目录
[1.meta learning](#1.meta learning)
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是meta learning的基本概念和基本的训练过程
1.meta learning
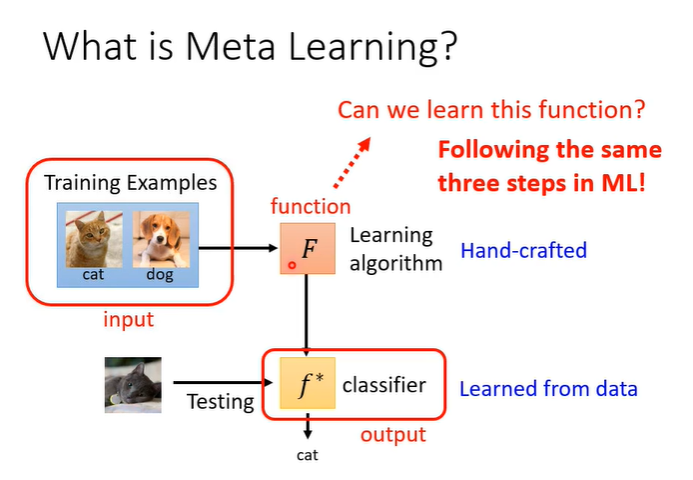
meta learning就是学习如何学习,首先复习一下machine learning,machine learning就是要找一个function,例如影像辨识,输入一张图片,输出是"猫"。一共三个步骤,第一是定义一个function,function有一些位置的参数。
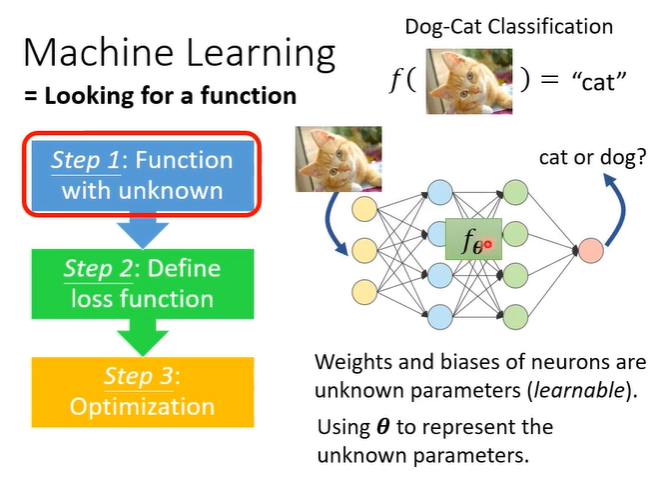
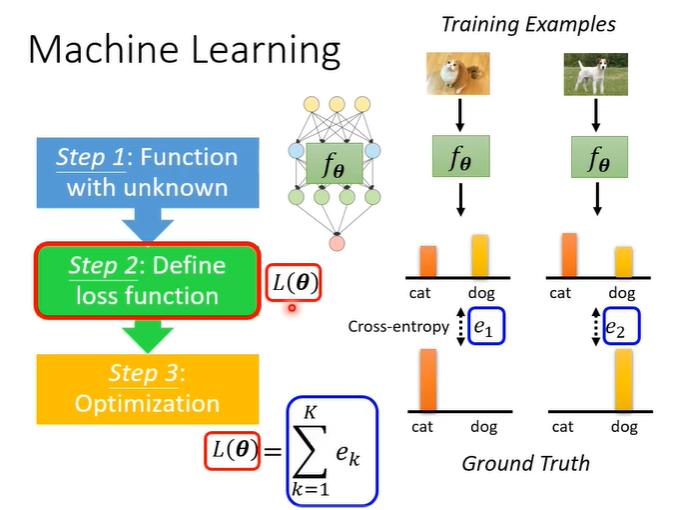
第二部是要定义一个loss function,它代表function的好坏。
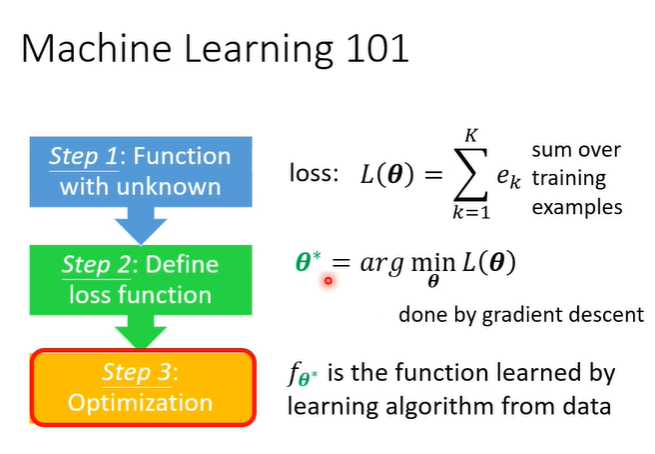
第三步,就是要找参数,这些参数使得loss function的值越小越好,常用gradient descent。
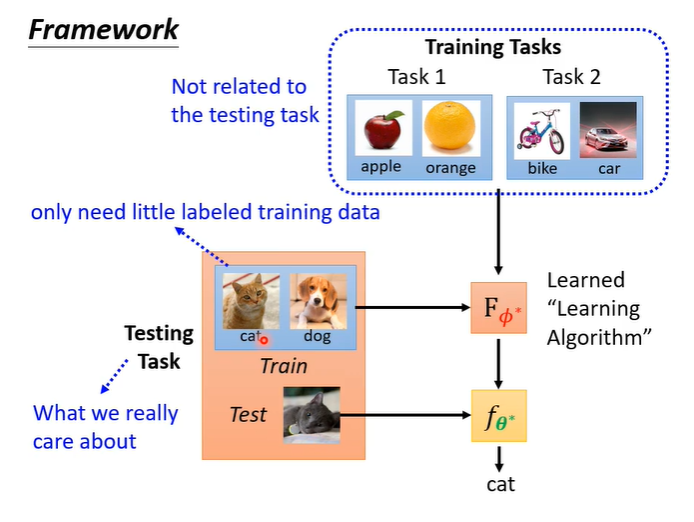
学习这件事,本身也是一个function,称为learning algorithm,假设训练的是一个classifier,把训练资料作为输入,输入函数F,输出一个classifier。 那么如何用与机器学习相同三个步骤去找这个函数F,就是meta learning。
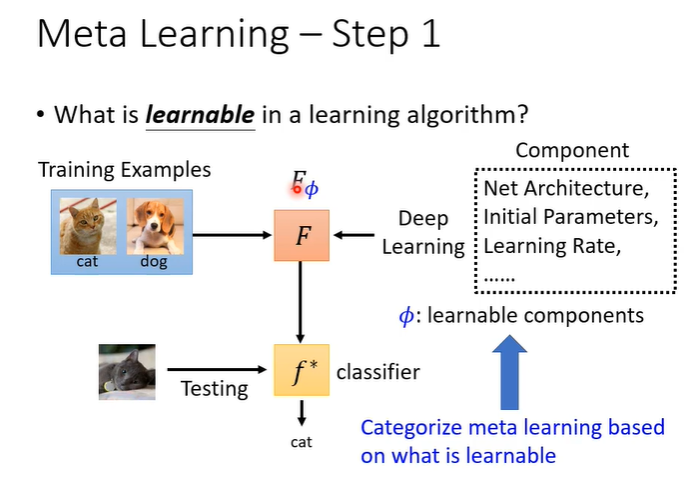
第一个步骤,在learning algorithm找到需要学习的东西(参数),称为,这些参数就是我们希望机器自己决定的东西。
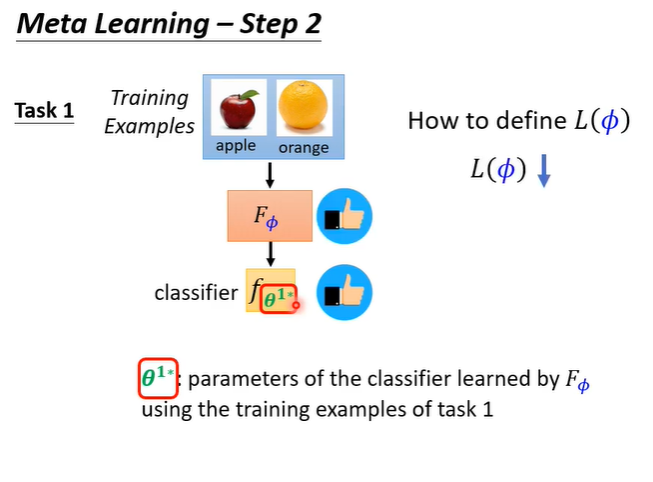
第二步,就是要定义loss function,记作,L一般来自于训练资料,在meta learning中收集的是训练的任务,假设想要训练一个二元分类器,就要准备很多二元分类的任务。

有了任务之后,判断F好不好的依据是,把任务拿出来给F学习看看得到classifier f1,如果f1是好的就代表F是好的,L就低。
如何判断f1好不好?就把f1跑在测试资料上,将结果与正确答案比较得到l1,l1代表f1的表现如何。l1的计算方法与机器学习很像,输入测试资料到f1,得到输出,计算输出与正确答案的corss entropy,把corss entropy都加起来即为l1。l越小代表f越好,就意味着F越好。
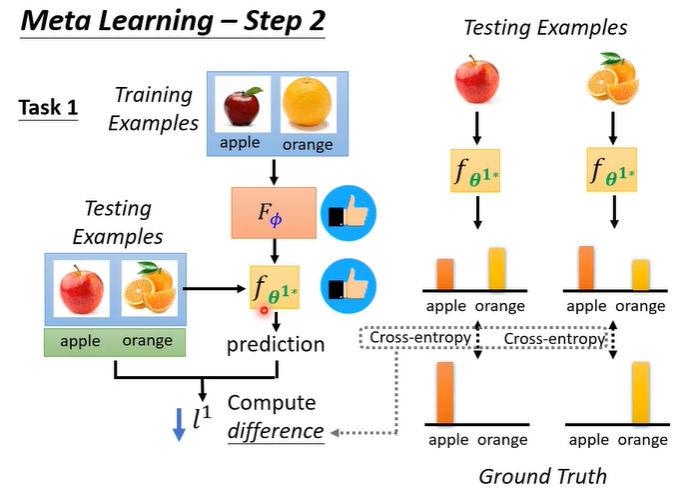
meta learning有很多的任务,所以不会只看一个任务,假设第二个二元分类器以同样的方式计算为l2,那么L就是l1+l2,即为所有任务的l的总和。
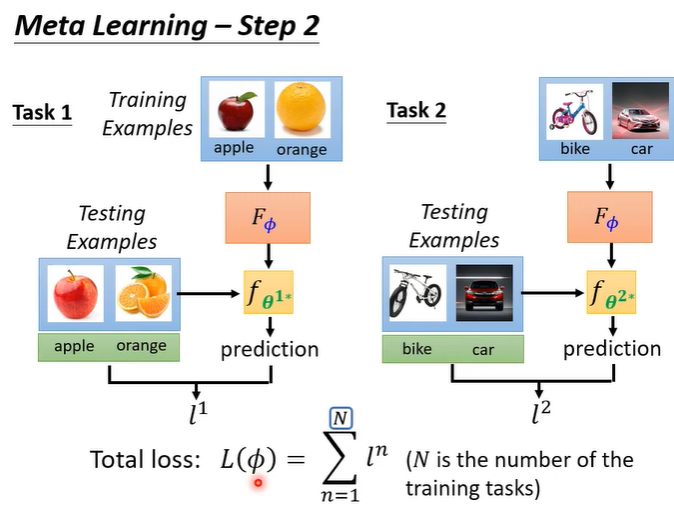
第三步,找一个让L越小越好。如果
是可以计算的,那么可以直接使用gradient descent的方法去寻找
;如果
是不可计算的,就用reinforce learning训练下去就能找到
。

整个meta learning的架构如下图,通过训练资料的任务得出了一个F,用测试资料的任务测试F是否能得出一个想要的classifier。