大家好,我是吾鳴。专注于分享提升工作与生活效率的工具,无偿分享AI领域相关的精选报告,持续关注AI的前沿动向。
你是不是也经历过这样的困境:每天花费数小时,疯狂刷着抖音,试图靠一己之力捕捉那稍纵即逝的热点?结果不仅眼睛酸、手指累,好不容易跟风发了一条,却发现自己永远是'最后一波'上车的人,流量早已被瓜分殆尽。
更让人纠结的是,明知市面上有付费的数据监控工具,但是那昂贵的年费,对个体创作者和小团队来说,无疑是笔沉重的负担。人工监控,效率低下;软件监控,成本高昂。 难道抓住热点,就注定是一场'肝'与'钞'能力的无奈比拼吗?
当然不是!
本文,就给大家介绍一个完全免费、效率超高的解决方案:利用扣子(Coze) 搭建一个专属你的抖音热点监控'智能助理'。它可以每天定时自动运行,将爆款视频的点赞数量、收藏数量、作者昵称、作者粉丝数量等信息直接整理到飞书表格中,让我们可以基于这些宝贵的数据,深度分析'低粉高爆'视频的成功模式,真正从源头破解流量密码,让你不再错过任何一波早期流量,实现精准'蹭热点'!文章有点长,建议收藏,以便可以随时找到。
可以看看热点监控小助理采集到飞书表格中的视频信息,分别包含视频标题、视频发布时间、互动数据、无水印下载地址、作者信息等,效果如下。

1. 完整的工作流流程
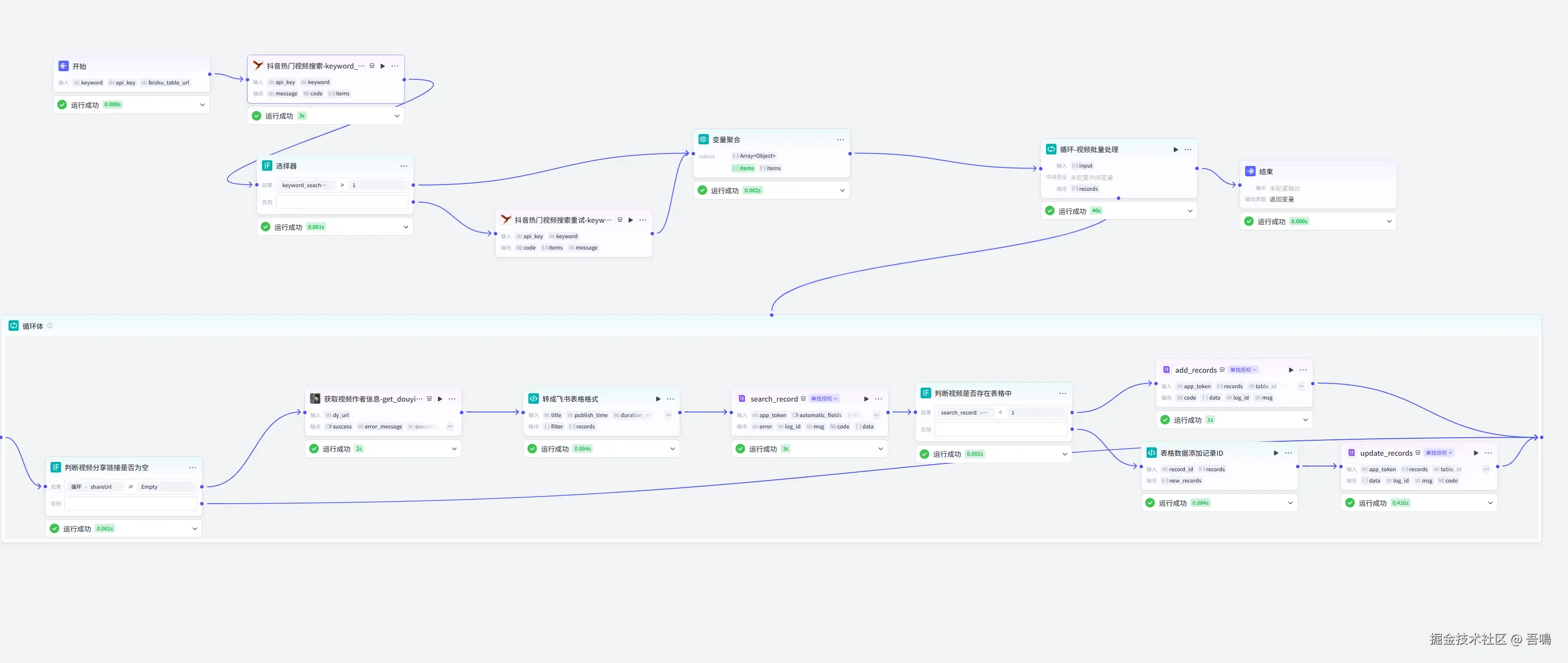
1、抖音热点视频搜索:通过扣子插件根据输入的监控的关键字搜索相关的视频热点,包含视频标题、发布时间、视频点赞量、收藏量、分享量、分享量、分享链接等信息。
2、视频详细信息获取:通过扣子插件根据分享链接获取视频的详细信息,包含作者昵称、作者粉丝量、视频无水印下载地址等信息。
3、视频信息转换成飞书表格格式:通过扣子的代码节点,把视频信息转化成飞书表格认识的格式。
4、视频写入飞书表格:通过扣子的飞书多维表格插件,检查视频信息是否已经存在于飞书表格?已存在则做信息更新,不存在则做信息写入,保证飞书表格中的数据不重复。
5、智能体配置:通过配置智能体,让工作流每天定时运行,每天自动把热门的视频信息更新到飞书表格中。
2. 工作流详细节点解读
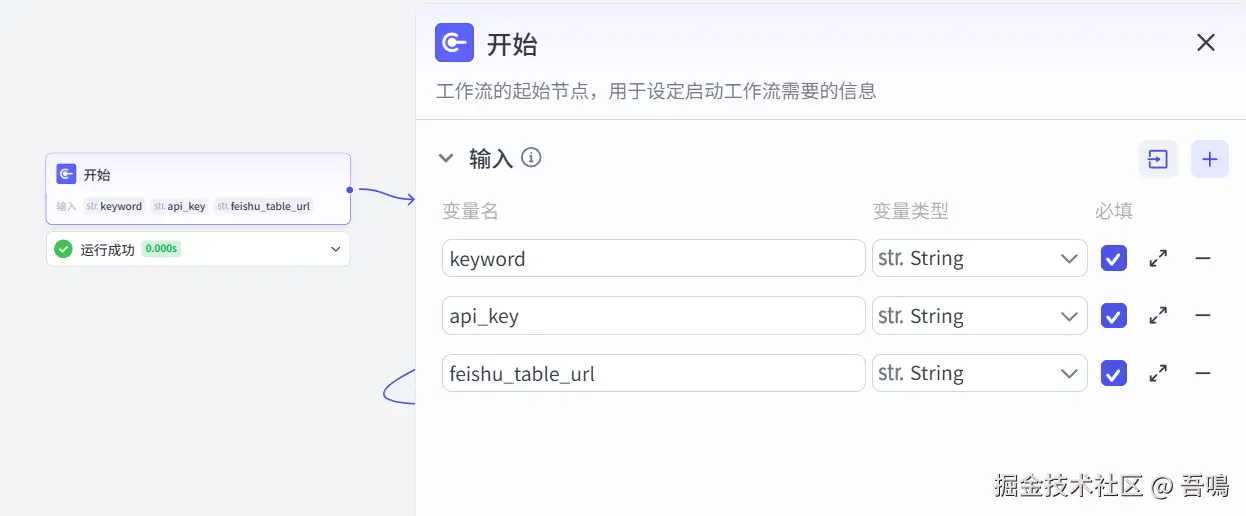
2.1. 开始
- keyword:热点关键词,必填
- api_key:朱雀平台认证,视频搜索插件需使用,必填
- feishu_table_url:飞书多维表格地址,必填
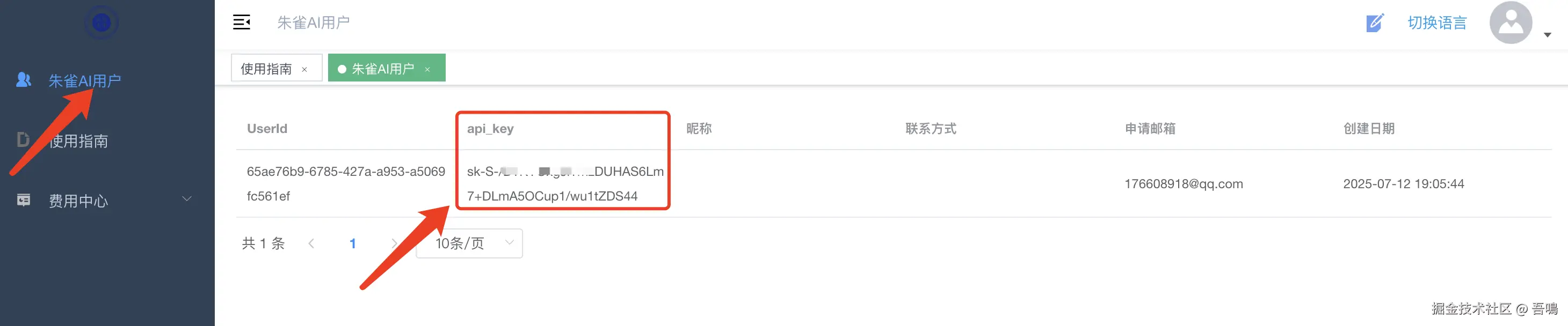
2.1.1. 朱雀平台认证
朱雀平台认证可以到这个(douyin.sdnhpy.cn/index)地址获取。
2.1.2. 飞书表格
飞书多维表格需要提前到飞书平台上创建好,飞书多维表格的字段的名称和字段的类型需要和文章开头的截图保持一致,下面是对飞书多维表格的字段名称和字段类型的定义,字段名称和类型对应不上会导致视频信息写入表格失败。
视频ID:文本
视频标题:文本
点赞数:字段类型【数字】、数字格式【整数】
收藏数:字段类型【数字】、数字格式【整数】
评论数:字段类型【数字】、数字格式【整数】
分享数:字段类型【数字】、数字格式【整数】
作者昵称:文本
作者粉丝量:字段类型【数字】、数字格式【整数】
作者点赞量:字段类型【数字】、数字格式【整数】
发布日期:文本
视频时长(单位秒):字段类型【数字】、数字格式【整数】
视频分享链接:超链接
视频封面:超链接
视频下载链接:超链接
记录时间:文本创建好飞书多维表格之后,获取飞书多维表格浏览器上方的地址作为feishu_table_url参数。

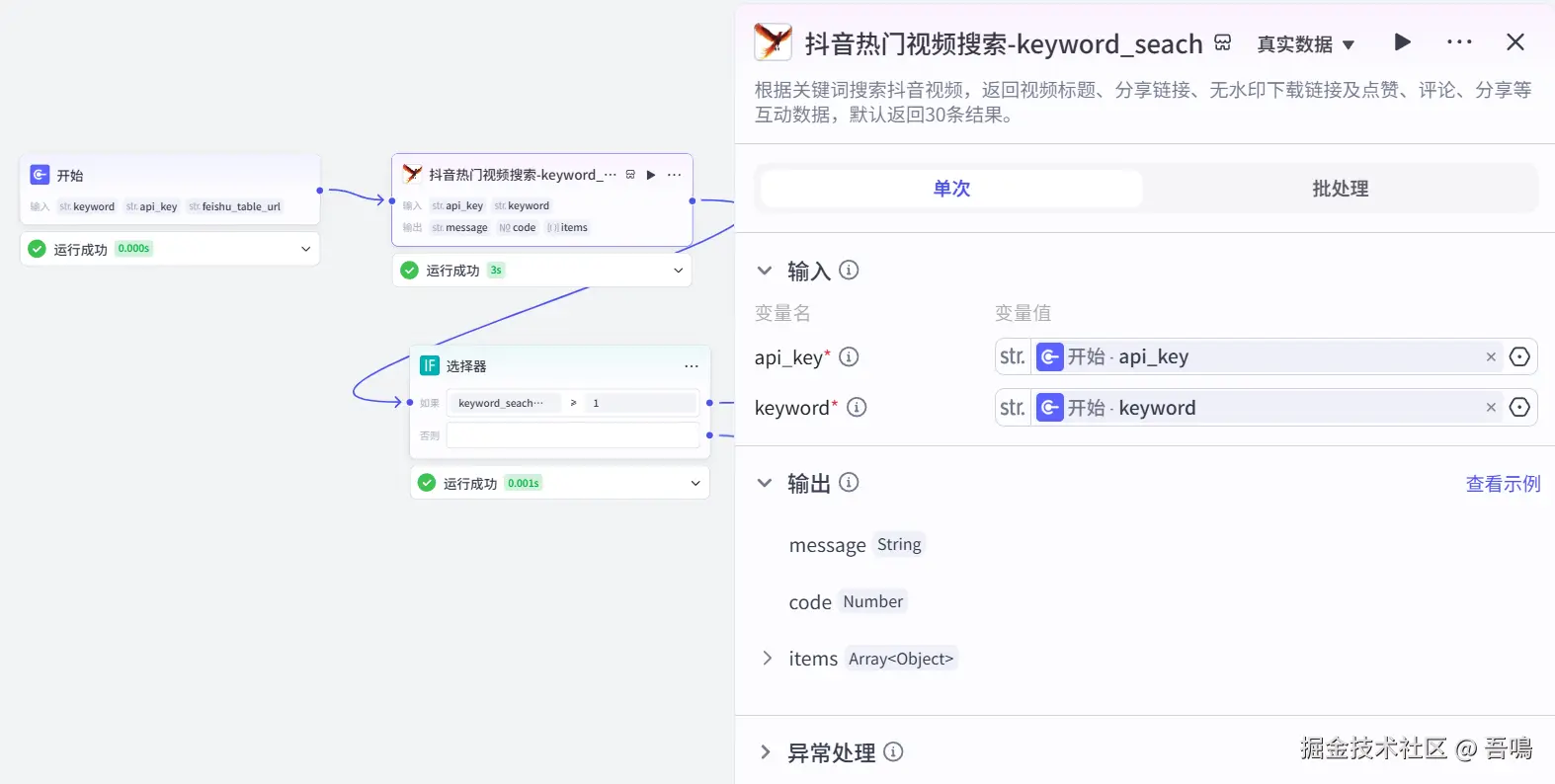
2.2. 热门视频搜索
这个节点使用到了【抖音信息提取】插件的【keyword_search】工具,用于搜索抖音的热门视频列表,目前亲测免费,还比较稳定。
2.3. 判断视频搜索是否成功
这个节点用于判断热门视频搜索是否成功,使用到了扣子官方的【选择器】节点。

2.4. 热门视频搜索重试
如果第一次的热门视频搜索不成功就会执行到这个节点,进行搜索重试,提升工作流运行的成功率。此节点和【热门视频搜索】节点使用了相同的插件和工具。
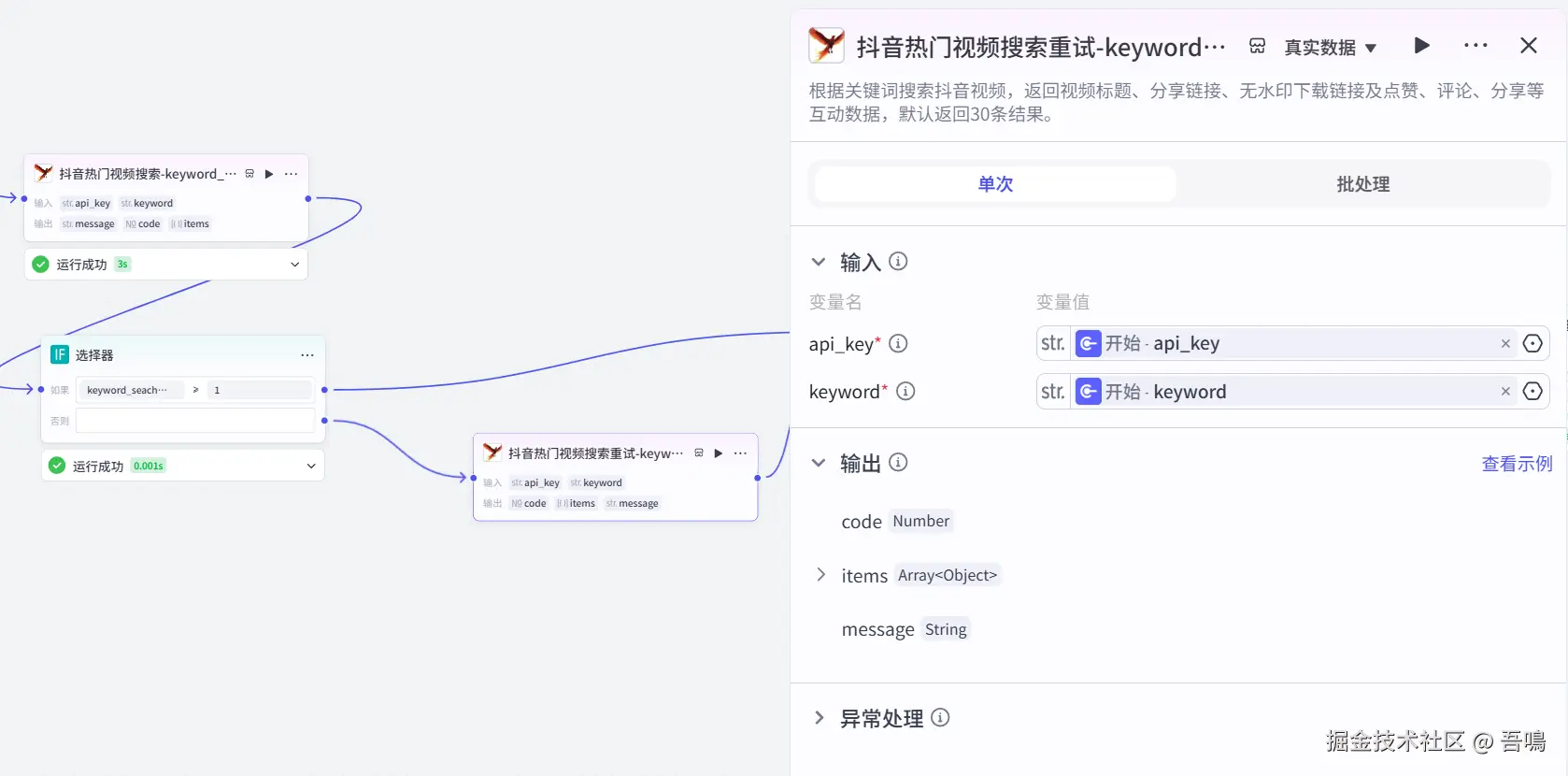
2.5. 变量聚合
这个节点的作用用于把两次视频搜索的结果聚合成一个,便于后面的节点处理。使用到了扣子官方的【变量聚合】节点。
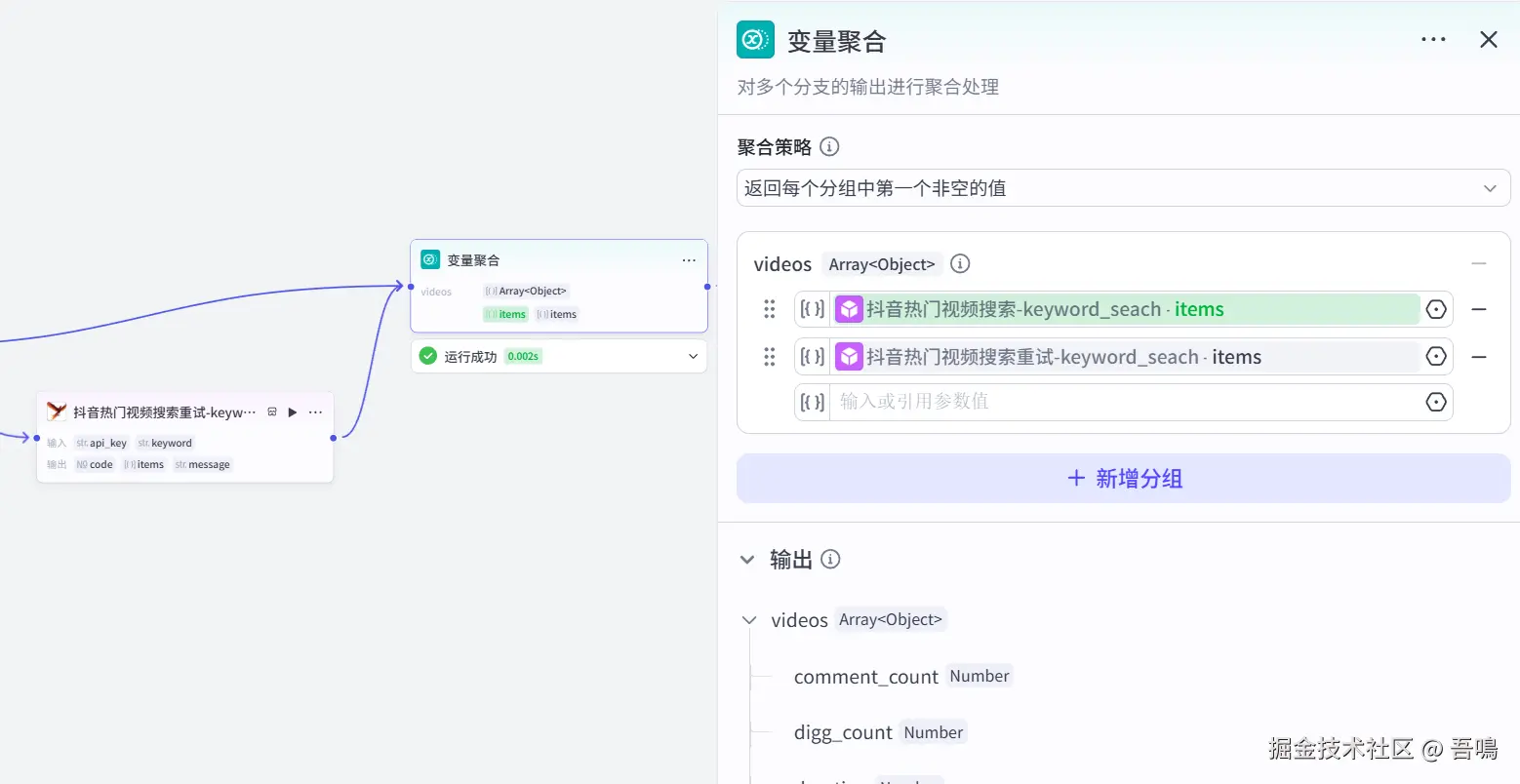
2.6. 视频批量处理
这个节点用于循环处理前面【热门视频搜索】节点搜索出来的每一条视频数据,使用到了扣子官方的【循环】节点。
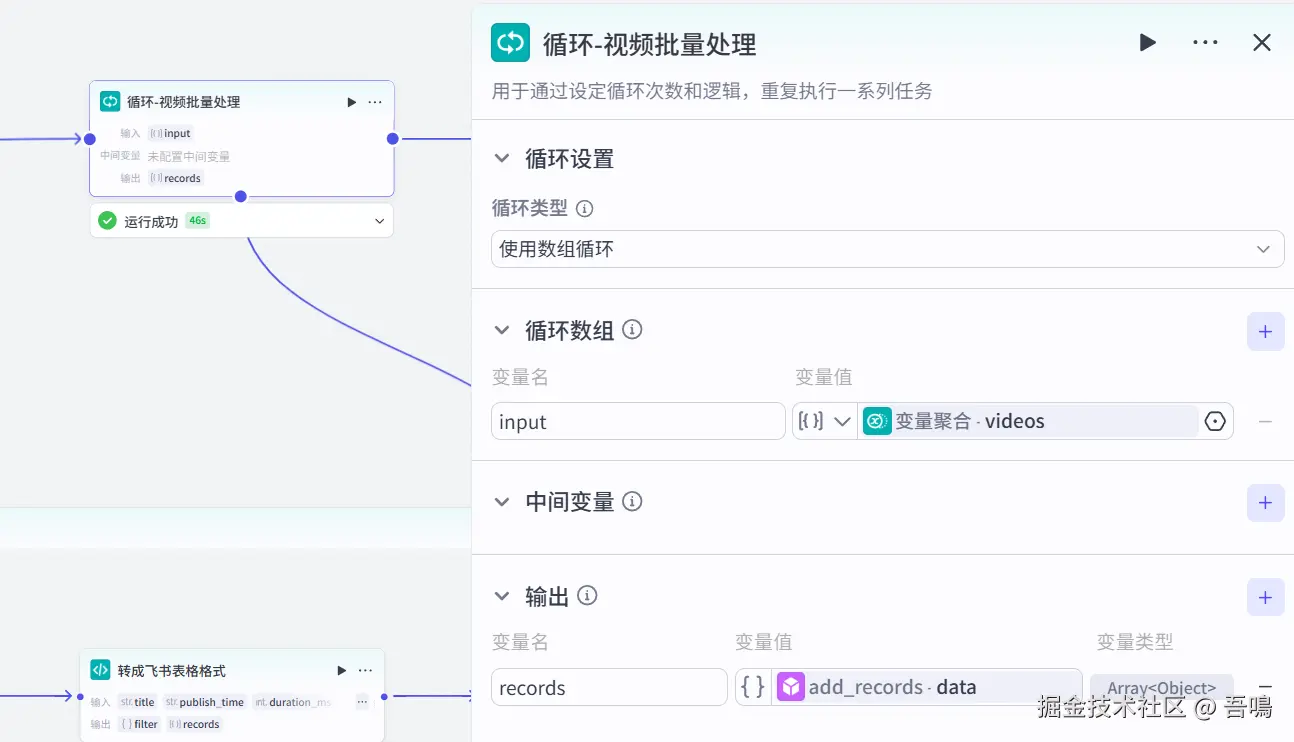
2.7. 判断视频分享链接是否为空
这个节点用于判断当前处理的视频信息的分享链接是否为空,为空则不处理本条视频数据,因测试过程中发现有些视频的分享链接为空导致后面的流程失败,因此增加了这个节点。它使用到了扣子官方的【选择器】节点。
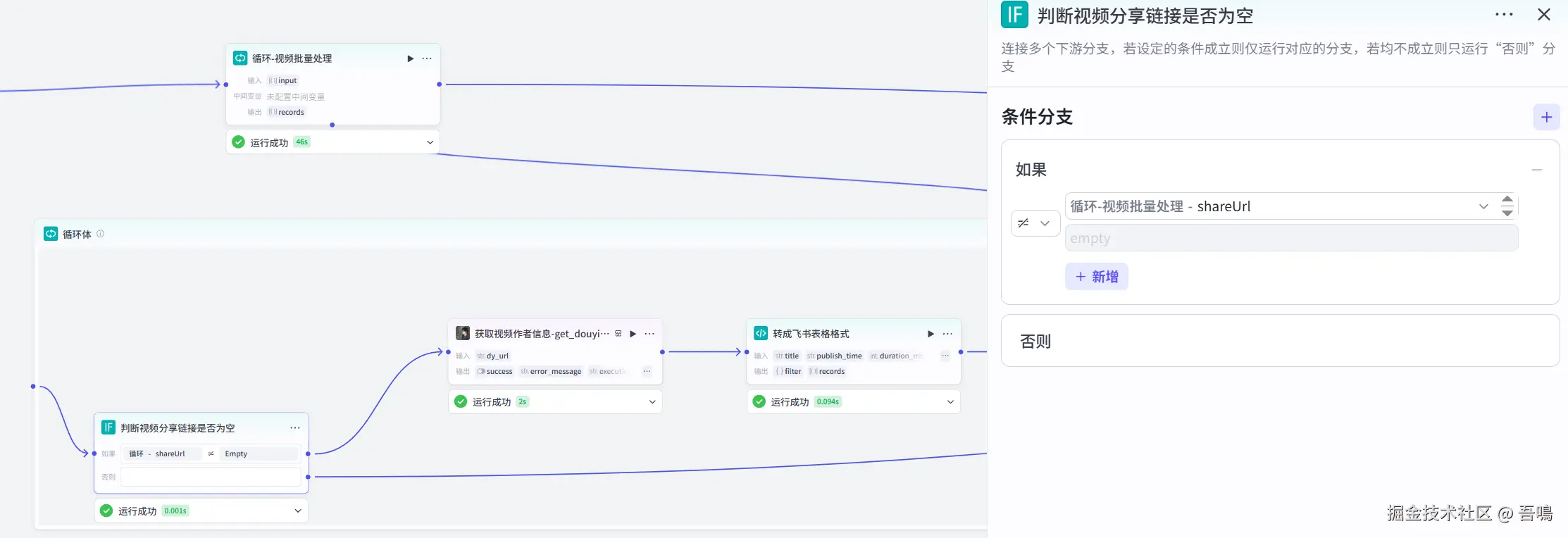
2.8. 获取视频作者信息
这个节点使用到了【抖音短视频链接信息提取_免费】插件的【get_douyin_info】工具,用于获取视频作者的粉丝数量、历史点赞数量等信息。
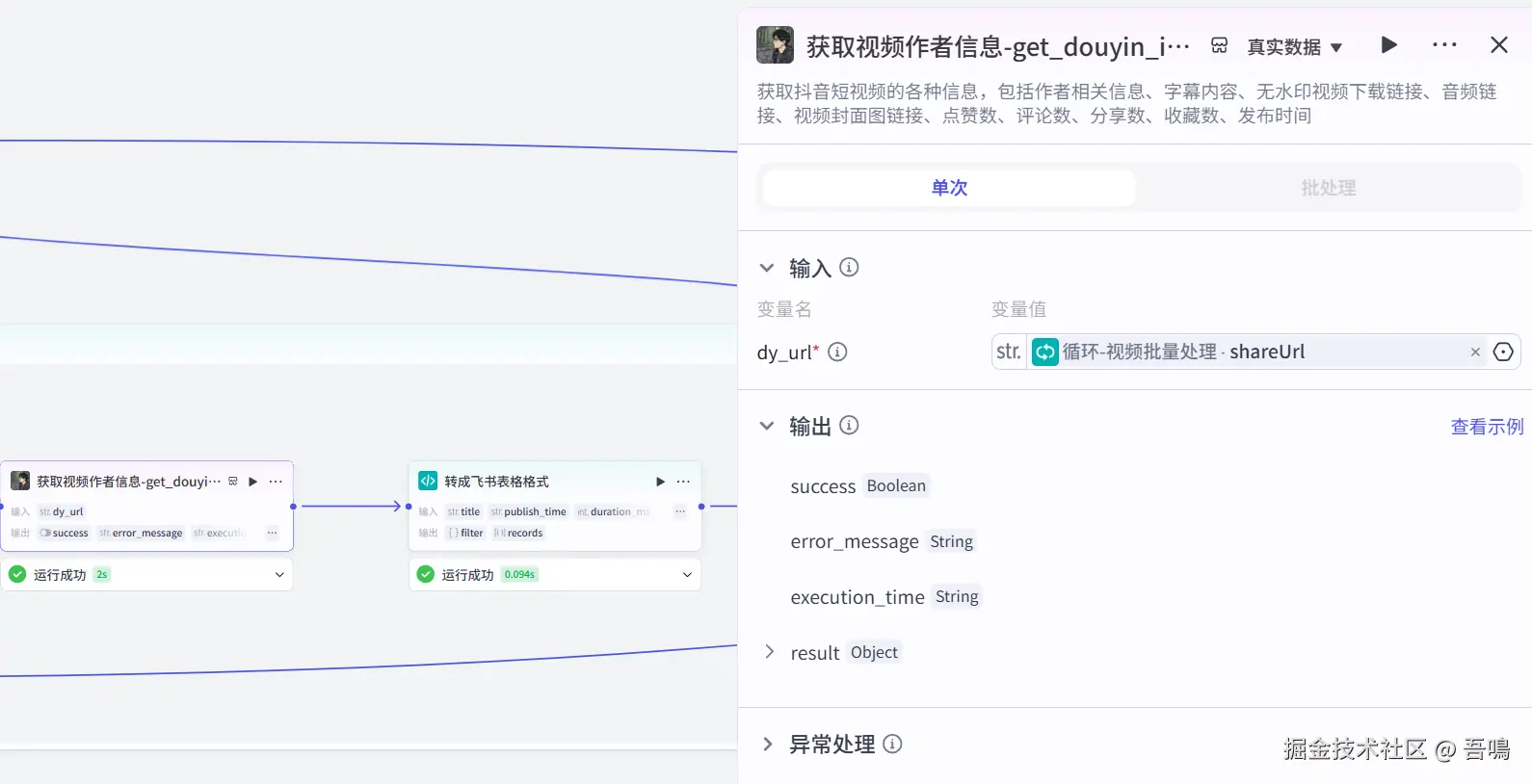
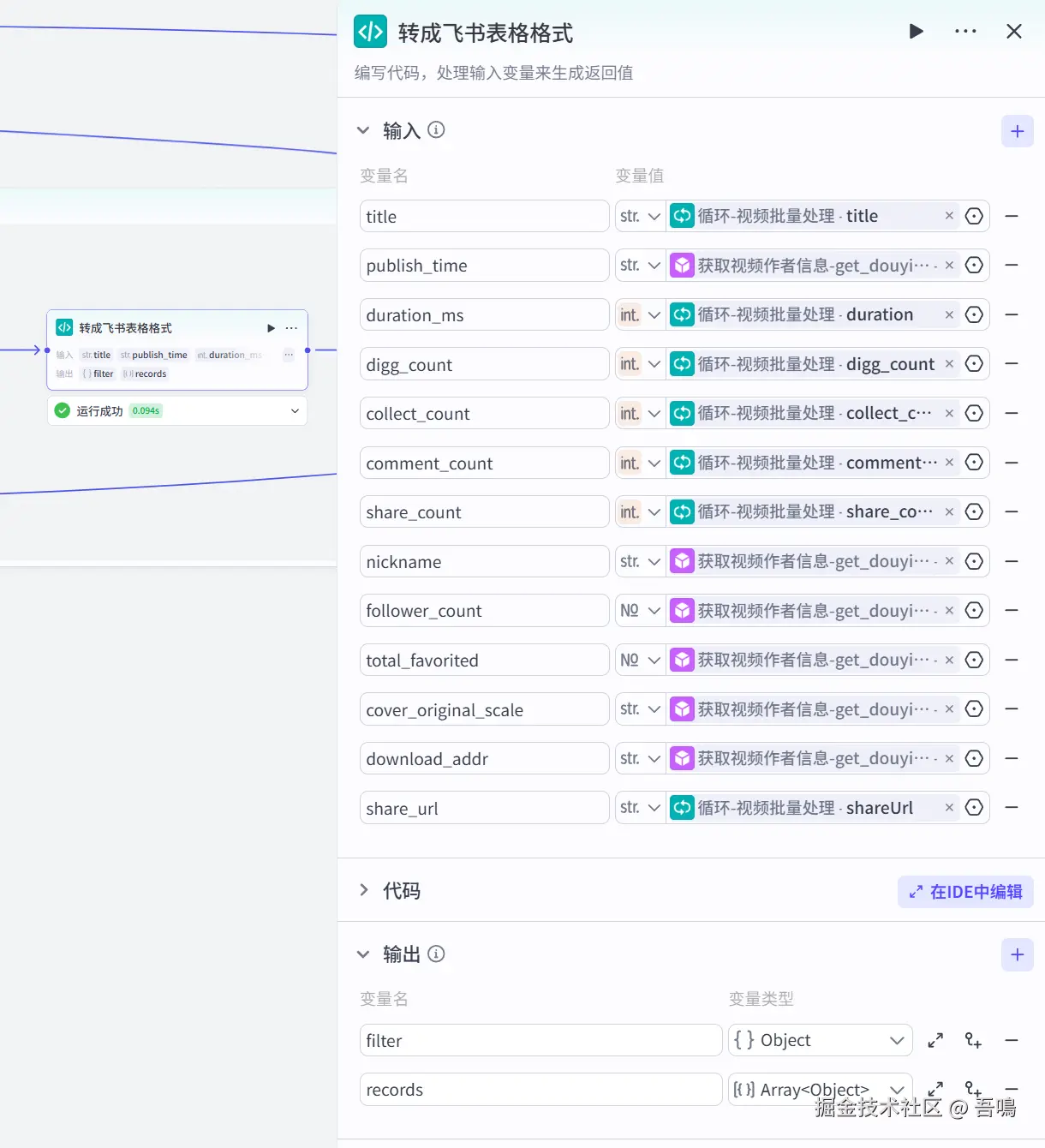
2.9. 转成飞书表格格式
这个是整个工作流中最复杂的节点了,用于把视频信息转换成飞书表格格式的数据,使用到了扣子官方的【代码】节点,主要的参数如下:
- 输入
-
- title:循环-视频批量处理 -> title
- publish_time:获取视频作者信息 -> formatted_time
- duration_ms:循环-视频批量处理 -> duration
- digg_count:循环-视频批量处理 -> digg_count
- collect_count:循环-视频批量处理 -> collect_count
- comment_count:循环-视频批量处理 -> comment_count
- share_count:循环-视频批量处理 -> share_count
- nick_name:获取视频作者信息 -> nickname
- follower_count:获取视频作者信息 -> follower_count
- total_favorited:获取视频作者信息 -> total_favorited
- cover_original_scale:获取视频作者信息 -> cover_original_scale
- download_addr:获取视频作者信息 -> download_addr
- share_url:循环-视频批量处理 -> share_url
- 输出
-
- filter:表格数据过滤条件
- records:写入表格数据
- 代码
ini
#author:吾鳴
#website:www.5mzy.com
from datetime import datetime
import hashlib
asyncdefmain(args: Args) -> Output:
params = args.params
title = params['title']
publish_time = params['publish_time']
duration_ms = params['duration_ms']
digg_count = params['digg_count']
collect_count = params['collect_count']
comment_count = params['comment_count']
share_count = params['share_count']
nickname = params['nickname']
follower_count = params['follower_count']
total_favorited = params['total_favorited']
cover_original_scale = params['cover_original_scale']
download_addr = params['download_addr']
share_url = params['share_url']
md5_obj = hashlib.md5()
md5_obj.update((nickname+title).encode('utf-8'))
shipin_id = md5_obj.hexdigest()
filter_data = {"conjunction": "and","conditions":[{"field_name":"视频ID","operator":"is","value":[shipin_id]}]}
records = [{"fields":{"视频ID": shipin_id, "视频标题": title, "发布日期": publish_time,
"视频时长(单位秒)": int(duration_ms/1000), "点赞数": digg_count, "收藏数": collect_count, "评论数": comment_count, "分享数": share_count, "作者昵称": nickname,
"作者粉丝量": int(follower_count), "作者点赞量": int(total_favorited),"视频封面":{"text": cover_original_scale,"link": cover_original_scale},
"视频下载链接":{"text": download_addr, "link": download_addr},"视频分享链接":{"text": share_url,"link": share_url},
"记录时间": datetime.now().strftime('%Y-%m-%d %H:%M:%S')}}]
# 构建输出对象
ret: Output = {
"filter": filter_data,
"records": records
}
return ret2.10. 查询数据是否存在
这个节点用于查询视频数据是否已存在表格中,使用到了【飞书多维表格】插件的【search_record】工具。
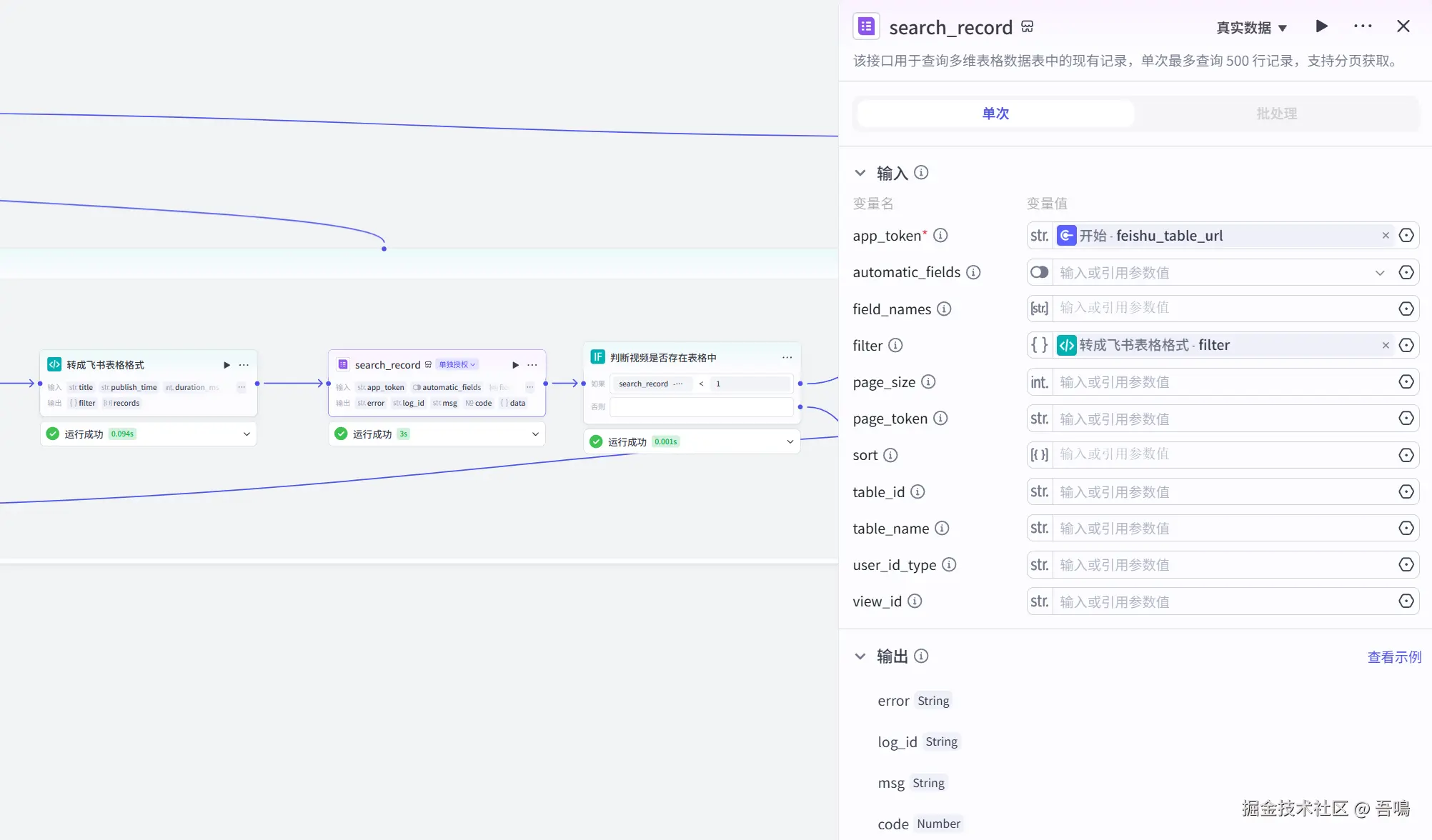
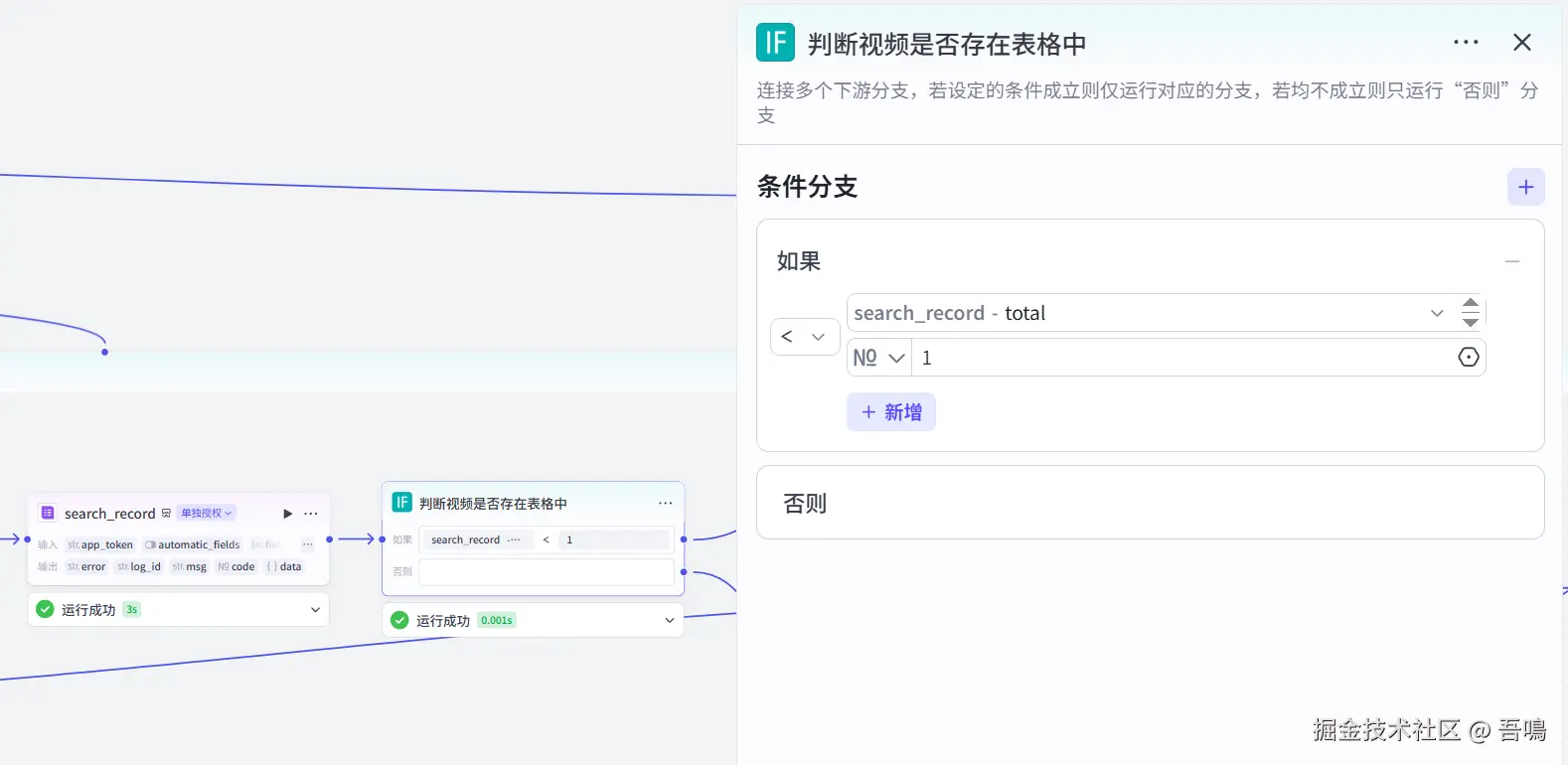
2.11. 判断视频是否存在表格中
这个节点使用到了扣子官方的【选择器】节点。用于判断视频是否存在于表格中,存在则更新表格数据,否则新增到表格中。
2.12. 添加视频到表格
这个节点使用到了【飞书多维表格】插件的【add_records】工具。
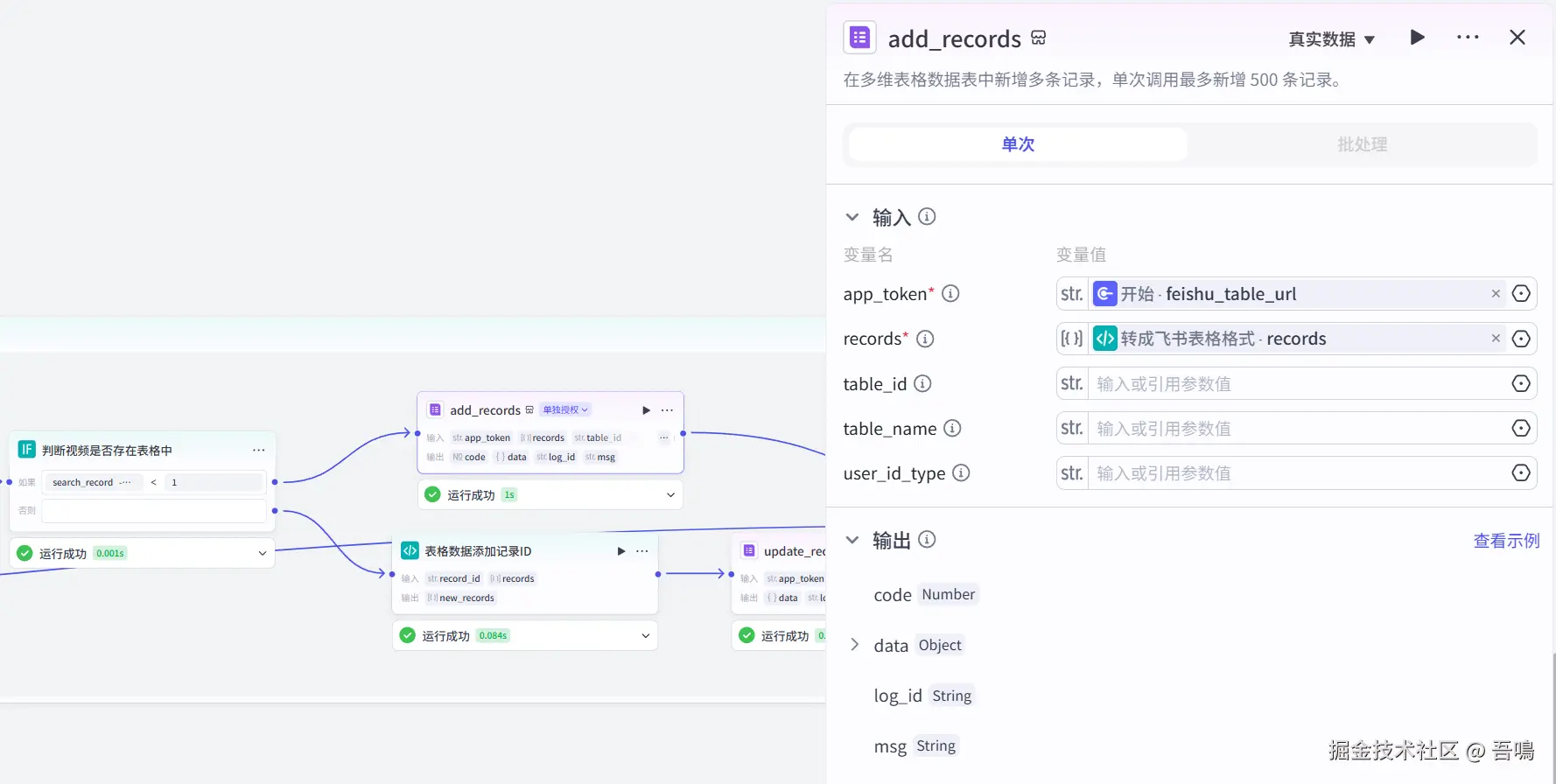
2.13. 表格数据添加记录ID
这个节点使用到了扣子官方的【代码】节点,用于把表格记录ID添加到数据中,便于做记录更新。
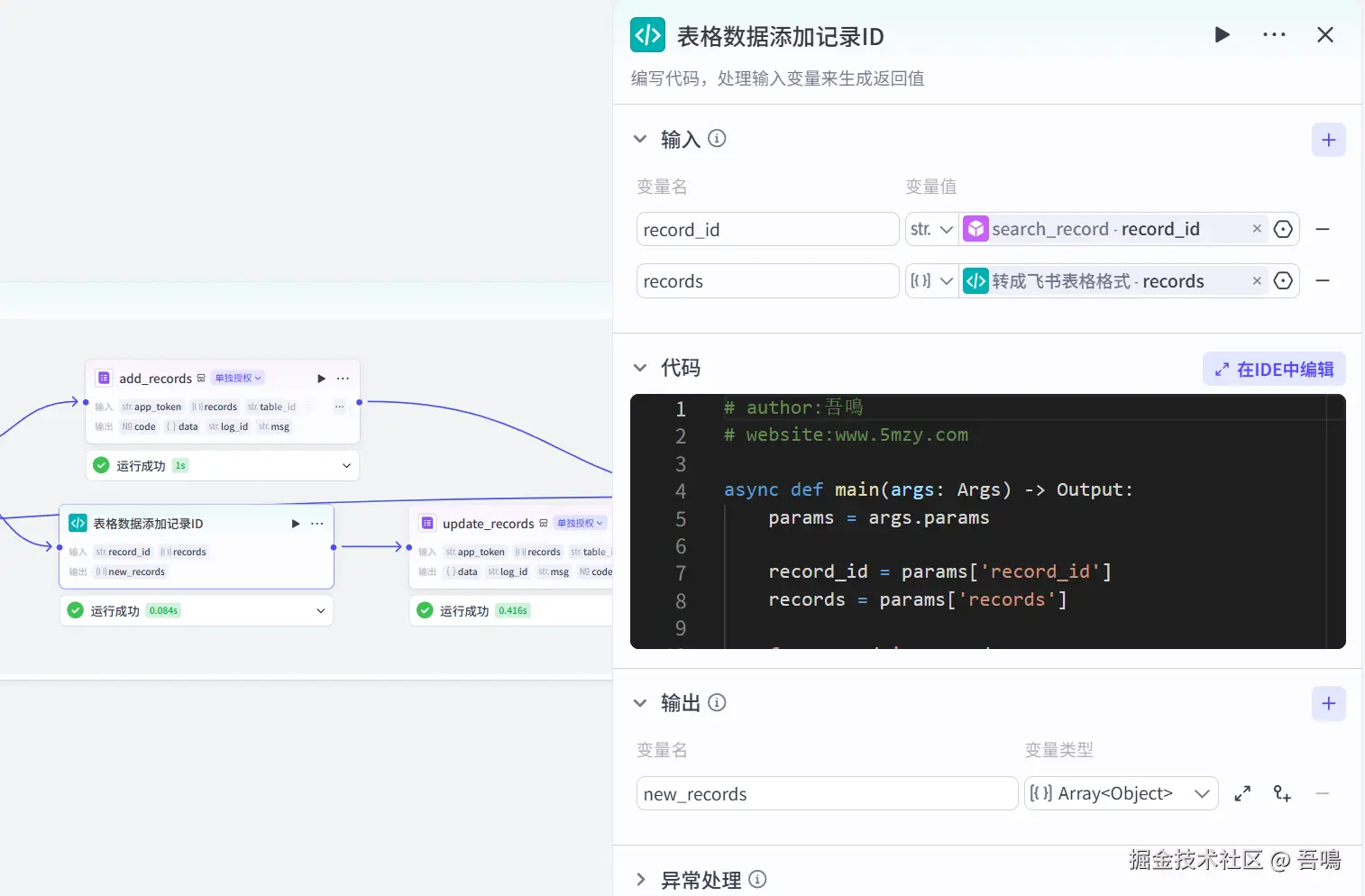
- 代码
csharp
# author:吾鳴
# website:www.5mzy.com
async def main(args: Args) -> Output:
params = args.params
record_id = params['record_id']
records = params['records']
for record in records:
record['record_id'] = record_id
# 构建输出对象
ret: Output = {
"new_records": records
}
return ret2.14. 更新表格记录
这个节点用于更新表格中的记录数据,因为点赞量等这些都是实时变化的,防止数据过于老旧。使用到了【飞书多维表格】插件的【update_records】工具。
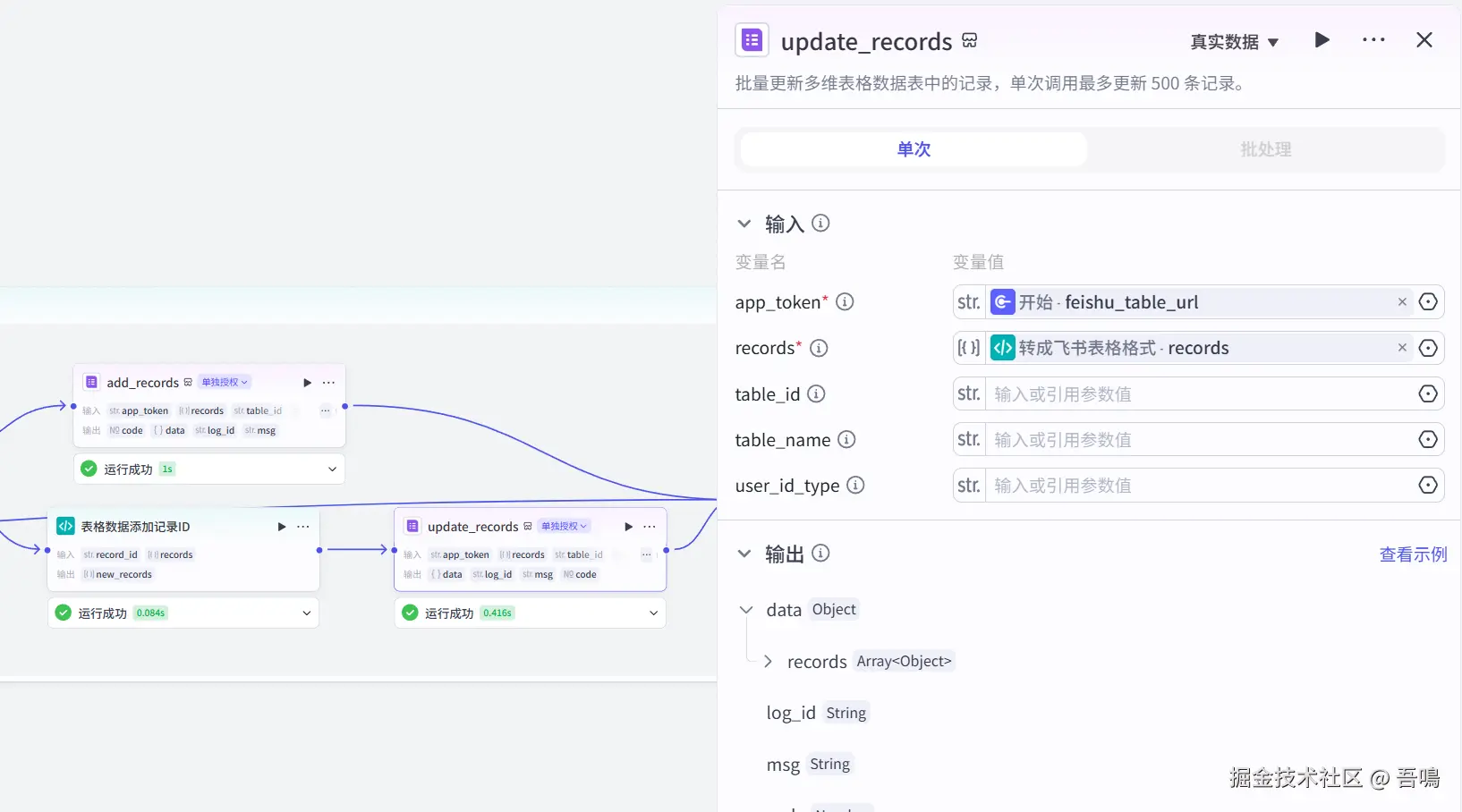
2.15. 结束
3. 智能体搭建
3.1. 新增智能体
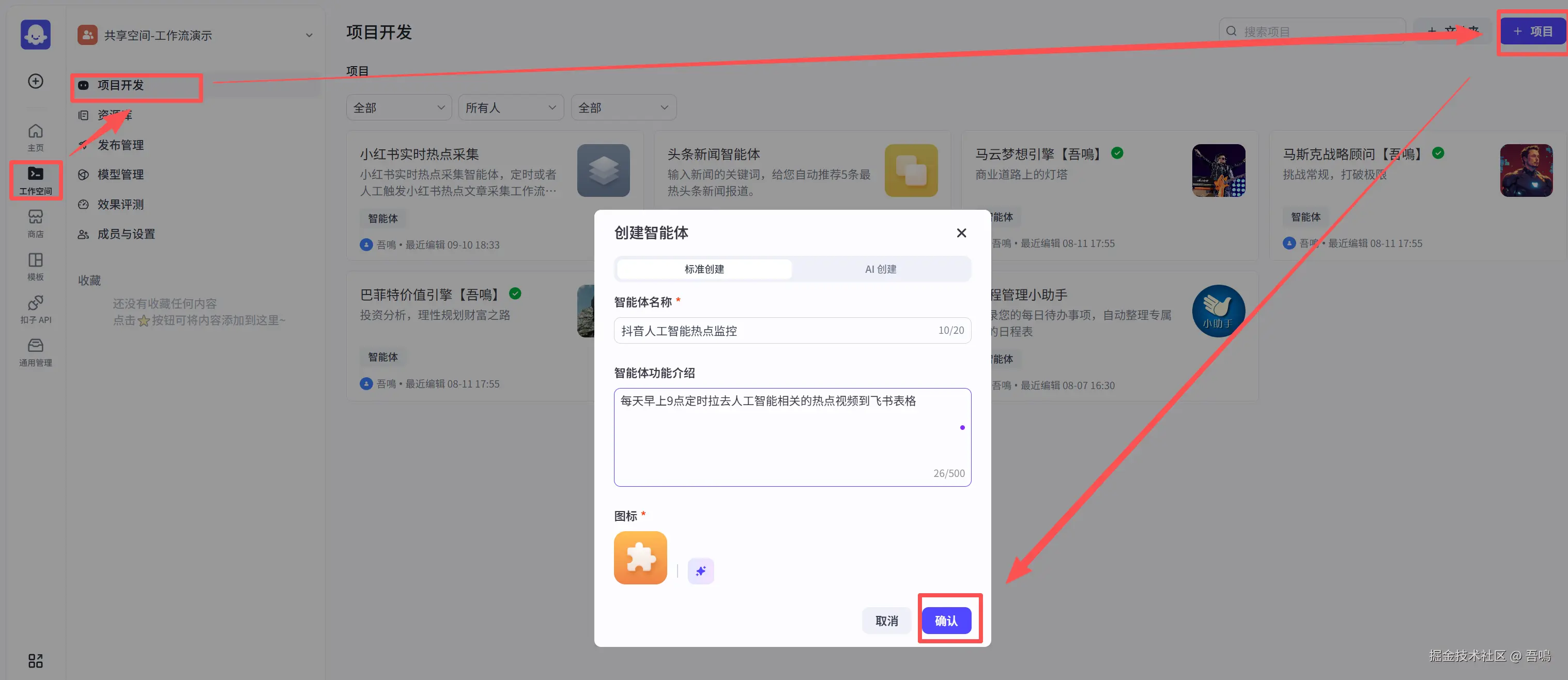
登录到扣子,工作空间-》项目开发-》+项目-》创建智能体。然后给智能体起个名字和描述,点击确认。
3.2. 添加触发器
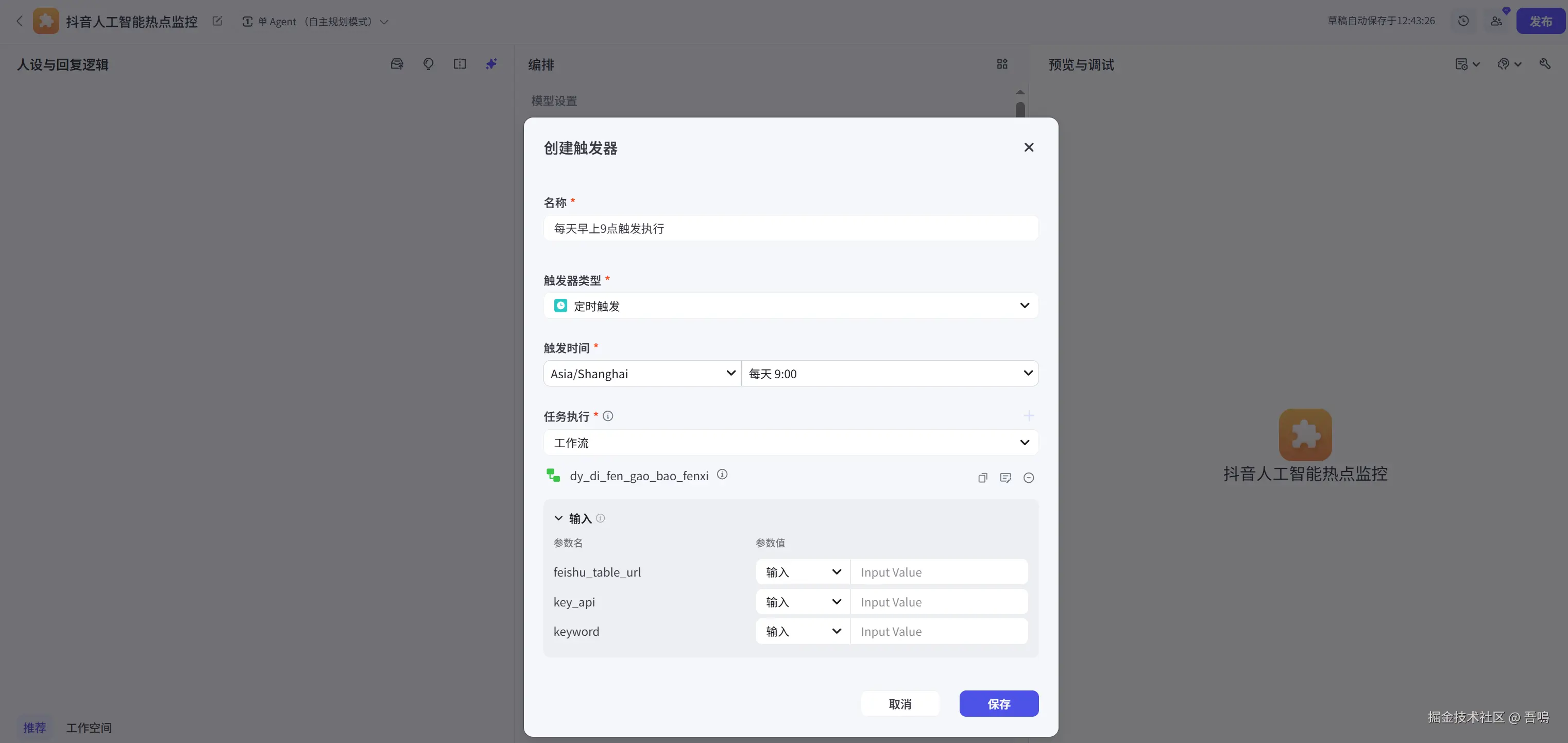
创建好智能体后,在智能体配置页面【技能】栏,选择添加触发器,选择每天9点触发,任务执行选择工作流。添加上工作流,并且设置上相应的工作流参数。
这里需要注意,需要把工作流先发布,这里才能选到相应的工作流。
3.3. 发布智能体
当我们把触发器配置好之后,就可以发布智能体了,直接点击右上角的发布按钮,与发布其他的智能体一样的流程,发布成功之后,抖音的热点就每天早上9点自动进行采集并写入到飞书,到这里你的抖音视频热点自动更新工具就弄好了。
4. 总结
本文开篇阐述了做抖音热点监控的痛点,人工操作繁琐,软件赋能昂贵等背景,然后本文介绍了如何使用扣子(Coze)来实现抖音热点的实时监控,详细的介绍了完整智能体的搭建过程,同时,文中详细的介绍了工作流的完整工作流程,并且对工作流中的每一个节点都做了详细的介绍和解读。
今天的分享就到这里,如果您觉得有收获的话,可以给个一键三连,您的鼓励是吾鳴持续输出的最大动力。有什么疑问也可以打在评论区,吾鳴会第一时间回复。

这个扣子工作流的源码、提示词都已经打包好,创作不易,感兴趣的朋友可以一键三连(必须动作) ,评论区评论"抖音热点监控" 领取。