- 对问题认识不清以及过度优化往往会让事情变得更加复杂,产生更多问题
- 在游戏开发过程中,从一开始就把优化当成是游戏设计中的一部分
- 优化不仅是程序员的工作,更需要美术人员在美术上进行一定的权衡。如
- 避免使用全屏屏幕特效
- 避免使用计算复杂的 shader
- 减少透明混合造成的 overdraw (一个像素被绘制多次)
- (等)
16.1 移动平台的特点
- 移动设备上的 GPU 架构专注于尽可能使用更小的带宽和功能
- 由于各 GPU 芯片架构不同,一些游戏往往需要针对不同芯片发布不同版本,以实现更有针对性的优化(尤其是安卓平台)
16.2 影响性能的因素
- 对于一个游戏来说,它主要使用两种计算资源:CPU 和 GPU
- 它们互相合作,来让游戏可在预期的
帧率和分辨率下工作 - CPU 主要负责保证帧率
- GPU 主要负责分辨率相关的
- 它们互相合作,来让游戏可在预期的
- 把造成游戏性能瓶颈的主要原因 分成以下几个方面
- CPU
- 过多的 draw call
- 复杂的脚本或物理模拟
- GPU
- 顶点处理
- 过多的顶点
- 过多的逐顶点计算
- 片元处理
- 过多的片元(分辨率或 overdraw 造成的)
- 过多的逐片元计算
- 顶点处理
- 带宽
- 使用了尺寸很大且未压缩的纹理
- 分辨率过高的帧缓存
- CPU
优化技术
- 对 CPU 来说,限制它的主要是每帧中的 draw call 数目
- 使用批处理减少 draw call 数量
- 对 GPU 来说,它负责整个渲染流水线
- 减少需要处理的顶点数量
- 优化几何体
- 使用模型的 LOD 技术
- 使用遮挡剔除技术
- 减少需要处理的片元数量
- 控制绘制顺序
- 警惕透明物体
- 减少实时光照
- 减少计算复杂度
- 使用 shader 的 LOD 技术
- 优化代码
- 减少需要处理的顶点数量
- 内在带宽
- 减少纹理大小
- 利用分辨率缩放
16.3 Unity 中的渲染分析工具
16.3.1 认识渲染统计窗口

- 相较于旧版本,去掉了 draw call 数目的显示,添加了批处理数目的显示(Batches 和 Saved by batching),更容易让开发者理解批处理的优化结果
- 想看 draw call 数目可通过性能分析器来查看
16.3.2 性能分析器的渲染区域
- 注意,性能分析器给出的 draw call 数目和批处理数目、Pass 数目并不相等。因为
- Unity 在背后需要进行很多工作,需要花费比"预期"更多的 draw call
16.3.3 再谈帧调试器
- 帧调试器的的调试面板上显示了渲染这一帧所需要的所有渲染事件
- 通过单击面板上每个事件,我们可以
- 在 Game 视图查看该事件的绘制结果
- 在渲染统计面板上看到截止到当前事件为止的统计数据
16.3.4 其他性能分析工具
- 对于 Android
- 高通的 Adreno
- 英伟达的 NVPerfHUD
- 对于 iOS
- Unity 内置的分析器可得到整个场景花费的 GPU 时间
- PowerVRAM 的 PVRUniSCo shader 分析器能给出大致的性能评估
- Xcode 中的 OpenGL ES Driver Instruments 可给出宏观上的性能信息
16.4 减少 draw call 数目
常见的就是批处理
- 原理:渲染一个包含了一千个三角形的网格,比渲染一千个三角形网格的速度要快很多
- 方法
- 使用同一材质的物体可进行批处理(它们之间的差别只在于顶点数据)
16.4.1 动态批处理
- 原理:每帧将满足批处理条件的模型网格进行合并,再传递给 GPU,然后使用同一个材质进行渲染
- 优点:处理后的物体可移动(每帧重新合并网格)
- 合并条件
- 网格
顶点属性规模小于 900(若每个顶点都包含位置、法线和纹理这 3 个属性,则顶点数不能超过 300) - 若使用了
光照纹理,需保证它们指向纹理中的同一位置 - 使用单 Pass 的 shader(多 Pass 的 shader 会中断批处理)
- 网格
- 合并网格操作会对 CPU 造成一定的负担
- 启用方式:
- Project Settings - Player - Other Settings 中的 Dynamic Batching
16.4.2 静态批处理
- 实现原理:只在运行开始阶段,把需要进行静态批处理的模型合并到一个新的网格中(意味着它们不能移动)
- 优点:只需要进行一次合并,比动态批处理高效
- 缺点:占用更多的内存来存储合并后的几何结构
- 若使用同一网格的对象很多(会在内存中生成对应数量复制品)
- 启用方式:
- Project Settings - Player - Other Settings 中的 Static Batching
- 把物体属性面板上的 Static 勾上
16.4.3 共享材质
- 若两个材质间只有使用的纹理不同,那可把这些纹理合并到一个更大的纹理中,它被称为
图集(atlas) - 若是材质上的参数不一样,就需要用到网格的顶点数据(不是材质属性面板上的)来存储这些参数了
16.4.4 批处理的注意事项
- 优先使用静态批处理,但要注意内存消耗和物体的移动限制
- 要使用动态批处理的话,注意各种条件限制,让这样的物体数量、物体顶点数量和顶点属性尽量少
- 小道具(顶点数少),可使用动态批处理
- 包含动画的物体,其不动的部分,使用静态批处理
16.5 减少需要处理的顶点数目
16.5.1 优化几何体
- 美术人员需负责对模型网格进行优化
- Unity 中显示的模型顶点数,往往要多于 3D 建模软件中显示的顶点数
- 一个顶点被多个面共享(如立方体的顶点被 3 个面共享),GPU 需要将它拆分为多个顶点,以保存与各面关联的顶点属性
- 最后一条优化建议:移除不必要的硬边及纹理衔接,避免边界平滑和纹理分离
16.5.2 模型的 LOD 技术
- 根据物体与摄像机的距离,动态切换不同精度的网格
16.5.3 遮挡剔除技术
- 用来消除在其他物体后面看不到的物体(摄像机视锥体剔除是剔除掉视锥体以外的物体)
16.6 减少需要处理的片元数目
- 重点在减少 overdraw(同一个像素被绘制了多次)
16.6.1 控制绘制顺序
- 若可以保证物体都是从前往后绘制的,那么就可以很大程度上减少 overdraw
- 渲染不透明物体的渲染队列(如"Background""Geometry"和"AlphaTest)",它们总体上是从前往后绘制的
- 其他队列(如"Transparent"和"Overlay"等),物体则是从后往前绘制的
- 充分利用 Unity 的
渲染队列来控制绘制顺序。拿 FPS 举例- 先绘制主要角色,因为它们使用的 shader 往往比较复杂,且占据大部分屏幕
- 在所有常规不透明物体渲染后,渲染敌方角色,因为它们通常在掩体后面
- 对于天空盒,它永远出现在所有物体后面,因此将它的队列设置为 Geometry+1
16.6.2 时刻警惕透明物体
- 由于渲染半透明对象没有开启深度写入,因此必须从后往前渲染,这意味着一定会造成 overdraw
- 常见场景:大面积半透明 GUI、很多层相互覆盖的半透明物体、透明粒子效果
- 对于 GUI
- 减少窗口中 GUI 所占面积
- 独立摄像机负责绘制
16.6.3 减少实时光照和阴影
- 过多的点光源,且使用了多个 Pass 的 Shader,对移动平台的性能影响非常大
- 很多画面效果看起来包含很多光源的成功游戏作品,其实都是使用一些技巧来骗过我们的眼睛(并没有真正使用光源)
烘焙:把光照提前烘焙到一张光照纹理(lightmap)中,运行时根据纹理采样得到光照结果God Ray:专门模拟小型光源,往往是通过透明纹理模拟得到
- 实时阴影对性能消耗也非常大,优化措施
- 使用烘焙把静态物体的阴影信息存储到光照纹理中
- 只对场景中的动态物体使用适当的实时阴影
16.7 节省带宽
16.7.1 减少纹理大小
-
所有纹理的最好是正方形,且长宽值最好是 2 的整数幂
-
应该尽可能使用
多级渐远纹理技术(mipmapping)和纹理压缩 -
mipmapping 启用方法
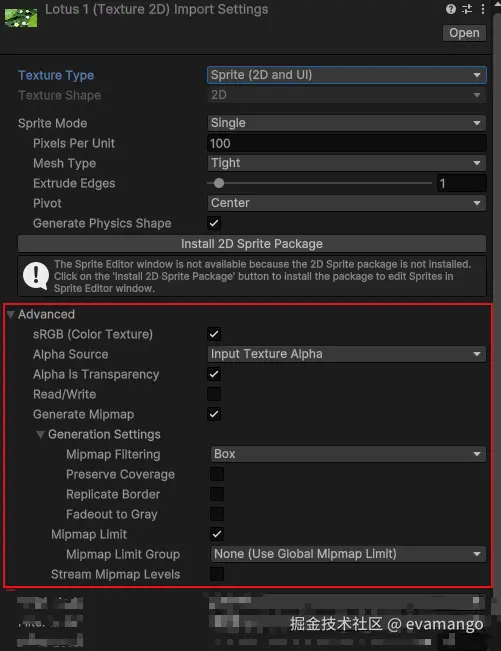
-
纹理压缩
- 安卓平台下有很多不同的 GPU 架构,对应有不同的纹理压缩技术
- Unity 可以根据不同的设备选择不同的压缩格式,我们只需要将纹理压缩格式设置为自动压缩即可
- GUI 的纹理由于对画质的要求,通常不进行压缩
16.7.2 利用分辨率缩放
16.8 减少计算复杂度
16.8.1 Shader 的 LOD 技术
-
Shader 的 LOD 技术可以控制使用的 Shader 等级
-
原理:只有 Shader 的 LOD 值小于某个设定的值,这个 Shader 才会被使用,而使用了那些超过设定值的 Shader 的物体将不会被渲染
-
使用方法:通常在 SubShader 中指明该 shader 的 LOD 值
jsSubShader { Tags { "RenderType"="Opaque" } LOD 200
16.8.2 代码方面的优化
- 游戏需要计算的对象、顶点和像素数目通常的排序是:对象 < 顶点 < 像素,因此尽可能将计算放在对象或逐顶点上
- 尽可能使用低精度的浮点数来计算
高精度数值 float/highp: 适用于存储诸如顶点坐标等变量,但它的计算速度是最慢的,尽量避免在片元着色器中使用高精度进行运算half/midiump:适用于一些标量、纹理坐标等变量fixed/lowp:适用于绝大多数颜色变量和归一化后的方向矢量
- 尽量避免在不同精度之间进行转换
- 尽可能不要使用全屏的屏幕后处理效果
- 尽量把多个特效合并到一个 Shader 中
- 其他常用
- 尽可能不要使用分支和循环语句
- 尽可能避免使用类似 sin、tan、pow、log 等较复杂的数学运算(用查表替代)
- 尽可能不要使用 discard 操作,这会影响硬件的某些优化
16.8.3 根据硬件条件进行缩放
16.9 扩展阅读
- 移动平台优化实践指南 (链接)