目录
[1 LSTM相关网络总结与对比](#1 LSTM相关网络总结与对比)
[1.1 理论总结](#1.1 理论总结)
[1.2 代码运行对比](#1.2 代码运行对比)
[2 量子计算入门](#2 量子计算入门)
[3 总结](#3 总结)
摘要
本周首先总结了LSTM、Bi-LSTM与GRU的区别与优缺点,对比了三者实战的代码与效果,还另外拓展了一些循环神经网络变体(包括窥视孔LSTM、耦合门LSTM与SRU)。其次,初步了解了量子计算的相关知识,包括量子比特、量子纠缠、量子干涉等,学习了量子比特与经典比特的区别、量子计算的经典算法、面临的挑战、主流技术路线与部分应用场景。
Abstract
This week, I firstly summarized the differences, advantages, and disadvantages among LSTM, Bi-LSTM, and GRU, compared their practical code implementations and performances. Additionally, I explored several RNN variants, including Peephole LSTM, Coupled Gate LSTM, and SRU. Secondly, I gained preliminary knowledge of quantum computing, covering concepts such as qubits, quantum entanglement, and quantum interference. I also studied the distinctions between qubits and classical bits, classic quantum algorithms, current challenges, mainstream technological approaches, and some application scenarios.
1 LSTM相关网络总结与对比
1.1 理论总结
回顾上周学习的LSTM、Bi-LSTM与GRU三种网络结构。
LSTM主要引入细胞状态与三个门控机制(遗忘门、输入门与输出门)以解决了传统RNN的相关问题,例如梯度消失,它能捕捉长期依赖,适合处理长序列,但参数多,训练十分缓慢;
Bi-LSTM没有改动LSTM的结构,而是使用两个独立的LSTM结构分布从右到左和从左到右处理序列,对两者结果进行求和或者拼接得到最终结果。因此,它的参数量相较LSTM更大,训练更慢,同时它需要完整序列,无法进行实时预测类的任务。但它能够捕捉语言语法中一些特定的前置或后置特征,增强语义关联,结果更为精准;
GRU则对LSTM的结构进行了部分改动,将三个门控机制简化合并到两个(更新门与重置门),在简化结构、减少参数量的同时略微削弱了其长期依赖建模的能力。在大多数任务中,GRU与LSTM性能还是接近的。
除此之外,循环神经网络还有许多其他的变体,例如,窥视孔 LSTM(Peephole LSTM),它在标准 LSTM 基础上,让门控机制也能访问细胞状态,能更精细地控制信息流动,主要应用在语音识别、手写识别等需要精确时序控制的任务上;耦合门 LSTM(Coupled LSTM),它将遗忘门和输入门耦合,不再独立决定"忘记什么"和"记住什么",而是统一决策,它强制忘记旧信息才能记住新信息,不够灵活,故很少使用;还有SRU(Simple Recurrent Unit),它是一种高度并行化的循环神经网络单元,由 Milly Song 等人在 2017 年 提出,训练速度极快(接近 CNN),显存占用小且适合长文本、语音等任务,其关键在于将隐藏状态的更新过程从时间依赖中解耦,允许完全并行计算整个序列,不像普通循环神经网络那样必须按时间步顺序计算。
1.2 代码运行对比
上周进行了LSTM的代码实战,训练总共花费6小时33分钟40秒,最终结果如下:
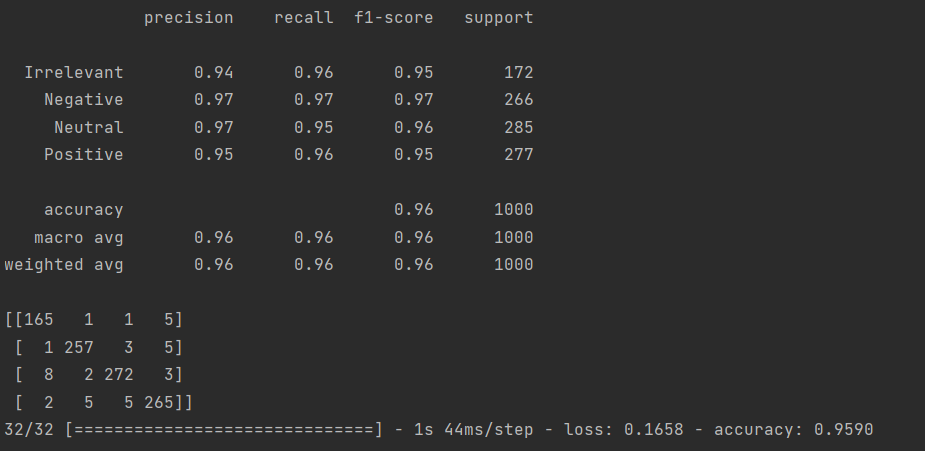
上述结果包括各项指标、混淆矩阵以及最终的损失与准确率。其中 macro avg 的中文名称为宏平均,其计算方式为每个指标的算术平均。weighted avg 是加权平均,它的计算方式是用每一个类别样本数量在所有类别的样本总数的占比作为权重。
若利用Bi-LSTM进行训练,需对模型定义部分进行如下改动:
python
def build_model(hp):
model = Sequential([
Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=100, input_length=MAX_SEQUENCE_LENGTH),
#改动部分
Bidirectional(LSTM(units=hp.Int('LSTM_UNITS', min_value=64, max_value=256, step=64),
dropout=hp.Float('dropout_rate', min_value=0.2, max_value=0.5, step=0.1))),
Dense(64, activation='relu'),
Dropout(0.5),
Dense(y_train.shape[1], activation='softmax')
])
model.compile(loss='categorical_crossentropy',
optimizer=Adam(learning_rate=hp.Choice('learning_rate', values=[0.001, 0.0005, 0.0001])),
metrics=['accuracy'])
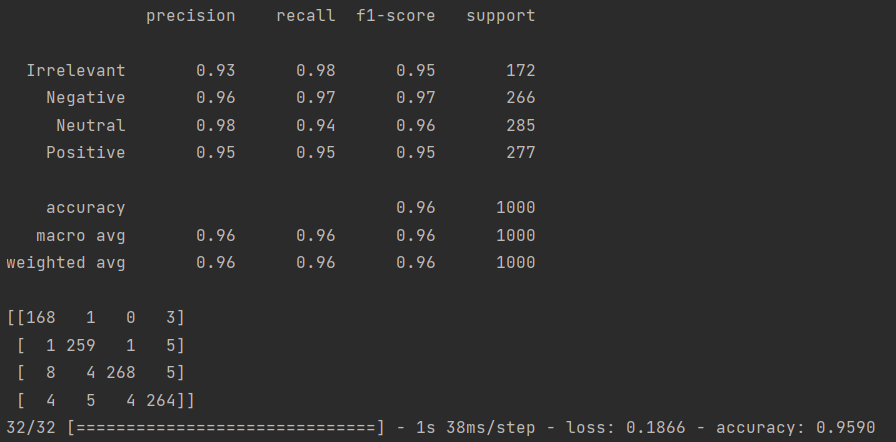
return model主要是利用 Bidirectional 包装器对 LSTM 层进行包装,它会创建两个独立的 LSTM 层,一个按原始顺序处理序列,一个按逆序处理序列,然后将两者的输出进行合并(默认是拼接 concat,也可以通过 merge_mode 进行调整)
训练总共花费13小时7分钟45秒,结果如下:
若利用GRU进行训练,需对模型定义部分进行如下改动:
python
def build_model(hp):
model = Sequential([
Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=100, input_length=MAX_SEQUENCE_LENGTH),
#改动部分
GRU(units=hp.Int('GRU_UNITS', min_value=64, max_value=256, step=64),
dropout=hp.Float('dropout_rate', min_value=0.2, max_value=0.5, step=0.1)),
Dense(64, activation='relu'),
Dropout(0.5),
Dense(y_train.shape[1], activation='softmax')
])
model.compile(loss='categorical_crossentropy',
optimizer=Adam(learning_rate=hp.Choice('learning_rate', values=[0.001, 0.0005, 0.0001])),
metrics=['accuracy'])
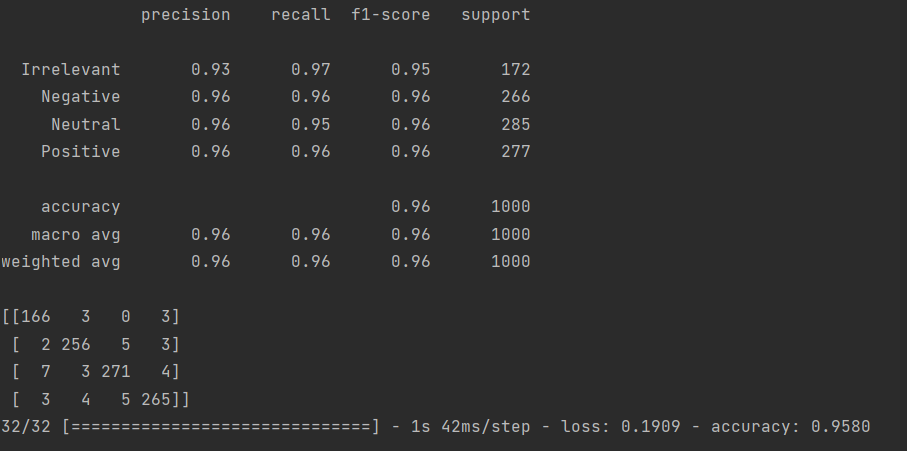
return model主要是将原代码中的 LSTM 改为 GRU。
训练总共花费4小时8分钟57秒,结果如下:
2 量子计算入门
量子计算本质上是一种新型的计算方式,它利用量子力学中的某些性质或现象(如叠加和纠缠),有望在特定任务上实现对经典计算机的"量子优越性"(Quantum Advantage),指的是量子计算机在解决某个特定、精心设计的问题上,其运算速度远远超过当今最强大的经典超级计算机,以至于经典计算机在可接受的时间内(例如数千年甚至更久)无法完成相同任务,这也是所谓的量子霸权。2019年,谷歌"悬铃木"(Sycamore)处理器在200秒内完成了一项经典超算需一万年才能完成的计算任务,首次实验证明了量子优越性,标志着量子计算从理论走向实践的关键里程碑。
为了理解量子计算,首先认识其最基本信息单元,量子比特(Qubit),它对应着经典计算中的比特。
经典计算中比特的状态只能是 0 或 1,具有确定性,测量能够得到真实值,而且多个比特若无逻辑链接,则状态相互独立;
但量子比特的状态不仅可以是 |0⟩、|1⟩,还可以是两者的叠加态,可表示为:
|ψ⟩ = a|0⟩+b|1⟩
其中 a 和 b 是复数,称为概率幅,且满足 。
量子比特的状态在测量前处于不确定状态,测量时会以 的概率坍缩为 |0⟩ ,以
的概率坍缩为|1⟩,多个量子比特可形成纠缠态,状态关联强。
叠加态是量子并行性的基础。一个n量子比特的系统可以同时表示2^n个经典状态的叠加。例如,2个量子比特可以同时处于|00⟩、|01⟩、|10⟩、|11⟩四种状态的叠加。这意味着量子计算机在一次操作中可以同时处理指数级数量的可能性,为解决复杂问题提供了巨大的潜在算力。
量子纠缠主要是指当两个或多个量子比特发生纠缠时,它们的状态会变得密不可分,无论相隔多远,对其中一个量子比特的测量会瞬间决定其他纠缠量子比特的状态。爱因斯坦曾称其为"鬼魅般的超距作用"。纠缠是量子通信(如量子密钥分发)、量子隐形传态和许多量子算法的核心资源,它使得量子系统能够表现出经典系统无法复制的强关联性。
在此基础上,量子计算可以通过精心设计的量子门操作(单量子比特门、双量子比特门等)构成量子电路,利用量子干涉来增强正确答案的概率幅,同时抑制错误答案的概率幅。这类似于波的干涉现象,即相长干涉使波增强,相消干涉使波减弱。量子算法的精妙之处就在于如何编排量子门序列,使得计算路径的干涉效应最终导向期望的输出结果(使得其概率尽可能地大)。
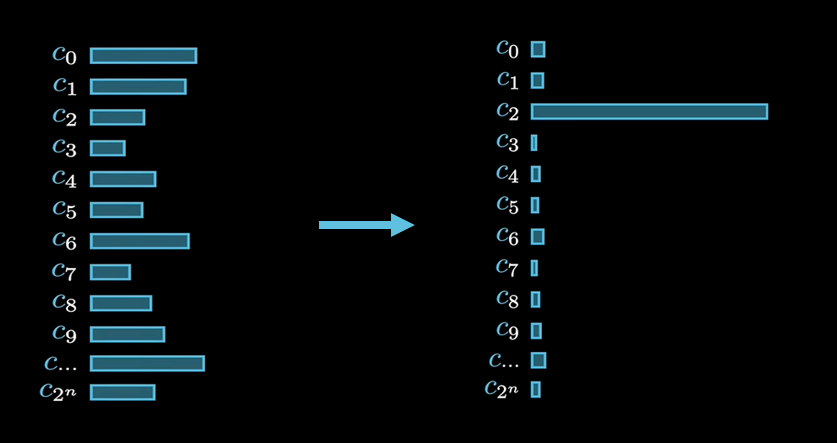
标志性量子算法包括以下几种,在后续也会详细学习:
首先是Shor算法,它由彼得·肖尔(Peter Shor)在1994年提出,主要解决了大整数质因数分解的问题。RSA等广泛使用的公钥加密体系的安全性都是基于大数分解的困难性。Shor算法能在多项式时间内解决此问题,一旦大规模容错量子计算机实现,将对现有密码学体系构成颠覆性威胁,这推动了"后量子密码学"(PQC)的研究。
其次是Grover算法,由洛夫·格罗弗(Lov Grover)在1996年提出,主要解决了在无序数据库中搜索特定项的问题。这个问题在经典计算中的时间复杂度为O(N),平均检查次数为 ,而Grover算法仅需约
√N 次查询时间复杂度为O(√N)时间,提供了二次加速。它虽然不如Shor算法的指数加速震撼,但在优化、密码分析等领域仍有重要应用价值。
最后是量子变分算法(VQE, QAOA)。由于在当前含噪声中等规模量子(NISQ)时代,硬件存在噪声和错误,难以运行前面两种或其他需要长深度电路和高保真度的"纯"量子算法。量子变分算法混合量子计算与经典计算,利用量子处理器和经典优化器,对噪声有一定容忍度,能利用现有NISQ硬件进行实验。其中量子处理器执行一个参数化的浅层量子电路(变分电路),测量输出;经典计算机根据测量结果优化电路参数,以最小化某个目标函数(如分子基态能量)。
量子计算的发展也面临一些挑战:
首先,由于量子态极其脆弱,易受环境噪声(热、电磁辐射等)干扰而逐步失去量子特性,退化为经典行为,保持量子态稳定的时间有限,这个退化的过程叫退相干,保持量子态稳定的时间被称为相干时间。退相干是量子计算中必须克服的最根本、最顽固的障碍之一。
其次,为了克服噪声,需引入冗余量子比特进行纠错。主流方案如表面码(Surface Code)要求大量物理量子比特来编码一个逻辑量子比特(可能需数千甚至上万),对硬件规模和保真度的要求极高。
还有是可扩展性,要制造、操控和连接成千上万个高质量量子比特,并保持高保真度,也是工程上的巨大挑战。
量子计算的主流技术路线包括超导量子比特(IBM, Google)、囚禁离子(IonQ)、光子量子计算(Xanadu)以及中性原子(ColdQuanta)。超导量子比特主要利用超导电路进行实现,制造工艺与半导体兼容,可扩展性好,但需极低温稀释制冷机,且易受电磁噪声干扰;囚禁离子主要是利用电磁场囚禁单个离子,用激光操控其能级作为量子比特,它的相干时间长,量子门保真度高,比特间连接性好,但操控速度相对较慢,规模化集成难度大;光子量子计算主要是利用光子的路径、偏振等来编码量子信息,可以在室温下运行,抗干扰能力强,天然适合量子通信,但实现确定性的相互作用较为困难,规模化挑战大;中性原子主要就是利用光镊阵列囚禁中性原子,用里德堡态实现长程相互作用,其可编程性强,易于构建二维/三维阵列,是近期发展迅速的热门方向。不同技术路线各有优劣,在相干时间、操控精度、可扩展性等方面面临不同挑战。
量子计算并非万能,它更擅长解决具有特定结构的问题,如:量子化学与材料科学,精确模拟分子和材料的量子行为,加速新药、催化剂、电池材料的研发;优化问题,比如物流、金融投资组合、供应链管理中的复杂优化难题的解决;机器学习,开发量子机器学习算法,处理高维数据,加速训练过程;密码学,破解现有加密,同时推动量子安全加密技术的发展。
3 总结
本周对循环神经网络,主要是LSTM相关网络进行了回顾,比较了LSTM、Bi-LSTM与GRU的实战代码与效果,同时学习了量子计算的入门知识,对量子计算有了一个大致的认识。