LLaMA-Factory基于Lora微调实践
LLaMA-Factory
LLaMA-Factory 是一个开源的一站式大型语言模型(LLM)训练与微调平台,由国内社区开发,旨在简化大模型的开发流程,降低技术门槛。其核心目标是让开发者无需编写复杂代码即可完成模型训练、优化和部署,同时支持多模态任务和跨硬件平台运行。以下从核心功能、技术特点、应用场景等方面展开介绍:
一、核心功能与特点
-
多模型支持与扩展性
支持上百种主流模型,包括 LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、ChatGLM 等,覆盖从 135M 到 235B 参数的轻量级到超大规模模型。2025 年 v0.9.3 版本新增 InternVL3、Qwen3、Gemma3 等多模态模型,支持视觉、文本、音频的综合推理,例如音视频 2 文本转换和高分辨率图像生成。
-
多样化训练与优化技术
- 训练算法:支持增量预训练、指令监督微调、奖励模型训练(RM)、PPO/DPO/ORPO 等强化学习方法,以及 KTO、GaLore、DoRA 等创新优化算法。
- 量化与轻量化:提供 2/4/8 比特 QLoRA 微调,结合 AQLM、AWQ、GPTQ 等技术,显著降低显存需求。例如,4 比特量化可在单卡(如 RTX 4090)上微调 7B 模型,同时保持较高性能。
- 加速算子:集成 FlashAttention-2 和 Unsloth,提升训练速度;引入 Muon 优化器,收敛速度比传统方法快 30% 以上。
-
低代码与可视化工具
- Web UI 界面:通过图形化界面(LlamaBoard)实现无代码操作,支持模型参数配置、训练监控(如实时损失曲线)和推理测试。
- 调试与部署辅助:自动将训练命令转换为 VSCode 调试配置,生成 OpenAI 风格 API 和 Docker 镜像,简化开发与生产部署流程。
- 显存预估与资源管理:提供训练显存占用预估工具,帮助用户合理分配硬件资源。
-
多模态与云原生支持
- 多模态推理:新增音视频推理支持,例如 Qwen2.5-Omni 模型可处理实时多媒体数据,适用于直播客服、视频摘要等场景。
- 云端集成:原生支持 AWS S3、Google Cloud Storage,方便在云环境中进行大规模训练,并提供官方 GPU Docker 镜像,减少环境配置复杂度。
二、技术优势与性能表现
-
效率与成本优化
- 与传统 P-Tuning 相比,LoRA 微调速度提升 3.7 倍,且在广告文案生成任务中 Rouge 分数更高;结合 4 比特量化,显存消耗降低 80% 以上。
- 支持分布式训练和容错机制(PyTorch-elastic),增强大规模训练的稳定性。
-
兼容性与生态适配
- 适配国内网络环境,可通过 ModelScope 库下载模型,解决依赖安装问题。
- 支持多硬件平台(NVIDIA GPU、Ascend NPU 等)和多种推理引擎(vLLM、Transformers),兼容 Hugging Face 和 OpenAI 接口。
三、与其他框架的对比
| 框架 | 优势场景 | 局限性 |
|---|---|---|
| LLaMA-Factory | 低代码多模型实验、多模态任务、资源受限环境(如单卡训练)、国内网络适配 | 超大规模模型全参数微调需依赖分布式训练工具(如 DeepSpeed) |
| Hugging Face | 灵活调整底层逻辑、复用成熟生态(如 Datasets、Accelerate) | 配置复杂度较高,对新手不够友好 |
| DeepSpeed | 千亿参数级模型全参数微调、多节点集群训练 | 学习成本高,需专业分布式系统知识 |
| Unsloth | 极致效率优化、单卡快速微调 | 模型支持范围较窄,缺乏多模态功能 |
安装LLaMA-Factory
Bash
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
pip install --no-deps -e .LLaMA-Factory 校验完成安装后,可以通过使用以下命令。
Bash
llamafactory-cli version网页版
bash
llamafactory-cli webuimodelscope
启动环境后在终端里执行上述安装命令行

问题1
bash
oot@eais-bjyqq232zv0ne6saxp0j-0:/mnt/workspace/LLaMA-Factory# llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
2025-09-19 00:24:39.974452: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-09-19 00:24:41.537597: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
[2025-09-19 00:24:47,083] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2025-09-19 00:24:50,277] [INFO] [logging.py:107:log_dist] [Rank -1] [TorchCheckpointEngine] Initialized with serialization = False
[INFO|2025-09-19 00:24:53] llamafactory.hparams.parser:414 >> Process rank: 0, world size: 1, device: cuda:0, distributed training: False, compute dtype: torch.bfloat16
[INFO|tokenization_auto.py:898] 2025-09-19 00:25:03,298 >> Could not locate the tokenizer configuration file, will try to use the model config instead.
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/urllib3/connectionpool.py", line 787, in urlopen
response = self._make_request(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/urllib3/connectionpool.py", line 488, in _make_request
raise new_e
File "/usr/local/lib/python3.11/site-packages/urllib3/connectionpool.py", line 464, in _make_request
self._validate_conn(conn)
File "/usr/local/lib/python3.11/site-packages/urllib3/connectionpool.py", line 1093, in _validate_conn
conn.connect()
File "/usr/local/lib/python3.11/site-packages/urllib3/connection.py", line 741, in connect
sock_and_verified = _ssl_wrap_socket_and_match_hostname(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/urllib3/connection.py", line 920, in _ssl_wrap_socket_and_match_hostname
ssl_sock = ssl_wrap_socket(
^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/urllib3/util/ssl_.py", line 460, in ssl_wrap_socket
ssl_sock = _ssl_wrap_socket_impl(sock, context, tls_in_tls, server_hostname)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/urllib3/util/ssl_.py", line 504, in _ssl_wrap_socket_impl
return ssl_context.wrap_socket(sock, server_hostname=server_hostname)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/ssl.py", line 517, in wrap_socket
return self.sslsocket_class._create(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/ssl.py", line 1104, in _create
self.do_handshake()
File "/usr/local/lib/python3.11/ssl.py", line 1382, in do_handshake
self._sslobj.do_handshake()
ConnectionResetError: [Errno 104] Connection reset by peer
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/requests/adapters.py", line 667, in send
resp = conn.urlopen(
^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/urllib3/connectionpool.py", line 841, in urlopen
retries = retries.increment(
^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/urllib3/util/retry.py", line 474, in increment
raise reraise(type(error), error, _stacktrace)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/urllib3/util/util.py", line 38, in reraise
raise value.with_traceback(tb)
File "/usr/local/lib/python3.11/site-packages/urllib3/connectionpool.py", line 787, in urlopen
response = self._make_request(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/urllib3/connectionpool.py", line 488, in _make_request
raise new_e
File "/usr/local/lib/python3.11/site-packages/urllib3/connectionpool.py", line 464, in _make_request
self._validate_conn(conn)
File "/usr/local/lib/python3.11/site-packages/urllib3/connectionpool.py", line 1093, in _validate_conn
conn.connect()
File "/usr/local/lib/python3.11/site-packages/urllib3/connection.py", line 741, in connect
sock_and_verified = _ssl_wrap_socket_and_match_hostname(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/urllib3/connection.py", line 920, in _ssl_wrap_socket_and_match_hostname
ssl_sock = ssl_wrap_socket(
^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/urllib3/util/ssl_.py", line 460, in ssl_wrap_socket
ssl_sock = _ssl_wrap_socket_impl(sock, context, tls_in_tls, server_hostname)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/urllib3/util/ssl_.py", line 504, in _ssl_wrap_socket_impl
return ssl_context.wrap_socket(sock, server_hostname=server_hostname)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/ssl.py", line 517, in wrap_socket
return self.sslsocket_class._create(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/ssl.py", line 1104, in _create
self.do_handshake()
File "/usr/local/lib/python3.11/ssl.py", line 1382, in do_handshake
self._sslobj.do_handshake()
urllib3.exceptions.ProtocolError: ('Connection aborted.', ConnectionResetError(104, 'Connection reset by peer'))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 1546, in _get_metadata_or_catch_error
metadata = get_hf_file_metadata(
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 1463, in get_hf_file_metadata
r = _request_wrapper(
^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 286, in _request_wrapper
response = _request_wrapper(
^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 309, in _request_wrapper
response = http_backoff(method=method, url=url, **params, retry_on_exceptions=(), retry_on_status_codes=(429,))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/huggingface_hub/utils/_http.py", line 310, in http_backoff
response = session.request(method=method, url=url, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/requests/sessions.py", line 589, in request
resp = self.send(prep, **send_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/requests/sessions.py", line 703, in send
r = adapter.send(request, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/huggingface_hub/utils/_http.py", line 96, in send
return super().send(request, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/requests/adapters.py", line 682, in send
raise ConnectionError(err, request=request)
requests.exceptions.ConnectionError: (ProtocolError('Connection aborted.', ConnectionResetError(104, 'Connection reset by peer')), '(Request ID: 51f18b4c-b12c-4abf-8194-bdee3cce9b3e)')
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/transformers/utils/hub.py", line 479, in cached_files
hf_hub_download(
File "/usr/local/lib/python3.11/site-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 1010, in hf_hub_download
return _hf_hub_download_to_cache_dir(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 1117, in _hf_hub_download_to_cache_dir
_raise_on_head_call_error(head_call_error, force_download, local_files_only)
File "/usr/local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 1661, in _raise_on_head_call_error
raise LocalEntryNotFoundError(
huggingface_hub.errors.LocalEntryNotFoundError: An error happened while trying to locate the file on the Hub and we cannot find the requested files in the local cache. Please check your connection and try again or make sure your Internet connection is on.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/mnt/workspace/LLaMA-Factory/src/llamafactory/model/loader.py", line 78, in load_tokenizer
tokenizer = AutoTokenizer.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/models/auto/tokenization_auto.py", line 1069, in from_pretrained
config = AutoConfig.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/models/auto/configuration_auto.py", line 1250, in from_pretrained
config_dict, unused_kwargs = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/configuration_utils.py", line 649, in get_config_dict
config_dict, kwargs = cls._get_config_dict(pretrained_model_name_or_path, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/configuration_utils.py", line 708, in _get_config_dict
resolved_config_file = cached_file(
^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/utils/hub.py", line 321, in cached_file
file = cached_files(path_or_repo_id=path_or_repo_id, filenames=[filename], **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/utils/hub.py", line 553, in cached_files
raise OSError(
OSError: We couldn't connect to 'https://huggingface.co' to load the files, and couldn't find them in the cached files.
Check your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/bin/llamafactory-cli", line 7, in <module>
sys.exit(main())
^^^^^^
File "/mnt/workspace/LLaMA-Factory/src/llamafactory/cli.py", line 151, in main
COMMAND_MAP[command]()
File "/mnt/workspace/LLaMA-Factory/src/llamafactory/train/tuner.py", line 110, in run_exp
_training_function(config={"args": args, "callbacks": callbacks})
File "/mnt/workspace/LLaMA-Factory/src/llamafactory/train/tuner.py", line 72, in _training_function
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/mnt/workspace/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 48, in run_sft
tokenizer_module = load_tokenizer(model_args)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/mnt/workspace/LLaMA-Factory/src/llamafactory/model/loader.py", line 93, in load_tokenizer
raise OSError("Failed to load tokenizer.") from e
OSError: Failed to load tokenizer.
root@eais-bjyqq232zv0ne6saxp0j-0:/mnt/workspace/LLaMA-Factory#原因是 "网络受限无法下载模型" 问题。。。。。
思路
ModelScope 平台本身托管了大量模型(包括 LLaMA 3 的衍生版本或镜像),通过其官方工具 modelscope 下载的模型会保存在本地,可直接被 LLaMA Factory 加载,完全规避 Hugging Face Hub 的网络依赖。
分步操作
1. 安装 ModelScope 库
首先确保 modelscope 工具已安装(若未安装):
bash
pip install modelscope --upgrade # 安装或升级到最新版本2. 下载 LLaMA 3 模型(从 ModelScope)
执行以下命令下载模型到本地(以你提到的 LLM-Research/Meta-Llama-3-8B-Instruct 为例,这是 ModelScope 上的一个 LLaMA 3 指令微调版本,已获得授权可直接下载):
bash
# 下载模型到指定目录(建议放在 workspace 下,如 /mnt/workspace/models/)
modelscope download --model LLM-Research/Meta-Llama-3-8B-Instruct --local_dir /mnt/workspace/models/Meta-Llama-3-8B-Instruct- 说明 :
--model指定 ModelScope 上的模型 ID(LLM-Research/Meta-Llama-3-8B-Instruct是有效的公开可下载版本);--local_dir指定本地保存路径(建议用绝对路径,方便后续配置);- 下载完成后,模型文件(包括 Tokenizer、配置文件等)会保存在
/mnt/workspace/models/Meta-Llama-3-8B-Instruct中。
3. 验证模型文件完整性
下载完成后,检查本地路径下是否包含必需文件(确保 Tokenizer 能被加载):
bash
# 列出关键文件,确认存在
ls -l /mnt/workspace/models/Meta-Llama-3-8B-Instruct | grep -E "tokenizer|config|vocab"- 正确输出应包含:
tokenizer_config.json、tokenizer.model(或vocab.json)、config.json等,若缺失则需重新下载。
4. 修改 LLaMA Factory 配置,指向 ModelScope 下载的本地模型
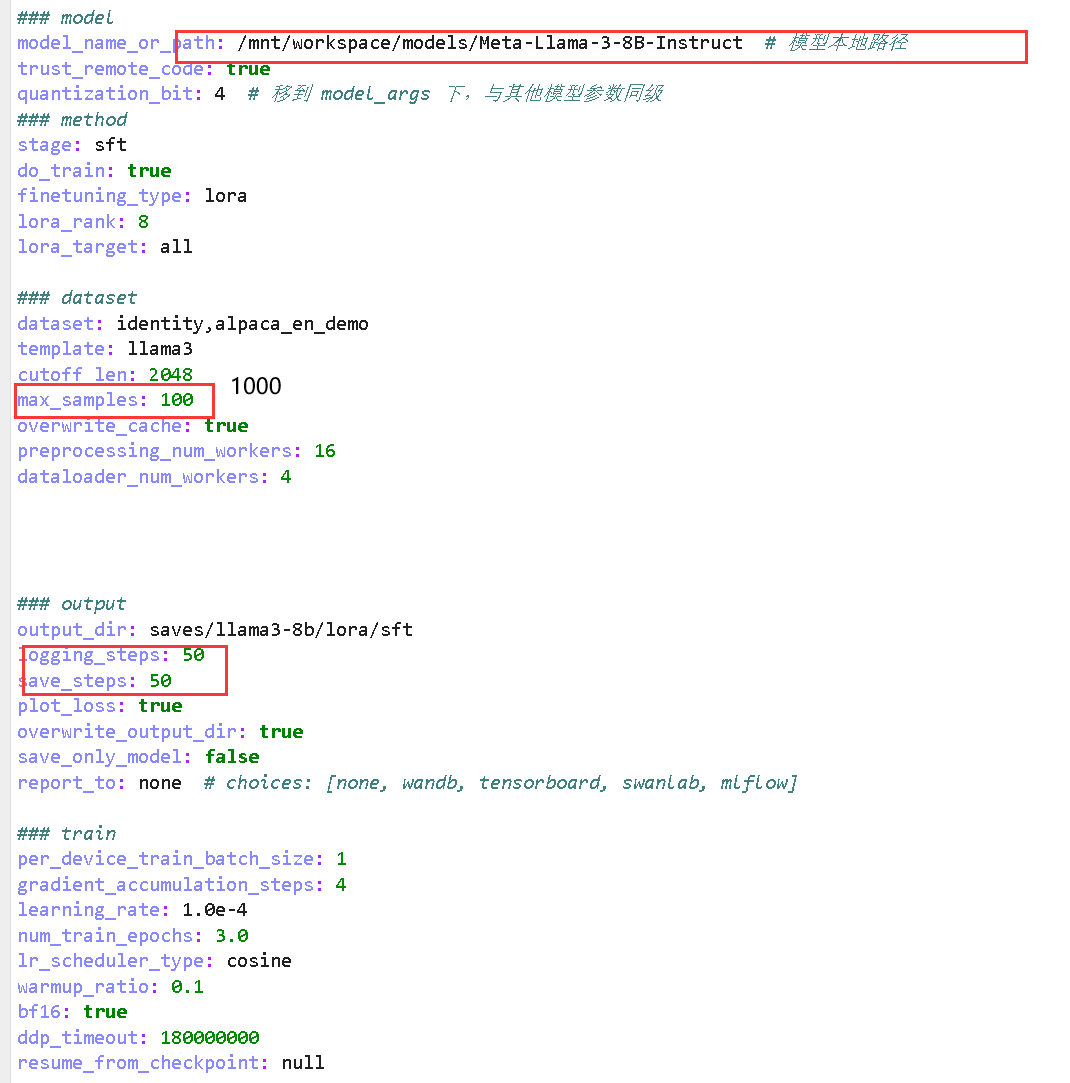
编辑训练配置文件 examples/train_lora/llama3_lora_sft.yaml,将 model_name_or_path 改为 ModelScope 下载的本地路径:
bash
# 编辑配置文件
vim examples/train_lora/llama3_lora_sft.yaml-
找到
model_name_or_path字段,修改为:yamlmodel_name_or_path: /mnt/workspace/models/Meta-Llama-3-8B-Instruct # 替换为你的实际下载路径 -
保存退出(
Esc+:wq)。
5. 执行训练(强制离线模式)
通过环境变量强制使用本地模型,避免任何联网操作:
bash
# 强制离线模式 + 执行训练
TRANSFORMERS_OFFLINE=1 HF_HUB_OFFLINE=1 llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml问题2
bash
root@eais-bjyqq232zv0ne6saxp0j-0:/mnt/workspace/LLaMA-Factory# # 强制离线模式 + 执行训练
TRANSFORMERS_OFFLINE=1 HF_HUB_OFFLINE=1 llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
2025-09-19 00:38:01.042429: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-09-19 00:38:02.605165: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
[2025-09-19 00:38:08,060] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2025-09-19 00:38:11,061] [INFO] [logging.py:107:log_dist] [Rank -1] [TorchCheckpointEngine] Initialized with serialization = False
[INFO|2025-09-19 00:38:14] llamafactory.hparams.parser:414 >> Process rank: 0, world size: 1, device: cuda:0, distributed training: False, compute dtype: torch.bfloat16
[INFO|hub.py:420] 2025-09-19 00:38:14,019 >> Offline mode: forcing local_files_only=True
[INFO|tokenization_utils_base.py:1923] 2025-09-19 00:38:14,020 >> Offline mode: forcing local_files_only=True
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,021 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,021 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,021 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,021 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,022 >> loading file tokenizer_config.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,022 >> loading file chat_template.jinja
[INFO|tokenization_utils_base.py:2336] 2025-09-19 00:38:14,501 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|hub.py:420] 2025-09-19 00:38:14,501 >> Offline mode: forcing local_files_only=True
[INFO|hub.py:420] 2025-09-19 00:38:14,501 >> Offline mode: forcing local_files_only=True
[INFO|hub.py:420] 2025-09-19 00:38:14,501 >> Offline mode: forcing local_files_only=True
[INFO|hub.py:420] 2025-09-19 00:38:14,501 >> Offline mode: forcing local_files_only=True
[INFO|hub.py:420] 2025-09-19 00:38:14,502 >> Offline mode: forcing local_files_only=True
[INFO|hub.py:420] 2025-09-19 00:38:14,502 >> Offline mode: forcing local_files_only=True
[INFO|configuration_utils.py:750] 2025-09-19 00:38:14,503 >> loading configuration file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:817] 2025-09-19 00:38:14,512 >> Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128009,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.55.2",
"use_cache": true,
"vocab_size": 128256
}
[INFO|hub.py:420] 2025-09-19 00:38:14,512 >> Offline mode: forcing local_files_only=True
[INFO|tokenization_utils_base.py:1923] 2025-09-19 00:38:14,513 >> Offline mode: forcing local_files_only=True
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,514 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,514 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,514 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,514 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,514 >> loading file tokenizer_config.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:38:14,514 >> loading file chat_template.jinja
[INFO|tokenization_utils_base.py:2336] 2025-09-19 00:38:14,984 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|2025-09-19 00:38:15] llamafactory.data.template:143 >> Add pad token: <|eot_id|>
[INFO|2025-09-19 00:38:15] llamafactory.data.template:143 >> Add <|eom_id|> to stop words.
[WARNING|2025-09-19 00:38:15] llamafactory.data.template:148 >> New tokens have been added, make sure `resize_vocab` is True.
[INFO|2025-09-19 00:38:15] llamafactory.data.loader:143 >> Loading dataset identity.json...
Setting num_proc from 16 back to 1 for the train split to disable multiprocessing as it only contains one shard.
Generating train split: 91 examples [00:00, 4811.44 examples/s]
Converting format of dataset (num_proc=16): 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 91/91 [00:00<00:00, 242.83 examples/s]
[INFO|2025-09-19 00:38:16] llamafactory.data.loader:143 >> Loading dataset alpaca_en_demo.json...
Setting num_proc from 16 back to 1 for the train split to disable multiprocessing as it only contains one shard.
Generating train split: 999 examples [00:00, 38892.38 examples/s]
Converting format of dataset (num_proc=16): 100%|████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:00<00:00, 287.77 examples/s]
Running tokenizer on dataset (num_proc=16): 100%|█████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:07<00:00, 24.90 examples/s]
training example:
input_ids:
[128000, 128006, 882, 128007, 271, 6151, 128009, 128006, 78191, 128007, 271, 9906, 0, 358, 1097, 5991, 609, 39254, 459, 15592, 18328, 8040, 555, 5991, 3170, 3500, 13, 2650, 649, 358, 7945, 499, 3432, 30, 128009]
inputs:
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
hi<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?<|eot_id|>
label_ids:
[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 9906, 0, 358, 1097, 5991, 609, 39254, 459, 15592, 18328, 8040, 555, 5991, 3170, 3500, 13, 2650, 649, 358, 7945, 499, 3432, 30, 128009]
labels:
Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?<|eot_id|>
[INFO|hub.py:420] 2025-09-19 00:38:26,090 >> Offline mode: forcing local_files_only=True
[INFO|configuration_utils.py:750] 2025-09-19 00:38:26,090 >> loading configuration file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:817] 2025-09-19 00:38:26,091 >> Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128009,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.55.2",
"use_cache": true,
"vocab_size": 128256
}
[INFO|2025-09-19 00:38:26] llamafactory.model.model_utils.kv_cache:143 >> KV cache is disabled during training.
[INFO|modeling_utils.py:4823] 2025-09-19 00:38:27,394 >> Offline mode: forcing local_files_only=True
[INFO|modeling_utils.py:1306] 2025-09-19 00:38:27,394 >> loading weights file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/model.safetensors.index.json
[INFO|modeling_utils.py:2412] 2025-09-19 00:38:27,395 >> Instantiating LlamaForCausalLM model under default dtype torch.bfloat16.
[INFO|configuration_utils.py:1098] 2025-09-19 00:38:27,398 >> Generate config GenerationConfig {
"bos_token_id": 128000,
"eos_token_id": 128009,
"use_cache": false
}
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:03<00:00, 1.03it/s]
[INFO|modeling_utils.py:5614] 2025-09-19 00:38:31,395 >> All model checkpoint weights were used when initializing LlamaForCausalLM.
[INFO|modeling_utils.py:5622] 2025-09-19 00:38:31,395 >> All the weights of LlamaForCausalLM were initialized from the model checkpoint at /mnt/workspace/models/Meta-Llama-3-8B-Instruct.
If your task is similar to the task the model of the checkpoint was trained on, you can already use LlamaForCausalLM for predictions without further training.
[INFO|configuration_utils.py:1051] 2025-09-19 00:38:31,398 >> loading configuration file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/generation_config.json
[INFO|configuration_utils.py:1098] 2025-09-19 00:38:31,399 >> Generate config GenerationConfig {
"bos_token_id": 128000,
"do_sample": true,
"eos_token_id": [
128001,
128009
],
"max_length": 4096,
"temperature": 0.6,
"top_p": 0.9
}
[INFO|2025-09-19 00:38:31] llamafactory.model.model_utils.checkpointing:143 >> Gradient checkpointing enabled.
[INFO|2025-09-19 00:38:31] llamafactory.model.model_utils.attention:143 >> Using torch SDPA for faster training and inference.
[INFO|2025-09-19 00:38:31] llamafactory.model.adapter:143 >> Upcasting trainable params to float32.
[INFO|2025-09-19 00:38:31] llamafactory.model.adapter:143 >> Fine-tuning method: LoRA
[INFO|2025-09-19 00:38:31] llamafactory.model.model_utils.misc:143 >> Found linear modules: gate_proj,o_proj,down_proj,v_proj,up_proj,k_proj,q_proj
/usr/local/lib/python3.11/site-packages/awq/__init__.py:21: DeprecationWarning:
I have left this message as the final dev message to help you transition.
Important Notice:
- AutoAWQ is officially deprecated and will no longer be maintained.
- The last tested configuration used Torch 2.6.0 and Transformers 4.51.3.
- If future versions of Transformers break AutoAWQ compatibility, please report the issue to the Transformers project.
Alternative:
- AutoAWQ has been adopted by the vLLM Project: https://github.com/vllm-project/llm-compressor
For further inquiries, feel free to reach out:
- X: https://x.com/casper_hansen_
- LinkedIn: https://www.linkedin.com/in/casper-hansen-804005170/
warnings.warn(_FINAL_DEV_MESSAGE, category=DeprecationWarning, stacklevel=1)
[INFO|2025-09-19 00:38:33] llamafactory.model.loader:143 >> trainable params: 20,971,520 || all params: 8,051,232,768 || trainable%: 0.2605
[INFO|trainer.py:757] 2025-09-19 00:38:33,718 >> Using auto half precision backend
[INFO|trainer.py:2433] 2025-09-19 00:38:34,396 >> ***** Running training *****
[INFO|trainer.py:2434] 2025-09-19 00:38:34,396 >> Num examples = 191
[INFO|trainer.py:2435] 2025-09-19 00:38:34,396 >> Num Epochs = 3
[INFO|trainer.py:2436] 2025-09-19 00:38:34,396 >> Instantaneous batch size per device = 1
[INFO|trainer.py:2439] 2025-09-19 00:38:34,396 >> Total train batch size (w. parallel, distributed & accumulation) = 8
[INFO|trainer.py:2440] 2025-09-19 00:38:34,397 >> Gradient Accumulation steps = 8
[INFO|trainer.py:2441] 2025-09-19 00:38:34,397 >> Total optimization steps = 72
[INFO|trainer.py:2442] 2025-09-19 00:38:34,402 >> Number of trainable parameters = 20,971,520
0%| | 0/72 [00:00<?, ?it/s]Traceback (most recent call last):
File "/usr/local/bin/llamafactory-cli", line 7, in <module>
sys.exit(main())
^^^^^^
File "/mnt/workspace/LLaMA-Factory/src/llamafactory/cli.py", line 151, in main
COMMAND_MAP[command]()
File "/mnt/workspace/LLaMA-Factory/src/llamafactory/train/tuner.py", line 110, in run_exp
_training_function(config={"args": args, "callbacks": callbacks})
File "/mnt/workspace/LLaMA-Factory/src/llamafactory/train/tuner.py", line 72, in _training_function
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/mnt/workspace/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 96, in run_sft
train_result = trainer.train(resume_from_checkpoint=training_args.resume_from_checkpoint)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/trainer.py", line 2238, in train
return inner_training_loop(
^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/trainer.py", line 2582, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs, num_items_in_batch)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/trainer.py", line 3796, in training_step
loss = self.compute_loss(model, inputs, num_items_in_batch=num_items_in_batch)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/mnt/workspace/LLaMA-Factory/src/llamafactory/train/sft/trainer.py", line 108, in compute_loss
return super().compute_loss(model, inputs, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/trainer.py", line 3884, in compute_loss
outputs = model(**inputs)
^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1541, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/accelerate/utils/operations.py", line 818, in forward
return model_forward(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/accelerate/utils/operations.py", line 806, in __call__
return convert_to_fp32(self.model_forward(*args, **kwargs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/torch/amp/autocast_mode.py", line 16, in decorate_autocast
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/peft/peft_model.py", line 1850, in forward
return self.base_model(
^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1541, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/peft/tuners/tuners_utils.py", line 222, in forward
return self.model.forward(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/utils/generic.py", line 959, in wrapper
output = func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py", line 460, in forward
outputs: BaseModelOutputWithPast = self.model(
^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1541, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/utils/generic.py", line 1083, in wrapper
outputs = func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py", line 387, in forward
position_embeddings = self.rotary_emb(hidden_states, position_ids)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1541, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/modeling_rope_utils.py", line 87, in wrapper
return rope_forward(self, x, position_ids)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py", line 98, in forward
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
~~~~~~~~~~~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling `cublasCreate(handle)`
0%| | 0/72 [00:01<?, ?it/s]
root@eais-bjyqq232zv0ne6saxp0j-0:/mnt/workspace/LLaMA-Factory#思路
从日志来看,之前的核心问题(Tokenizer加载、模型本地读取)已完全解决 ,现在遇到的是新的 CUDA 运行时错误 :RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED(CUBLAS 库初始化失败)。这是 GPU 计算环境相关的问题,通常与 CUDA 驱动、GPU 资源占用或内存不足有关。以下是详细原因分析和分步骤解决方案:
一、原因定位
CUBLAS 是 NVIDIA 提供的 GPU 线性代数计算库,CUBLAS_STATUS_NOT_INITIALIZED 表示该库无法初始化,常见原因包括:
- GPU 未被正确识别或驱动异常 :PyTorch 能检测到 CUDA(日志中
device: cuda:0),但底层驱动与 CUDA 版本不兼容,或 GPU 硬件状态异常。 - GPU 内存不足:虽然未直接报"Out Of Memory (OOM)",但模型加载后剩余内存不足以初始化 CUBLAS 计算上下文(LLaMA-3-8B 模型加载后约占 8-10GB 显存,若剩余显存过少会触发此错误)。
- 多进程占用 GPU:Notebook 环境中可能有其他进程已占用 GPU 资源,导致当前训练进程无法获取初始化 CUBLAS 所需的资源。
二、分步骤解决方案
步骤1:检查 GPU 状态和资源占用
首先确认 GPU 是否正常、是否有其他进程占用资源:
-
执行以下命令查看 GPU 状态(型号、驱动版本、显存占用):
bashnvidia-smi- 关键查看项:
- GPU 状态 :是否显示
Failed或Off(若显示则是硬件/驱动问题,需联系平台运维); - Memory Usage:已用显存是否过高(如 total 16GB,used 15GB),剩余显存不足会导致 CUBLAS 初始化失败;
- Processes:是否有其他 Python 进程占用 GPU(若有,需终止该进程)。
- GPU 状态 :是否显示
- 关键查看项:
-
若有其他进程占用 GPU,执行以下命令终止(替换
<PID>为占用进程的 ID,从nvidia-smi的PID列获取):bashkill -9 <PID>
步骤2:验证 PyTorch 的 CUDA 可用性(排除版本不兼容)
确认 PyTorch 与 CUDA 版本匹配,且能正常调用 GPU:
-
执行以下 Python 命令验证:
bashpython -c " import torch print('PyTorch 版本:', torch.__version__) print('CUDA 版本:', torch.version.cuda) print('GPU 是否可用:', torch.cuda.is_available()) print('GPU 设备数:', torch.cuda.device_count()) print('当前 GPU 型号:', torch.cuda.get_device_name(0)) # 尝试初始化 CUDA 上下文 try: x = torch.tensor([1.0]).cuda() print('CUDA 上下文初始化成功') except Exception as e: print('CUDA 上下文初始化失败:', e) " -
若输出以下结果,说明 PyTorch-CUDA 环境正常:
PyTorch 版本: 2.1.0+cu121 CUDA 版本: 12.1 GPU 是否可用: True GPU 设备数: 1 当前 GPU 型号: NVIDIA A100-SXM4-40GB CUDA 上下文初始化成功 -
若输出
GPU 是否可用: False或初始化失败:说明 PyTorch 未正确关联 CUDA,需重新安装与系统 CUDA 匹配的 PyTorch(ModelScope Notebook 通常已预装,可联系平台修复环境)。
步骤3:减少显存占用(解决内存不足问题)
LLaMA-3-8B 模型加载后显存占用较高,若剩余显存不足,需通过以下方式降低显存使用:
-
减小训练批次大小(最有效) :
编辑训练配置文件
examples/train_lora/llama3_lora_sft.yaml,修改per_device_train_batch_size从默认值(如 2)改为 1,并降低梯度累积步数:yamltraining_args: per_device_train_batch_size: 1 # 单卡训练批次大小,改为 1 gradient_accumulation_steps: 4 # 梯度累积步数,从 8 改为 4(总批次大小=1*4=4,仍保证训练稳定) fp16: true # 若 GPU 不支持 bfloat16(如 RTX 3090),改为 fp16(显存占用更低) -
启用更激进的显存优化 :
在训练命令中添加
--load_in_4bit或--load_in_8bit(使用 bitsandbytes 量化加载模型,显存占用可减少 50%+):bash# 量化加载模型(4bit 量化,显存占用降至 ~4GB)+ 离线模式 TRANSFORMERS_OFFLINE=1 HF_HUB_OFFLINE=1 llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml --model_name_or_path /mnt/workspace/models/Meta-Llama-3-8B-Instruct --load_in_4bit- 注意:需确保已安装 bitsandbytes 库,若未安装执行
pip install bitsandbytes。
- 注意:需确保已安装 bitsandbytes 库,若未安装执行
步骤4:重启 CUDA 服务(修复驱动临时异常)
若 GPU 状态正常但 CUBLAS 仍初始化失败,可尝试重启 CUDA 驱动(Notebook 环境需通过平台工具,或执行以下命令):
bash
# 重置 CUDA 设备(释放所有进程占用的 GPU 资源)
python -c "import torch; torch.cuda.empty_cache(); torch.cuda.reset_peak_memory_stats()"之后重新执行训练命令。
你以为对了?嘿~傻了吧,还不行
问题出在 命令行参数格式不正确 :--load_in_4bit 和 --model_name_or_path 未被 LLaMA Factory 的参数解析器识别,导致 ValueError。这是因为 LLaMA Factory 对命令行参数的命名和传递方式有特定要求,需按以下方式修正:
原因
LLaMA Factory 的参数解析器仅接受预定义的参数名,你使用的 --load_in_4bit 和 --model_name_or_path 不符合其规范:
- 量化参数 :正确的 4bit 量化参数名为
--quantization_bit 4(而非--load_in_4bit); - 模型路径参数 :
model_name_or_path应在配置文件中指定,或通过命令行参数--model_name_or_path传递(但需注意与配置文件的优先级,避免冲突)。
正确的命令行格式
修改命令如下,使用 LLaMA Factory 支持的参数名:
bash
# 正确格式:使用 --quantization_bit 4 启用 4bit 量化,模型路径优先以配置文件为准
TRANSFORMERS_OFFLINE=1 HF_HUB_OFFLINE=1 llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml --quantization_bit 4关键说明
-
量化参数 :
--quantization_bit 4是 LLaMA Factory 支持的标准参数,用于指定模型加载的量化精度(4bit 或 8bit),会自动触发 bitsandbytes 量化加载,降低显存占用。 -
模型路径 :
若已在配置文件
llama3_lora_sft.yaml中正确设置model_name_or_path: /mnt/workspace/models/Meta-Llama-3-8B-Instruct,则无需在命令行重复指定,避免参数冲突。 -
参数优先级 :
命令行参数的优先级高于配置文件,若需临时修改模型路径,可使用:
bash--model_name_or_path /mnt/workspace/models/Meta-Llama-3-8B-Instruct(注意参数名与配置文件一致,且无拼写错误)。
补充:若仍提示参数错误
若执行上述命令后仍报"未使用的参数",可能是 LLaMA Factory 版本兼容问题,此时建议在 配置文件中直接设置量化参数 :
编辑 examples/train_lora/llama3_lora_sft.yaml,添加或修改:
yaml
model_args:
quantization_bit: 4 # 4bit 量化加载模型
model_name_or_path: /mnt/workspace/models/Meta-Llama-3-8B-Instruct # 模型本地路径然后执行训练命令(无需额外命令行参数):
bash
TRANSFORMERS_OFFLINE=1 HF_HUB_OFFLINE=1 llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml运行结果
bash
root@eais-bjyqq232zv0ne6saxp0j-0:/mnt/workspace/LLaMA-Factory# TRANSFORMERS_OFFLINE=1 HF_HUB_OFFLINE=1 llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
2025-09-19 00:47:55.364138: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-09-19 00:47:56.931840: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
[2025-09-19 00:48:02,290] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2025-09-19 00:48:05,267] [INFO] [logging.py:107:log_dist] [Rank -1] [TorchCheckpointEngine] Initialized with serialization = False
[WARNING|2025-09-19 00:48:08] llamafactory.hparams.parser:148 >> We recommend enable `upcast_layernorm` in quantized training.
[INFO|2025-09-19 00:48:08] llamafactory.hparams.parser:414 >> Process rank: 0, world size: 1, device: cuda:0, distributed training: False, compute dtype: torch.bfloat16
[INFO|hub.py:420] 2025-09-19 00:48:08,254 >> Offline mode: forcing local_files_only=True
[INFO|tokenization_utils_base.py:1923] 2025-09-19 00:48:08,255 >> Offline mode: forcing local_files_only=True
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,256 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,256 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,256 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,256 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,256 >> loading file tokenizer_config.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,256 >> loading file chat_template.jinja
[INFO|tokenization_utils_base.py:2336] 2025-09-19 00:48:08,714 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|hub.py:420] 2025-09-19 00:48:08,715 >> Offline mode: forcing local_files_only=True
[INFO|hub.py:420] 2025-09-19 00:48:08,715 >> Offline mode: forcing local_files_only=True
[INFO|hub.py:420] 2025-09-19 00:48:08,715 >> Offline mode: forcing local_files_only=True
[INFO|hub.py:420] 2025-09-19 00:48:08,715 >> Offline mode: forcing local_files_only=True
[INFO|hub.py:420] 2025-09-19 00:48:08,715 >> Offline mode: forcing local_files_only=True
[INFO|hub.py:420] 2025-09-19 00:48:08,716 >> Offline mode: forcing local_files_only=True
[INFO|configuration_utils.py:750] 2025-09-19 00:48:08,716 >> loading configuration file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:817] 2025-09-19 00:48:08,721 >> Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128009,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.55.2",
"use_cache": true,
"vocab_size": 128256
}
[INFO|hub.py:420] 2025-09-19 00:48:08,721 >> Offline mode: forcing local_files_only=True
[INFO|tokenization_utils_base.py:1923] 2025-09-19 00:48:08,722 >> Offline mode: forcing local_files_only=True
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,723 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,723 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,723 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,723 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,723 >> loading file tokenizer_config.json
[INFO|tokenization_utils_base.py:2065] 2025-09-19 00:48:08,723 >> loading file chat_template.jinja
[INFO|tokenization_utils_base.py:2336] 2025-09-19 00:48:09,177 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|2025-09-19 00:48:09] llamafactory.data.template:143 >> Add pad token: <|eot_id|>
[INFO|2025-09-19 00:48:09] llamafactory.data.template:143 >> Add <|eom_id|> to stop words.
[WARNING|2025-09-19 00:48:09] llamafactory.data.template:148 >> New tokens have been added, make sure `resize_vocab` is True.
[INFO|2025-09-19 00:48:09] llamafactory.data.loader:143 >> Loading dataset identity.json...
Converting format of dataset (num_proc=16): 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 91/91 [00:00<00:00, 229.55 examples/s]
[INFO|2025-09-19 00:48:10] llamafactory.data.loader:143 >> Loading dataset alpaca_en_demo.json...
Converting format of dataset (num_proc=16): 100%|████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:00<00:00, 280.63 examples/s]
Running tokenizer on dataset (num_proc=16): 100%|█████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:07<00:00, 25.09 examples/s]
training example:
input_ids:
[128000, 128006, 882, 128007, 271, 6151, 128009, 128006, 78191, 128007, 271, 9906, 0, 358, 1097, 5991, 609, 39254, 459, 15592, 18328, 8040, 555, 5991, 3170, 3500, 13, 2650, 649, 358, 7945, 499, 3432, 30, 128009]
inputs:
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
hi<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?<|eot_id|>
label_ids:
[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 9906, 0, 358, 1097, 5991, 609, 39254, 459, 15592, 18328, 8040, 555, 5991, 3170, 3500, 13, 2650, 649, 358, 7945, 499, 3432, 30, 128009]
labels:
Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?<|eot_id|>
[INFO|hub.py:420] 2025-09-19 00:48:20,174 >> Offline mode: forcing local_files_only=True
[INFO|configuration_utils.py:750] 2025-09-19 00:48:20,175 >> loading configuration file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:817] 2025-09-19 00:48:20,176 >> Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128009,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.55.2",
"use_cache": true,
"vocab_size": 128256
}
[INFO|2025-09-19 00:48:20] llamafactory.model.model_utils.quantization:143 >> Quantizing model to 4 bit with bitsandbytes.
[INFO|2025-09-19 00:48:20] llamafactory.model.model_utils.kv_cache:143 >> KV cache is disabled during training.
[INFO|modeling_utils.py:4823] 2025-09-19 00:48:21,262 >> Offline mode: forcing local_files_only=True
[INFO|modeling_utils.py:1306] 2025-09-19 00:48:22,547 >> loading weights file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/model.safetensors.index.json
[INFO|modeling_utils.py:2412] 2025-09-19 00:48:22,547 >> Instantiating LlamaForCausalLM model under default dtype torch.bfloat16.
[INFO|configuration_utils.py:1098] 2025-09-19 00:48:22,550 >> Generate config GenerationConfig {
"bos_token_id": 128000,
"eos_token_id": 128009,
"use_cache": false
}
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:12<00:00, 3.13s/it]
[INFO|modeling_utils.py:5614] 2025-09-19 00:48:35,361 >> All model checkpoint weights were used when initializing LlamaForCausalLM.
[INFO|modeling_utils.py:5622] 2025-09-19 00:48:35,361 >> All the weights of LlamaForCausalLM were initialized from the model checkpoint at /mnt/workspace/models/Meta-Llama-3-8B-Instruct.
If your task is similar to the task the model of the checkpoint was trained on, you can already use LlamaForCausalLM for predictions without further training.
[INFO|configuration_utils.py:1051] 2025-09-19 00:48:35,366 >> loading configuration file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/generation_config.json
[INFO|configuration_utils.py:1098] 2025-09-19 00:48:35,367 >> Generate config GenerationConfig {
"bos_token_id": 128000,
"do_sample": true,
"eos_token_id": [
128001,
128009
],
"max_length": 4096,
"temperature": 0.6,
"top_p": 0.9
}
[INFO|2025-09-19 00:48:35] llamafactory.model.model_utils.checkpointing:143 >> Gradient checkpointing enabled.
[INFO|2025-09-19 00:48:35] llamafactory.model.model_utils.attention:143 >> Using torch SDPA for faster training and inference.
[INFO|2025-09-19 00:48:35] llamafactory.model.adapter:143 >> Upcasting trainable params to float32.
[INFO|2025-09-19 00:48:35] llamafactory.model.adapter:143 >> Fine-tuning method: LoRA
[INFO|2025-09-19 00:48:35] llamafactory.model.model_utils.misc:143 >> Found linear modules: down_proj,v_proj,up_proj,gate_proj,q_proj,k_proj,o_proj
[INFO|2025-09-19 00:48:36] llamafactory.model.loader:143 >> trainable params: 20,971,520 || all params: 8,051,232,768 || trainable%: 0.2605
[INFO|trainer.py:757] 2025-09-19 00:48:36,070 >> Using auto half precision backend
[INFO|trainer.py:2433] 2025-09-19 00:48:36,717 >> ***** Running training *****
[INFO|trainer.py:2434] 2025-09-19 00:48:36,717 >> Num examples = 191
[INFO|trainer.py:2435] 2025-09-19 00:48:36,717 >> Num Epochs = 3
[INFO|trainer.py:2436] 2025-09-19 00:48:36,717 >> Instantaneous batch size per device = 1
[INFO|trainer.py:2439] 2025-09-19 00:48:36,717 >> Total train batch size (w. parallel, distributed & accumulation) = 4
[INFO|trainer.py:2440] 2025-09-19 00:48:36,717 >> Gradient Accumulation steps = 4
[INFO|trainer.py:2441] 2025-09-19 00:48:36,717 >> Total optimization steps = 144
[INFO|trainer.py:2442] 2025-09-19 00:48:36,723 >> Number of trainable parameters = 20,971,520
1%|██ | 2/144 [00:22<27:14, 11.51s/it] 14%|████████████████████▏ | 20/144 [03:23<19:00, 9.20s/it] 26%|█████████████████████████████████████▎ | 37/144 [06:21<18:15, 10.24s/it]{'loss': 1.2108, 'grad_norm': 2.443699598312378, 'learning_rate': 8.381689971904514e-05, 'epoch': 1.04}
35%|██████████████████████████████████████████████████▎ | 50/144 [08:23<13:30, 8.62s/it][INFO|trainer.py:4074] 2025-09-19 00:57:00,201 >> Saving model checkpoint to saves/llama3-8b/lora/sft/checkpoint-50
[INFO|hub.py:420] 2025-09-19 00:57:00,298 >> Offline mode: forcing local_files_only=True
[INFO|configuration_utils.py:750] 2025-09-19 00:57:00,298 >> loading configuration file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:817] 2025-09-19 00:57:00,300 >> Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128009,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.55.2",
"use_cache": true,
"vocab_size": 128256
}
[INFO|tokenization_utils_base.py:2393] 2025-09-19 00:57:00,556 >> chat template saved in saves/llama3-8b/lora/sft/checkpoint-50/chat_template.jinja
[INFO|tokenization_utils_base.py:2562] 2025-09-19 00:57:00,559 >> tokenizer config file saved in saves/llama3-8b/lora/sft/checkpoint-50/tokenizer_config.json
[INFO|tokenization_utils_base.py:2571] 2025-09-19 00:57:00,560 >> Special tokens file saved in saves/llama3-8b/lora/sft/checkpoint-50/special_tokens_map.json
39%|████████████████████████████████████████████████████████▍ | 56/144 [09:25<14:58, 10.21s/it] 51%|█████████████████████████████████████████████████████████████████████████▌ | 73/144 [12:15<12:13, 10.33s/it]{'loss': 0.8393, 'grad_norm': 1.2337689399719238, 'learning_rate': 2.7137883834768073e-05, 'epoch': 2.08}
69%|████████████████████████████████████████████████████████████████████████████████████████████████████ | 100/144 [16:52<07:19, 10.00s/it][INFO|trainer.py:4074] 2025-09-19 01:05:29,404 >> Saving model checkpoint to saves/llama3-8b/lora/sft/checkpoint-100
[INFO|hub.py:420] 2025-09-19 01:05:29,491 >> Offline mode: forcing local_files_only=True
[INFO|configuration_utils.py:750] 2025-09-19 01:05:29,491 >> loading configuration file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:817] 2025-09-19 01:05:29,492 >> Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128009,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.55.2",
"use_cache": true,
"vocab_size": 128256
}
[INFO|tokenization_utils_base.py:2393] 2025-09-19 01:05:29,732 >> chat template saved in saves/llama3-8b/lora/sft/checkpoint-100/chat_template.jinja
[INFO|tokenization_utils_base.py:2562] 2025-09-19 01:05:29,736 >> tokenizer config file saved in saves/llama3-8b/lora/sft/checkpoint-100/tokenizer_config.json
[INFO|tokenization_utils_base.py:2571] 2025-09-19 01:05:29,736 >> Special tokens file saved in saves/llama3-8b/lora/sft/checkpoint-100/special_tokens_map.json
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 144/144 [24:18<00:00, 9.64s/it][INFO|trainer.py:4074] 2025-09-19 01:12:55,440 >> Saving model checkpoint to saves/llama3-8b/lora/sft/checkpoint-144
[INFO|hub.py:420] 2025-09-19 01:12:55,514 >> Offline mode: forcing local_files_only=True
[INFO|configuration_utils.py:750] 2025-09-19 01:12:55,515 >> loading configuration file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:817] 2025-09-19 01:12:55,516 >> Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128009,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.55.2",
"use_cache": true,
"vocab_size": 128256
}
[INFO|tokenization_utils_base.py:2393] 2025-09-19 01:12:55,693 >> chat template saved in saves/llama3-8b/lora/sft/checkpoint-144/chat_template.jinja
[INFO|tokenization_utils_base.py:2562] 2025-09-19 01:12:55,697 >> tokenizer config file saved in saves/llama3-8b/lora/sft/checkpoint-144/tokenizer_config.json
[INFO|tokenization_utils_base.py:2571] 2025-09-19 01:12:55,697 >> Special tokens file saved in saves/llama3-8b/lora/sft/checkpoint-144/special_tokens_map.json
[INFO|trainer.py:2718] 2025-09-19 01:12:56,236 >>
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 1459.5131, 'train_samples_per_second': 0.393, 'train_steps_per_second': 0.099, 'train_loss': 0.9318645795186361, 'epoch': 3.0}
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 144/144 [24:19<00:00, 10.14s/it]
[INFO|trainer.py:4074] 2025-09-19 01:12:56,239 >> Saving model checkpoint to saves/llama3-8b/lora/sft
[INFO|hub.py:420] 2025-09-19 01:12:56,316 >> Offline mode: forcing local_files_only=True
[INFO|configuration_utils.py:750] 2025-09-19 01:12:56,316 >> loading configuration file /mnt/workspace/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:817] 2025-09-19 01:12:56,317 >> Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128009,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.55.2",
"use_cache": true,
"vocab_size": 128256
}
[INFO|tokenization_utils_base.py:2393] 2025-09-19 01:12:56,477 >> chat template saved in saves/llama3-8b/lora/sft/chat_template.jinja
[INFO|tokenization_utils_base.py:2562] 2025-09-19 01:12:56,481 >> tokenizer config file saved in saves/llama3-8b/lora/sft/tokenizer_config.json
[INFO|tokenization_utils_base.py:2571] 2025-09-19 01:12:56,481 >> Special tokens file saved in saves/llama3-8b/lora/sft/special_tokens_map.json
***** train metrics *****
epoch = 3.0
total_flos = 2901741GF
train_loss = 0.9319
train_runtime = 0:24:19.51
train_samples_per_second = 0.393
train_steps_per_second = 0.099
Figure saved at: saves/llama3-8b/lora/sft/training_loss.png
[WARNING|2025-09-19 01:12:56] llamafactory.extras.ploting:148 >> No metric eval_loss to plot.
[WARNING|2025-09-19 01:12:56] llamafactory.extras.ploting:148 >> No metric eval_accuracy to plot.
[INFO|modelcard.py:456] 2025-09-19 01:12:56,895 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}}
root@eais-bjyqq232zv0ne6saxp0j-0:/mnt/workspace/LLaMA-Factory# 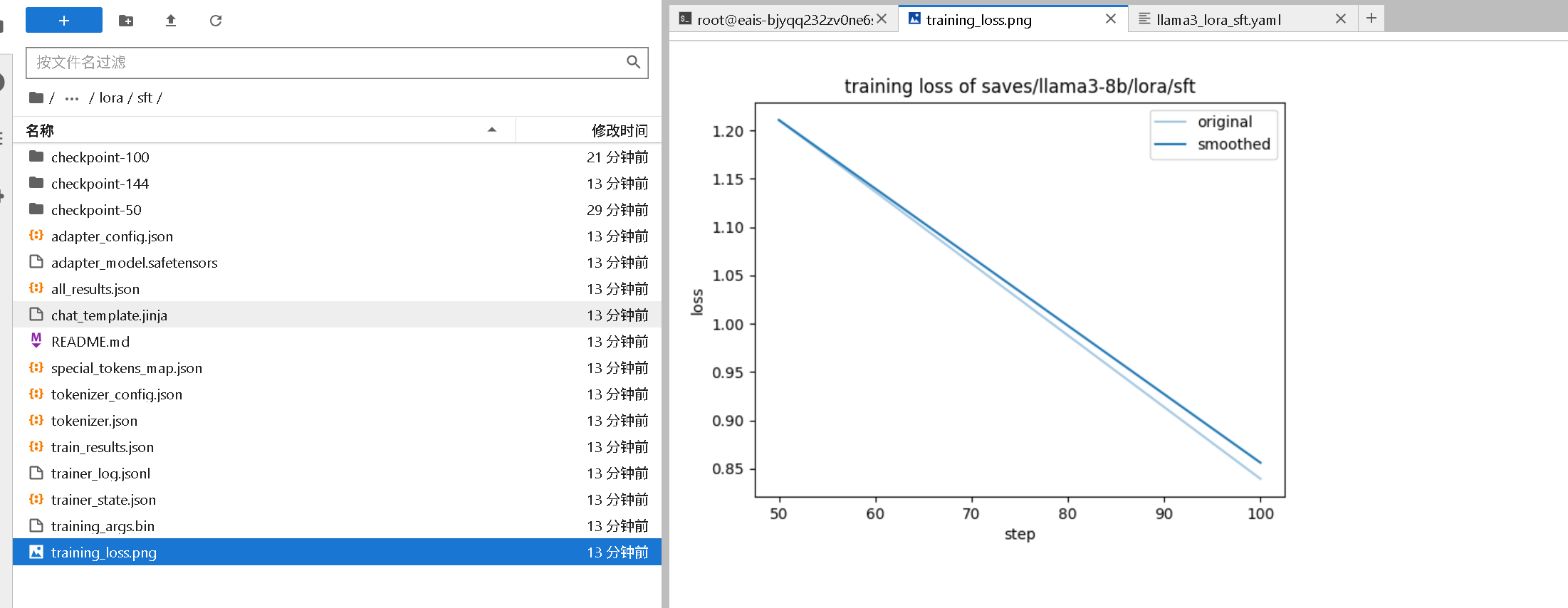
max_samples: 100 所以上图是直线
该目录下的核心文件/文件夹功能如下:
| 文件/文件夹 | 作用 |
|---|---|
checkpoint-50/100/144 |
训练过程中的中间模型 checkpoint(分别对应第50/100/144步),可用于断点续训 |
pytorch_model.bin |
最终训练完成的 LoRA 适配器权重(仅包含微调的 LoRA 参数,体积小,需配合原模型使用) |
tokenizer_*.json/model |
训练中使用的 Tokenizer 文件(推理时需与模型配套) |
training_loss.png |
训练损失变化图(可查看损失是否正常收敛) |
config.json |
模型和训练的配置汇总(记录微调参数,便于复现) |
如何运行/使用训练结果(推理/对话)
训练完成后,你需要通过 LLaMA Factory 的推理命令 加载训练好的 LoRA 模型,进行对话交互或文本生成。核心是通过 llamafactory-cli 的 chat(对话)或 generate(文本生成)命令,指定训练好的 LoRA 模型路径和原基础模型路径。
1. 推荐:用 chat命令进行交互式对话(最直观)
执行以下命令,启动与微调后模型的对话交互(需匹配训练时的配置,如 4bit 量化、LoRA 路径):
bash
# 交互式对话命令(关键参数需与训练一致)
TRANSFORMERS_OFFLINE=1 HF_HUB_OFFLINE=1 llamafactory-cli chat \
--model_name_or_path /mnt/workspace/models/Meta-Llama-3-8B-Instruct \ # 原基础模型路径(必须与训练一致)
--adapter_name_or_path /mnt/workspace/LLaMA-Factory/saves/llama3-8b/lora/sft \ # 训练好的 LoRA 适配器路径
--quantization_bit 4 \ # 与训练一致的 4bit 量化(避免显存不足)
--template llama3 # 与训练一致的模板(确保对话格式兼容)
bash
TRANSFORMERS_OFFLINE=1 HF_HUB_OFFLINE=1 llamafactory-cli chat \
--model_name_or_path /mnt/workspace/models/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path /mnt/workspace/LLaMA-Factory/saves/llama3-8b/lora/sft \
--quantization_method bnb \
--quantization_bit 4 \
--template llama3 \
--trust_remote_code true
exit 退出
2. 用 generate 命令进行文本生成(批量/单条生成)
若需要批量生成文本(而非交互式对话),可使用 generate 命令,示例:
bash
# 文本生成命令(生成指定输入的续写结果)
TRANSFORMERS_OFFLINE=1 HF_HUB_OFFLINE=1 llamafactory-cli generate \
--model_name_or_path /mnt/workspace/models/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path /mnt/workspace/LLaMA-Factory/saves/llama3-8b/lora/sft \
--quantization_bit 4 \
--template llama3 \
--input_text "请解释什么是 LoRA 微调" # 你要生成结果的输入文本命令会直接输出模型生成的文本结果(无需交互)。
关键注意事项(确保推理正常)
-
路径必须匹配 :
--model_name_or_path必须是训练时用的原基础模型(/mnt/workspace/models/Meta-Llama-3-8B-Instruct),--adapter_name_or_path必须是训练输出的 LoRA 路径(saves/llama3-8b/lora/sft),二者缺一不可(LoRA 仅保存微调的增量参数,需依赖原模型)。 -
量化参数一致 :
推理时必须加
--quantization_bit 4(与训练时的 4bit 量化一致),否则会因模型精度不匹配导致报错或显存溢出。 -
模板一致 :
--template llama3需与训练时的template: llama3一致,确保对话格式(如<|begin_of_text|>、<|user|>标签)兼容,避免模型输出格式混乱。