点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月15日更新到: Java-124 深入浅出 MySQL Seata框架详解:分布式事务的四种模式与核心架构 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- Spark Streaming DStream 有状态转换
- DStream 有状态转换 案例

基础介绍
针对不同的Spark、Kafka版本,集成处理数据的方式有两种:
- Receiver Approach
- Direct Approach
对应的版本: 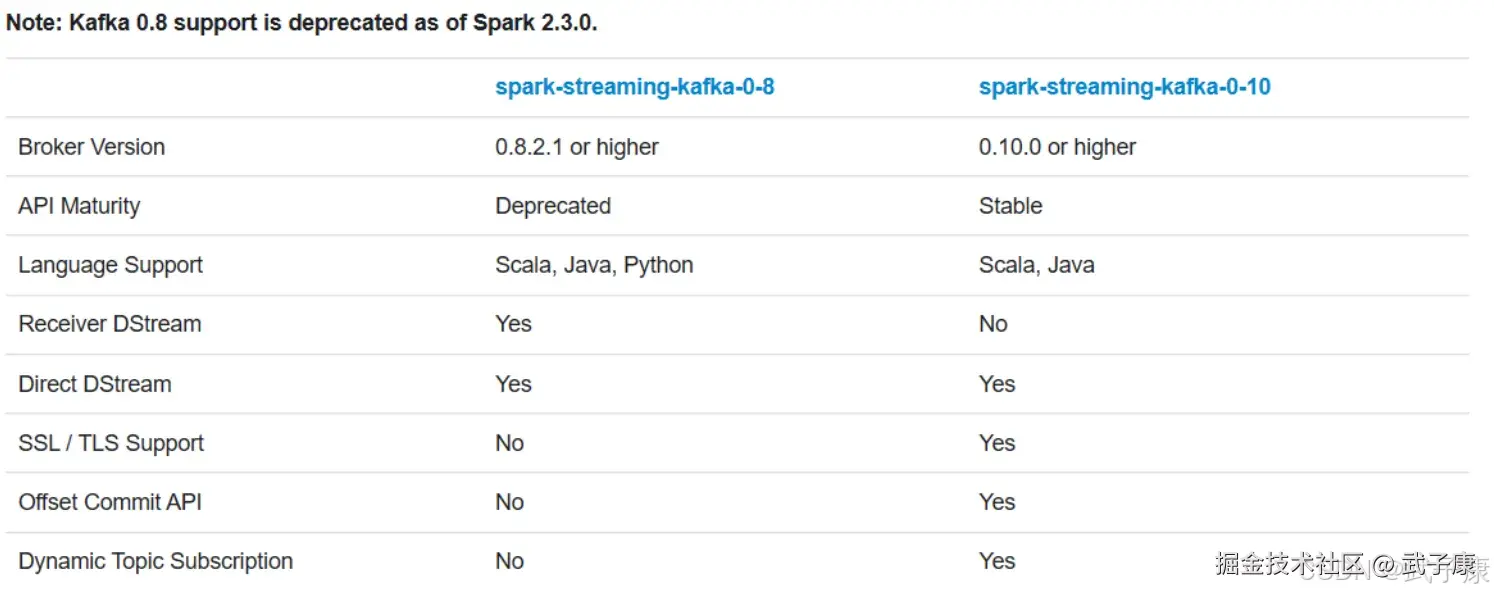 版本的发展:
版本的发展: 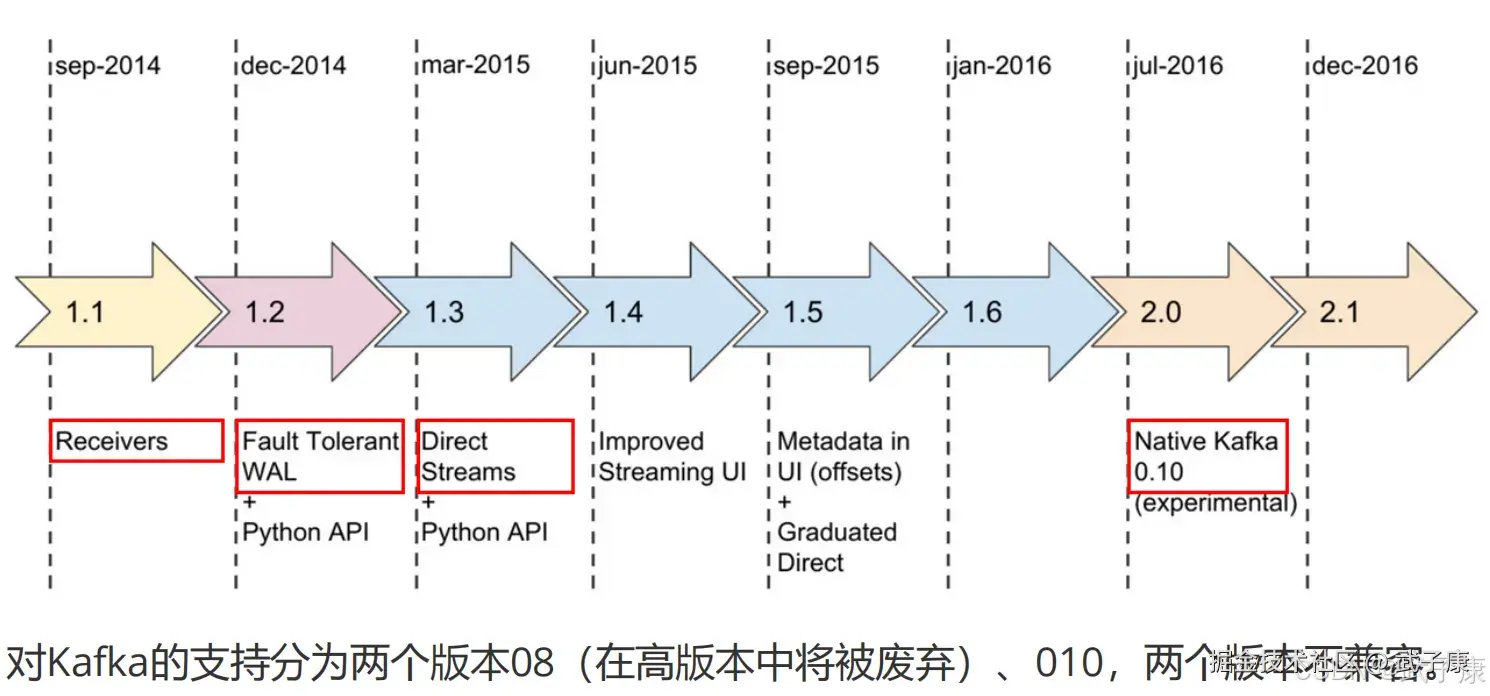
Kafka-08 接口
Receiver based Approach
基于 Receiver 的 Kafka 消费方式采用 Kafka 旧版本(0.8.2.1 及之前版本)的高阶消费者 API 实现。这种方式的整体工作流程如下:
-
数据接收与存储:
- 每个 Receiver 作为一个长期运行的 Task 被调度到 Executor 上执行
- 接收到的 Kafka 数据首先存储在 Spark Executor 的内存中,底层通过 BlockManager 进行管理
- 默认情况下,每 200ms(由 spark.streaming.blockInterval 参数控制)会将累积的数据生成一个 Block
- 这些 Block 会被复制到其他 Executor 以实现容错(默认复制因子为 2)
-
数据处理流程:
- Spark Streaming 定期生成 Job 时,会根据这些 Block 构建 BlockRDD
- 最终这些 RDD 会被作为普通的 Spark 任务执行
- 每个 Block 对应 RDD 的一个分区,因此可以通过调整 blockInterval 来控制 RDD 的分区数量
-
关键特性与注意事项:
Receiver 部署特性:
- 每个 Receiver 作为一个常驻线程运行在 Executor 上,会持续占用一个 CPU 核心
- Receiver 数量由调用 KafkaUtils.createStream() 的次数决定,每次调用创建一个 Receiver
- 可通过多个 createStream() 调用来实现多个 Receiver 并行消费
并行度限制:
- Kafka Topic 的分区数与 Spark RDD 分区数没有直接关联
- 增加 Kafka Topic 的分区数只会增加单个 Receiver 内部的消费线程数
- 实际的 Spark 处理并行度仍由 Block 数量决定
- 示例:一个 Receiver 消费 4 分区 Topic,但仍只生成单个 RDD 分区
性能考量:
- 数据本地性问题:包含 Receiver 的 Executor 会优先被调度执行 Task,可能导致集群负载不均衡
- 默认 blockInterval 为 200ms,可根据数据量调整:
- 小数据量:可适当增大间隔减少开销
- 大数据量:可减小间隔提高并行度
可靠性保障:
- 默认配置下,Receiver 方式可能在故障时丢失已接收但未处理的数据
- 可通过启用预写日志(WAL)提高可靠性:
- 设置 spark.streaming.receiver.writeAheadLog.enable=true
- 数据会先写入 HDFS 等可靠存储
- 但会带来额外的磁盘 IO 开销,降低吞吐量约 10-20%
-
典型应用场景:
- 适合对延迟不敏感、吞吐量适中的场景
- 当需要与 Kafka 0.8.x 旧版本兼容时
- 需要简单实现 Exactly-once 语义时可结合 WAL 使用
- 不适合需要高吞吐、低延迟或严格资源隔离的场景
Kafka-08接口(Receiver方式)
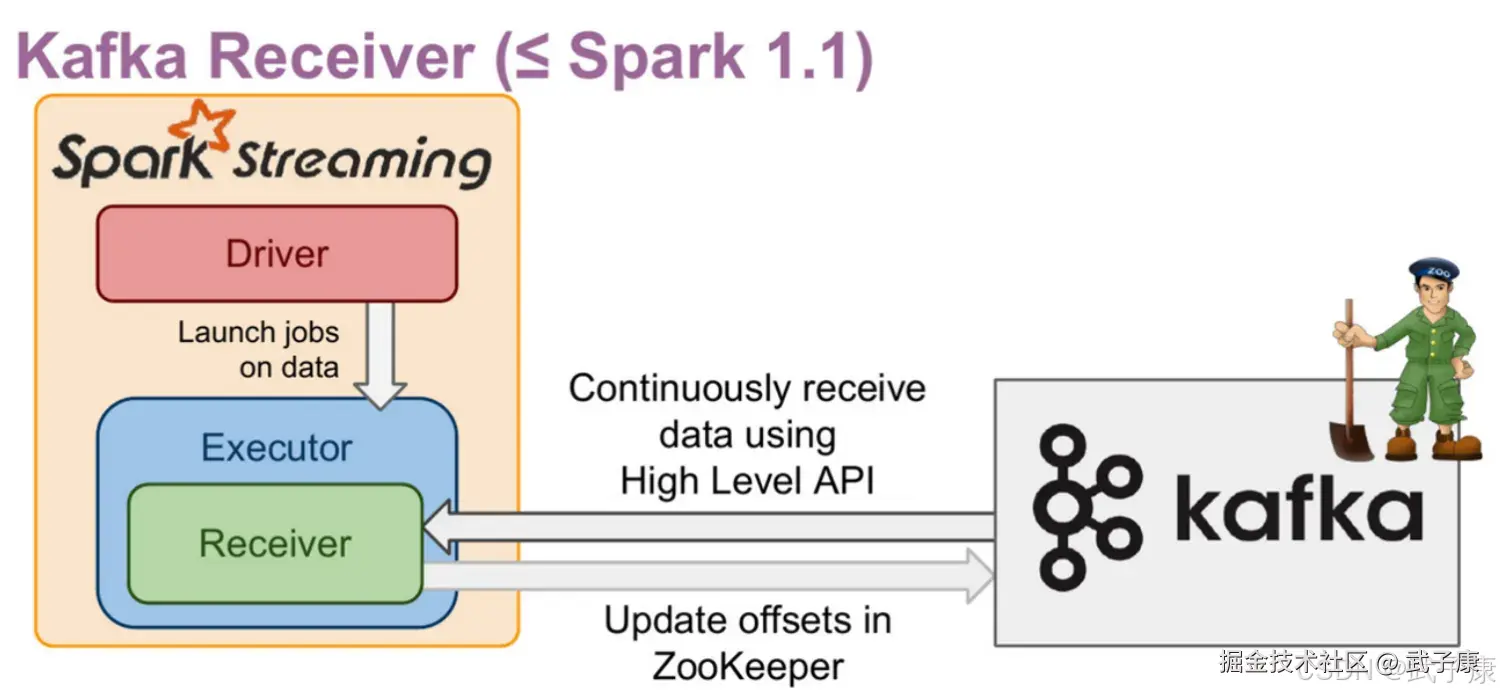
- Offset 保存在ZK中,系统管理
- 对应Kafka版本 0.8.2.1 +
- 接口底层实现使用Kafka旧版消费者 高阶API
- DStream底层实现为BlockRDD
Kafka-08接口(Receiver with WAL)
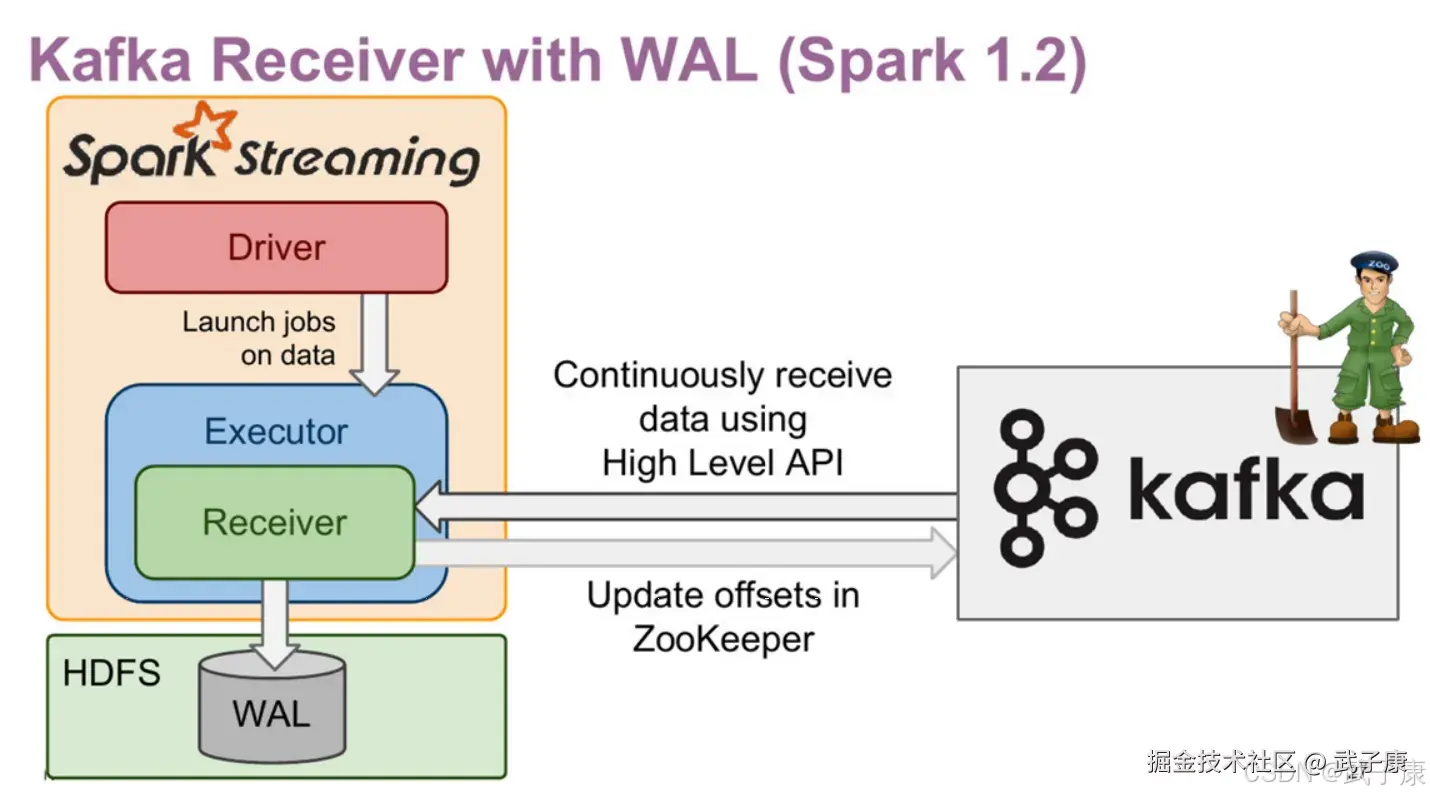
- 增强了故障恢复的能力
- 接收的数据与Driver的元数据保存到HDFS
- 增加了流式应用处理的延迟
Direct Approach
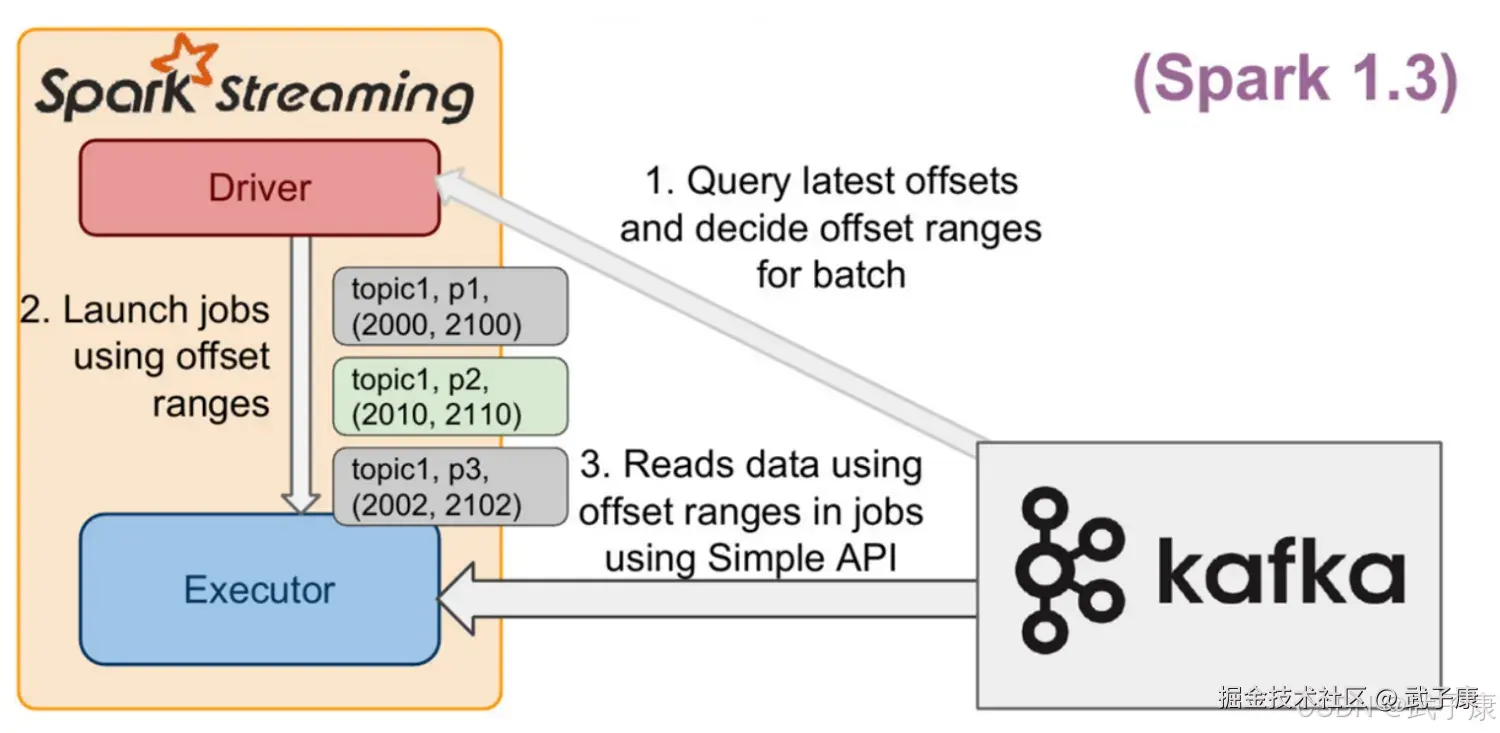 Direct Approach 是 Spark Streaming 不使用 Receiver 集成 Kafka 的方式,在企业生产环境中使用较多,相较于 Receiver,有以下特点:
Direct Approach 是 Spark Streaming 不使用 Receiver 集成 Kafka 的方式,在企业生产环境中使用较多,相较于 Receiver,有以下特点:
- 不使用 Receiver,减少不必要的CPU占用,减少了 Receiver接收数据写入BlockManager,然后运行时再通过 BlockId、网络传输、磁盘读取等来获取数据的整个过程,提升了效率,无需WAL,进一步减少磁盘IO
- Direct方式生的RDD是KafkaRDD,它的分区数与Kafka分区数保持一致,便于把控并行度。注意:在Shuffle 或 Repartition 操作后生成的 RDD,这种对应关系会失效
- 可以手动维护 Offset,实现 Exactly Once 语义
Kafka-10 接口
Spark Streaming 与 Kafka 0.10整合,和 0.8版本的Direct方式很像,Kafka的分区和Spark的RDD分区是一一对应的,可以获取 Offsets 和 元数据,API使用起来没有显著的区别。
添加依赖
xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency>不要手动添加 org.apache.kafka相关的依赖,如 kafka-clients,spark-streaming-kafka-0-10已经包含相关的依赖了,不同的版本会有不同程度的不兼容。
使用 kafka010接口从Kafka中获取数据:
- Kafka集群
- Kafka生产者发送数据
- Spark Streaming 程序接收数
KafkaProducer
编写代码
scala
package icu.wzk
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.codehaus.jackson.map.ser.std.StringSerializer
import java.util.Properties
object KafkaProducerTest {
def main(args: Array[String]): Unit = {
// 定义 Kafka 参数
val brokers = "h121.wzk.icu:9092"
val topic = "topic_test"
val prop = new Properties()
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
// KafkaProducer
val producer = new KafkaProducer[String, String](prop)
for (i <- 1 to 1000) {
val msg = new ProducerRecord[String, String](topic, i.toString, i.toString)
// 发送消息
producer.send(msg)
println(s"i = $i")
Thread.sleep(100)
}
producer.close()
}
}运行测试
shell
i = 493
i = 494
i = 495
i = 496
i = 497
i = 498
i = 499
i = 500
i = 501
i = 502
i = 503
i = 504运行过程截图为: 
查看Kafka
我们在服务器上查看当前Kafka中的队列信息:
shell
kafka-topics.sh --list --zookeeper h121.wzk.icu:2181可以看到队列已经加入了,spark_streaming_test01: 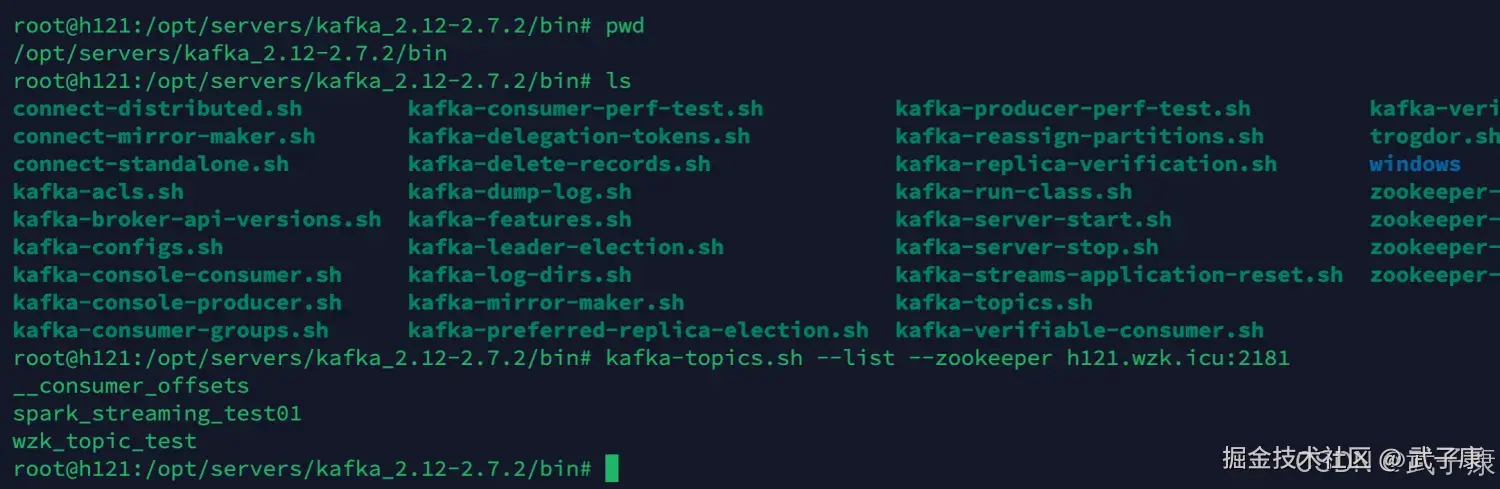
KafkaDStream
编写代码
scala
package icu.wzk
object KafkaDStream1 {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR)
val conf = new SparkConf()
.setAppName("KafkaDStream1")
.setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(2))
val kafkaParams: Map[String, Object] = getKafkaConsumerParameters("wzkicu")
val topics: Array[String] = Array("spark_streaming_test01")
// 从 Kafka 中获取数据
val dstream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils
.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams))
// dstream输出
dstream.foreachRDD {
(rdd, time) => if (!rdd.isEmpty()) {
println(s"========== rdd.count = ${rdd.count()}, time = $time ============")
}
}
ssc.start()
ssc.awaitTermination()
}
private def getKafkaConsumerParameters(groupId: String): Map[String, Object] = {
Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "h121.wzk.icu:9092",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "earliest",
ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG -> (false: java.lang.Boolean)
)
}
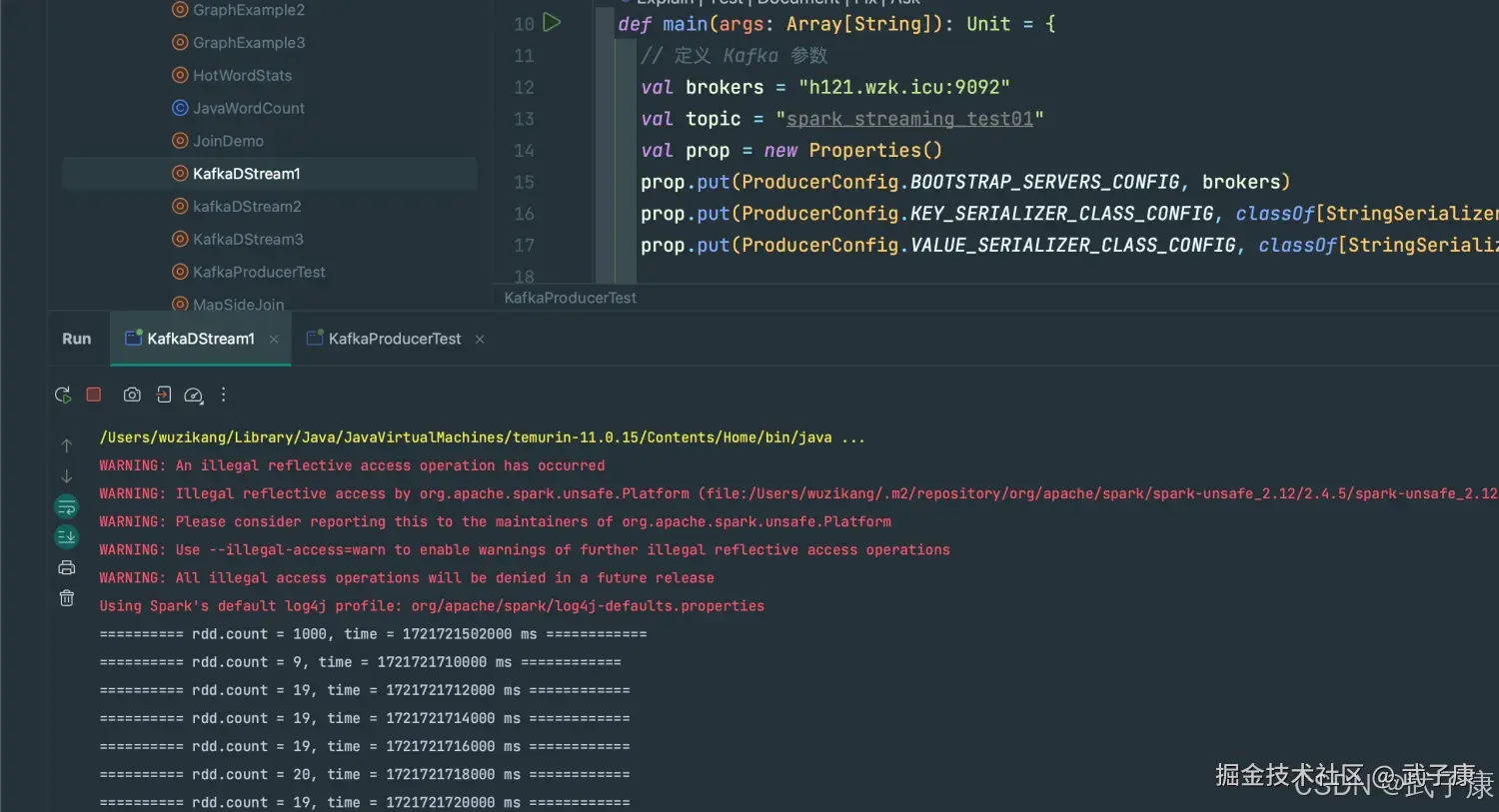
}运行结果
shell
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/Users/wuzikang/.m2/repository/org/apache/spark/spark-unsafe_2.12/2.4.5/spark-unsafe_2.12-2.4.5.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
========== rdd.count = 1000, time = 1721721502000 ms ============运行截图如下: 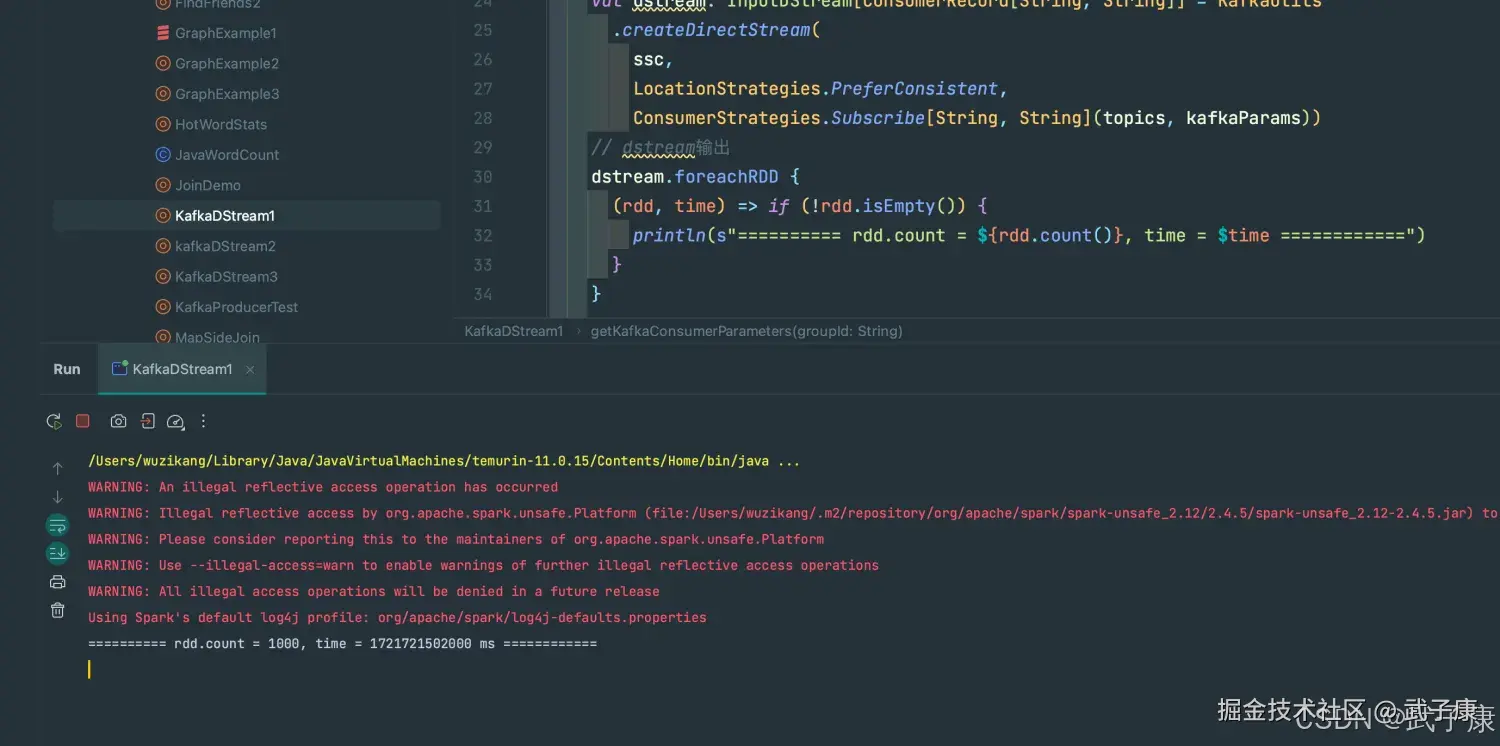
生成数据
继续启动 KafkaProducer 的程序,让数据不断地写入 我们会看到控制台输出内容如下:
shell
========== rdd.count = 1000, time = 1721721502000 ms ============
========== rdd.count = 9, time = 1721721710000 ms ============
========== rdd.count = 19, time = 1721721712000 ms ============
========== rdd.count = 19, time = 1721721714000 ms ============
========== rdd.count = 19, time = 1721721716000 ms ============
========== rdd.count = 20, time = 1721721718000 ms ============
========== rdd.count = 19, time = 1721721720000 ms ============
========== rdd.count = 19, time = 1721721722000 ms ============
========== rdd.count = 19, time = 1721721724000 ms ============运行结果如下图所示: