一、概述
仅需0.5B参数,VoxCPM就能用你的声音说任何话:这款开源语音模型在音色克隆和情感表达上突破极限,实时生成媲美真人的播报、演讲甚至方言,错误率低至行业新标杆。
在语音合成技术快速发展的背景下,面壁智能与清华大学深圳国际研究生院人机语音交互实验室(THUHCSI)近日联合发布了一款新型语音生成模型 ------VoxCPM。这款模型以0.5B 的参数尺寸,致力于为用户提供高质量、自然的语音合成体验。
VoxCPM 的推出标志着高拟真语音生成领域的又一里程碑。该模型在自然度、音色相似度及韵律表现力等关键指标上,均达到了行业领先水平。通过零样本声音克隆技术,VoxCPM 能够以极少的数据,生成用户独特的声音,从而实现个性化的语音合成。这一技术进步为语音生成的应用场景带来了更多可能性,尤其是在个性化语音助手、游戏角色配音等领域。

据悉,VoxCPM 已在 GitHub、Hugging Face 等平台开源,并为开发者提供了线上体验平台,便于用户探索和使用其强大功能。模型在权威语音合成评测榜单 Seed-TTS-EVAL 中表现出色,尤其是在词错误率和音色相似度方面取得了极低的错误率,展示了其卓越的推理效率。在一张 NVIDIA RTX4090显卡上,VoxCPM 的实时因子(RTF)达到约0.17,满足了高质量实时交互的需求。
VoxCPM 不仅在技术性能上有所突破,其在音质和情感表达方面也表现出色。模型能够根据文本内容智能选择合适的声音、腔调和韵律,模拟出与真人无异的听感。无论是气象播报、英雄演讲,还是方言主播,VoxCPM 都能精准再现,提供沉浸式的听觉体验。
此外,VoxCPM 的技术架构基于最新的扩散自回归语音生成模型,融合了层次化语言建模和局部扩散生成的连续表征,显著提升了生成语音的表现力与自然度。该模型的核心架构包括多个模块,协同工作,实现了高效的 "语义 - 声学" 生成过程。
🔗 Github:
https://github.com/OpenBMB/VoxCPM/
🔗 Hugging Face:
https://huggingface.co/openbmb/VoxCPM-0.5B
🔗 ModelScope:
https://modelscope.cn/models/OpenBMB/VoxCPM-0.5B
🔗 PlayGround体验:
https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo
🔗 音频样例页面地址:
https://openbmb.github.io/VoxCPM-demopage
二、音频样例
打开音频样例页面地址:
https://openbmb.github.io/VoxCPM-demopage
这里列举几个
宝儿姐
叫啥子叫,之前不是说了吗,有姐罩着你呢。那个啥子,小师叔,打狗还要看主人呢,你要是再继续的话,我就是你的对手方言
风车车,你不要跑,我来抓你来咯!你莫怪老子心狠手辣哈,哪个叫你娃儿不听话?抓住你,我就要把你做成耗儿肉!粤语
九流十家無一能,八仙過海七星聚,六親不認五更雞,四海為家三餐飽,兩手空空一場夢。数学符号标识
沸羊羊,如果 △ABC∽△DEF,且AB:DE=1:2,那我问你,△ABC的面积与△DEF的面积之比是多少?这里比较亮眼的是,VoxCPM居然支持方言。因为一般的语言生成模型,比如Index-TTS2,只支持普通话 ,即使原始的音频是方言,输出的也依然是普通话。
还有一点,VoxCPM也支持比较复杂的数学符号
三、实战音频输出
Microsoft C++ Build Tools
注意:windows11安装voxcpm模块会提示报错,因为缺少一些编译环境。
官方地址:https://visualstudio.microsoft.com/zh-hant/visual-cpp-build-tools/
下载安装
代码生成
访问github地址:https://github.com/OpenBMB/VoxCPM/
下载代码到本地,安装模块
pip install voxcpm下载模型VoxCPM-0.5B
pip install modelscope
modelscope download --model OpenBMB/VoxCPM-0.5B下载ZipEnhancer和SenseVoice Small。在网络演示中,我们使用ZipEnhancer增强语音提示,使用SenseVoice Small增强语音提示ASR。
modelscope download --model iic/speech_zipenhancer_ans_multiloss_16k_base
modelscope download --model iic/SenseVoiceSmall基本用法
import soundfile as sf
import numpy as np
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")
# Non-streaming
wav = model.generate(
text="VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech.",
prompt_wav_path=None, # optional: path to a prompt speech for voice cloning
prompt_text=None, # optional: reference text
cfg_value=2.0, # LM guidance on LocDiT, higher for better adherence to the prompt, but maybe worse
inference_timesteps=10, # LocDiT inference timesteps, higher for better result, lower for fast speed
normalize=True, # enable external TN tool
denoise=True, # enable external Denoise tool
retry_badcase=True, # enable retrying mode for some bad cases (unstoppable)
retry_badcase_max_times=3, # maximum retrying times
retry_badcase_ratio_threshold=6.0, # maximum length restriction for bad case detection (simple but effective), it could be adjusted for slow pace speech
)
sf.write("output.wav", wav, 16000)
print("saved: output.wav")
# Streaming
chunks = []
for chunk in model.generate_streaming(
text = "Streaming text to speech is easy with VoxCPM!",
# supports same args as above
):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("output_streaming.wav", wav, 16000)
print("saved: output_streaming.wav")例如,要生成宝儿姐的语音
先下载音频文件,地址:https://openbmb.github.io/VoxCPM-demopage/audio/dialect_zeroshot/prompt_wav/baoerjie.wav
修改代码
import soundfile as sf
import numpy as np
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")
# Non-streaming
wav = model.generate(
text="叫啥子叫,之前不是说了吗,有姐罩着你呢。那个啥子,小师叔,打狗还要看主人呢,你要是再继续的话,我就是你的对手",
# optional: path to a prompt speech for voice cloning
prompt_wav_path="baoerjie.wav",
prompt_text="他们总说我瓜,其实我一点儿都不瓜,大多时候我都机智的一笔。", # optional: reference text
# LM guidance on LocDiT, higher for better adherence to the prompt, but maybe worse
cfg_value=2.0,
# LocDiT inference timesteps, higher for better result, lower for fast speed
inference_timesteps=10,
normalize=True, # enable external TN tool
denoise=True, # enable external Denoise tool
# enable retrying mode for some bad cases (unstoppable)
retry_badcase=True,
retry_badcase_max_times=3, # maximum retrying times
# maximum length restriction for bad case detection (simple but effective), it could be adjusted for slow pace speech
retry_badcase_ratio_threshold=6.0,
)
sf.write("output.wav", wav, 16000)
print("saved: output.wav")
# Streaming
chunks = []
for chunk in model.generate_streaming(
text="Streaming text to speech is easy with VoxCPM!",
# supports same args as above
):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("output_streaming.wav", wav, 16000)
print("saved: output_streaming.wav")执行代码,等待5分钟,会生成文件output.wav,试听一下,就是上面的实例效果。
CLI方式生成
本地新建文件1.txt,内容如下:
他们总说我瓜,其实我一点儿都不瓜,大多时候我都机智的一笔。执行命令:
voxcpm --model-path "D:\file\lmstudio\model\OpenBMB\VoxCPM-0___5B" --text "叫啥子叫,之前不是说了吗,有姐罩着你呢。那个啥子,小师叔,打狗还要看主人呢,你要是再继续的话,我就是你的对手" --prompt-audio baoerjie.wav --prompt-file "1.txt" --output out.wav --denoise等待5分钟,会生成文件out.wav,试听一下,就是上面的实例效果。
web页面生成
可以通过运行python app.py启动UI界面,它允许您执行语音克隆和语音创建。
执行命令:
python app.py输出:
🚀 Running on device: cuda
funasr version: 1.2.7.
Downloading Model to directory: C:\Users\xiao\.cache\modelscope\hub\iic/SenseVoiceSmall
2025-09-23 17:05:28,488 - modelscope - WARNING - Using branch: master as version is unstable, use with caution
WARNING:root:trust_remote_code: False
* Running on local URL: http://localhost:7860打开网页地址:http://localhost:7860
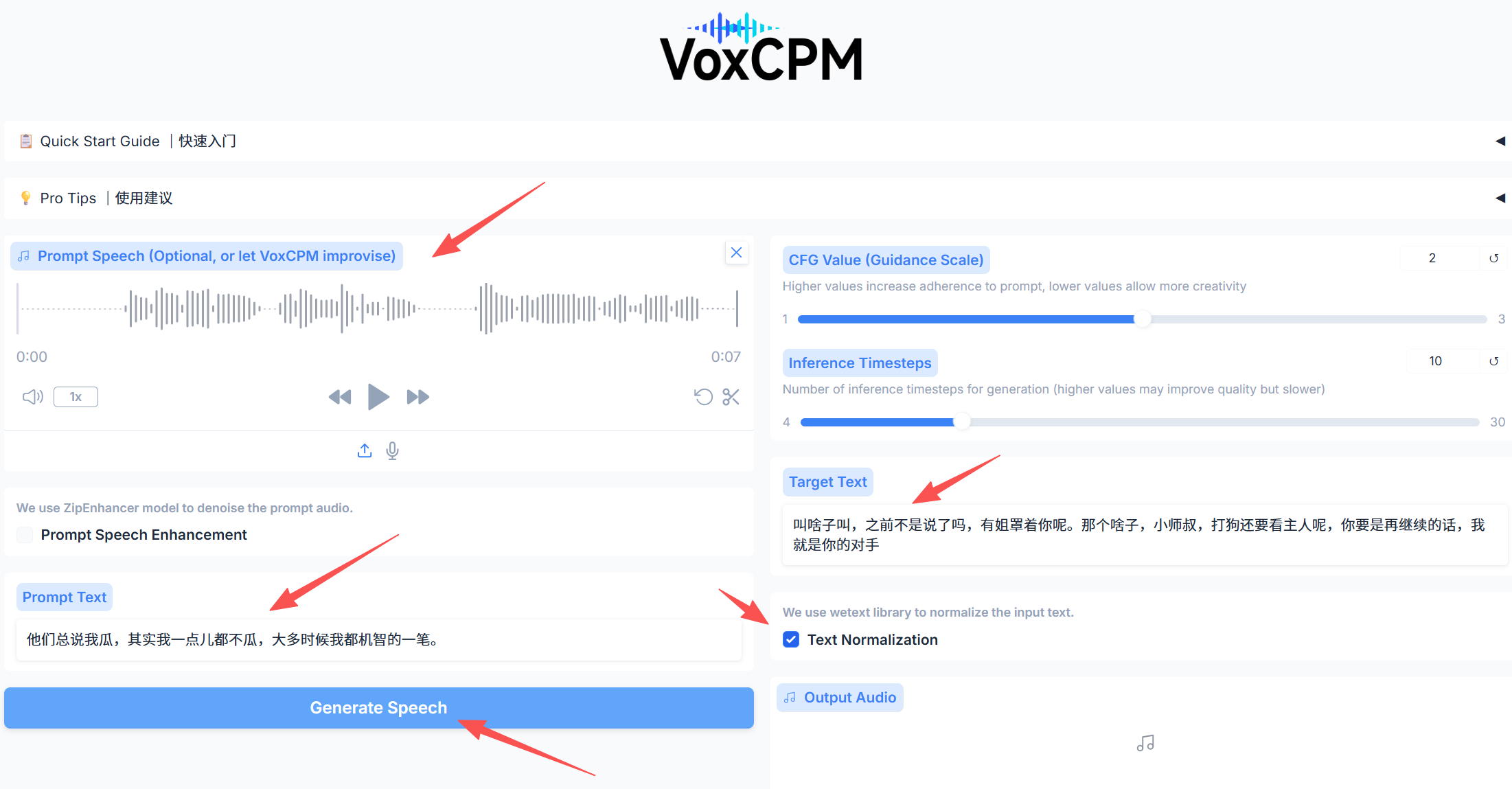
效果如下:
上传音频文件,修改Prompt Text和Target Text,点击Generate Speech,生成语音
等待5分钟,会生成文件out.wav,试听一下,就是上面的实例效果。