人脸识别
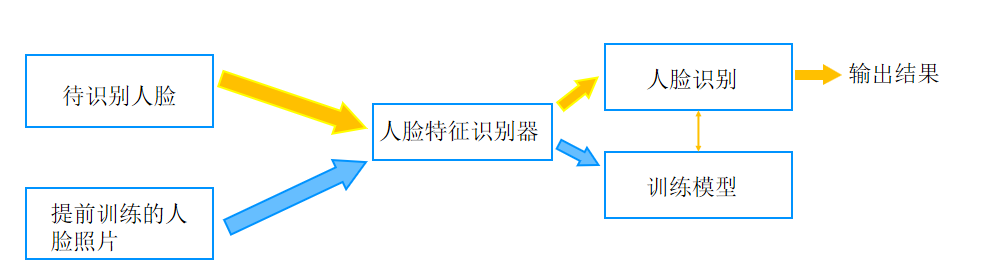
特征识别器
Opencv提供了三种用于识别人脸的特征提取算法。分别是 LBPH 算法、EigenFaces 算法、FisherFaces 算法。
人脸识别-- LBPH 算法
LBPH(Local Binary Patterns Histogram,局部二值模式直方图)算法使用的模型基于LBP(Local Binary Pattern,局部二值模式)算法。LBP 算法最早是被作为一种有效的纹理描述算提出的,因在表述图像局部纹理特征方面效果出众而得到广泛应用。
代码
python
import cv2
import numpy as np
# 提前训练的人脸照片
images=[]
images.append(cv2.imread('hg1.png',cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('hg2.png',cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('pyy1.png',cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('pyy2.png',cv2.IMREAD_GRAYSCALE))
labels=[0,0,1,1]
dic={0:'hg',1:'pyy',-1:'无法识别'}
predict_image=cv2.imread('hg.png',cv2.IMREAD_GRAYSCALE) # 待识别人脸
# cv2.face.LBPHFaceRecognizer_create(radius=None, neighbors=None, grid_x=None, grid_y=None, threshold=None)
# 功能:创建一个LBPH的人脸特征识别器
# radius:可选参数 圆形局部二进制模式的半径,建议使用默认值
# neighbors:可选参数,圆形局部二进制模式的采样点数目,建议使用默认值
# grid_x:可选参数 水平方向上的的单元格数,默认值为8,即将LBP特征图在水平方向上划分为8个单元。
# grid_y:可选参数 垂直方向上的的单元格数,默认值为8,建议使用默认值,若grid_x和grid_y都为默认值
# 则表示特征图划分为8*8大小,统计8*8大小的直方图。
# threshold:可选参数 人脸识别时使用的阈值,建议使用默认值
recognizer=cv2.face.LBPHFaceRecognizer_create(threshold=80)
# 函数train用给定的数据和相关标签训练生成的实例模型。该函数的语法格式为
# None = 识别器对象.train( src, labels )
# 其中,各参数的含义如下:
# 。src: 训练图像,用来学习的人脸图像
# 。labels: 标签,人脸图像对应的标签。
recognizer.train(images,np.array(labels))
#函数predict()对一个待识别人脸图像进行判断,寻找与当前图像距离最近的人脸图像。
# 与哪幅人脸图像距离最近,就将当前待测图像标注为该人脸图像对应的标签。
# 若待识别人脸图像与所有人脸图像的距离都大于特定的距离值(阈值),则认为没有找到对应的结果,
# 参数与返回值的含义如下:
# ·src: 需要识别的人脸图像
# label: 返回的识别结果标签,返回-1表示无法识别当前人脸。
# confidence: 返回的置信度评分,用来衡量识别结果与原有模型之间的距离,
# 评分越小表示匹配越高,但是若高于80,则认为识别结果与原有模型差距大。
label,confidence=recognizer.predict(predict_image)
print('这人是:',dic[label])
print('置信度:',confidence)逻辑
- 数据准备 :
- 加载训练图像:
python
python
images = []
images.append(cv2.imread('hg1.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('hg2.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('pyy1.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('pyy2.png', cv2.IMREAD_GRAYSCALE))从文件中读取了四张灰度图像,分别命名为hg1.png、hg2.png、pyy1.png和pyy2.png,并将它们添加到images列表中。这些图像将用于训练人脸识别模型。
- 定义标签:
python
python
labels = [0, 0, 1, 1]为上述加载的图像定义对应的标签。标签0对应hg的图像,标签1对应pyy的图像。
- 定义标签字典:
python
python
dic = {0: 'hg', 1: 'pyy', -1: '无法识别'}创建一个字典dic,用于将模型预测的标签转换为对应的人名或 "无法识别" 的提示。
- 加载待识别图像:
python
python
predict_image = cv2.imread('hg.png', cv2.IMREAD_GRAYSCALE)读取名为hg.png的灰度图像,这是待识别的人脸图像。
- 模型创建与训练 :
- 创建 LBPH 人脸识别器:
python
python
recognizer = cv2.face.LBPHFaceRecognizer_create(threshold = 80)使用cv2.face.LBPHFaceRecognizer_create函数创建一个 LBPH 人脸识别器对象recognizer,并设置阈值为 80。阈值用于判断识别结果的置信度,如果预测的置信度高于此阈值,则认为识别结果与原有模型差距大。
- 训练模型:
python
python
recognizer.train(images, np.array(labels))调用recognizer的train方法,使用之前加载的训练图像images和对应的标签labels(转换为numpy数组)对模型进行训练。
- 模型预测与结果输出 :
- 进行预测:
python
python
label, confidence = recognizer.predict(predict_image)调用recognizer的predict方法,对待识别图像predict_image进行预测。该方法返回预测的标签label和置信度评分confidence。
- 输出结果:
python
python
print('这人是:', dic[label])
print('置信度:', confidence)根据预测的标签label,从字典dic中获取对应的人名或 "无法识别" 的提示并打印。同时打印预测的置信度评分confidence,该值越小表示匹配越高。
LBPH 实现步骤
1、以每个像素为中心,判断与周围像素灰度值大小关系,对其进行二进制编码,从而获得整幅图像的LBP编码图像;
2、再将LBP图像分为n个区域,获取每个区域的LBP编码直方图,继而得到整幅图像的LBP编码直方图。 通过比较不同人脸图像LBP编码直方图达到人脸识别的目的,其优点是不会受到光照、缩放、旋转和平移的影响。
步骤1: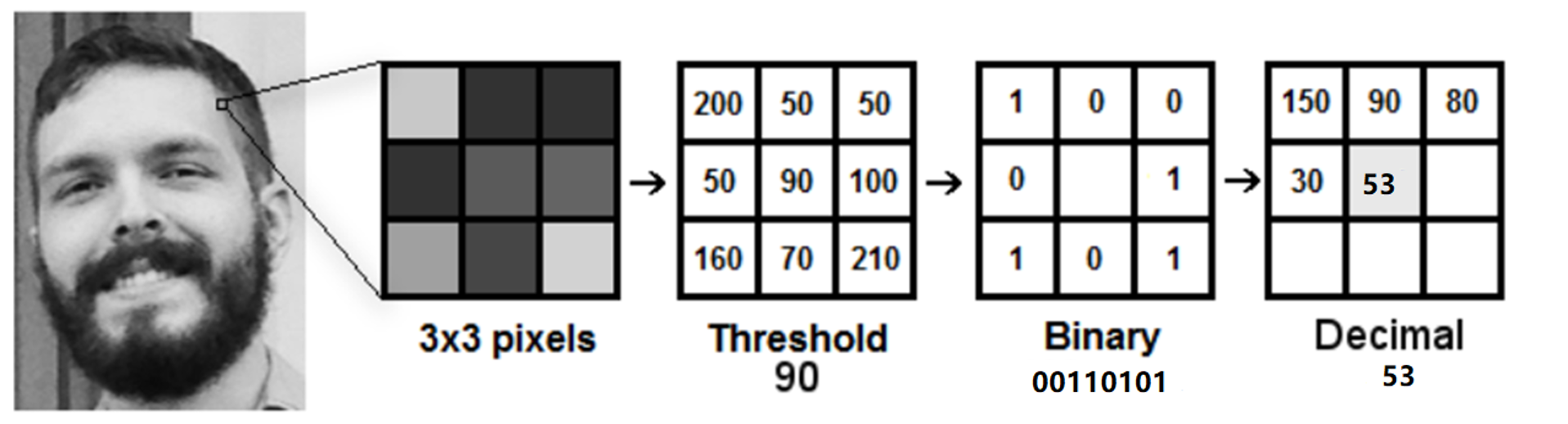
步骤1:缩放
为了得到不同尺度下的纹理结构,可以使用圆形邻域,将计算扩大到任意大小的邻域内。圆形邻域可以用(P,R)表示,其中,P表示圆形邻域内参与运算的像素点个数,R 表示圆形邻域的半径。
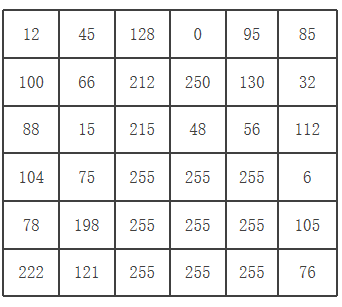
步骤1:
旋转和平移
1、将中心点像素作为圆心,将周围的像素点按照顺时针方向依次移动一个位置。 2、再计算所有图像的LBP值,取其中最小值作为最终的值
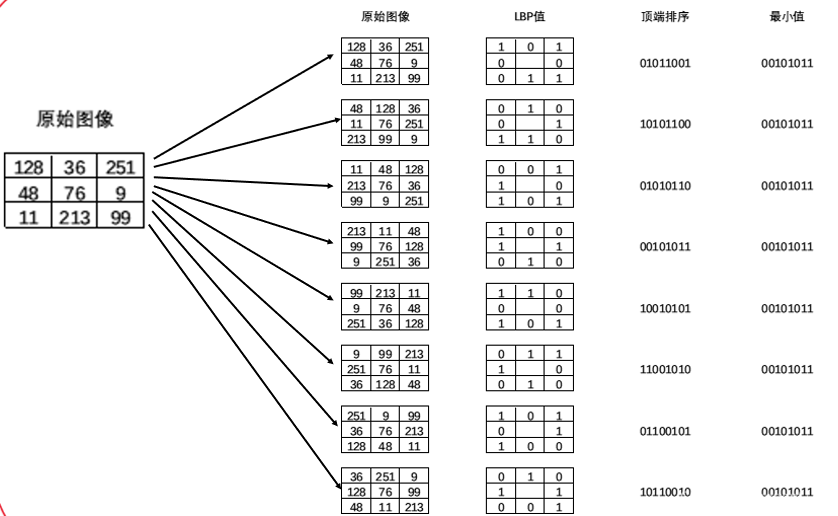
步骤2:
将LBP图像分为个n区域,获取每个区域的LBP编码直方
图,继而得到整幅图像的LBP编码直方图。
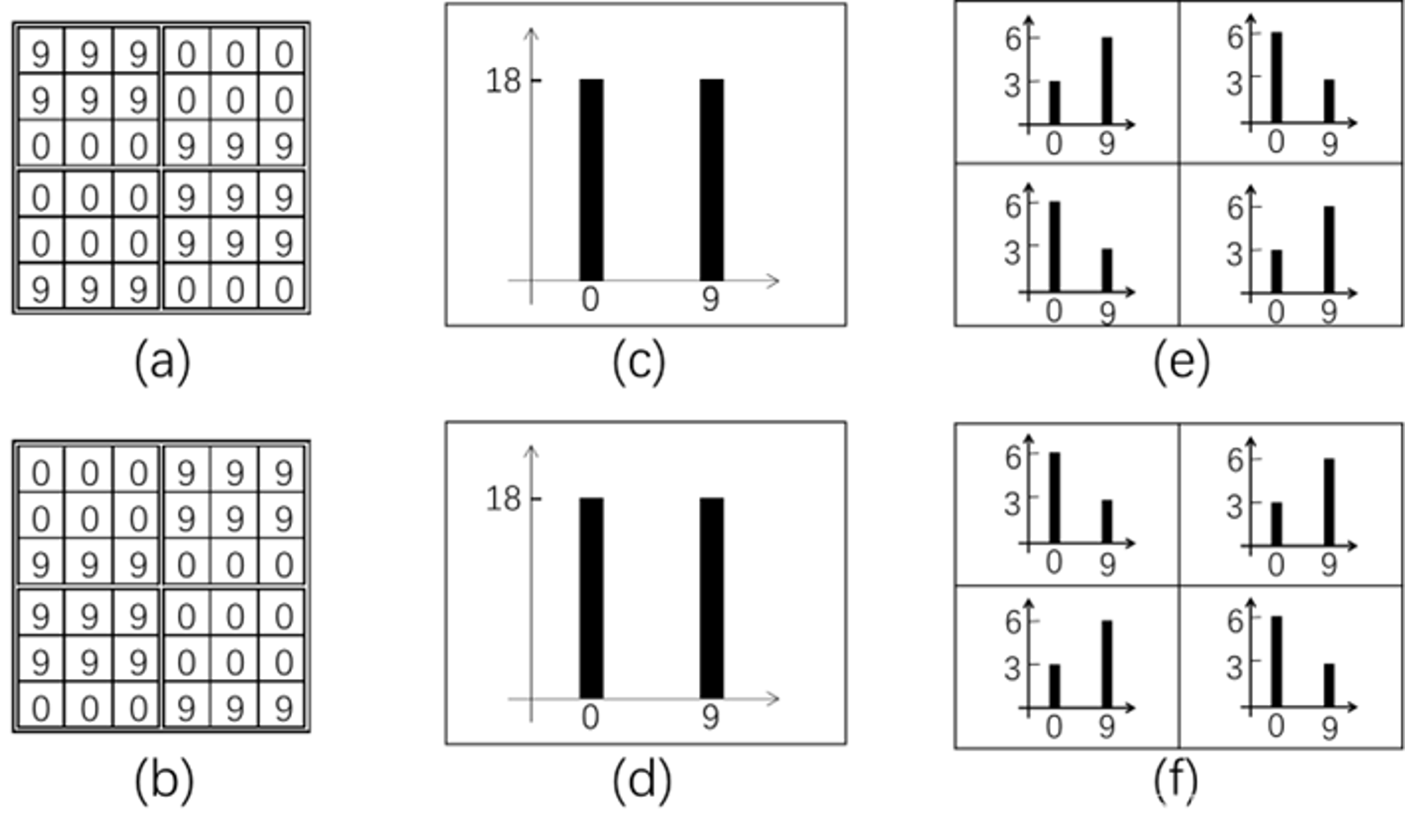
LBP特征与Haar特征很相似,都是图像的灰度变化特征。
EigenFaces算法
Eigenfaces是在人脸识别的计算机视觉问题中使用的一组特征向量的名称,Eigenfaces是基于PCA(主成分分析)算法实现的。
PCA(主成分分析)算法
主成分分析(PCA)是一种矩阵的压缩算法,在减少矩阵维数的同时尽可能的保留原矩阵的信息,简单来说就是将 n×m的矩阵转换成n×k的矩阵,仅保留矩阵中所存在的主要特性,从而可以大大节省空间和数据量。
代码
python
import cv2
import numpy as np
images=[] # 读取训练图像, 注意:图片大小需要一致
a=cv2.imread('hg1.png',0)
a=cv2.resize(a,(120,180))
b=cv2.imread('hg2.png',0)
b=cv2.resize(b,(120,180))
c=cv2.imread('pyy1.png',0)
c=cv2.resize(c,(120,180))
d=cv2.imread('pyy2.png',0)
d=cv2.resize(d,(120,180))
images.append(a)
images.append(b)
images.append(c)
images.append(d)
# images.append(cv2.imread('hg1.png',0))
# images.append(cv2.imread('hg2.png',0))
# images.append(cv2.imread('pyy1.png',0))
# images.append(cv2.imread('pyy2.png',0))
labels=[0,0,1,1]
pre_image=cv2.imread('hg.png',0)
pre_image=cv2.resize(pre_image,(120,180))
# 创建Eigenfaces人脸识别器
# cv2.face.EigenFaceRecognizer_create(num_components=None, threshold=None)
# 作用:创建一个EigenFace的人脸特征识别器
# num_components:在PCA中要保留的分量个数。当然,该参数值通常要根据输入数据来具体确定,
# 并没有一定取值。一般程序中,取80即可 (降维成多少个特征)
# threshold:进行人脸识别所采用的阈值
recognizer = cv2.face.EigenFaceRecognizer_create() # threshold=5000 4000
# 使用训练数据(images和labels)来训练识别器
# 函数FaceRecognizertrain用给定的数据和相关标签训练生成的实例模型。该函数的语法格式为
#None = cv2.faceFaceRecognizer.train(src, labels )
#参数的含义如下:
# src: 训练图像,用来学习的人脸图像
# labels: 标签,人脸图像对应的标签。
recognizer.train(images, np.array(labels))
# 对预测图像(pre_image)进行人脸识别预测
# confidence:大小介于0到20000,只要低于5000都被认为是可靠的结果。
label,confidence = recognizer.predict(pre_image)
dic={0:'hg',1:'pyy'}
print('这人是:',dic[label])
print('置信度为:',confidence)
aa=cv2.putText(cv2.imread('hg.png').copy(),dic[label],(10,30),cv2.FONT_HERSHEY_SIMPLEX,
0.9,(0,0,255),2)
cv2.imshow('xx',aa)
cv2.waitKey(0)逻辑
-
代码功能概述这段代码实现了基于 Eigenfaces 算法的人脸识别。它首先读取一系列训练图像,对其进行尺寸调整,然后使用这些图像训练 Eigenfaces 人脸识别器,最后对待识别图像进行预测,并在图像上标注识别结果并显示。
-
代码详细分析
- 训练图像读取与预处理
python
python
images = []
a = cv2.imread('hg1.png', 0)
a = cv2.resize(a, (120, 180))
b = cv2.imread('hg2.png', 0)
b = cv2.resize(b, (120, 180))
c = cv2.imread('pyy1.png', 0)
c = cv2.resize(c, (120, 180))
d = cv2.imread('pyy2.png', 0)
d = cv2.resize(d, (120, 180))
images.append(a)
images.append(b)
images.append(c)
images.append(d)创建一个空列表images用于存储训练图像。依次读取四张灰度图像hg1.png、hg2.png、pyy1.png和pyy2.png,并使用cv2.resize函数将它们调整为相同大小(120x180 像素),然后添加到images列表中。这样做是为了确保训练图像在特征提取和模型训练时具有一致的尺寸。
- 定义标签
python
python
labels = [0, 0, 1, 1]为训练图像定义对应的标签。这里0代表hg相关的图像,1代表pyy相关的图像。这些标签将用于训练模型,使模型能够学习到不同图像所对应的身份信息。
- 待识别图像读取与预处理
python
python
pre_image = cv2.imread('hg.png', 0)
pre_image = cv2.resize(pre_image, (120, 180))读取待识别的灰度图像hg.png,同样使用cv2.resize函数将其调整为与训练图像相同的尺寸(120x180 像素)。这一步确保待识别图像与训练图像在格式上一致,以便输入到训练好的模型中进行预测。
- 创建并训练 Eigenfaces 人脸识别器
python
python
recognizer = cv2.face.EigenFaceRecognizer_create()
recognizer.train(images, np.array(labels))使用cv2.face.EigenFaceRecognizer_create()创建一个 Eigenfaces 人脸识别器对象recognizer,这里未指定num_components和threshold参数,采用默认值。然后调用recognizer的train方法,将训练图像images和对应的标签labels(转换为numpy数组)作为参数传入,训练人脸识别模型。在训练过程中,模型会学习到不同人脸图像的特征模式与标签之间的映射关系。
- 进行人脸识别预测
python
python
label, confidence = recognizer.predict(pre_image)调用recognizer的predict方法,将待识别图像pre_image作为参数传入进行预测。该方法返回预测的标签label和置信度confidence。预测过程中,模型会将待识别图像的特征与训练过程中学习到的特征模式进行比较,找出最匹配的标签,并给出一个置信度分数,用于衡量匹配的可靠性。
- 输出识别结果
python
python
dic = {0: 'hg', 1: 'pyy'}
print('这人是:', dic[label])
print('置信度为:', confidence)创建一个字典dic,将标签0映射为hg,标签1映射为pyy。根据预测得到的标签label,从字典dic中获取对应的人名并打印,同时打印预测的置信度confidence。置信度大小介于 0 到 20000,一般低于 5000 被认为是可靠的结果,通过打印置信度可以让用户了解识别结果的可靠性。
- 在图像上标注并显示结果
python
python
aa = cv2.putText(cv2.imread('hg.png').copy(), dic[label], (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
0.9, (0, 0, 255), 2)
cv2.imshow('xx', aa)
cv2.waitKey(0)首先使用cv2.imread('hg.png').copy()读取原始待识别彩色图像并复制一份,避免对原图像造成修改。然后使用cv2.putText函数在图像上添加识别结果标签,位置为 (10, 30),字体为cv2.FONT_HERSHEY_SIMPLEX,字体大小为 0.9,颜色为红色(0, 0, 255),线宽为 2。最后通过cv2.imshow显示标注后的图像,并使用cv2.waitKey(0)等待用户按键关闭窗口。
FisherFaces算法
PCA方法是EigenFaces人脸识别的核心,但是其具有明显的缺点,在操作过程中会损失许多人脸的特征信息。因此在某些特殊的情况下,如果损失的信息刚好是用于分类的关键信息,必然导致结果预测错误。
FisherFaces算法
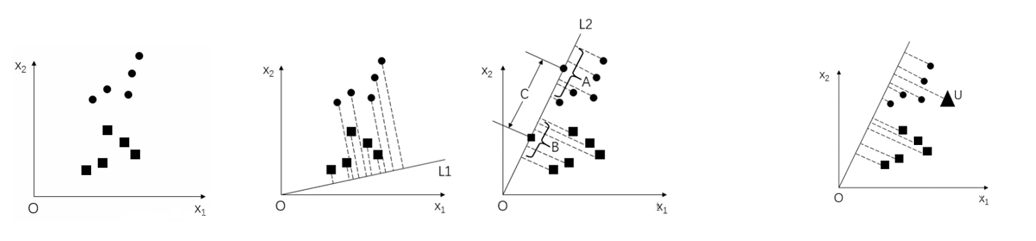
Fisherfaces采用LDA(Linear Discriminant Analysis,线性判别分析)实现人脸识别。
其基本原理:在低维表示下,首先将训练集样本集投影到一条直线A上,让投影后的点满足:
同类间的点尽可能地靠近
异类间的点尽可能地远离
代码
python
import cv2
import numpy as np
def image_re(image):
a=cv2.imread(image,0)
a=cv2.resize(a,(120,180))
return a
images=[]
a=image_re('hg1.png')
b=image_re('hg2.png')
c=image_re('pyy1.png')
d=image_re('pyy2.png')
images.append(a)
images.append(b)
images.append(c)
images.append(d)
labels=[0,0,1,1]
pre_image=image_re('hg.png')# 读取待识别图像
# cv2.face.FisherFaceRecognizer_create( [, num_components[, threshold]] )
# 作用:创建一个FisherFace的人脸特征识别器
# num_components:进行线性判别分析时保留的成分数量。可以采用默认值"0",让函数自动设置合适的成分数量。
# threshold:进行识别时所用的阈值。如果最近的距离比设定的阈值threshold还要大,函数会返回"-1"。
recognizer=cv2.face.FisherFaceRecognizer_create()
# 函数FaceRecognizertrain用给定的数据和相关标签训练生成的实例模型。该函数的语法格式为
# None = cv2.faceFaceRecognizer.train(src, labels )
#参数的含义如下:
# src: 训练图像,用来学习的人脸图像
# labels: 标签,人脸图像对应的标签。
recognizer.train(images,np.array(labels))
# confidence:大小介于0到20000,只要低于5000都被认为是可靠的结果。
label,confidence=recognizer.predict(pre_image)
dic={0:'hg',1:'pyy'}
print('这人是:',dic[label])
print('置信度为:',confidence)
aa=cv2.putText(cv2.imread('hg.png').copy(),dic[label],(10,30),cv2.FONT_HERSHEY_SIMPLEX,
0.9,(0,0,255),2)
cv2.imshow('xx',aa)
cv2.waitKey(0)逻辑
- 定义标签
python
python
labels = [0, 0, 1, 1]为训练图像定义对应的标签。这里0代表hg相关的图像,1代表pyy相关的图像。这些标签将用于训练模型,使模型能够学习到不同图像所对应的身份信息。
- 待识别图像读取与预处理
python
python
pre_image = cv2.imread('hg.png', 0)
pre_image = cv2.resize(pre_image, (120, 180))读取待识别的灰度图像hg.png,同样使用cv2.resize函数将其调整为与训练图像相同的尺寸(120x180 像素)。这一步确保待识别图像与训练图像在格式上一致,以便输入到训练好的模型中进行预测。
- 创建并训练 Eigenfaces 人脸识别器
python
python
recognizer = cv2.face.EigenFaceRecognizer_create()
recognizer.train(images, np.array(labels))使用cv2.face.EigenFaceRecognizer_create()创建一个 Eigenfaces 人脸识别器对象recognizer,这里未指定num_components和threshold参数,采用默认值。然后调用recognizer的train方法,将训练图像images和对应的标签labels(转换为numpy数组)作为参数传入,训练人脸识别模型。在训练过程中,模型会学习到不同人脸图像的特征模式与标签之间的映射关系。
- 进行人脸识别预测
python
python
label, confidence = recognizer.predict(pre_image)调用recognizer的predict方法,将待识别图像pre_image作为参数传入进行预测。该方法返回预测的标签label和置信度confidence。预测过程中,模型会将待识别图像的特征与训练过程中学习到的特征模式进行比较,找出最匹配的标签,并给出一个置信度分数,用于衡量匹配的可靠性。
- 输出识别结果
python
python
dic = {0: 'hg', 1: 'pyy'}
print('这人是:', dic[label])
print('置信度为:', confidence)创建一个字典dic,将标签0映射为hg,标签1映射为pyy。根据预测得到的标签label,从字典dic中获取对应的人名并打印,同时打印预测的置信度confidence。置信度大小介于 0 到 20000,一般低于 5000 被认为是可靠的结果,通过打印置信度可以让用户了解识别结果的可靠性。
- 在图像上标注并显示结果
python
python
aa = cv2.putText(cv2.imread('hg.png').copy(), dic[label], (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
0.9, (0, 0, 255), 2)
cv2.imshow('xx', aa)
cv2.waitKey(0)首先使用cv2.imread('hg.png').copy()读取原始待识别彩色图像并复制一份,避免对原图像造成修改。然后使用cv2.putText函数在图像上添加识别结果标签,位置为 (10, 30),字体为cv2.FONT_HERSHEY_SIMPLEX,字体大小为 0.9,颜色为红色(0, 0, 255),线宽为 2。最后通过cv2.imshow显示标注后的图像,并使用cv2.waitKey(0)等待用户按键关闭窗口。
首先使用cv2.imread('hg.png').copy()读取原始待识别彩色图像并复制一份,避免对原图像造成修改。然后使用cv2.putText函数在图像上添加识别结果标签,位置为 (10, 30),字体为cv2.FONT_HERSHEY_SIMPLEX,字体大小为 0.9,颜色为红色(0, 0, 255),线宽为 2。最后通过cv2.imshow显示标注后的图像,并使用cv2.waitKey(0)等待用户按键关闭窗口。
FisherFaces算法
PCA方法是EigenFaces人脸识别的核心,但是其具有明显的缺点,在操作过程中会损失许多人脸的特征信息。因此在某些特殊的情况下,如果损失的信息刚好是用于分类的关键信息,必然导致结果预测错误。
FisherFaces算法
Fisherfaces采用LDA(Linear Discriminant Analysis,线性判别分析)实现人脸识别。
其基本原理:在低维表示下,首先将训练集样本集投影到一条直线A上,让投影后的点满足:
同类间的点尽可能地靠近
异类间的点尽可能地远离
代码
python
import cv2
import numpy as np
def image_re(image):
a=cv2.imread(image,0)
a=cv2.resize(a,(120,180))
return a
images=[]
a=image_re('hg1.png')
b=image_re('hg2.png')
c=image_re('pyy1.png')
d=image_re('pyy2.png')
images.append(a)
images.append(b)
images.append(c)
images.append(d)
labels=[0,0,1,1]
pre_image=image_re('hg.png')# 读取待识别图像
# cv2.face.FisherFaceRecognizer_create( [, num_components[, threshold]] )
# 作用:创建一个FisherFace的人脸特征识别器
# num_components:进行线性判别分析时保留的成分数量。可以采用默认值"0",让函数自动设置合适的成分数量。
# threshold:进行识别时所用的阈值。如果最近的距离比设定的阈值threshold还要大,函数会返回"-1"。
recognizer=cv2.face.FisherFaceRecognizer_create()
# 函数FaceRecognizertrain用给定的数据和相关标签训练生成的实例模型。该函数的语法格式为
# None = cv2.faceFaceRecognizer.train(src, labels )
#参数的含义如下:
# src: 训练图像,用来学习的人脸图像
# labels: 标签,人脸图像对应的标签。
recognizer.train(images,np.array(labels))
# confidence:大小介于0到20000,只要低于5000都被认为是可靠的结果。
label,confidence=recognizer.predict(pre_image)
dic={0:'hg',1:'pyy'}
print('这人是:',dic[label])
print('置信度为:',confidence)
aa=cv2.putText(cv2.imread('hg.png').copy(),dic[label],(10,30),cv2.FONT_HERSHEY_SIMPLEX,
0.9,(0,0,255),2)
cv2.imshow('xx',aa)
cv2.waitKey(0)逻辑
- 定义标签
python
python
labels = [0, 0, 1, 1]为训练图像定义对应的标签。这里0代表hg相关的图像,1代表pyy相关的图像。这些标签将用于训练模型,使模型能够学习到不同图像所对应的身份信息。
- 待识别图像读取与预处理
python
python
pre_image = cv2.imread('hg.png', 0)
pre_image = cv2.resize(pre_image, (120, 180))读取待识别的灰度图像hg.png,同样使用cv2.resize函数将其调整为与训练图像相同的尺寸(120x180 像素)。这一步确保待识别图像与训练图像在格式上一致,以便输入到训练好的模型中进行预测。
- 创建并训练 Eigenfaces 人脸识别器
python
python
recognizer = cv2.face.EigenFaceRecognizer_create()
recognizer.train(images, np.array(labels))使用cv2.face.EigenFaceRecognizer_create()创建一个 Eigenfaces 人脸识别器对象recognizer,这里未指定num_components和threshold参数,采用默认值。然后调用recognizer的train方法,将训练图像images和对应的标签labels(转换为numpy数组)作为参数传入,训练人脸识别模型。在训练过程中,模型会学习到不同人脸图像的特征模式与标签之间的映射关系。
- 进行人脸识别预测
python
python
label, confidence = recognizer.predict(pre_image)调用recognizer的predict方法,将待识别图像pre_image作为参数传入进行预测。该方法返回预测的标签label和置信度confidence。预测过程中,模型会将待识别图像的特征与训练过程中学习到的特征模式进行比较,找出最匹配的标签,并给出一个置信度分数,用于衡量匹配的可靠性。
- 输出识别结果
python
python
dic = {0: 'hg', 1: 'pyy'}
print('这人是:', dic[label])
print('置信度为:', confidence)创建一个字典dic,将标签0映射为hg,标签1映射为pyy。根据预测得到的标签label,从字典dic中获取对应的人名并打印,同时打印预测的置信度confidence。置信度大小介于 0 到 20000,一般低于 5000 被认为是可靠的结果,通过打印置信度可以让用户了解识别结果的可靠性。
- 在图像上标注并显示结果
python
python
aa = cv2.putText(cv2.imread('hg.png').copy(), dic[label], (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
0.9, (0, 0, 255), 2)
cv2.imshow('xx', aa)
cv2.waitKey(0)首先使用cv2.imread('hg.png').copy()读取原始待识别彩色图像并复制一份,避免对原图像造成修改。然后使用cv2.putText函数在图像上添加识别结果标签,位置为 (10, 30),字体为cv2.FONT_HERSHEY_SIMPLEX,字体大小为 0.9,颜色为红色(0, 0, 255),线宽为 2。最后通过cv2.imshow显示标注后的图像,并使用cv2.waitKey(0)等待用户按键关闭窗口。