本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。

RAG,是一种把"检索"与"生成"无缝拼在一起的技术框架。它既不指望大模型记住所有知识,也不满足于传统检索只给出一堆文档,而是让两者取长补短: 检索器(Retriever)负责"查资料",生成器(Generator)负责"写答案" 。
RAG,本质上是一种结合搜索技术和大型语言模型(LLMs)的技术。它通过从数据源中检索信息来辅助LLM生成答案。具体来说,RAG利用搜索算法找到的信息作为背景上下文,将这些查询和检索到的上下文信息整合进发送给LLM的提示中。这样,大模型在回答提出的问题时,可以在搜索到的信息的基础上进行生成,从而提供更准确和全面的答案。
RAG基本原理
- 检索: 根据用户的查询内容,从外部知识库获取相关信息。具体而言,将用户的查询通过嵌入模型转换为向量,以便与向量数据库中存储的相关知识进行比对。通过相似性搜索,找出与查询最匹配的前K个数据。
- 增强: 将用户的查询内容和检索到的相关知识一起嵌入到一个预设的提示词模板中,作为语言大模型的上下文输入。
- 生成: 大语言模型根据增强后的输入生成回答,结合外部知识内容,提升输出的专业性和准确性。
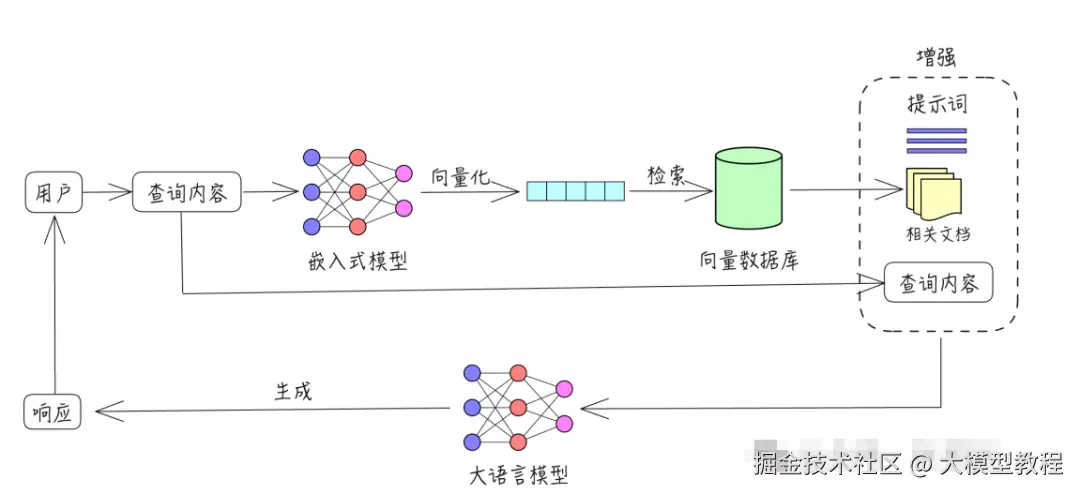
RAG的基本工作原理
定义知识库
知识库通常指的是经过组织、系统化存储的知识集合,能够被方便地检索、查询和更新。它不仅仅是数据的简单堆积,而是有结构、有分类,可能还包含元数据、索引等,方便用户高效获取信息。
医疗知识库痛点分析
A-数据源头:活数据难采、古籍海量但沉睡。
1.四诊信息主观性强。
脉象"弦细"、舌苔"薄白"缺乏统一量化口径,导致临床数据无法直接入表。
2.医案非结构化比例高 历代医案以文言、半文言书写,实体关系稀疏,NER+F1 值普遍 < 0.7。
3 高质量数据私有化 名老中医经验沉淀在个人笔记、手抄本或私有 HIS 中,医院层面难以合规汇聚。
B-数据标准:缺顶层、缺映射、缺维护 1 .缺国家层面中医 EMR 模板(标准化电子病历模板) 西医有 ICD-10/ICD-9-CM,中医仍靠各医院自定义 1000+ 症状术语。 2 .中西医术语映射断裂 "肝阳上亢"与"高血压"无法一一对应,导致联合科研与医保结算受阻。 3.动态维护机制空白 指南、药典、专家共识年更新率 >15%,但知识库版本迭代滞后 2--3 年。
C-技术落地:模型难训、算力难筹、接口难接
- 小样本、高维度 某三甲医院 5 年仅累积 2 万条带标注的四诊-辨证-处方三元组,远低于 NLP 训练所需规模。 2.算法解释性不足 黑箱模型给出"柴胡疏肝散+丹参"推荐,却无法用君臣佐使理论说服医生。
- 院内系统烟囱林立 HIS、LIS、PACS、EMR 由不同厂商承建,缺少标准 API,知识库难以实时写回。
系统功能模块设计

基于RAG与垂直领域大模型的AI检索知识库的构建
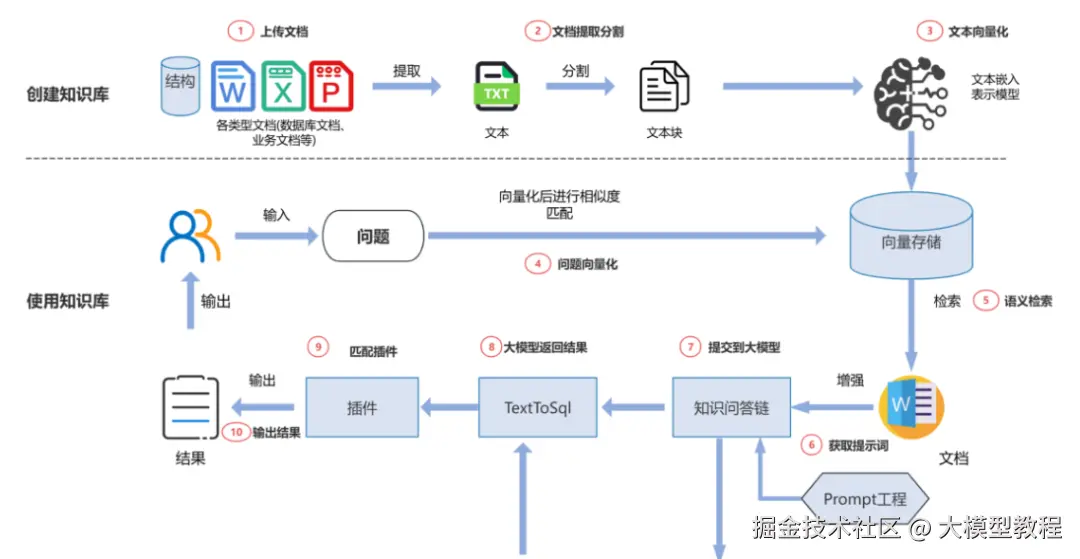
1.语料库与知识库构建阶段
构建用于检索的语料库的过程,包括"文档数据提取与处理------文本分块---文本向量化---创建索引---导入向量数据库"几步。这一阶段的关键是如何通过各类技术,构建有效的知识语料库,以提供给模型用于生成文本的信息。
在RAG的流程中,知识库扮演着关键角色。为了让模型能"现查现答",我们需要先把领域知识转化为便于检索的向量形式。整个过程大致包括四个步骤,如图所示:
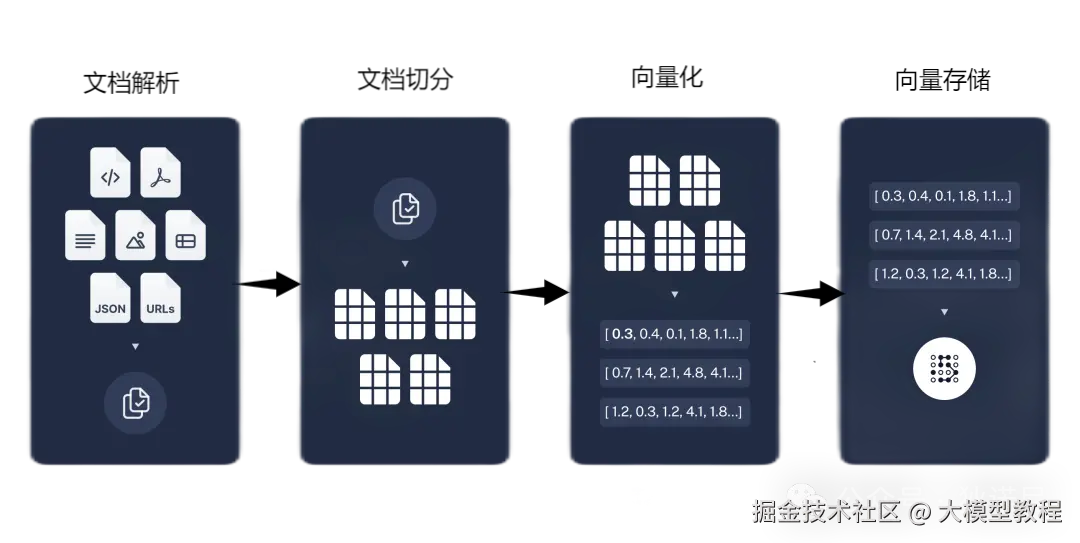
文档解析: 将用户上传的知识文档(如 PDF、Word、网页等)解析成纯文本。也就是把结构化或非结构化的数据转化为可处理的文字内容。
文档切分:* *在 RAG 系统中,大模型并不是直接读取整篇文档,而是将文档切分成一段段"小块"(chunks)来处理。**由于向量模型的输入长度有限,我们需要把长文档拆成适当大小的片段(比如按段落或句子切分),确保每段内容都能被向量模型正常处理。
向量化: 使用嵌入模型(如 OpenAI Embedding、BGE、text2vec 等)将每个文本片段转换成向量。这个向量可以看作是该片段的"语义表示",后续检索就靠它来找"语义上相似"的内容。
向量存储: 将所有向量以及对应的原始文本、文件名等元数据,存入向量数据库中。常见的向量库包括 Milvus、FAISS、Elasticsearch 等。(向量数据库存储元数据)
完成以上步骤后,当用户提问时:系统会将问题同样进行向量化;在向量库中找出与问题最相关的几个文本片段;再把这些内容和用户提问拼接成一个 Prompt,交给大语言模型生成答案。
2.问题理解和检索阶段
RAG接收用户输入的问题或请求。然后,利用检索模块对问题进行分析和理解,将其转化为适合检索的形式(文本嵌入,形成问题文本的嵌入向量)。接着,从预定义的知识库、文档集合或向量数据库中,通过相似度匹配、关键词搜索等技术,找到与问题最相关的文本片段。这些文本片段可以是短语、句子、段落甚至是整个文档,它们包含了回答问题所需的关键信息。
具体而言:将文本分割成块,然后使用一些 Transformer Encoder 模型将这些块嵌入到向量中,将所有这些向量放入索引中,最后创建一个 LLM 提示,告诉模型回答给定我们在搜索步骤中找到的上下文的用户查询。
在运行时,我们使用同一编码器模型对用户的查询进行向量化,然后搜索该查询向量的索引,找到 top-k 个结果,从我们的数据库中检索相应的文本块,并将它们作为上下文输入到 LLM 提示中。
3.生成阶段
在获取相关文本片段后,RAG 模型将这些片段与原始问题结合,作为上下文信息输入到生成模型(如GPT、百度千帆、文心一言、通义千问等大语言模型)中。大语言模型基于输入的问题和上下文信息,利用其强大的语言生成能力,生成最终的答案或文本输出。
4.输出优化阶段
为确保生成的答案准确、相关且符合逻辑,RAG 模型通常会在生成阶段加入后处理步骤。例如,对生成的答案进行置信度评估,判断答案的可靠性;进行多候选答案筛选,从多个生成的答案中选择最优的结果;对答案进行语法和语义检查,修正可能存在的错误。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。