文本词频统计器
这是一个用C语言编写的文本词频统计程序,可以读取文本文件并统计每个单词的出现次数,然后输出频率最高的10个单词。
功能特点
- 读取文本文件(支持.txt等文本格式)
- 自动识别单词(字母和数字组合)
- 忽略大小写差异
- 统计每个单词的出现次数
- 按出现频率排序
- 输出前10个高频单词
- 支持大文件处理
编译方法
bash
gcc -Wall -Wextra -std=c99 -O2 -o word_frequency word_frequency.c使用方法
基本用法
bash
./word_frequency <文本文件名>示例
bash
# 使用提供的示例文件
./word_frequency sample.txt
# 使用自己的文本文件
./word_frequency my_text.txtWindows用户
bash
# 编译
gcc -o word_frequency.exe word_frequency.c
# 运行
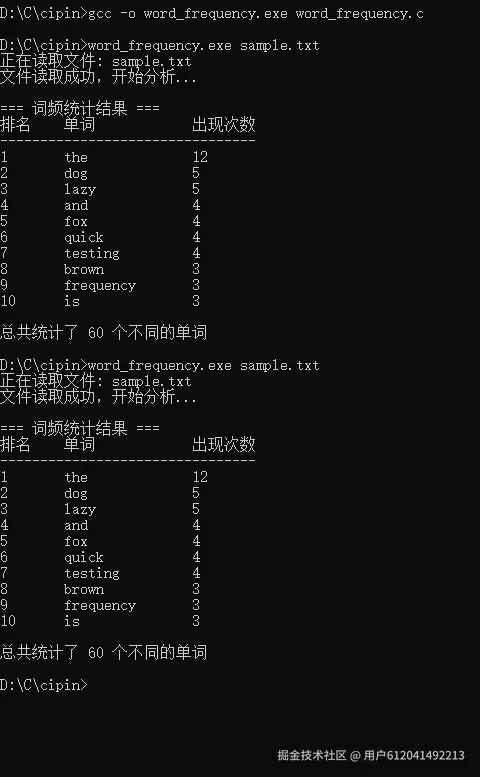
word_frequency.exe sample.txt输出示例
markdown
正在读取文件: sample.txt
文件读取成功,开始分析...
=== 词频统计结果 ===
排名 单词 出现次数
--------------------------------
1 the 8
2 dog 4
3 lazy 4
4 fox 3
5 quick 3
6 brown 3
7 jumps 2
8 over 2
9 was 2
10 testing 2
总共统计了 45 个不同的单词程序特性
- 智能单词识别:程序会自动识别由字母和数字组成的单词
- 大小写不敏感:所有单词都会被转换为小写进行统计
- 高效排序:使用快速排序算法对结果进行排序
- 内存管理:动态分配内存,支持大文件处理
- 错误处理:包含完善的错误处理机制
技术实现
- 使用结构体存储单词和计数
- 动态内存分配处理文件内容
- 快速排序算法进行结果排序
- 标准C库函数进行文件操作和字符串处理
文件说明
word_frequency.c- 主程序源代码sample.txt- 示例文本文件README.md- 说明文档
系统要求
- C编译器(如GCC、Clang等)
- 支持C99标准
- 足够的可用内存(取决于文本文件大小)
注意事项
- 程序最多支持统计10000个不同的单词
- 单个单词最大长度为100个字符
- 确保输入文件存在且可读
- 程序会忽略标点符号,只统计字母数字组合