全栈 AI 体系升级,覆盖全模态。
太多、太强大,这回真的看不过来了。
今天上午,阿里在 2025 云栖大会上拿出了压箱底的本领,从基础大模型到模型架构、代码专用模型、视频生成模型、全模态模型,全系列新模型正式发布,实现了全方位的技术突破。

大会现场展示了不少性能对比图、demo 演示,可见这些新模型在智能水平、Agent 工具调用、Coding 能力、深度推理、多模态等方面相较以往都有大幅的进步,而且它们很多都已可以直接上手使用和体验了。
基础模型:超越 GPT-5,探索新方向
仔细数来,通义家族这次共有七款新模型。
旗舰模型方面,新一代旗舰模型通义千问 Qwen3-Max 预览版此前已经发布,其性能已跻身全球第三,超过了 GPT5、Claude Opus 4 等人们耳熟能详的业内顶尖模型。
本次云栖大会,Qwen3-Max 正式发布。
Qwen3-Max 的总参数量超过 1 万亿,分为指令(Instruct)和推理(Thinking)两大版本,新模型在中英文理解、复杂指令遵循、模型工具调用能力和编程能力上实现了突破,智力和情商都大幅增强,与此同时大幅减少了大模型幻觉,在更智能的同时也更加可靠。
具体能力上,Qwen3-Max 在大模型用 Coding 解决真实世界问题的 SWE-Bench 评测中获得了 69.6 分,位列全球第一梯队。在聚焦 Agent 工具调用能力的 Tau2 Bench 测试上,Qwen3-Max 取得突破性的 74.8 分,超过 Claude Opus4 和 DeepSeek V3.1。
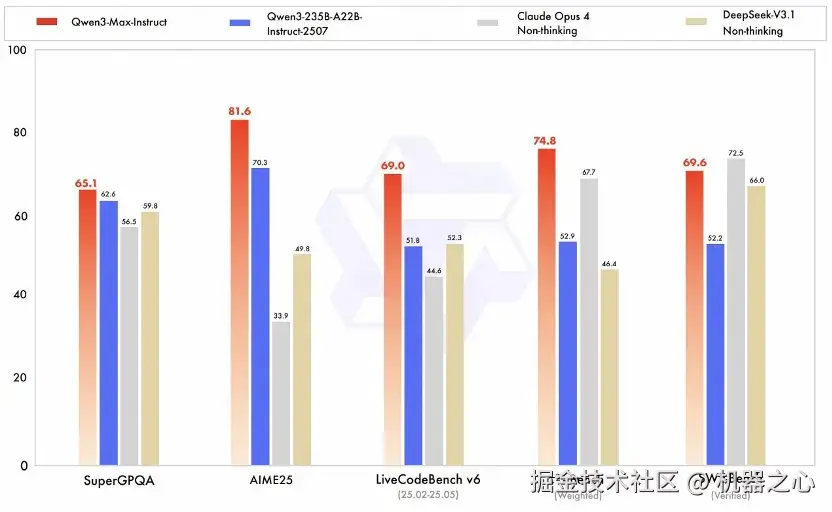
推理增强版本 Qwen3-Max-Thinking-Heavy 可实现结合工具的深度思考,深度推理能力实现重大突破,在 AIME25、HMMT 等数学能力评测中获得满分,是国内首次。
Qwen3-Max 推理模型之所以能力强大,是因为大模型在解题时懂得调动工具,自行写代码做题。另外,增加测试时的计算资源,也能让模型表现变得更好。
在旗舰模型 Qwen3-Max 取得超高性能之外,通义正在探索下一代大模型的前进方向,这次正式发布了千问下一代的基础模型架构 Qwen3-Next 及其系列模型。
众所周知,大模型目前的发展趋势是上下文长度与参数规模两方面的持续扩展。Qwen3-Next 顺应大模型的发展趋势而进行设计,针对性地引入了多项创新:包括混合注意力机制、高稀疏度的 MoE 架构以及多 Token 预测(MTP)机制等核心技术,从而在性能与效率之间实现更优的平衡。
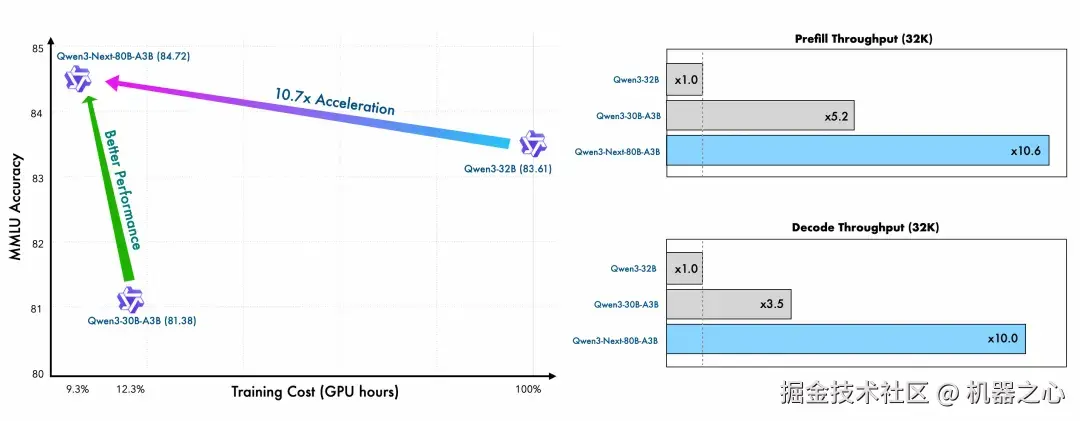
Qwen3-Next 模型总参数为 80B,仅激活 3B ,性能即就可媲美千问 3 旗舰版 235B 模型,实现了模型计算效率的重大突破,模型训练成本较密集模型 Qwen3-32B 大降超 90%,长文本推理吞吐量提升 10 倍以上,为未来大模型的训练和推理的效率树立了全新标准。
除了旗舰级别的大模型,这次发布的模型还覆盖了广泛的专项领域。
专用、多模态模型:进入专业级,填补开源空白
例如大模型最广泛应用的编程领域,千问编程模型 Qwen3-Coder 进行了重磅升级。全新的 Qwen3-Coder 结合了领先的编程系统 Qwen Code 与 Claude Code 进行联合训练,具有非常强大的代码生成和补全能力,更快的推理速度,更安全的代码生成。
Qwen3-Coder 目前已经完全开源,在社区好评如潮,曾在知名 API 调用平台 OpenRouter 上的调用量激增 1474%,全球第二。
另外在多模态领域,千问重磅发布了视觉理解模型 Qwen3-VL,是 Qwen 系列迄今为止最强大的视觉语言模型。该模型一经推出就引起了广泛的讨论。
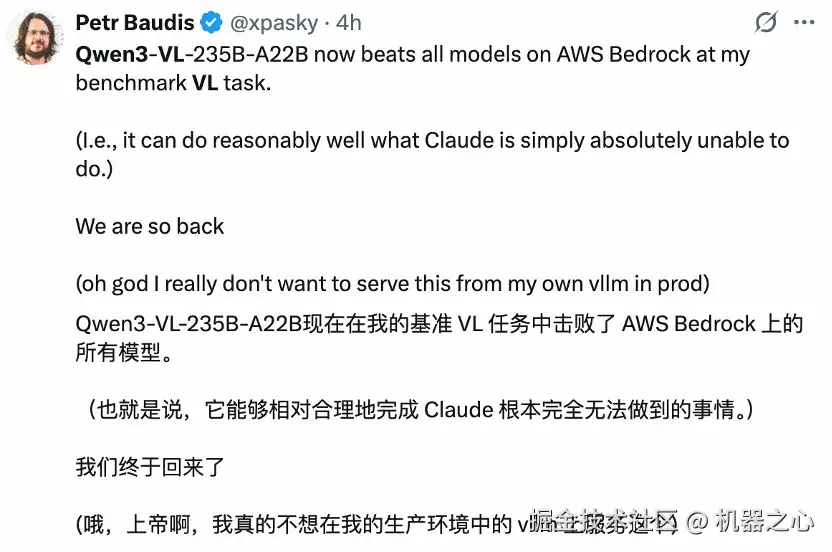
其核心模型 Qwen3-VL-235B-A22B 现已开源,并提供 Instruct 和 Thinking 两种版本:Instruct 在关键视觉基准测试中优于 Gemini 2.5 Pro;Thinking 在多模态推理任务上达到 SOTA 性能 。
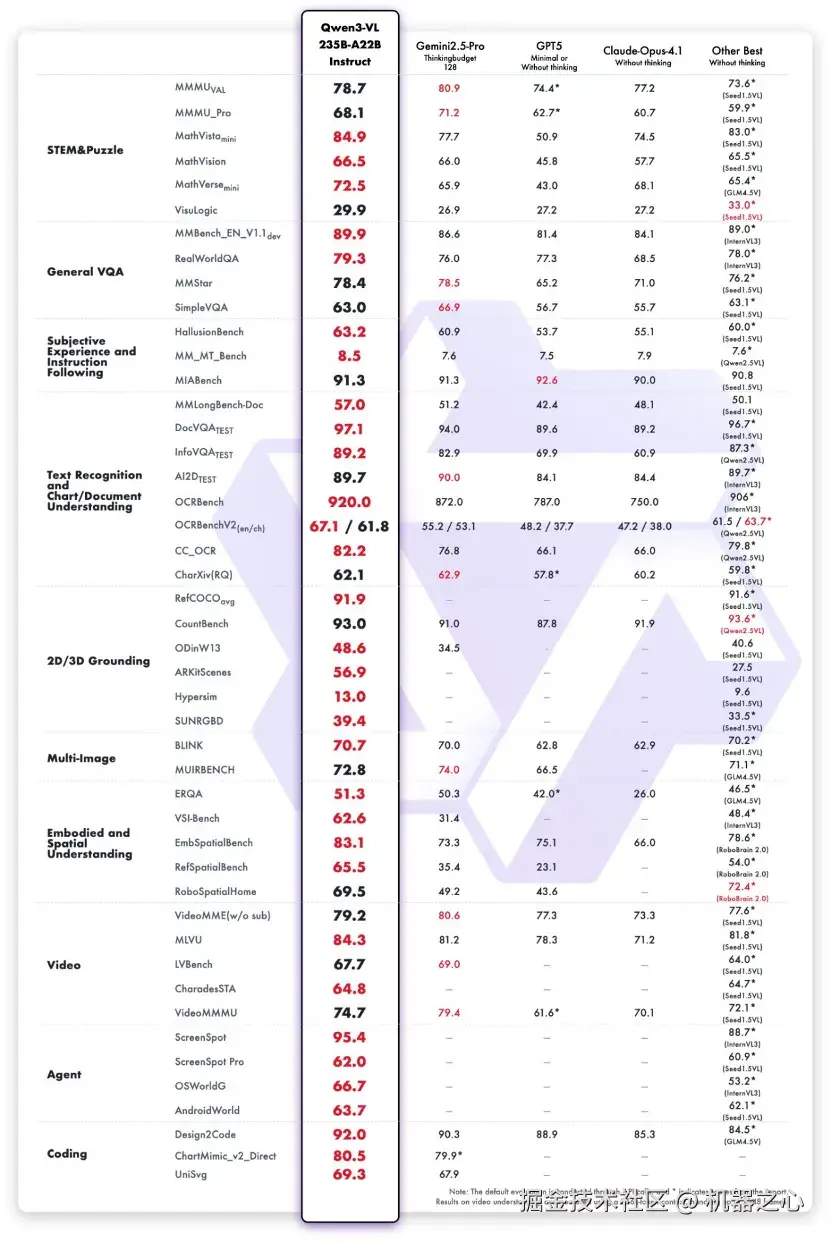
从「看见」到「理解」,从「识别」到「推理与行动」,Qwen3-VL 具备「视觉智能体」(Visual Agent)、「视觉编程」(Visual Coding)以及 3D Grounding(3D 检测)等能力。
Qwen3-VL 能够自主进行电脑和手机界面的操作,识别 GUI 元素、理解按钮功能,还可以通过调用工具执行任务,实现 o3 级别的「带图推理」功能;能够根据设计草图或小游戏视频,生成可执行的 Draw.io/HTML/CSS/JS 代码,完美复刻「所见即所得」的视觉编程。
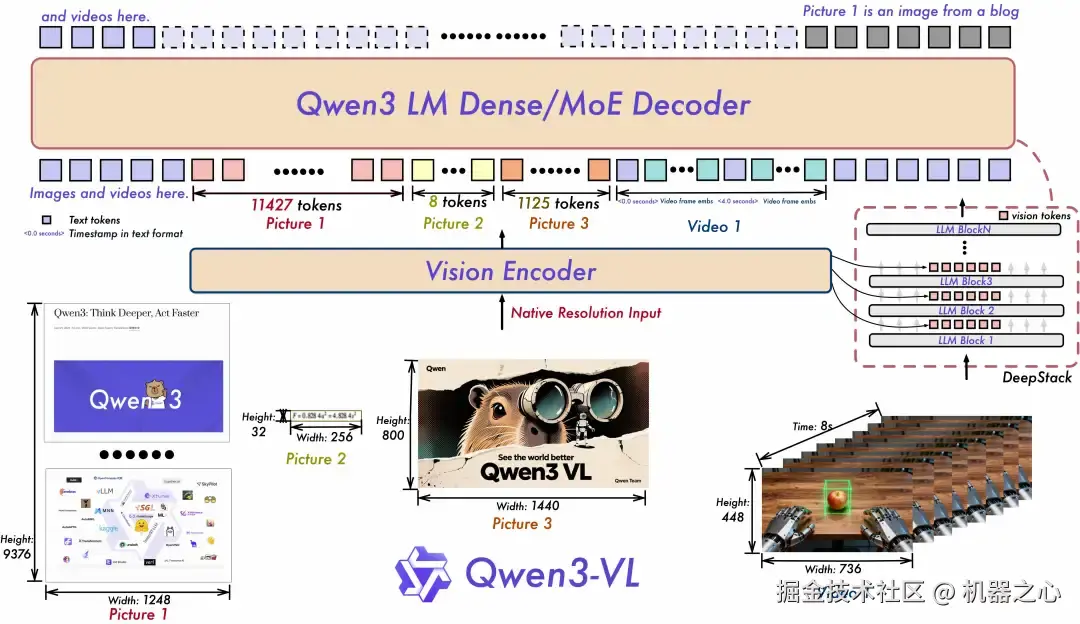
此外,Qwen3-VL 将上下文拓展至百万 tokens,将视频理解时长拓展到 2 小时以上。现在,无论是几百页技术文档、整本教材,还是长达数小时的会议录像、教学视频,都能一股脑丢进去,模型可以全程记忆,实现精准检索。
面向具身智能的空间感知,Qwen3-VL 专门增强了 3D 检测(grounding)能力,可让机器人更好地判断物体方位、视角变化和遮挡关系。
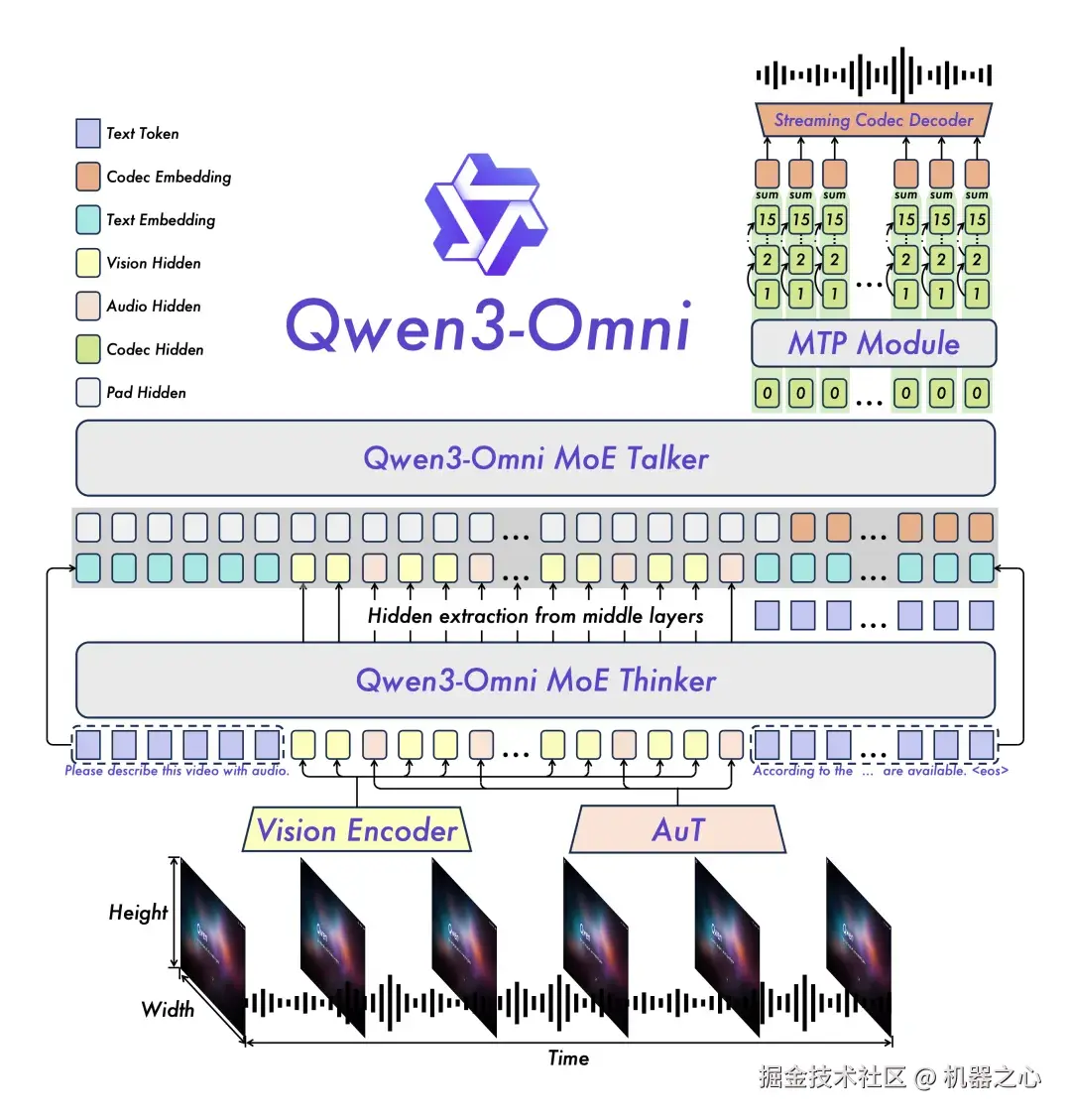
令人惊喜的是,全模态模型 Qwen3-Omni 这次开源了三大版本:Qwen3-Omni-30B-A3B-Instruct、Qwen3-Omni-30B-A3B-Thinking 和 Qwen3-Omni-30B-A3B-Captioner。
它们在 36 项音视频领域公开评测中狂揽 32 项开源最佳性能 SOTA,音频识别、理解、对话能力比肩 Gemini2.5-pro。Qwen3-Omni 能够完全覆盖文本、图像、音频、视频等全模态输入,实时流式响应,可以实现像真人一样实时对话,甚至可以设定个性化角色,打造专属的个人 IP。
其中,Qwen3-Omni-30B-A3B-Captioner 为全球首次开源的通用音频 caption 模型,可以清晰描述用户输入音频的特征,填补了开源社区的空白。
图片编辑模型 Qwen3-Image-Edit 也同样进行了版本更新,新模型支持多图编辑,单图一致性显著提升。
通义大模型家族中的视觉基础模型通义万相,一直是多模态视觉生成领域的领头羊,在图像生成、视频生成、数字人和世界模型等领域保持前列,受到用户的广泛欢迎。至今为止,通义万相已经累计生成 3.9 亿张图像,7000 万个视频。
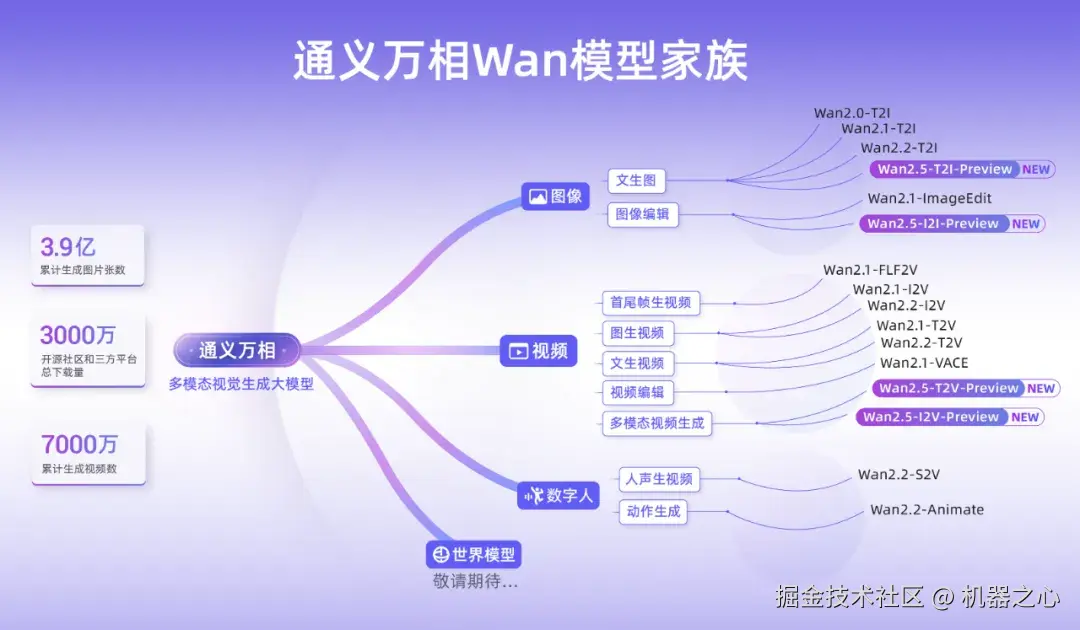
这次推出了 Wan2.5-preview 系列模型,涵盖文生视频、图生视频、文生图和图像编辑四大模型。
Wan2.5 能生成和画面匹配的人声、音效和音乐 BGM,首次实现音画同步的视频生成能力,进一步降低了电影级视频创作的门槛。该模型视频生成的时长达到 10 秒,支持 24 帧每秒的 1080P 高清视频生成,并进一步提升了模型指令遵循能力。Wan2.5-preview 系列模型真正让视频生成迈入「电影级全感官叙事时代」。
此次,通义万相 2.5 还全面升级了图像生成能力,可生成中英文文字和图表,支持图像编辑功能,输入一句话即可完成图像处理。
这里还有 one more thing:云栖大会上,通义大模型家族迎来了最新成员 ------ 语音大模型通义百聆 Fun。

它包括语音识别大模型 Fun-ASR 和语音合成大模型 Fun-CosyVoice。据通义团队介绍,Fun-ASR 由数千万小时真实语音数据训练而成,具备强大的上下文理解能力与适用性。Fun-CosyVoice 则可以提供上百种预制音色,可以用于客服、销售、直播电商、消费电子、有声书、儿童娱乐等落地场景。
引爆科技圈的 Qwen,已经完成了整体布局
至此,通义大模型家族完成了最后一块拼图,它覆盖了从 0.5B 到 480B 的「全尺寸」,基础模型、编程、图像、语音、视频的「全模态」,全面开源,现在还又更新了一遍。
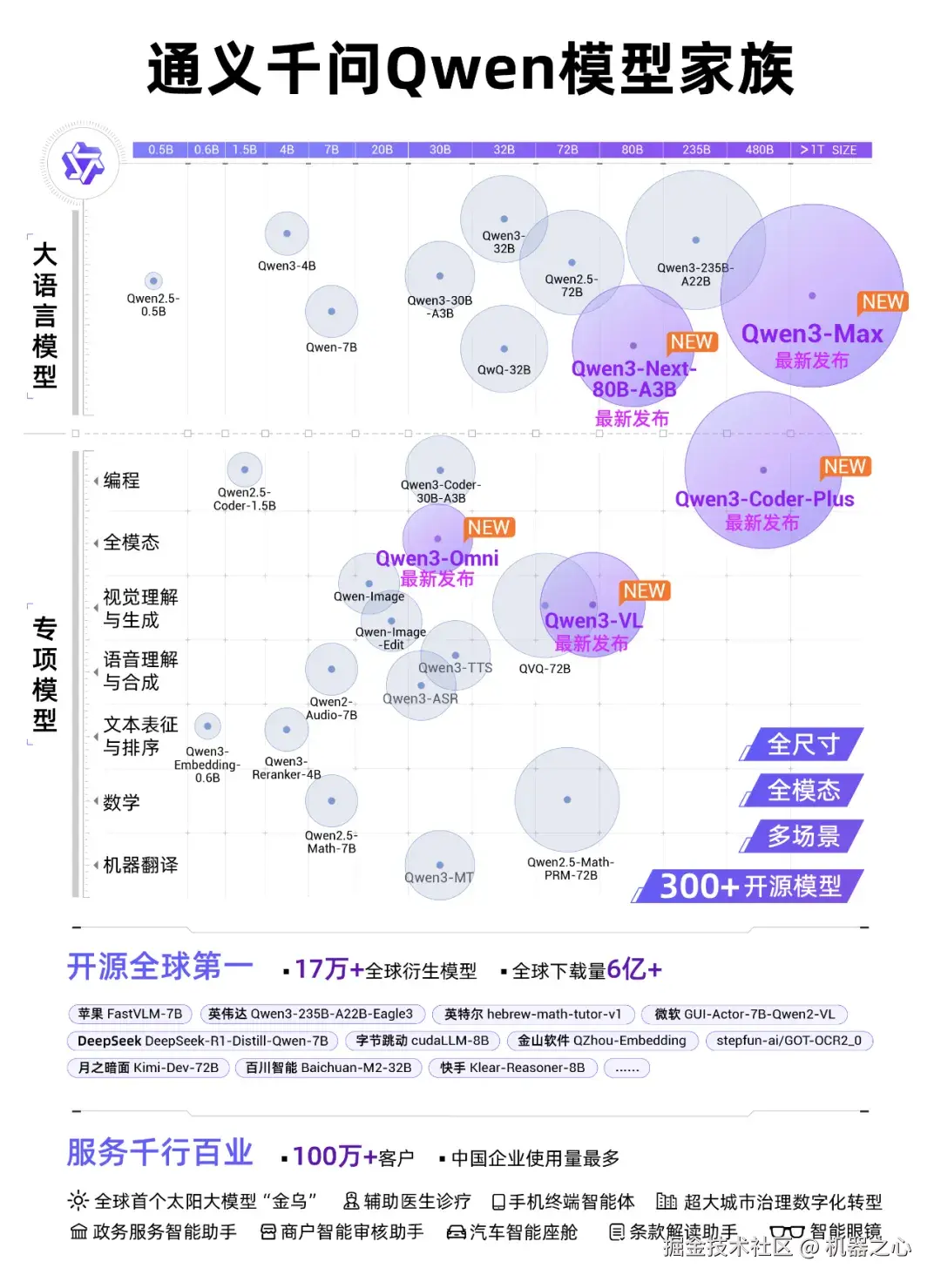
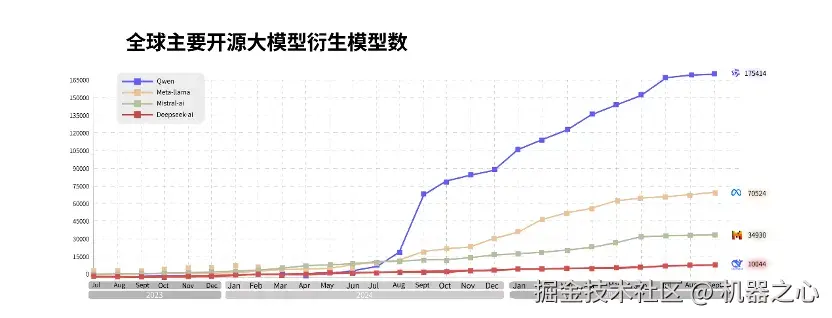
在 AI 圈里,通义早已是全球范围内不可忽视的一股力量,它的每次发布都会在国内外引发关注和讨论。自去年 9 月超越 Llama 成为衍生模型数量第一以来,千问大模型持续快速发展,其开源的模型不仅在多项关键性能评测中取得领先,更能以先进的架构、效率的优势,深刻影响着 AI 技术各方向的普及和应用。
在云栖大会上,阿里公布了通义的一系列最新成绩:截至目前,阿里已开源 300 余款通义大模型,全球下载量突破 6 亿次,衍生模型突破 17 万个,稳居全球第一,有超过 100 万家客户接入了通义大模型。
阿里还表示,未来三年将投入超过 3800 亿元用于建设云和 AI 硬件基础设施,持续升级全栈 AI 能力。
阿里巴巴集团董事兼 CEO、阿里云智能集团董事长兼 CEO 吴泳铭表示,实现 AGI,现在看来已成为确定性事件。但 AGI 并非 AI 发展的终点,而是全新的起点。AI 不会止步于 AGI,它将迈向超越人类智能、能够自我迭代进化的超级人工智能(ASI)。

阿里云的战略路径,一是坚定通义千问的开源开放路线,打造「AI 时代的安卓系统」,二是构建作为「下一代计算机」的超级 AI 云,为全球提供智能算力网络。
未来,大模型将会替代现代操作系统(OS)的地位,成为链接所有真实世界工具的接口。所有用户需求和行业应用将会通过大模型相关工具执行任务,LLM 将会是承载用户、软件与 AI 计算资源交互调度的中间层。

AI 的格局,将会被开源模型所改变。