DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning




https://www.nature.com/articles/s41586-025-09422-z.pdf
Data availability
We provide the data samples used in our rejection sampling and RL prompts at https://github.com/deepseek-ai/DeepSeek-R1 (https://doi.org/10.5281/zenodo.15753193)33. Comprehensive statistics and details of our complete data-generation methodology are presented in Supplementary Information, section 2.3.
Code availability
Trained weights of DeepSeek-R1-Zero and DeepSeek-R1 are available under an MIT license at https://github.com/deepseek-ai/DeepSeek-R1 (https://doi.org/10.5281/zenodo.15753193)33. The inference script is released at https://github.com/deepseek-ai/DeepSeek-V3 (https://doi.org/10.5281/zenodo.15753347)34. Neural networks were developed with PyTorch35 and the distributed framework is based on our internal framework HAI-LLM (https://www.high-flyer.cn/en/blog/hai-llm). The inference framework is based on vLLM36. Data analysis used Python v.3.8 (https://www.python.org/), NumPy v.1.23.1 (https://github.com/numpy/numpy), Matplotlib v.3.5.2 (https://github.com/matplotlib/matplotlib) and TensorBoard v.2.9.1 (https://github.com/tensorflow/tensorboard).
Abstract
General reasoning represents a long-standing and formidable challenge in artificial intelligence (AI). Recent breakthroughs, exemplified by large language models (LLMs)1,2 and chain-of-thought (CoT) prompting3, have achieved considerable success on foundational reasoning tasks. However, this success is heavily contingent on extensive human-annotated demonstrations and the capabilities of models are still insufficient for more complex problems. Here we show that the reasoning abilities of LLMs can be incentivized through pure reinforcement learning (RL), obviating the need for human-labelled reasoning trajectories. The proposed RL framework facilitates the emergent development of advanced reasoning patterns, such as self-reflection, verification and dynamic strategy adaptation. Consequently, the trained model achieves superior performance on verifiable tasks such as mathematics, coding competitions and STEM fields, surpassing its counterparts trained through conventional supervised learning on human demonstrations. Moreover, the emergent reasoning patterns exhibited by these large-scale models can be systematically used to guide and enhance the reasoning capabilities of smaller models.
通用推理是人工智能领域一个长期且艰巨的挑战。最近的技术突破,例如大型语言模型和思维链提示,在基础推理任务上取得了显著成功。然而,这种成功严重依赖于大量人工标注的示例,并且模型的能力在处理更复杂问题时仍显不足。本文研究表明,无需人类标注的推理轨迹,仅通过纯强化学习即可激发LLMs的推理能力 。所提出的强化学习框架促进了高级推理模式的出现,例如自我反思、验证和动态策略调整。因此,训练出的模型在数学、编程竞赛和STEM领域等可验证任务上表现出色,性能超越了基于人类演示的传统监督学习方法。此外,这些大规模模型所展现出的推理模式,可系统性地用于指导并增强小模型的推理能力。
Main
推理能力是人类智能的基石,它支撑着从数学解题到逻辑演绎和编程等一系列复杂认知任务。人工智能的最新进展表明,当LLMs达到足够规模时,可以展现出包括推理能力在内的涌现行为 。然而,在预训练中获得这种能力通常需要巨大的计算资源。并行的一个研究方向表明,通过思维链提示可以有效增强LLMs。该技术通过提供少量示例或使用"让我们一步步思考"等简洁提示,使模型能够产生中间推理步骤,从而大幅提升其在复杂任务上的表现。类似地,在训练后阶段让模型学习高质量的多步推理轨迹也能带来进一步的性能提升。尽管有效,这些方法存在明显局限:对人工标注推理轨迹的依赖限制了可扩展性并引入了认知偏差;同时,通过限制模型复制人类思维过程,其性能本质上受限于人类提供的范例,阻碍了对潜在的、更优越的非人类式推理路径的探索。
为解决这些问题,本文旨在探索在最小化依赖人工标注的前提下,通过强化学习框架下的自我进化来开发LLMs推理潜力。具体而言,本文基于DeepSeek-V3 Base模型,并采用分组相对策略优化作为本文的强化学习框架。奖励信号仅基于最终预测答案的正确性,对推理过程本身不加任何限制。值得注意的是,本文绕过了强化学习训练前常规的监督微调阶段。这一设计源于本文的假设:人类定义的推理模式可能限制模型探索,而无限制的强化学习能更好地激发LLMs中新推理能力的涌现。通过此过程,本文的模型(称为DeepSeek-R1-Zero)自然发展出了多样且复杂的推理行为。为解决推理问题,该模型倾向于生成更长的回应,在单个回应中融入验证、反思以及对替代方法的探索。尽管本文没有明确教导模型如何推理,它仍成功通过强化学习掌握了改进的推理策略。
尽管DeepSeek-R1-Zero展现出卓越的推理能力,但它也面临可读性差、语言混合(偶尔在单个思维链回应中混合中英文)等挑战。此外,其基于规则的强化学习阶段仅专注于推理任务,导致在写作、开放域问答等更广泛领域表现有限。为应对这些挑战,本文引入了DeepSeek-R1 。该模型通过一个集成拒绝采样、强化学习和监督微调的多阶段学习框架进行训练。此训练流程使DeepSeek-R1能够继承DeepSeek-R1-Zero的推理能力,同时通过进一步的非推理数据使模型行为与人类偏好对齐。
为以更低能耗推广强大的人工智能,本文蒸馏了多个小模型并公开提供。这些蒸馏模型展现出强大的推理能力,性能超越了其原始的指令微调版本。本文相信这些指令微调版本将为研究界理解长思维链推理模型的机制、推动更强大推理模型的发展提供宝贵资源。本文按"代码可用性"部分所述,向公众发布DeepSeek-R1-Zero、DeepSeek-R1、数据样本和蒸馏模型。
DeepSeek-R1-Zero
为实现大规模强化学习,本文采用了高效的强化学习流程。具体而言,本文使用GRPO作为强化学习算法,并采用基于规则的奖励系统来计算准确性和格式奖励。本文的高性能强化学习基础设施确保了可扩展且高效的训练。
具体来说,本文在DeepSeek-V3 Base模型上应用强化学习技术来训练DeepSeek-R1-Zero。训练中,本文设计了一个简洁模板,要求模型先产生推理过程,再给出最终答案。提示模板如下:
"一段用户与助手之间的对话。用户提问,助手解决问题。推理过程和答案包含在<think b>...</认为>和<回答>...</answer>标签,即<思考>的推理过程在这里</思考><回答>的答案在这里</回答>。用户:提示。助手:",其中提示被替换为培训时的具体推理问题。 本文刻意将约束仅限于此结构格式,避免任何内容上的偏见,以确保能准确观察模型在强化学习过程中的自然演进。
图1a 显示了DeepSeek-R1-Zero在AIME 2024基准测试上的性能随强化学习训练的变化轨迹。其平均pass@1分数从初始的15.6%显著跃升至77.9%。此外,通过使用自一致性解码,模型性能可进一步提升至86.7%的准确率。此表现远超AIME人类参赛者的平均成绩 。除数学竞赛外,DeepSeek-R1-Zero在编程竞赛以及研究生水平的生物、物理和化学问题上也取得了显著性能。这些结果突显了强化学习在增强LLMs推理能力方面的有效性。
Fig.1 Accuracy and output length of DeepSeek-R1-Zero throughout the training process.
图1a,DeepSeek-R1-Zero在训练期间的AIME准确率。 AIME以数学问题作为输入,数字作为输出(见扩展数据表1)。pass@1和cons@16的说明见补充信息第4.1节。基线是人类参与者在AIME竞赛中的平均得分。
图 b,RL过程中DeepSeek-R1-Zero在训练集上的平均响应长度。 DeepSeek-R1-Zero自然地学会了用更长的思考时间来解决推理任务。请注意,训练步长指的是单次策略更新操作。
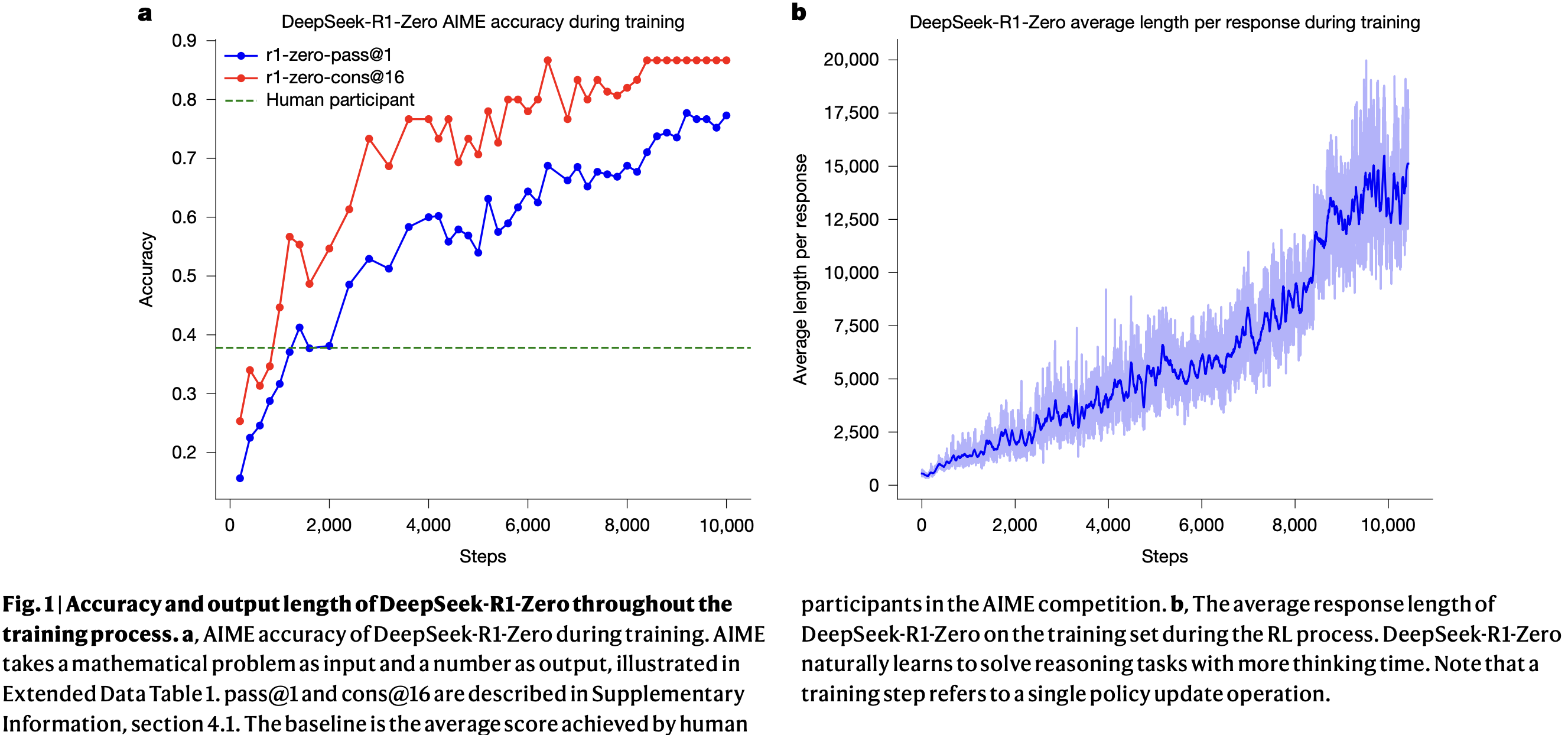
除了推理能力在训练过程中的逐步增强,DeepSeek-R1-Zero还展现出随RL训练而自我进化的行为。如图1b所示,在仅由内部适应而非外部修改驱动下,DeepSeek-R1-Zero在整个训练过程中表现出思考时间的稳定增长。利用长思维链,模型逐步完善其推理,生成数百至数千个token来探索和改进其问题解决策略。
思考时间的增加有助于复杂行为的自主发展 。具体而言,DeepSeek-R1-Zero越来越多地展现出高级推理策略,例如反思性推理 和对替代解决方案的系统性探索 (见扩展数据图1a),这显著提升了其在数学和编程等可验证任务上的性能。值得注意的是,在训练期间,DeepSeek-R1-Zero经历了一个 "顿悟时刻" (见表1),其特征是在反思过程中"wait"一词的使用量突然增加(见扩展数据图1b)。这一时刻标志着推理模式的显著变化,清晰地展示了DeepSeek-R1-Zero的自我进化过程。
Table 1 An interesting 'aha moment' of an intermediate version of DeepSeek-R1-Zero

DeepSeek-R1-Zero的自我进化凸显了强化学习的威力和美感:本文并非明确教导模型如何解决问题,而仅仅是提供正确的激励,它便能自主发展出高级的问题解决策略。这提醒本文RL在解锁LLMs更高层次能力方面的潜力,为未来开发更自主、更自适应的模型铺平了道路。
DeepSeek-R1
尽管DeepSeek-R1-Zero展现出强大的推理能力,但它面临一些问题,例如可读性差和语言混合(因为DeepSeek-V3 Base使用多种语言训练,尤其是中英文)。为解决这些问题,本文开发了DeepSeek-R1,其流程如图2所示。在初始阶段,收集了数千条展现对话式、符合人类思维的思考过程的冷启动数据 。随后应用RL训练,以改进模型在对话式思维过程和语言一致性方面的表现。接着,再次应用拒绝采样和监督微调 。此阶段将推理和非推理数据集都纳入SFT过程,使模型不仅擅长推理任务,还展现出高级的写作能力。为进一步使模型与人类偏好对齐,实施了第二阶段RL训练,旨在增强模型的有用性和无害性,同时优化其推理能力。总训练成本见补充信息第2.4.4节。
Fig. 2: The multistage pipeline of DeepSeek-R1.
A detailed background on DeepSeek-V3 Base and DeepSeek-V3 is provided in Supplementary Information, section 1.1. The models DeepSeek-R1 Dev1, Dev2 and Dev3 represent intermediate checkpoints in this pipeline.
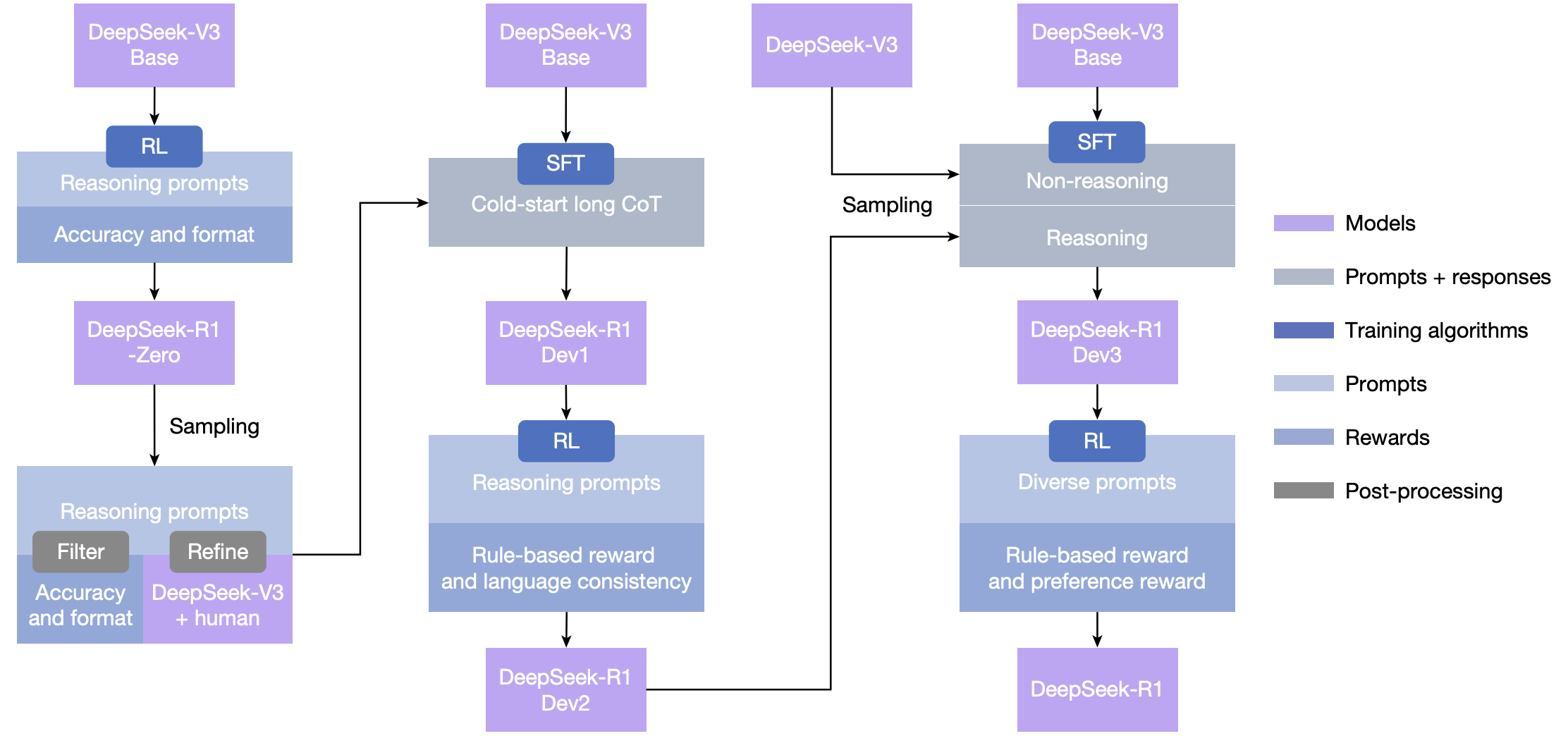
模型DeepSeek-R1 Dev1、Dev2和Dev3代表了此流程中的中间检查点。
本文在MMLU、MMLU-Redux、MMLU-Pro、DROP、C-Eval、IFEval、FRAMES、GPQA Diamond、SimpleQA、C-SimpleQA、CLUEWSC、AlpacaEval 2.0、Arena-Hard、SWE-bench Verified、Aider-Polyglot、LiveCodeBench、Codeforces、中国高中数学联赛(CNMO 2024)和AIME 2024等基准上评估了本文的模型。这些基准的详细信息见补充表15--29。
表2总结了DeepSeek-R1在几个发展阶段(对应图2)的性能。 DeepSeek-R1-Zero与DeepSeek-R1 Dev1的比较显示,在指令遵循方面有显著改进(IFEval和Arena-Hard得分更高)。然而,由于冷启动数据集规模有限,与DeepSeek-R1-Zero相比,Dev1的推理性能出现部分下降(在AIME基准上尤为明显)。相比之下,DeepSeek-R1 Dev2 在需要高级推理技能的基准上表现出显著性能提升,包括代码生成、数学问题解决和STEM相关任务。面向通用任务的基准仅显示边际改善。这些结果表明,面向推理的RL显著增强了推理能力,同时对面向用户偏好的基准影响有限。
Table 2 Experimental results at each stage of DeepSeek-R1
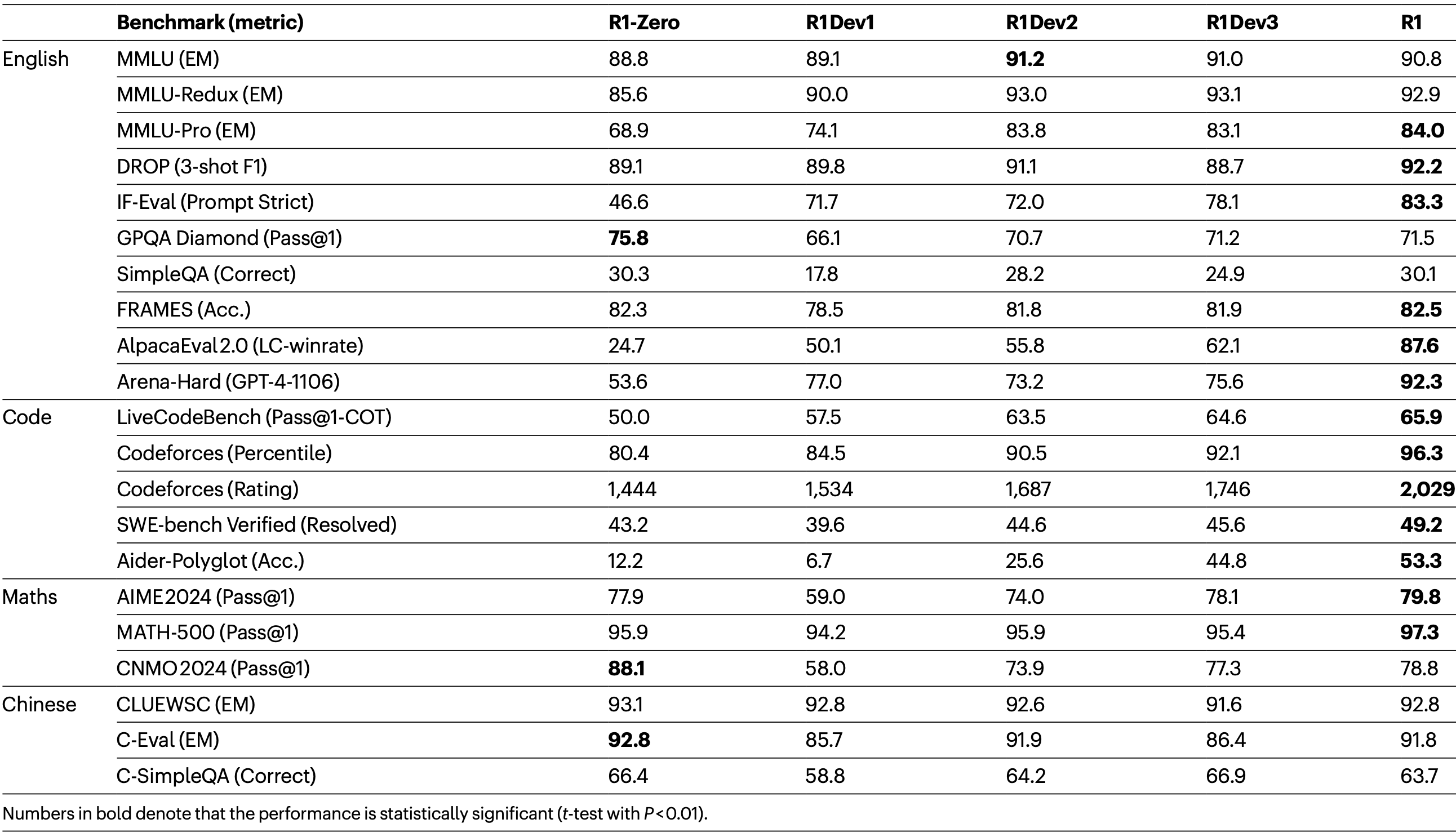
DeepSeek-R1 Dev3 将推理和非推理数据集都整合到SFT流程中,从而增强了模型在推理和通用语言生成任务上的能力。与Dev2相比,Dev3在AlpacaEval 2.0和Aider-Polyglot上取得了显著性能提升,这归因于大规模非推理语料库和代码工程数据集的加入。最后,在Dev3基础上使用混合的推理导向和通用数据进行的全面RL训练产生了最终的DeepSeek-R1 。在代码和数学基准上仅有边际改善,因为大量针对推理的RL已在前期完成。最终DeepSeek-R1的主要进步体现在通用指令遵循和用户偏好基准上,AlpacaEval 2.0提升了25%,Arena-Hard提升了17%。
本文还在补充信息第4.2节中将DeepSeek-R1与其他模型进行了比较。模型安全性评估见补充信息第4.3节。补充信息第5节提供了全面的评估分析,包括与DeepSeek-V3的比较、在新测试集上的性能评估、按类别划分的数学能力细分以及测试时缩放行为的研究。补充信息第6节表明,强大的推理能力可以迁移到更小的模型。
Ethics and safety statement
随着DeepSeek-R1推理能力的进步,本文深刻认识到潜在的伦理风险。例如,R1可能遭受越狱攻击 ,导致生成诸如爆炸物制造指南等危险内容;而增强的推理能力使模型能够提供操作性更强、更易执行的计划。此外,公开模型也易受进一步微调的影响,这可能损害其固有的安全防护。
在补充信息第4.3节中,本文从多个角度提供了一份全面的安全报告,包括在开源和内部安全评估基准上的表现、多语言安全水平以及抵御越狱攻击的能力。这些综合分析表明,DeepSeek-R1模型固有的安全水平与其他前沿模型相比,总体处于中等程度 。然而,当结合风险控制系统后,模型的安全水平可提升至卓越标准。
Conclusion, limitation and future work
本文提出了DeepSeek-R1-Zero和DeepSeek-R1,它们依赖大规模强化学习来激励模型的推理行为。结果表明,预训练检查点本身在复杂推理任务上具有巨大潜力。本文认为,释放此潜力的关键不在于大规模人工标注,而在于提供困难的推理问题、可靠的验证器以及足够的RL计算资源。复杂的推理行为,如自我验证和反思,似乎在RL过程中有机地涌现出来。
尽管DeepSeek-R1在推理基准上取得了领先成果,但它仍面临一些能力限制,概述如下:
-
结构化输出与工具使用 :目前,DeepSeek-R1的结构化输出能力仍逊于现有模型。此外,DeepSeek-R1无法利用搜索引擎和计算器等工具来提升输出性能。不过,为结构化输出和工具使用构建RL环境并非难事,本文相信该问题将在下一版本中得到解决。
-
Token效率 :与多数投票或蒙特卡洛树搜索等传统测试时计算缩放方法不同,DeepSeek-R1能根据问题复杂度动态分配推理计算资源 。然而,在Token效率方面仍有进一步优化空间,因为在处理较简单问题时仍会观察到过度推理的现象。
-
语言混合 :DeepSeek-R1目前主要针对中英文优化,这可能导致处理其他语言查询时出现语言混合问题。这一限制可能与基础检查点DeepSeek-V3 Base主要使用中英文有关。本文旨在未来更新中解决此问题。
-
提示工程 :在评估中发现,DeepSeek-R1对提示词敏感。少样本提示通常会降低其性能。因此,建议用户直接描述问题并使用零样本提示指定输出格式以获得最佳结果。
-
软件工程任务 :由于评估耗时影响RL效率,大规模RL未在软件工程任务中广泛应用。因此,DeepSeek-R1在此类基准上相对DeepSeek-V3未展现出巨大提升。未来版本将通过对软件工程数据进行拒绝采样或在RL过程中引入异步评估来提高效率。
除具体能力限制外,纯RL方法本身也存在固有挑战:
- 奖励破解 :纯RL的成功依赖于可靠的奖励信号。本研究通过基于规则的奖励模型确保可靠性。然而,对于某些任务难以构建可靠的奖励模型。如果奖励信号由模型而非预定规则给出,则更容易在训练中被利用。因此,对于无法通过可靠奖励模型有效评估的复杂任务,扩展纯RL方法仍是一个开放挑战。
在本工作中,对于无法获得可靠信号的任务,DeepSeek-R1使用人工标注创建监督数据,并仅进行数百步RL训练。希望未来能获得更稳健的奖励模型来解决此类问题。
随着DeepSeek-R1等纯RL方法的出现,未来在解决任何可由验证器有效评估的任务方面具有巨大潜力。配备此类先进RL技术的机器,有望通过试错迭代优化性能,从而在这些领域超越人类能力。然而,对于构建可靠奖励模型本身就很困难的任务,挑战依然存在。未来研究应专注于为这些复杂、难以验证的问题开发创新的奖励结构定义与优化方法。
此外,在推理过程中利用工具具有显著前景 。无论是使用编译器、搜索引擎来检索或计算必要信息,还是使用生物或化学试剂等外部工具在现实世界中验证最终结果,这种工具增强推理的整合将极大扩展机器驱动解决方案的范围和准确性。
Methods
GRPO
GRPO是本文用于训练DeepSeek-R1-Zero和DeepSeek-R1的RL算法。该算法最初被提出是为了简化训练过程并降低近端策略优化(PPO)的资源消耗,而PPO广泛用于LLMs的RL阶段。GRPO的流程见扩展数据图2。
对于每个问题qq,GRPO从旧策略πoldπold采样一组输出{o1,o2,...,oGo1,o2,...,oG},然后通过最大化以下目标来优化策略模型πθπθ:
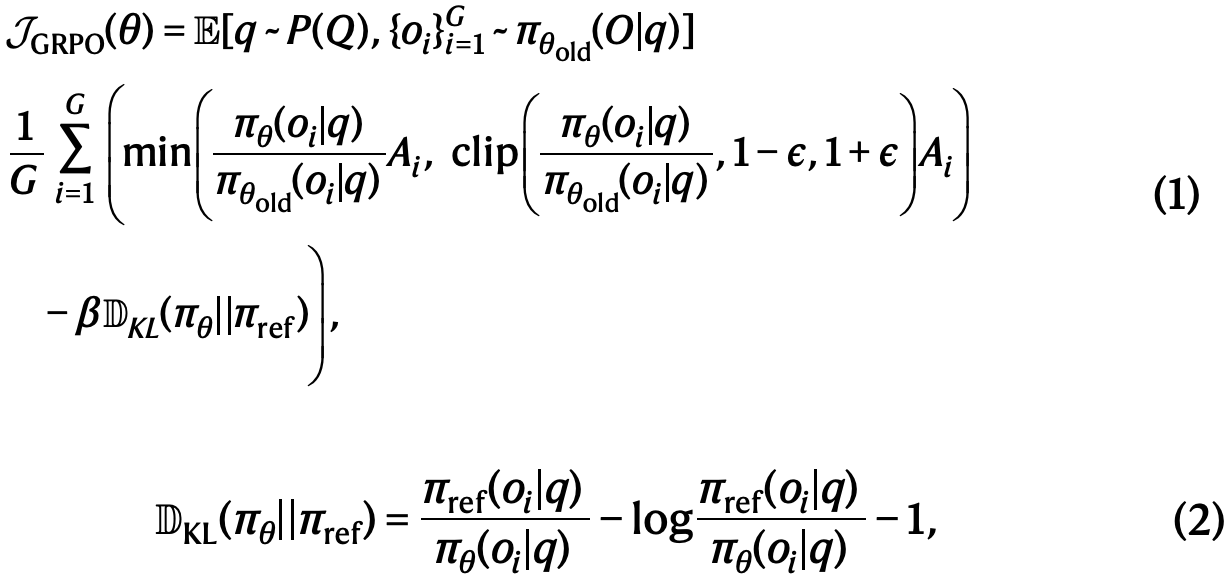
其中πrefπref是参考策略,ϵϵ和ββ是超参数,AiAi是优势函数,使用对应每组输出的奖励{r1,r2,...,rGr1,r2,...,rG}计算得出:
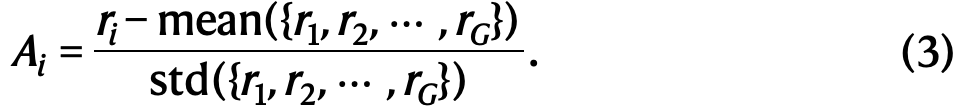
本文在补充信息第1.3节给出了GRPO与PPO的比较。
Reward design
奖励是训练信号的来源,决定了RL优化的方向。对于DeepSeek-R1-Zero,使用基于规则的奖励 为数学、编程和逻辑推理领域的数据提供精确反馈。对于DeepSeek-R1,扩展了此方法,结合了面向推理数据的规则奖励和面向通用数据的模型奖励,从而增强了学习过程在不同领域的适应性。
Rule-based rewards
本文的规则奖励系统主要包括两种奖励:准确性奖励 和格式奖励。
准确性奖励评估响应是否正确。例如,对于结果确定的数学问题,要求模型以指定格式提供最终答案,从而实现可靠的基于规则的正确性验证。类似地,对于代码竞赛提示,可以使用编译器针对一套预定义的测试用例来评估模型的响应,从而生成关于正确性的客观反馈。
格式奖励 通过强制执行特定的格式要求来补充准确性奖励。特别是,激励模型将其推理过程封装在指定的标签(<think>和</think>)内。这确保了模型的思维过程被明确划分,增强了可解释性并便于后续分析。

准确性奖励和格式奖励以相同权重结合。值得注意的是,本文不对推理任务使用神经奖励模型。这一决定基于本文的观察:神经奖励模型在大规模RL期间容易受到奖励破解的影响。此外,重新训练此类模型需要大量计算资源,并给训练流程引入进一步复杂性。
Model-based rewards
对于通用数据,本文借助奖励模型 来捕捉复杂微妙场景中的人类偏好。基于DeepSeek-V3流程,使用了类似的偏好对和训练提示分布。对于有用性 ,只关注最终摘要,确保评估强调响应对于用户的使用性和相关性,同时最小化对底层推理过程的干扰。对于无害性,本文评估模型的整个响应(包括推理过程和摘要),以识别和减轻生成过程中可能出现的任何潜在风险、偏见或有害内容。
Helpful reward model
对于有用性奖励模型训练,首先通过使用Arena-Hard提示格式提示DeepSeek-V3来生成偏好对。每个偏好对包含一个用户查询和两个候选响应。对于每个偏好对,本文查询DeepSeek-V3四次,随机分配响应为"响应A"或"响应B"以减轻位置偏差。最终偏好得分通过平均四次独立判断确定,仅保留得分差异大于1的配对以确保区分度。此外,为减少长度相关偏差,本文确保整个数据集中被选中和拒绝的响应具有可比长度。本文总共整理了66,000个数据对用于训练奖励模型。该数据集中的提示均为非推理问题,来源为公开可用的开源数据集或明确同意共享数据以改进模型的用户。本文的奖励模型架构与DeepSeek-R1一致,但增加了一个用于预测标量偏好得分的奖励头。
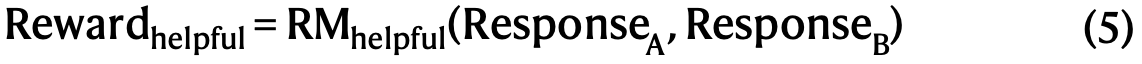
有用性奖励模型的训练批大小为256,学习率为6×10⁻⁶,并在训练数据集上训练一个周期。训练期间最大序列长度设置为8,192个token,而在奖励模型推理期间不设明确限制。
Safety reward model
为评估和提高模型安全性,本文整理了一个包含106,000个提示的数据集,其中模型生成的响应根据预定义的安全指南被标注为"安全"或"不安全"。与有用性奖励模型使用的成对损失不同,安全性奖励模型使用逐点方法进行训练以区分安全和不安全响应。训练超参数与有用性奖励模型相同。

对于通用查询,每个实例被归类属于安全性数据集或有用性数据集。分配给每个查询的通用奖励对应于相关数据集中定义的相应奖励。
Training details
Training details of DeepSeek-R1-Zero
学习率设为3×10⁻⁶,KL系数为0.001,用于生成的采样温度为1。对于每个问题,在第8.2千步之前采样16个输出(最大长度32,768个token),之后为65,536个token。因此,DeepSeek-R1-Zero的性能和响应长度在第8.2千步出现显著跳跃,训练总共持续10,400步(对应1.6个训练周期)。每个训练步包含32个独立问题,训练批大小为512。每400步,将参考模型更新为最新的策略模型。为加速训练,每次生成8,192个输出,随机分成16个小批次,并且仅训练一个内部周期。
Training details of the first RL stage
学习率设为3×10⁻⁶,KL系数为0.001,GRPO裁剪比率ϵϵ为10,用于生成的采样温度为1。每个问题采样16个输出(最大长度32,768个token)。每个训练步包含32个独立问题,训练批大小为512。每400步更新参考模型。为加速训练,每次生成8,192个输出,随机分成16个小批次,仅训练一个内部周期。然而,为缓解语言混合问题,在RL训练中引入了语言一致性奖励,其计算为思维链中目标语言词汇的比例。
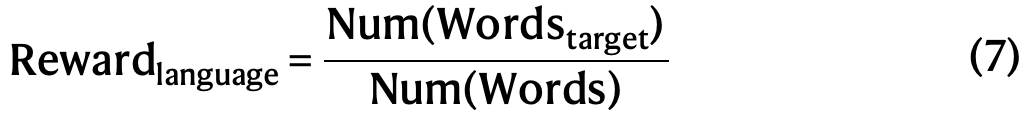
尽管补充信息第2.6节的消融实验表明这种对齐会导致模型性能轻微下降,但该奖励符合人类偏好,使其更具可读性。通过将其直接加到最终奖励中,将语言一致性奖励应用于推理和非推理数据。
请注意,裁剪比率在训练中起关键作用。较低值可能导致大量token的梯度被截断,从而降低模型性能;而较高值可能导致训练不稳定。本阶段使用的RL数据详情见补充信息第2.3节。
Training details of the second RL stage
本文结合奖励信号和多样化的提示分布来训练模型。对于推理数据,遵循DeepSeek-R1-Zero中的方法,使用基于规则的奖励指导数学、编程和逻辑推理领域的学习。在训练过程中,观察到思维链经常出现语言混合,尤其是在RL提示涉及多种语言时。对于通用数据,使用奖励模型指导训练。最终,奖励信号与多样化数据分布的整合使****本文 能够开发出一个不仅擅长推理,而且优先考虑有用性和无害性的模型。给定一批数据,奖励可公式化为:

其中
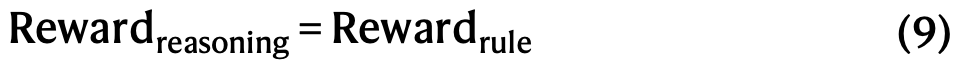

第二阶段RL保留了第一阶段的大部分参数,关键区别在于采样温度降至0.7(因发现此阶段较高温度会导致生成不连贯)。该阶段共包含1,700个训练步,其中通用指令数据和基于偏好的奖励仅在最后400步引入。本文发现使用基于模型的偏好奖励信号进行更多训练步可能导致奖励破解(见补充信息第2.5节)。