12. LangChain4j + 向量数据库操作详细说明
@toc

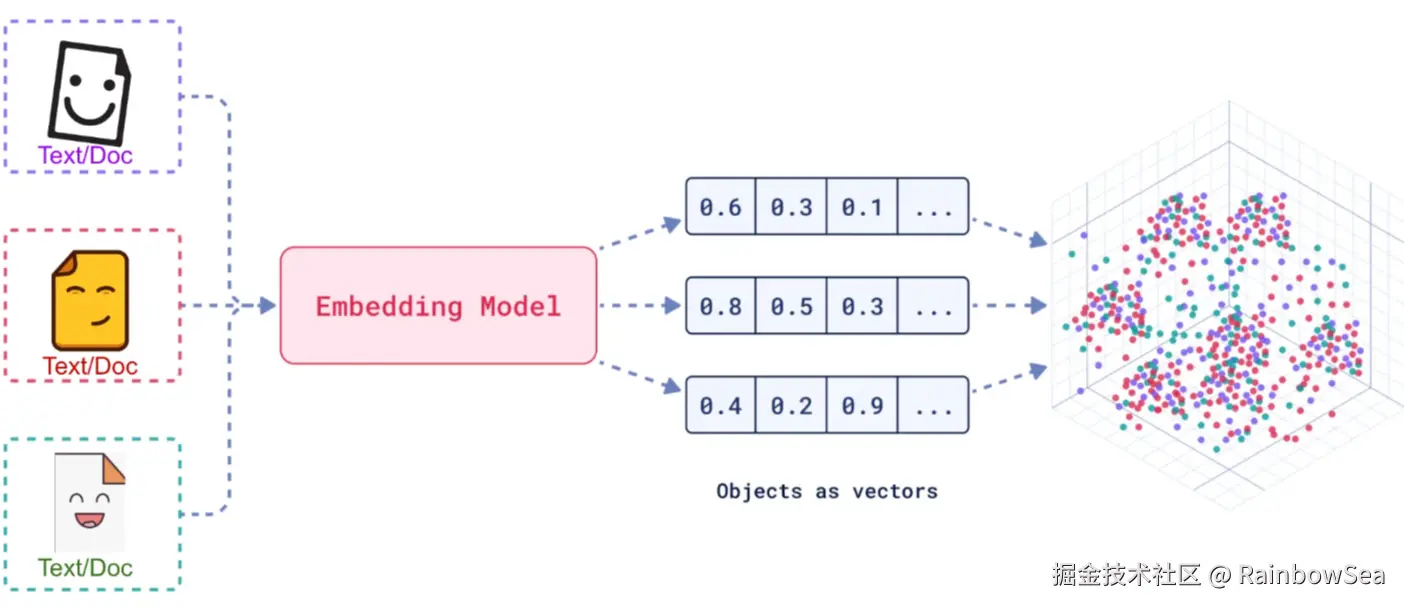
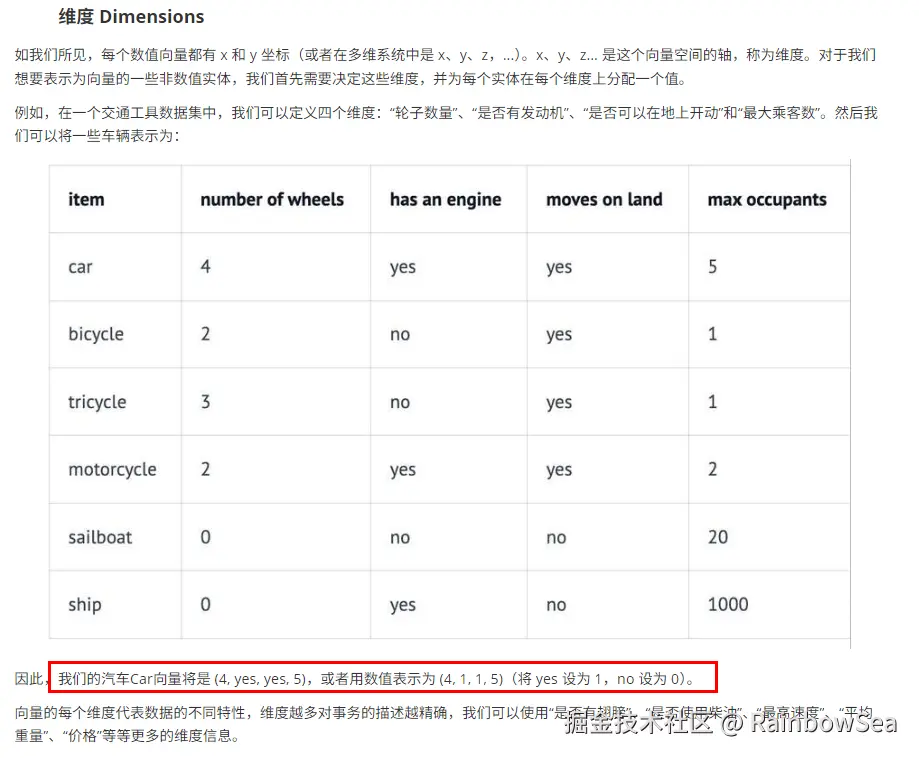
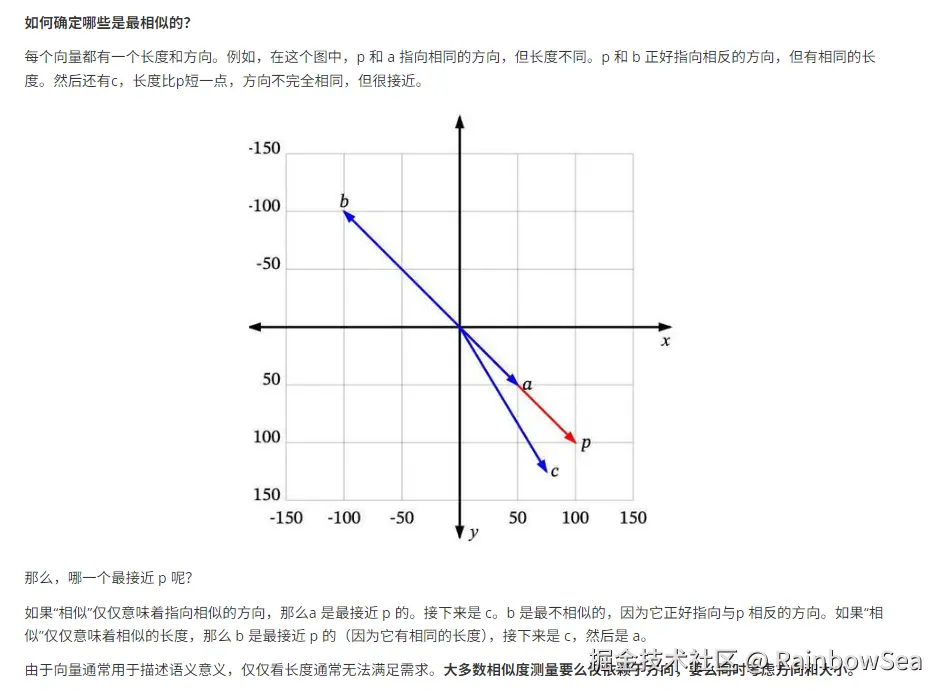
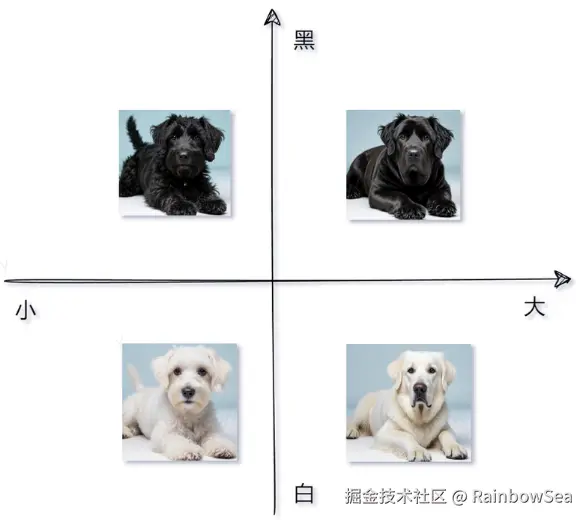
LangChain4j 向量化 3 件套:

- Embedding Model模型简介:
docs.langchain4j.dev/tutorials/r...
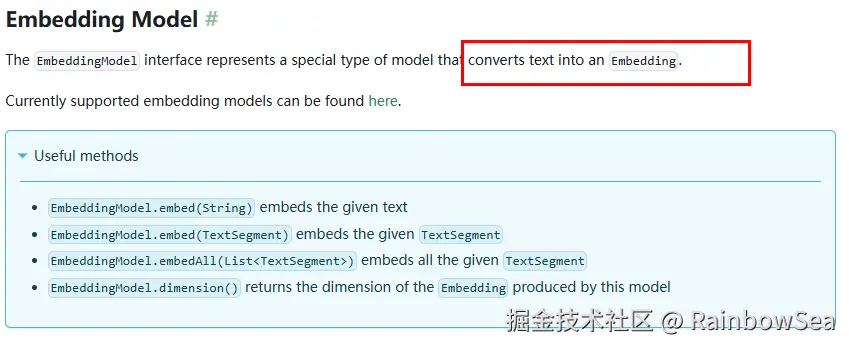

嵌入(Embedding) 的工作原理是将文本,图像和视频转换为称为向量(Vectors) 的浮点数数组。
- Embedding Store存储简介
docs.langchain4j.dev/tutorials/r...

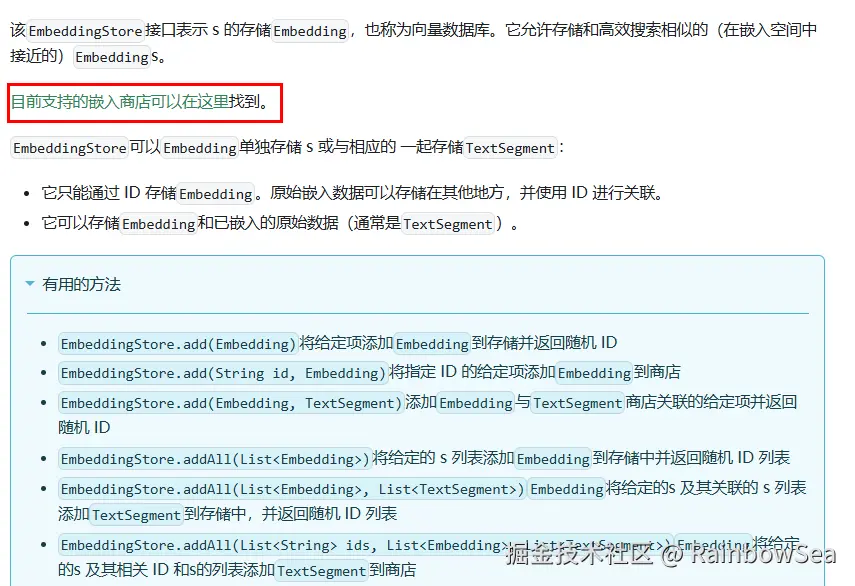

向量存储(VectorStore) 是一种用于存储和检索高维向量数据的数据库或存储解决方案。
在 VectorStrore 中,查询与传统关系数据库不同。它们执行相似性搜索,而不是精确匹配。
sql
mysql select * from book where id = 1- EmbeddingSearchRequest查询
docs.langchain4j.dev/tutorials/r...
小总结:
嵌入模型是一种机器学习模型,旨在在连续的低维向量空间中表示数据(例如文本、图像或其他形式的信息)。
这些嵌入可以捕获数据之间的语义或上下文相似性,使机器能够更有效地执行比较、聚类或分类等任务。
假设你想描述不同的水果。你不用长篇大论,而是用数字来描述甜度、大小和颜色等特征。例如,苹果可能是8,5,7,而香蕉是9,7,4。这些数字使比较或对相似的水果进行分组变得更容易。
向量数据库能做什么:
将文本,图像和视频转换为称为向量(Vectors) 的浮点数数组在 VectroStore 中,查询与传统关系数据库不同。它们执行相似性搜索,而不是精确匹配。当给定一个向量作为查询时,VectorStore 返回与查询向量"相似"的向量。
特点:
- 捕捉复杂的词汇关系(如语义相似性,同义词,同义词)
- 超越传统词袋模型的简单计数方式
- 动态嵌入模式(如 BERT)可根据上下文生成不同的词向量
- 向量嵌入为现代搜索和检索增强生成(RAG) 应用程序提供支持
总结:
将文本映射到高维空间中的点,使语义相似的文本在这个空间中距离较近。
例如:"肯德基" 和 "麦当劳"的向量可能会比"肯德基"和"新疆大盘鸡"的向量更接近
LangChain4j 支持的向量数据库
docs.langchain4j.dev/integration...
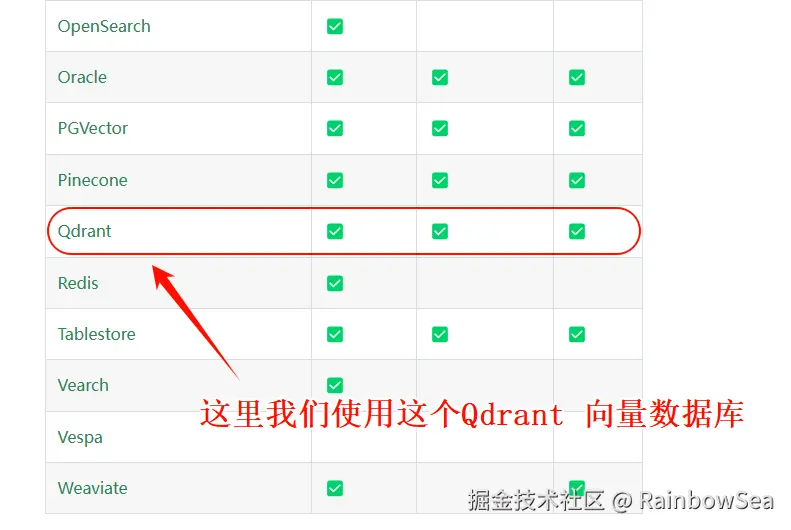

docs.langchain4j.info/integration...
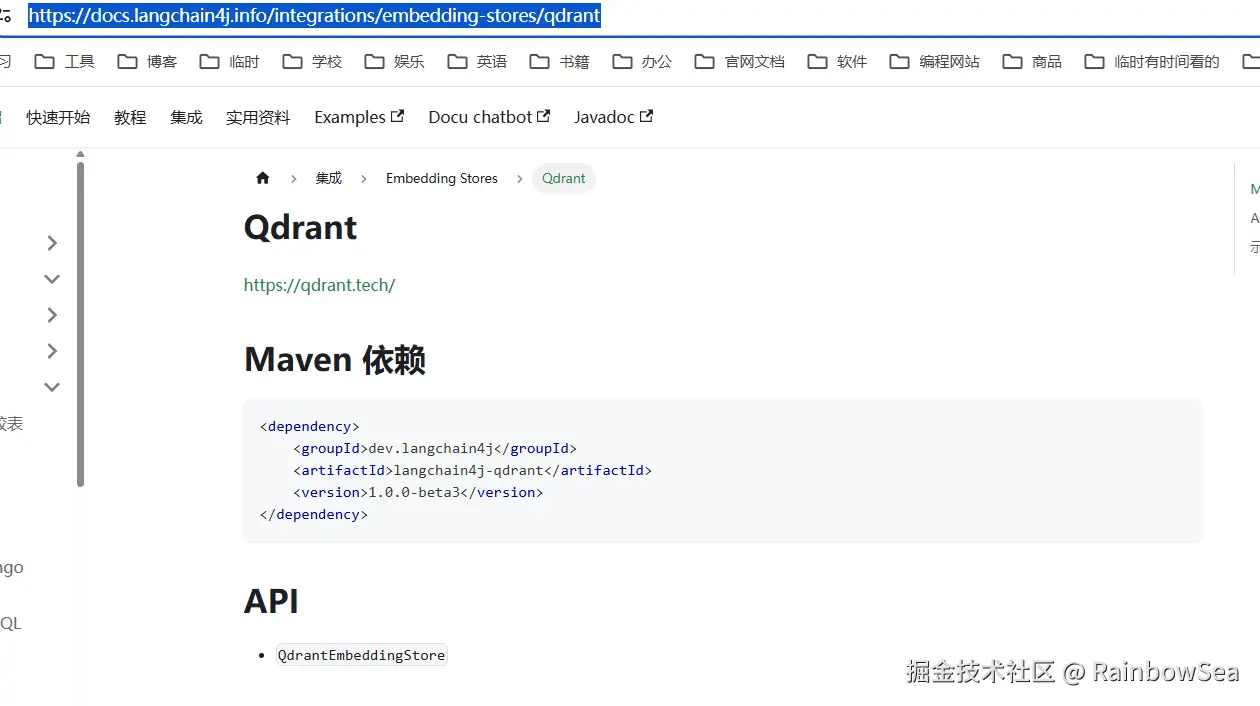
LangChain4j + 向量数据库实操------Qdrant
- 创建对应项目的 module 模块内容:
- 导入相关的 pom.xml 的依赖,这里我们采用流式输出的方式,导入 整合 Spring Boot ,langchain4j-open-ai-spring-boot-starter,langchain4j-spring-boot-starter ,同时我们加入我们的 qdrant 向量数据库 jak 依赖。这里我们不指定版本,而是通过继承的 pom.xml 当中获取。
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<!--qdrant-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-qdrant</artifactId>
<version>1.2.0-beta8</version>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>Docker 容器当中安装 Qdrant 向量数据库
关于 Qdarant 学习内容,参考如下官网:
Qdrant是一个高性能的向量数据库,用于存储嵌入并进行快速的向量搜索其它。

这里我们使用 Docker 安装 Qdrant 。
shell
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant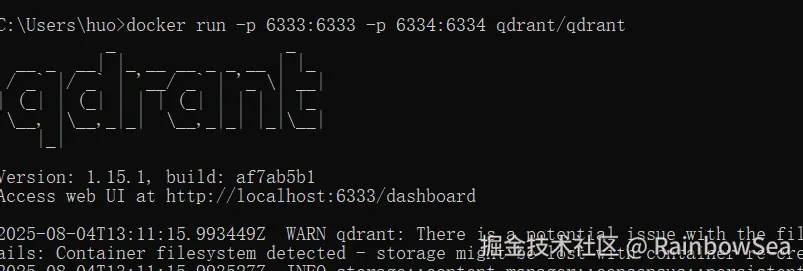

打开浏览器访问:http://localhost:6333/
打开浏览器访问: http://localhost:6333/dashboard#/collections

可以打开上述两个页面就说明 Qdant 向量数据库安装成功了。
- 设置 applcation.yaml / properties 配置文件,其中指明我们的输出响应的编码格式,因为如果不指定的话,存在返回的中文,就是乱码了。
properties
server.port=9011
spring.application.name=langchain4j-11chat-embedding
# 设置响应的字符编码,避免流式返回输出乱码
server.servlet.encoding.charset=utf-8
server.servlet.encoding.enabled=true
server.servlet.encoding.force=true
# https://docs.langchain4j.dev/tutorials/spring-boot-integration
#langchain4j.open-ai.chat-model.api-key=${aliQwen-api}
#langchain4j.open-ai.chat-model.model-name=qwen-plus
#langchain4j.open-ai.chat-model.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1
# 大模型调用不可以明文配置,你如何解决该问题
# 1 yml: ${aliQwen-api},从环境变量读取
# 2 config配置类: System.getenv("aliQwen-api")从环境变量读取使用向量数据库实操
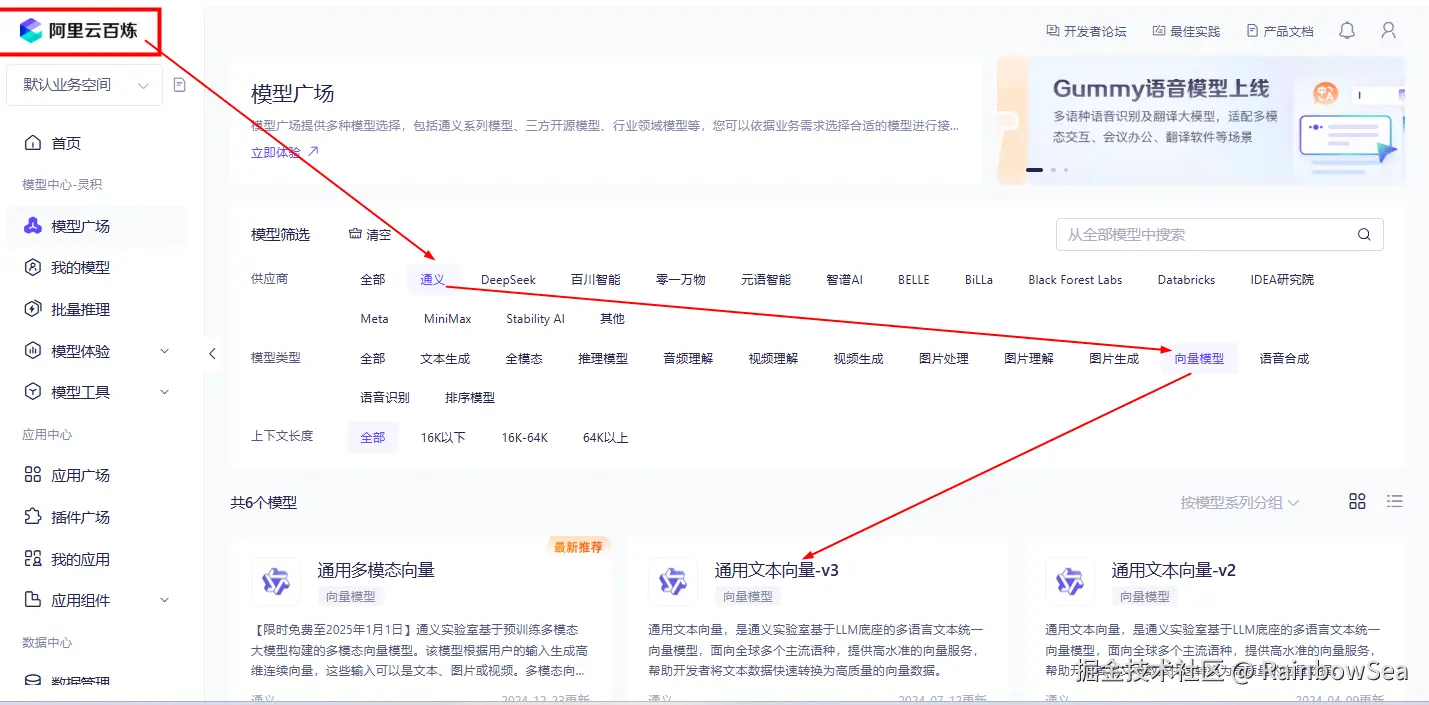
- 选取我们合适的向量大模型,注意:向量数据库是一个将文本,图像和视频转换为称为向量(Vectors) 的浮点数数组在 VectroStore 中的数据库,而我们需要将我们的文本,图像,视频等信息转换为向量数据库可以存储是向量数据,就需要借助使用我们的向量大模型(也被称之为嵌入大模型),这里我们选择大阿里云百炼的向量大模型。
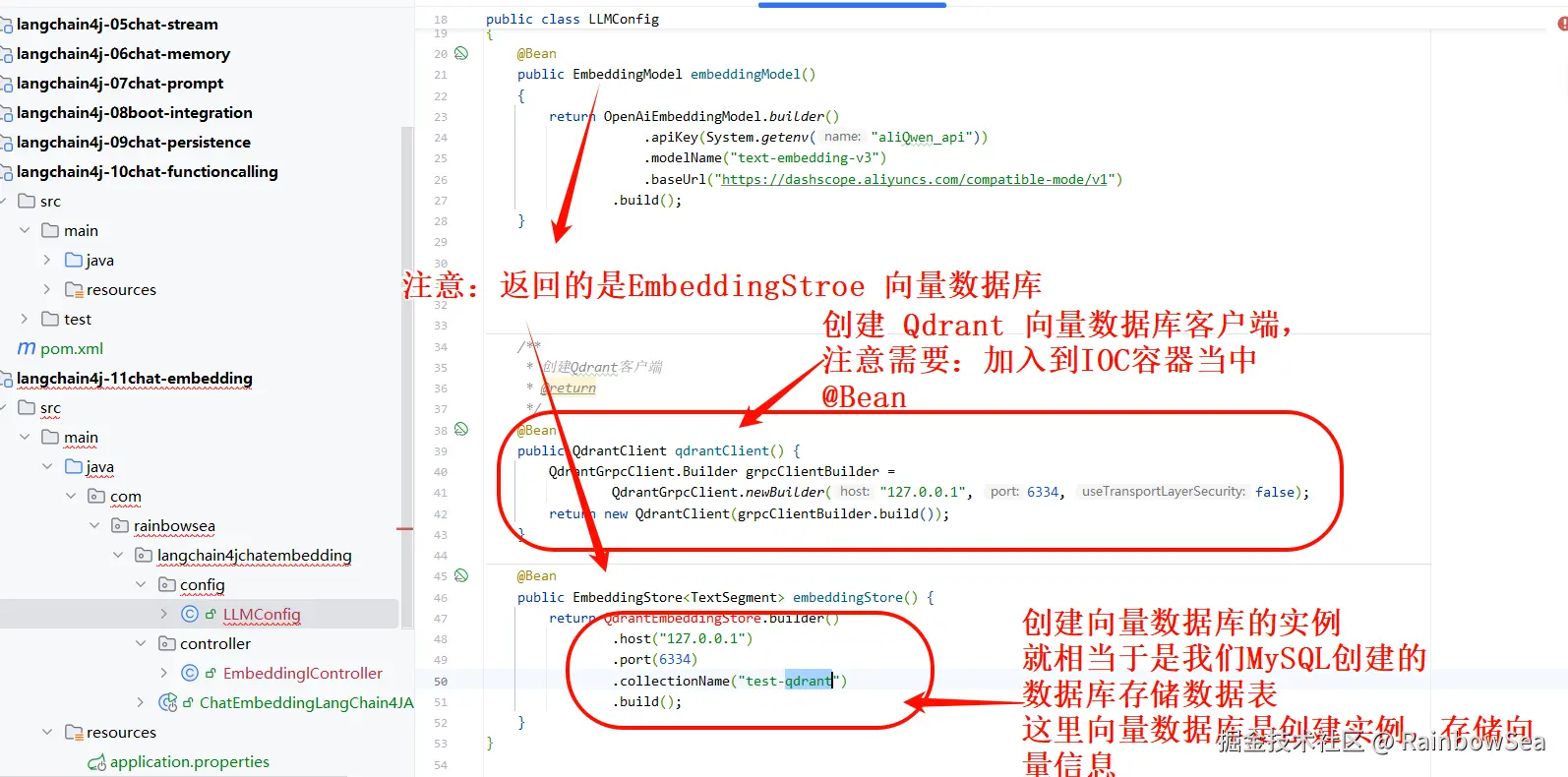
- 编写大模型三件套(大模型 key,大模型 name,大模型 url) 三件套的大模型配置类。同时也需要配置,我们的向量数据库,让向量数据库和向量大模型(嵌入式大模型)绑定,进行写入到向量数据库当中
java
package com.rainbowsea.langchain4jchatembedding.config;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.qdrant.QdrantEmbeddingStore;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
*/
@Configuration
public class LLMConfig
{
@Bean
public EmbeddingModel embeddingModel()
{
return OpenAiEmbeddingModel.builder()
.apiKey(System.getenv("aliQwen_api"))
.modelName("text-embedding-v3")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
}
/**
* 创建Qdrant客户端
* @return
*/
@Bean
public QdrantClient qdrantClient() {
QdrantGrpcClient.Builder grpcClientBuilder =
QdrantGrpcClient.newBuilder("127.0.0.1", 6334, false);
return new QdrantClient(grpcClientBuilder.build());
}
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
return QdrantEmbeddingStore.builder()
.host("127.0.0.1")
.port(6334)
.collectionName("test-qdrant")
.build();
}
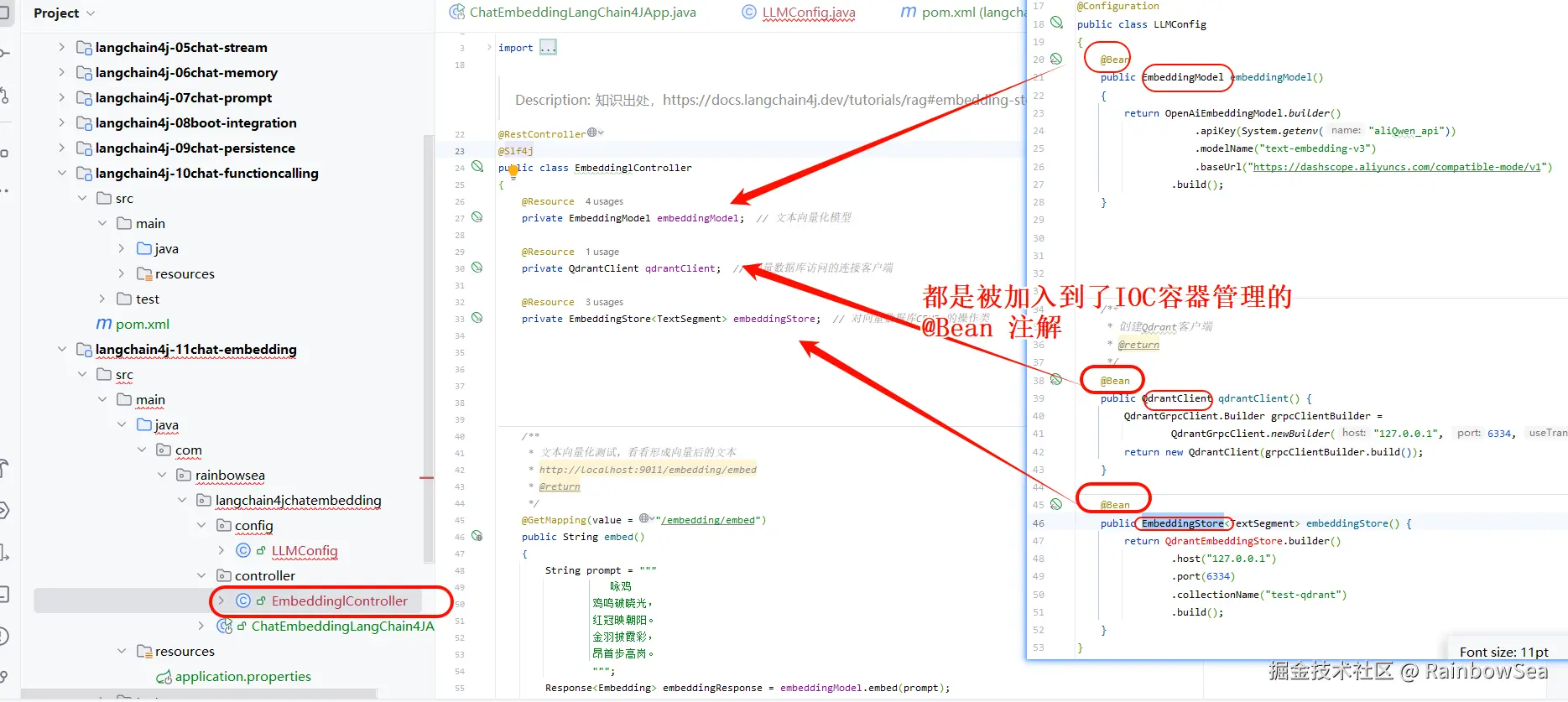
}- 编写对外访问的 ctroller ,注意:我们先将数据通过向量大模型将文本信息写入到向量数据库,在查询操作向量数据库当中的信息、
java
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingSearchResult;
import dev.langchain4j.store.embedding.EmbeddingStore;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.grpc.Collections;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import static dev.langchain4j.store.embedding.filter.MetadataFilterBuilder.metadataKey;
/**
* @Description: 知识出处,https://docs.langchain4j.dev/tutorials/rag#embedding-store
*/
@RestController
@Slf4j
public class EmbeddinglController
{
@Resource
private EmbeddingModel embeddingModel; // 文本向量化模型
@Resource
private QdrantClient qdrantClient; // 向量数据库访问的连接客户端
@Resource
private EmbeddingStore<TextSegment> embeddingStore; // 对向量数据库CRUD 的操作类
/**
* 文本向量化测试,看看形成向量后的文本,
* http://localhost:9011/embedding/embed
* @return
*/
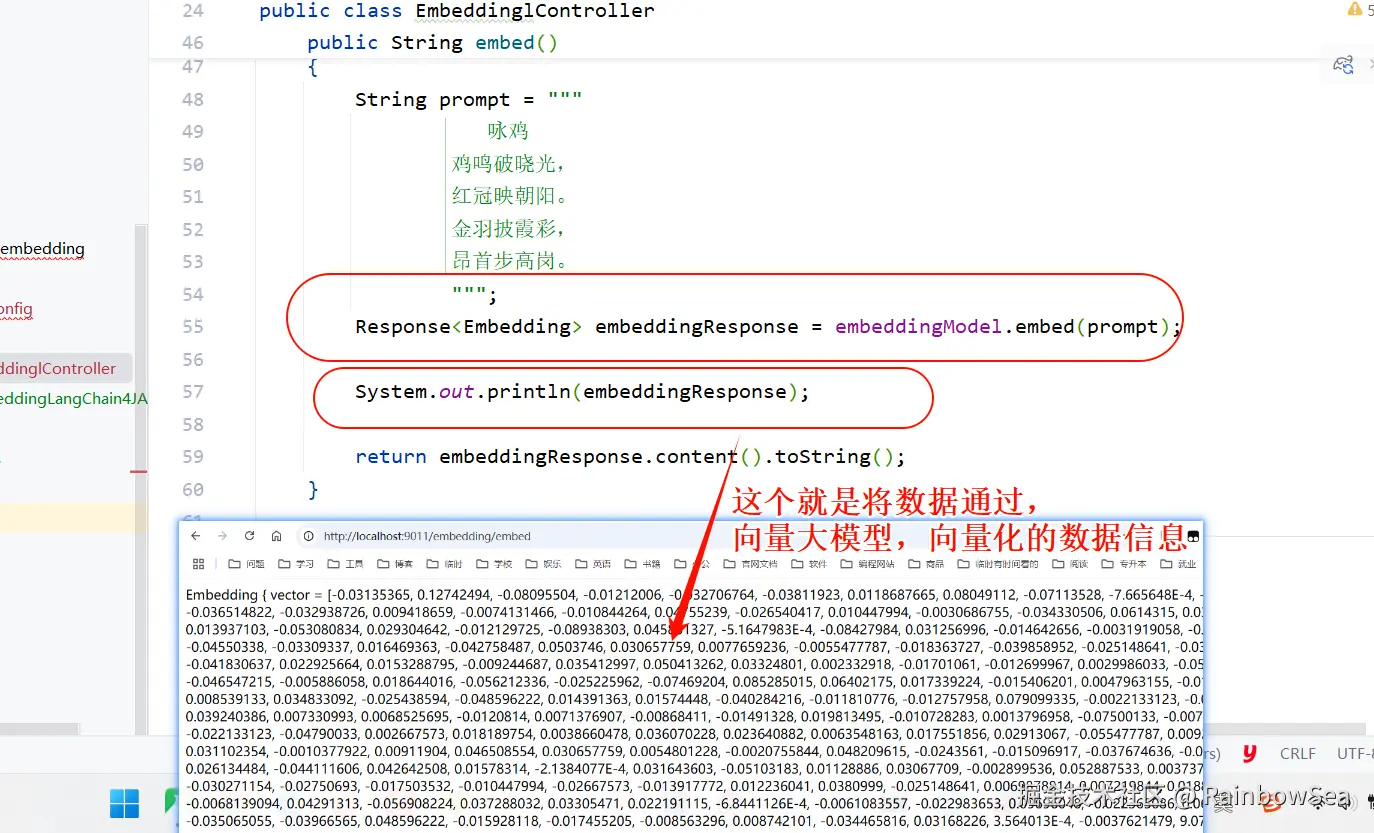
@GetMapping(value = "/embedding/embed")
public String embed()
{
String prompt = """
咏鸡
鸡鸣破晓光,
红冠映朝阳。
金羽披霞彩,
昂首步高岗。
""";
// 向量大模型将(文本,图像,视频)信息,转换为向量信息
Response<Embedding> embeddingResponse = embeddingModel.embed(prompt);
System.out.println(embeddingResponse);
return embeddingResponse.content().toString();
}
/**
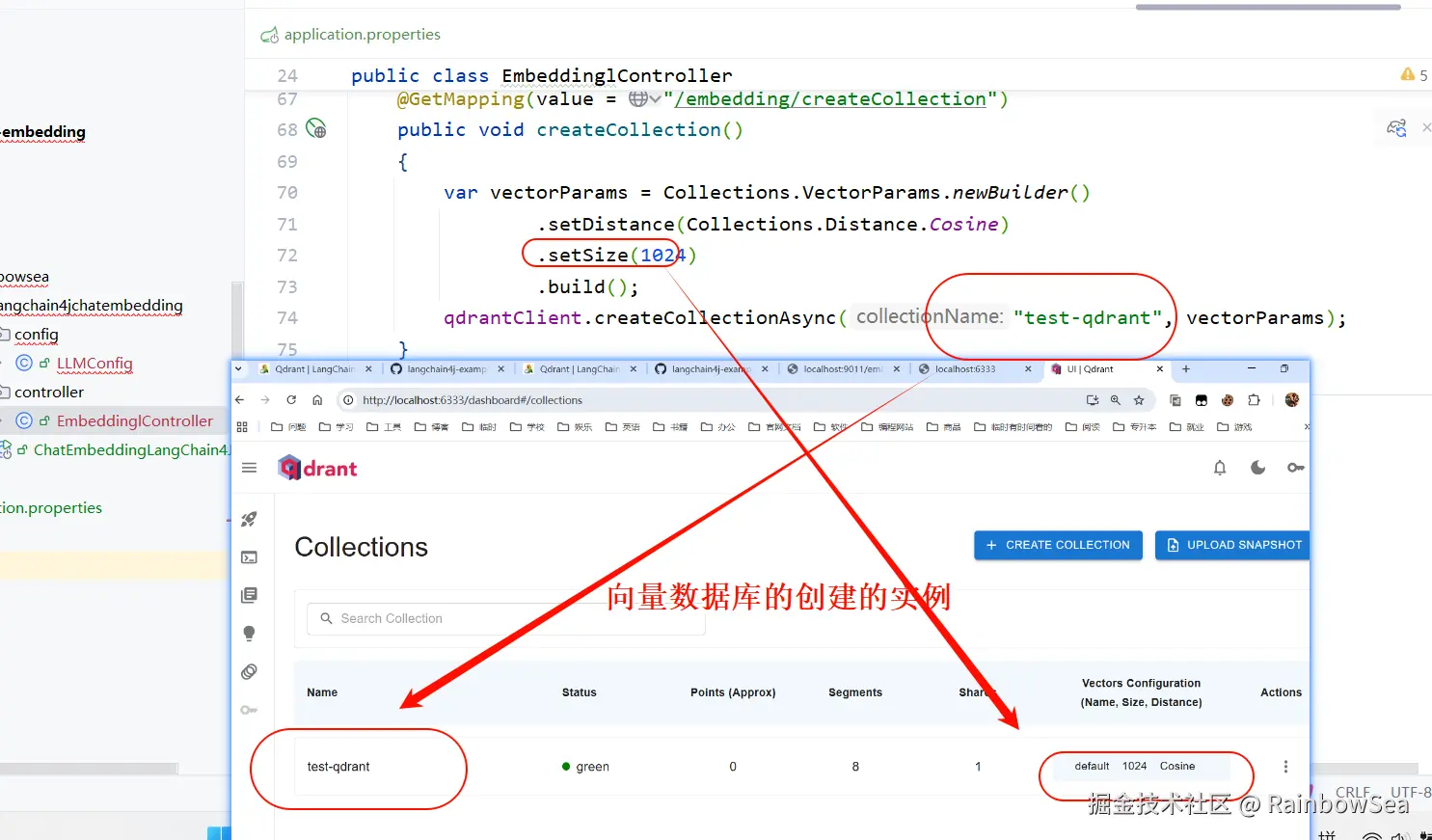
* 新建向量数据库实例和创建索引:test-qdrant
* 类似mysql create database test-qdrant
* http://localhost:9011/embedding/createCollection
*/
@GetMapping(value = "/embedding/createCollection")
public void createCollection()
{
// 创建向量数据库实例和创建索引:test-qdrant
var vectorParams = Collections.VectorParams.newBuilder()
.setDistance(Collections.Distance.Cosine)
.setSize(1024)
.build();
qdrantClient.createCollectionAsync("test-qdrant", vectorParams);
}
}
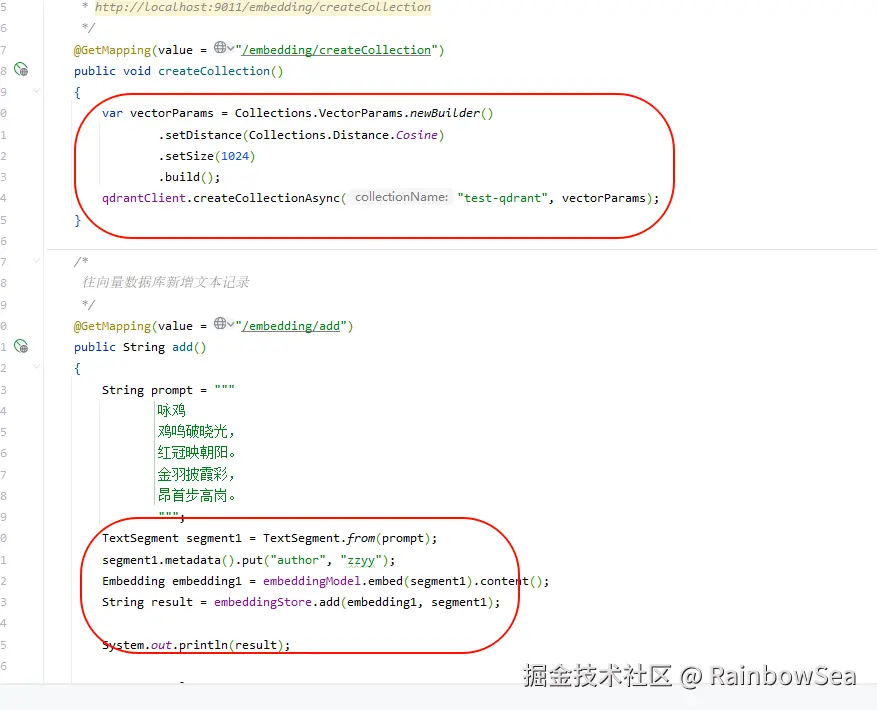
- 往向量数据库当中写入向量数据:
注意:我们需要先将(文本,图像,视频)数据通过向量大模型,转换为向量信息,才能写入到向量数据当中。
java
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingSearchResult;
import dev.langchain4j.store.embedding.EmbeddingStore;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.grpc.Collections;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import static dev.langchain4j.store.embedding.filter.MetadataFilterBuilder.metadataKey;
/**
* @Description: 知识出处,https://docs.langchain4j.dev/tutorials/rag#embedding-store
*/
@RestController
@Slf4j
public class EmbeddinglController
{
@Resource
private EmbeddingModel embeddingModel; // 文本向量化模型
@Resource
private QdrantClient qdrantClient; // 向量数据库访问的连接客户端
@Resource
private EmbeddingStore<TextSegment> embeddingStore; // 对向量数据库CRUD 的操作类
/**
* 新建向量数据库实例和创建索引:test-qdrant
* 类似mysql create database test-qdrant
* http://localhost:9011/embedding/createCollection
*/
@GetMapping(value = "/embedding/createCollection")
public void createCollection()
{
var vectorParams = Collections.VectorParams.newBuilder()
.setDistance(Collections.Distance.Cosine)
.setSize(1024)
.build();
qdrantClient.createCollectionAsync("test-qdrant", vectorParams);
}
/*
往向量数据库新增文本记录
*/
@GetMapping(value = "/embedding/add")
public String add()
{
String prompt = """
咏鸡
鸡鸣破晓光,
红冠映朝阳。
金羽披霞彩,
昂首步高岗。
""";
// 为我们的信息添加上 作者
TextSegment segment1 = TextSegment.from(prompt);
// 为我们的信息添加上 作者,便于向量化,相似匹配更接近
segment1.metadata().put("author", "zzyy");
Embedding embedding1 = embeddingModel.embed(segment1).content();
// 向量大模型转换好的信息,写入到向量数据库当中
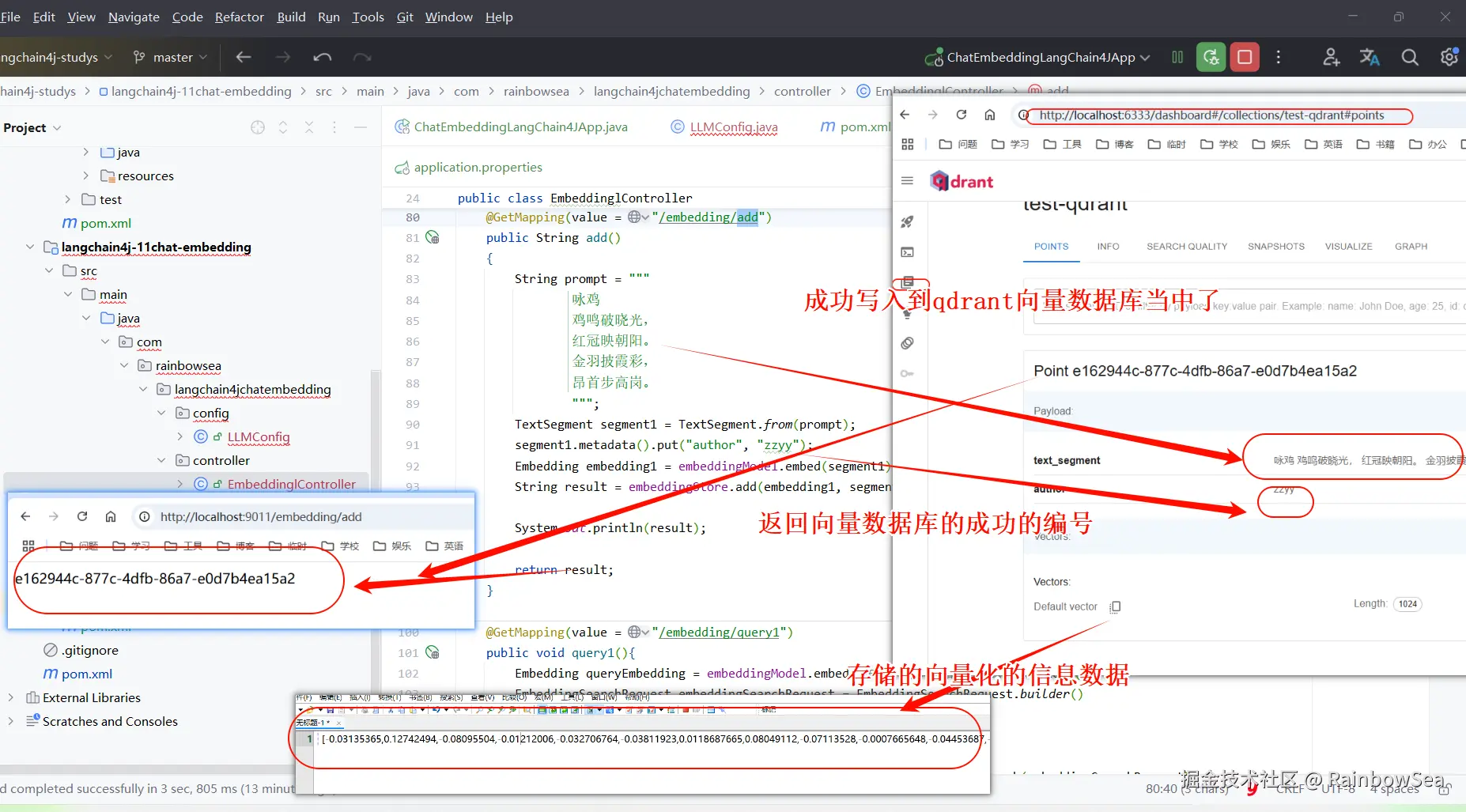
String result = embeddingStore.add(embedding1, segment1);
System.out.println(result);
return result;
}
}
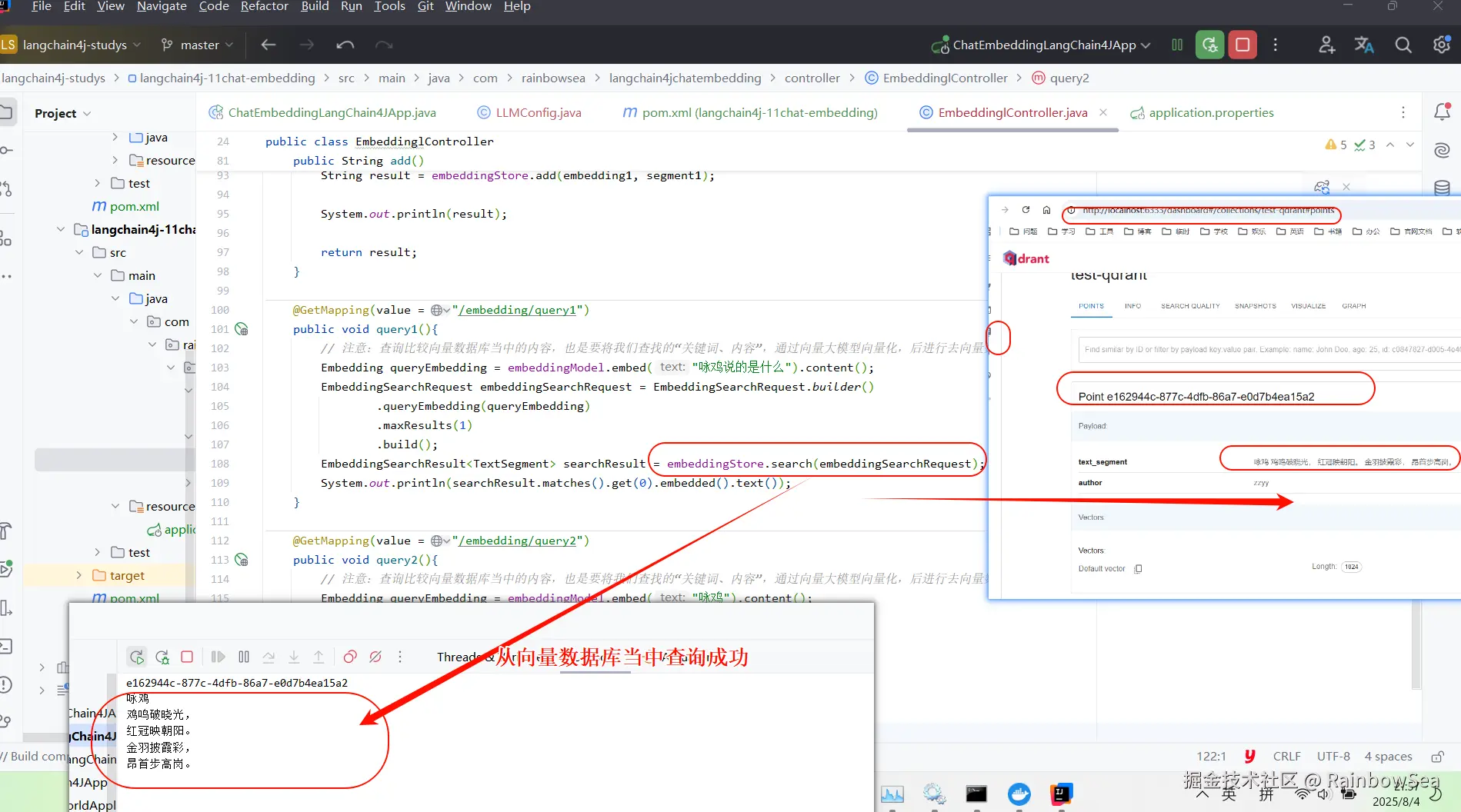
查询向量数据库的内容(比较相似度,不是精确查找)
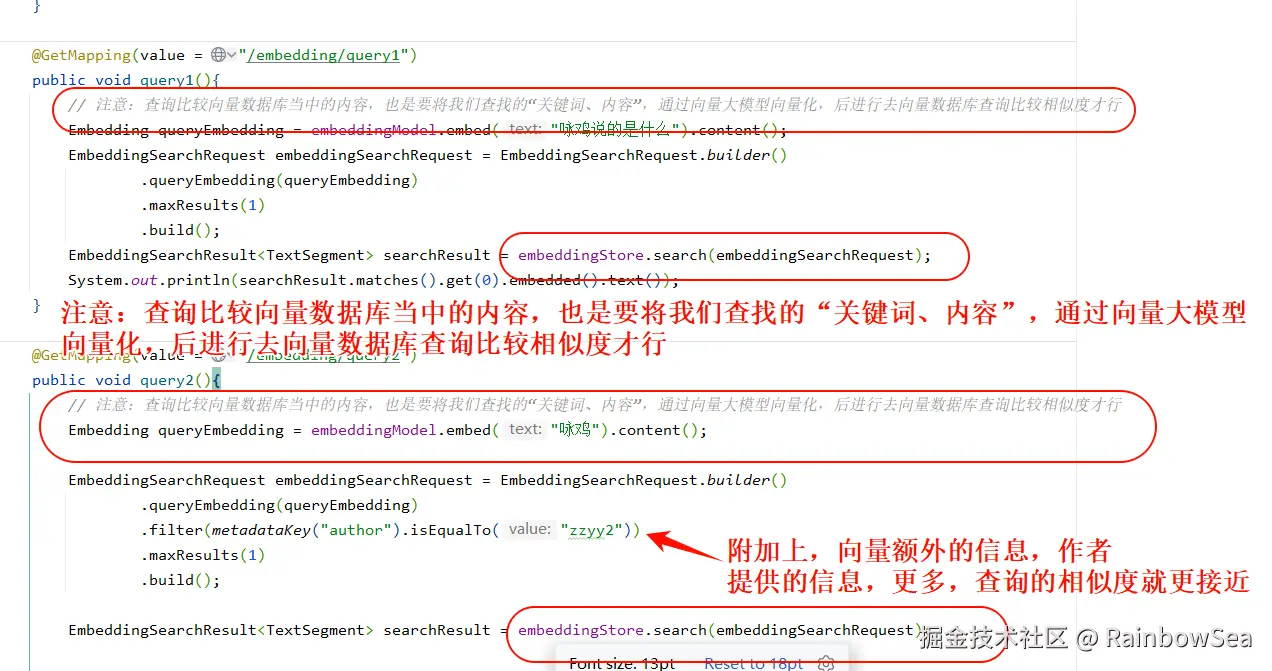
注意:查询比较向量数据库当中的内容,也是要将我们查找的"关键词、内容",通过向量大模型向量化,后进行去向量数据库查询比较相似度才行
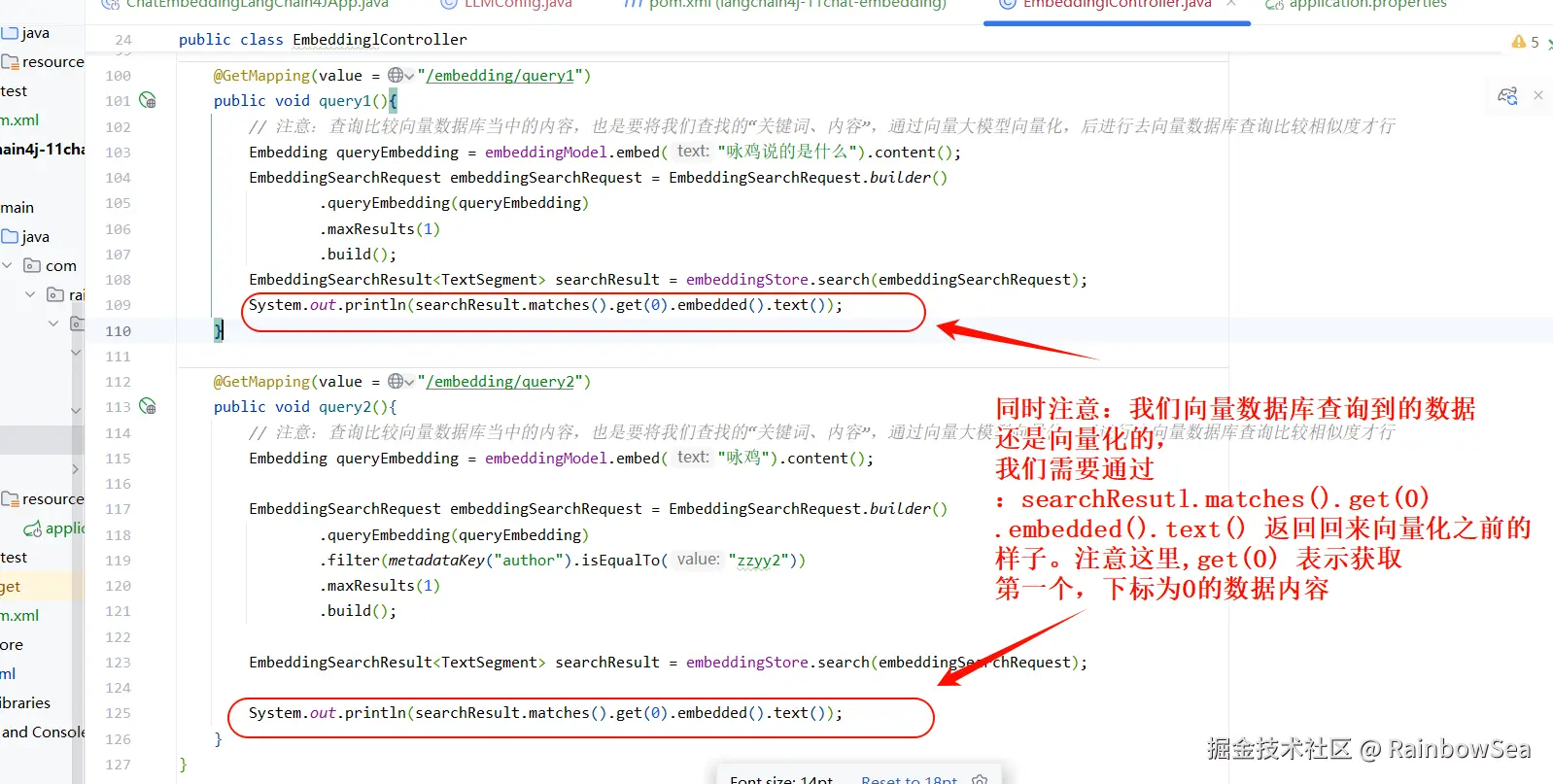
同时注意:我们向量数据库查询到的数据 还是向量化的, 我们需要通过 :searchResutl.matches().get(0) .embedded().text() 返回回来向量化之前的 样子。注意这里,get(0) 表示获取 第一个,下标为0的数据内容
java
package com.rainbowsea.langchain4jchatembedding.controller;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingSearchResult;
import dev.langchain4j.store.embedding.EmbeddingStore;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.grpc.Collections;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import static dev.langchain4j.store.embedding.filter.MetadataFilterBuilder.metadataKey;
/**
* @Description: 知识出处,https://docs.langchain4j.dev/tutorials/rag#embedding-store
*/
@RestController
@Slf4j
public class EmbeddinglController
{
@Resource
private EmbeddingModel embeddingModel; // 文本向量化模型
@Resource
private QdrantClient qdrantClient; // 向量数据库访问的连接客户端
@Resource
private EmbeddingStore<TextSegment> embeddingStore; // 对向量数据库CRUD 的操作类
@GetMapping(value = "/embedding/query1")
public void query1(){
// 注意:查询比较向量数据库当中的内容,也是要将我们查找的"关键词、内容",通过向量大模型向量化,后进行去向量数据库查询比较相似度才行
Embedding queryEmbedding = embeddingModel.embed("咏鸡说的是什么").content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(embeddingSearchRequest);
System.out.println(searchResult.matches().get(0).embedded().text());
}
@GetMapping(value = "/embedding/query2")
public void query2(){
// 注意:查询比较向量数据库当中的内容,也是要将我们查找的"关键词、内容",通过向量大模型向量化,后进行去向量数据库查询比较相似度才行
Embedding queryEmbedding = embeddingModel.embed("咏鸡").content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.filter(metadataKey("author").isEqualTo("zzyy2"))
.maxResults(1)
.build();
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(embeddingSearchRequest);
System.out.println(searchResult.matches().get(0).embedded().text());
}
}
最后:
"在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。"
