在一次SaaS系统分表设计中,我发现并非所有场景都需要复杂的分布式ID方案,这引发了我对分布式ID生成技术的深入思考。
前言:一个出乎意料的分表方案
最近在负责公司SaaS化系统的分表改造时,遇到了一个有趣的问题:如何为分表后的数据生成唯一ID?
按照常规思路,我们首先想到的就是引入一套分布式ID生成系统,比如雪花算法或者美团Leaf。但在深入分析业务场景后,我们发现了一个值得深思的现象:并不是所有分表场景都需要复杂的分布式ID方案。
我们的SaaS系统服务于多个店铺,每个店铺的数据完全隔离,不存在跨店铺查询或者表连接的需求。对于订单、商品这类非核心数据,我们并不担心自增ID会暴露业务总量。于是,我们采用了这样的方案:直接使用"公司ID"或"店铺ID"作为分表键,然后在每个分片内使用数据库自增ID。
这种设计简单有效,完全满足业务需求,避免了引入分布式ID系统的复杂性。但这个特例也让我意识到,分布式ID生成确实是一个值得深入探讨的技术话题。在一些需要全局唯一ID或者无法使用上述简化方案的场景中,我们仍然需要一套完善的分布式ID解决方案。
那么,一个优秀的分布式ID生成系统应该满足哪些要求呢?
- 全局唯一:必须保证在任何情况下都不会出现重复ID
- 高性能高可用:需要支撑高并发场景,且不能有单点故障
- 趋势递增:生成的ID最好保持递增趋势,这对数据库索引友好
- 容灾性:在部分节点故障时,仍能正常提供服务
- 信息安全(可选):ID中不应包含可能暴露业务量的敏感信息
接下来,让我们系统性地了解几种常见的分布式ID生成方案,并重点剖析美团Leaf的巧妙设计。
一、常用分布式ID方案深度解析
1. 数据库不同步长自增
这是最直观的一种分布式数据库ID生成方案,适合刚刚开始分库分表的场景。
实现原理: 部署多台数据库实例,每台设置不同的自增起始值和相同的自增步长:
- 数据库DB1:
auto_increment_offset = 1,auto_increment_increment = 3→ 生成ID: 1, 4, 7, 10... - 数据库DB2:
auto_increment_offset = 2,auto_increment_increment = 3→ 生成ID: 2, 5, 8, 11... - 数据库DB3:
auto_increment_offset = 3,auto_increment_increment = 3→ 生成ID: 3, 6, 9, 12...
优点:
- 实现简单,基于现有数据库能力,改造成本低
- ID为数字类型且保持自增特性
缺点:
- 扩展性极差:一旦初始步长设定,后续增加数据库节点需要重新规划,操作复杂
- 数据库压力大:每次生成ID都需要数据库IO操作,高并发下容易成为性能瓶颈
- 强依赖数据库:数据库的可用性直接影响整个系统的可用性
- 信息安全风险:连续的自增ID会暴露业务增长量,存在安全隐患
适用场景:小型项目,数据库数量固定且并发量不高的场景
2. 数据库号段模式
这是对数据库自增方案的优化,核心思想是"批量取号",减轻数据库压力。
工作原理:
- 服务不是每次生成ID都访问数据库,而是一次性获取一个号段(如1~1000)
- 这个号段范围内的ID加载到服务内存中,后续请求在内存中分配
- 当号段用尽后,再去数据库获取下一个号段
优点:
- 大幅降低数据库压力,提升性能
- 保持ID的递增特性
缺点:
- 需要额外维护号段表
- ID不是严格连续,号段耗尽未使用会造成ID"空洞"
3. UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000,有多种版本实现。(版本号由第三个段落的第一个字符表示)
Java中的UUID生成 : Java提供了java.util.UUID类,最常用的是基于随机数的UUID Version 4:
java
// 生成基于随机数的UUID (version 4)
UUID uuid = UUID.randomUUID();
String uuidString = uuid.toString(); // 示例: "f47ac10b-58cc-4372-a567-0e02b2c3d479"其他版本包括:
- Version 1:基于时间戳和MAC地址
- Version 3:基于命名空间和MD5哈希
- Version 5:基于命名空间和SHA-1哈希
优点:
- 本地生成,无网络消耗,性能极高
- 全局唯一性保证,理论上不会重复
缺点:
- 存储空间大:作为主键时索引占用空间大
- 内存消耗高:较大的ID尺寸会导致数据库主键索引和二级索引消耗更多内存
- 完全无序:随机生成的UUID导致数据库插入时频繁发生页分裂与页合并,严重拖慢写入性能
- 可读性差:无法从中获取任何业务意义
适用场景:对性能要求极高且不需要建索引的场景,如日志TraceID、临时令牌等
4. 雪花算法(Snowflake)
Twitter开源的经典方案,巧妙解决了UUID无序的问题。 结构如下图(图片来自网络)所示:

算法结构: 雪花算法将一个64位的Long型ID划分为几个部分:
- 1位符号位:恒为0,保证ID为正数
- 41位时间戳:精确到毫秒,可表示约69年的时间范围(计算方式:(2^41)/(1000×60×60×24×365) ≈ 69)
- 10位工作机器ID:最多支持1024个节点,可根据业务需求灵活分配
- 12位序列号:同一毫秒内产生的序列号,支持每毫秒生成4096个ID
灵活分配示例: 如果我们有机房划分需求,可以将10位工作机器ID进一步拆分:
- 5位给IDC机房:最多支持32个机房
- 5位给工作机器:每个机房最多支持32台机器
这种分配方式保证了任何一个机房的任何一台机器在任意毫秒内生成的ID都是不同的。理论上,单个Worker使用雪花算法的QPS可达409.6万/秒(1000ms × 4096/ms),完全满足绝大多数高并发场景。
优点:
- 本地生成,无网络消耗,性能极高
- ID趋势递增,对数据库索引友好
- ID中隐含时间信息,便于后期分析
缺点:
- 时钟回拨问题:如果机器时钟发生回拨,可能导致生成重复ID
- 需要维护Worker ID:需要保证每个节点的Worker ID全局唯一
时钟回拨问题:是指当计算机的硬件时钟因同步(如NTP校准)或手动调整而突然跳回到之前的某个时间点时,会导致严重依赖系统时间的应用程序产生重复的时间戳或ID,从而破坏其预期的唯一性和递增顺序。
注意⚠️:雪花算法生成ID是趋势递增,而非严格递增
- 在同一个Worker节点上:同一毫秒内生成的ID,序列号递增,是严格递增的。
- 跨多个Worker节点 :主要在于不同工作节点的时钟偏差 ,导致生成的ID无法保证与真实的时间顺序完全一致,只能是趋势递增。这对于绝大多数应用(如MySQL InnoDB主键)来说已经完全足够,因为它能避免频繁的B+树中间插入,从而减少页分裂。
根本原因在于:它是一个去中心化、无协调的分布式系统,无法保证所有工作节点(Worker)的时钟绝对同步和请求处理的绝对时序。
二、美团的王牌方案:Leaf
美团点评面对庞大的业务体量,在Snowflake的基础上自主研发了Leaf分布式ID生成服务。Leaf提供了Leaf-segment 和Leaf-snowflake两种模式来满足不同业务场景的需求。
- Leaf-segment模式:支持双号段缓存,避免了请求毛刺的问题
- Leaf-snowflake模式:解决了雪花算法的时钟回拨、ID非严格递增的问题。
Leaf这个名字的灵感来源于德国哲学家莱布尼茨的名言:"There are no two identical leaves in the world"(世界上没有两片相同的树叶),寓意着生成的ID全局唯一,文艺又贴切。
1. Leaf-segment 模式(数据库号段模式优化版)
这是对传统数据库号段模式的增强,通过双Buffer机制优化性能。 话不多说,直接看图(图片来自于美团官方文章)
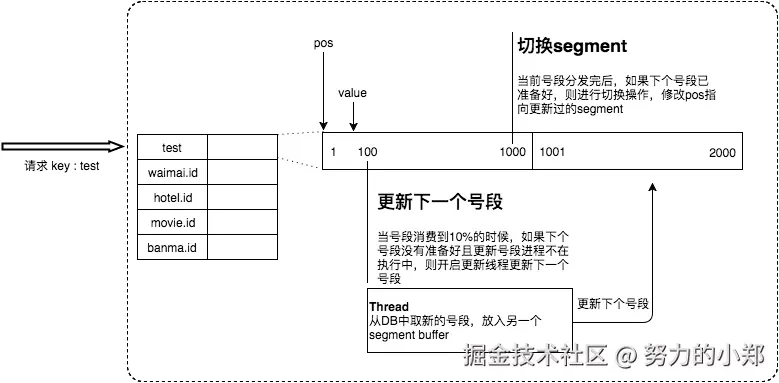
工作原理:
- Leaf服务不是每次生成ID都访问数据库,而是一次性获取一个号段(如1~1000)
- 号段范围内的ID加载到Leaf服务的内存中,后续请求在内存中分配
- 引入双Buffer机制:当一个号段用到一定比例(如10%)时,异步预取下一个号段
- 号段用尽后无缝切换到已预取的号段,避免请求毛刺
优点:
- 性能极致:99.9%的请求在内存中完成,QPS可达百万级
- 平滑过渡:双Buffer机制避免号段切换时的性能毛刺
- 容灾性好:即使数据库短暂宕机,依靠内存中的剩余号段,仍能保持一段时间内不受影响
- ID递增:ID为趋势递增的数字,对数据库友好
缺点:
- ID不是严格连续递增,号段耗尽未使用会导致ID"空洞"
- 仍然需要依赖数据库,不过压力大幅降低
2. Leaf-snowflake 模式(改进雪花算法)
Leaf-snowflake 模式流程图 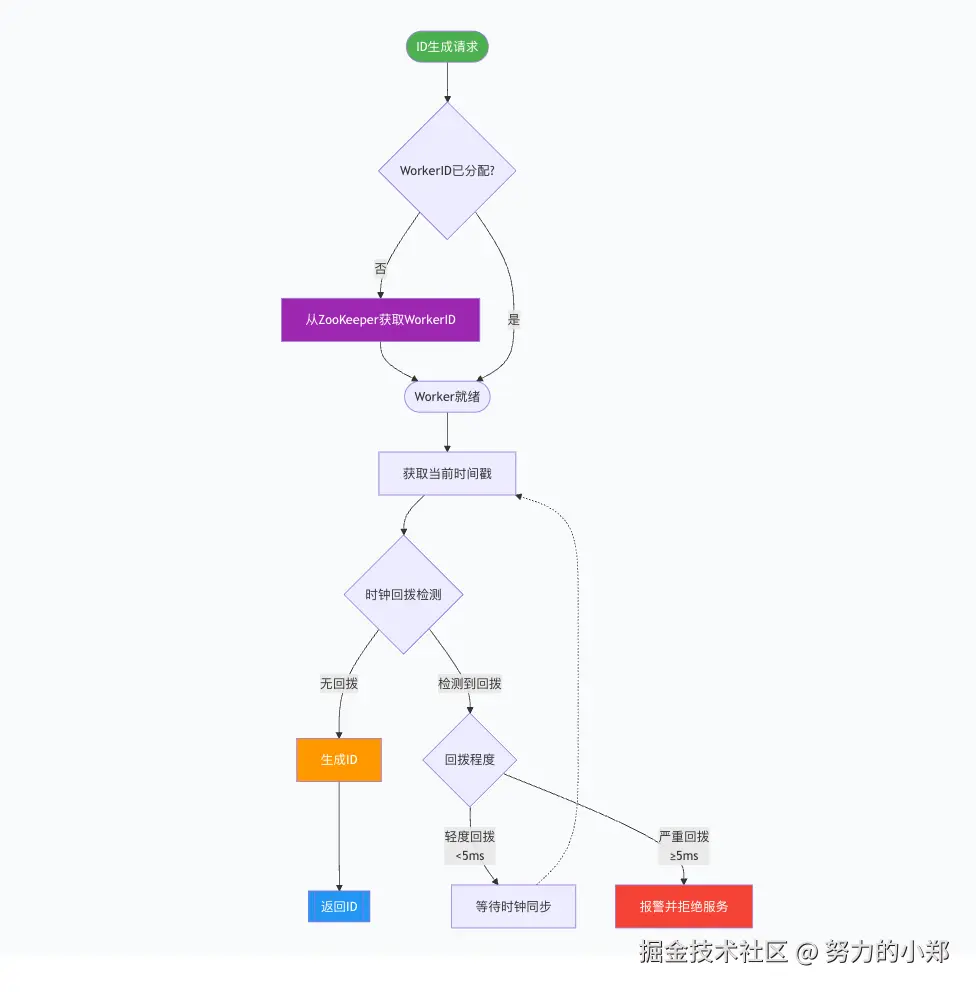
Leaf在原生Snowflake算法上最大的贡献是彻底解决了时钟回拨问题 。除此之外还有一点通常容易被忽视:通过中心化的ZooKeeper严格管理所有工作节点的时钟状态。
工作原理:
- WorkerID动态分配:Leaf服务启动时,通过ZooKeeper分配全局唯一的WorkerID
- 处理时钟回拨 :
- 轻度回拨(< 5ms):等待时钟追上来,然后再继续工作
- 严重回拨 (> 5ms):Leaf直接拒绝服务 并报警,通知人工介入
优点:
- 完全分布式,不依赖中心数据库,性能高
- ID严格单调递增
- 彻底解决时钟回拨痛点,方案更加健壮可靠
缺点:
- 弱依赖ZooKeeper(作为注册中心管理WorkId),系统复杂度增加
- 生成速度理论上不如Leaf-segment模式
注意⚠️Leaf-snowflake生成的ID是实现全局严格递增的。
主要原因在于其通过中心化的ZooKeeper协调器 ,严格管理所有工作节点的时钟状态,主动监测并杜绝了时钟回拨 的可能性,并顺序分配Worker ID,从而确保了ID生成的全局严格时序。
三、方案对比总结
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 数据库不同步长 | 实现简单,ID递增 | 扩展性差,暴露业务信息 | 小型项目,节点数固定 |
| 数据库号段 | 降低DB压力,趋势递增 | 需要维护号段表,ID不连续 | 中型项目,可接受少量数据库依赖 |
| UUID | 本地生成,性能高,全局唯一 | 无序,存储大,影响索引性能 | 日志TraceID、临时令牌 |
| Snowflake | 性能高,趋势递增,含时间信息 | 有时钟回拨问题,需管理WorkerID | 并发量适中的分布式系统 |
| Leaf-segment | 性能极致,容灾性好,趋势递增 | 依赖DB,ID不连续 | 高并发、海量数据的业务 |
| Leaf-snowflake | 严格递增,无中心DB依赖,解决时钟回拨 | 依赖ZK,复杂度高 | 对ID递增有严格要求的系统 |
完全依赖数据库自增生成的分布式ID的方案,都有存在暴露业务增长信息的风险。例如:数据库不同步长 、数据库号段 、Leaf-segment 。最简单的解决方法就是可以为号段设置一个巨大的随机起始偏移量来处理。
结尾与思考
通过这次分表实践,我深刻认识到技术方案的选择必须结合具体业务场景。对于像我们这样店铺数据完全隔离的SaaS系统,使用"店铺ID+数据库自增ID"的简单方案完全足够,避免了过度设计。
然而,在需要真正全局唯一ID的场景中,分布式ID生成方案的选择就需要慎重考虑了。每种方案都有其适用场景和优缺点:
- 初创项目或中小型系统可以从数据库号段 或Snowflake开始
- 超高并发场景下,Leaf-segment的思路非常值得借鉴
- 对ID单调递增有严格要求且基础设施完善的系统,Leaf-snowflake是更优选择
其实分布式ID生成并不神秘,其核心就是在性能、可用性和业务需求间寻找平衡。