打开终端,选择一个目录,执行git clone https://github.com/langgenius/dify.git克隆dify项目
打开文件管理器,进入dify项目的docker文件夹,将.env.example文件复制并改名为.env
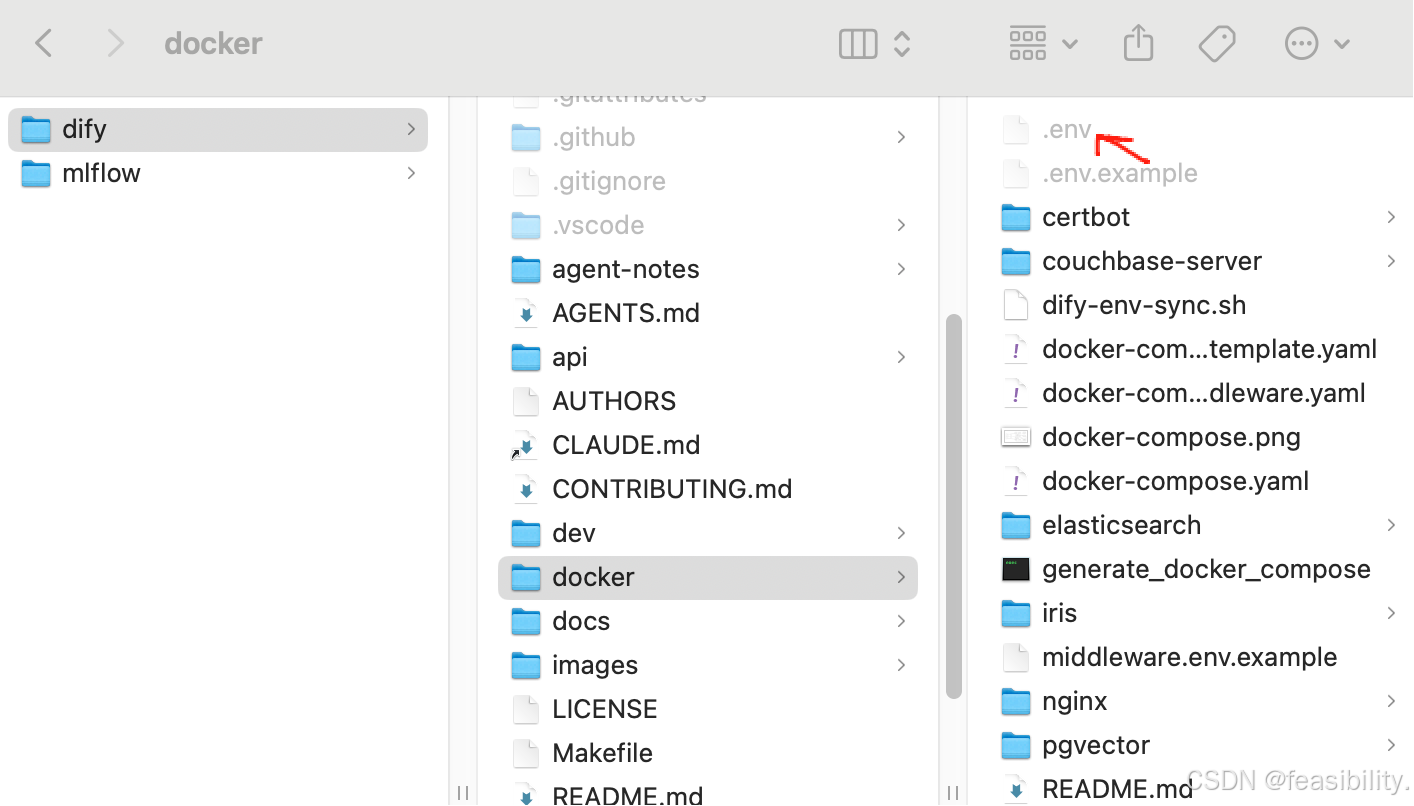
终端进入执行,进入dify项目的docker文件夹,执行docker compose up -d,出现图中的报错需要先启动docker
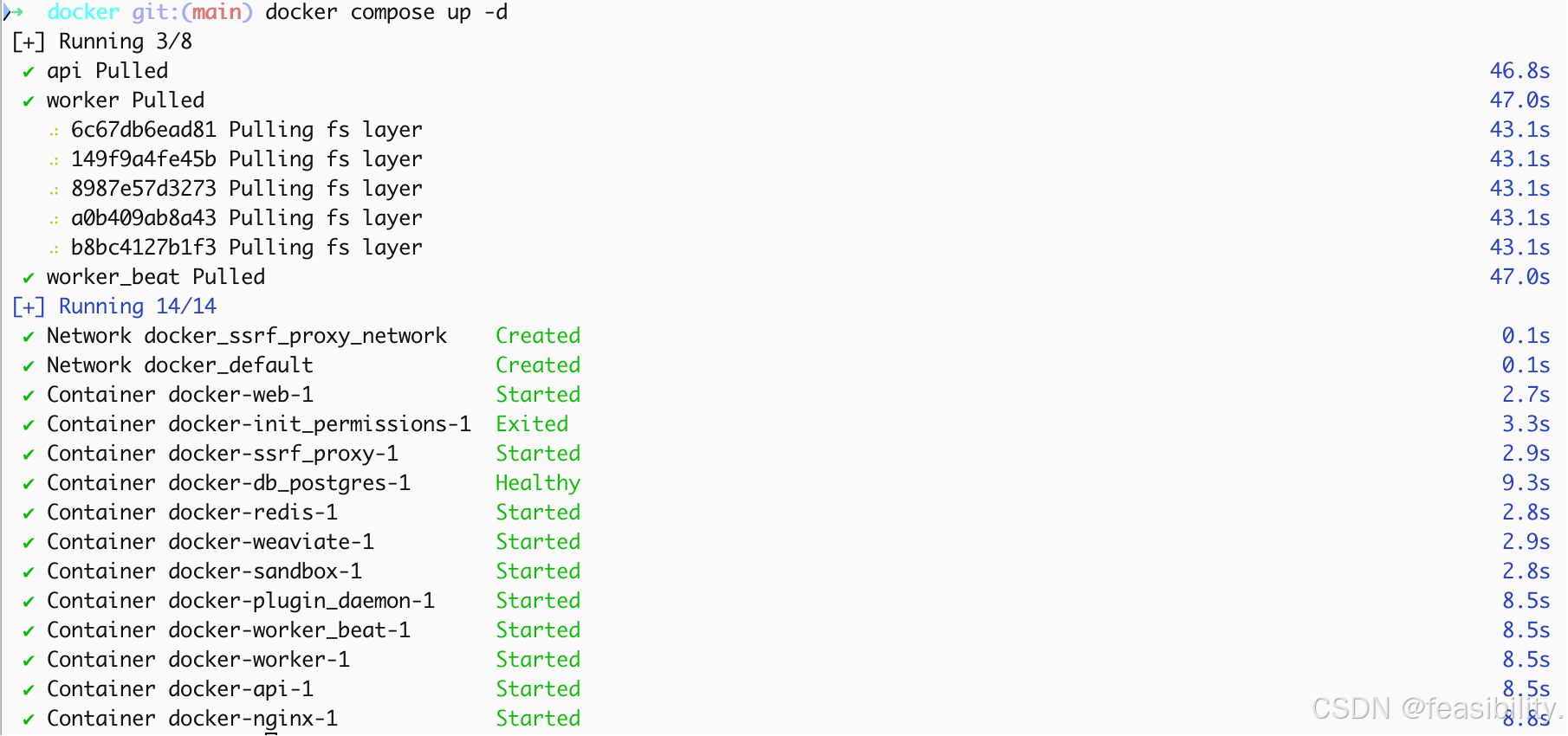
若执行docker compose up -d过程出现类似报错failed to extract layer (application/vnd.oci.image.layer.v1.tar+gzip sha256:b8bc4127b1f38e33dba73c3fa3086d6d9e679b4e8b48893bfc340bb36626c85f) to overlayfs as "extract-70202844-MAT- sha256:66be5b59489bf8798fcb90588a24c22076d1aa2f3c471c7520731bf798864501": open /var/lib/desktop-containerd/daemon/io.containerd.snapshotter.v1.overlayfs/snapshots/380/fs/app/api/.venv/lib/python3.12/site-packages/sympy/printing/rcode.py: input/output error,说明磁盘空间不足,可执行以下清理缓存
bash
# 清理构建缓存 + 悬空镜像 + 未使用卷 + 未使用网络
docker builder prune -a -f && \
docker images -f "dangling=true" -q | xargs -r docker rmi && \
docker volume prune -f && \
docker network prune -f如果想改docker当前项目名及容器,可参考以下命令可修改项目名为dify,对应的容器前缀也会改
bash
# 1. 先停止并删除旧项目的容器(数据卷会保留,不会丢失数据)
docker compose down
# 2. 用新项目名启动,所有容器会以dify-为前缀
docker compose -p dify up -d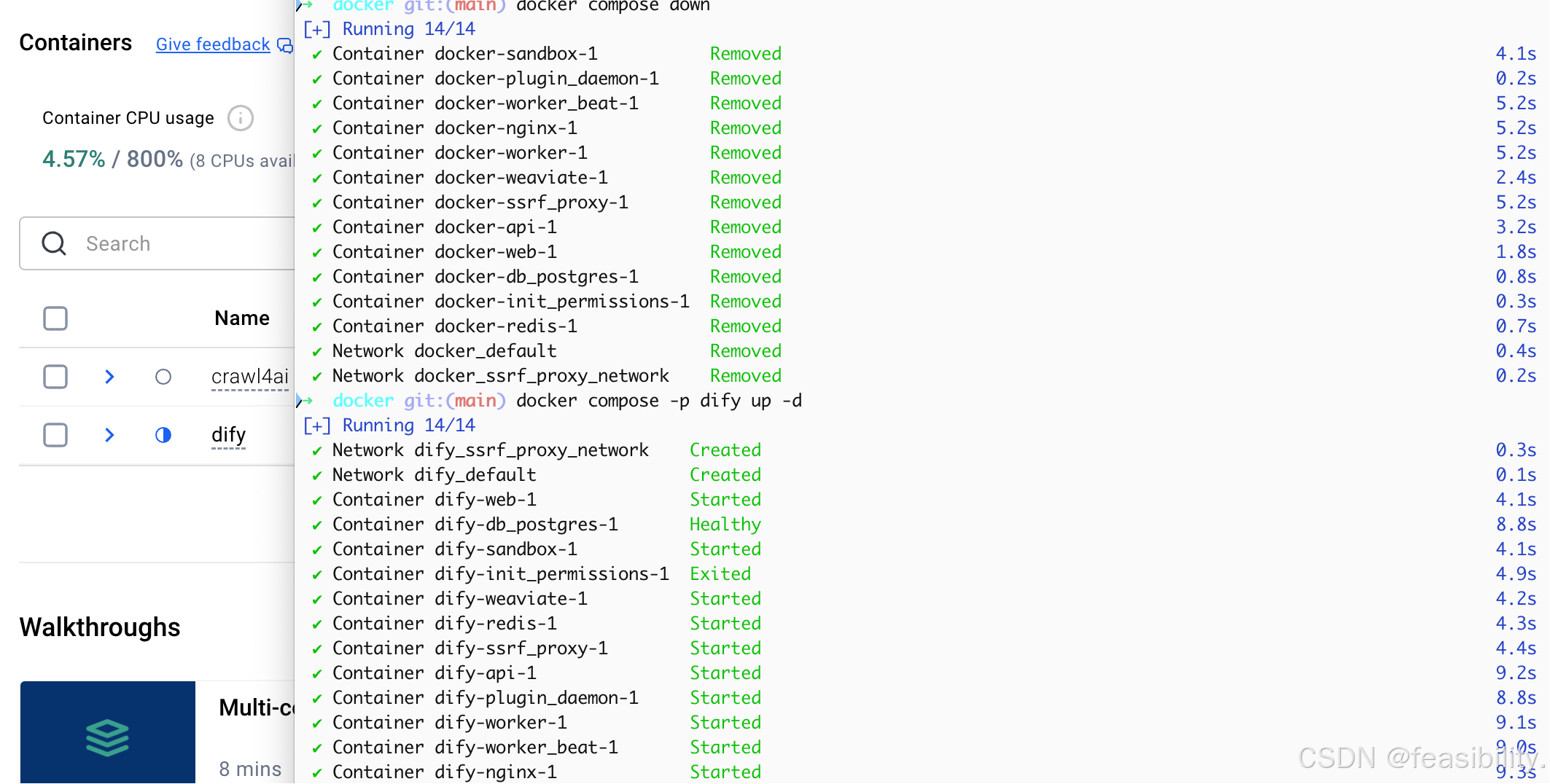
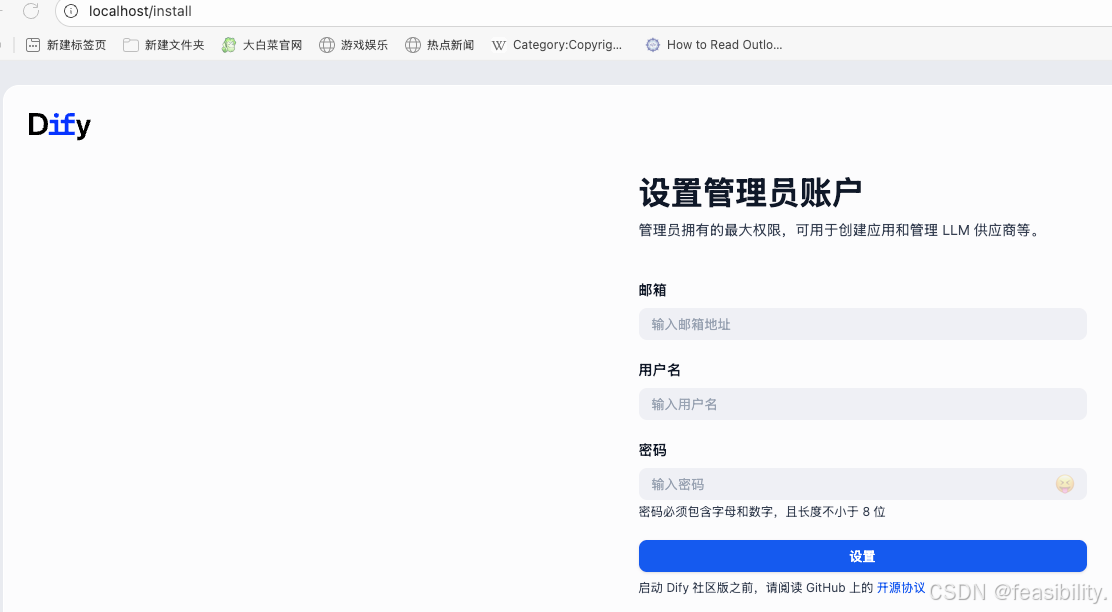
打开http://localhost/install注册邮箱和密码
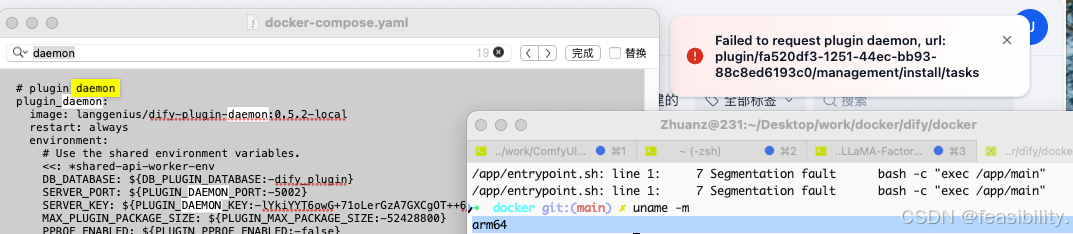
注册后跳转页面,出现Failed to request plugin daemon, 报错,因为本人电脑上arm64架构,而plugin-daemon这个镜像/二进制,默认版本支持x86,对 ARM64 特别敏感,plugin daemon 是一个编译型二进制核心服务,而且它还要和 sandbox / wasm / runtime 打交道,一旦架构不对,会出现段错误 segfault,需要修改dify目录的docker子文件夹的docker-composer.yaml文件
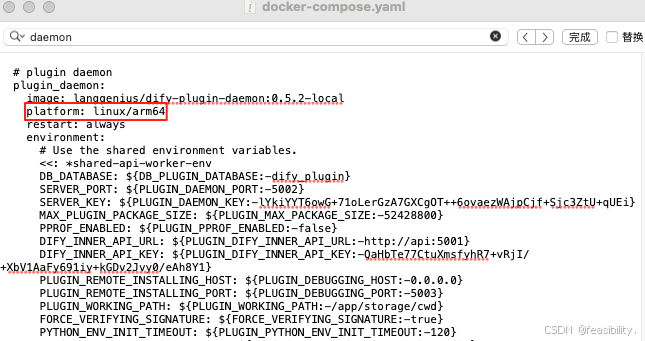
 增加platform: linux/arm64,保存
增加platform: linux/arm64,保存
重新启动
bash
docker compose down
docker compose pull
docker compose -p dify up -d依然报错,这说明镜像本身 ARM64 不兼容,尝试改为 platform: linux/amd64寻找可用 x86模拟版本
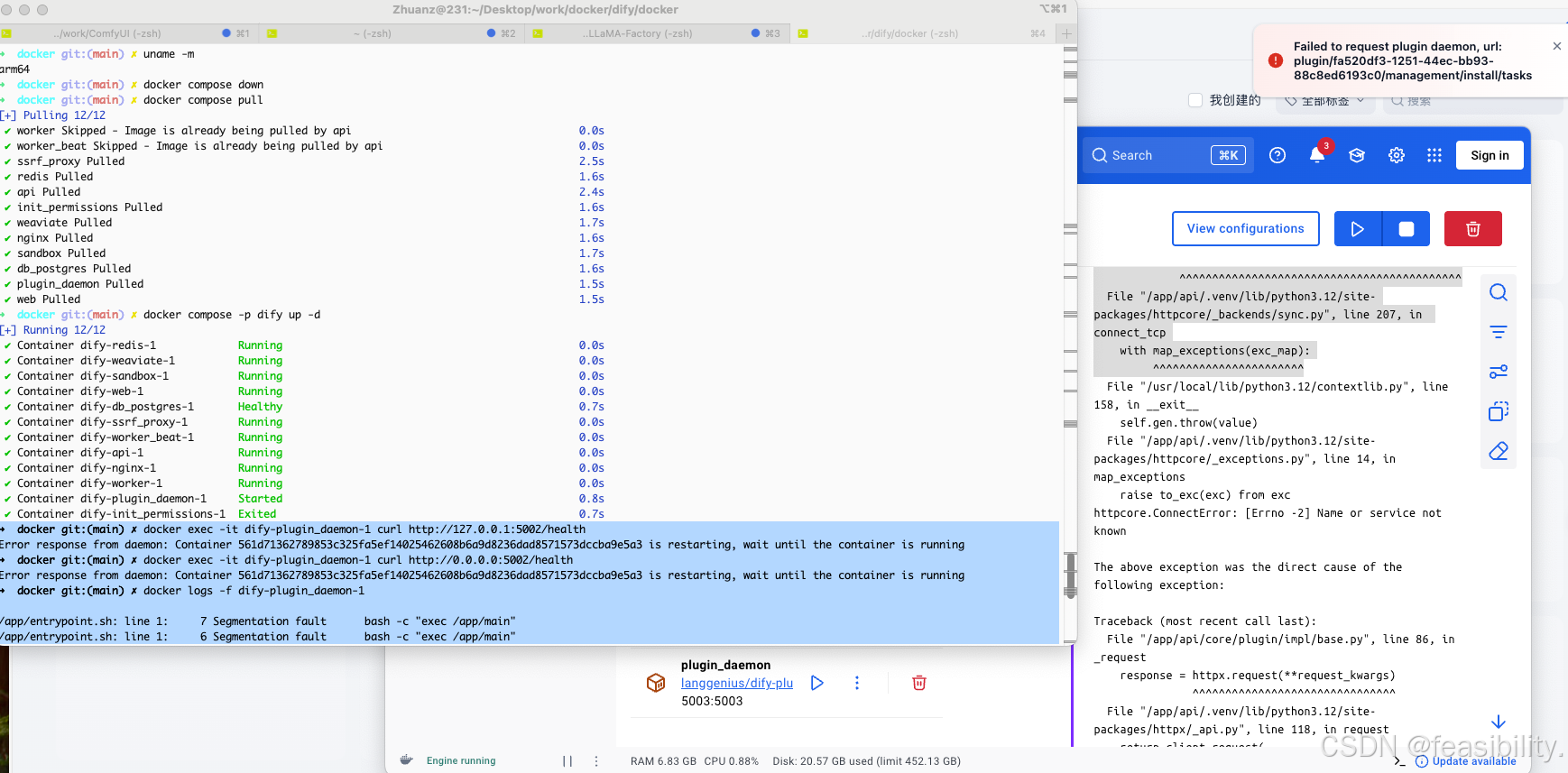
修改后重新启动,不再出现报错
执行命令安装PostgreSQL 17,用来存放商品数据
# 安装 PostgreSQL 17
brew install postgresql@17
# 或安装 PostgreSQL 16(如果您偏好更成熟的版本)
# brew install postgresql@16
# 启动新服务
brew services start postgresql@17
安装成功,执行以下命令将PostgreSQL 17添加到环境变量
bash
# 将 PostgreSQL 17 添加到 PATH(优先于旧版本)
echo 'export PATH="/opt/homebrew/opt/postgresql@17/bin:$PATH"' >> ~/.zshrc
# 立即生效
source ~/.zshrc
# 验证版本(应该显示 17.7)
psql --version添加环境变量成功

执行命令安装安装 pgvector用于存储商品的图片向量
bash
# 安装 pgvector 扩展
brew install pgvector
# 连接到数据库并启用扩展
psql postgres -c "CREATE EXTENSION IF NOT EXISTS vector;"
# 验证安装
psql postgres -c "SELECT * FROM pg_available_extensions WHERE name = 'vector';"成功安装 pgvector
到https://hf-mirror.com/Qwen/Qwen3-VL-2B-Instruct下载模型
下载https://hf-mirror.com/Qwen/Qwen3-VL-Embedding-2B/tree/main的检索模型及其脚本,同样也下载https://hf-mirror.com/Qwen/Qwen3-VL-Reranker-2B 的重排序模型及其脚本
qwen3-vl项目文件夹的model情况参考
qwen3-vl项目文件夹的scripts文件夹
配置python环境
执行uv pip install psycopg2-binary安装操作PostgreSQL的库psycopg2
因为pgvector 的 vector 类型在创建 HNSW 索引时有硬限制2000维,lfvec 类型可支持到 4000 维,而 Qwen3-VL-Embedding-2B 输出的是 2048维 向量,所以采用halfvec 类型
编写清洗商品数据clean-goods.py脚本
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Qwen3-VL 商品数据清洗脚本
功能:
1. 使用 Qwen3-VL-2B-Instruct 生成商品文案、视觉描述、结构化标签
2. 使用 Qwen3-VL-Embedding-2B 生成文本和图片向量(2048维)
3. 存储到 PostgreSQL + pgvector
4. 支持测试模式(小批量验证)和全量处理(带进度条)
"""
import os
import sys
import json
import time
import logging
from datetime import datetime, timedelta
from typing import List, Dict, Optional, Tuple
import numpy as np
import pandas as pd
from PIL import Image
from tqdm import tqdm
import psycopg2
from psycopg2 import sql
from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMIT
from scripts.qwen3_vl_embedding import Qwen3VLEmbedder
# 模型相关
import torch
from transformers import (
Qwen3VLForConditionalGeneration,
AutoProcessor
)
# 配置区
CONFIG = {
# 模型路径(本地)
"model_paths": {
"instruct": "/Users/Zhuanz/Desktop/work/Qwen3-VL/model/Qwen3-VL-2B-Instruct",
"embedding": "/Users/Zhuanz/Desktop/work/Qwen3-VL/model/Qwen3-VL-Embedding-2B"
},
# 数据源路径
"data": {
"csv_path": "/Users/Zhuanz/Desktop/work/spider/jd_data_merged/all_data.csv",
"image_dir": "/Users/Zhuanz/Desktop/work/spider/jd_data_merged/images"
},
# 数据库配置(无密码,本地开发环境)
"db": {
"host": "localhost",
"port": 5432,
"database": "jd_products",
"user": "Zhuanz", # 默认用户postgres,无密码,对Mac用户应该改用Mac用户名
"password": None # 无密码
},
# 处理参数
"batch_size": 4, # 根据16GB内存调整,建议4-8
"test_limit": 5, # 测试模式处理数量
"image_max_size": 448, # Qwen3-VL标准输入尺寸
# 向量维度(Qwen3-VL-Embedding-2B)
"vector_dim": 2048
}
# 设置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('cleaning.log', encoding='utf-8'),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
class DatabaseManager:
"""PostgreSQL + pgvector 管理"""
def __init__(self, config: Dict):
self.config = config
self.conn = None
self.cursor = None
def connect(self, dbname: str = None):
"""连接数据库"""
try:
params = {
"host": self.config["host"],
"port": self.config["port"],
"user": self.config["user"],
"password": self.config["password"] or "",
}
if dbname:
params["dbname"] = dbname
self.conn = psycopg2.connect(**params)
self.conn.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT)
self.cursor = self.conn.cursor()
logger.info(f"✅ 成功连接到 PostgreSQL (数据库: {dbname or 'postgres'})")
return True
except Exception as e:
logger.error(f"❌ 数据库连接失败: {e}")
return False
def create_database(self):
"""创建数据库(如果不存在)"""
try:
# 先连接到默认postgres数据库
self.connect("postgres")
# 检查数据库是否存在
self.cursor.execute(
"SELECT 1 FROM pg_database WHERE datname = %s",
(self.config["database"],)
)
exists = self.cursor.fetchone()
if not exists:
# 创建数据库
self.cursor.execute(
sql.SQL("CREATE DATABASE {}").format(
sql.Identifier(self.config["database"])
)
)
logger.info(f"✅ 创建数据库: {self.config['database']}")
else:
logger.info(f"ℹ️ 数据库已存在: {self.config['database']}")
self.close()
# 连接到新数据库
self.connect(self.config["database"])
# 启用pgvector扩展
self.cursor.execute("CREATE EXTENSION IF NOT EXISTS vector;")
#self.cursor.execute("SELECT vector_dims('[]::vector');") # 显式转vector类型,空向量测试
logger.info("✅ pgvector 扩展已启用")
return True
except Exception as e:
logger.error(f"❌ 创建数据库失败: {e}")
return False
def create_tables(self):
"""创建商品表(使用halfvec支持2048维)"""
try:
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS products (
id VARCHAR(50) PRIMARY KEY,
source_id VARCHAR(50),
page INT,
-- 基础信息
title TEXT NOT NULL,
price DECIMAL(10,2),
price_segment VARCHAR(20),
currency VARCHAR(10) DEFAULT 'CNY',
-- 媒体信息
image_local_path TEXT,
image_url TEXT,
image_hash VARCHAR(64),
-- Qwen3-VL生成的内容(JSONB存储)
generated_content JSONB,
-- 文本向量(2048维,使用halfvec)
text_embedding halfvec({CONFIG['vector_dim']}),
-- 图片向量(2048维,使用halfvec)
image_embedding halfvec({CONFIG['vector_dim']}),
-- 搜索优化字段
searchable_text TEXT,
combined_tags TEXT[],
-- 元数据
status VARCHAR(20) DEFAULT 'success',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建向量索引(使用halfvec_cosine_ops)
CREATE INDEX IF NOT EXISTS idx_text_embedding
ON products USING hnsw (text_embedding halfvec_cosine_ops);
CREATE INDEX IF NOT EXISTS idx_image_embedding
ON products USING hnsw (image_embedding halfvec_cosine_ops);
-- 创建普通索引
CREATE INDEX IF NOT EXISTS idx_price ON products(price);
CREATE INDEX IF NOT EXISTS idx_tags ON products USING GIN(combined_tags);
CREATE INDEX IF NOT EXISTS idx_source ON products(source_id);
"""
self.cursor.execute(create_table_sql)
logger.info("✅ 表和索引创建成功(使用halfvec支持2048维)")
return True
except Exception as e:
logger.error(f"❌ 创建表失败: {e}")
return False
def insert_product(self, data: Dict) -> bool:
"""插入单条商品数据"""
try:
sql = """
INSERT INTO products (
id, source_id, page, title, price, price_segment,
image_local_path, image_url,
generated_content, text_embedding, image_embedding,
searchable_text, combined_tags, status
) VALUES (
%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s
)
ON CONFLICT (id) DO UPDATE SET
generated_content = EXCLUDED.generated_content,
text_embedding = EXCLUDED.text_embedding,
image_embedding = EXCLUDED.image_embedding,
searchable_text = EXCLUDED.searchable_text,
combined_tags = EXCLUDED.combined_tags,
updated_at = CURRENT_TIMESTAMP;
"""
self.cursor.execute(sql, (
data['id'],
data['source_id'],
data['page'],
data['title'],
data['price'],
data['price_segment'],
data['image_local_path'],
data['image_url'],
json.dumps(data['generated_content']),
data['text_embedding'], # list转vector由psycopg2处理
data['image_embedding'],
data['searchable_text'],
data['combined_tags'],
'success'
))
return True
except Exception as e:
logger.error(f"❌ 插入数据失败 {data.get('id')}: {e}")
return False
def get_processed_ids(self) -> set:
"""获取已处理的商品ID(用于断点续传)"""
try:
self.cursor.execute("SELECT id FROM products")
rows = self.cursor.fetchall()
return {row[0] for row in rows}
except Exception as e:
logger.warning(f"⚠️ 查询已处理ID失败(可能是空表): {e}")
return set()
def get_ids_without_embeddings(self) -> set:
"""获取需要重新生成向量的商品ID(已有generated_content但无向量)"""
try:
self.cursor.execute("""
SELECT id FROM products
WHERE generated_content IS NOT NULL
AND (text_embedding IS NULL OR image_embedding IS NULL)
""")
return {row[0] for row in self.cursor.fetchall()}
except Exception as e:
logger.warning(f"⚠️ 查询待处理ID失败: {e}")
return set()
def get_embedding_progress(self) -> Tuple[int, int]:
"""获取向量生成进度(已生成/总数)"""
try:
self.cursor.execute("""
SELECT
COUNT(*) FILTER (WHERE text_embedding IS NOT NULL) as with_emb,
COUNT(*) as total
FROM products
WHERE generated_content IS NOT NULL
""")
row = self.cursor.fetchone()
return row[0], row[1]
except:
return 0, 0
def clear_embeddings(self):
"""只清空向量字段,保留结构化数据"""
try:
self.cursor.execute("""
UPDATE products
SET text_embedding = NULL, image_embedding = NULL, updated_at = CURRENT_TIMESTAMP;
""")
logger.info("🗑️ 已清空所有向量字段,准备重新生成")
return True
except Exception as e:
logger.error(f"❌ 清空向量失败: {e}")
return False
def clear_all_data(self):
"""清空所有数据(全量重置时使用)"""
try:
self.cursor.execute("TRUNCATE TABLE products RESTART IDENTITY;")
logger.info("🗑️ 已清空数据库,准备全量重新生成")
return True
except Exception as e:
logger.error(f"❌ 清空数据失败: {e}")
return False
def close(self):
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
logger.info("🔌 数据库连接已关闭")
class Qwen3VLProcessor:
"""Qwen3-VL 模型处理器(生成文案+向量)"""
def __init__(self, config: Dict):
self.config = config
self.device = self._get_device()
logger.info(f"🖥️ 使用设备: {self.device}")
self.embedder = None
self.instruct_model = None
self.instruct_processor = None
def _get_device(self):
if torch.backends.mps.is_available():
return "mps"
elif torch.cuda.is_available():
return "cuda"
return "cpu"
def load_embedding_model(self):
"""加载官方Embedding模型"""
if self.embedder is not None:
return
logger.info("🔄 正在加载 Qwen3-VL-Embedding-2B (官方实现)...")
start = time.time()
try:
# 使用官方Qwen3VLEmbedder
self.embedder = Qwen3VLEmbedder(
model_name_or_path=self.config["model_paths"]["embedding"],
max_length=512,
torch_dtype=torch.float16 if self.device != "cpu" else torch.float32,
# 不使用flash_attention_2,让transformers自动选择
)
# MPS需要手动设置设备
if self.device == "mps":
self.embedder.model = self.embedder.model.to("mps")
self.embedder.device = torch.device("mps")
# 确保processor的device也正确
if hasattr(self.embedder.processor, 'device'):
self.embedder.processor = self.embedder.processor
load_time = time.time() - start
logger.info(f"✅ Embedding模型加载完成,耗时: {load_time:.2f}s")
# 验证模型是否有效:测试一个简单向量
test_vec = self.get_text_embedding("测试")
if all(v == 0 for v in test_vec) or np.isnan(test_vec).any():
raise ValueError("模型返回零向量或NaN,加载失败")
logger.info(f"✅ 模型验证通过,向量范数: {np.linalg.norm(test_vec):.4f}")
except Exception as e:
logger.error(f"❌ Embedding模型加载失败: {e}")
raise
def load_instruct_model(self):
"""加载对话模型(用于生成文案)"""
if self.instruct_model is not None:
return
logger.info("🔄 正在加载 Qwen3-VL-2B-Instruct...")
start = time.time()
try:
self.instruct_processor = AutoProcessor.from_pretrained(
self.config["model_paths"]["instruct"],
trust_remote_code=True
)
self.instruct_model = Qwen3VLForConditionalGeneration.from_pretrained(
self.config["model_paths"]["instruct"],
dtype=torch.float16,
device_map=self.device,#"auto",
trust_remote_code=True
).eval()
load_time = time.time() - start
logger.info(f"✅ Instruct模型加载完成,耗时: {load_time:.2f}s")
except Exception as e:
logger.error(f"❌ Instruct模型加载失败: {e}")
raise
def generate_product_description(self, title: str, price: str, image_path: str) -> Dict:
"""使用Instruct模型生成商品结构化描述"""
if not os.path.exists(image_path):
logger.warning(f"⚠️ 图片不存在: {image_path}")
image = None
else:
try:
image = Image.open(image_path).convert('RGB')
# 调整尺寸
image = image.resize((448, 448))
except Exception as e:
logger.error(f"❌ 图片加载失败: {e}")
image = None
prompt = f"""分析这个商品,标题:{title},价格:{price}。
请生成以下JSON格式信息:
{{
"visual_description": "详细描述图片中的颜色、款式、材质、图案",
"target_group": ["人群标签1", "人群标签2"],
"scenes": ["使用场景1", "使用场景2"],
"style_tags": ["风格关键词1", "风格关键词2"],
"attributes": {{"颜色": "具体颜色", "材质": "面料材质", "版型": "版型特点"}},
"marketing_copy": "一段50字内的营销文案"
}}
只输出JSON,不要其他内容。"""
try:
# 构建消息
messages = [
{"role": "system", "content": "你是一个电商商品分析师。"},
{"role": "user", "content": [
{"type": "image", "image": image} if image else {"type": "text", "text": "[无图片]"},
{"type": "text", "text": prompt}
]}
]
# 处理输入
text = self.instruct_processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = self.instruct_processor(text=text, images=[image] if image else None, return_tensors="pt")
inputs = {k: v.to(self.device) for k, v in inputs.items()}
# 生成
with torch.no_grad():
outputs = self.instruct_model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True
)
# JSON提取
response = self.instruct_processor.batch_decode(outputs, skip_special_tokens=True)[0]
#print(f'response={response}')
# 方法1: 查找JSON块(支持markdown代码块)
import re
json_match = re.search(r'```json\s*(\{.*?\})\s*```', response, re.DOTALL)
if not json_match:
json_match = re.search(r'```\s*(\{.*?\})\s*```', response, re.DOTALL)
if not json_match:
json_match = re.search(r'(\{.*?\})', response, re.DOTALL)
if json_match:
json_str = json_match.group(1)
generated = json.loads(json_str)
else:
# 如果还是失败,保存原始响应
logger.warning(f"无法提取JSON,原始响应: {response[:200]}...")
generated = {"raw_response": response, "parse_error": True}
return {
"title": title,
"price": price,
"generated": generated,
"success": True
}
except Exception as e:
logger.error(f"❌ 生成文案失败: {e}")
return {
"title": title,
"price": price,
"error": str(e),
"success": False
}
def get_text_embedding(self, text: str) -> List[float]:
"""使用官方实现获取文本Embedding"""
try:
inputs = [{"text": text.strip()}]
embeddings = self.embedder.process(inputs, normalize=True)
return embeddings[0].cpu().float().numpy().tolist()
except Exception as e:
logger.error(f"❌ 文本Embedding失败: {e}")
return [0.0] * CONFIG['vector_dim']
def get_image_embedding(self, image_path: str) -> List[float]:
"""使用官方实现获取图片Embedding"""
try:
if not os.path.exists(image_path):
logger.warning(f"⚠️ 图片不存在: {image_path}")
return [0.0] * CONFIG['vector_dim']
# 官方实现支持直接传路径
inputs = [{"image": image_path}]
embeddings = self.embedder.process(inputs, normalize=True)
return embeddings[0].cpu().float().numpy().tolist()
except Exception as e:
logger.error(f"❌ 图片Embedding失败 {image_path}: {e}")
return [0.0] * CONFIG['vector_dim']
def process_batch(self, batch_items: List[Dict]) -> List[Dict]:
"""批量处理商品(生成文案+向量)"""
results = []
for item in batch_items:
try:
# 1. 生成结构化描述
desc_result = self.generate_product_description(
item['title'],
item['price'],
item['image_path']
)
if not desc_result['success']:
continue
gen_content = desc_result.get('generated', {})
# 2. 构建搜索文本(用于Embedding)
searchable_parts = [
item['title'],
gen_content.get('marketing_copy', ''),
' '.join(gen_content.get('target_group', [])),
' '.join(gen_content.get('scenes', [])),
' '.join(gen_content.get('style_tags', []))
]
searchable_text = ' '.join([p for p in searchable_parts if p])
# 3. 生成文本向量
text_emb = self.get_text_embedding(searchable_text)
# 4. 生成图片向量
img_emb = self.get_image_embedding(item['image_path'])
# 5. 提取价格数字
price_val = 0.0
price_segment = "unknown"
try:
price_str = item['price'].replace('¥', '').replace(',', '')
price_val = float(price_str)
if price_val < 100:
price_segment = "budget"
elif price_val < 300:
price_segment = "mid"
else:
price_segment = "premium"
except:
pass
# 6. 构建最终数据
processed = {
'id': f"{item['img_name'].replace('.jpg', '')}",
'source_id': item['img_name'].replace('.jpg', ''),
'page': item['page'],
'title': item['title'],
'price': price_val,
'price_segment': price_segment,
'image_local_path': item['image_path'],
'image_url': item['img_url'],
'generated_content': gen_content,
'text_embedding': text_emb,
'image_embedding': img_emb,
'searchable_text': searchable_text,
'combined_tags': gen_content.get('target_group', []) +
gen_content.get('scenes', []) +
gen_content.get('style_tags', [])
}
results.append(processed)
except Exception as e:
logger.error(f"❌ 处理商品失败 {item.get('title', 'unknown')}: {e}")
continue
return results
class DataCleaner:
"""主清洗控制器"""
def __init__(self, config: Dict):
self.config = config
self.db = DatabaseManager(config["db"])
self.vl_processor = Qwen3VLProcessor(config)
def init_system(self):
"""初始化数据库和模型"""
logger.info("🚀 开始初始化系统...")
# 1. 初始化PostgreSQL
if not self.db.create_database():
return False
if not self.db.create_tables():
return False
# 2. 加载模型
try:
self.vl_processor.load_embedding_model() # 先加载embedding,使用更频繁
except Exception as e:
logger.error(f"❌ 模型加载失败: {e}")
return False
return True
def load_csv_data(self, limit: Optional[int] = None, exclude_ids: Optional[set] = None) -> pd.DataFrame:
"""加载CSV数据"""
logger.info(f"📂 正在加载CSV: {self.config['data']['csv_path']}")
try:
df = pd.read_csv(self.config['data']['csv_path'])
df = df[df['status'] == 'success']
# 构建图片路径(保持原有逻辑)
df['image_path'] = df.apply(
lambda row: os.path.join(
self.config['data']['image_dir'],
row['img_name']
), axis=1
)
df['image_exists'] = df['image_path'].apply(os.path.exists)
df = df[df['image_exists'] == True]
# ===== 断点续传过滤逻辑 =====
if exclude_ids:
original_count = len(df)
# 构建id列用于过滤
df['temp_id'] = df.apply(
lambda row: f"{row['img_name'].replace('.jpg', '')}",
axis=1
)
df = df[~df['temp_id'].isin(exclude_ids)]
filtered_count = len(df)
skipped = original_count - filtered_count
logger.info(f"⏭️ 断点续传模式:跳过 {skipped} 条已处理数据,剩余 {filtered_count} 条待处理")
df = df.drop('temp_id', axis=1)
# ===== 结束新增 =====
if limit:
df = df.head(limit)
logger.info(f"✅ 加载完成,有效数据: {len(df)} 条")
return df
except Exception as e:
logger.error(f"❌ CSV加载失败: {e}")
return pd.DataFrame()
def test_pipeline(self):
"""测试模式:小批量验证流程是否通畅"""
logger.info("🧪 进入测试模式...")
# 1. 加载测试数据
test_df = self.load_csv_data(limit=self.config['test_limit'])
if test_df.empty:
logger.error("❌ 没有可用于测试的数据")
return False
# 2. 加载Instruct模型(测试时加载)
self.vl_processor.load_instruct_model()
# 3. 处理测试数据
test_items = test_df.to_dict('records')
logger.info(f"🔄 开始处理 {len(test_items)} 条测试数据...")
start_time = time.time()
processed = self.vl_processor.process_batch(test_items)
duration = time.time() - start_time
# 4. 验证写入数据库
success_count = 0
for item in processed:
if self.db.insert_product(item):
success_count += 1
logger.info(f"✅ 测试完成!")
logger.info(f" - 处理: {len(processed)}/{len(test_items)} 条")
logger.info(f" - 写入: {success_count}/{len(processed)} 条")
logger.info(f" - 耗时: {duration:.2f}s")
logger.info(f" - 预估单条耗时: {duration/len(processed):.2f}s")
if success_count == len(processed):
logger.info("🎉 测试通过!可以开始全量处理")
return True
else:
logger.error("⚠️ 测试未完全通过,请检查日志")
return False
def run_full_cleaning(self, mode: str = "resume"):
"""
全量清洗(带断点续传)
mode: "resume"(断点续传,默认) | "full"(清空后全量) | "update"(强制更新所有)
"""
# ===== 模式处理逻辑 =====
processed_ids = set()
if mode == "full":
# 全量重置:清空数据库
self.db.clear_all_data()
elif mode == "resume":
# 断点续传:获取已处理ID
processed_ids = self.db.get_processed_ids()
logger.info(f"📋 发现 {len(processed_ids)} 条已处理数据,将自动跳过")
# mode == "update" 时 processed_ids 保持为空,会更新所有数据(依赖SQL的ON CONFLICT UPDATE)
# ===== 结束新增 =====
# 1. 加载全部数据(传入exclude_ids用于过滤)
df = self.load_csv_data(exclude_ids=processed_ids if mode == "resume" else None)
if df.empty:
if mode == "resume" and len(processed_ids) > 0:
logger.info("✅ 所有数据已处理完毕,无需继续")
return
total = len(df)
logger.info(f"🎯 开始处理,共 {total} 条数据 (模式: {mode})")
# 2. 确保模型已加载
self.vl_processor.load_instruct_model()
# 3. 准备批处理
batch_size = self.config['batch_size']
items = df.to_dict('records')
processed_count = 0
error_count = 0
start_time = time.time()
# 4. 使用tqdm显示进度
with tqdm(total=total, desc="清洗进度", unit="条") as pbar:
for i in range(0, total, batch_size):
batch = items[i:i+batch_size]
batch_start = time.time()
# 处理批次
results = self.vl_processor.process_batch(batch)
# 写入数据库
for item in results:
if self.db.insert_product(item):
processed_count += 1
else:
error_count += 1
# 计算统计
batch_time = time.time() - batch_start
elapsed = time.time() - start_time
speed = (i + len(batch)) / elapsed if elapsed > 0 else 0
remaining = (total - (i + len(batch))) / speed if speed > 0 else 0
eta = datetime.now() + timedelta(seconds=remaining)
# 更新进度条
pbar.update(len(batch))
pbar.set_postfix({
'batch': f"{batch_time:.1f}s",
'speed': f"{speed:.1f}条/s",
'ETA': eta.strftime('%H:%M')
})
# 每10批次输出一次日志
if (i // batch_size) % 10 == 0:
progress = (i + len(batch)) / total * 100
logger.info(f"进度: {progress:.1f}% | 已处理: {i+len(batch)}/{total} | 剩余: {remaining/60:.1f}分钟")
# 5. 最终统计
total_time = time.time() - start_time
logger.info("🎉 全量处理完成!")
logger.info(f" - 总计: {total}")
logger.info(f" - 成功: {processed_count}")
logger.info(f" - 失败: {error_count}")
logger.info(f" - 总耗时: {total_time/60:.2f}分钟")
logger.info(f" - 平均速度: {total/total_time:.2f}条/秒")
def run_reembedding(self, mode: str = "resume"):
"""
重新生成向量(支持断点续传)
mode: "resume"(仅处理缺失向量) | "full"(清空后全部重新生成)
"""
if mode == "full":
# 全量重置:清空所有向量
self.db.clear_embeddings()
logger.info("🗑️ 全量重置模式:已清空所有向量")
# 获取待处理ID
if mode == "resume":
pending_ids = self.db.get_ids_without_embeddings()
processed_count, total_count = self.db.get_embedding_progress()
logger.info(f"📋 断点续传模式:已生成 {processed_count}/{total_count},剩余 {len(pending_ids)} 条")
else:
pending_ids = None # 处理所有
# 获取数据(带过滤)
if pending_ids:
placeholders = ','.join(['%s'] * len(pending_ids))
self.db.cursor.execute(f"""
SELECT id, title, generated_content, image_local_path
FROM products
WHERE id IN ({placeholders})
""", tuple(pending_ids))
else:
self.db.cursor.execute("""
SELECT id, title, generated_content, image_local_path
FROM products
WHERE generated_content IS NOT NULL
""")
rows = self.db.cursor.fetchall()
if not rows:
logger.info("ℹ️ 数据库中没有商品数据")
return
logger.info(f"📝 需要重新生成 {len(rows)} 条商品的向量")
# 分批处理
batch_size = self.config['batch_size']
processed = 0
errors = 0
with tqdm(total=len(rows), desc="重新生成向量") as pbar:
for i in range(0, len(rows), batch_size):
batch = rows[i:i+batch_size]
for row in batch:
try:
id_, title, gen_content_json, img_path = row
# 解析generated_content
if isinstance(gen_content_json, str):
gen_content = json.loads(gen_content_json)
else:
gen_content = gen_content_json or {}
# 重建searchable_text
searchable_parts = [title]
if isinstance(gen_content, dict):
searchable_parts.extend([
gen_content.get('marketing_copy', ''),
' '.join(gen_content.get('target_group', [])),
' '.join(gen_content.get('scenes', [])),
' '.join(gen_content.get('style_tags', []))
])
searchable_text = ' '.join([p for p in searchable_parts if p])
# 生成新向量
text_emb = self.vl_processor.get_text_embedding(searchable_text)
img_emb = self.vl_processor.get_image_embedding(img_path) if os.path.exists(img_path or '') else [0.0] * CONFIG['vector_dim']
# 更新数据库
self.db.cursor.execute("""
UPDATE products
SET text_embedding = %s, image_embedding = %s, updated_at = CURRENT_TIMESTAMP
WHERE id = %s
""", (text_emb, img_emb, id_))
processed += 1
except Exception as e:
logger.error(f"❌ 处理 {row[0]} 失败: {e}")
errors += 1
pbar.update(len(batch))
logger.info(f"✅ 完成!成功: {processed}, 失败: {errors}")
# 验证向量质量
self.verify_embeddings()
def verify_embeddings(self):
"""验证向量质量"""
logger.info("🔍 验证向量质量...")
# 先显示进度
with_emb, total = self.db.get_embedding_progress()
logger.info(f"📊 向量生成进度: {with_emb}/{total} ({with_emb/total*100:.1f}%)")
if with_emb == 0:
logger.warning("⚠️ 没有可用的向量")
return
try:
# 测试相似商品
self.db.cursor.execute("""
SELECT id, title, text_embedding::vector(2048)
FROM products
WHERE title LIKE '%婴儿%' AND text_embedding IS NOT NULL
LIMIT 2
""")
rows = self.db.cursor.fetchall()
if len(rows) == 2:
_, t1, v1 = rows[0]
_, t2, v2 = rows[1]
vec1 = np.array([float(x) for x in str(v1).strip('[]').split(',')])
vec2 = np.array([float(x) for x in str(v2).strip('[]').split(',')])
sim = np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
logger.info(f"相似商品 '{t1[:30]}...' vs '{t2[:30]}...' 相似度: {sim:.4f}")
if sim > 0.6:
logger.info("✅ 向量质量良好!")
elif sim > 0.3:
logger.warning("⚠️ 向量质量一般,可能需要检查")
else:
logger.error("❌ 向量质量差,仍有问题")
except Exception as e:
logger.error(f"验证失败: {e}")
def cleanup(self):
"""清理资源"""
self.db.close()
# 清理GPU缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()
logger.info("🧹 资源清理完成")
def main():
"""主入口"""
cleaner = DataCleaner(CONFIG)
try:
# 1. 初始化(数据库+模型)
if not cleaner.init_system():
logger.error("❌ 系统初始化失败")
return
# 2. 询问用户模式
print("\n" + "="*50)
print("商品数据清洗工具")
print("="*50)
print("1. 测试模式 (处理{}条数据)".format(CONFIG['test_limit']))
print("2. 断点续传模式 (跳过已处理,继续上次进度)")
print("3. 全量重置模式 (清空数据库,重新生成所有)")
print("4. 强制更新模式 (更新所有数据,保留数据库)")
print("5. 重新生成向量 (断点续传)")
print("6. 重新生成向量 (全量重置)")
print("7. 验证向量质量")
print("="*50)
choice = input("请选择模式 (1/2/3/4/5/6/7): ").strip()
if choice == "1":
success = cleaner.test_pipeline()
if success:
retry = input("\n测试通过,是否立即开始断点续传处理?(y/n): ").strip()
if retry.lower() == 'y':
cleaner.run_full_cleaning(mode="resume") # 默认断点续传
elif choice == "2":
cleaner.run_full_cleaning(mode="resume") # 断点续传
elif choice == "3":
confirm = input("⚠️ 警告:将清空所有已有数据!确认请输入 'reset': ").strip()
if confirm == "reset":
cleaner.run_full_cleaning(mode="full") # 全量重置
elif choice == "4":
cleaner.run_full_cleaning(mode="update") # 强制更新所有
elif choice == "5":
# 向量断点续传
cleaner.run_reembedding(mode="resume")
elif choice == "6":
# 向量全量重置
confirm = input("⚠️ 警告:将清空所有向量重新生成!确认请输入 'reset': ").strip()
if confirm == "reset":
cleaner.run_reembedding(mode="full")
elif choice == "7":
cleaner.verify_embeddings()
else:
print("无效输入")
except KeyboardInterrupt:
logger.info("⛔ 用户中断")
except Exception as e:
logger.error(f"❌ 程序异常: {e}")
import traceback
logger.error(traceback.format_exc())
finally:
cleaner.cleanup()
if __name__ == "__main__":
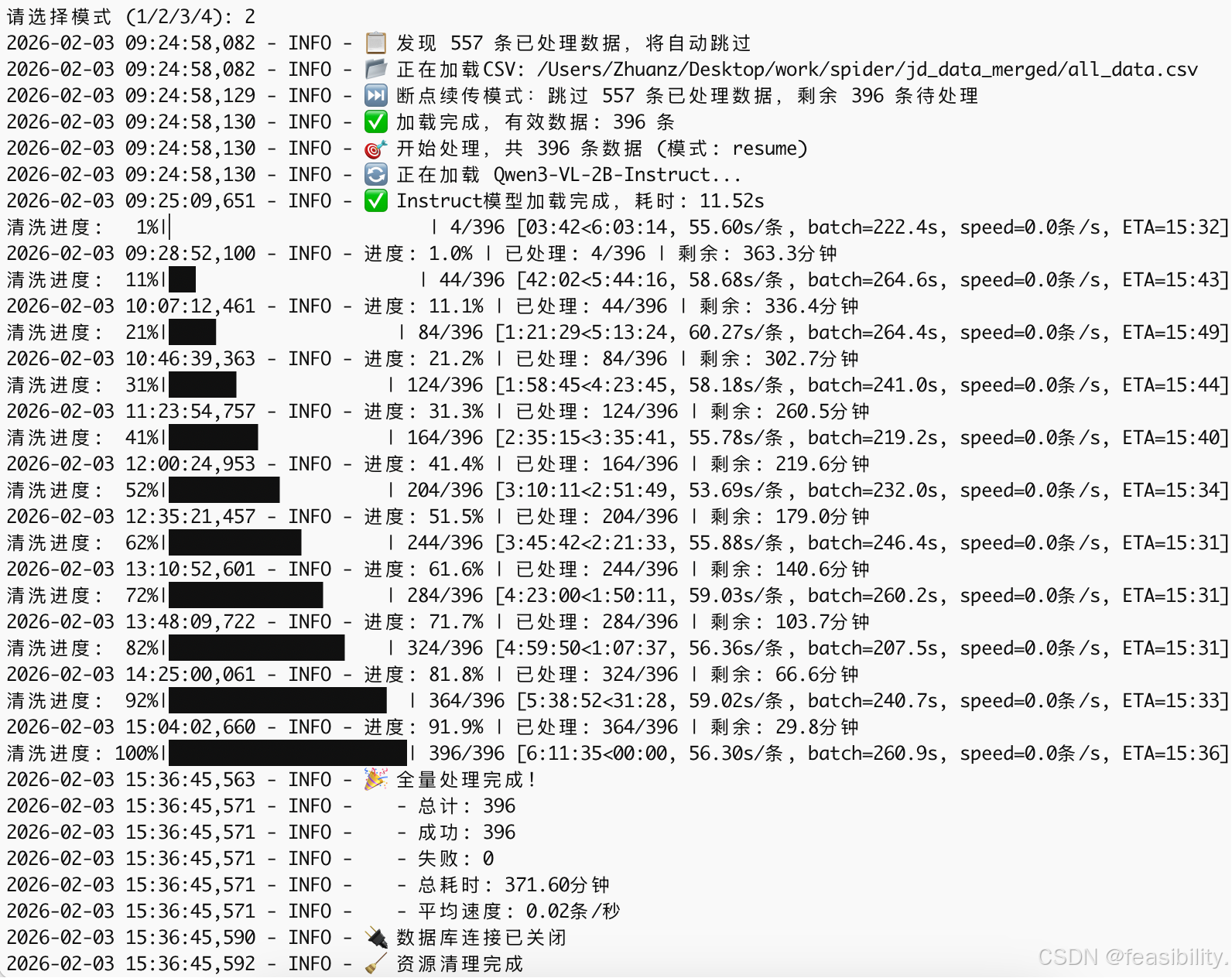
main()执行uv run clean-goods.py,进行小批量商品的结构化文案写入pg数据库测试
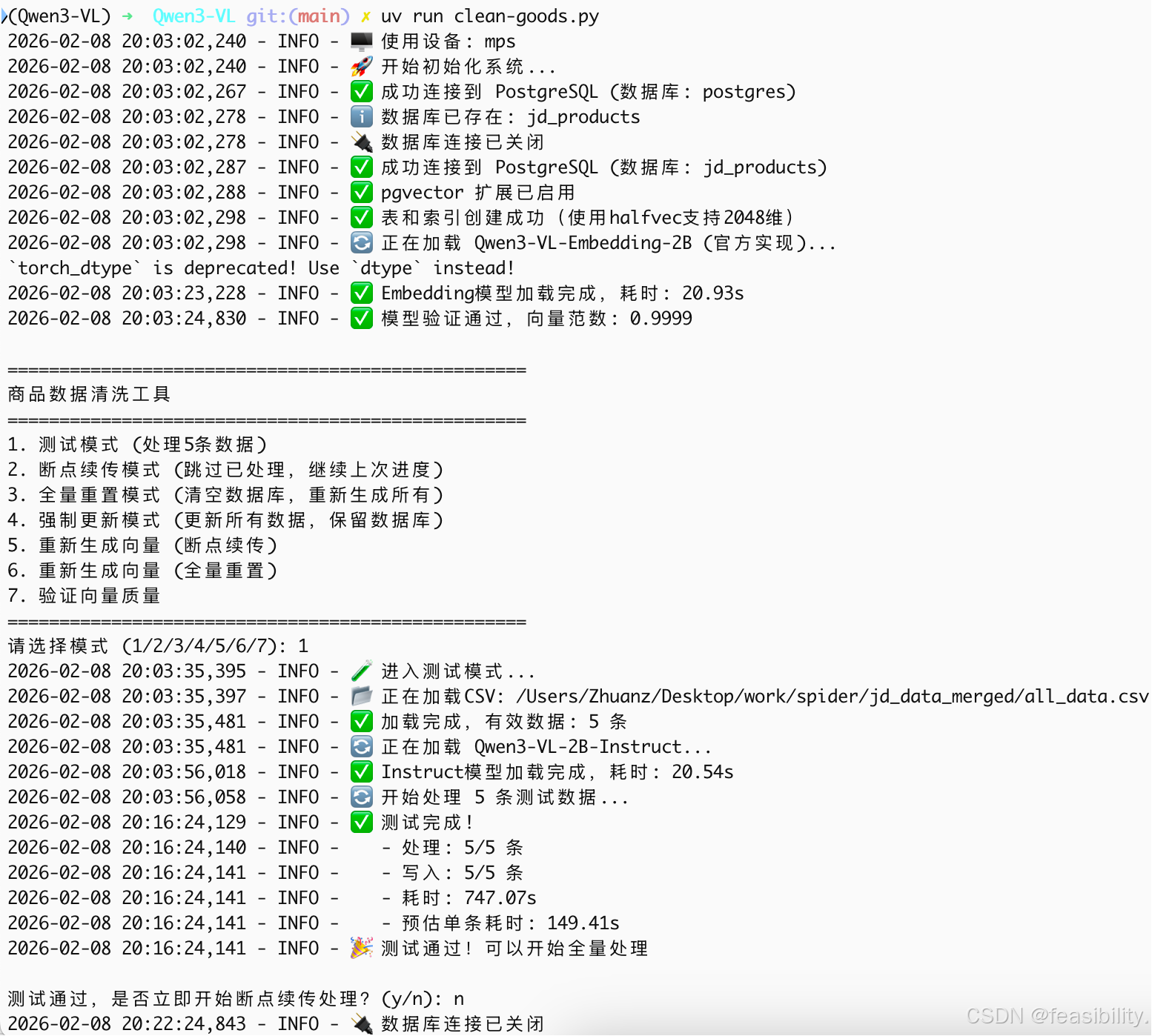
执行psql -d jd_products -U Zhuanz进入数据库查看,对于Mac用户需要将Zhuanz换成你的用户名,对于非Mac的用户默认是postgres
bash
# 在 psql 提示符下执行:
-- 查看总条数
SELECT COUNT(*) FROM products;
-- 查看最近 5 条
SELECT id, title, price, created_at
FROM products
ORDER BY created_at DESC
LIMIT 5;
-- 查看完整字段(JSON内容、向量维度)
SELECT
id,
title,
price,
generated_content->>'marketing_copy' as marketing_copy,
vector_dims(text_embedding) as text_dim,
vector_dims(image_embedding) as img_dim,
combined_tags,
status
FROM products
LIMIT 3;
-- 查看向量相似度检索(示例)
SELECT
id,
title,
price,
text_embedding <=> (SELECT text_embedding FROM products LIMIT 1) as distance
FROM products
ORDER BY distance
LIMIT 5;
-- 退出
\q
查看后按q退出



也可以写检查商品数据库的信息check-good.py脚本方便查看
python
import psycopg2
import json
conn = psycopg2.connect(
host="localhost",
port=5432,
database="jd_products",
user="Zhuanz"
)
cursor = conn.cursor()
# 查询总数
cursor.execute("SELECT COUNT(*) FROM products;")
print(f"📊 总条数: {cursor.fetchone()[0]}")
# 查询详细信息
cursor.execute("""
SELECT
id,
title,
price,
generated_content,
searchable_text,
combined_tags,
status,
created_at
FROM products
ORDER BY created_at DESC
LIMIT 5;
""")
for i, row in enumerate(cursor.fetchall(), 1):
print(f"\n{'='*70}")
print(f"🎁 商品 #{i}: {row[0]}")
print(f"{'='*70}")
print(f"📌 标题: {row[1]}")
print(f"💰 价格: ¥{row[2]}")
# 判断类型并序列化
gen_content = row[3]
if gen_content and isinstance(gen_content, dict):
# 字典转JSON字符串再切片
json_str = json.dumps(gen_content, ensure_ascii=False, indent=2)
print(f"\n📝 生成内容: {json_str[:300]}...")
elif gen_content:
print(f"\n📝 生成内容: {str(gen_content)[:200]}...")
else:
print(f"\n⚠️ 生成内容: 空")
print(f"\n🔍 搜索文本: {str(row[4])[:100]}...")
print(f"🏷️ 标签: {row[5]}")
print(f"✅ 状态: {row[6]}")
print(f"⏰ 创建时间: {row[7]}")
# 验证向量维度
cursor.execute("""
SELECT
COUNT(*) as total,
MIN(vector_dims(text_embedding)) as min_text_dim,
MAX(vector_dims(text_embedding)) as max_text_dim,
MIN(vector_dims(image_embedding)) as min_img_dim,
MAX(vector_dims(image_embedding)) as max_img_dim
FROM products;
""")
stats = cursor.fetchone()
print(f"\n{'='*70}")
print(f"📐 向量维度统计:")
print(f"{'='*70}")
print(f"总记录数: {stats[0]}")
print(f"文本向量维度: {stats[1]} - {stats[2]}")
print(f"图片向量维度: {stats[3]} - {stats[4]}")
conn.close()运行脚本,可以看出即使是2B参数规模且未经过微调的VLM模型,对商品信息结构化文案描述能力还是相当出色的
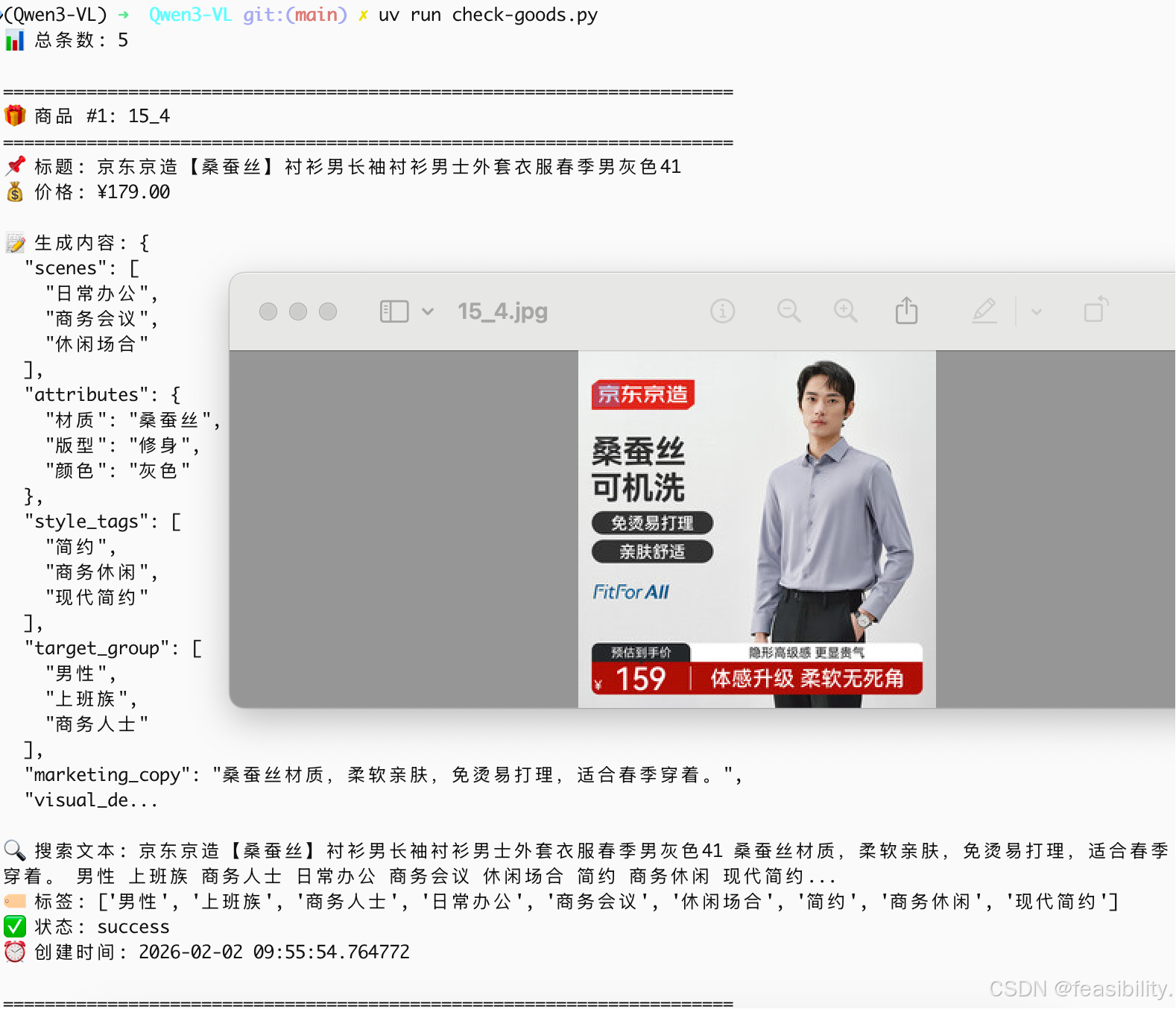
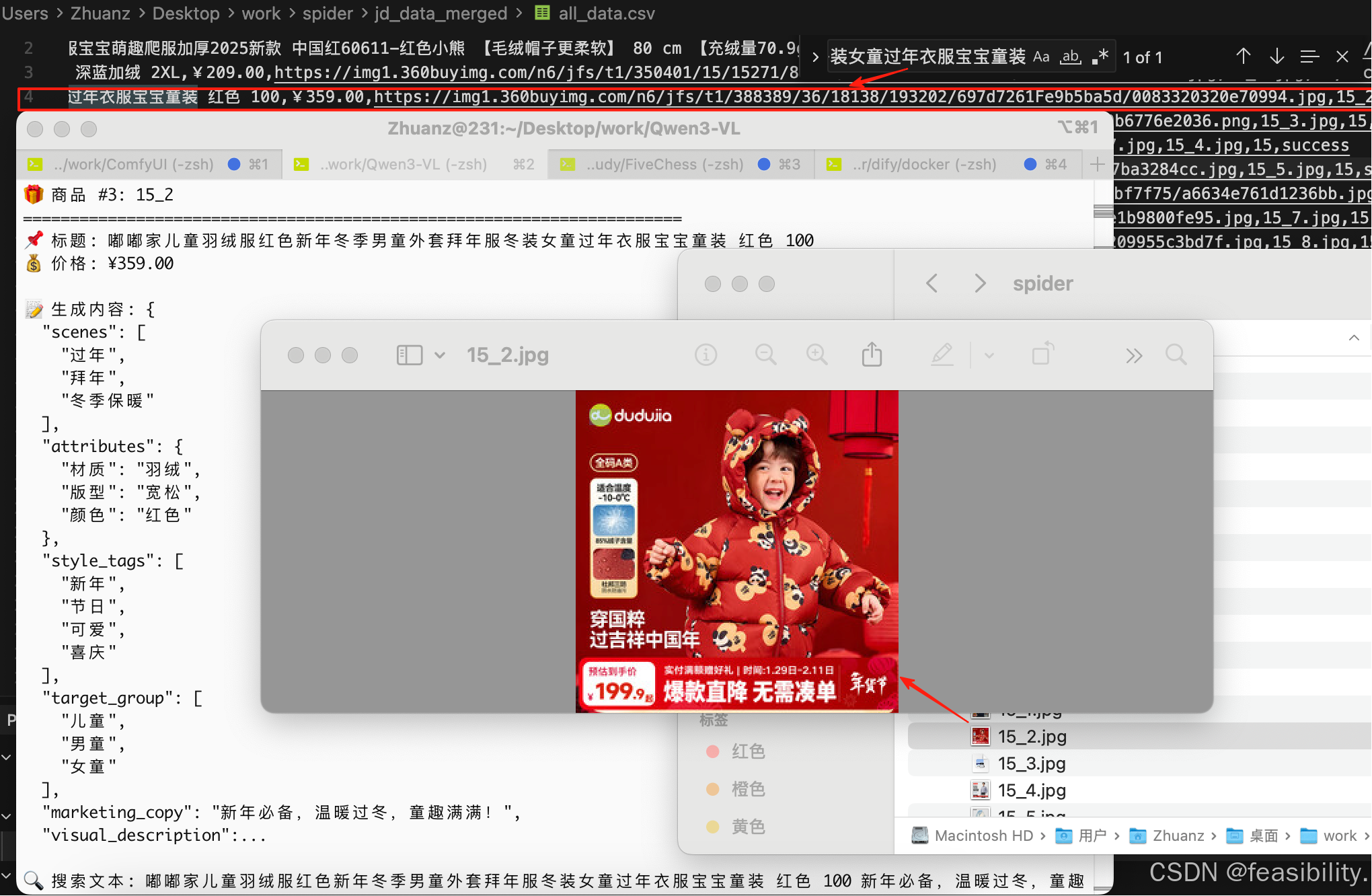
再次执行uv run clean-goods.py,写入全量商品的结构化文案到pg数据库中
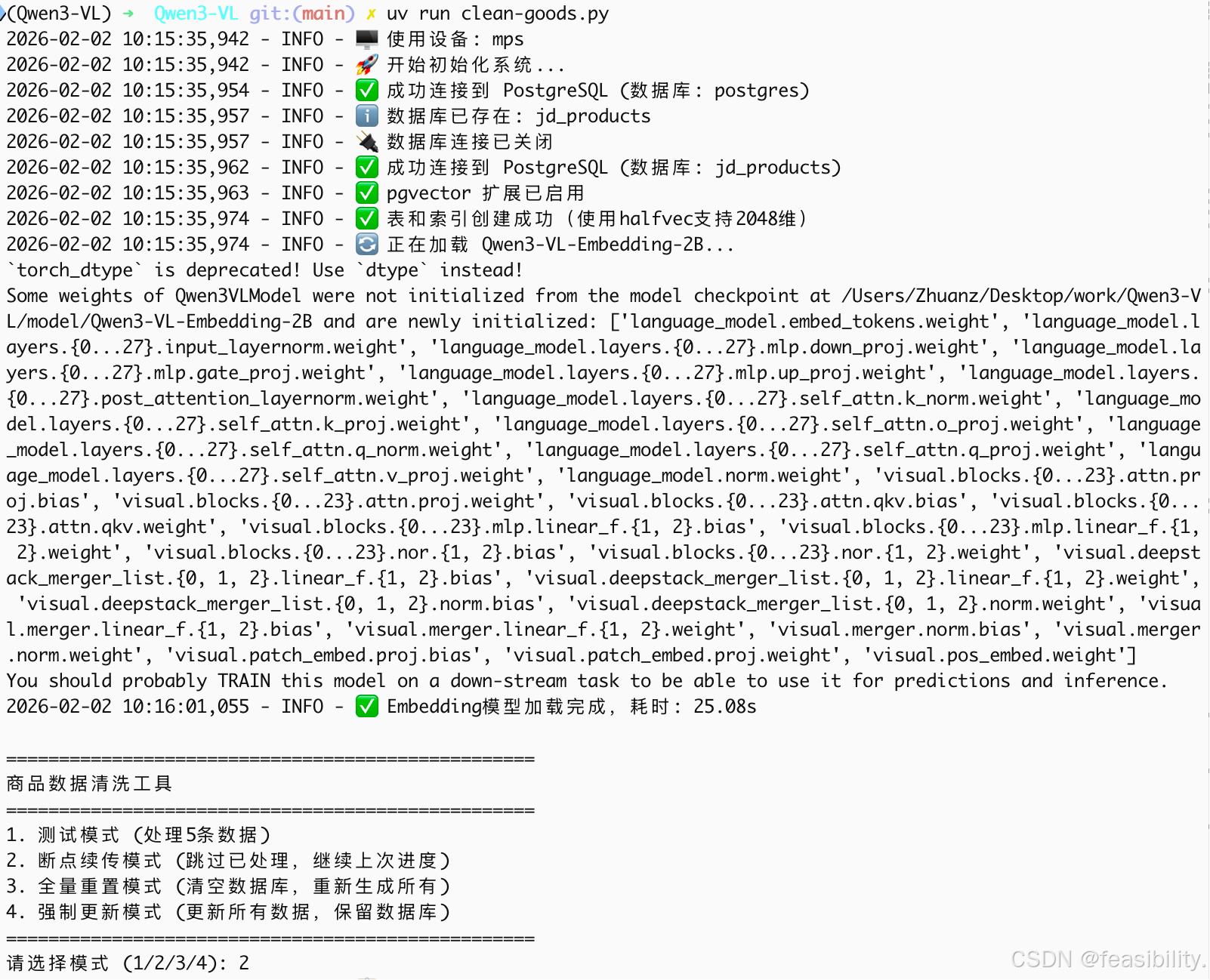
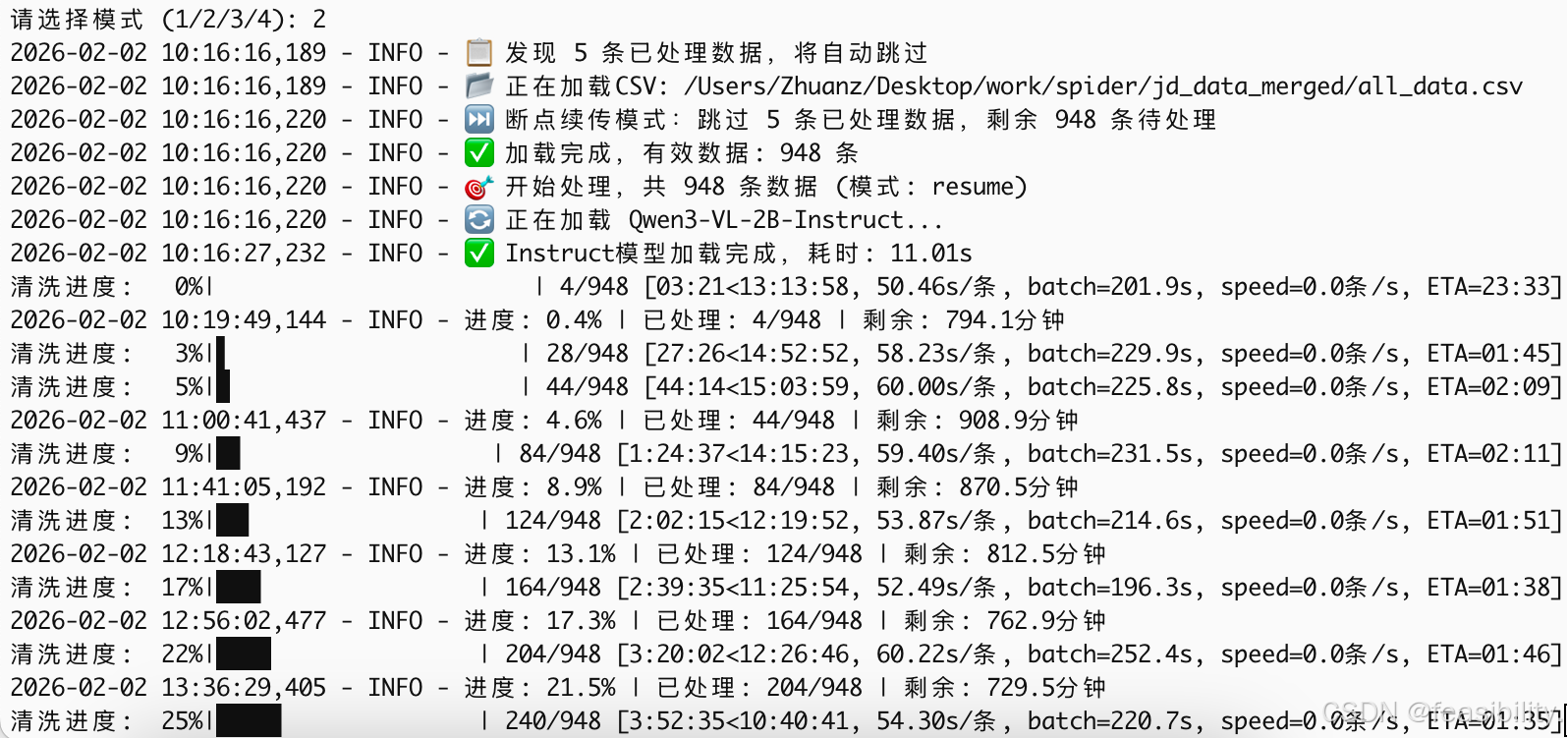
中间运行其他任务暂停,再次断点重传
如果发现相似度不对,可以重新更新向量
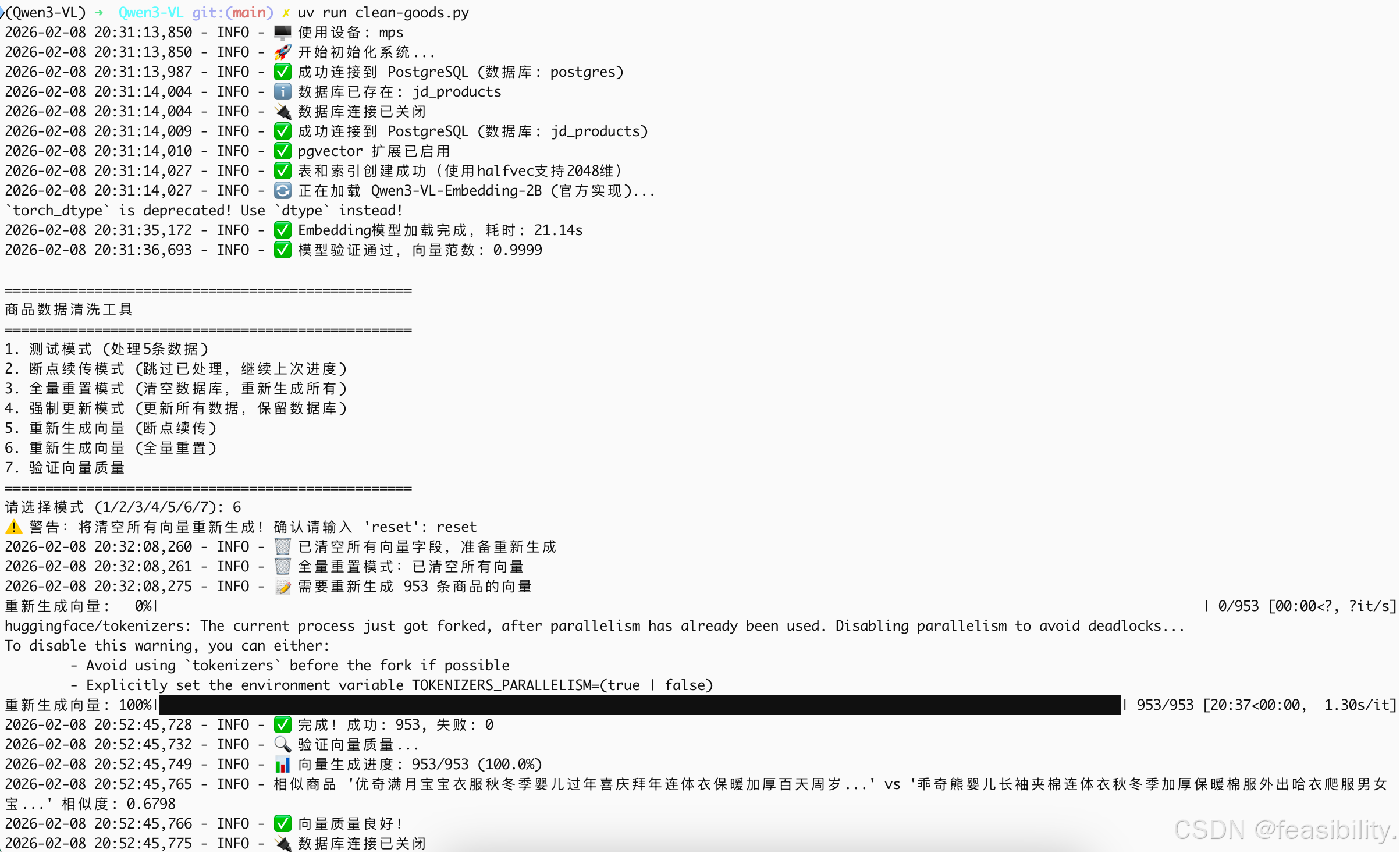
执行验证向量检索是否正常
bash
uv run python -c "
import psycopg2
import numpy as np
conn = psycopg2.connect(host='localhost', database='jd_products', user='Zhuanz')
cur = conn.cursor()
cur.execute(\"\"\"SELECT id, title, text_embedding::vector(2048) FROM products WHERE title LIKE '%婴儿%' AND text_embedding IS NOT NULL LIMIT 2\"\"\")
rows = cur.fetchall()
if len(rows) == 2:
_, t1, v1 = rows[0]
_, t2, v2 = rows[1]
vec1 = np.array([float(x) for x in str(v1).strip('[]').split(',')])
vec2 = np.array([float(x) for x in str(v2).strip('[]').split(',')])
sim = np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
print(f'=== 相似商品(都是婴儿衣服)===')
print(f'{t1[:40]}...')
print(f'{t2[:40]}...')
print(f'相似度: {sim:.4f}')
cur.execute(\"\"\"SELECT id, title, 1 - (text_embedding <=> (SELECT text_embedding FROM products WHERE id = '15_0')) as similarity FROM products WHERE text_embedding IS NOT NULL AND id != '15_0' ORDER BY text_embedding <=> (SELECT text_embedding FROM products WHERE id = '15_0') LIMIT 3\"\"\")
rows = cur.fetchall()
print(f'\n=== 与商品15_0最相似的商品 ===')
for id_, title, sim in rows:
print(f'相似度 {sim:.4f}: {title[:50]}...')
cur.close()
"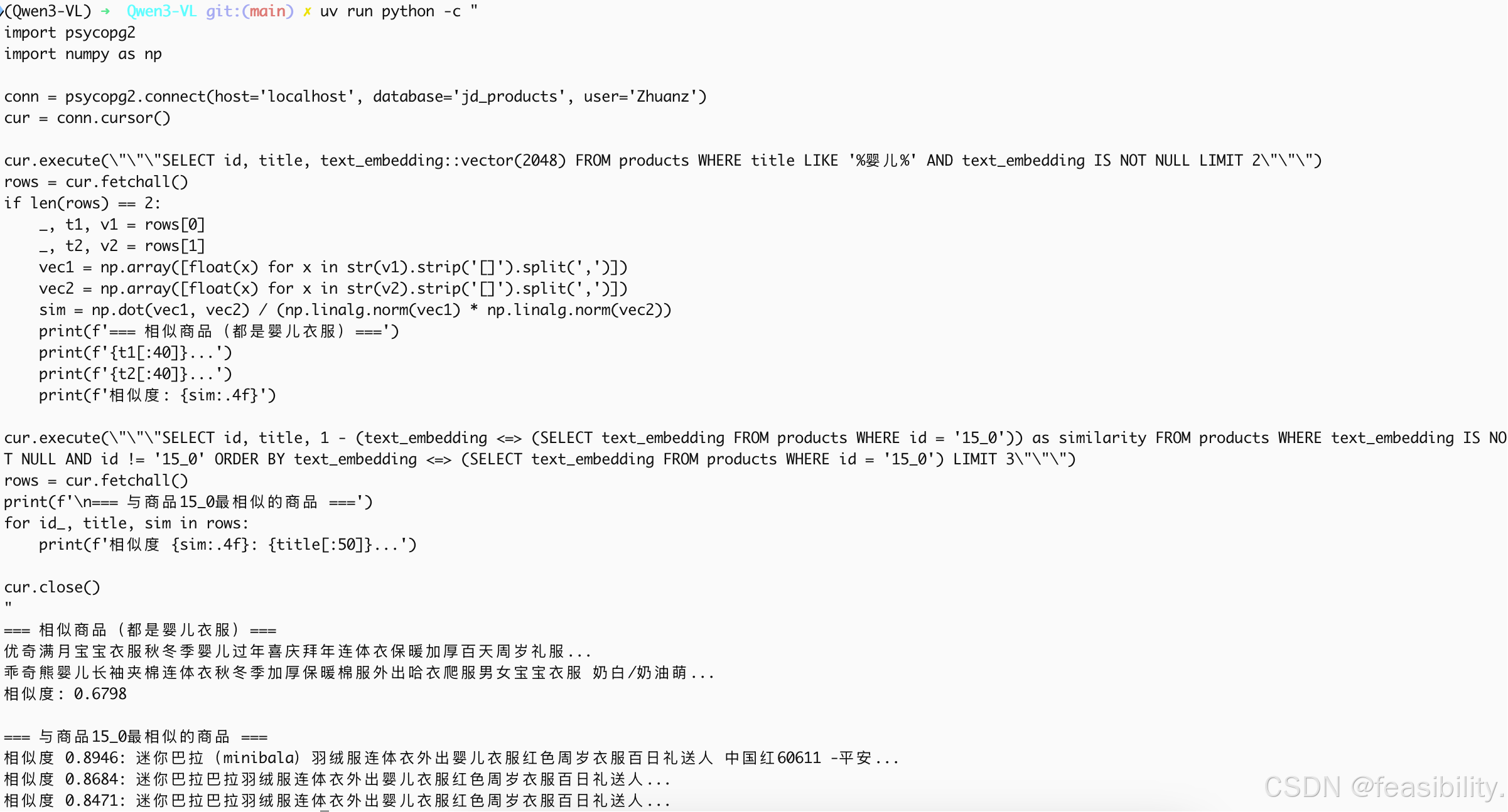
由此看来不微调的qwen3-embedding是能找出相似的产品的
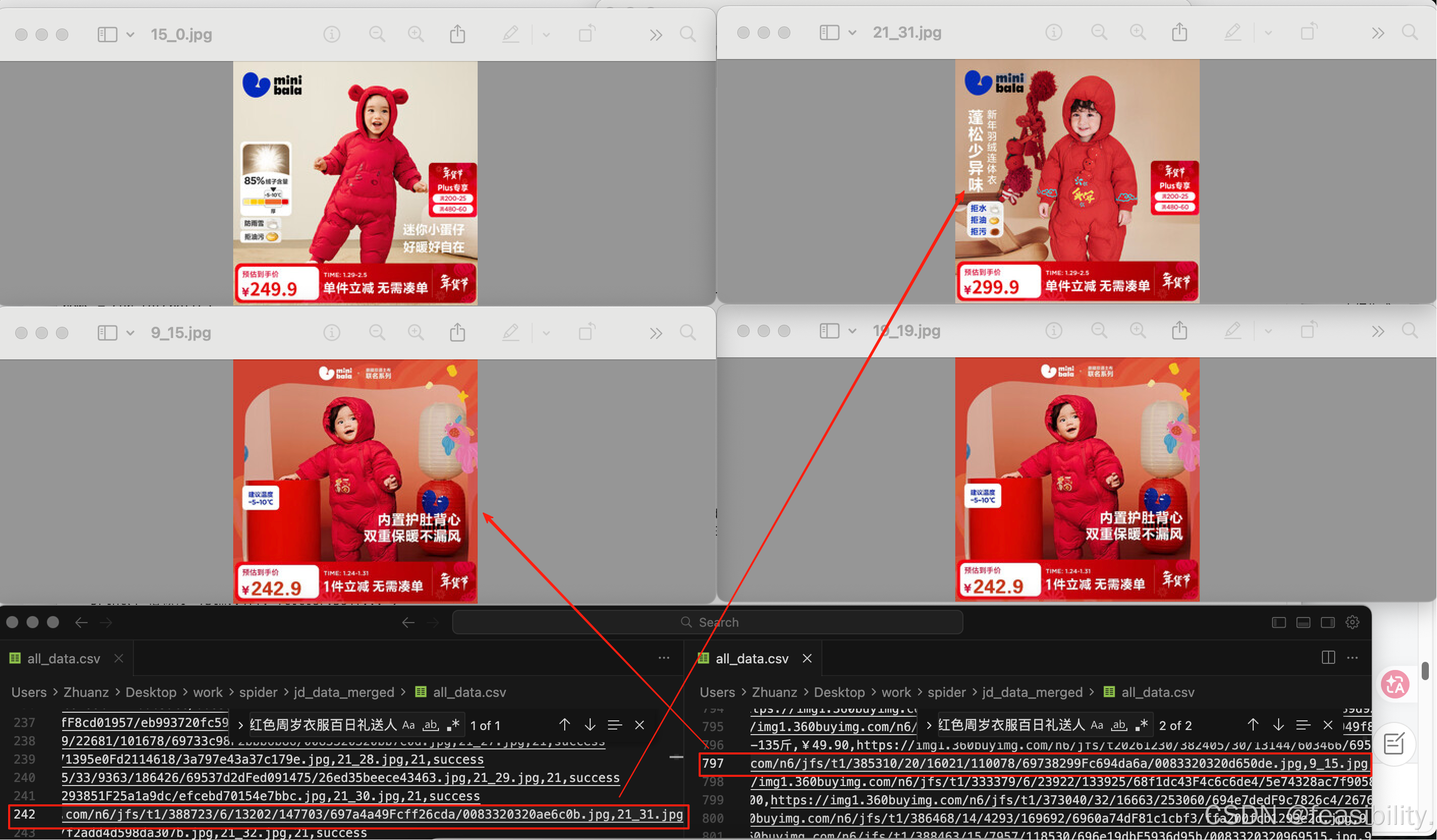
搭建工作流
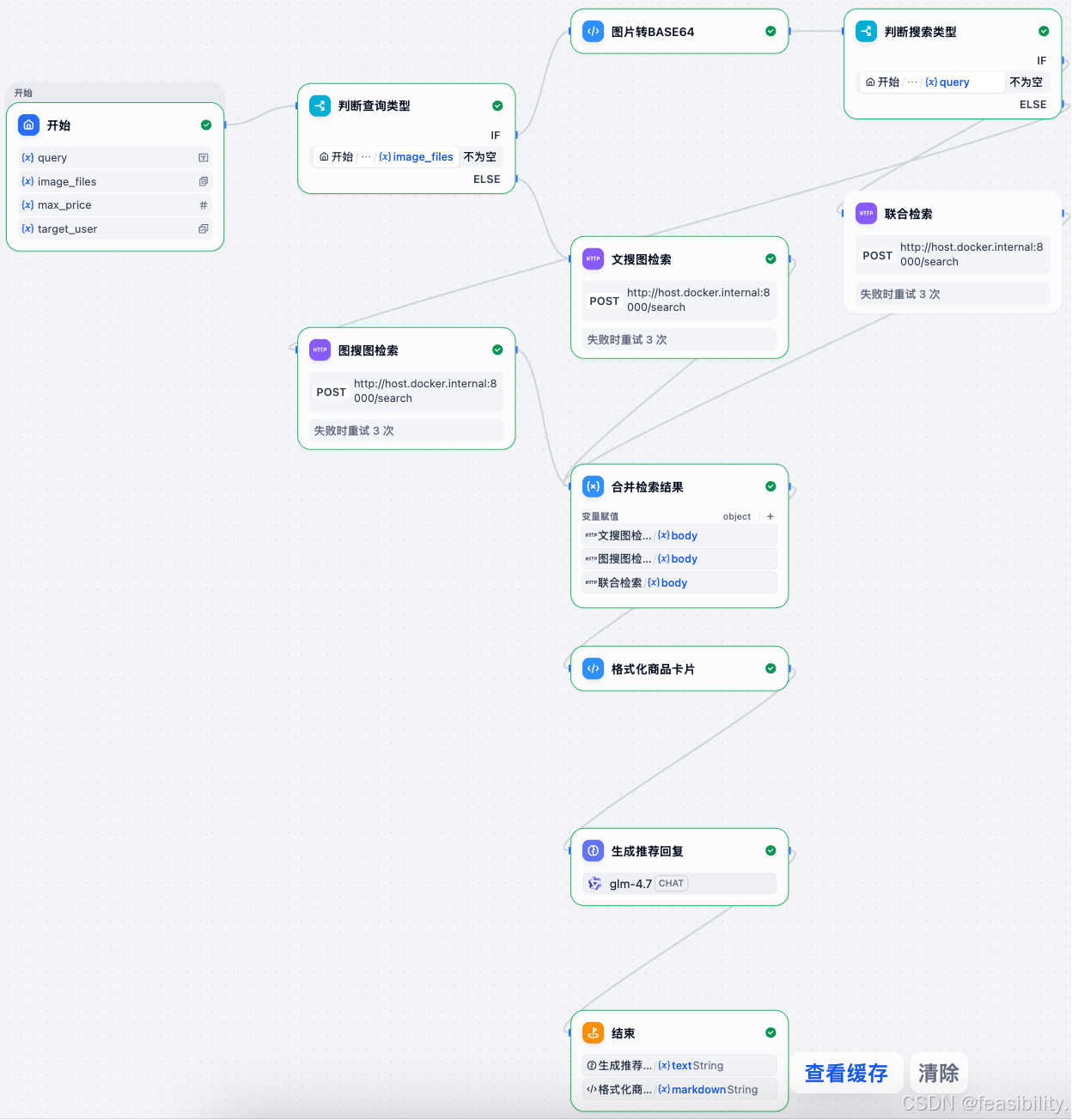
执行docker ps | grep dify
从docker ps 输出可以看到:
31525b6ff4b6 nginx:latest ... 0.0.0.0:80->80/tcp dify-nginx-1
关键发现(避坑):
-
Dify 的架构:Dify 使用 nginx 作为反向代理/网关
-
文件访问路径:dify-nginx-1
:80→ 通过 nginx 反向代理,能正确路由到文件服务 -
文件 URL 的生成逻辑:
-
Dify 生成的相对路径
/files/...是为 nginx 设计的 -
nginx 配置中将
/files/路由到文件服务 -
直接访问 时,API 服务没有处理
/files/端点,返回 404
-
结论:Dify 的文件预览功能是通过 nginx 反向代理 提供的,不是直接通过 API 服务。所以必须通过 nginx 访问才能获取文件内容。
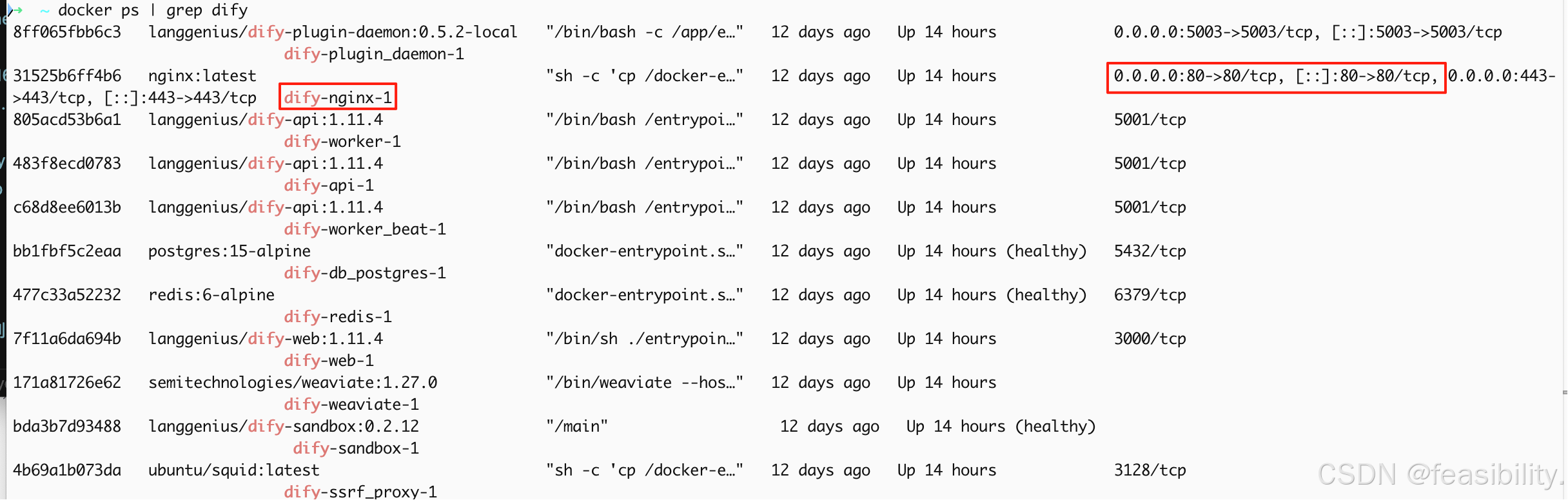
因此图片转BASE64的节点代码的base_url需要根据自己的情况改
编写后端检索代码uv run retrieval_api.py
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Qwen3-VL 多模态检索API服务
功能:
1. 严格遵循官方Qwen3-VL-Embedding调用方式生成查询向量
2. 使用Qwen3-VL-Reranker进行精排(Cross-Attention机制)
3. 支持文搜图、图搜图、混合搜索 + 结构化过滤
4. 包含测试模式验证模型和数据库连接
"""
import os
import sys
import json
import base64
import io
import logging
from typing import List, Dict, Optional, Literal, Tuple
from datetime import datetime
import torch
from PIL import Image
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
import uvicorn
from psycopg2.pool import ThreadedConnectionPool
from scripts.qwen3_vl_embedding import Qwen3VLEmbedder
from scripts.qwen3_vl_reranker import Qwen3VLReranker
# 配置
CONFIG = {
"model_paths": {
"embedding": "/Users/Zhuanz/Desktop/work/Qwen3-VL/model/Qwen3-VL-Embedding-2B",
"reranker": "/Users/Zhuanz/Desktop/work/Qwen3-VL/model/Qwen3-VL-Reranker-2B"
},
"db": {
"host": "localhost",
"port": 5432,
"database": "jd_products",
"user": "Zhuanz",
"password": None,
"minconn": 1,
"maxconn": 10
},
"vector_dim": 2048,
"device": "mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available() else "cpu",
"recall_topk": 50, # 向量召回数量
"rerank_topk": 10, # 精排后返回数量
"batch_size": 4 # Reranker批处理大小(16GB内存建议4)
}
# 日志设置
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# ==================== 模型加载器(遵循官方实现)====================
class Qwen3VLEmbeddingWrapper:
def __init__(self, model_path: str):
self.model_path = model_path
self.device = CONFIG["device"] # "mps" 或 "cuda" 或 "cpu"
self.embedder = None
def load(self):
logger.info(f"🔄 正在加载 Qwen3-VL-Embedding-2B...")
start = datetime.now()
try:
# 使用官方Qwen3VLEmbedder类
self.embedder = Qwen3VLEmbedder(
model_name_or_path=self.model_path,
max_length=512, # 根据需求调整
# 不使用flash_attention_2,让transformers自动选择
torch_dtype=torch.float16 if self.device != "cpu" else torch.float32,
device_map=self.device if self.device != "mps" else None, # MPS不支持device_map
)
# 如果是MPS,手动移动模型
if self.device == "mps":
self.embedder.model = self.embedder.model.to("mps")
self.embedder.device = torch.device("mps")
duration = (datetime.now() - start).total_seconds()
logger.info(f"✅ Embedding模型加载完成,耗时: {duration:.2f}s")
return True
except Exception as e:
logger.error(f"❌ Embedding模型加载失败: {e}")
import traceback
logger.error(traceback.format_exc())
return False
def embed_text(self, text: str) -> List[float]:
try:
# 使用官方process方法
inputs = [{"text": text}]
embeddings = self.embedder.process(inputs, normalize=True)
return embeddings[0].cpu().numpy().tolist()
except Exception as e:
logger.error(f"❌ 文本Embedding失败: {e}")
raise
def embed_image(self, image_input) -> List[float]:
try:
# 处理输入为PIL Image
if isinstance(image_input, str) and image_input.startswith('data:image'):
image_data = base64.b64decode(image_input.split(',')[1])
image = Image.open(io.BytesIO(image_data)).convert('RGB')
elif isinstance(image_input, str) and os.path.exists(image_input):
image = Image.open(image_input).convert('RGB')
elif isinstance(image_input, Image.Image):
image = image_input.convert('RGB')
else:
raise ValueError("不支持的图片输入格式")
# 使用官方process方法
inputs = [{"image": image}]
embeddings = self.embedder.process(inputs, normalize=True)
return embeddings[0].cpu().numpy().tolist()
except Exception as e:
logger.error(f"❌ 图片Embedding失败: {e}")
raise
class Qwen3VLRerankerWrapper:
def __init__(self, model_path: str):
self.model_path = model_path
self.device = CONFIG["device"]
self.reranker = None
def load(self):
logger.info(f"🔄 正在加载 Qwen3-VL-Reranker-2B...")
start = datetime.now()
try:
self.reranker = Qwen3VLReranker(
model_name_or_path=self.model_path,
max_length=1024,
torch_dtype=torch.float16 if self.device != "cpu" else torch.float32,
)
# MPS手动处理
if self.device == "mps":
self.reranker.model = self.reranker.model.to("mps")
self.reranker.score_linear = self.reranker.score_linear.to("mps")
self.reranker.device = torch.device("mps")
duration = (datetime.now() - start).total_seconds()
logger.info(f"✅ Reranker模型加载完成,耗时: {duration:.2f}s")
return True
except Exception as e:
logger.error(f"❌ Reranker模型加载失败: {e}")
return False
def rerank(self, query_text: Optional[str], query_image, candidates: List[Dict]) -> List[Dict]:
try:
# 构建query
query = {}
if query_text:
query['text'] = query_text
if query_image is not None:
query['image'] = query_image
# 构建documents
documents = []
for cand in candidates:
doc = {
'text': f"{cand['title']} {cand.get('searchable_text', '')}"
}
# 如果有本地图片,加载
img_path = cand.get('image_local_path', '')
if os.path.exists(img_path):
doc['image'] = Image.open(img_path).convert('RGB')
documents.append(doc)
# 调用官方process
inputs = {
"query": query,
"documents": documents,
"instruction": "Judge the semantic similarity."
}
scores = self.reranker.process(inputs)
# 排序
indexed_scores = [(i, s) for i, s in enumerate(scores)]
indexed_scores.sort(key=lambda x: x[1], reverse=True)
reranked = []
for idx, score in indexed_scores[:CONFIG["rerank_topk"]]:
candidate = candidates[idx].copy()
candidate['rerank_score'] = float(score)
reranked.append(candidate)
return reranked
except Exception as e:
logger.error(f"❌ Reranker失败: {e}")
# Fallback
return candidates[:CONFIG["rerank_topk"]]
# ==================== 数据库管理 ====================
class DatabasePool:
"""PostgreSQL连接池管理"""
def __init__(self, config: Dict):
self.config = config
self.pool = None
def init(self):
"""初始化连接池"""
try:
self.pool = ThreadedConnectionPool(
minconn=self.config["minconn"],
maxconn=self.config["maxconn"],
host=self.config["host"],
port=self.config["port"],
database=self.config["database"],
user=self.config["user"],
password=self.config["password"] or ""
)
logger.info("✅ PostgreSQL连接池初始化成功")
return True
except Exception as e:
logger.error(f"❌ 连接池初始化失败: {e}")
return False
def get_conn(self):
return self.pool.getconn()
def put_conn(self, conn):
self.pool.putconn(conn)
def close(self):
if self.pool:
self.pool.closeall()
# ==================== 检索逻辑 ====================
class MultimodalRetriever:
"""多模态检索核心逻辑"""
def __init__(self, db_pool: DatabasePool, embedder: Qwen3VLEmbeddingWrapper, reranker: Qwen3VLRerankerWrapper):
self.db_pool = db_pool
self.embedder = embedder
self.reranker = reranker
def vector_search(self, query_vec: List[float], search_type: Literal["text", "image"],
filters: Dict, top_k: int = 50) -> List[Dict]:
"""
pgvector向量检索 - 支持跨模态(文本向量查image_embedding等)
"""
conn = self.db_pool.get_conn()
cursor = conn.cursor()
try:
# 构建WHERE条件
where_clauses = ["text_embedding IS NOT NULL", "image_embedding IS NOT NULL"] # 确保向量存在
params = []
price_max = filters.get("price_max")
if price_max not in (None, "", []):
try:
price_val = float(price_max)
where_clauses.append("price <= %s")
params.append(price_val)
except (ValueError, TypeError):
pass # 忽略无效价格
price_min = filters.get("price_min")
if price_min not in (None, "", []):
try:
price_val = float(price_min)
where_clauses.append("price >= %s")
params.append(price_val)
except (ValueError, TypeError):
pass
# 标签过滤 - 关键修复:过滤空字符串
target_group = filters.get("target_group")
if target_group:
# 过滤掉空字符串,确保有有效标签
if isinstance(target_group, list):
target_group = [t for t in target_group if t and str(t).strip()]
elif isinstance(target_group, str):
target_group = [target_group] if str(target_group).strip() else []
if target_group: # 确保过滤后还有内容
where_clauses.append("combined_tags && %s")
params.append(target_group)
scenes = filters.get("scenes")
if scenes:
if isinstance(scenes, list):
scenes = [s for s in scenes if s and str(s).strip()]
elif isinstance(scenes, str):
scenes = [scenes] if str(scenes).strip() else []
if scenes:
where_clauses.append("combined_tags && %s")
params.append(scenes)
where_sql = " AND ".join(where_clauses)
#将list转为pgvector字符串格式
vec_str = '[' + ','.join(str(x) for x in query_vec) + ']'
# 选择向量字段(关键:实现文搜图/图搜图)
if search_type == "text":
# 文本查询:同时查text_embedding(最相关)和image_embedding(跨模态)
vector_field = "text_embedding"
else:
vector_field = "image_embedding"
# pgvector查询:使用<=>操作符(欧氏距离),转换为相似度分数
query_sql = f"""
SELECT
id, title, price, price_segment, image_url, image_local_path,
generated_content, searchable_text, combined_tags,
1 - ({vector_field}::vector <=> %s::vector(2048)) as similarity
FROM products
WHERE {where_sql}
ORDER BY {vector_field}::vector <=> %s::vector(2048)
LIMIT %s;
"""
params = [vec_str] + params + [vec_str, top_k]
cursor.execute(query_sql, params)
columns = [desc[0] for desc in cursor.description]
results = []
for row in cursor.fetchall():
result = dict(zip(columns, row))
# 解析JSONB(psycopg2 2.7+ 自动将JSONB转为dict,无需再loads)
if isinstance(result.get('generated_content'), str):
result['generated_content'] = json.loads(result['generated_content'])
# 如果已经是dict,保持不变
results.append(result)
return results
finally:
cursor.close()
self.db_pool.put_conn(conn)
def search(self, query_text: Optional[str], query_image_b64: Optional[str],
filters: Dict, mode: Literal["text", "image", "hybrid"]) -> List[Dict]:
"""
统一检索入口:向量召回 + Reranker精排
"""
# 1. 生成查询向量(可能多个)
query_vectors = []
query_image = None
query_image_pil = None
if mode in ["text", "hybrid"] and query_text:
text_vec = self.embedder.embed_text(query_text)
query_vectors.append(("text", text_vec))
if mode in ["image", "hybrid"] and query_image_b64:
# 保存原始PIL图片给Reranker用
if isinstance(query_image_b64, str) and query_image_b64.startswith('data:image'):
image_data = base64.b64decode(query_image_b64.split(',')[1])
query_image_pil = Image.open(io.BytesIO(image_data)).convert('RGB')
query_image = self.embedder.embed_image(query_image_b64)
logger.info(f"图片向量: 维度={len(query_image)}...")
query_vectors.append(("image", query_image))
logger.info(f"搜索请求: mode={mode}, text={query_text[:50] if query_text else None}, image_len={len(query_image_b64) if query_image_b64 else 0}")
if not query_vectors:
raise ValueError("必须提供文本或图片查询")
# 2. 多路向量召回(RRF融合候选集)
all_candidates = {}
for qtype, qvec in query_vectors:
candidates = self.vector_search(qvec, qtype, filters, CONFIG["recall_topk"])
for c in candidates:
cid = c['id']
if cid not in all_candidates:
all_candidates[cid] = c
all_candidates[cid]['_scores'] = {qtype: c['similarity']}
else:
all_candidates[cid]['_scores'][qtype] = c['similarity']
candidates_list = list(all_candidates.values())
if len(candidates_list) == 0:
return []
# 3. Reranker精排(Cross-Attention重排序)
try:
reranked = self.reranker.rerank(query_text, query_image_pil, candidates_list)
return reranked
except Exception as e:
logger.error(f"Reranker失败,返回向量召回结果: {e}")
# Fallback:按相似度排序返回
sorted_candidates = sorted(
candidates_list,
key=lambda x: max(x['_scores'].values()),
reverse=True
)
return sorted_candidates[:CONFIG["rerank_topk"]]
# ==================== FastAPI应用 ====================
# 全局状态
db_pool: Optional[DatabasePool] = None
embedder: Optional[Qwen3VLEmbeddingWrapper] = None
reranker: Optional[Qwen3VLRerankerWrapper] = None
retriever: Optional[MultimodalRetriever] = None
app = FastAPI(title="Qwen3-VL 多模态商品检索API", version="1.0.0")
class SearchRequest(BaseModel):
query_text: Optional[str] = Field(None, description="查询文本,如'红色婴儿连体衣'")
query_image_base64: Optional[str] = Field(None, description="Base64编码的查询图片(data:image/jpeg;base64,...)")
mode: Literal["text", "image", "hybrid"] = Field("hybrid", description="检索模式")
top_k: int = Field(10, ge=1, le=50)
filters: Optional[Dict] = Field(default_factory=dict, description="结构化过滤条件")
class Config:
json_schema_extra = {
"example": {
"query_text": "适合新年穿的红色婴儿衣服",
"mode": "hybrid",
"top_k": 10,
"filters": {"price_max": 500, "target_group": ["婴儿"]}
}
}
class SearchResponse(BaseModel):
results: List[Dict]
total_recall: int
reranked: bool
query_mode: str
latency_ms: float
@app.on_event("startup")
async def startup_event():
"""启动时加载模型和数据库"""
global db_pool, embedder, reranker, retriever
logger.info("🚀 启动多模态检索服务...")
# 1. 初始化数据库
db_pool = DatabasePool(CONFIG["db"])
if not db_pool.init():
raise RuntimeError("数据库连接失败")
# 2. 加载Embedding模型
embedder = Qwen3VLEmbeddingWrapper(CONFIG["model_paths"]["embedding"])
if not embedder.load():
raise RuntimeError("Embedding模型加载失败")
# 3. 加载Reranker模型
reranker = Qwen3VLRerankerWrapper(CONFIG["model_paths"]["reranker"])
if not reranker.load():
raise RuntimeError("Reranker模型加载失败")
# 4. 初始化检索器
retriever = MultimodalRetriever(db_pool, embedder, reranker)
logger.info("✅ 所有组件初始化完成,服务就绪")
@app.on_event("shutdown")
async def shutdown_event():
"""关闭时释放资源"""
global db_pool, embedder, reranker
logger.info("🛑 正在关闭服务...")
if db_pool:
db_pool.close()
logger.info("数据库连接池已关闭")
# 清理GPU缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()
elif torch.backends.mps.is_available():
torch.mps.empty_cache()
logger.info("✅ 服务已安全关闭")
@app.get("/health")
async def health_check():
"""健康检查端点"""
return {
"status": "healthy",
"models": {
"embedding": embedder is not None,
"reranker": reranker is not None
},
"database": db_pool is not None
}
@app.post("/search", response_model=SearchResponse)
async def search(request: SearchRequest):
"""
多模态检索主接口
"""
print('开始搜索')
print('SearchResponse:',SearchResponse)
import time
start_time = time.time()
try:
# 执行检索
results = retriever.search(
query_text=request.query_text,
query_image_b64=request.query_image_base64,
filters=request.filters or {},
mode=request.mode
)
latency = (time.time() - start_time) * 1000 # ms
return SearchResponse(
results=results,
total_recall=len(results),
reranked=True,
query_mode=request.mode,
latency_ms=round(latency, 2)
)
except Exception as e:
logger.error(f"检索失败: {e}")
raise HTTPException(status_code=500, detail=str(e))
# ==================== 测试模式 ====================
def run_test_mode():
"""
测试模式:验证模型加载、数据库连接、向量检索全流程
"""
logger.info("🧪 进入测试模式...")
# 1. 测试数据库连接
logger.info("1️⃣ 测试数据库连接...")
test_db = DatabasePool(CONFIG["db"])
if not test_db.init():
logger.error("❌ 数据库连接测试失败")
return False
# 检查表和数据
conn = test_db.get_conn()
cursor = conn.cursor()
try:
cursor.execute("SELECT COUNT(*) FROM products")
count = cursor.fetchone()[0]
logger.info(f" ✅ 数据库连接成功,现有商品: {count} 条")
# 检查向量字段
cursor.execute("""
SELECT id FROM products
WHERE text_embedding IS NOT NULL
LIMIT 1
""")
sample = cursor.fetchone()
if not sample:
logger.error("❌ 警告:没有找到带向量的数据,请先运行清洗脚本")
return False
logger.info(f" ✅ 向量数据检查通过(样例ID: {sample[0]})")
finally:
cursor.close()
test_db.put_conn(conn)
# 2. 测试Embedding模型
logger.info("2️⃣ 测试Embedding模型...")
test_embedder = Qwen3VLEmbeddingWrapper(CONFIG["model_paths"]["embedding"])
if not test_embedder.load():
logger.error("❌ Embedding模型加载失败")
return False
test_text = "测试:红色婴儿连体衣"
try:
vec = test_embedder.embed_text(test_text)
if len(vec) != CONFIG["vector_dim"]:
logger.error(f"❌ 向量维度错误: {len(vec)} != {CONFIG['vector_dim']}")
return False
logger.info(f" ✅ 文本Embedding测试通过,维度: {len(vec)}")
except Exception as e:
logger.error(f"❌ Embedding测试失败: {e}")
return False
# 测试图片Embedding(如果测试图片存在)
test_img_path = "/Users/Zhuanz/Desktop/work/spider/jd_data_merged/images/15_0.jpg"
if os.path.exists(test_img_path):
try:
vec = test_embedder.embed_image(test_img_path)
logger.info(f" ✅ 图片Embedding测试通过,维度: {len(vec)}")
except Exception as e:
logger.warning(f"⚠️ 图片Embedding测试失败: {e}")
# 3. 测试Reranker模型
logger.info("3️⃣ 测试Reranker模型...")
test_reranker = Qwen3VLRerankerWrapper(CONFIG["model_paths"]["reranker"])
if not test_reranker.load():
logger.error("❌ Reranker模型加载失败")
return False
# 构造假候选测试Reranker
fake_candidates = [
{
"id": "test_1",
"title": "测试商品:红色婴儿连体衣",
"searchable_text": "婴儿 连体衣 红色 保暖",
"image_local_path": test_img_path if os.path.exists(test_img_path) else "",
"price": 199.0
}
]
try:
result = test_reranker.rerank("红色婴儿衣服", None, fake_candidates)
logger.info(f" ✅ Reranker测试通过,输出分数: {result[0].get('rerank_score', 'N/A')}")
except Exception as e:
logger.warning(f"⚠️ Reranker测试失败: {e},但可继续运行(将使用Fallback模式)")
# 4. 测试完整检索流程
logger.info("4️⃣ 测试完整检索流程...")
test_retriever = MultimodalRetriever(test_db, test_embedder, test_reranker)
try:
results = test_retriever.search(
query_text="红色婴儿衣服",
query_image_b64=None,
filters={"price_max": 500},
mode="text"
)
if results:
logger.info(f" ✅ 检索流程测试通过,返回 {len(results)} 条结果")
logger.info(f" 📊 第一条结果: {results[0]['title'][:50]}... (分数: {results[0].get('rerank_score', results[0].get('similarity', 'N/A')):.3f})")
else:
logger.warning("⚠️ 检索返回空结果,可能是数据库中无匹配数据")
except Exception as e:
logger.error(f"❌ 检索流程测试失败: {e}")
return False
# 5. 测试API端点(启动服务测试)
logger.info("5️⃣ 测试API端点...")
try:
import requests
# 注意:这里需要服务已启动,实际测试可手动curl
logger.info(" ℹ️ 请手动测试: curl http://localhost:8000/health")
except:
pass
logger.info("✅ 所有测试通过!可以正式运行服务")
test_db.close()
return True
def main():
import argparse
parser = argparse.ArgumentParser(description="Qwen3-VL 多模态检索API")
parser.add_argument("--test", type=bool, default=False, help="运行测试模式验证环境")
parser.add_argument("--host", default="0.0.0.0", help="绑定地址")
parser.add_argument("--port", type=int, default=8000, help="端口")
args = parser.parse_args()
if args.test:
success = run_test_mode()
sys.exit(0 if success else 1)
else:
# 正式运行前快速检查
logger.info("🔍 启动前快速检查(使用--test进行完整测试)...")
uvicorn.run(app, host=args.host, port=args.port)
if __name__ == "__main__":
main()执行uv run retrieval_api.py,启动检索API服务

测试图搜图
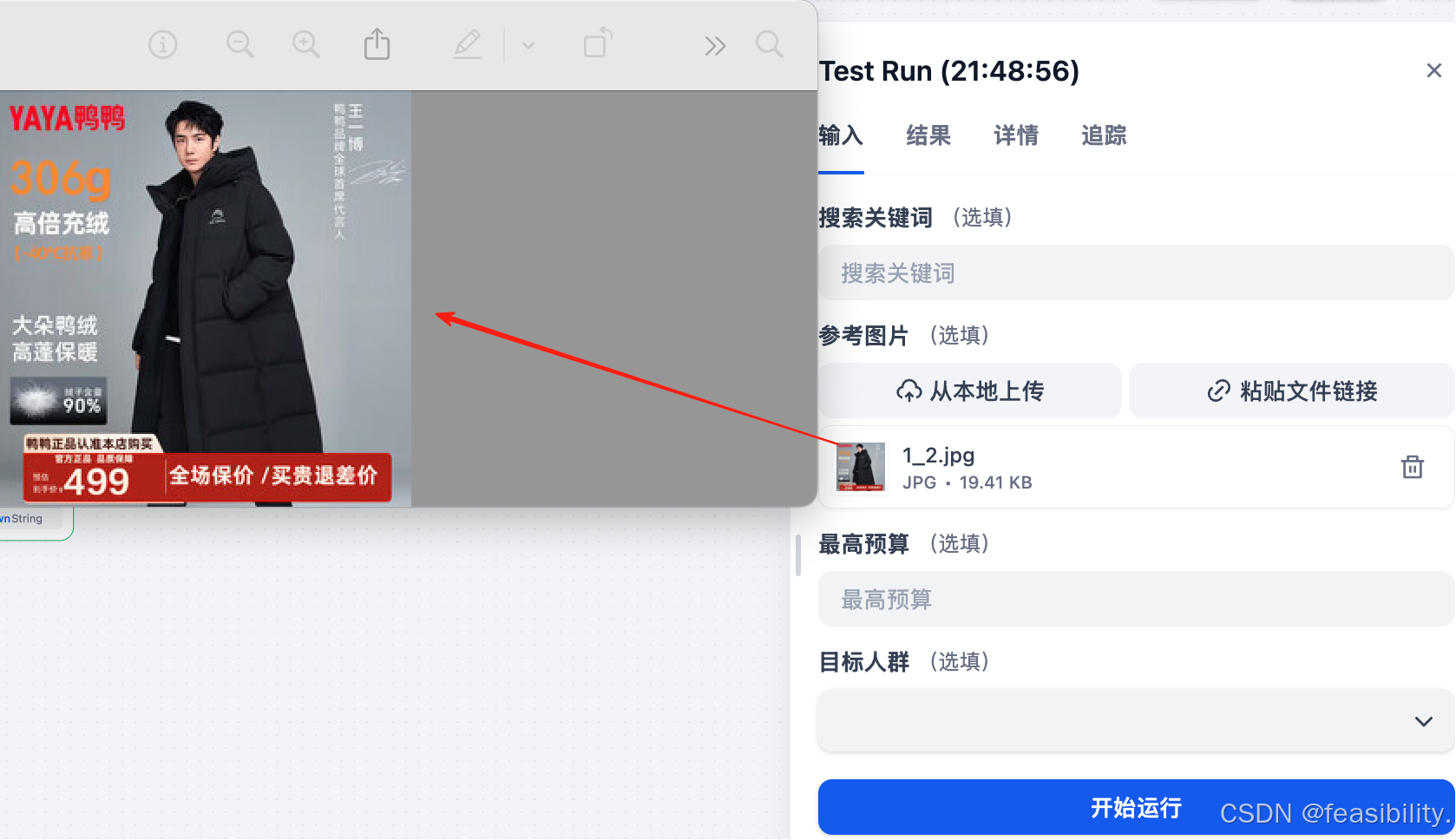

成功找到相似产品


测试文搜图
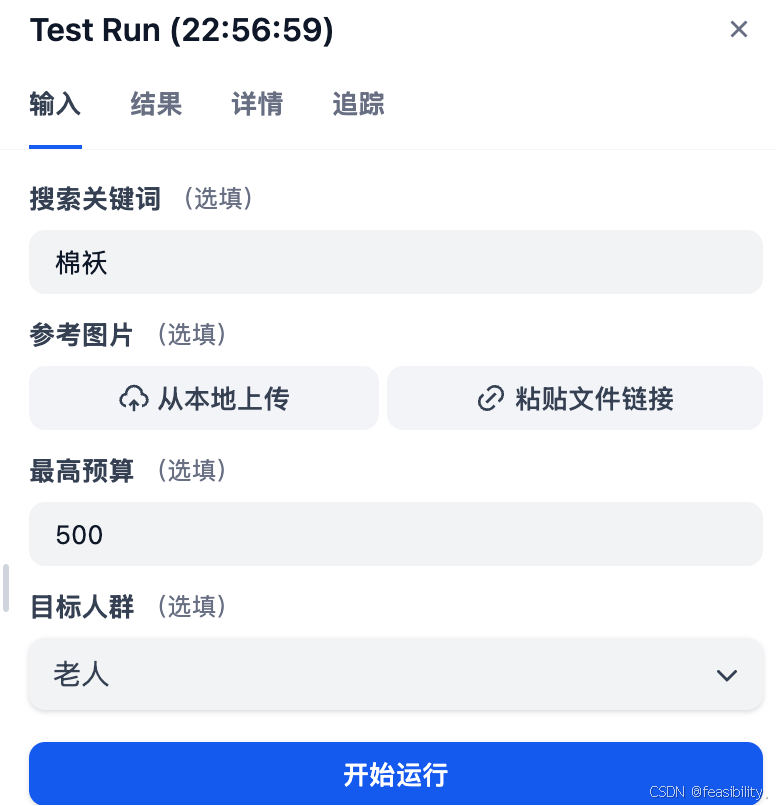
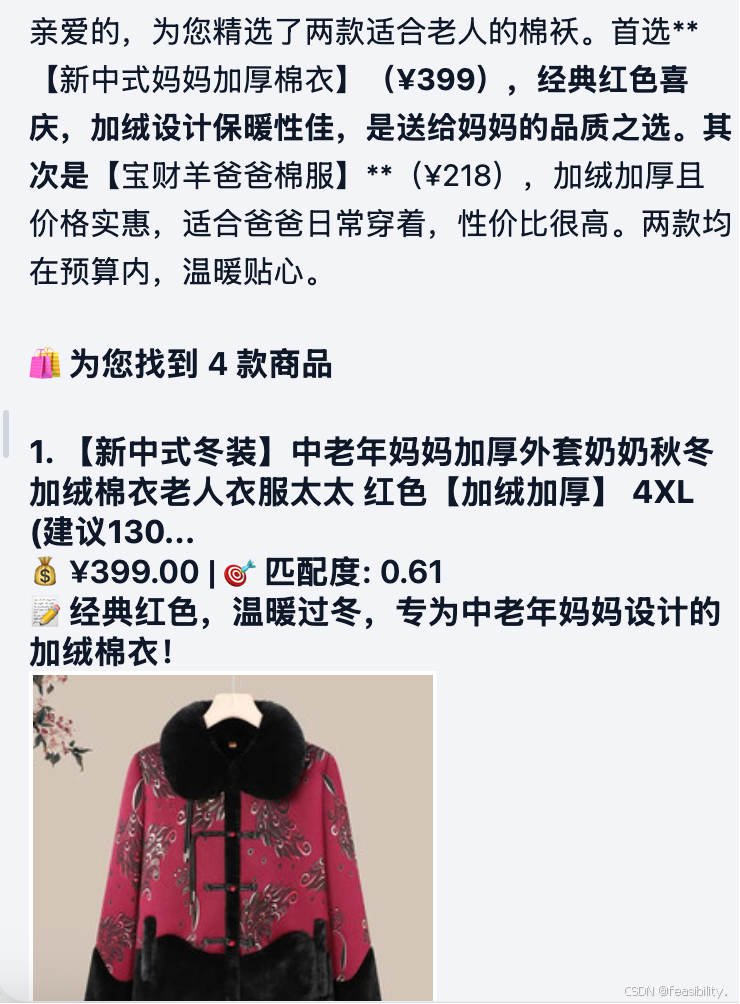

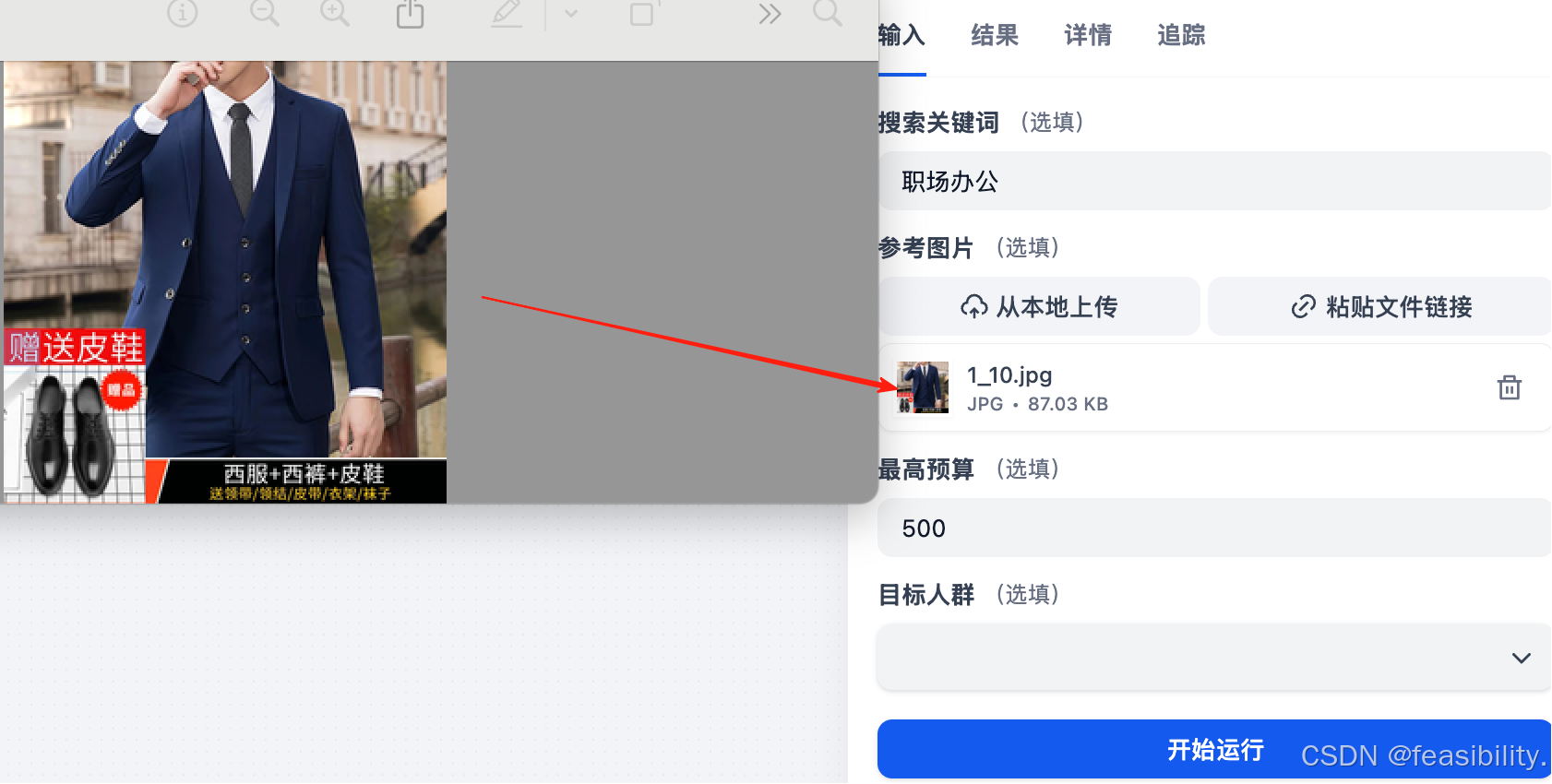
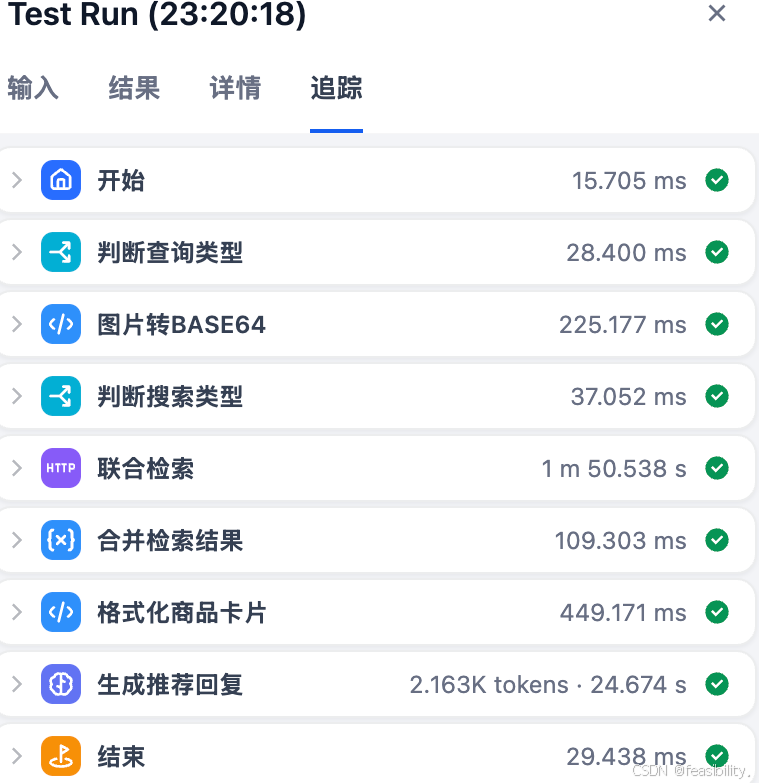
测试混合搜索




至此,本系统基本实现了图文多模态检索的智能电商助手/工作流,后续优化可考虑量化和微调提高速度和准确性
如果有需要数据和这个工作流,可以通过网盘分享的文件获取:ShopDataSrc.zip
链接: https://pan.baidu.com/s/13R-yOPYU_ftSnMTaCZzeGQ?pwd=na53 提取码: na53
创作不易,禁止抄袭,转载请附上原文链接及标题