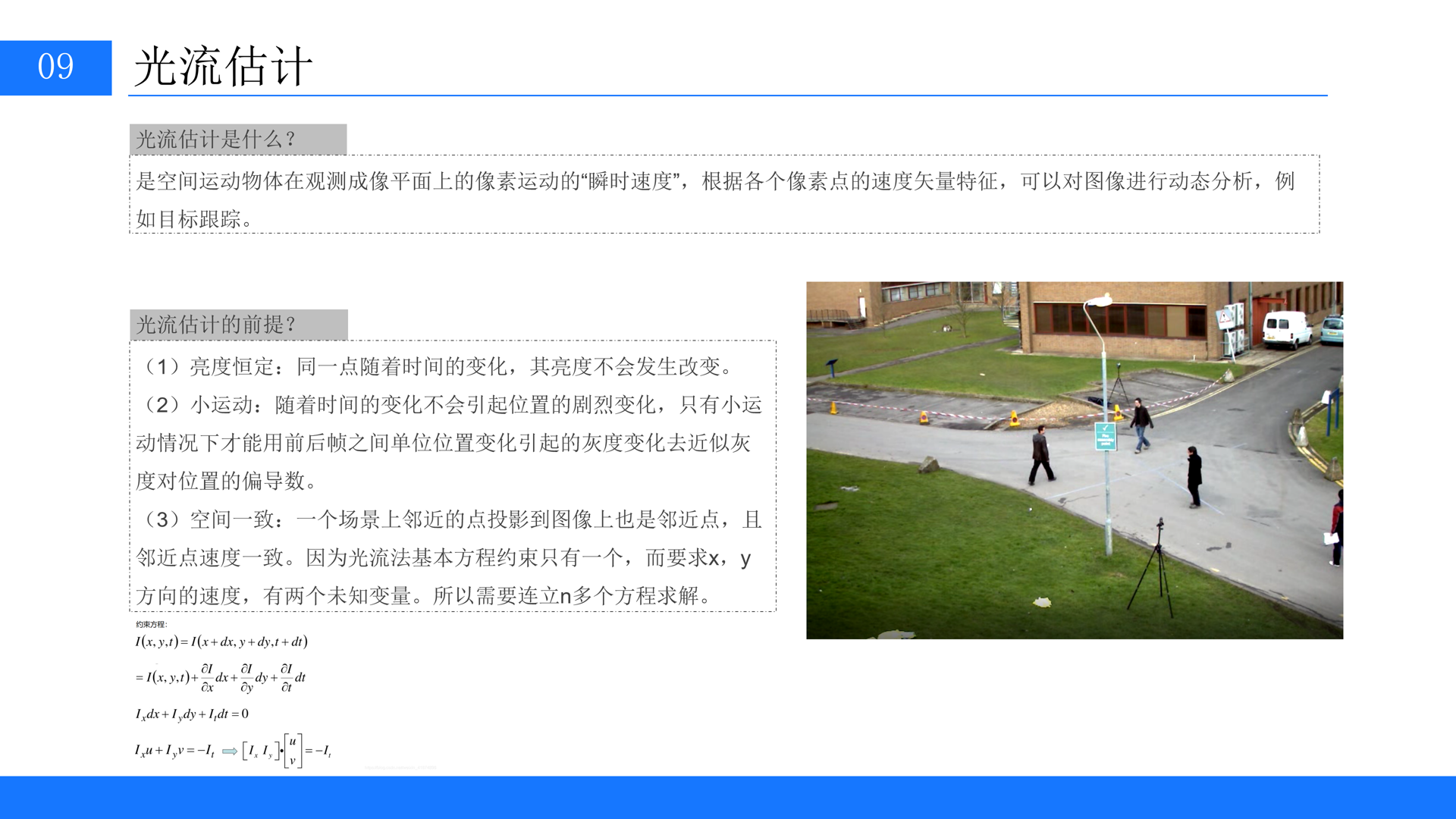
先讲解下什么是光流估计
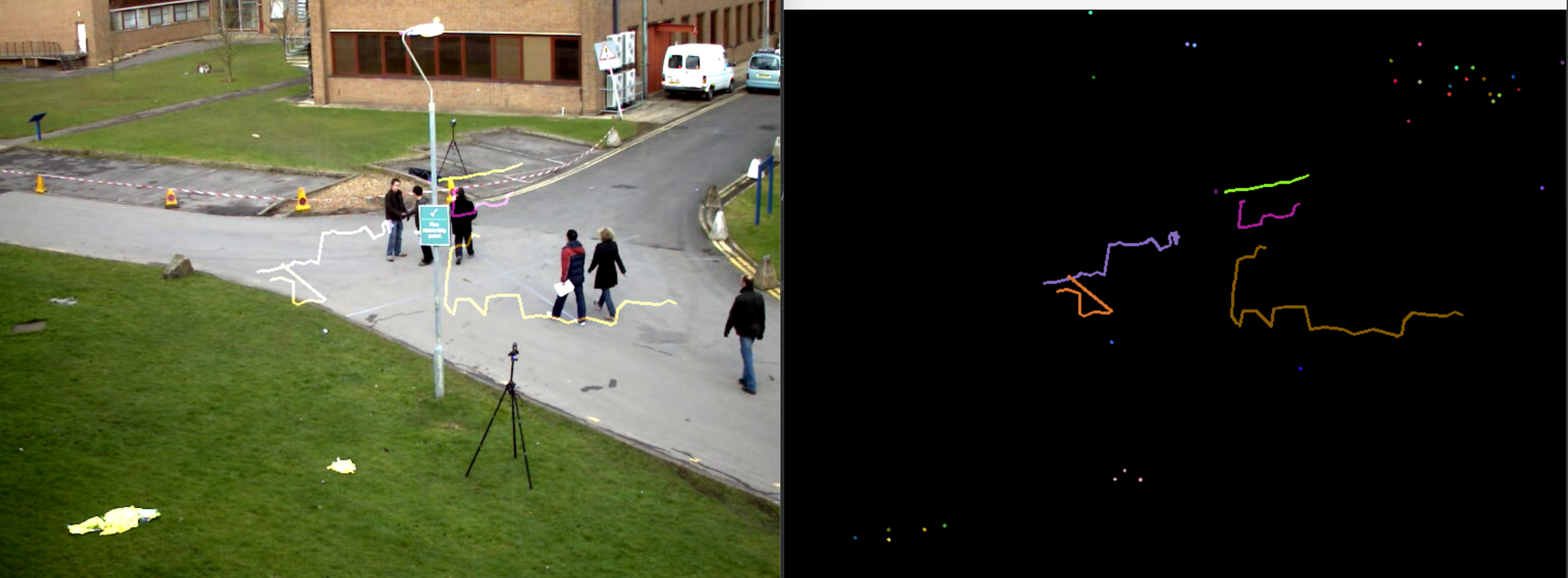
结果展示
代码部分
import numpy as np
import cv2
# 打开视频文件
cap = cv2.VideoCapture('test.avi')
# 随机生成颜色,用于绘制轨迹
color = np.random.randint(0, 255, (100, 3))
# 读取视频的第一帧
ret, old_frame = cap.read()
# 将第一帧转换为灰度图像
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# 定义特征点检测参数
feature_params = dict(maxCorners=100, # 最大角点数量
qualityLevel=0.3, # 角点质量的阈值
minDistance=7) # 最小距离,用于分散角点
# 使用角点检测方法找到特征点
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None,** feature_params)
# 创建一个与当前帧大小相同的全零掩模,用于绘制轨迹
mask = np.zeros_like(old_frame)
# 定义Lucas-Kanade光流参数
lk_params = dict(winSize=(15, 15), # 窗口大小
maxLevel=2) # 金字塔层数
# 主循环,处理视频的每一帧
while True:
# 读取下一帧
ret, frame = cap.read()
# 检查是否成功读取到帧
if not ret:
break
# 将当前帧转换为灰度图像
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流,获取新的特征点位置和状态
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, ** lk_params)
# 选择好的点(状态为1的点)
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel() # 获取新点的坐标
c, d = old.ravel() # 获取旧点的坐标
a, b, c, d = int(a), int(b), int(c), int(d) # 转换为整数
# 在掩模上绘制线段,连接新点和旧点
mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2)
# 显示掩模
cv2.imshow('mask', mask)
# 将掩模添加到当前帧上,生成最终图像
img = cv2.add(frame, mask)
# 显示结果图像
cv2.imshow('frame', img)
# 等待150ms,检测是否按下了Esc键(键码为27)
k = cv2.waitKey(150)
if k == 27: # 按下Esc键,退出循环
break
# 更新旧灰度图和旧特征点
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2) # 重新整理特征点为适合下次计算的形状
# 释放资源
cap.release()
cv2.destroyAllWindows()这段代码实现了一个基于 Lucas-Kanade 光流法
的视频特征点追踪程序。它能实时跟踪视频中物体的运动轨迹。下面我来分步解释代码的各个部分。
🔍 代码逐行解释
1. 导入库与初始化
import numpy as np
import cv2
# 打开视频文件
cap = cv2.VideoCapture('test.avi')
# 随机生成颜色,用于绘制轨迹
color = np.random.randint(0, 255, (100, 3))cv2.VideoCapture('test.avi'): 创建视频捕获对象,用于读取名为'test.avi'的视频文件。你也可以将其替换为0来调用摄像头进行实时追踪。np.random.randint(0, 255, (100, 3)): 随机生成100种颜色(BGR格式),用于绘制不同特征点的运动轨迹。
2. 处理第一帧与特征点检测
# 读取视频的第一帧
ret, old_frame = cap.read()
# 将第一帧转换为灰度图像
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# 定义特征点检测参数
feature_params = dict(maxCorners=100, # 最大角点数量
qualityLevel=0.3, # 角点质量的阈值
minDistance=7) # 最小距离,用于分散角点
# 使用角点检测方法找到特征点
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)cap.read(): 读取视频的第一帧。ret是布尔值,表示是否成功读取帧。cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY): 将帧转换为灰度图,因为许多图像处理算法(包括光流)通常在灰度图像上操作。feature_params: 一个字典,定义了特征点(角点)检测的参数:maxCorners: 要检测的最大角点数量。qualityLevel: 角点质量的阈值(0-1之间),值越小,检测到的角点越多。minDistance: 角点之间的最小欧氏距离,有助于避免角点过于集中。
cv2.goodFeaturesToTrack(): 使用Shi-Tomasi角点检测方法在灰度图像中寻找适合跟踪的特征点。返回的是这些角点的坐标。
3. 初始化与光流参数设置
# 创建一个与当前帧大小相同的全零掩模,用于绘制轨迹
mask = np.zeros_like(old_frame)
# 定义Lucas-Kanade光流参数
lk_params = dict(winSize=(15, 15), # 窗口大小
maxLevel=2) # 金字塔层数mask = np.zeros_like(old_frame): 创建一个与视频帧大小相同的黑色图像,后续用于绘制运动轨迹。lk_params: 另一个参数字典,用于配置Lucas-Kanade光流算法:winSize: 每个金字塔层级上用于搜索光流的窗口大小。较大的窗口能捕获更快的运动,但计算量更大。maxLevel: 图像金字塔的层数。金字塔用于处理大位移运动,层数越高,能处理的位移越大,但计算也更复杂。0表示不使用金字塔。
4. 主循环:处理视频流与光流计算
while True:
# 读取下一帧
ret, frame = cap.read()
if not ret:
break
# 将当前帧转换为灰度图像
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流,获取新的特征点位置和状态
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)cap.read()在循环中读取每一帧。cv2.calcOpticalFlowPyrLK(): 这是核心函数,实现了Lucas-Kanade光流法 。它计算当前帧frame_gray中相对于前一帧old_gray的特征点p0的新位置p1。p1: 新一帧中特征点的计算位置。st: 状态数组(1表示该点的光流被成功找到,0表示未找到)。err: 每个特征点的误差向量。
5. 筛选有效点与绘制轨迹
# 选择好的点(状态为1的点)
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel() # 获取新点的坐标
c, d = old.ravel() # 获取旧点的坐标
a, b, c, d = int(a), int(b), int(c), int(d) # 转换为整数
# 在掩模上绘制线段,连接新点和旧点
mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2)- 只保留那些光流被成功追踪到的点 (
st == 1)。 - 遍历所有好的点,在
mask图像上从旧位置到新位置绘制一条线段,线段的颜色是在初始化时随机生成的。
6. 显示结果与更新
# 显示掩模
cv2.imshow('mask', mask)
# 将掩模添加到当前帧上,生成最终图像
img = cv2.add(frame, mask)
# 显示结果图像
cv2.imshow('frame', img)
# 等待150ms,检测是否按下了Esc键(键码为27)
k = cv2.waitKey(150)
if k == 27: # 按下Esc键,退出循环
break
# 更新旧灰度图和旧特征点
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2) # 重新整理特征点为适合下次计算的形状cv2.imshow(): 显示纯轨迹图像 (mask) 和叠加了轨迹的当前视频帧 (img)。cv2.waitKey(150): 等待150毫秒,并检测键盘输入。如果按下 ESC键 (ASCII码为27),则退出循环。- 更新
old_gray和p0为当前帧的灰度图和特征点位置,为下一次迭代做准备。这是关键步骤,它使得光流能够逐帧持续追踪。