随着技术演进以及对可扩展且具备韧性的系统需求不断增长,理解支配分布式系统的基础模式变得尤为重要。
从管理节点之间的通信到保障容错(FT)与一致性,本章将探讨一组关键的设计模式,帮助开发者构建稳健的分布式系统。无论你在搭建微服务还是实现云原生应用,掌握这些模式都能为你有效应对分布式计算的复杂性提供工具。
在本章中,我们将讨论以下主题:
- 限流(Throttling)模式
- 重试(Retry)模式
- 熔断器(Circuit Breaker)模式
- 其他分布式系统模式
技术要求
请先参见第 1 章中的通用要求。本章代码的额外环境需求如下:
- 安装 Flask 与 Flask-Limiter:
python -m pip install flask flask-limiter - 安装 PyBreaker:
python -m pip install pybreaker
限流(Throttling)模式
限流是当今应用与 API 中常会用到的重要模式。在此语境中,限流指控制某个用户(或客户端服务)在给定时间内向某个服务或 API 发送请求的速率 ,以保护服务资源不被过度使用。
例如,我们可以限制某 API 的用户请求数为每日 1,000 次 。达到上限后,再次请求将返回 429(Too Many Requests) 错误,并附带"请求过多"的提示信息。
关于限流有许多需要理解的点:包括选用何种限制策略与算法 、如何度量服务使用情况 等。有关限流模式的技术细节,可参考 Microsoft 的云设计模式目录:
learn.microsoft.com/en-us/azure...
现实示例
- 高速公路交通管理:红绿灯或限速用来调节车流。
- 水龙头:调节水流量大小。
- 演唱会售票:热门演出开售时,网站可能限制每位用户的单次购票数量,以防需求激增导致服务器崩溃。
- 用电分时计费:一些电力公司按高峰/低谷分时计价,引导用户错峰用电。
- 自助餐取餐:可能限制一次只取一盘,以保证公平并减少浪费。
实现限流的软件示例:
- django-throttle-requests (github.com/sobotklp/dj...):为 Django 项目提供应用级限流中间件框架。
- Flask-Limiter (flask-limiter.readthedocs.io/en/stable/):为 Flask 路由提供限流能力。
适用场景
当你需要确保系统持续稳定服务 、优化服务使用成本 、或应对突发流量时,建议采用该模式。实践中可实现如下规则:
- 将某 API 的总请求数 限制为 N/天(如 N=1000)。
- 针对某个 IP、国家或地区 限制 N/天。
- 对已认证用户限制读写次数。
除速率限制外,限流也可用于资源分配,确保在多客户端之间公平分配资源。
实现限流模式
在实现之前需了解:限流有多种类型,例如速率限制(Rate-Limit) 、IP 级限制 (如白名单机制)、以及并发连接数限制 等。前两者较易上手,本节聚焦速率限制。
下面以一个最小化的 Flask Web 应用为例,结合 Flask-Limiter 演示速率限制。
导入:
javascript
from flask import Flask
from flask_limiter import Limiter
from flask_limiter.util import get_remote_address创建 Flask 应用:
ini
app = Flask(__name__)定义 Limiter 实例 :传入键函数 get_remote_address、应用对象、默认限额等参数:
ini
limiter = Limiter(
get_remote_address,
app=app,
default_limits=["100 per day", "10 per hour"],
storage_uri="memory://",
strategy="fixed-window",
)受默认限额保护的路由 /limited:
python
@app.route("/limited")
def limited_api():
return "Welcome to our API!"更严格的路由 /more_limited(每分钟 2 次):
less
@app.route("/more_limited")
@limiter.limit("2/minute")
def more_limited_api():
return "Welcome to our expensive, thus very limited, API!"常规启动入口:
ini
if __name__ == "__main__":
app.run(debug=True)测试
运行:python ch09/throttling_flaskapp.py(见图 9.1 -- throttling_flaskapp:Flask 应用启动示例)。

浏览器访问 http://127.0.0.1:5000/limited,可看到欢迎页面(图 9.2 -- /limited 响应)。

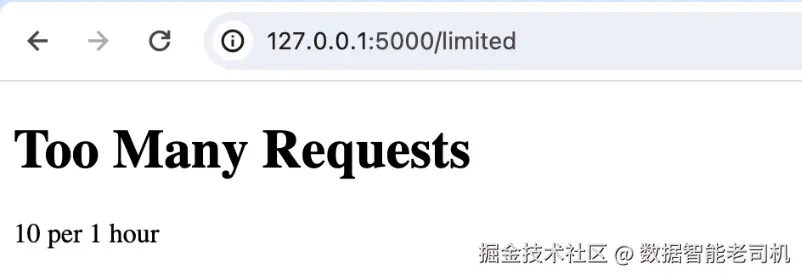
多次刷新后,第 第 10 次 会收到 Too Many Requests (429)错误(图 9.3 -- /limited 请求过多)。
再访问第二个路由:http://127.0.0.1:5000/more_limited(图 9.4 -- /more_limited 响应)。

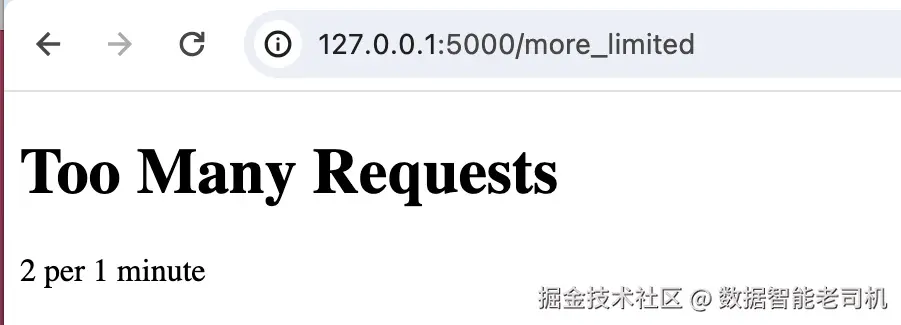
若在 1 分钟内刷新超过两次 ,将再次收到 Too Many Requests (图 9.5 -- /more_limited 请求过多)。
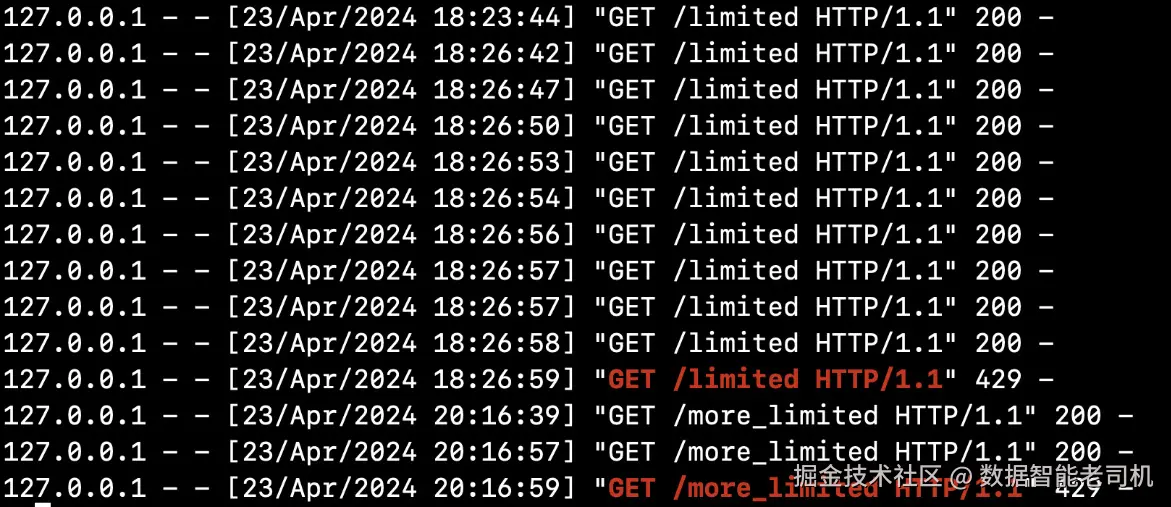
同时,运行 Flask 服务器的控制台会显示每个收到的 HTTP 请求及响应状态码(图 9.6 -- 服务器控制台输出)。
借助 Flask-Limiter,你可以在 Flask 应用中实现多种限流策略。文档还介绍了不同的限流算法策略 与存储后端(如 Redis)的用法,便于按需选择与扩展。
重试(Retry)模式
在分布式系统语境下,重试越来越常见。想想微服务或云端基础设施:各组件彼此协作,但往往由不同团队开发、部署与运维。
在云原生应用的日常运行中,部分组件可能会遭遇所谓的瞬时性故障 (transient faults/failures)------看起来像 Bug,但并非应用本身导致,而是网络 、外部服务器/服务性能 等你无法掌控的约束所致。结果就是:你的应用可能出现异常行为(用户的感知至少如此),甚至在某些位置卡住 。应对这类风险的办法,是引入重试逻辑 :再次调用该服务(可能立刻 ,也可能等待几秒后)以越过这次短暂问题。
现实类比
- 打电话 :拨打朋友电话但占线或网络不佳,通常会稍等再拨,而不是立刻放弃。
- ATM 取现 :因临时的网络拥堵/连接问题导致交易失败,稍后再次尝试,往往就能成功。
在软件领域,也有帮助实现重试模式的工具/技术:
- Python 的 Retrying 库(github.com/rholder/ret...)
- Go 开发者可用 Pester 库(github.com/sethgrid/pe...)
适用场景
- 与外部组件/服务通信时,因网络故障 或服务器过载 导致的瞬时失败需要被缓解。
- 注意:不建议 用重试来处理应用逻辑自身错误 引发的内部异常。还需分析外部服务的响应:若频繁出现"忙碌"故障,通常意味着服务端需扩容或修复。
- 与微服务 架构相关:服务间通过网络通信,重试能避免短暂故障触发系统级失败。
- 数据同步 :在系统间同步数据时,重试可应对临时不可用的一方。
重试模式的实现示例
下面用"数据库连接"为例,实现一个装饰器驱动的重试机制。
导入与日志:
arduino
import logging
import random
import time
logging.basicConfig(level=logging.DEBUG)重试装饰器 :自动对被装饰的函数进行最多 attempts 次重试。
python
def retry(attempts):
def decorator(func):
def wrapper(*args, **kwargs):
for _ in range(attempts):
try:
logging.info("Retry happening")
return func(*args, **kwargs)
except Exception as e:
time.sleep(1)
logging.debug(e)
return "Failure after all attempts"
return wrapper
return decorator模拟数据库连接 :随机抛出"临时错误",并用装饰器设置最多 3 次重试。
java
@retry(attempts=3)
def connect_to_database():
if random.randint(0, 1):
raise Exception("Temporary Database Error")
return "Connected to Database"测试代码:
python
if __name__ == "__main__":
for i in range(1, 6):
logging.info(f"Connection attempt #{i}")
print(f"--> {connect_to_database()}")运行:
bash
python ch09/retry/retry_database_connection.py可能输出:
ruby
INFO:root:Connection attempt #1
INFO:root:Retry happening
--> Connected to Database
INFO:root:Connection attempt #2
INFO:root:Retry happening
DEBUG:root:Temporary Database Error
INFO:root:Retry happening
DEBUG:root:Temporary Database Error
INFO:root:Retry happening
DEBUG:root:Temporary Database Error
--> Failure after all attempts
INFO:root:Connection attempt #3
INFO:root:Retry happening
--> Connected to Database
INFO:root:Connection attempt #4
INFO:root:Retry happening
--> Connected to Database
INFO:root:Connection attempt #5
INFO:root:Retry happening
DEBUG:root:Temporary Database Error
INFO:root:Retry happening
DEBUG:root:Temporary Database Error
INFO:root:Retry happening
DEBUG:root:Temporary Database Error
--> Failure after all attempts当发生临时数据库错误时,会触发最多三次 重试;若三次均失败,则认定本次操作失败。总体来看,重试模式 是处理分布式系统中此类场景的可行手段;但如果错误频繁(如示例中的多次 DB 错误),很可能意味着存在更持久/更严重的问题,应当在服务端或架构层面予以修复或扩容。
熔断器(Circuit Breaker)模式
实现容错(FT)的一种方式是重试 ,我们刚刚已看到。但当与外部组件通信导致的故障很可能是长期存在 时,继续使用重试机制会影响应用的响应性 :对极可能失败的请求反复尝试只是在浪费时间与资源 。此时就需要另一种模式:熔断器模式(Circuit Breaker) 。
在熔断器模式中,你会用一个特殊的(熔断器)对象包裹 脆弱的函数调用或外部服务的集成点,并监控失败 。一旦失败次数达到阈值,熔断器就会跳闸(打开) ,随后对熔断器的所有调用都会立刻返回错误 ,而不会再去执行被保护的调用。
现实示例
-
水/电分配回路:断路器(空气开关)在异常时跳闸,保护线路与设备。
-
软件中的做法:
- 电商结算:支付网关宕机时,熔断器停止进一步的支付尝试,避免系统雪崩。
- 有速率限制的 API:当 API 达到限额时,熔断器阻止继续请求,以免触发惩罚。
适用场景
当你的系统组件在与外部组件、服务或资源通信时,需要对长期性故障具备容错能力,推荐使用熔断器模式。下面我们通过示例理解它如何应对这些场景。
实现熔断器模式
假设你要在一个容易出错 (例如受不稳定网络影响)的函数上使用熔断器。我们用 pybreaker 库(pypi.org/project/pyb...)演示。
本实现改编自这个仓库中的脚本:github.com/veltra/pybr...
导入:
javascript
import pybreaker
from datetime import datetime
import random
from time import sleep定义熔断器 :例如在该函数连续失败五次后自动打开(示例代码中设置了参数):
ini
breaker = pybreaker.CircuitBreaker(fail_max=2, reset_timeout=5)被保护的"脆弱函数" (用装饰器语法包裹):
python
@breaker
def fragile_function():
if not random.choice([True, False]):
print(" / OK", end="")
else:
print(" / FAIL", end="")
raise Exception("This is a sample Exception")主程序:
python
def main():
while True:
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"), end="")
try:
fragile_function()
except Exception as e:
print(" / {} {}".format(type(e), e), end="")
finally:
print("")
sleep(1)运行:python ch09/circuit_breaker.py
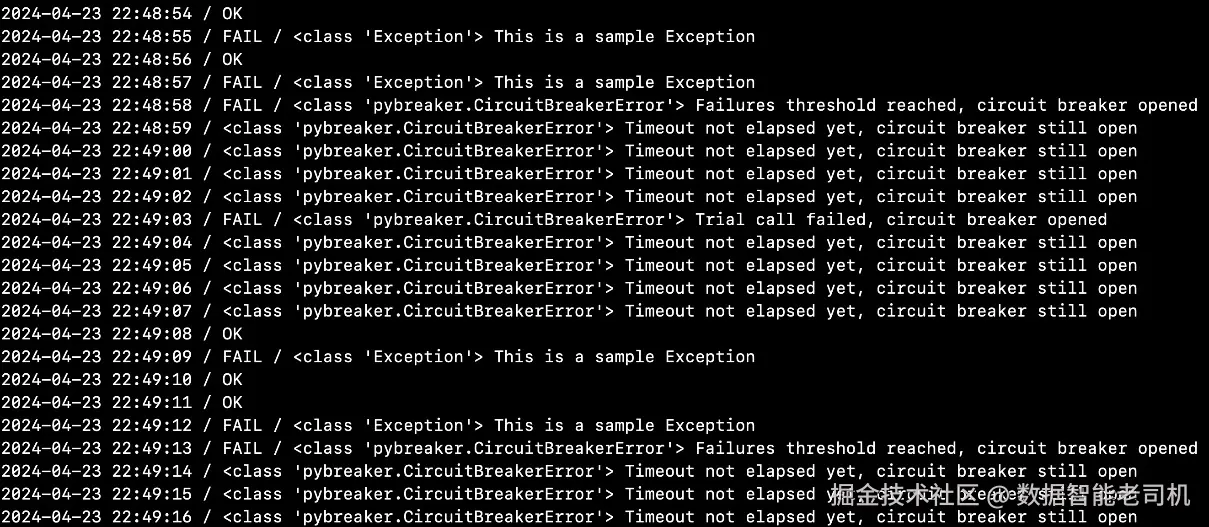 图 9.7 -- 使用熔断器的程序输出
图 9.7 -- 使用熔断器的程序输出
从输出可以看到,熔断器按预期工作:当其处于打开 状态时,fragile_function() 的调用会立即失败 (抛出 CircuitBreakerError),而不会 尝试真正的受保护操作。超时 5 秒 后,熔断器允许下一次 调用通过:若该次成功,熔断器闭合 ;若失败,则再次打开并等待下一次超时。
其他分布式系统模式
除了本章涵盖的模式,还有许多可用的分布式系统模式,例如:
- 命令查询职责分离(CQRS) :将读写职责分离,通过针对性的数据模型与操作优化数据访问与可扩展性。
- 两阶段提交(2PC) :分布式事务协议,通过"准备(prepare)→提交(commit)"两阶段,确保多参与资源间的原子性与一致性。
- Saga :由一系列本地事务 构成的分布式事务,通过补偿机制在部分失败或中止时维持一致性。
- Sidecar(边车) :在主服务旁部署辅助服务,增强监控、日志、安全等能力,而无需直接修改主应用。
- 服务注册中心(Service Registry) :集中管理与发现服务,使服务能动态注册/发现彼此,促进通信与可扩展性。
- 隔舱(Bulkhead) :借鉴船舱隔离思想,对系统资源/组件进行分区隔离,避免故障蔓延,增强容错与韧性。
这些模式针对分布式系统的不同挑战,提供架构与实现层面的策略与最佳实践,帮助设计在动态且不可预测环境中依然稳健、可扩展的系统。
小结
本章深入探讨了分布式系统模式,重点介绍了限流(Throttling) 、重试(Retry)与熔断器(Circuit Breaker) 。这些模式对于构建稳健、容错、高效的分布式系统至关重要:
- 通过限流,你能有效管理服务负载与资源分配。
- 掌握重试 的实现,让你的操作在面对瞬时故障时更可靠。
- 学会熔断器 ,即可在优雅处理长期性故障的同时保护系统。
需要牢记:这些模式并非孤立的银弹,而是可组合 的工具,应根据系统的具体需求与约束 加以裁剪与搭配。核心在于理解其原理 ,以便灵活应用,打造韧性强、效率高的分布式系统。
最后,我们简要介绍了其他分布式系统模式,受篇幅所限未能一一展开。
下一章 将聚焦测试相关的模式。