【mysql】内部技术架构
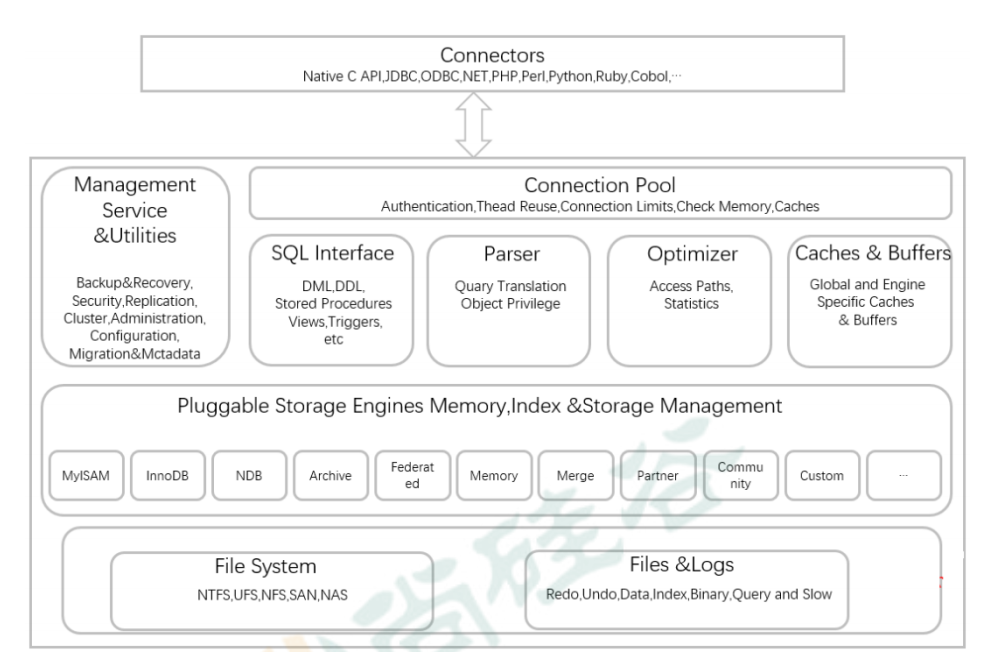
宏观架构:经典的 C/S 模型与分层设计
MySQL 遵循客户端/服务器模型,其核心架构可以分为三层,如下图所示(我们可以先进行文字描述,你可以在脑中构建这个图像):
连接层
服务层(SQL Layer)
存储引擎层(Storage Engine Layer)
1.连接层
这是客户端与 MySQL 交互的入口。
- 功能:
- 身份认证:当客户端(如 Java 应用、MySQL 命令行工具)发起连接请求时,连接层负责验证用户名、密码和主机权限。
- 连接管理:管理连接线程。MySQL 会为每个连接分配一个线程,使用线程池来管理这些连接,避免频繁创建和销毁线程带来的开销。
- 相关命令/参数:mysql -h -u -p, show processlist, max_connections, thread_cache_size
2.服务层(SQL Layer)
-
1.连接池(Connection Pool)
管理和复用数据库连接,以解决频繁创建和销毁连接所带来的巨大性能开销,在服务启动时或首次请求时,预先创建一定数量的数据库连接并保存在池中。当应用程序需要连接时,它直接从池中获取一个空闲的、已建立好的连接。使用完毕后,应用程序将连接"归还"给池,而不是真正关闭它。这个连接可以被下一个请求复用。
-
2.SQL 接口(SQL Interface)
接收SQL命令,判断其类型(如 DML、DDL、存储过程等),并分发给后续正确的组件去执行,最后将结果返回给客户端。
-
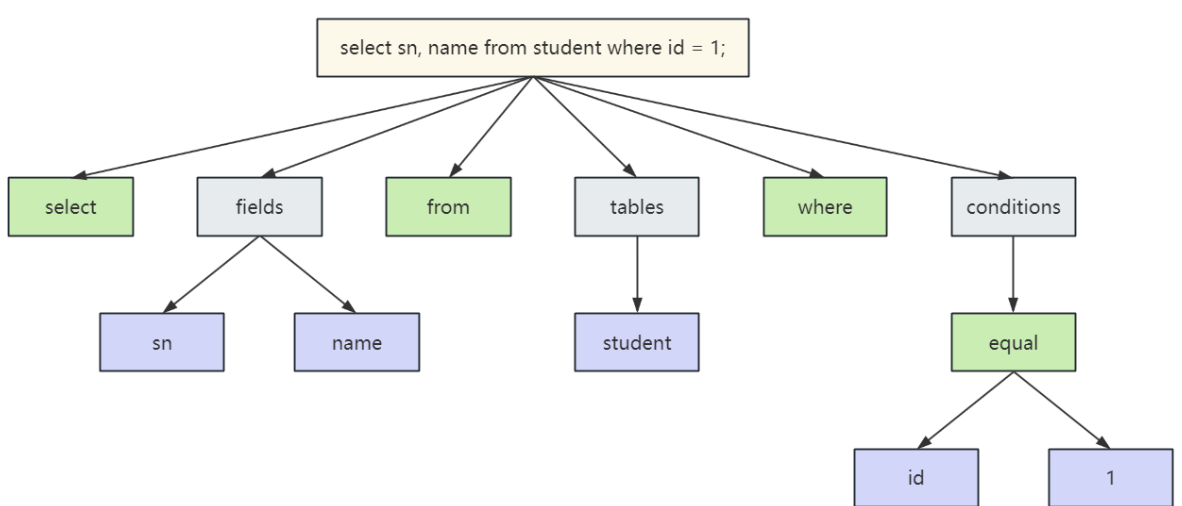
3.解析器(Parser)
将人类可读的、文本形式的 SQL 语句,转换成一个 MySQL 内部能够理解并操作的数据结构(解析树)
- 词法分析: 将完整的 SQL 语句拆分成一个个的"词元"(Token),例如识别 SELECT, FROM, users 等。
- 语法分析:根据 MySQL 的语法规则,检查 SQL 语句是否合法,并生成一颗解析树(Parse Tree),语法分析器会验证 Token 的顺序和结构是否正确。例如,它知道 SELECT 后面应该跟着表达式列表,然后应该是 FROM 子句等。
-
4.优化器(Optimizer)
接收解析器生成的解析树,分析所有可能的执行方式,然后选择它认为"最优"的一个方案,最终生成一个可执行的"查询计划"
优化类型:
- 1.逻辑优化(基于规则的优化):
首先,优化器会对解析树进行一些重写和简化,这些通常是基于公认的逻辑规则,与具体数据无关。例如:
1).条件化简: WHERE a > 5 AND a > 10 会被简化为 WHERE a > 10。
2).常量传递: WHERE a = 5 AND b = a 会被转换为 WHERE a = 5 AND b = 5。
3).无效代码消除: WHERE 1=1 这样的恒真条件会被直接移除。
4).视图展开:如果查询涉及视图,会将视图的 SQL 定义合并到主查询中。 - 2.物理优化(基于成本的优化):
这是核心。优化器会根据表的统计信息(如索引基数、数据分布)来估算不同执行计划(全表扫描、使用哪个索引、多表连接的顺序等)的"成本"(I/O 成本、CPU 成本),然后选择它认为成本最低的那个。
- 1.逻辑优化(基于规则的优化):
-
4.查询缓存(8.0之后被移除):
在 8.0 之前,如果查询语句完全相同(字节级相同),且表数据未发生变更,则直接返回缓存的结果。
被移除的原因:缓存的失效非常频繁,任何对表的修改都会导致所有相关缓存失效,在高并发写环境下,缓存命中率极低,且管理缓存本身带来了不小的开销。
3.存储引擎(Storage Engine Layer)
存储引擎负责从磁盘读取和存储数据。它是真正与磁盘文件打交道的一层。MySQL 提供了多种存储引擎,每个引擎都有其特点,适用于不同的场景。
常见存储引擎对比:
-
InnoDB(默认):
支持外键,事务,行级锁,聚簇索引(数据和索引存储在一起,存储在.idb文件中)
使用场景:绝大多数场景,尤其是需要事务、高并发读写、数据一致性要求高的场景。
-
MYISAM:
不支持事务,外键,表级锁,二级索引(数据和索引分开存放,数据存储在.MYD文件中,索引存储在.MYI文件中),读取速度块,二级索引叶子节点记录数据物理地址。
使用场景:只读或读多写少的场景,如数据仓库、日志表。在并发写场景下性能较差。
-
Memory:
数据存储在内存中,服务器重启数据丢失,访问速度极快,表级锁。
使用场景:用于临时表、缓存或会话管理。适合快速查找的只读数据。
核心机制:
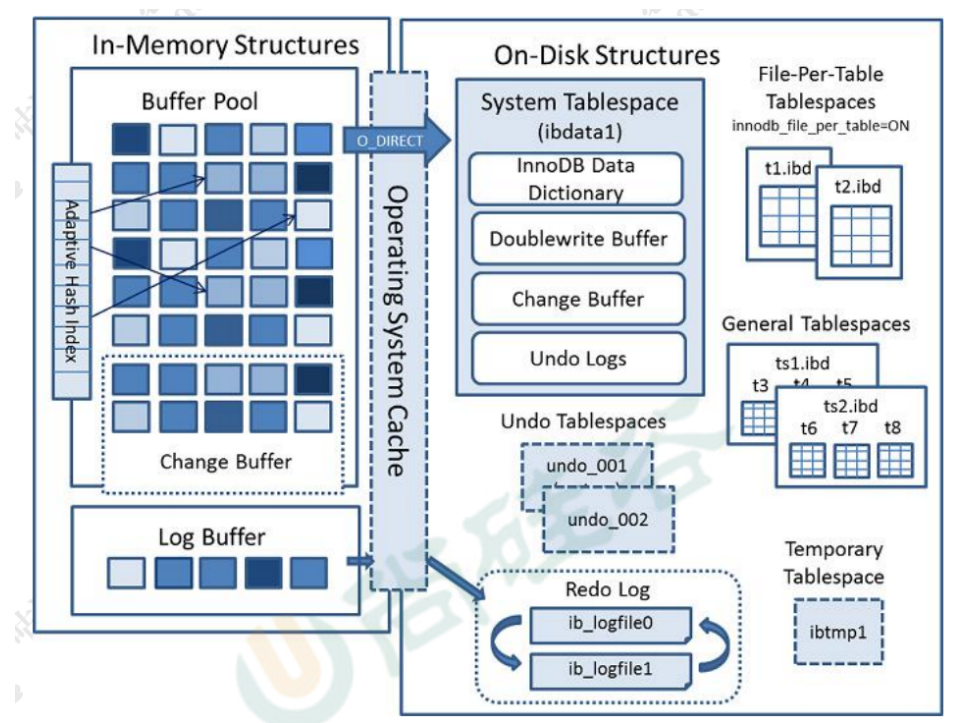
1.缓冲池(Buffer Pool) - InnoDB核心
这是 InnoDB 在内存中开辟的一块关键区域,用于缓存表和索引数据。
读取数据:当需要读取数据时,InnoDB首先检查数据页是否在Buffer Pool中,如果在Buffer Pool中,则直接从Buffer Pool中读取,返回数据,如果不在Buffer Pool中,则从磁盘读取该页放入Buffer Pool。
修改数据:当需要修改数据时,InnoDB首先在BufferPool中修改对应数据页,这个被修改的页称为脏页。InnoDB会有后台线程定期将数据刷线到脏页中。
2.日志模块:
-
重做日志(RedoLog)
- 作用:保证事务的持久性,它是物理日志,记录的是"在某个数据页上做了什么修改"
- 工作流程(Write-Ahead Logging, WAL):事务提交时,先写到redolog日志中,再在合适的时候将BufferPool中的脏页刷新到磁盘中。即使数据库崩溃重启,也可以重做redolog日志中已提交但为写入到数据文件中的事务。保证数据不丢失。
-
回滚日志(Undo Log)
- 作用:保证事务的原子性(Atomicity) 和 MVCC。它是逻辑日志,记录数据被修改前的样子。
- 工作流程:在事务修改前,会将旧数据写入到UndoLog日志中,如果事务需要进行回滚操作,或者其他事务需要读取事务的旧版本(MVCC),就可以从 Undo log中获取数据。
-
二进制日志(Binlog)
- 归属:属于Mysql服务层,所有存储引擎都可以使用。
- 作用:用于主从复制和数据恢复。它记录逻辑日志,记录的是sql语句的原始逻辑。(如 UPDATE users SET name='Bob' WHERE id=1;
一条sql发送给mysql后,内部是如何执行的?(说一下 MySQL执行一条查询语句的内部执行过程?)
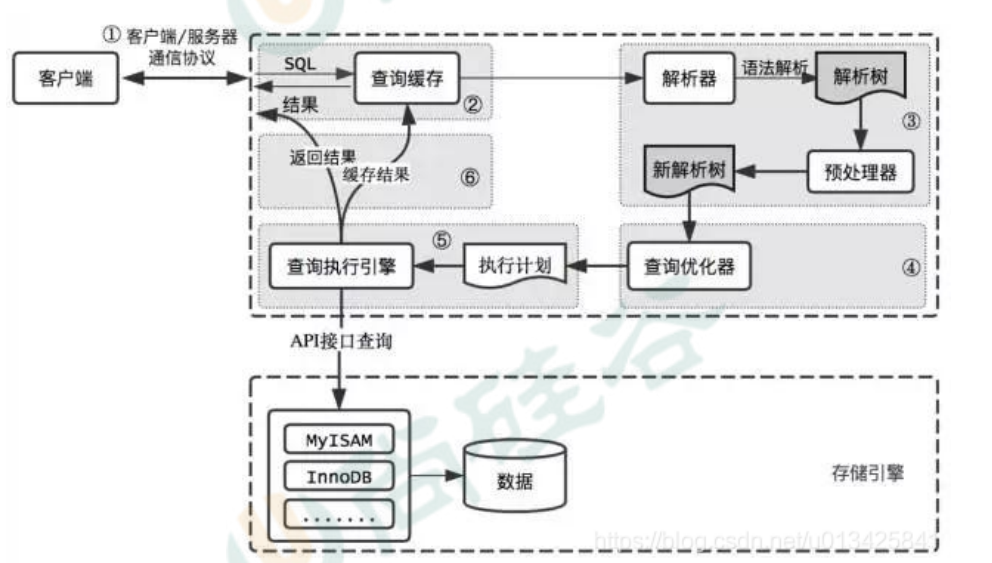
mysql客户端先通过协议与服务器进行连接,通过sql接口发送sql语句,先检查查询缓存是否命中,命中直接返回给客户端。没有命中,进行语句解析,解析器对sql语句进行词法分析(将sql语句拆分成一个个"词元")和语法分析(检查这些"次元"生成的sql语句是否合法),并生成一颗解析树。优化器会根据这个解析树生成一个高效的执行计划,最后进入执行阶段,查询执行引擎根据执行计划调用存储引擎提供的接口查询将结果返回给客户端。