本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
一、为什么需要RAG

可以将大语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。不幸的是,这种态度会对用户的信任产生负面影响,这是不希望聊天机器人效仿的!
我们将大模型用于实际的业务时候,会发现通用的基础大模型基本无法满足我们实际的业务需求,经过实践主要有以下几个方面:
- 知识的局限性:大模型对于一些具有实时性、非公开或者离线的数据是无法获取的
- 幻觉问题:当大模型不具备某一领域的知识或者有不擅长的场景时,就会出现幻觉问题,简言之就是开始一本正经的胡说八道。
- 数据安全性:数据是一个企业至关重要的东西,没有企业愿意承担数据泄露的风险
RAG 是解决其中一些挑战的一种方法。它会重定向 LLM,从权威的、预先确定的知识来源中检索相关信息。组织可以更好地控制生成的文本输出,并且用户可以深入了解 LLM 如何生成响应。
二、什么是RAG
2.1 RAG的概念
比较官方的概念就是:Retrieval-Augmented Generation(检索增强生成)是一种结合了检索模型和生成模型的AI技术,它能让大型语言模型(LLM)在回答问题或生成文本时,先从外部的知识库(如公司内部文档或数据库)检索相关信息,再将这些信息整合到生成过程中,从而生成更准确、更相关、更新鲜的答案,而无需重新训练或微调整个模型。
下面我们来拆解一下RAG的概念:
- Retrieval - 检索模型:将用户的Prompt首先Embedding,然后和向量数据库中的上下文进行对比,相似性搜索,找到向量数据库中最匹配的前k个数据。核心就是两部分。
- 建立索引:将知识库转换为可搜索/查询的内容,建立相关索引。
- 执行查询:从搜索内容中提取最相关的,最佳知识片段。
- Augmented - 增强:将用户的Prompt和检索到的相关信息,一起嵌入到一个预设的提示词模板中。
- Generate - 生成模型:最终将增强后的Prompt输入给LLM。
2.2 RAG的特点
RAG通过以下几个特点来弥补单纯的语言模型:
- 信息检索: RAG使用检索系统(比如Elasticsearch)来从大规模数据集中检索相关文档或数据。
- 上下文融合: 将检索到的信息和原始的问题或输入融合,构造一个扩展的上下文。
- 知识增强:通过上下文融合,模型可以利用外部检索到的知识来指导生成过程,这可以显著减少"幻觉"。
- 快速更新:实施RAG需要矢量数据库等技术,这些技术可以快速编码新数据,并搜索该数据以输入给LLM模型。
- 灵活性: RAG模型可以与不同的检索库和不同的语言模型结合使用。
- 不需要训练:RAG可以通过查询最新的外部数据源来处理频繁变化的数据,不需要训练,模型大小不会产生变化。
2.3 RAG 主要组成
RAG的主要组成,分别是:数据提取 - embedding(向量化) - 创建索引 - 检索 - 自动排序 - Rerank - LLM归纳生成。
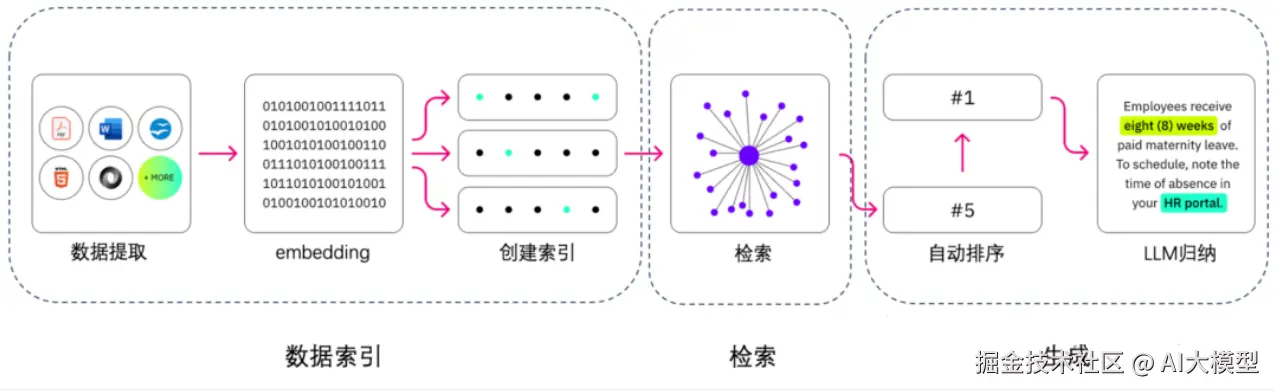
RAG就是让大模型进行开卷考试,如果大家准备的资料都差不多,那么我们怎么在有限的时间内,能够取得优异的成绩呢?
- 准备的资料准确:如果答案都是错误的,写上去也是错误的
- 准备的资料充分:考的全是资料上面的,自然正确率是非常高的
上面的要求也是我们在建立RAG知识库时候需要注意的地方。
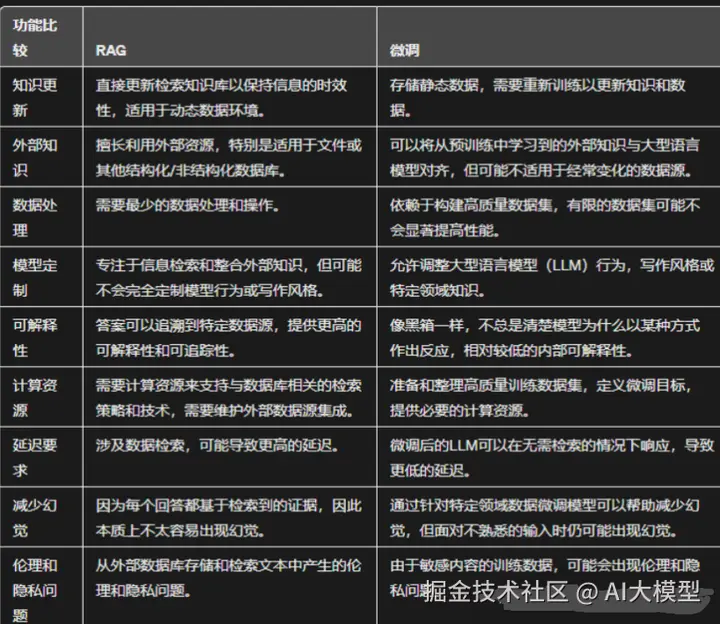
三、RAG 和 Fine-tuning 的区别
Fine-tuning(微调):是指用一定的数据集对LLM进行局部参数调整,需要进行训练,以期望LLM理解我们的业务逻辑,有更好的 zero-shot (零样本)能力。简而言之:让大模型通过学习,内化知识。
RAG(检索增强生成):是指把文档先进行embedding(向量化),借助检索先得到大致的知识范围答案,将用户输入的Prompt和检索得到的答案一起给到LLM,让LLM生成最终答案。简而言之:让大模型可以开卷考试。
添加图片注释,不超过 140 字(可选)
四、RAG 未来的趋势
检索增强生成的未来趋势集中在使 RAG 技术更高效、更适应各种应用。 以下是一些值得关注的趋势:
- 个性化:RAG 模型将继续纳入用户特定的知识。 这将使他们能够提供更加个性化的响应,特别是在内容推荐和虚拟助理等应用程序中。
- 可定制的行为:除了个性化之外,用户本身还可以更好地控制 RAG 模型的行为和响应方式,以帮助他们获得所需的结果。
- 可扩展性:RAG 模型将能够处理比目前更大量的数据和用户交互。
- 混合模型:RAG 与其他人工智能技术(例如强化学习)的集成将允许更通用和上下文感知的系统,可以同时处理各种数据类型和任务。
- 实时、低延迟部署:随着 RAG 模型检索速度和响应时间的提高,它们将更多地用于需要快速响应的应用程序(例如聊天机器人和虚拟助手)。
五、OceanBase 实战
5.1 OceanBase 介绍
该项目是基于 langchain、langchain-oceanbase 和 streamlit 构建,处理流程是先将 OceanBase 数据库的文档,通过 Embedding 模型转化为向量数据,并存储在 OceanBase 数据库中。当用户提问时,系统会用相同的模型将问题转化为向量,然后通过向量检索找到相关的文档内容,再将这些文档作为上下文提交给大语言模型,从而生成更精准的回答。
Github地址:github.com/oceanbase/o...
参考线上地址:www.oceanbase.com/obi
5.2 OceanBase 特性
- 向量检索:支持向量索引和高效查询,可用于 AI 应用、推荐系统和语义搜索,提供高吞吐、低延迟的向量搜索能力;
- 水平扩展:单机群支持超过1500节点、PB级数据量和单表超万亿行数据;
- 极致性能:TPC-C 7.07亿tmpC和TPC-H 1526 万 QphH @30000GB;
- 低成本:存储成本节省70%-90%;
- 实时分析:不需要额外开销,支持HTAP;
- 高可用:RPO = 0(0数据丢失),RTO < 8秒(恢复时间);
- MySQL 兼容:很容易的从MySQL迁移过来。
5.3 部署开始
使用 Linux系统 部署
bash
# 下载并安装 all-in-one (需要联网)
bash -c "$(curl -s https://obbusiness-private.oss-cn-shanghai.aliyuncs.com/download-center/opensource/oceanbase-all-in-one/installer.sh)"
source ~/.oceanbase-all-in-one/bin/env.sh
# 快速部署 OceanBase database
obd demo使用 docker 部署
- 启动 OceanBase 数据库实例
ini
# 部署一个mini模式实例
docker run -p 2881:2881 --name oceanbase-ce -e MODE=mini -d oceanbase/oceanbase-ce
# 使用 quay.io 仓库的镜像部署 OceanBase.
# docker run -p 2881:2881 --name oceanbase-ce -e MODE=mini -d quay.io/oceanbase/oceanbase-ce
# 使用 ghcr.io 仓库的镜像部署 OceanBase.
# docker run -p 2881:2881 --name oceanbase-ce -e MODE=mini -d ghcr.io/oceanbase/oceanbase-ce- 连接 OceanBase
bash
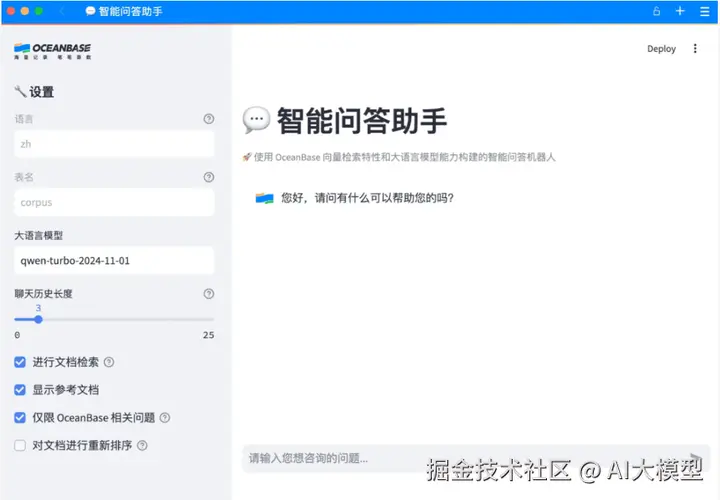
docker exec -it oceanbase-ce obclient -h127.0.0.1 -P2881 -uroot # 连接root用户sys租户下面是部署成功后的UI界面:
六、最后总结
优化RAG的关键是什么?我得到的答案是数据 + 检索。
数据质量决定了基础,高质量数据从海量数据提纯而来,检索则是确保内容能够被快速且准确提取的关键。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。