AutoDrive-R²引入了一个用于自动驾驶的视觉-语言-动作框架,通过增强推理和自我反思来生成准确、安全且物理可行的轨迹。它在nuScenes数据集上实现了0.19米的L2误差,在Waymo数据集的零样本设置中实现了0.20米的L2误差,以显著更少的训练数据超越了先前的专用模型。
概述
自动驾驶系统已从传统的模块化流水线发展到集成式端到端方法,其中视觉-语言-动作(VLA)模型代表了最新的进展。然而,当前自动驾驶中的 VLA 模型面临关键挑战:它们经常生成物理上不可行的轨迹,并且在复杂的驾驶场景中难以进行充分的推理。AutoDrive-R² 通过一个全面的框架解决了这些局限性,该框架增强了自动驾驶系统的推理能力和物理可行性。

图 1:AutoDrive-R² 框架概述,展示了完整的框架以及不同模型之间的比较结果,证明了在轨迹预测任务中的卓越性能。
方法论与框架
AutoDrive-R² 采用复杂的两阶段训练方法,结合了结构化推理和基于物理的优化。该框架通过系统地整合认知过程和物理约束,弥合了高级语义理解和低级物理控制之间的鸿沟。
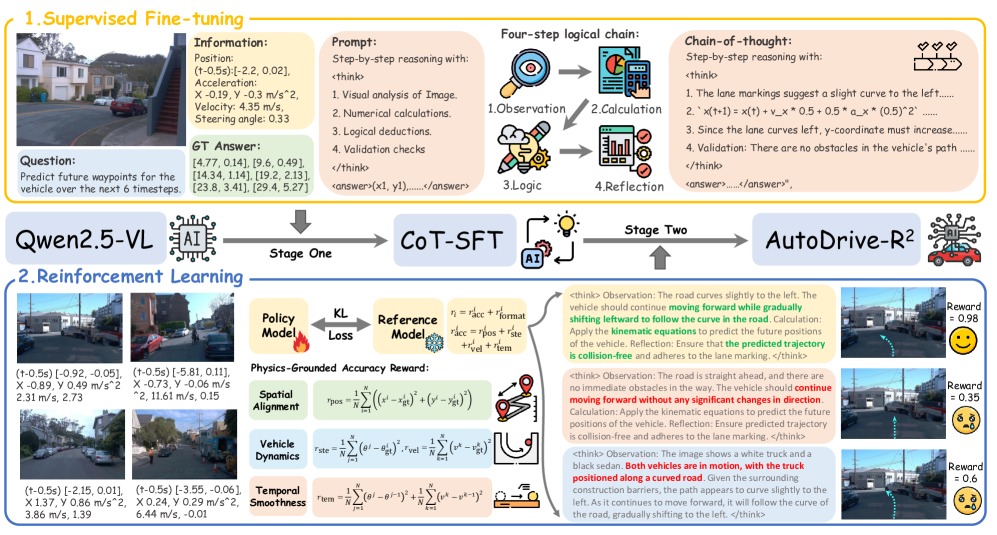
图 2:两阶段训练方法,展示了第一阶段(思维链监督微调)和第二阶段(基于物理奖励的强化学习)。
阶段 1:思维链监督微调
第一阶段通过创建和利用 nuScenesR²-6K 数据集建立了基础推理能力,该数据集是第一个专为自动驾驶 VLA 模型设计的思维链(CoT)数据集。该数据集包含从 nuScenes 训练集中手动标注的 6,000 对图像-轨迹对,并使用先进的 Qwen2.5-VL-72B 模型合成了详细的推理序列。
思维链(CoT)框架实现了带有自我反思的四步逻辑链:
- 图像驱动分析:建立场景理解,包括障碍物检测、车道定位和交通标志识别。
- 基于物理的计算:应用运动学方程,利用速度、加速度和位置计算将视觉观察转化为可量化的预测。
- 上下文逻辑合成:整合领域特定知识,如交通规则和先行权规定。
- 自我反思验证:一个关键步骤,模型验证推理的一致性并检查矛盾,从而实现"推理自我修正时刻"。
阶段 2:基于物理奖励的强化学习
第二阶段使用群组相对策略优化(GRPO)和全面的基于物理的奖励来优化模型。GRPO 通过成对比较机制简化了训练,消除了复杂的评论家网络,同时保持了优化效果。
基于物理的准确性奖励(r_acc)通过多个现实世界约束来评估轨迹质量:
- 空间对齐(r_pos):测量预测坐标和真实坐标之间的欧几里得距离。
- 车辆动力学 :
- 转向角一致性(r_ste)用于运动学可行性。
- 速度调节(r_vel)用于现实的加速模式。
- 时间平滑性(r_tem):通过惩罚转向和速度的快速变化来确保平稳运动。
总奖励结合了这些组成部分:
r_{acc} = r_{pos} + r_{ste} + r_{vel} + r_{tem}
实验结果与性能
AutoDrive-R² 在标准基准测试中表现出色,以卓越的数据效率取得了最先进的结果。在 nuScenes 数据集上,7B 模型实现了 0.19m 的平均 L2 误差,显著优于 EMMA+(0.29m)等专业模型和 Qwen2.5-VL-7B(1.45m)等通用 VLM。
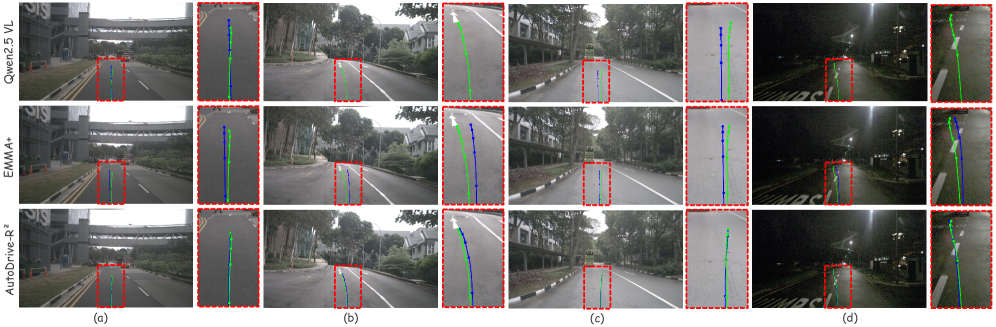
图3:不同场景下轨迹预测的视觉对比,展示了AutoDrive-R²相对于基线模型在精度和物理可行性方面的卓越表现。
该模型的泛化能力通过在Waymo数据集上的强大零样本性能得到验证,实现了0.20米的平均L2误差------比EMMA+提升33.3%,比Qwen2.5-VL-72B基线提升90.7%。这一性能仅使用了6,000个精心策划的CoT样本实现,而竞争对手使用了103,000多个场景,这凸显了其卓越的数据效率。
全面的消融研究验证了该框架的各个组件。两阶段训练方法被证明至关重要,因为纯RL训练的表现比SFT差22.2%。每个推理组件都贡献显著:移除四步结构会使误差增加31.5%,而取消自我反思则会导致性能下降21.1%。
推理能力和自我反思
AutoDrive-R²融入了复杂的推理机制,模仿了人类的决策过程。模型通过对驾驶场景的详细分析展示了显式推理,如定性示例所示。

图4:AutoDrive-R²成功推理过程的示例,展示了详细的逐步分析,从而生成适当的轨迹。
自我反思机制使模型能够识别并纠正其推理过程中潜在的错误。这种能力在模型必须平衡多重约束和安全考量的挑战性场景中尤为明显。

图5:模型自我纠正能力的演示,其中它识别了其初始推理中潜在的问题并进行相应调整。
推理过程将视觉分析与基于物理的计算和上下文逻辑相结合,确保轨迹预测不仅在几何上准确,而且符合交通法规和车辆动力学约束。

图6:复杂场景推理示例,展示了模型如何处理交通信号、行人、车辆动力学等多种因素。
独特贡献与意义
AutoDrive-R²对自动驾驶研究做出了几项独特的贡献。该框架引入了第一个专为自动驾驶VLA模型设计的思维链数据集,为在驾驶环境中训练推理能力建立了新范式。自我反思机制的系统集成代表着在开发更可解释和值得信赖的自动驾驶系统方面取得了重大进展。
基于物理的奖励系统通过空间对齐、车辆动力学和时间平滑度考量,全面解决了现实世界的约束。这种多方面的方法确保生成的轨迹不仅准确,而且在物理上可行并能为乘客提供舒适体验。
两阶段训练方法展示了如何将结构化推理与强化学习有效结合,以实现认知复杂性和实际性能。所取得的卓越数据效率------以比竞争对手少得多的训练样本获得最先进的结果------预示着一种更可持续的自动驾驶系统开发方法。
该框架强大的泛化能力,由其在不同数据集上表现出的鲁棒零样本性能所证明,表明了其广泛的应用潜力。显式推理和自我反思机制增强了系统可解释性,解决了安全关键的自动驾驶应用中关键的信任和验证需求。
这项研究为自动驾驶AI的未来发展奠定了基础,展示了如何将先进的推理能力与物理约束系统地结合起来,以创建更可靠、可解释并最终可部署的自动驾驶系统。