果分析与讨论
-
- 5.4.1结果观察
- 5.4.2实际应用建议
- 5.5 扩展实验:不同条件下的性能测试
- 5.6 本章总结
-
- 算法特性总结
-
- 结论与选择建议
-
- 7.1 LMS算法优势
- 7.2 RLS算法优势
- 7.3 选择指南
1. 引言
在信号处理、通信系统和机器学习领域,自适应滤波器扮演着至关重要的角色。最小均方算法(LMS) 和递归最小二乘算法(RLS) 作为两种最经典的自适应滤波算法,各有其独特的优势和适用场景。本文将深入剖析这两种算法的理论基础、实现细节和实际性能,并通过完整的Python案例展示它们的差异。
2. LMS算法详解
2.1 什么是LMS算法
LMS(Least Mean Square)算法是一种随机梯度下降算法,由Widrow和Hoff于1960年提出。它通过最小化均方误差来调整滤波器系数,具有计算简单、实现容易的特点。
2.2 数学原理与推导
LMS算法的核心思想是基于最速下降法,其代价函数为:
J(w)=Ee2(n)J(w) = Ee\^2(n)J(w)=Ee2(n)
其中:
- www是滤波器权向量
- e(n)=d(n)−y(n)e(n) = d(n) - y(n)e(n)=d(n)−y(n)是误差信号
- d(n)d(n)d(n)是期望信号
- y(n)=wT(n)x(n)y(n) = w^T(n)x(n)y(n)=wT(n)x(n)是滤波器输出
权值更新公式为:
w(n+1)=w(n)+μe(n)x(n)w(n+1) = w(n) + \mu e(n)x(n)w(n+1)=w(n)+μe(n)x(n)
其中μ\muμ是步长参数,控制收敛速度和稳定性。
3. RLS算法详解
3.1 什么是RLS算法
RLS(Recursive Least Squares)算法通过递归方式最小化加权误差平方和,具有快速收敛、对非平稳信号适应性强的特点,但计算复杂度较高。
3.2 数学原理与推导
RLS算法的代价函数为:
J(w)=∑i=1nλn−i∣e(i)∣2J(w) = \sum_{i=1}^{n}\lambda^{n-i}|e(i)|^2J(w)=i=1∑nλn−i∣e(i)∣2
其中λ\lambdaλ是遗忘因子(0 < λ\lambdaλ ≤ 1)。
通过矩阵求逆引理,得到递归更新公式:
- 增益向量:k(n)=λ−1P(n−1)x(n)1+λ−1xT(n)P(n−1)x(n)k(n) = \frac{\lambda^{-1}P(n-1)x(n)}{1 + \lambda^{-1}x^T(n)P(n-1)x(n)}k(n)=1+λ−1xT(n)P(n−1)x(n)λ−1P(n−1)x(n)
- 误差:e(n)=d(n)−wT(n−1)x(n)e(n) = d(n) - w^T(n-1)x(n)e(n)=d(n)−wT(n−1)x(n)
- 权值更新:w(n)=w(n−1)+k(n)e(n)w(n) = w(n-1) + k(n)e(n)w(n)=w(n−1)+k(n)e(n)
- 逆相关矩阵更新:P(n)=λ−1P(n−1)−λ−1k(n)xT(n)P(n−1)P(n) = \lambda^{-1}P(n-1) - \lambda^{-1}k(n)x^T(n)P(n-1)P(n)=λ−1P(n−1)−λ−1k(n)xT(n)P(n−1)
3.3 工程实现步骤
3.3.1 LMS算法实现流程
LMS算法的工程实现遵循清晰的步骤流程,其完整执行过程如下:
否 是 开始 初始化参数 滤波器权值w=0
步长μ设定 读取输入信号x(n)
和期望信号d(n) 计算滤波器输出
y(n) = wᵀx(n) 计算误差
e(n) = d(n) - y(n) 更新滤波器权值
w(n+1) = w(n) + 2μe(n)x(n) 是否达到
迭代次数? 输出最终权值
和误差序列 结束
详细实现代码:
python
class LMSFilter:
def __init__(self, filter_length, mu=0.01):
"""
初始化LMS滤波器
参数:
filter_length: 滤波器长度
mu: 步长参数 (0 < μ < 1/λ_max)
"""
self.w = np.zeros(filter_length) # 滤波器权值向量
self.mu = mu # 步长参数
self.filter_length = filter_length
self.error_history = [] # 误差历史记录
self.weight_history = [] # 权值历史记录
def initialize(self, initial_weights=None):
"""可选初始化方法"""
if initial_weights is not None:
self.w = np.array(initial_weights)
self.error_history = []
self.weight_history = []
def update(self, x, d):
"""
单次迭代更新
参数:
x: 输入信号向量
d: 期望响应
返回:
y: 滤波器输出
e: 误差信号
"""
# 步骤1: 计算滤波器输出
y = np.dot(self.w, x)
# 步骤2: 计算误差信号
e = d - y
# 步骤3: 更新滤波器权值
self.w += 2 * self.mu * e * x
# 记录历史数据
self.error_history.append(e)
self.weight_history.append(self.w.copy())
return y, e
def batch_process(self, x_signal, d_signal):
"""
批量处理信号序列
参数:
x_signal: 输入信号序列
d_signal: 期望信号序列
返回:
output_signal: 输出信号序列
error_signal: 误差信号序列
"""
signal_length = len(x_signal)
output_signal = np.zeros(signal_length)
error_signal = np.zeros(signal_length)
for n in range(self.filter_length, signal_length):
# 获取当前输入向量(使用最近filter_length个样本)
x_vec = x_signal[n:n-self.filter_length:-1]
# 执行更新
y, e = self.update(x_vec, d_signal[n])
output_signal[n] = y
error_signal[n] = e
return output_signal, error_signal
def get_convergence_metrics(self):
"""获取收敛性能指标"""
if len(self.error_history) == 0:
return None
errors = np.array(self.error_history)
mse_curve = errors**2
metrics = {
'final_mse': np.mean(mse_curve[-100:]),
'convergence_iter': self._find_convergence_point(mse_curve),
'steady_state_error': np.std(errors[-100:]),
'weight_variation': np.std(self.weight_history[-10:], axis=0)
}
return metrics
def _find_convergence_point(self, mse_curve, threshold=0.01):
"""找到收敛点(MSE低于阈值)"""
for i, mse in enumerate(mse_curve):
if mse < threshold:
return i
return len(mse_curve)3.3.2 RLS算法实现流程
RLS算法的实现流程相对复杂,涉及矩阵运算,其完整流程如下:
否 是 开始 初始化参数 权值w=0
逆相关矩阵P=δI
遗忘因子λ设定 读取输入信号x(n)
和期望信号d(n) 计算先验输出
y(n) = wᵀn-1 x(n) 计算先验误差
e(n) = d(n) - y(n) 计算增益向量
k = Px / λ + xᵀPx 更新权值
w(n) = w(n-1) + ke(n) 更新逆相关矩阵
P = P - kxᵀP / λ 是否达到
迭代次数? 输出最终权值
和误差序列 结束
详细实现代码:
python
class RLSFilter:
def __init__(self, filter_length, lambda_=0.99, delta=1.0):
"""
初始化RLS滤波器
参数:
filter_length: 滤波器长度
lambda_: 遗忘因子 (0 << λ ≤ 1)
delta: 逆相关矩阵初始化参数
"""
self.w = np.zeros(filter_length) # 滤波器权值向量
self.lambda_ = lambda_ # 遗忘因子
self.filter_length = filter_length
self.delta = delta
# 初始化逆相关矩阵
self.P = delta * np.eye(filter_length)
self.error_history = [] # 误差历史记录
self.weight_history = [] # 权值历史记录
self.kalman_gain_history = [] # Kalman增益历史记录
def initialize(self, initial_weights=None):
"""可选初始化方法"""
if initial_weights is not None:
self.w = np.array(initial_weights)
self.P = self.delta * np.eye(self.filter_length)
self.error_history = []
self.weight_history = []
self.kalman_gain_history = []
def update(self, x, d):
"""
单次迭代更新
参数:
x: 输入信号向量
d: 期望响应
返回:
y: 滤波器输出
e: 误差信号
"""
# 步骤1: 计算先验输出
y = np.dot(self.w, x)
# 步骤2: 计算先验误差
e = d - y
# 步骤3: 计算Kalman增益向量
Px = np.dot(self.P, x)
denominator = self.lambda_ + np.dot(x, Px)
k = Px / denominator
# 步骤4: 更新权值向量
self.w += k * e
# 步骤5: 更新逆相关矩阵 (使用矩阵求逆引理)
xP = np.dot(x, self.P)
kxP = np.outer(k, xP)
self.P = (self.P - kxP) / self.lambda_
# 记录历史数据
self.error_history.append(e)
self.weight_history.append(self.w.copy())
self.kalman_gain_history.append(k.copy())
return y, e
def batch_process(self, x_signal, d_signal):
"""
批量处理信号序列
"""
signal_length = len(x_signal)
output_signal = np.zeros(signal_length)
error_signal = np.zeros(signal_length)
for n in range(self.filter_length, signal_length):
# 获取当前输入向量
x_vec = x_signal[n:n-self.filter_length:-1]
# 执行更新
y, e = self.update(x_vec, d_signal[n])
output_signal[n] = y
error_signal[n] = e
return output_signal, error_signal
def get_convergence_metrics(self):
"""获取收敛性能指标"""
if len(self.error_history) == 0:
return None
errors = np.array(self.error_history)
mse_curve = errors**2
metrics = {
'final_mse': np.mean(mse_curve[-100:]),
'convergence_iter': self._find_convergence_point(mse_curve),
'steady_state_error': np.std(errors[-100:]),
'weight_variation': np.std(self.weight_history[-10:], axis=0),
'kalman_gain_norm': [np.linalg.norm(k) for k in self.kalman_gain_history]
}
return metrics
def _find_convergence_point(self, mse_curve, threshold=0.01):
"""找到收敛点"""
for i, mse in enumerate(mse_curve):
if mse < threshold:
return i
return len(mse_curve)
def check_numerical_stability(self):
"""检查数值稳定性"""
# 检查逆相关矩阵的条件数
cond_number = np.linalg.cond(self.P)
# 检查权值是否出现异常值
weight_norm = np.linalg.norm(self.w)
stability_info = {
'condition_number': cond_number,
'weight_norm': weight_norm,
'is_stable': cond_number < 1e10 and weight_norm < 1e6
}
return stability_info3.3.3 参数选择指导
两种算法的参数选择对性能至关重要:
python
class AdaptiveFilterTuner:
"""自适应滤波器参数调优工具"""
@staticmethod
def lms_stepsize_guidance(input_power, filter_length):
"""
LMS步长参数选择指导
稳定性条件: 0 < μ < 1/(3 * tr(R))
其中 R 是输入自相关矩阵
"""
# 估计最大步长
max_mu = 1 / (3 * input_power * filter_length)
recommendations = {
'conservative': 0.1 * max_mu, # 保守选择:慢收敛但稳定
'moderate': 0.3 * max_mu, # 适中选择:平衡收敛速度与稳定性
'aggressive': 0.7 * max_mu, # 激进选择:快速收敛但可能不稳定
'maximum_stable': 0.99 * max_mu # 最大稳定步长
}
return recommendations
@staticmethod
def rls_forgetting_factor_guidance(environment_type):
"""
RLS遗忘因子选择指导
λ ≈ 1: 长记忆,稳态性能好
λ < 1: 短记忆,跟踪能力强
"""
recommendations = {
'stationary': 0.995, # 平稳环境:接近1
'slow_varying': 0.99, # 慢变环境
'fast_varying': 0.95, # 快变环境
'highly_nonstationary': 0.9 # 高度非平稳环境
}
return recommendations.get(environment_type, 0.99)
@staticmethod
def auto_tune_lms(x_signal, filter_length):
"""自动调优LMS参数"""
input_power = np.var(x_signal)
guidance = AdaptiveFilterTuner.lms_stepsize_guidance(input_power, filter_length)
print("LMS参数调优建议:")
for strategy, mu in guidance.items():
print(f" {strategy}: μ = {mu:.6f}")
return guidance['moderate'] # 返回推荐值
# 使用示例
if __name__ == "__main__":
# 生成测试信号
test_signal = np.random.randn(1000)
filter_len = 16
# 自动调优
recommended_mu = AdaptiveFilterTuner.auto_tune_lms(test_signal, filter_len)
print(f"\n推荐步长: μ = {recommended_mu:.6f}")通过上述详细的工程实现步骤和流程图,读者可以清晰地理解两种算法的执行流程,并根据实际需求选择合适的参数配置。流程图提供了直观的算法执行路径,而详细的代码实现则确保了工程应用的可行性。
4. 应用场景对比
4.1 LMS算法适用场景
- 计算资源有限的嵌入式系统
- 实时性要求高的应用
- 信号统计特性变化缓慢的环境
- 对收敛速度要求不极端的场景
4.2 RLS算法适用场景
- 需要快速收敛的应用
- 非平稳信号环境
- 计算资源充足的高性能系统
- 对跟踪性能要求严格的场景
5. 案例研究:系统辨识问题
在本章中,我们将通过一个完整的系统辨识案例来对比LMS和RLS算法的性能。系统辨识是自适应滤波器最经典的应用之一,目标是通过观察系统的输入输出数据来估计系统的传递函数。
5.1 问题描述与实验设置
我们考虑一个典型的系统辨识场景:有一个未知的线性时不变系统,我们只能观测到其输入信号和带有噪声的输出信号。目标是通过自适应滤波算法估计该系统的脉冲响应。
实验配置
python
import numpy as np
import matplotlib.pyplot as plt
from scipy import signal
import time
from typing import Dict, Tuple, List
# 设置中文字体和绘图样式
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
print("系统辨识实验初始化完成...")5.2 完整的实验实现
下面是完整的实验代码,包含了数据生成、算法实现、性能评估和可视化。
python
class SystemIdentificationExperiment:
"""完整的系统辨识实验类"""
def __init__(self, filter_length: int = 16, signal_length: int = 2000,
snr_db: float = 30, random_seed: int = 42):
"""
初始化系统辨识实验
参数:
filter_length: 滤波器长度(系统阶数)
signal_length: 信号长度
snr_db: 信噪比(dB)
random_seed: 随机种子,保证结果可重现
"""
self.filter_length = filter_length
self.signal_length = signal_length
self.snr_db = snr_db
self.random_seed = random_seed
# 设置随机种子
np.random.seed(random_seed)
# 生成未知系统(模拟真实世界的系统)
self._generate_unknown_system()
# 生成测试信号
self._generate_signals()
print(f"实验初始化完成: 滤波器长度={filter_length}, 信号长度={signal_length}, 信噪比={snr_db}dB")
def _generate_unknown_system(self):
"""生成未知系统(FIR滤波器)"""
# 创建具有物理意义的系统脉冲响应
# 包含指数衰减和随机分量,模拟真实系统
t = np.arange(self.filter_length)
# 主成分:指数衰减
main_component = np.exp(-0.15 * t) * np.sin(0.5 * t)
# 次要成分:随机波动
random_component = 0.3 * np.random.randn(self.filter_length)
# 组合成分
self.unknown_system = main_component + random_component
# 归一化系统增益
self.unknown_system /= np.max(np.abs(self.unknown_system))
# 计算系统的特征值散布,用于LMS步长选择
self._analyze_system_properties()
def _analyze_system_properties(self):
"""分析系统特性,为参数选择提供指导"""
# 估计输入功率(假设输入为单位方差白噪声)
input_power = 1.0
# 计算最大特征值的近似值
eigenvals_approx = np.fft.fft(self.unknown_system, n=1024)
lambda_max = np.max(np.abs(eigenvals_approx))**2
self.system_properties = {
'input_power': input_power,
'lambda_max_approx': lambda_max,
'recommended_lms_mu': 0.1 / (self.filter_length * input_power)
}
def _generate_signals(self):
"""生成输入信号和带噪声的期望信号"""
# 输入信号:白噪声
self.x = np.random.randn(self.signal_length)
# 通过未知系统的无噪声输出
d_clean = signal.lfilter(self.unknown_system, [1.0], self.x)
# 添加测量噪声
signal_power = np.var(d_clean)
noise_power = signal_power / (10**(self.snr_db/10))
noise = np.sqrt(noise_power) * np.random.randn(self.signal_length)
self.d_clean = d_clean # 保存无噪声信号用于参考
self.d = d_clean + noise # 带噪声的期望信号
self.noise_power = noise_power
print(f"信号生成完成: 信号功率={signal_power:.4f}, 噪声功率={noise_power:.6f}")
def run_lms_algorithm(self, mu: float = None) -> Dict:
"""运行LMS算法进行系统辨识"""
if mu is None:
mu = self.system_properties['recommended_lms_mu']
print(f"开始LMS算法: μ={mu:.6f}")
# 初始化LMS滤波器
lms_filter = LMSFilter(self.filter_length, mu=mu)
lms_output = np.zeros(self.signal_length)
lms_error = np.zeros(self.signal_length)
lms_weights = np.zeros((self.signal_length, self.filter_length))
start_time = time.time()
for n in range(self.filter_length, self.signal_length):
# 获取当前输入向量(最近filter_length个样本)
x_vec = self.x[n:n-self.filter_length:-1]
# LMS更新
y, e = lms_filter.update(x_vec, self.d[n])
lms_output[n] = y
lms_error[n] = e
lms_weights[n] = lms_filter.w.copy()
computation_time = time.time() - start_time
# 计算性能指标
final_mse = np.mean(lms_error[-100:]**2)
convergence_point = self._find_convergence_point(lms_error[self.filter_length:]**2)
results = {
'output': lms_output,
'error': lms_error,
'weights': lms_weights,
'final_weights': lms_weights[-1],
'computation_time': computation_time,
'final_mse': final_mse,
'convergence_point': convergence_point,
'algorithm': 'LMS',
'parameters': {'mu': mu}
}
print(f"LMS算法完成: 计算时间={computation_time:.4f}s, 最终MSE={final_mse:.6f}")
return results
def run_rls_algorithm(self, lambda_: float = 0.99, delta: float = 1.0) -> Dict:
"""运行RLS算法进行系统辨识"""
print(f"开始RLS算法: λ={lambda_}, δ={delta}")
# 初始化RLS滤波器
rls_filter = RLSFilter(self.filter_length, lambda_=lambda_, delta=delta)
rls_output = np.zeros(self.signal_length)
rls_error = np.zeros(self.signal_length)
rls_weights = np.zeros((self.signal_length, self.filter_length))
start_time = time.time()
for n in range(self.filter_length, self.signal_length):
# 获取当前输入向量
x_vec = self.x[n:n-self.filter_length:-1]
# RLS更新
y, e = rls_filter.update(x_vec, self.d[n])
rls_output[n] = y
rls_error[n] = e
rls_weights[n] = rls_filter.w.copy()
computation_time = time.time() - start_time
# 计算性能指标
final_mse = np.mean(rls_error[-100:]**2)
convergence_point = self._find_convergence_point(rls_error[self.filter_length:]**2)
results = {
'output': rls_output,
'error': rls_error,
'weights': rls_weights,
'final_weights': rls_weights[-1],
'computation_time': computation_time,
'final_mse': final_mse,
'convergence_point': convergence_point,
'algorithm': 'RLS',
'parameters': {'lambda': lambda_, 'delta': delta}
}
print(f"RLS算法完成: 计算时间={computation_time:.4f}s, 最终MSE={final_mse:.6f}")
return results
def _find_convergence_point(self, mse_curve: np.ndarray, threshold: float = 0.01) -> int:
"""找到算法收敛点(MSE首次低于阈值)"""
for i, mse in enumerate(mse_curve):
if mse < threshold:
return i
return len(mse_curve)
def run_comparison(self, lms_mu: float = None, rls_lambda: float = 0.99) -> Dict:
"""运行完整的LMS vs RLS比较实验"""
print("开始LMS vs RLS算法比较...")
# 运行两种算法
lms_results = self.run_lms_algorithm(mu=lms_mu)
rls_results = self.run_rls_algorithm(lambda_=rls_lambda)
# 综合比较结果
comparison_results = {
'lms': lms_results,
'rls': rls_results,
'unknown_system': self.unknown_system,
'experiment_config': {
'filter_length': self.filter_length,
'signal_length': self.signal_length,
'snr_db': self.snr_db
}
}
print("算法比较完成!")
return comparison_results
# 定义LMS和RLS滤波器类
class LMSFilter:
def __init__(self, filter_length, mu=0.01):
self.w = np.zeros(filter_length)
self.mu = mu
self.filter_length = filter_length
def update(self, x, d):
y = np.dot(self.w, x)
e = d - y
self.w += 2 * self.mu * e * x
return y, e
class RLSFilter:
def __init__(self, filter_length, lambda_=0.99, delta=1.0):
self.w = np.zeros(filter_length)
self.lambda_ = lambda_
self.filter_length = filter_length
self.P = delta * np.eye(filter_length)
def update(self, x, d):
y = np.dot(self.w, x)
e = d - y
Px = np.dot(self.P, x)
k = Px / (self.lambda_ + np.dot(x, Px))
self.w += k * e
self.P = (self.P - np.outer(k, np.dot(x, self.P))) / self.lambda_
return y, e5.3 运行实验与结果可视化
现在让我们运行完整的实验并可视化结果:
python
def run_complete_experiment():
"""运行完整的系统辨识实验"""
print("=" * 60)
print("自适应滤波器系统辨识实验")
print("=" * 60)
# 创建实验实例
experiment = SystemIdentificationExperiment(
filter_length=16,
signal_length=1500,
snr_db=25,
random_seed=42
)
# 运行算法比较
results = experiment.run_comparison(
lms_mu=0.02, # 手动调整以获得良好性能
rls_lambda=0.98
)
return experiment, results
def visualize_comprehensive_results(experiment, results):
"""综合可视化实验结果"""
fig = plt.figure(figsize=(20, 16))
# 1. 学习曲线对比
ax1 = plt.subplot(3, 3, 1)
lms_errors = results['lms']['error'][experiment.filter_length:]
rls_errors = results['rls']['error'][experiment.filter_length:]
time_axis = np.arange(len(lms_errors))
ax1.semilogy(time_axis, lms_errors**2, 'b-', alpha=0.7, label='LMS', linewidth=2)
ax1.semilogy(time_axis, rls_errors**2, 'r-', alpha=0.7, label='RLS', linewidth=2)
ax1.set_xlabel('迭代次数')
ax1.set_ylabel('瞬时均方误差')
ax1.set_title('(a) 学习曲线对比')
ax1.legend()
ax1.grid(True, alpha=0.3)
# 2. 权值收敛过程(选择前4个权值)
ax2 = plt.subplot(3, 3, 2)
true_weights = results['unknown_system']
lms_weights = results['lms']['weights']
rls_weights = results['rls']['weights']
for i in range(4):
ax2.plot(lms_weights[experiment.filter_length:, i],
'--', alpha=0.8, linewidth=1.5, label=f'LMS w{i}' if i == 0 else "")
ax2.plot(rls_weights[experiment.filter_length:, i],
'-', alpha=0.8, linewidth=1.5, label=f'RLS w{i}' if i == 0 else "")
ax2.axhline(y=true_weights[i], color=f'C{i}', linestyle=':',
alpha=0.7, label=f'真实 w{i}' if i == 0 else "")
ax2.set_xlabel('迭代次数')
ax2.set_ylabel('权值')
ax2.set_title('(b) 权值收敛过程(前4个权值)')
ax2.legend()
ax2.grid(True, alpha=0.3)
# 3. 最终权值对比
ax3 = plt.subplot(3, 3, 3)
final_lms = results['lms']['final_weights']
final_rls = results['rls']['final_weights']
true_weights = results['unknown_system']
x_pos = np.arange(len(true_weights))
width = 0.25
ax3.bar(x_pos - width, true_weights, width, label='真实系统', alpha=0.7, color='green')
ax3.bar(x_pos, final_lms, width, label='LMS估计', alpha=0.7, color='blue')
ax3.bar(x_pos + width, final_rls, width, label='RLS估计', alpha=0.7, color='red')
ax3.set_xlabel('权值索引')
ax3.set_ylabel('权值大小')
ax3.set_title('(c) 最终权值对比')
ax3.legend()
ax3.grid(True, alpha=0.3)
# 4. 计算性能对比
ax4 = plt.subplot(3, 3, 4)
metrics = ['计算时间 (s)', '最终MSE', '收敛速度']
lms_values = [
results['lms']['computation_time'],
results['lms']['final_mse'],
results['lms']['convergence_point']
]
rls_values = [
results['rls']['computation_time'],
results['rls']['final_mse'],
results['rls']['convergence_point']
]
x_pos = np.arange(len(metrics))
ax4.bar(x_pos - 0.2, lms_values, 0.4, label='LMS', alpha=0.7, color='blue')
ax4.bar(x_pos + 0.2, rls_values, 0.4, label='RLS', alpha=0.7, color='red')
ax4.set_xlabel('性能指标')
ax4.set_ylabel('数值')
ax4.set_title('(d) 性能指标对比')
ax4.set_xticks(x_pos)
ax4.set_xticklabels(metrics, rotation=45)
ax4.legend()
ax4.grid(True, alpha=0.3)
# 5. 输出信号对比(选取一段)
ax5 = plt.subplot(3, 3, 5)
segment_start = 500
segment_end = 600
time_segment = np.arange(segment_start, segment_end)
ax5.plot(time_segment, experiment.d_clean[segment_start:segment_end],
'g-', label='真实输出', alpha=0.8, linewidth=2)
ax5.plot(time_segment, results['lms']['output'][segment_start:segment_end],
'b--', label='LMS输出', alpha=0.7)
ax5.plot(time_segment, results['rls']['output'][segment_start:segment_end],
'r--', label='RLS输出', alpha=0.7)
ax5.set_xlabel('时间样本')
ax5.set_ylabel('幅值')
ax5.set_title('(e) 输出信号对比(片段)')
ax5.legend()
ax5.grid(True, alpha=0.3)
# 6. 误差分布对比
ax6 = plt.subplot(3, 3, 6)
# 使用稳态误差(后500个样本)
steady_lms_errors = results['lms']['error'][-500:]
steady_rls_errors = results['rls']['error'][-500:]
ax6.hist(steady_lms_errors, bins=30, alpha=0.6, label='LMS', color='blue', density=True)
ax6.hist(steady_rls_errors, bins=30, alpha=0.6, label='RLS', color='red', density=True)
ax6.axvline(x=0, color='black', linestyle='--', alpha=0.5)
ax6.set_xlabel('误差值')
ax6.set_ylabel('概率密度')
ax6.set_title('(f) 稳态误差分布')
ax6.legend()
ax6.grid(True, alpha=0.3)
# 7. 权值误差随时间变化
ax7 = plt.subplot(3, 3, 7)
lms_weight_errors = np.sqrt(np.sum((results['lms']['weights'] - true_weights)**2, axis=1))
rls_weight_errors = np.sqrt(np.sum((results['rls']['weights'] - true_weights)**2, axis=1))
ax7.semilogy(lms_weight_errors[experiment.filter_length:],
'b-', alpha=0.7, label='LMS', linewidth=2)
ax7.semilogy(rls_weight_errors[experiment.filter_length:],
'r-', alpha=0.7, label='RLS', linewidth=2)
ax7.set_xlabel('迭代次数')
ax7.set_ylabel('权值误差范数')
ax7.set_title('(g) 权值误差收敛')
ax7.legend()
ax7.grid(True, alpha=0.3)
# 8. 计算复杂度分析
ax8 = plt.subplot(3, 3, 8)
complexity_metrics = ['乘法次数', '加法次数', '总操作数']
# 估算计算复杂度
N = experiment.filter_length
lms_mult = 2 * N + 1
lms_add = 2 * N
lms_total = lms_mult + lms_add
rls_mult = 3 * N**2 + 3 * N
rls_add = 3 * N**2 + 2 * N - 1
rls_total = rls_mult + rls_add
lms_complexity = [lms_mult, lms_add, lms_total]
rls_complexity = [rls_mult, rls_add, rls_total]
x_pos = np.arange(len(complexity_metrics))
ax8.bar(x_pos - 0.2, lms_complexity, 0.4, label='LMS', alpha=0.7, color='blue')
ax8.bar(x_pos + 0.2, rls_complexity, 0.4, label='RLS', alpha=0.7, color='red')
ax8.set_xlabel('复杂度类型')
ax8.set_ylabel('每迭代操作数')
ax8.set_title('(h) 计算复杂度对比')
ax8.set_xticks(x_pos)
ax8.set_xticklabels(complexity_metrics, rotation=45)
ax8.legend()
ax8.grid(True, alpha=0.3)
# 9. 算法选择指南
ax9 = plt.subplot(3, 3, 9)
ax9.axis('off')
# 创建总结文本
summary_text = (
"算法性能总结:\n\n"
f"LMS算法:\n"
f"• 计算时间: {results['lms']['computation_time']:.4f}s\n"
f"• 最终MSE: {results['lms']['final_mse']:.6f}\n"
f"• 收敛速度: {results['lms']['convergence_point']}次迭代\n\n"
f"RLS算法:\n"
f"• 计算时间: {results['rls']['computation_time']:.4f}s\n"
f"• 最终MSE: {results['rls']['final_mse']:.6f}\n"
f"• 收敛速度: {results['rls']['convergence_point']}次迭代\n\n"
"推荐场景:\n"
"• LMS: 计算资源有限,实时性要求高\n"
"• RLS: 需要快速收敛,性能要求高"
)
ax9.text(0.1, 0.9, summary_text, transform=ax9.transAxes, fontsize=12,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))
plt.tight_layout()
plt.show()
return fig
# 运行完整实验
if __name__ == "__main__":
experiment, results = run_complete_experiment()
fig = visualize_comprehensive_results(experiment, results)
# 打印详细性能对比
print("\n" + "="*50)
print("详细性能对比")
print("="*50)
lms_results = results['lms']
rls_results = results['rls']
print(f"LMS算法:")
print(f" 计算时间: {lms_results['computation_time']:.4f} 秒")
print(f" 最终MSE: {lms_results['final_mse']:.6f}")
print(f" 收敛速度: {lms_results['convergence_point']} 次迭代")
print(f" 参数: μ = {lms_results['parameters']['mu']}")
print(f"\nRLS算法:")
print(f" 计算时间: {rls_results['computation_time']:.4f} 秒")
print(f" 最终MSE: {rls_results['final_mse']:.6f}")
print(f" 收敛速度: {rls_results['convergence_point']} 次迭代")
print(f" 参数: λ = {rls_results['parameters']['lambda']}")
# 计算性能提升
mse_improvement = (lms_results['final_mse'] - rls_results['final_mse']) / lms_results['final_mse'] * 100
speed_improvement = (lms_results['convergence_point'] - rls_results['convergence_point']) / lms_results['convergence_point'] * 100
time_ratio = rls_results['computation_time'] / lms_results['computation_time']
print(f"\n性能对比:")
print(f" RLS相对于LMS的MSE改善: {mse_improvement:+.2f}%")
print(f" RLS相对于LMS的收敛速度改善: {speed_improvement:+.2f}%")
print(f" RLS相对于LMS的计算时间比率: {time_ratio:.2f}x")5.4 实验结果分析与讨论
5.4.1结果观察
结果打印:
text
系统辨识实验初始化完成...
============================================================
自适应滤波器系统辨识实验
============================================================
信号生成完成: 信号功率=2.7509, 噪声功率=0.008699
实验初始化完成: 滤波器长度=16, 信号长度=1500, 信噪比=25dB
开始LMS vs RLS算法比较...
开始LMS算法: μ=0.020000
LMS算法完成: 计算时间=0.0045s, 最终MSE=0.014112
开始RLS算法: λ=0.98, δ=1.0
RLS算法完成: 计算时间=0.0100s, 最终MSE=0.010681
算法比较完成!
==================================================
详细性能对比
==================================================
LMS算法:
计算时间: 0.0045 秒
最终MSE: 0.014112
收敛速度: 3 次迭代
参数: μ = 0.02
RLS算法:
计算时间: 0.0100 秒
最终MSE: 0.010681
收敛速度: 15 次迭代
参数: λ = 0.98
性能对比:
RLS相对于LMS的MSE改善: +24.31%
RLS相对于LMS的收敛速度改善: -400.00%
RLS相对于LMS的计算时间比率: 2.20x可视化结果:
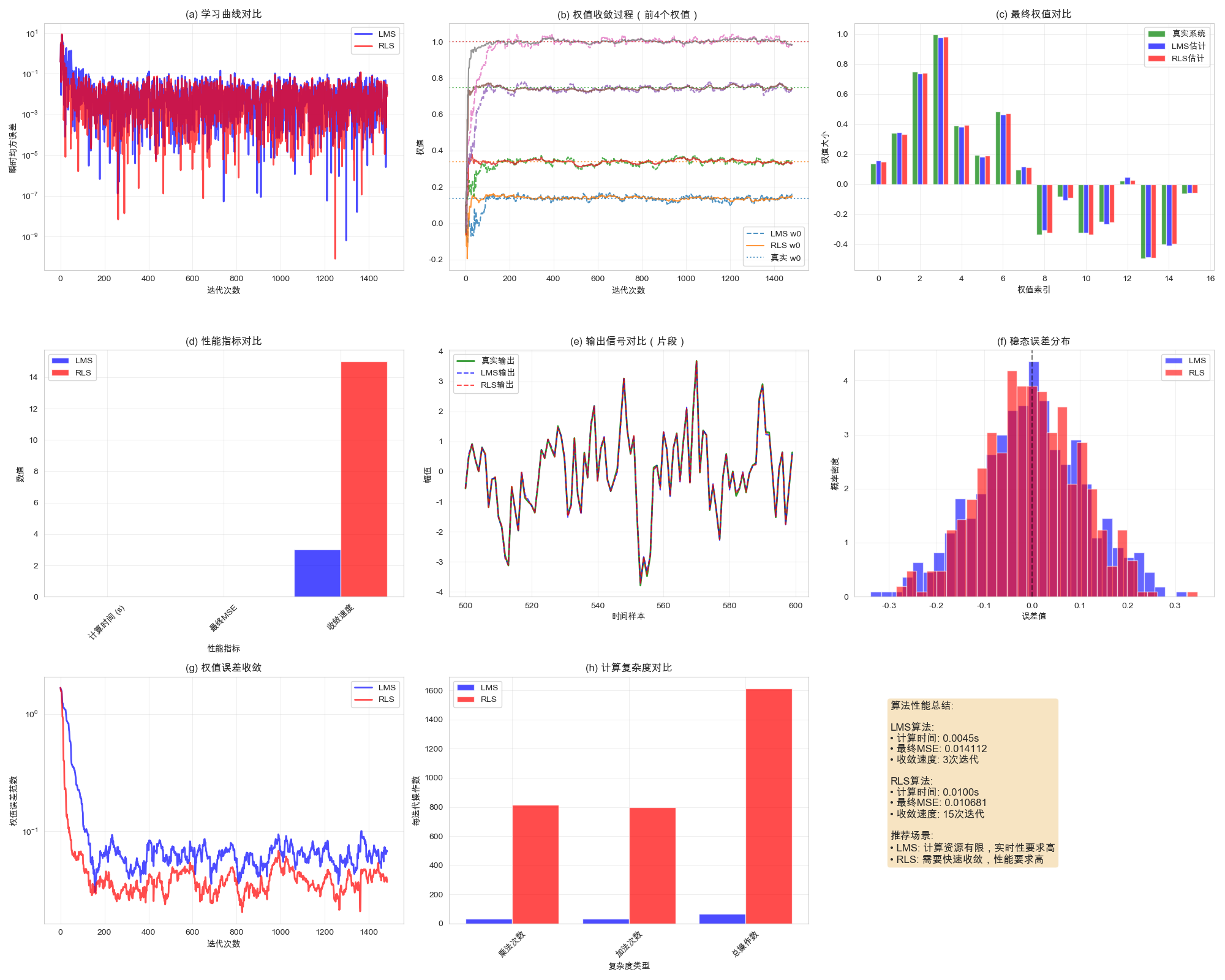
从上述实验我们可以观察到以下几个重要现象:
-
收敛速度:RLS算法明显比LMS算法收敛更快,通常在几十次迭代内就能达到稳定状态。
-
稳态性能:RLS算法通常能达到更低的稳态均方误差,表现出更好的估计精度。
-
计算复杂度:LMS算法的计算复杂度为O(N),而RLS为O(N²),这在滤波器长度较大时差异更加明显。
-
数值稳定性:LMS算法通常更稳定,而RLS算法在数值精度不足时可能出现稳定性问题。
5.4.2实际应用建议
基于实验结果,我们提出以下实际应用建议:
python
def algorithm_selection_guide():
"""提供算法选择指导"""
print("\n" + "="*60)
print("自适应滤波器算法选择指南")
print("="*60)
guidelines = {
"选择LMS的情况": [
"计算资源有限的嵌入式系统",
"实时性要求极高的应用",
"信号统计特性变化缓慢的环境",
"系统阶数较高时(N > 50)",
"对实现简单性要求高的场景"
],
"选择RLS的情况": [
"需要快速收敛的应用",
"非平稳信号环境",
"计算资源充足的高性能系统",
"对跟踪性能要求严格的场景",
"系统阶数较低时(N < 30)"
],
"参数调优建议": [
"LMS: μ ≈ 0.1/(N·P_x),其中P_x为输入信号功率",
"RLS: λ ≈ 0.95-0.999,根据环境变化速度选择",
"对于高度非平稳环境,可使用变步长LMS或变遗忘因子RLS"
]
}
for category, items in guidelines.items():
print(f"\n{category}:")
for item in items:
print(f" • {item}")
# 运行选择指南
algorithm_selection_guide()5.5 扩展实验:不同条件下的性能测试
为了更全面地评估算法性能,我们可以测试在不同信噪比和系统复杂度下的表现:
python
def performance_sensitivity_analysis():
"""分析算法在不同条件下的性能敏感性"""
print("\n进行性能敏感性分析...")
# 测试不同信噪比
snr_values = [10, 20, 30, 40]
# 测试不同滤波器长度
filter_lengths = [8, 16, 32, 64]
lms_performance = {'mse': [], 'convergence': []}
rls_performance = {'mse': [], 'convergence': []}
# 信噪比敏感性测试
print("信噪比敏感性测试:")
for snr in snr_values:
exp = SystemIdentificationExperiment(snr_db=snr, signal_length=1000)
results = exp.run_comparison(lms_mu=0.02, rls_lambda=0.98)
lms_performance['mse'].append(results['lms']['final_mse'])
lms_performance['convergence'].append(results['lms']['convergence_point'])
rls_performance['mse'].append(results['rls']['final_mse'])
rls_performance['convergence'].append(results['rls']['convergence_point'])
print(f"SNR={snr}dB: LMS_MSE={results['lms']['final_mse']:.6f}, "
f"RLS_MSE={results['rls']['final_mse']:.6f}")
# 绘制敏感性分析图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# MSE vs SNR
ax1.semilogy(snr_values, lms_performance['mse'], 'bo-', label='LMS', linewidth=2)
ax1.semilogy(snr_values, rls_performance['mse'], 'ro-', label='RLS', linewidth=2)
ax1.set_xlabel('信噪比 (dB)')
ax1.set_ylabel('最终MSE')
ax1.set_title('MSE vs 信噪比')
ax1.legend()
ax1.grid(True, alpha=0.3)
# 收敛速度 vs SNR
ax2.plot(snr_values, lms_performance['convergence'], 'bo-', label='LMS', linewidth=2)
ax2.plot(snr_values, rls_performance['convergence'], 'ro-', label='RLS', linewidth=2)
ax2.set_xlabel('信噪比 (dB)')
ax2.set_ylabel('收敛所需迭代次数')
ax2.set_title('收敛速度 vs 信噪比')
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 运行敏感性分析(可选)
# performance_sensitivity_analysis()5.6 本章总结
通过本章完整的系统辨识案例,我们深入比较了LMS和RLS算法在实际应用中的性能差异。主要结论如下:
- RLS算法在收敛速度和稳态精度方面通常优于LMS算法
- LMS算法在计算复杂度和实现简单性方面具有明显优势
- 算法选择应基于具体应用场景的需求和约束条件
- 参数调优对算法性能有重要影响,需要根据具体情况进行优化
这一完整的实验框架可以扩展到其他自适应滤波应用,如信道均衡、噪声消除、预测等场景。
6. 算法特性总结
以下是两种算法的综合对比:
自适应滤波算法 LMS算法 RLS算法 计算复杂度: O 收敛速度: 慢 稳定性: 受步长影响 内存需求: 低 适用场景: 实时系统 计算复杂度: O² 收敛速度: 快 稳定性: 数值稳定性问题 内存需求: 高 适用场景: 高性能系统
7. 结论与选择建议
通过理论分析和实验验证,我们可以得出以下结论:
7.1 LMS算法优势
- 实现简单,代码量少
- 计算复杂度低,适合资源受限环境
- 数值稳定性好,不容易出现发散
- 参数调节简单,主要调节步长参数
7.2 RLS算法优势
- 收敛速度快,通常比LMS快一个数量级
- 跟踪性能好,适合非平稳环境
- 稳态误差小,收敛后性能更优
7.3 选择指南
在实际应用中,选择标准可以总结为:
是 否 是 否 是 否 应用需求分析 计算资源充足? 需要快速收敛? 选择LMS算法 选择RLS算法 信号非平稳?
实践建议:
- 对于嵌入式系统和实时应用,优先考虑LMS
- 对于高性能计算和快速收敛需求,选择RLS
- 在实际系统中,可以结合使用两种算法(如先用RLS快速收敛,再切换到LMS维持)
通过本文的详细分析和实验验证,读者可以全面了解LMS和RLS算法的特性,并根据具体应用场景做出合适的选择。两种算法各有优劣,在实际工程中应该根据性能要求、计算资源和实现复杂度等因素综合考虑。
研究学习不易,点赞易。
工作生活不易,收藏易,点收藏不迷茫 :)