点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月22日更新到: Java-130 深入浅出 MySQL MyCat 深入解析 核心配置文件 server.xml 使用与优化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节完成了如下的内容:
- Offsets 管理
- 与Kakfa集成
- Redis管理Offsets
- 从Redis获取Offsets 并更新到Redis

基本介绍
Spark GraphX 是一个基于 Apache Spark 的分布式图计算框架,专门用于处理图数据和执行图算法。它为用户提供了一种灵活而高效的方式来表达图计算,并支持复杂的图分析任务。GraphX 主要用于社交网络分析、推荐系统、网络流量分析等领域。
顶点 (Vertices) 和边 (Edges)
图是由一组顶点(节点)和边(连接)构成的。顶点表示图中的实体(例如人、设备等),边表示实体之间的关系(例如朋友关系、通信路径等)。 在 GraphX 中,顶点和边的属性可以是任意类型的数据结构,这使得它可以适应多种应用场景。
图 (Graph)
GraphX 中的图是由一组顶点和边构成的,并且可以具有属性。这些属性可以是图结构相关的数据,比如顶点的标签和边的权重。 GraphX 提供了丰富的图操作和变换方法,如子图提取、边反转、顶点属性更新等。
图操作
GraphX 提供了多种图操作,包括基于属性的图转换、子图提取、图的聚合操作等。 例如,可以通过 mapVertices 和 mapEdges 操作对顶点和边进行变换,还可以通过 subgraph 提取满足特定条件的子图。
Pregel API
GraphX 提供了 Pregel API,这是一种灵活的图计算模型,允许用户通过迭代计算的方式来处理图数据。 Pregel 模型允许用户为每个顶点定义一个消息处理函数,在每次迭代时更新顶点的属性,直到满足某个条件。
图算法库
GraphX 包含了一些常用的图算法库,例如 PageRank、Connected Components(连通分量)、Triangle Counting(三角计数)等。 这些算法可以直接用于图数据分析,帮助用户快速获取图的特征和模式。
与 Spark RDD 的集成
GraphX 的一个重要特性是与 Spark RDD 的无缝集成。用户可以将图的顶点和边表示为 RDD,然后使用 RDD 操作来处理图数据。 这种集成使得 GraphX 可以利用 Spark 的分布式计算能力,同时支持图数据的复杂分析。
性能优化
GraphX 通过数据切片、消息压缩、图的分区等技术来优化分布式图计算的性能。 这些优化使得 GraphX 能够处理大规模图数据,保持高效的计算性能。
Spark GraphX 概述
- GraphX 是 Spark 一个组件,专门用来表示图以及进行图的并行计算。GraphX通过重新定义了图的抽象概念来拓展了RDD:定向多图,其属性附加到每个顶点和边。
- 为了支持图计算,GraphX公开了一系列基本运算(比如:mapVertices、mapEdges、subgraph)以及优化后的 Pregel API 变种。此外,还包含越来越多的图算法和构建器,以简化图形分析任务。
- GraphX在图顶点信息和边信息存储上做了优化,使得图计算框架性能相对于云原生RDD实现得以较大提升,接近或达到 GraphLab 等专业计算平台的性能。
- GraphX 最大的贡献是,在 Spark 之上提供了一栈式数据解决方案,可以方便且高效的完成图计算的一整套流水作业。
图的相关术语
图是一种较线性和树更为复杂的数据结构,图表达的是多对多的关系。 如下图所示,G1是一个简单的图,其中V1、V2、V3、V4被称为顶点(Vertex),任意两个顶点之间的通路被称为边(Edge),它可以由(V1、V2)有序对来表示,此时称G1为有向图,意味着边是有方向的,若以无序对来表示图中一条边,则该图为无向图,如G2。
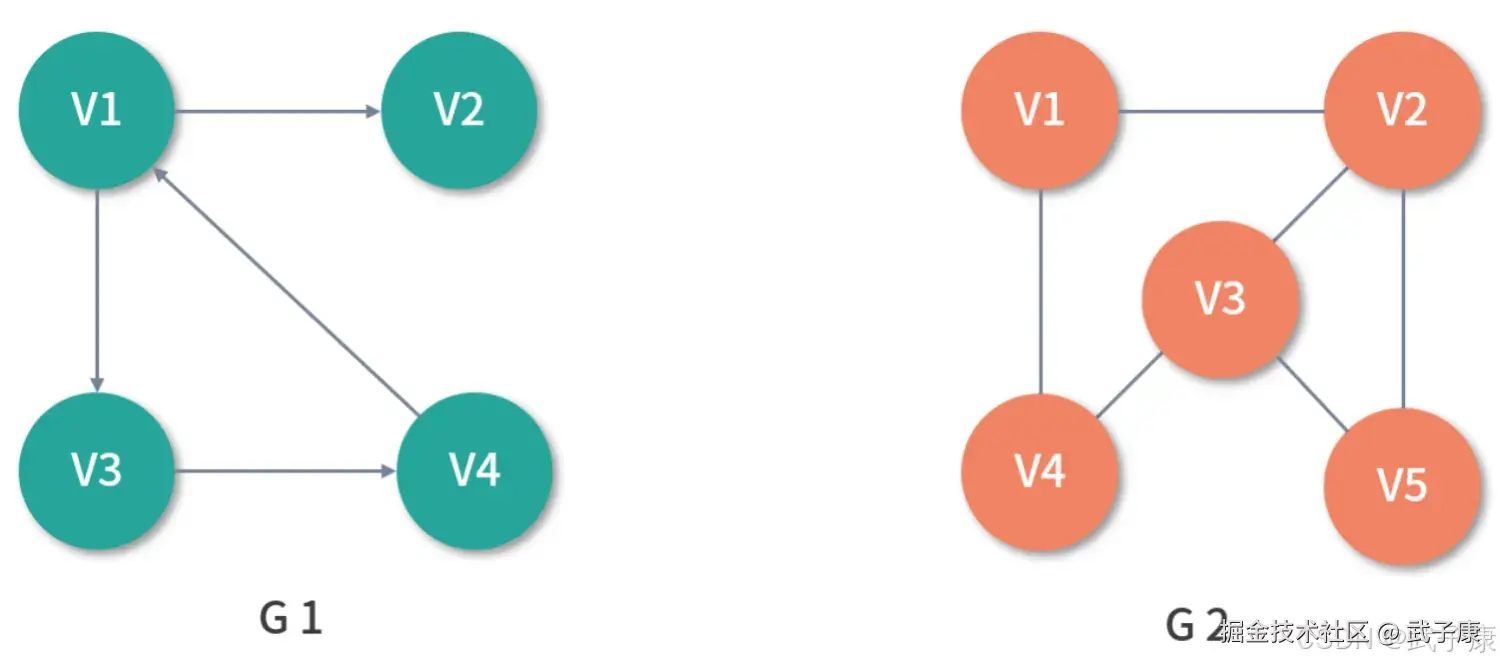 在 G1 中,与顶点相关联的边的数量被称为顶点的度(Degree),其中,以顶点为起点的边的数量被称为顶点的出度(OutDegree),以顶点为终点的边的数量被称为顶点的入度(InDegree)。 以 G1 中的 V1 举例,V1的度是3,其中出度为2,入度为1。 在无向图 G2 中,如果任意两个顶点之间是连通的,则称 G2 为连通图(Connected Graph)。 在有向图中G1中,如果任意两个顶点 Vm、Vn 且 m不等于n,从Vm到Vn以及从Vn到Vm之间都存在通路,则称G1为强连通图(Strongly Connected Graph)。任意两个顶点之间存在通路,则称为路径(Path),用一个顶点序列表示,若第一个顶点和最后一个顶点相同,则称为回路或者环(Cycle)。
在 G1 中,与顶点相关联的边的数量被称为顶点的度(Degree),其中,以顶点为起点的边的数量被称为顶点的出度(OutDegree),以顶点为终点的边的数量被称为顶点的入度(InDegree)。 以 G1 中的 V1 举例,V1的度是3,其中出度为2,入度为1。 在无向图 G2 中,如果任意两个顶点之间是连通的,则称 G2 为连通图(Connected Graph)。 在有向图中G1中,如果任意两个顶点 Vm、Vn 且 m不等于n,从Vm到Vn以及从Vn到Vm之间都存在通路,则称G1为强连通图(Strongly Connected Graph)。任意两个顶点之间存在通路,则称为路径(Path),用一个顶点序列表示,若第一个顶点和最后一个顶点相同,则称为回路或者环(Cycle)。
图数据库与图计算
- Neo4j 是一个老牌的开源图数据库,目前在业界的使用也较为广泛,它提供了一种简单易学的查询语言:Cypher。
- Neo4j 支持交互式查询,查询效率很高,能够迅速从整网中找出符合特定模式的子网,供随后分析用,适用于 OLTP 场景。
- Neo4j是图数据库,偏向于存储和查询,能存储关联关系比较复杂,实体之间的连接丰富。比如:社交网络、知识图谱、金融风控等领域的数据。
- 擅长从某个点或者某些点出发,根据特定条件在复杂的关系中找到目标点或者边。如在社交网络中找到某个点三步以内能认识的人,这些人可以认为是潜在朋友。
- 数据量限定在一定范围内,能短时间完成的查询就是所谓的OLTP操作。
- Neo4j查询与插入速度较快,没有分布式版本,容量有限,而且一旦图变得很大,如数十亿顶点,数百亿边,查询速度会变得非常缓慢。
- Neo4j分为社区和企业版,企业版提供了一些高级的功能,但是价格昂贵。
 比较复杂的分析和算法,如基于图的聚类,PageRank算法等,这类计算任务对于图数据库来说很难胜任了,主要由一些图挖掘技术来负责。
比较复杂的分析和算法,如基于图的聚类,PageRank算法等,这类计算任务对于图数据库来说很难胜任了,主要由一些图挖掘技术来负责。
Pregel 是 Google 与 2010年在 SIGMOD会议上发表的《Pregel:A System for Large-Scale Graph Processing》论文中提到海量并行图挖掘的抽象框架,Pregel与Dremel一样,是Google新三驾马车之一,它基于BSP模型(Bulk Synchronous Paralles,整体同步并行计算模型),将计算分为若干个超步(Super Step),在超步内,通过消息来传播顶点之间的状态。 Pergel 可以看成是同步计算,即等所有顶点完成处理后再进行下一轮的超步,Spark基于Pregel论文实现的海量并行图挖掘框架GraphX。
图计算模式
目前基于图的并行计算框架已经有很多,比如来自Google的Pergel、来自Apache开源的图计算框架Giraph/HAMA以及最著名的GraphLab,其中 Pregel、HAMA和Giraph都是非常类似的,都是基于BSP模式。 BSP即整体同步并行,它将计算分成一系列超步的迭代,从纵向上看,它是一个串行模式,而从横向上看,它是一个并行模式,每两个超步之间设置一个栅栏(barrier),即整体同步点,确定所有并行的计算都完成后再启动下一轮超步。
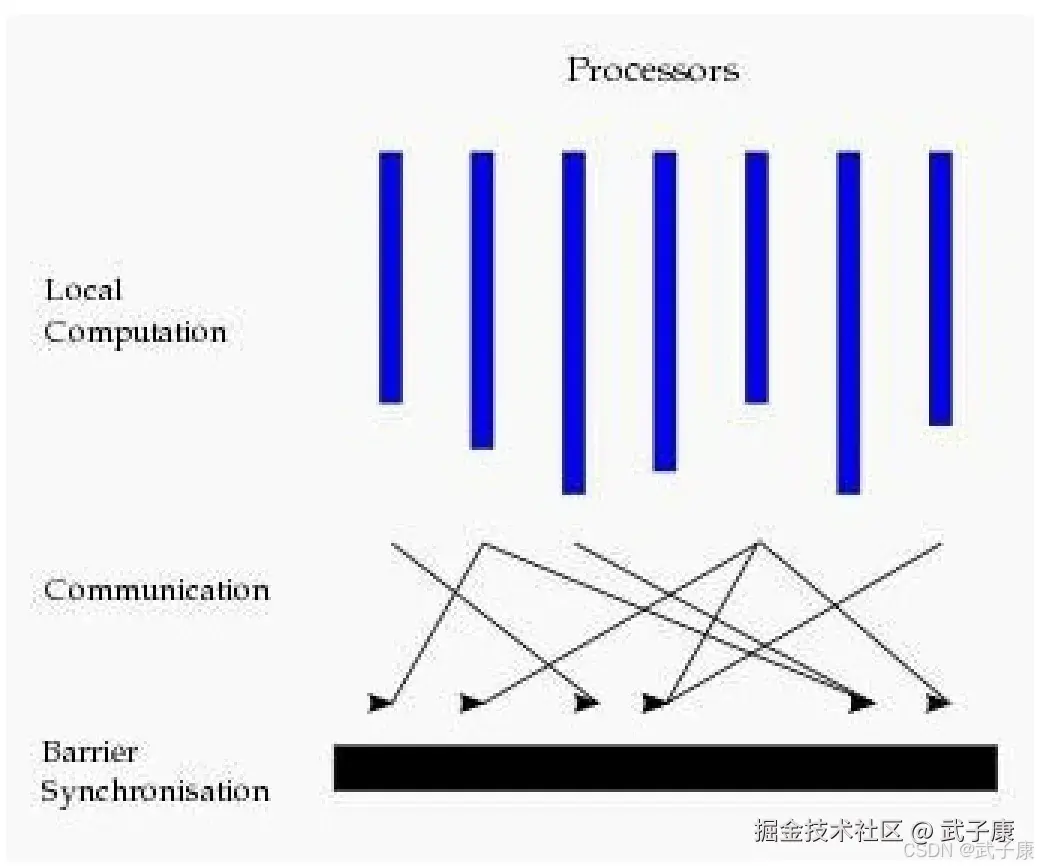 每一个超步包含三部分内容:
每一个超步包含三部分内容:
- 计算Compute:每一个 processor 利用上一个超步传过来的消息和本地数据进行本地计算
- 消息传递:每一个processor 计算完毕后,将消息传递给与之关联的其他processor
- 整体同步点:用于整体同步,确定所有的计算和消息传递都没有进行完毕后,进入下一个超步
GraphX 基础
GraphX与Spark其他组件相比比较独立,拥有自己的核心数据结构和算子。
GraphX架构
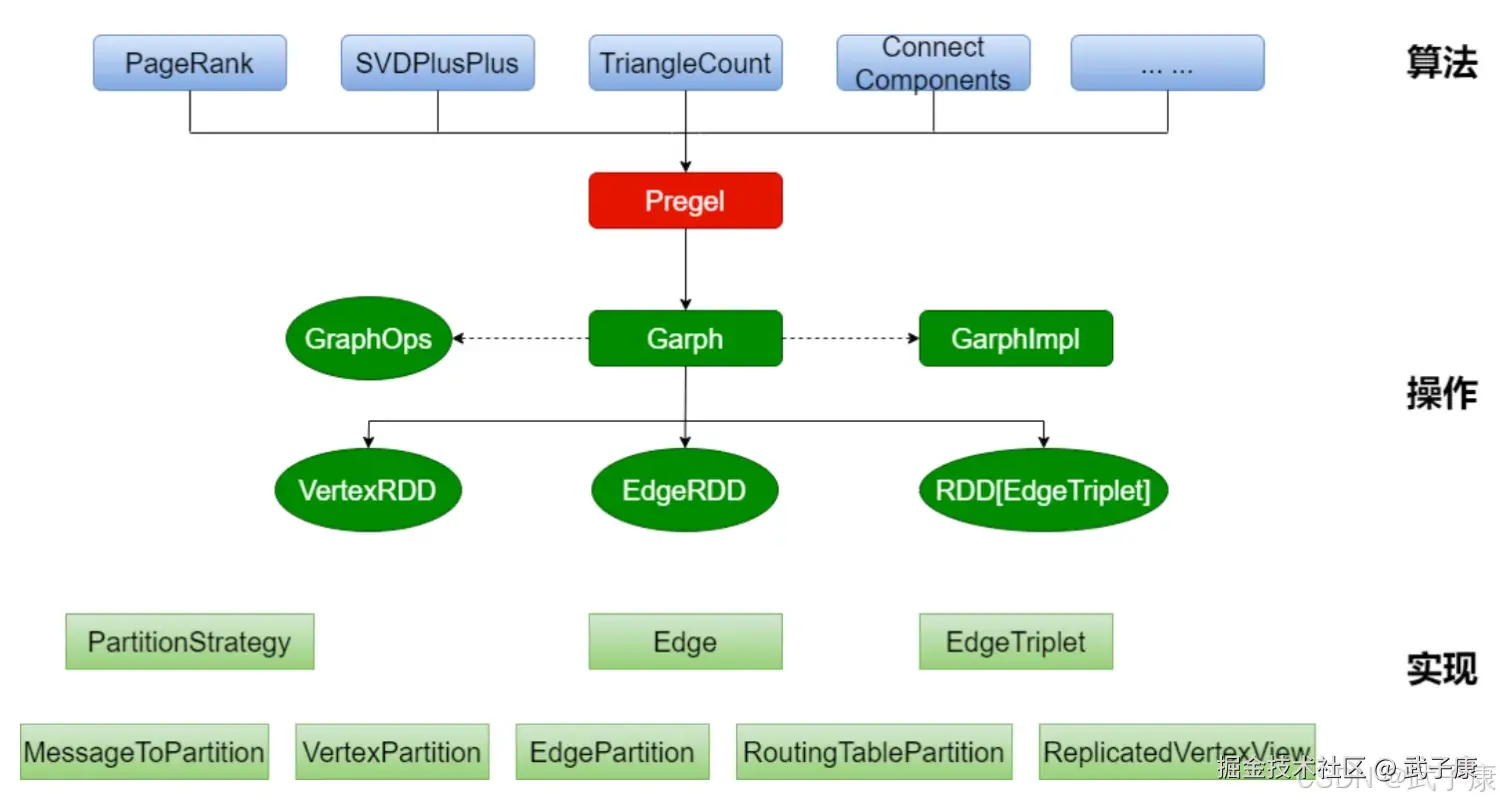
GraphX的整体架构可以分为三个部分:
- 算法层:基于 Pregel 接口实现了常用的图算法,包括PageRank、SVDPlusPlus、TriangleCount、ConnectedComponents、StronglyConnectedComponents 等算法
- 接口层:在底层RDD基础上实现了Pergel模型 BSP模式的计算接口
- 底层:图计算的核心类,包含:VertexRDD、EdgeRDD、RDDEdgeTriplet
存储模式
巨型图的存储总体上有边分割和点分割两种存储方式,2013年,GraphLab2.0将其存储方式由边分割变为点分割,在性能上取得重大提升,目前基本上被业界广泛接受并使用。
- 边分割(Edge-Cut ):每个顶点都存储一次,但有的边会被打断分到两台机器上,这样做的好处是节省存储空间,坏处是对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,要跨机器通信传输数据,内网流量大
- 点分割(Vertex-Cut):每条边只存储一次,都只会出现在一台机器上,邻居多的点会被复制到多台机器上,增加存储开销,同时会引发数据同步的问题,好处是可以大幅减少内网通信量
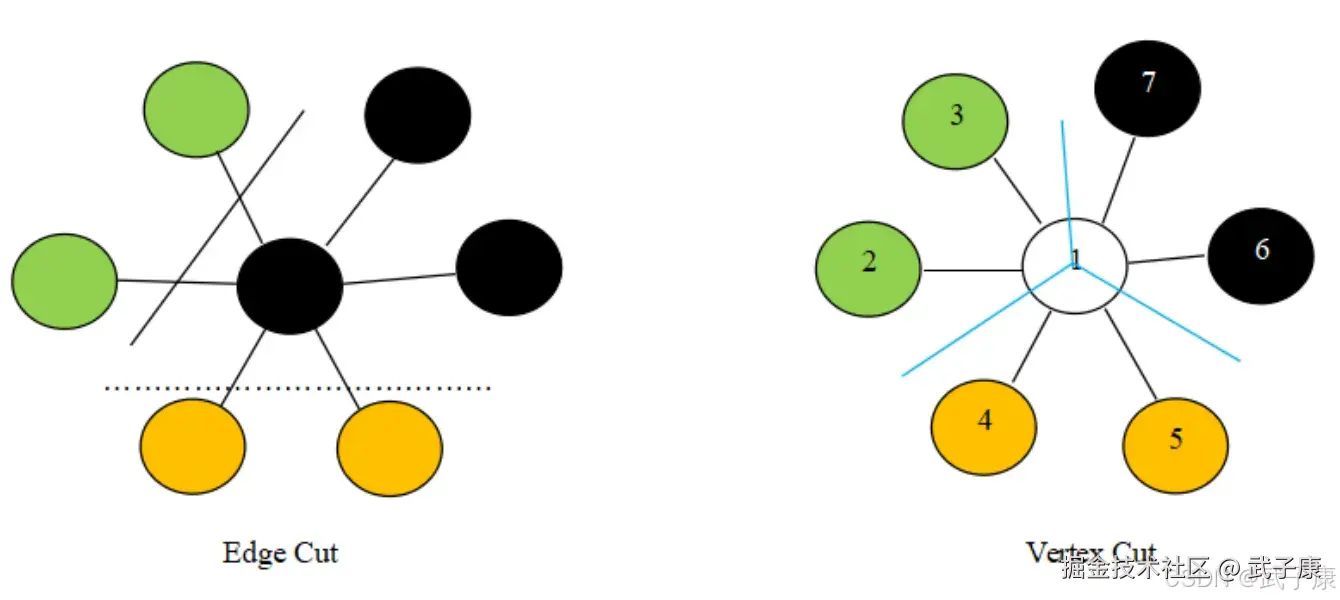
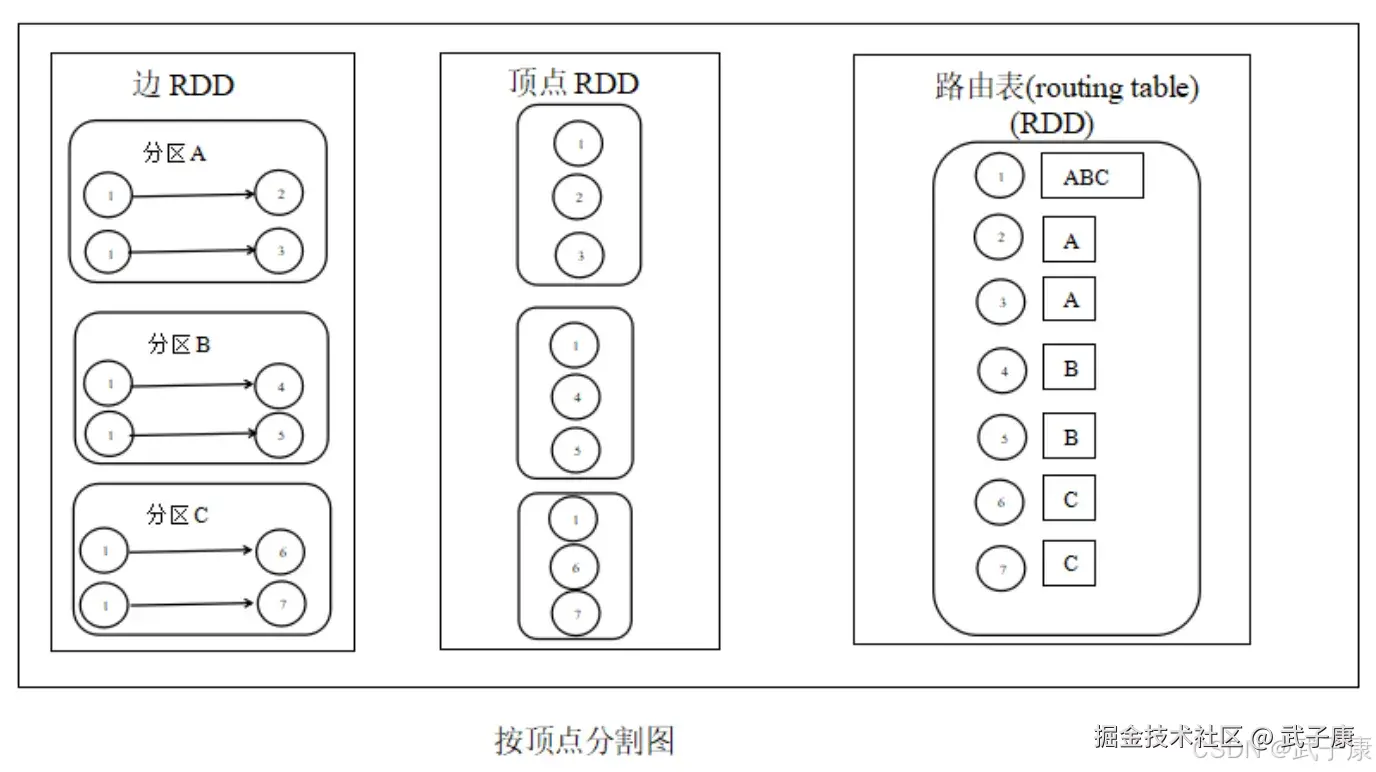 虽然两种方法互有利弊,但现在是点分割占上风,各种分布式图计算框架都将自己底层存储变成了点分割,主要原因有以下两个:
虽然两种方法互有利弊,但现在是点分割占上风,各种分布式图计算框架都将自己底层存储变成了点分割,主要原因有以下两个:
- 磁盘价格下降,存储空间不再是问题,而内网的通信资源并没有突破性进展,集群计算时内网带宽是宝贵的,时间比磁盘珍贵。用空间来换时间。
- 在当前的应用场景下,绝大多数网络都是无尺度网络,遵循幂律分布,不同点的邻居数量相差非常悬殊,而边分割会使那些多邻居的点所相连的边大多数被分到不同的机器上,这样的数据分布会使得内网带宽更加的捉襟见肘,于是边分割存储的方式就被逐渐抛弃了。
核心数据结构
核心数据结构包括:
- Graph
- Vertices
- Edges
- Triplets
GraphX API的开发语言目前仅支持Scala,GraphX的核心数据结构Graph由RDD封装而成。
Graph
GraphX 用属性图的方式表示图,顶点有属性,边有属性。存储结构采用边集数组的形式,即一个顶点表,一个边表,如下图所示: 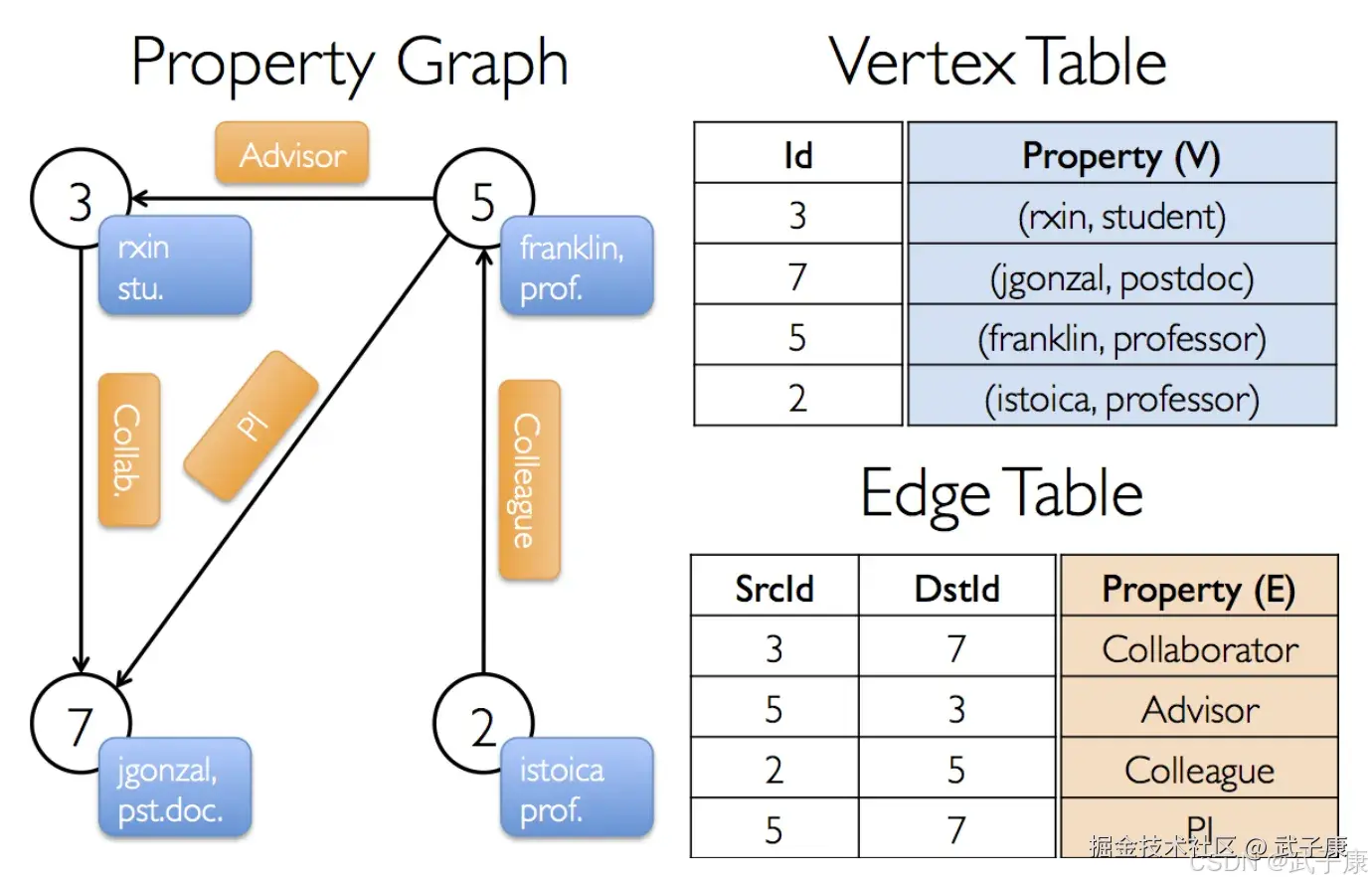 顶点ID是非常重要的手段,它不光是顶点的唯一标识符,也是描述边的唯一手段。 顶点表与边表实际上就是RDD,它们分别为 VertexRDD 与 EdgeRDD。 Graph 类如下:
顶点ID是非常重要的手段,它不光是顶点的唯一标识符,也是描述边的唯一手段。 顶点表与边表实际上就是RDD,它们分别为 VertexRDD 与 EdgeRDD。 Graph 类如下: 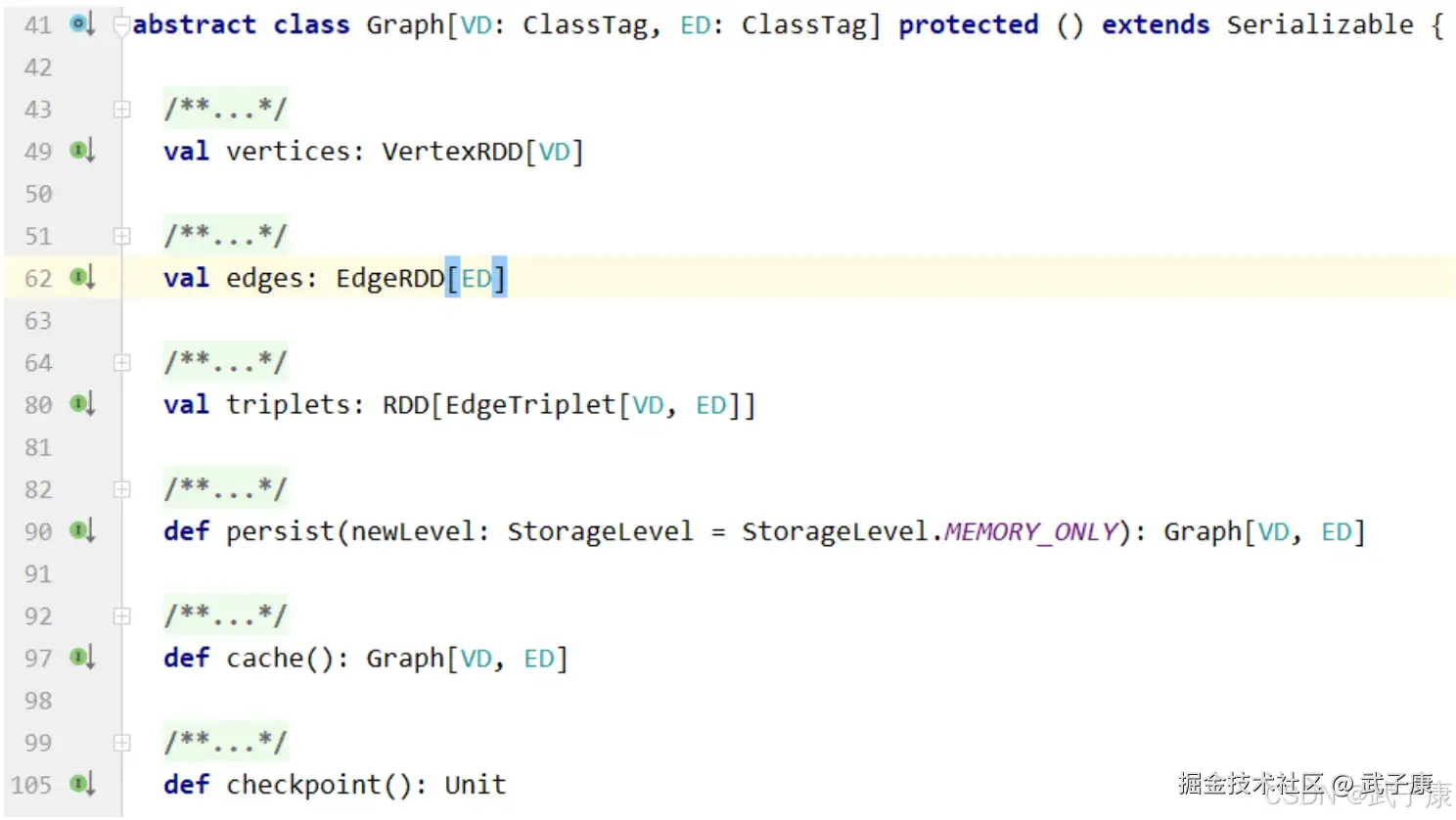
- Vertices 为顶点表,VD为顶点属性类型
- Edges 为边表,ED为边属性类型
- 可以通过Graph的Vertices与Edges成员直接得到顶点RDD与边RDD
- 边RDD类型为EdgeRDD,继承自RDDEdge\[ED]
Vertices
Vertices对应着名为 VertexRDD 的 RDD,这个RDD由顶点ID和顶点属性两个成员变量。  VertexRDD继承自RDD(VertexID,VD),这里VertexId表示顶点ID,VD表示顶点所带的属性的类别。 而 VertexId 实际上是一个 Long 类型的数据
VertexRDD继承自RDD(VertexID,VD),这里VertexId表示顶点ID,VD表示顶点所带的属性的类别。 而 VertexId 实际上是一个 Long 类型的数据 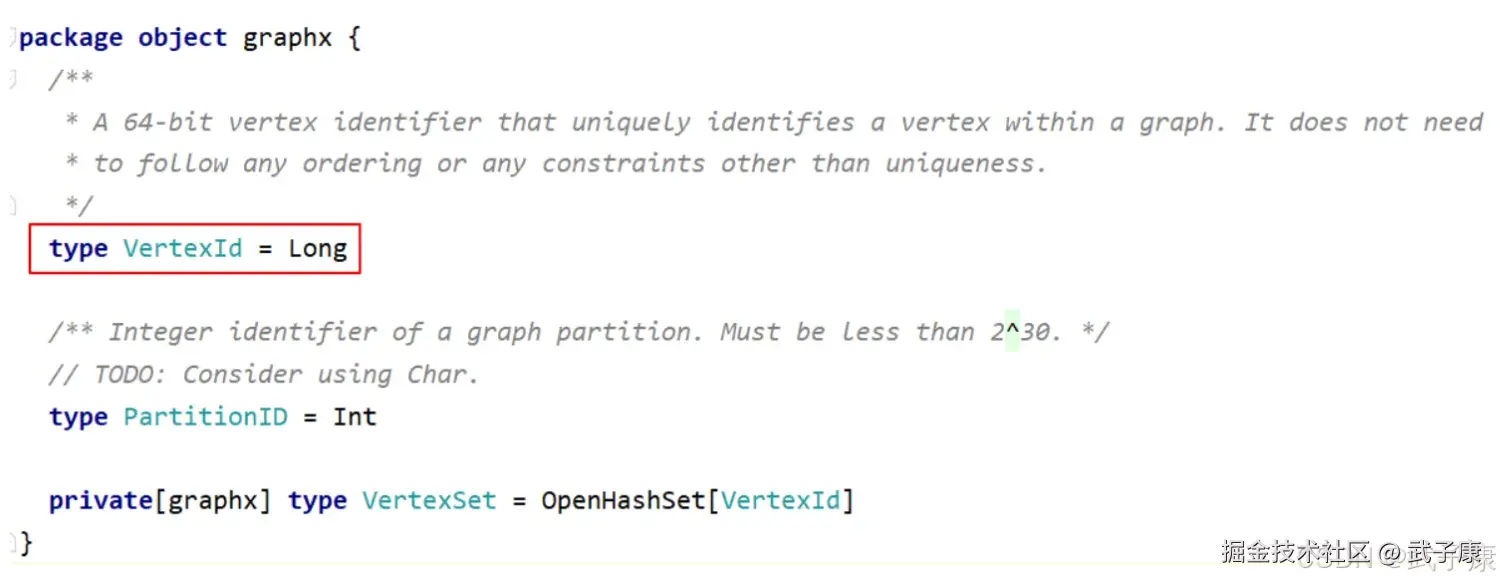
Edges
Edges对应着EdgeRDD,这个RDD拥有三个成员变量,分别是源顶点Id、目标顶点Id,以及边属性。  Edge代表边,由源顶点ID、目标顶点ID,以及边的属性构成。
Edge代表边,由源顶点ID、目标顶点ID,以及边的属性构成。 
Triplets
Triplets表示边点三元组,如下图所示(其中圆柱形分别代表顶点属性与边属性)  通过Triplets成员,用户可以直接获取到起点顶点,起点顶点属性、终点顶点、终点顶点属性、边与边属性信息。Triplets的生成可以有边表与顶点表通过Scrld与Dstld连接而成。 Triplets对应着EdgeTriplet,它是一个三元组视图,这个视图逻辑上将顶点和边的属性保存为一个RDDEdgeTriples\[VD,ED]
通过Triplets成员,用户可以直接获取到起点顶点,起点顶点属性、终点顶点、终点顶点属性、边与边属性信息。Triplets的生成可以有边表与顶点表通过Scrld与Dstld连接而成。 Triplets对应着EdgeTriplet,它是一个三元组视图,这个视图逻辑上将顶点和边的属性保存为一个RDDEdgeTriples\[VD,ED] 
shell
import org.apache.spark.graphx._
import org.apache.spark.rdd.RDD
// 创建顶点和边
val vertices: RDD[(VertexId, String)] = sc.parallelize(Array(
(1L, "Alice"),
(2L, "Bob"),
(3L, "Charlie"),
(4L, "David")
))
val edges: RDD[Edge[Int]] = sc.parallelize(Array(
Edge(1L, 2L, 1),
Edge(2L, 3L, 1),
Edge(3L, 4L, 1),
Edge(4L, 1L, 1)
))
// 构建图
val graph = Graph(vertices, edges)
// 运行 PageRank 算法
val ranks = graph.pageRank(0.01).vertices
// 输出结果
ranks.collect().foreach { case (id, rank) =>
println(s"Vertex $id has rank: $rank")
}