大家好,我是你们熟悉的 31岁程序员小米。
今天来聊一个在 MySQL 社招面试里特别容易"踩坑"的问题:
"如何优化 UNION 查询?"
别看这个问题貌似冷门,但在一些大厂的数据库笔试和面试环节,它几乎是 必考题。因为很多候选人一上来就会写 UNION,但面试官心里在想:你真的知道 UNION 和 UNION ALL 的区别吗?你知道它们对性能的影响有多大吗?
这次,我就用一个小故事,把这个问题聊透。读完之后,你不仅能答出"UNION ALL 的效率高于 UNION",还能用几个妙招,把面试官拿捏得死死的。
一个面试里的故事
上周,我去面试一家互联网公司。面试官出了一道 SQL 题:
现在有两个查询语句,需要把它们的结果合并起来输出,写 SQL。
我心想:"这不就是 UNION 嘛,小 case!"于是我刷刷写了:

面试官笑了笑,问:"为什么用 UNION,不用 UNION ALL?"
我心里咯噔一下。
很多人写 SQL 的时候根本没想过这个问题,习惯性就写了 UNION。但其实,这里面藏着一个面试必问的点。
UNION 和 UNION ALL 的本质区别
来,敲黑板。
UNION 和 UNION ALL 都是用来合并两个结果集的,但是------
- UNION :会对结果进行 去重,也就是说,如果两个子查询中有相同的行,最终结果只会保留一行。
- UNION ALL:不会去重,直接把两个结果集"拼接"起来,全量输出。
听起来只是多了一个"去重"的小功能,但这个小功能却是性能杀手!
为什么?
因为 UNION 为了去重,必须要做:
- 把两个结果集先合并到一起。
- 对合并后的数据做排序(或者 hash),来判断哪些是重复的。
- 去掉重复的记录,最后返回结果。
这三个步骤里,第二步排序/去重特别耗费资源。尤其是数据量一大,磁盘临时文件 + CPU 排序分分钟让你的 SQL 卡成狗。
而 UNION ALL 就简单粗暴了,直接把结果集拼在一起,不去重,效率自然高很多。
所以,在结果集不需要去重的场景下,坚决用 UNION ALL!
面试官追问:那什么时候必须用 UNION?
我当时就这么答:
如果业务上要求结果必须唯一,那就用 UNION。
但大多数场景下,其实我们并不需要去重,直接 UNION ALL 就够了。比如:
- 查询两个年度的用户表(user_2024 + user_2025),它们本身是分库分表的数据,根本不会重复。
- 查询两类不同类型的订单(线上订单表 + 线下订单表),业务逻辑上不可能重复。
这时候用 UNION 去重,简直就是自找麻烦。
仅仅会说 UNION ALL 比 UNION 高效,还不够打动面试官。要想回答得漂亮,你得讲一些更深入的优化思路。
确认是否真的需要UNION
很多时候,大家用 UNION 只是为了图省事,但其实用其他 SQL 结构更高效。举个例子:
如果两个查询的表结构一样,你完全可以考虑用 分区表 或者 联合视图,而不是每次都写两个 SELECT。
比如:
把 user_2024 和 user_2025 做成分区表 user_all,以后查的时候:

性能比 UNION ALL 更稳,还不用担心 SQL 越写越长。
尽量在子查询里过滤数据
另一个优化点是:先过滤,再 UNION。不要偷懒写这种 SQL:

然后在外层再 WHERE age > 18。
这样 MySQL 会先合并两张表的数据,再过滤,数据量大时开销特别大。正确的写法应该是:

让每个子查询先走索引过滤,结果集小很多,再 UNION,效率自然就上来了。
避免 ORDER BY + UNION
有些同学喜欢在每个子查询里加 ORDER BY,比如:

这是大忌!
因为 MySQL 会把两个子查询结果分别排序,然后再合并,效率极差。正确做法是:
只在最外层加 ORDER BY:

这样只排序一次,快很多。
控制返回字段
还有一个小技巧:返回尽量少的字段。
因为 UNION 在去重的时候,需要对比每一列,如果你写了 SELECT *,那就是整行整行对比,负担非常重。
而如果你只选择业务上真正需要的字段,MySQL 需要比较的数据量会小很多,效率自然就上来了。
用临时表优化复杂 UNION
当 UNION 涉及多个表、多层嵌套时,可以考虑用 临时表 或 中间表。比如:
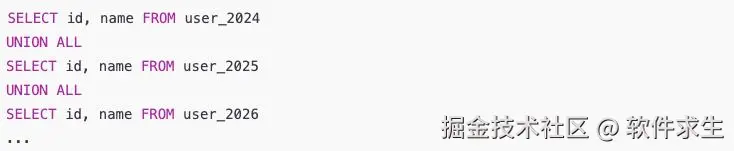
如果子查询很多,MySQL 可能会做多次排序/合并,性能很差。
这时候可以把前几个结果先放到临时表里,再和其他表做 UNION。
这样逻辑更清晰,执行计划也更容易被优化器处理。
面试官的点评
我把上面这些思路说出来的时候,面试官点了点头,说:
很多人能答出 UNION ALL 比 UNION 快,但很少有人能说到 如何在子查询里先过滤、避免多次排序、甚至用分区表代替 UNION。
这些才是你真正能在工作里用得上的优化手段。
瞬间,我觉得自己加了不少分。
总结
好啦,今天的分享差不多了,我们来总结一下:
1、UNION vs UNION ALL:
- UNION:会去重,性能差。
- UNION ALL:不去重,效率高,能用 ALL 就别用普通 UNION。
2、优化技巧:
- 尽量用分区表、视图替代频繁的 UNION。
- 在子查询里先过滤数据,而不是在外层过滤。
- 避免在子查询里 ORDER BY,只在外层排序。
- 返回尽量少的字段,减少比较开销。
- 复杂 UNION 可以用临时表来拆分优化。
3、面试回答套路:
- 先说 UNION ALL 的效率优势。
- 再结合业务场景说明什么时候必须用 UNION。
- 最后补充几招实际可用的优化思路,完美!
END
写到这里,我想问问你:
你在工作里用 UNION 多吗?有没有踩过 "用 UNION 导致查询慢得离谱" 的坑?
欢迎在评论区分享你的故事,我们一起交流下经验!
我是小米,一个喜欢分享技术的31岁程序员。如果你喜欢我的文章,欢迎关注我的微信公众号"软件求生",获取更多技术干货!