Leetcode 5
- [201. Bitwise AND of Numbers Range](#201. Bitwise AND of Numbers Range)
- [202. Happy Number](#202. Happy Number)
- [203. Remove Linked List Elements](#203. Remove Linked List Elements)
- [204. Count Primes](#204. Count Primes)
- [205. Isomorphic Strings](#205. Isomorphic Strings)
- [206. Reverse Linked List](#206. Reverse Linked List)
- [207. Course Schedule](#207. Course Schedule)
- [208. Implement Trie (Prefix Tree)](#208. Implement Trie (Prefix Tree))
- [209. Minimum Size Subarray Sum](#209. Minimum Size Subarray Sum)
- [210. Course Schedule II](#210. Course Schedule II)
- [211. Design Add and Search Words Data Structure](#211. Design Add and Search Words Data Structure)
- [213. House Robber II](#213. House Robber II)
- [215. Kth Largest Element in an Array](#215. Kth Largest Element in an Array)
- [**TO BE FINISHED NOT CHECK**](#TO BE FINISHED NOT CHECK)
- [216. Combination Sum III](#216. Combination Sum III)
- [217. Contains Duplicate](#217. Contains Duplicate)
- [219. Contains Duplicate II](#219. Contains Duplicate II)
- [221. Maximal Square](#221. Maximal Square)
- [222. Count Complete Tree Nodes](#222. Count Complete Tree Nodes)
- [223. Rectangle Area](#223. Rectangle Area)
- [225. Implement Stack using Queues](#225. Implement Stack using Queues)
- [226. Invert Binary Tree](#226. Invert Binary Tree)
- [227. Basic Calculator II](#227. Basic Calculator II)
- [228. Summary Ranges](#228. Summary Ranges)
- [229. Majority Element II](#229. Majority Element II)
- [230. Kth Smallest Element in a BST](#230. Kth Smallest Element in a BST)
- [231. Power of Two](#231. Power of Two)
- [232. Implement Queue using Stacks](#232. Implement Queue using Stacks)
- [234. Palindrome Linked List](#234. Palindrome Linked List)
- [235. Lowest Common Ancestor of a Binary Search Tree](#235. Lowest Common Ancestor of a Binary Search Tree)
- [239. Sliding Window Maximum](#239. Sliding Window Maximum)
- [354. Russian Doll Envelopes](#354. Russian Doll Envelopes)
- [355. Design Twitter](#355. Design Twitter)
- [399. Evaluate Division](#399. Evaluate Division)
- [1091. Shortest Path in Binary Matrix](#1091. Shortest Path in Binary Matrix)
- [438. Find All Anagrams in a String](#438. Find All Anagrams in a String)
- 474
- [567. Permutation in String](#567. Permutation in String)
- [647. Palindromic Substrings](#647. Palindromic Substrings)
- [692. Top K Frequent Words](#692. Top K Frequent Words)
- [752. Open the Lock](#752. Open the Lock)
- [875. Koko Eating Bananas](#875. Koko Eating Bananas)
- [886. Possible Bipartition](#886. Possible Bipartition)
- [1091. Shortest Path in Binary Matrix](#1091. Shortest Path in Binary Matrix)
- [1143. Longest Common Subsequence](#1143. Longest Common Subsequence)
201. Bitwise AND of Numbers Range
201. Bitwise AND of Numbers Range
Given two integers left and right that represent the range left, right, return the bitwise AND of all numbers in this range, inclusive.
Example 1:Input: left = 5, right = 7
Output: 4
Example 2:
Input: left = 0, right = 0
Output: 0
Example 3:
Input: left = 1, right = 2147483647
Output: 0
Constraints:0 <= left <= right <= 231 - 1
Brute force
java
public int rangeBitwiseAnd1(int left, int right) {
int ans = left;
if(left==2147483646){
return left;
}else if(left==2147483647){
return right;
}
for(int i = left + 1; i <= right; i++){
if(ans == 0){
return 0;
}
ans &= i;
}
return ans;
}Bitwise-AND of any two numbers will always produce a number less than or equal to the smaller number.
From the right (bigger) to the left(less), decreasing the left , right boundary iteratively.
Because after the & right boundary, it will generate a smaller answer.
Just update the right value and because we know that during '&' operations the value either remain the same or get decreases so we can skip many iterations!
java
public int rangeBitwiseAnd(int left, int right) {
for(int i=right-1;i>=left;i--) {
right=right&i;
i=right;
}
return right;
}202. Happy Number
Write an algorithm to determine if a number n is happy.
A happy number is a number defined by the following process:
Starting with any positive integer, replace the number by the sum of the squares of its digits.
Repeat the process until the number equals 1 (where it will stay), or it loops endlessly in a cycle which does not include 1.
Those numbers for which this process ends in 1 are happy.
Return true if n is a happy number, and false if not.
Example 1:Input: n = 19
Output: true
Explanation:
1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 0^2 = 1
Example 2:
Input: n = 2
Output: false
Constraints:1 <= n <= 2^31 - 1
Check when to end the loop
If the result is 1 end the loop and return, if it will be false and can't end the loop automatically, have to check when to end the loop.
Use the set to examine the duplicate result and end the loop. If the result is duplicate, it proofs it is can't quit the loop automatically.
java
class Solution {
public boolean isHappy(int n) {
int ans = 0;
int temp;
//use set to examine the loop
//HashSet is unordered
HashSet<Integer> set = new HashSet<>();
set.add(n);
while(n>0){
if(n==1){
return true;
}
while(n > 0){
temp = n%10;
ans += (temp*temp);
n /= 10;
}
if(set.contains(ans)){
return false;
}
n = ans;
set.add(n);
ans = 0;
}
return false;
}
}203. Remove Linked List Elements
203. Remove Linked List Elements
Given the head of a linked list and an integer val, remove all the nodes of the linked list that has Node.val == val, and return the new head.
Example 1:Input: head = 1,2,6,3,4,5,6, val = 6
Output: 1,2,3,4,5
Example 2:
Input: head = \[\], val = 1
Output: \[\]
Example 3:
Input: head = 7,7,7,7, val = 7
Output: \[\]
Constraints:The number of nodes in the list is in the range 0, 104.
1 <= Node.val <= 50
0 <= val <= 50
Use a dummyHead and test the next node.
java
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeElements(ListNode head, int val) {
ListNode pre = new ListNode();
pre.next =head;
ListNode s = pre;
while(pre.next!=null){
if(pre.next.val==val){
pre.next = pre.next.next;
}
else{
pre = pre.next;
}
}
return s.next;
}
}204. Count Primes
Given an integer n, return the number of prime numbers that are strictly less than n.
Example 1:Input: n = 10
Output: 4
Explanation: There are 4 prime numbers less than 10, they are 2, 3, 5, 7.
Example 2:
Input: n = 0
Output: 0
Example 3:
Input: n = 1
Output: 0
Constraints:0 <= n <= 5 * 106
Prime Sieve
A prime number (or a prime) is a natural number greater than 1 that is not a product of two smaller natural numbers.
Prime Number can't be the multiple of any other natural number besides 1 and itself.
For the sieve of Eratosthenes, we start by creating a boolean array (seen) of size n to represent each of the numbers less than n.
We start at 2 and for each number processed (num), we iterate through and mark each multiple (mult) of num, starting at num ^ 2, as seen. We start at num ^ 2 because every multiple up to the num'th multiple will have been guaranteed to have been seen before, since they're also a multiple of a smaller number. For example, when processing 5s, we can skip to 25 because 10 will have been seen when we processed 2s, 15 when we processed 3s, and 20 when we processed 2s.
Then we move num forward, skipping any numbers that have already been seen. By doing this, we will only stop on prime numbers, because they haven't been seen as a multiple of a previous iteration. We just have to update our count (ans) each time we stop and then return ans once we reach n.
Method 1
Use array to note whether a number is a composite number (not prime, has a factorization).
Mark multiples starting from num*num because the numbers before num*num are not prime numbers that have been marked
java
public int countPrimes(int n) {
boolean[] seen = new boolean[n];
int ans = 0;
for (int num = 2; num < n; num++) {
//if seen[]==true not a prime continue
if (seen[num]) continue;
//not skip, is prime, count++, add all multiples of the number to the prime sieve
//Mark multiples starting from num*num
ans += 1;
for (long mult = (long)num * num; mult < n; mult += num)
seen[(int)mult] = true;
}
return ans;
}123 ms 89.02% 47 MB 74.20%
Method 2
mark multiple from 2 to sqrt(n)****, get the number of prime by subtract the number of composite number
java
public int countPrimes(int n) {
if (n <= 2) return 0;
int count = n-2; // Initially we have n-2 primes as 1 and n are excluded
double rootN = Math.floor(Math.sqrt(n));
boolean[] isPrime = new boolean[n];
Arrays.fill(isPrime,true);
for (int i=2; i<=rootN; i++)
if (isPrime[i])
for (int j=i*i; j<n; j+=i)
if (isPrime[j]) {
isPrime[j] = false;
count--;
}
return count;
}104 ms 95.57% 46.8 MB 79.83 %
205. Isomorphic Strings
Given two strings s and t, determine if they are isomorphic.
Two strings s and t are isomorphic if the characters in s can be replaced to get t.
All occurrences of a character must be replaced with another character while preserving the order of characters. No two characters may map to the same character, but a character may map to itself.
Example 1:Input: s = "egg", t = "add"
Output: true
Example 2:
Input: s = "foo", t = "bar"
Output: false
Example 3:
Input: s = "paper", t = "title"
Output: true
Constraints:1 <= s.length <= 5 * 104
t.length == s.length
s and t consist of any valid ascii character.
Use string replace to replace the character in t and check whether is equals to s.
Wrong
"egcd"
"adfd"
Output true
Expected false
Your input"foo"
"bar"
Output true
Expected false
java
class Solution {
public boolean isIsomorphic(String s, String t) {
if(s.length()!=t.length()){
return false;
}
for(int i = 0; i < s.length(); i++){
if(s.charAt(i)!=t.charAt(i)){
t = t.replace(t.charAt(i),s.charAt(i));
}
}
int[] ch = new int[256];
for(int i = 0; i < s.length(); i++){
ch[s.charAt(i)]++;
}
for(int i = 0; i < s.length(); i++){
ch[t.charAt(i)]--;
}
for(int i:ch){
if(i != 0){
return false;
}
}
return true;
}
}AC
There is one-one relationship between the chars.
Use HashMap to store the one-one relationship.
key: character in s
value: corresponding character in t
java
public boolean isIsomorphic(String s, String t) {
if(s == null || s.length() <= 1) return true;
HashMap<Character, Character> map = new HashMap<>();
for(int i = 0 ; i< s.length(); i++){
char a = s.charAt(i);
char b = t.charAt(i);
if(map.containsKey(a)){
if(map.get(a).equals(b))
continue;
else
return false;
}else{
if(!map.containsValue(b))
map.put(a,b);
else return false;
}
}
return true;
}206. Reverse Linked List
Given the head of a singly linked list, reverse the list, and return the reversed list.
Example 1:Input: head = 1,2,3,4,5
Output: 5,4,3,2,1
Example 2:
Input: head = 1,2
Output: 2,1
Example 3:
Input: head = \[\]
Output: \[\]
Constraints:The number of nodes in the list is the range 0, 5000.
-5000 <= Node.val <= 5000
Method 1 Insert the node at head of the list
java
public ListNode reverseList(ListNode head) {
if(head==null) return head;
ListNode pre = new ListNode();
pre.next = head;
ListNode p = head.next;
head.next = null;
ListNode s;
while(p!=null){
s = p.next;
p.next = pre.next;
pre.next = p;
p = s;
}
return pre.next;
}0ms 100% 43.8MB 5.97%
Method 2 Reverse the pointer
p s r p->s p<-s
java
public ListNode reverseList(ListNode head) {
if(head==null) return head;
ListNode p = head;
ListNode s = p.next;
p.next = null;
ListNode r;
while(s!=null){
r = s.next;
s.next = p;
p = s;
s = r;
}
return p;
}0ms 100% 44MB
207. Course Schedule
There are a total of numCourses courses you have to take, labeled from 0 to numCourses - 1. You are given an array prerequisites where prerequisitesi = ai, bi indicates that you must take course bi first if you want to take course ai.
For example, the pair 0, 1, indicates that to take course 0 you have to first take course 1.
Return true if you can finish all courses. Otherwise, return false.
Example 1:Input: numCourses = 2, prerequisites = \[1,0]
Output: true
Explanation: There are a total of 2 courses to take.
To take course 1 you should have finished course 0. So it is possible.
Example 2:
Input: numCourses = 2, prerequisites = \[1,0,0,1]
Output: false
Explanation: There are a total of 2 courses to take.
To take course 1 you should have finished course 0, and to take course 0 you should also have finished course 1. So it is impossible.
Constraints:1 <= numCourses <= 2000
0 <= prerequisites.length <= 5000
prerequisitesi.length == 2
0 <= ai, bi < numCourses
All the pairs prerequisitesi are unique.
There are a total of numCourses courses you have to take, labeled from 0 to numCourses - 1. Return true if you can finish all courses.
0 , 1 : To Take course 0 you have to first take course 1.
deadlock
Check whether there is a deadlock.
Graph Problem
Use DFS or BFS to check whether there is a loop.
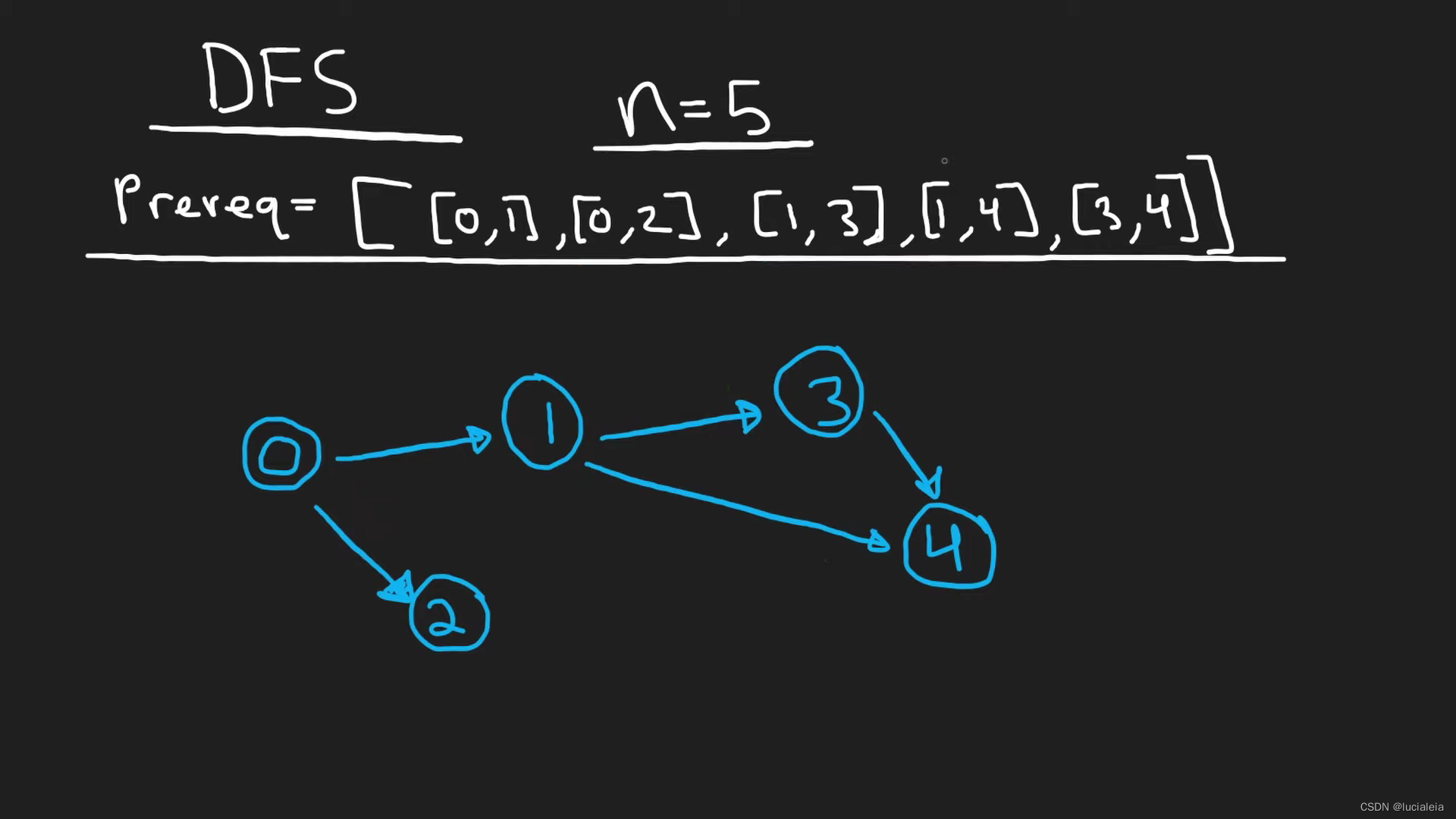
Use the HashMap to store the dependency relationship.
Key: Each course
Value: All their prerequisite courses
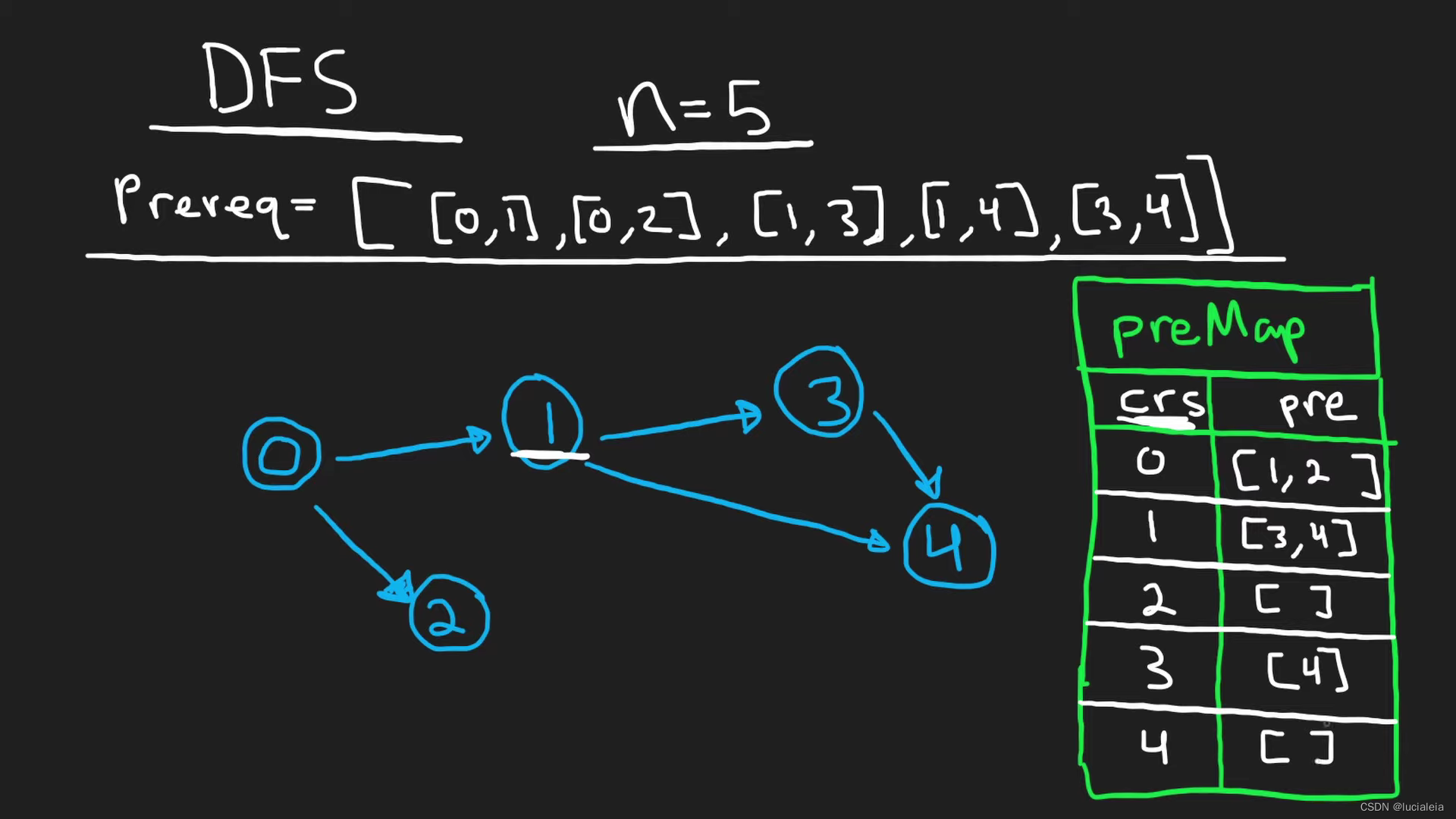
Do DFS from 0 to n-1 node.
java
class Solution {
HashSet<Integer> visiting = new HashSet<>();
ArrayList<ArrayList<Integer>> arr = new ArrayList<>();
HashSet<Integer> canVisit = new HashSet<>();
public boolean canFinish(int numCourses, int[][] prerequisites) {
//initialize the preCourse list
//use arr.get(courseNum) to get course's preCourse
for(int i = 0; i < numCourses; i++){
ArrayList<Integer> pre = new ArrayList<>();
arr.add(pre);
}
for(int i = 0; i < prerequisites.length; i++){
arr.get(prerequisites[i][0]).add(prerequisites[i][1]);
}
for(int i = 0; i < numCourses; i++){
if(dfs(i)==false){
return false;
}
}
return true;
}
public boolean dfs(int course){
//visiting means this dfs() is searching for course's pre. Itself is in the loop.
if(visiting.contains(course)){
return false;
}
//shortcut remember the the possible answer, avoiding repeated calculation
if(canVisit.contains(course)){
return true;
}
//no preCourse for this course, can be taken
if(arr.get(course).size()==0){
canVisit.add(course);
return true;
}
//Add to current visiting before check the preCourse
visiting.add(course);
for(Integer i:arr.get(course)){
if(dfs(i)==false){
return false;
}
}
canVisit.add(course);
//Remove from current visiting. Because this course can be reach and not in a loop
visiting.remove(course);
return true;
}
}3 ms 95.77% 43.2 MB 70.85%
Another solution of same idea
java
class Solution {
//DFS
enum Status {
NOT_VISITED, VISITED, VISITING;
}
public boolean canFinish(int numCourses, int[][] prerequisites) {
if(prerequisites == null || prerequisites.length == 0 || prerequisites[0].length == 0) return true;
// building graph
List<List<Integer>> list = new ArrayList<>();
// System.out.println(list.size());
for(int i = 0; i < numCourses; i++) {
list.add(new ArrayList<Integer>());
}
for(int[] p: prerequisites) {
int prerequisite = p[1];
int course = p[0];
list.get(course).add(prerequisite);
}
Status[] visited = new Status[numCourses];
for(int i = 0; i < numCourses; i++) {
// if there is a cycle, return false
if(dfs(list, visited, i)) return false;
}
return true;
}
private boolean dfs(List<List<Integer>> list, Status[] visited, int cur) {
if(visited[cur] == Status.VISITING) return true;
if(visited[cur] == Status.VISITED) return false;
visited[cur] = Status.VISITING;
for(int next: list.get(cur)) {
if(dfs(list, visited, next)) return true;
}
visited[cur] = Status.VISITED;
return false;
}
}208. Implement Trie (Prefix Tree)
208. Implement Trie (Prefix Tree)
A trie (pronounced as "try") or prefix tree is a tree data structure used to efficiently store and retrieve keys in a dataset of strings. There are various applications of this data structure, such as autocomplete and spellchecker.
Implement the Trie class:Trie() Initializes the trie object.
void insert(String word) Inserts the string word into the trie.
boolean search(String word) Returns true if the string word is in the trie (i.e., was inserted before), and false otherwise.
boolean startsWith(String prefix) Returns true if there is a previously inserted string word that has the prefix prefix, and false otherwise.
Example 1:Input
"Trie", "insert", "search", "search", "startsWith", "insert", "search"
\[\], \["apple"\], \["apple"\], \["app"\], \["app"\], \["app"\], \["app"\]
Output
null, null, true, false, true, null, true
Explanation
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // return True
trie.search("app"); // return False
trie.startsWith("app"); // return True
trie.insert("app");
trie.search("app"); // return True
Constraints:1 <= word.length, prefix.length <= 2000
word and prefix consist only of lowercase English letters.
At most 3 * 104 calls in total will be made to insert, search, and startsWith.
java
class TrieNode{
public TrieNode[] list;
public boolean isEnd;
public TrieNode(){
list = new TrieNode[26];
isEnd = false;
}
}
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String word) {
TrieNode p = root;
for(int i = 0; i < word.length(); i++){
if(p.list[word.charAt(i)-'a']==null){
// if null insert node
p.list[word.charAt(i)-'a'] = new TrieNode();
}
p = p.list[word.charAt(i)-'a'];
}
p.isEnd = true;
}
public boolean search(String word) {
TrieNode p = root;
for(int i = 0; i < word.length(); i++){
if(p.list[word.charAt(i)-'a']==null){
// character not exist
return false;
}
p = p.list[word.charAt(i)-'a'];
}
if(p.isEnd == true){
return true;
}
return false;
}
public boolean startsWith(String prefix) {
TrieNode p = root;
for(int i = 0; i < prefix.length(); i++){
if(p.list[prefix.charAt(i)-'a']==null){
// character not exist
return false;
}
p = p.list[prefix.charAt(i)-'a'];
}
return true;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/36 ms 90.36% 51.1 MB 90.80%
209. Minimum Size Subarray Sum
209. Minimum Size Subarray Sum
Given an array of positive integers nums and a positive integer target, return the minimal length of a subarray whose sum is greater than or equal to target. If there is no such subarray, return 0 instead.
Example 1:Input: target = 7, nums = 2,3,1,2,4,3
Output: 2
Explanation: The subarray 4,3 has the minimal length under the problem constraint.
Example 2:
Input: target = 4, nums = 1,4,4
Output: 1
Example 3:
Input: target = 11, nums = 1,1,1,1,1,1,1,1
Output: 0
Constraints:1 <= target <= 109
1 <= nums.length <= 105
1 <= numsi <= 104
Follow up: If you have figured out the O(n) solution, try coding another solution of which the time complexity is O(n log(n)).
Sliding window
left , right
Move the right boundary until it reach the condition, then move the left to narrow the edge and update the optimal solution. When it get out of the condition, keep move the right boundary.
java
class Solution {
public int minSubArrayLen(int target, int[] nums) {
int left = 0;
int right = 0;
int min = Integer.MAX_VALUE;
int sum = 0;
while(right<nums.length){
while(sum < target && right<nums.length){
sum += nums[right];
right++;
}
while(sum>=target && left<=right){
int len = right - left;
if(min>len){
min = len;
}
sum -= nums[left];
left++;
}
}
return min==Integer.MAX_VALUE?0:min;
}
}1 ms 100.00% 49.7 MB 91.47%
210. Course Schedule II
There are a total of numCourses courses you have to take, labeled from 0 to numCourses - 1. You are given an array prerequisites where prerequisitesi = ai, bi indicates that you must take course bi first if you want to take course ai.
For example, the pair 0, 1, indicates that to take course 0 you have to first take course 1.
Return the ordering of courses you should take to finish all courses. If there are many valid answers, return any of them. If it is impossible to finish all courses, return an empty array.
Example 1:Input: numCourses = 2, prerequisites = \[1,0]
Output: 0,1
Explanation: There are a total of 2 courses to take. To take course 1 you should have finished course 0. So the correct course order is 0,1.
Example 2:
Input: numCourses = 4, prerequisites = \[1,0,2,0,3,1,3,2]
Output: 0,2,1,3
Explanation: There are a total of 4 courses to take. To take course 3 you should have finished both courses 1 and 2. Both courses 1 and 2 should be taken after you finished course 0.
So one correct course order is 0,1,2,3. Another correct ordering is 0,2,1,3.
Example 3:
Input: numCourses = 1, prerequisites = \[\]
Output: 0
Constraints:1 <= numCourses <= 2000
0 <= prerequisites.length <= numCourses * (numCourses - 1)
prerequisitesi.length == 2
0 <= ai, bi < numCourses
ai != bi
All the pairs ai, bi are distinct.
Return an empty array :
return new int[0];
java
class Solution {
HashSet<Integer> visiting = new HashSet<>();
ArrayList<ArrayList<Integer>> arr = new ArrayList<>();
HashSet<Integer> canVisit = new HashSet<>();
int[] result;
int index = 0;
public int[] findOrder(int numCourses, int[][] prerequisites) {
result = new int[numCourses];
//initialize the preCourse list
//use arr.get(courseNum) to get course's preCourse
for(int i = 0; i < numCourses; i++){
ArrayList<Integer> pre = new ArrayList<>();
arr.add(pre);
}
for(int i = 0; i < prerequisites.length; i++){
arr.get(prerequisites[i][0]).add(prerequisites[i][1]);
}
for(int i = 0; i < numCourses; i++){
if(canVisit.contains(i)){
continue;
}
if(dfs(i)==false){
return new int[0];
}
}
return result;
}
public boolean dfs(int course){
//visiting means this dfs() is searching for course's pre. Itself is in the loop.
if(visiting.contains(course)){
return false;
}
//shortcut remember the the possible answer, avoiding repeated calculation
if(canVisit.contains(course)){
return true;
}
//no preCourse for this course, can be taken
if(arr.get(course).size()==0){
canVisit.add(course);
result[index] = course;
index++;
return true;
}
//Add to current visiting before check the preCourse
visiting.add(course);
for(Integer i:arr.get(course)){
if(dfs(i)==false){
return false;
}
}
canVisit.add(course);
//Remove from current visiting. Because this course can be reach and not in a loop
visiting.remove(course);
result[index] = course;
index++;
return true;
}
}3 ms 99.03% 43.3 MB 86.90%
Topological sort
Used in Directed Acyclic Graph (DAG) 有向无环图
a linear ordering of its vertices such that for every directed edge u->v from vertex u to vertex v, u comes before v in the ordering.
Steps:
- Initialization:
- Create a visited array to keep track of visited nodes.
- Use a stack to store the nodes in the topological order.
- DFS for Topological Sort:
- For each unvisited node, perform DFS.
- During DFS, mark the current node as visited.
- Recur for all adjacent nodes (dependencies).
- After all the adjacent nodes are processed, push the current node onto the stack.
- Result:
- After the DFS completes for all nodes, the stack contains the topological order, which is obtained by popping nodes from the stack.
211. Design Add and Search Words Data Structure
211. Design Add and Search Words Data Structure
Design a data structure that supports adding new words and finding if a string matches any previously added string.
Implement the WordDictionary class:WordDictionary() Initializes the object.
void addWord(word) Adds word to the data structure, it can be matched later.
bool search(word) Returns true if there is any string in the data structure that matches word or false otherwise. word may contain dots '.' where dots can be matched with any letter.
Example:Input
"WordDictionary","addWord","addWord","addWord","search","search","search","search"
\[\],\["bad"\],\["dad"\],\["mad"\],\["pad"\],\["bad"\],\[".ad"\],\["b..."\]
Output
null,null,null,null,false,true,true,true
Explanation
WordDictionary wordDictionary = new WordDictionary();
wordDictionary.addWord("bad");
wordDictionary.addWord("dad");
wordDictionary.addWord("mad");
wordDictionary.search("pad"); // return False
wordDictionary.search("bad"); // return True
wordDictionary.search(".ad"); // return True
wordDictionary.search("b..."); // return True
Constraints:1 <= word.length <= 25
word in addWord consists of lowercase English letters.
word in search consist of '.' or lowercase English letters.
There will be at most 3 dots in word for search queries.
At most 104 calls will be made to addWord and search.
Prefix Tree / TrieTree
Use dfs and backtrack to track all the exist node when meeting ' . '
java
class TrieNode{
public TrieNode[] dic;
boolean isEnd;
public TrieNode(){
dic = new TrieNode[26];
isEnd = false;
}
}
class WordDictionary {
TrieNode root;
public WordDictionary() {
root = new TrieNode();
}
public void addWord(String word) {
TrieNode p = root;
for(int i = 0; i < word.length(); i++){
if(p.dic[word.charAt(i)-'a']==null){
p.dic[word.charAt(i)-'a'] = new TrieNode();
}
p = p.dic[word.charAt(i)-'a'];
}
p.isEnd = true;
}
public boolean search(TrieNode p,String word,int index){
if(index > word.length() || p==null){
return false;
}
if(index == word.length()){
return p.isEnd;
}
if(word.charAt(index) == '.'){
for(TrieNode n:p.dic){
if(search(n,word,index+1)){
return true;
}
}
return false;
}
if (p.dic[word.charAt(index)-'a']==null){
return false;
}
return search(p.dic[word.charAt(index)-'a'],word,index+1);
}
public boolean search(String word) {
return search(root,word,0);
}
}533 ms 80.82% 104.4 MB 64.85%
213. House Robber II
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed. All houses at this place are arranged in a circle. That means the first house is the neighbor of the last one. Meanwhile, adjacent houses have a security system connected, and it will automatically contact the police if two adjacent houses were broken into on the same night.
Given an integer array nums representing the amount of money of each house, return the maximum amount of money you can rob tonight without alerting the police.
Example 1:
Input: nums = 2,3,2
Output: 3
Explanation: You cannot rob house 1 (money = 2) and then rob house 3 (money = 2), because they are adjacent houses.
Example 2:
Input: nums = 1,2,3,1
Output: 4
Explanation: Rob house 1 (money = 1) and then rob house 3 (money = 3).
Total amount you can rob = 1 + 3 = 4.
Example 3:
Input: nums = 1,2,3
Output: 3
Constraints:1 <= nums.length <= 100
0 <= numsi <= 1000
Houses are linked as a circular linked list .
The first house is related to the last house.
Have two conditions: 1. Rob the first one and leave the last one. 2. Leave first and rob the last.
Test this two condition by using two dp array.
java
//rob[] store the last house
//notrob[] not rob the last
//dp[i] = Max(dp[i-2]+nums[i], dp[i-1])
public int rob(int[] nums) {
if(nums.length==1){
return nums[0];
}
int[] rob = new int[nums.length+1];
int[] notrob = new int[nums.length+1];
notrob[1] = nums[0];
rob[1] = 0;
for(int i = 2; i < nums.length; i++){
notrob[i] = Math.max(notrob[i-2]+nums[i-1], notrob[i-1]);
rob[i] = Math.max(rob[i-2]+nums[i-1], rob[i-1]);
}
notrob[nums.length] = notrob[nums.length-1];
rob[nums.length] = Math.max(rob[nums.length-2]+nums[nums.length-1], rob[nums.length-1]);
return Math.max(notrob[nums.length],rob[nums.length]);
}0 ms 100% 41.5 MB 44.04%
215. Kth Largest Element in an Array
215. Kth Largest Element in an Array
Given an integer array nums and an integer k, return the kth largest element in the array.
Note that it is the kth largest element in the sorted order, not the kth distinct element.
You must solve it in O(n) time complexity.
Example 1:Input: nums = 3,2,1,5,6,4, k = 2
Output: 5
Example 2:
Input: nums = 3,2,3,1,2,4,5,5,6, k = 4
Output: 4
Constraints:1 <= k <= nums.length <= 105
-104 <= numsi <= 104
Must solve it in O(n) time complexity
k largest(or smallest) elements in an array
Method 1 Heap Sort
Use Max Heap the pop k times.
Use Min Heap to store the smallest k number.
The elements are stored based on the priority order which is ascending by default.
java
public int findKthLargest(int[] nums, int k) {
Queue<Integer> minHeap = new PriorityQueue<>();
for (int n : nums) {
minHeap.add(n);
if (minHeap.size() > k) {
minHeap.remove();
}
}
return minHeap.peek();
}PriorityQueue
java
Queue<Integer> minHeap = new PriorityQueue<>();The elements are stored based on the priority order which is ascending by default.
- boolean add(E element)
- public peek() : This method retrieves, but does not remove, the head of this queue, or returns null if this queue is empty.
- public poll() : This method retrieves and removes the head of this queue, or returns null if this queue is empty.
Constructors:
-
PriorityQueue(): Creates a PriorityQueue with the default initial capacity (11) that orders its elements according to their natural ordering.
PriorityQueue<E> pq = new PriorityQueue<E>(); -
PriorityQueue(Collection c): Creates a PriorityQueue containing the elements in the specified collection.
PriorityQueue<E> pq = new PriorityQueue<E>(Collection<E> c); -
PriorityQueue(int initialCapacity): Creates a PriorityQueue with the specified initial capacity that orders its elements according to their natural ordering.
PriorityQueue<E> pq = new PriorityQueue<E>(int initialCapacity); -
PriorityQueue(int initialCapacity, Comparator comparator): Creates a PriorityQueue with the specified initial capacity that orders its elements according to the specified comparator.
PriorityQueue<E> pq = new PriorityQueue(int initialCapacity, Comparator<E> comparator);
Implement PriorityQueue through Comparator in Java
Heap Sort
Array = {1, 3, 5, 4, 6, 13, 10, 9, 8, 15, 17}
Corresponding Complete Binary Tree is:
1
/ \
3 5
/ \ / \
4 6 13 10
/ \ / \
9 8 15 17Total Nodes = 11.
Total non-leaf nodes= (11/2)-1=5
last non-leaf node = 6.
Therefore, Last Non-leaf node index = 4.
To build the heap, heapify only the nodes: 1, 3, 5, 4, 6 in reverse order.
Heapify 6: Swap 6 and 17.
1
/ \
3 5
/ \ / \
4 17 13 10
/ \ / \
9 8 15 6Heapify 4: Swap 4 and 9.
1
/ \
3 5
/ \ / \
9 17 13 10
/ \ / \
4 8 15 6Heapify 5: Swap 13 and 5.
1
/ \
3 13
/ \ / \
9 17 5 10
/ \ / \
4 8 15 6Heapify 3: First Swap 3 and 17, again swap 3 and 15.
1
/ \
17 13
/ \ / \
9 15 5 10
/ \ / \
4 8 3 6Heapify 1: First Swap 1 and 17, again swap 1 and 15, finally swap 1 and 6.
17
/ \
15 13
/ \ / \
9 6 5 10
/ \ / \
4 8 3 1Method 2 Quick Sort
java
//quick sort
public int findKthLargest(int[] nums, int k) {
int start = 0, end = nums.length - 1, index = nums.length - k;
while (start < end) {
int pivot = partion(nums, start, end);
if (pivot < index) start = pivot + 1;
else if (pivot > index) end = pivot - 1;
else return nums[pivot];
}
return nums[start];
}
private int partion(int[] nums, int start, int end) {
int pivot = start, temp;
while (start <= end) {
while (start <= end && nums[start] <= nums[pivot]) start++;
while (start <= end && nums[end] > nums[pivot]) end--;
if (start > end) break;
temp = nums[start];
nums[start] = nums[end];
nums[end] = temp;
}
temp = nums[end];
nums[end] = nums[pivot];
nums[pivot] = temp;
return end;
}TO BE FINISHED NOT CHECK
216. Combination Sum III
Find all valid combinations of k numbers that sum up to n such that the following conditions are true:
Only numbers 1 through 9 are used.
Each number is used at most once.
Return a list of all possible valid combinations. The list must not contain the same combination twice, and the combinations may be returned in any order.
Example 1:Input: k = 3, n = 7
Output: \[1,2,4]
Explanation:
1 + 2 + 4 = 7
There are no other valid combinations.
Example 2:
Input: k = 3, n = 9
Output: \[1,2,6,1,3,5,2,3,4]
Explanation:
1 + 2 + 6 = 9
1 + 3 + 5 = 9
2 + 3 + 4 = 9
There are no other valid combinations.
Example 3:
Input: k = 4, n = 1
Output: \[\]
Explanation: There are no valid combinations.
Using 4 different numbers in the range 1,9, the smallest sum we can get is 1+2+3+4 = 10 and since 10 > 1, there are no valid combination.
Constraints:2 <= k <= 9
1 <= n <= 60
backtrack
When adding into List<List< Integer >>, must give its a new instance(memory address), or the ans(List< Integer >) will remain changeable in the later traverse.
Wrong
ansList.add(ans);
ansList = [{}]
Accepted
ansList.add(new ArrayList(ans));
java
class Solution {
public List<List<Integer>> combinationSum3(int k, int n) {
List<List<Integer>> ansList = new ArrayList<>();
helper(k,1,n,ansList,new ArrayList<Integer>());
return ansList;
}
public void helper(int k,int i,int n,List<List<Integer>> ansList,List<Integer> ans){
if(k == 0 && n == 0){
ansList.add(new ArrayList(ans));
return;
}
for(;i <= 9; i++){
if(i > n){
return;
}
ans.add(i);
helper(k-1,i+1,n-i,ansList,ans);
ans.remove(ans.size()-1);
}
}
}0 ms 100.00% 40.2 MB 65.34%
217. Contains Duplicate
Given an integer array nums, return true if any value appears at least twice in the array, and return false if every element is distinct.
Example 1:Input: nums = 1,2,3,1
Output: true
Example 2:
Input: nums = 1,2,3,4
Output: false
Example 3:
Input: nums = 1,1,1,3,3,4,3,2,4,2
Output: true
Constraints:1 <= nums.length <= 105
-109 <= numsi <= 109
Method 1 Use Set
java
public boolean containsDuplicate(int[] nums) {
HashSet<Integer> set = new HashSet<>();
for(int i = 0; i < nums.length; i++){
if(set.contains(nums[i])){
return true;
}
set.add(nums[i]);
}
return false;
}7 ms 88.51% 54.5 MB 83.40%
Method 2 Sort and check
java
class Solution {
public boolean containsDuplicate(int[] nums) {
Arrays.sort(nums);
for(int i = 0; i < nums.length-1; i++){
if(nums[i]==nums[i+1]){
return true;
}
}
return false;
}
}23 ms 45.55% 71.1 MB 20.57%
219. Contains Duplicate II
Given an integer array nums and an integer k, return true if there are two distinct indices i and j in the array such that numsi == numsj and abs(i - j) <= k.
Example 1:Input: nums = 1,2,3,1, k = 3
Output: true
Example 2:
Input: nums = 1,0,1,1, k = 1
Output: true
Example 3:
Input: nums = 1,2,3,1,2,3, k = 2
Output: false
Constraints:1 <= nums.length <= 105
-109 <= numsi <= 109
0 <= k <= 105
Use a hashmap to store the number and its indexs.
Calculate the dictance when traversing.
java
//Use HashMap to record the value and the corresponding index. Duplicate when containsKey()==true
//can also use hashset
public boolean containsNearbyDuplicate(int[] nums, int k) {
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
for (int i = 0; i < nums.length; i++) {
if (map.containsKey(nums[i])) {
if (i - map.get(nums[i]) <= k) return true;
}
map.put(nums[i], i);
}
return false;
}221. Maximal Square
Given an m x n binary matrix filled with 0's and 1's, find the largest square containing only 1's and return its area.
Example 1:Input: matrix = \["1","0","1","0","0","1","0","1","1","1","1","1","1","1","1","1","0","0","1","0"]
Output: 4
Example 2:Input: matrix = \["0","1","1","0"]
Output: 1
Example 3:
Input: matrix = \["0"]
Output: 0
Constraints:m == matrix.length
n == matrixi.length
1 <= m, n <= 300
matrixij is '0' or '1'.

dp
if(matrix x y ==0){
dp x y = 0;
}
if(matrix x y ==1){
dp x y = min(dp x - 1 y ,dp x y - 1 ,dp x - 1 y - 1 ) + 1;
}
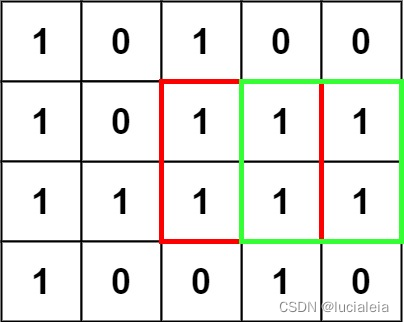
Record the maximum square boundary length according to the top,left,top-left grid.
\["1","0","1","0"
"1","0","1","1"
"1","0","1","1"
"1","1","1","1"\]
Expected 4
java
class Solution {
//https://leetcode.com/problems/maximal-square/discuss/600149/Python-Thinking-Process-Diagrams-DP-Approach
/*
matrix[i][j]=='1'
dp[i][j] = min(dp[i-1][j],dp[i][j-1],dp[i-1][j-1])+1
According to the top,left,top-left, record the maximum square boundary length
0 1 1 1 1 1 0 1 1 0
1 X 1 X 1 1 0 1 2 0
1 1 0 1 1 0 1 1
*/
public int maximalSquare(char[][] matrix) {
int max = 0;
int[][] dp = new int[matrix.length][matrix[0].length];
for(int i = 0; i < matrix.length; i++){
for(int j = 0; j < matrix[0].length; j++){
if(i == 0 || j == 0){
if(matrix[i][j]=='1'){
dp[i][j] = 1;
}
//dp[i][j] init to be 0
}
else if(matrix[i][j]=='1'){
dp[i][j] = Math.min(Math.min(dp[i-1][j],dp[i][j-1]),dp[i-1][j-1])+1;
}
//dp[i][j] init to be 0
if(dp[i][j]>max){
max = dp[i][j];
}
}
}
return max*max;
}
}6 ms 85.29% 53.9 MB 89.48%
java
public int maximalSquare(char[][] matrix) {
int max = 0;
int[][] dp = new int[matrix.length+1][matrix[0].length+1];
for(int i = 1; i <= matrix.length; i++){
for(int j = 1; j <= matrix[0].length; j++){
if(matrix[i-1][j-1]=='1'){
dp[i][j] = Math.min(Math.min(dp[i-1][j],dp[i][j-1]),dp[i-1][j-1])+1;
}
if(dp[i][j]>max){
max = dp[i][j];
}
}
}
return max*max;
}8 ms 72.00% 58.4 MB 66.15%
222. Count Complete Tree Nodes
222. Count Complete Tree Nodes
Given the root of a complete binary tree, return the number of the nodes in the tree.
According to Wikipedia, every level, except possibly the last, is completely filled in a complete binary tree, and all nodes in the last level are as far left as possible. It can have between 1 and 2h nodes inclusive at the last level h.
Design an algorithm that runs in less than O(n) time complexity.
Example 1:Input: root = 1,2,3,4,5,6
Output: 6
Example 2:
Input: root = \[\]
Output: 0
Example 3:
Input: root = 1
Output: 1
Constraints:The number of nodes in the tree is in the range 0, 5 \* 104.
0 <= Node.val <= 5 * 104
The tree is guaranteed to be complete.
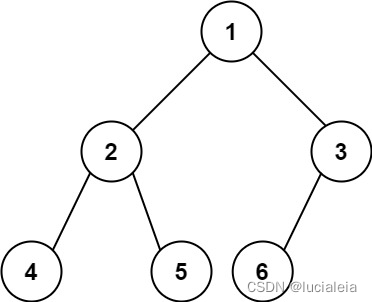
In Complete Tree, only the last level can have the missing nodes. All previous levels are filled.
The number of nodes in each leve is 2^(n-1) (root in the 1 level).
The number of nodes n in a full binary tree is and at most (2^n) - 1
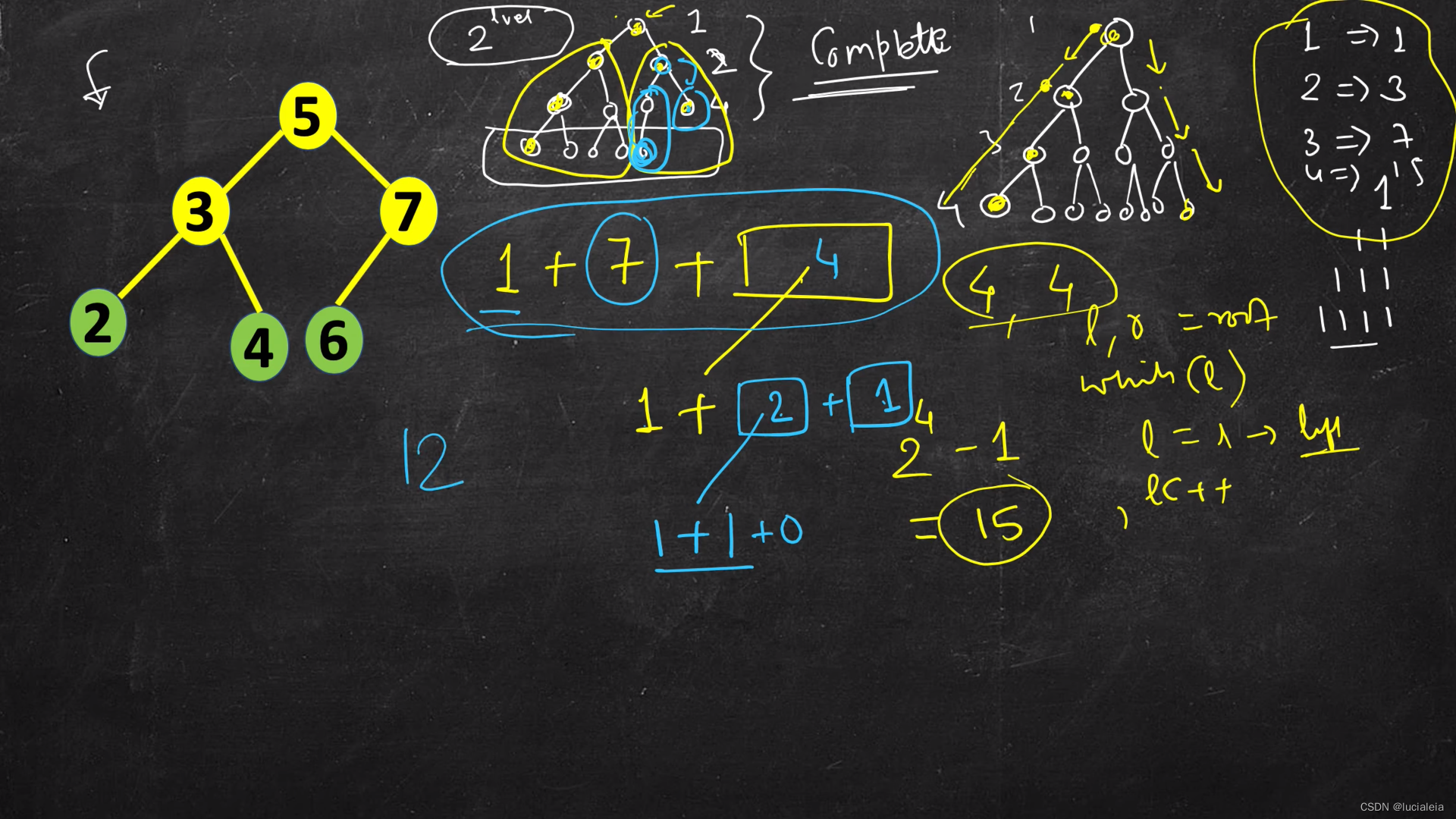
java
class Solution {
public int countNodes(TreeNode root) {
if(root==null){
return 0;
}
TreeNode left = root, right = root;
int countL = 0,countR = 0;
while(left!=null){
countL++;
left = left.left;
}
while(right!=null){
countR++;
right = right.right;
}
if(countL==countR){
return (1<<countL)- 1;
}
return 1 + countNodes(root.left) + countNodes(root.right);
}
}0 ms 100.00% 45.2 MB 84.59%
Use BFS to count the last level and depth.
java
class Solution {
public int countNodes(TreeNode root) {
//BFS level traverse
if(root==null) return 0;
Queue<TreeNode> queue = new LinkedList<>();
TreeNode p = root;
int count = 0;
queue.offer(p);
while(!queue.isEmpty()){
p = queue.poll();
count++;
if(p.left!=null) queue.offer(p.left);
if(p.right!=null) queue.offer(p.right);
}
return count;
}
}5 ms 7.98% 51.9 MB
223. Rectangle Area
Given the coordinates of two rectilinear rectangles in a 2D plane, return the total area covered by the two rectangles.
The first rectangle is defined by its bottom-left corner (ax1, ay1) and its top-right corner (ax2, ay2).
The second rectangle is defined by its bottom-left corner (bx1, by1) and its top-right corner (bx2, by2).
Example 1:Rectangle Area
Input: ax1 = -3, ay1 = 0, ax2 = 3, ay2 = 4, bx1 = 0, by1 = -1, bx2 = 9, by2 = 2
Output: 45
Example 2:
Input: ax1 = -2, ay1 = -2, ax2 = 2, ay2 = 2, bx1 = -2, by1 = -2, bx2 = 2, by2 = 2
Output: 16
Constraints:-104 <= ax1 <= ax2 <= 104
-104 <= ay1 <= ay2 <= 104
-104 <= bx1 <= bx2 <= 104
-104 <= by1 <= by2 <= 104
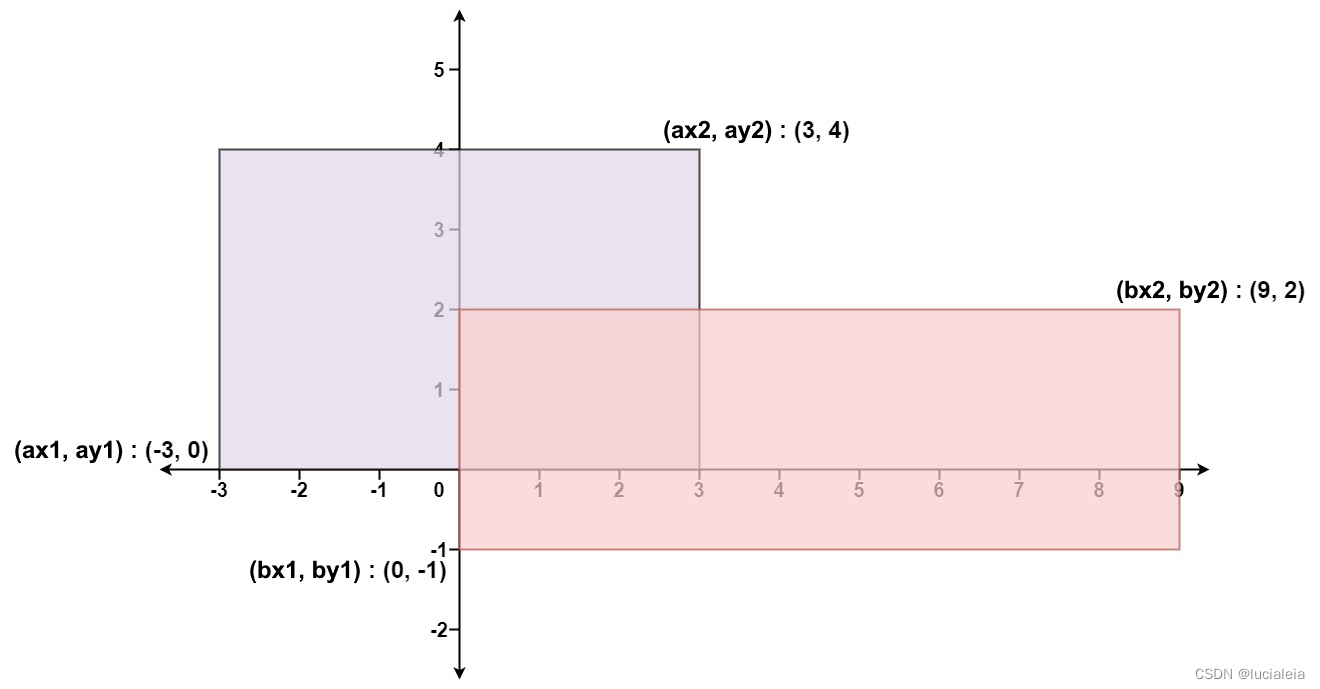
There are primarily 3 scenarios.
scenario 1 (partly overlapping):
ax1-----------ax2
bx1-----------bx2
scenario 2 (fully overlapping):
ax1-----------ax2
bx1-bx2
scenario 3 (no overlapping):
ax1-----------ax2
bx1-----------bx2Hence, intersection can be discovered by:
-
determining the greater of the two starting locations
-
calculating the smaller of the two endpoints
ax1-----------ax2 bx1-----------bx2 : ax2 - bx1 ax1-----------ax2 bx1-----------bx2 : bx2 - ax1 overlapX = min(ax2,bx2) - max(ax1,bx1) overlapY = min(ay2,by2) - max(ay1,by1)
No overlapping: 0 0 0 0 / -1 -1 1 1
Expected: 4
java
class Solution {
public int computeArea(int ax1, int ay1, int ax2, int ay2, int bx1, int by1, int bx2, int by2) {
int areaOf1stRectangle = (ax2 - ax1) * (ay2 - ay1);
int areaOf2ndRectangle = (bx2 - bx1) * (by2 - by1);
int xOverlap = Math.min(ax2, bx2) - Math.max(ax1, bx1);
int yOverlap = Math.min(ay2, by2) - Math.max(ay1, by1);
int areaOverlap = (xOverlap > 0 && yOverlap > 0) ? xOverlap * yOverlap : 0;
return (areaOf1stRectangle + areaOf2ndRectangle - areaOverlap);
}
}225. Implement Stack using Queues
225. Implement Stack using Queues
Implement a last-in-first-out (LIFO) stack using only two queues. The implemented stack should support all the functions of a normal stack (push, top, pop, and empty).
Implement the MyStack class:void push(int x) Pushes element x to the top of the stack.
int pop() Removes the element on the top of the stack and returns it.
int top() Returns the element on the top of the stack.
boolean empty() Returns true if the stack is empty, false otherwise.
Notes:
You must use only standard operations of a queue, which means that only push to back, peek/pop from front, size and is empty operations are valid.
Depending on your language, the queue may not be supported natively. You may simulate a queue using a list or deque (double-ended queue) as long as you use only a queue's standard operations.
Example 1:Input
"MyStack", "push", "push", "top", "pop", "empty"
\[\], \[1\], \[2\], \[\], \[\], \[\]
Output
null, null, null, 2, 2, false
Explanation
MyStack myStack = new MyStack();
myStack.push(1);
myStack.push(2);
myStack.top(); // return 2
myStack.pop(); // return 2
myStack.empty(); // return False
Constraints:1 <= x <= 9
At most 100 calls will be made to push, pop, top, and empty.
All the calls to pop and top are valid.
Approach #1 (Two Queues, push - O(1)O(1), pop O(n)O(n) )
java
class MyStack {
//LinkedList inplements Queue interface
//Queue<String> queue = new LinkedList<String>();
Queue<Integer> queue1;
Queue<Integer> queue2;
public MyStack() {
queue1 = new LinkedList<> ();
queue2 = new LinkedList<> ();
}
public void push(int x) {
queue1.offer(x);
}
public int pop() {
int temp,ans = -1;
while(queue1.size()!=1){
temp = queue1.poll();
queue2.offer(temp);
}
ans = queue1.poll();
while(!queue2.isEmpty()){
temp = queue2.poll();
queue1.offer(temp);
}
return ans;
}
public int top() {
int temp = -1,ans = -1;
while(!queue1.isEmpty()){
temp = queue1.poll();
queue2.offer(temp);
}
ans = temp;
while(!queue2.isEmpty()){
temp = queue2.poll();
queue1.offer(temp);
}
return ans;
}
public boolean empty() {
return queue1.isEmpty();
}
}
/**
* Your MyStack object will be instantiated and called as such:
* MyStack obj = new MyStack();
* obj.push(x);
* int param_2 = obj.pop();
* int param_3 = obj.top();
* boolean param_4 = obj.empty();
*/Approach #2 (One Queue, push - O(n)O(n), pop O(1)O(1) )
Push
When we push an element into a queue, it will be stored at back of the queue due to queue's properties. But we need to implement a stack, where last inserted element should be in the front of the queue, not at the back. To achieve this we can invert the order of queue elements when pushing a new element.
java
private LinkedList<Integer> q1 = new LinkedList<>();
// Push element x onto stack.
public void push(int x) {
q1.add(x);
int sz = q1.size();
while (sz > 1) {
q1.add(q1.remove());
sz--;
}
}Time complexity : O(n)O(n). The algorithm removes n elements and inserts n + 1n+1 elements to q1 , where n is the stack size. This gives 2n + 12n+1 operations. The operations add and remove in linked lists has O(1)O(1) complexity.
Space complexity : O(1)O(1).
Pop
The last inserted element is always stored at the front of q1 and we can pop it for constant time.
java
// Removes the element on top of the stack.
public void pop() {
q1.remove();
}Complexity Analysis
- Time complexity : O(1)O(1).
- Space complexity : O(1)O(1).
Empty
Queue q1 contains all stack elements, so the algorithm checks if q1 is empty.
java
// Return whether the stack is empty.
public boolean empty() {
return q1.isEmpty();
}Time complexity : O(1)O(1).
Space complexity : O(1)O(1).
Top
The top element is always positioned at the front of q1. Algorithm return it.
java
// Get the top element.
public int top() {
return q1.peek();
}Time complexity : O(1)O(1).
Space complexity : O(1)O(1).
java
class MyStack {
Queue<Integer> q;
public MyStack() {
q = new LinkedList<>();
}
public void push(int x) {
int size = q.size();
q.offer(x);
while(size > 0){
q.offer(q.poll());
size--;
}
}
public int pop() {
return q.poll();
}
public int top() {
return q.peek();
}
public boolean empty() {
return q.isEmpty();
}
}0 ms 100.00% 40.1 MB 76.71%
Add1 1
Add2 1 2-> 21
Add3 21 3-> 321
java
public void push(int x) {
int size = q.size();
int[] temp = new int[size];
int i = 0;
while(i < size){
temp[i++] = q.peek();
q.poll();
}
q.offer(x);
for(int t:temp){
q.offer(t);
}
}offer,add 区别:
一些队列有大小限制,因此如果想在一个满的队列中加入一个新项,多出的项就会被拒绝。
这时新的 offer 方法就可以起作用了。它不是对调用 add() 方法抛出一个 unchecked 异常,而只是得到由 offer() 返回的 false。
poll,remove 区别:
remove() 和 poll() 方法都是从队列中删除第一个元素。remove() 的行为与 Collection 接口的版本相似, 但是新的 poll() 方法在用空集合调用时不是抛出异常,只是返回 null。因此新的方法更适合容易出现异常条件的情况。
peek,element区别:
element() 和 peek() 用于在队列的头部查询元素。与 remove() 方法类似,在队列为空时, element() 抛出一个异常,而 peek() 返回 null。
226. Invert Binary Tree
Given the root of a binary tree, invert the tree, and return its root.
Example 1:
Input: root = 4,2,7,1,3,6,9
Output: 4,7,2,9,6,3,1
Example 2:
Input: root = 2,1,3
Output: 2,3,1
Example 3:
Input: root = \[\]
Output: \[\]
Constraints:The number of nodes in the tree is in the range 0, 100.
-100 <= Node.val <= 100
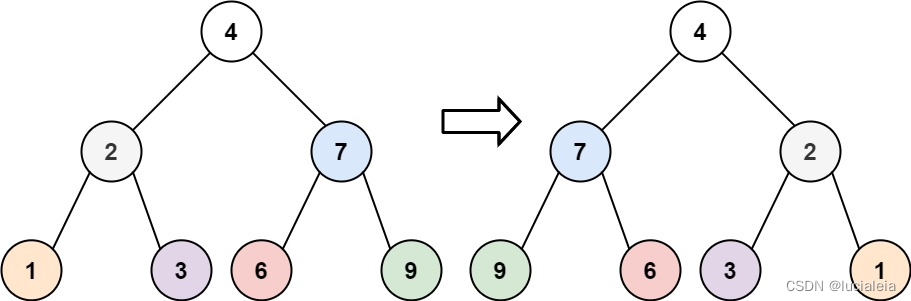
Recursive
Swift the left subtree and the right subtree.
Inverting from the subtree to root is equals to inverting from root to subtree
Invert the root and go to the subtree.
java
class Solution {
public TreeNode invertTree(TreeNode root) {
if(root==null) return root;
TreeNode temp;
temp = root.left;
root.left = root.right;
root.right = temp;
invertTree(root.left);
invertTree(root.right);
return root;
}
}227. Basic Calculator II
228. Summary Ranges
You are given a sorted unique integer array nums.
A range a,b is the set of all integers from a to b (inclusive).
Return the smallest sorted list of ranges that cover all the numbers in the array exactly. That is, each element of nums is covered by exactly one of the ranges, and there is no integer x such that x is in one of the ranges but not in nums.
Each range a,b in the list should be output as:
"a->b" if a != b
"a" if a == b
Example 1:Input: nums = 0,1,2,4,5,7
Output: "0-\>2","4-\>5","7"
Explanation: The ranges are:
0,2 --> "0->2"
4,5 --> "4->5"
7,7 --> "7"
Example 2:
Input: nums = 0,2,3,4,6,8,9
Output: "0","2-\>4","6","8-\>9"
Explanation: The ranges are:
0,0 --> "0"
2,4 --> "2->4"
6,6 --> "6"
8,9 --> "8->9"
Constraints:0 <= nums.length <= 20
-231 <= numsi <= 231 - 1
All the values of nums are unique.
nums is sorted in ascending order.
java
class Solution {
public List<String> summaryRanges(int[] nums) {
List<String> ans = new ArrayList<>();
if(nums.length == 0) return ans;
int begin = -1;
for(int i = 0; i < nums.length; i++){
begin = i;
//find continuous sequence
while(i+1<nums.length && nums[i]+1==nums[i+1]){
i++;
}
if(begin!=i){
//String s = (char)(nums[begin]+'0')+"->"+(char)(nums[i]+'0');
String s = ""+nums[begin]+"->"+nums[i];
ans.add(s);
}
else{
String s = Integer.toString(nums[i]);
ans.add(s);
}
}
return ans;
}
}229. Majority Element II
Given an integer array of size n, find all elements that appear more than ⌊ n/3 ⌋ times.
Example 1:Input: nums = 3,2,3
Output: 3
Example 2:
Input: nums = 1
Output: 1
Example 3:
Input: nums = 1,2
Output: 1,2
Constraints:1 <= nums.length <= 5 * 104
-109 <= numsi <= 109
Follow up: Could you solve the problem in linear time and in O(1) space?
Method 1
Use HashMap to count the number of appearances.
Time complexity :- O(NlogN)
Space Complexity :- O(N) Hash Map + O(N) List
java
public List<Integer> majorityElement(int[] nums) {
Map<Integer, Integer> map = new HashMap<>();
for (int n : nums) {
if (!map.containsKey(n))
map.put(n, 1);
else {
map.put(n, map.get(n) + 1);
}
}
List<Integer> majority = new ArrayList<>();
for (Map.Entry<Integer, Integer> entries : map.entrySet()) {
if (entries.getValue() > Math.floor(nums.length / 3)) {
majority.add(entries.getKey());
}
}
return majority;
}Method 2
Sort the array and count every distinct element.
java
class Solution {
public List<Integer> majorityElement(int[] nums) {
Arrays.sort(nums);
List<Integer> ans = new ArrayList<Integer>();
int count = 1;
int len = nums.length/3;
for(int i = 0; i < nums.length; i++){
count = 1;
while(i+1 < nums.length && nums[i+1]==nums[i]){
count++;
i++;
}
if(count>len){
ans.add(nums[i]);
}
}
return ans;
}
}Method 3 Boyer-Moore vote

Given an integer array of size n, find all elements that appear more than ⌊ n/3 ⌋ times.
Only 1 - 2 possible number.
Time Compexity :- O(N)
Space Complexity :- O(1)
java
public List<Integer> majorityElement(int[] nums) {
int num1 = Integer.MAX_VALUE, num2 = Integer.MAX_VALUE, count1 = 0, count2 = 0, len = nums.length;
// collecting votes
for (int n : nums) {
if (n == num1) count1++;
else if (n == num2) count2++;
else if (count1 == 0) {
num1 = n;
count1 = 1;
} else if (count2 == 0) {
num2 = n;
count2 = 1;
} else {
count1--;
count2--;
}
}
// now checking if num1 and num2 occurs more than n/3 times i.e validating vote count
count1 = 0;
count2 = 0;
for (int n : nums) {
if (n == num1) count1++;
if (n == num2) count2++;
}
List<Integer> result = new ArrayList<>();
if (count1 > len / 3)
result.add(num1);
if (count2 > len / 3)
result.add(num2);
return result;
}There can be at most k - 1 major element in an array if the major element appears more than ⌊n / k⌋ times.
In the begining, we assume there are k - 1 candidates:
These candidates can take any value;
The vote of these candidates must be 0
int num1 = any integer, num2 = Iany integer, count1 = 0, count2 = 0Then we traverse the array:
If current element equals to the value of any candidate, the candidate get a vote; (one voter can only vote for one candidate)
if (n == num1) count1++;If the vote of any candidate is 0, then current element is set as a new candidate and he can get a vote immediately; (A voter can also be elected)
if (count1 == 0) {
num1 = n;
count1 = 1;
}Otherwise, current element vote against all candidates and all candidates lose a vote.
else {
count1--;
count2--;
}Assume you're voting for the president. If you want to select Trump or Biden. Ok, just vote for them (case 1). If Trump is impeached or Biden is dead, now you can run for the president (case 2). If you want to vote for Lebron James, of course both Biden or Trump won't get your vote (case 3).
After election, we need to count the vote of each candidate to see whether they are qualified for the position, i.e., the vote is larger than ⌊n / k⌋.
230. Kth Smallest Element in a BST
230. Kth Smallest Element in a BST
Given the root of a binary search tree, and an integer k, return the kth smallest value (1-indexed) of all the values of the nodes in the tree.
Example 1:Input: root = 3,1,4,null,2, k = 1
Output: 1
Example 2:
Input: root = 5,3,6,2,4,null,null,1, k = 3
Output: 3
Constraints:The number of nodes in the tree is n.
1 <= k <= n <= 104
0 <= Node.val <= 104
Follow up: If the BST is modified often (i.e., we can do insert and delete operations) and you need to find the kth smallest frequently, how would you optimize?
Use Inorder traversal to visit the BST and get the ascending sequence.
Recursive dfs
java
class Solution {
private static int ans;
private static int count;
public int kthSmallest(TreeNode root, int k) {
count = k;
trackBST(root);
return ans;
}
private void trackBST(TreeNode root){
if(root.left!=null) trackBST(root.left);
count--;
if(count==0){
ans = root.val;
return ;
}
if(root.right!=null) trackBST(root.right);
}
}0 ms 100.00% 42.5 MB 71.17%
k不作为全局变量 在递归时不共享
JAVA 对象传递(数组、类、接口)是引用传递,原始类型数据(整形、浮点型、字符型、布尔型)传递是值传递。
Stack
java
public int kthSmallest(TreeNode root, int k) {
//DFS 中序遍历
Deque<TreeNode> st = new ArrayDeque<>();
TreeNode p = root;
//把左子树左结点都进栈
while(p!=null){
st.addFirst(p);
p = p.left;
}
while(!st.isEmpty()){
p = st.removeFirst();
k--;
if(k==0){
return p.val;
}
p = p.right;
//右子树也从左结点开始入栈
while(p!=null){
st.addFirst(p);
p = p.left;
}
}
return -1;
}0ms 100.00% 44.8 MB 7.91%
231. Power of Two
Given an integer n, return true if it is a power of two. Otherwise, return false.
An integer n is a power of two, if there exists an integer x such that n == 2x.
Example 1:Input: n = 1
Output: true
Explanation: 20 = 1
Example 2:
Input: n = 16
Output: true
Explanation: 24 = 16
Example 3:
Input: n = 3
Output: false
Constraints:-231 <= n <= 231 - 1
Consider edge cases: n == 1, 0, negative
java
class Solution {
public boolean isPowerOfTwo(int n) {
if(n == 1){
return true;
}
if(n <= 0){
return false;
}
while(n > 2){
if(n % 2 == 1){
return false;
}
n >>= 1;
}
return true;
}
}1 ms100.00% 39.5 MB 84.15%
java
class Solution {
public boolean isPowerOfTwo(int n) {
if(n == 1) return true;
if(n <= 0) return false;
while(n > 1){
if(n % 2 == 1){
return false;
}
n /= 2;
}
return true;
}
}
java
public boolean isPowerOfTwo(int n) {
return n>0 && Integer.bitCount(n) == 1;
}The bitCount() method of Integer class of java.lang package returns the count of the number of one-bits in the two's complement binary representation of an int value. This function is sometimes referred to as the population count.
232. Implement Queue using Stacks
232. Implement Queue using Stacks
Implement a first in first out (FIFO) queue using only two stacks. The implemented queue should support all the functions of a normal queue (push, peek, pop, and empty).
Implement the MyQueue class:
void push(int x) Pushes element x to the back of the queue.
int pop() Removes the element from the front of the queue and returns it.
int peek() Returns the element at the front of the queue.
boolean empty() Returns true if the queue is empty, false otherwise.
Notes:
You must use only standard operations of a stack, which means only push to top, peek/pop from top, size, and is empty operations are valid.
Depending on your language, the stack may not be supported natively. You may simulate a stack using a list or deque (double-ended queue) as long as you use only a stack's standard operations.
Example 1:Input
"MyQueue", "push", "push", "peek", "pop", "empty"
\[\], \[1\], \[2\], \[\], \[\], \[\]
Output
null, null, null, 1, 1, false
Explanation
MyQueue myQueue = new MyQueue();
myQueue.push(1); // queue is: 1
myQueue.push(2); // queue is: 1, 2 (leftmost is front of the queue)
myQueue.peek(); // return 1
myQueue.pop(); // return 1, queue is 2
myQueue.empty(); // return false
Constraints:1 <= x <= 9
At most 100 calls will be made to push, pop, peek, and empty.
All the calls to pop and peek are valid.
Follow-up: Can you implement the queue such that each operation is amortized O(1) time complexity? In other words, performing n operations will take overall O(n) time even if one of those operations may take longer.
Two stack
java
class MyQueue {
Stack<Integer> st1;
Stack<Integer> st2;
public MyQueue() {
st1 = new Stack<Integer>();
st2 = new Stack<Integer>();
}
public void push(int x) {
st1.push(x);
}
public int pop() {
int temp;
int ans;
while(!st1.isEmpty()){
temp = st1.pop();
st2.push(temp);
}
ans = st2.pop();
while(!st2.isEmpty()){
temp = st2.pop();
st1.push(temp);
}
return ans;
}
public int peek() {
int temp;
int ans;
while(!st1.isEmpty()){
temp = st1.pop();
st2.push(temp);
}
ans = st2.peek();
while(!st2.isEmpty()){
temp = st2.pop();
st1.push(temp);
}
return ans;
}
public boolean empty() {
return st1.isEmpty();
}
}One Stack
java
class MyQueue {
Stack<Integer> s;
public MyQueue() {
s = new Stack<>();
}
public void push(int x) {
int[] temp = new int[s.size()];
int i = 0;
while(!s.isEmpty()){
temp[i++] = s.peek();
s.pop();
}
s.add(x);
while(i > 0){
s.add(temp[--i]);
}
}
public int pop() {
return s.pop();
}
public int peek() {
return s.peek();
}
public boolean empty() {
return s.empty();
}
}empty() isEmpty()
234. Palindrome Linked List
Given the head of a singly linked list, return true if it is a palindrome or false otherwise.
Example 1:Input: head = 1,2,2,1
Output: true
Example 2:
Input: head = 1,2
Output: false
Constraints:The number of nodes in the list is in the range 1, 105.
0 <= Node.val <= 9
Follow up: Could you do it in O(n) time and O(1) space?
Use array to copy half of the list: O(n) time and O(n) space
Reverse the first half part of the list
Reverse the second half of the list
java
public boolean isPalindrome(ListNode head) {
ListNode slow = head, fast = head, prev, temp;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
prev = slow;
slow = slow.next;
prev.next = null;
while (slow != null) {
temp = slow.next;
slow.next = prev;
prev = slow;
slow = temp;
}
fast = head;
slow = prev;
while (slow != null) {
if (fast.val != slow.val) return false;
fast = fast.next;
slow = slow.next;
}
return true;
}235. Lowest Common Ancestor of a Binary Search Tree
235. Lowest Common Ancestor of a Binary Search Tree
Given a binary search tree (BST), find the lowest common ancestor (LCA) node of two given nodes in the BST.
According to the definition of LCA on Wikipedia: "The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself)."
Example 1:Input: root = 6,2,8,0,4,7,9,null,null,3,5, p = 2, q = 8
Output: 6
Explanation: The LCA of nodes 2 and 8 is 6.
Example 2:
Input: root = 6,2,8,0,4,7,9,null,null,3,5, p = 2, q = 4
Output: 2
Explanation: The LCA of nodes 2 and 4 is 2, since a node can be a descendant of itself according to the LCA definition.
Example 3:
Input: root = 2,1, p = 2, q = 1
Output: 2
Constraints:The number of nodes in the tree is in the range 2, 105.
-109 <= Node.val <= 109
All Node.val are unique.
p != q
p and q will exist in the BST.
- if both p and q exist in Tree rooted at root, then return their LCA
- if neither p and q exist in Tree rooted at root, then return null
- if only one of p or q (NOT both of them), exists in Tree rooted at root, return it
java
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if( root == p || root == q || root == null)
return root;
TreeNode left = lowestCommonAncestor( root.left, p, q);
TreeNode right = lowestCommonAncestor( root.right, p, q);
if(left == null)
return right;
else if (right == null)
return left;
else
return root;
}
}parent pointer and path
父节点指针表:
使用哈希表 parentMap 记录每个节点的父节点。我们通过深度优先搜索(DFS)遍历树,记录每个节点的父节点。
使用一个栈来进行遍历,每次从栈中取出节点,并将其子节点及其父节点关系记录到 parentMap 中。
查找 p 的祖先:
一旦建立了 parentMap,我们可以从节点 p 开始,一直追溯到根节点,并将所有的祖先节点存储到集合 ancestors 中。
查找 q 的第一个公共祖先:
从节点 q 开始追溯,直到找到第一个出现在 p 的祖先集合中的节点。这就是 p 和 q 的最近公共祖先。
java
import java.util.HashMap;
import java.util.HashSet;
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
// Map to store parent pointers
HashMap<TreeNode, TreeNode> parentMap = new HashMap<>();
// Stack for tree traversal
Stack<TreeNode> stack = new Stack<>();
// Initialize with the root (root has no parent)
parentMap.put(root, null);
stack.push(root);
// Traverse the tree until we find both p and q
while (!parentMap.containsKey(p) || !parentMap.containsKey(q)) {
TreeNode node = stack.pop();
// Add the children to the stack and record their parent
if (node.left != null) {
parentMap.put(node.left, node);
stack.push(node.left);
}
if (node.right != null) {
parentMap.put(node.right, node);
stack.push(node.right);
}
}
// Create a set to store the ancestors of p
HashSet<TreeNode> ancestors = new HashSet<>();
// Traverse from p to the root, adding all ancestors of p to the set
while (p != null) {
ancestors.add(p);
p = parentMap.get(p);
}
// Now traverse from q to the root. The first ancestor of q that is in p's ancestor set is the LCA
while (!ancestors.contains(q)) {
q = parentMap.get(q);
}
return q; // q is now the lowest common ancestor
}
}Use dfs to find the ancester stack of the two Node. Compare the ancester.
java
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
Deque<TreeNode> pStack = new ArrayDeque<TreeNode>();
Deque<TreeNode> qStack = new ArrayDeque<TreeNode>();
TreeNode target = null;
if (findPath(root, p, pStack) && findPath(root, q, qStack)) {
while (!pStack.isEmpty()) {
TreeNode pNode = pStack.removeFirst();
if (qStack.contains(pNode))
target = pNode;
}
}
return target;
}
private boolean findPath(TreeNode root, TreeNode node, Deque<TreeNode> stack) {
if (root == null)
return false;
if (root == node) {
stack.addFirst(root);
return true;
} else {
if (findPath(root.left, node, stack) || findPath(root.right, node, stack)) {
stack.addFirst(root);
return true;
}
}
return false;
}
}5 ms 98.48% 43.7 MB 96.27%
Two stack
java
import java.util.Stack;
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
// Stacks to hold the paths from root to p and from root to q
Stack<TreeNode> pathToP = new Stack<>();
Stack<TreeNode> pathToQ = new Stack<>();
// Find path to p and path to q
findPath(root, p, pathToP);
findPath(root, q, pathToQ);
// Compare the paths
TreeNode lca = null;
while (!pathToP.isEmpty() && !pathToQ.isEmpty() && pathToP.peek() == pathToQ.peek()) {
lca = pathToP.pop();
pathToQ.pop();
}
return lca;
}
// Helper function to find the path from root to target
private boolean findPath(TreeNode root, TreeNode target, Stack<TreeNode> path) {
if (root == null) {
return false;
}
// Add current node to path
path.push(root);
// Check if current node is the target
if (root == target) {
return true;
}
// Check if target is in the left or right subtree
if (findPath(root.left, target, path) || findPath(root.right, target, path)) {
return true;
}
// If target is not found, backtrack
path.pop();
return false;
}
}239. Sliding Window Maximum
You are given an array of integers nums, there is a sliding window of size k which is moving from the very left of the array to the very right. You can only see the k numbers in the window. Each time the sliding window moves right by one position.
Return the max sliding window.
Example 1:Input: nums = 1,3,-1,-3,5,3,6,7, k = 3
Output: 3,3,5,5,6,7
Explanation:
Window position Max
1 3 -1 -3 5 3 6 7 3
1 3 -1 -3 5 3 6 7 3
1 3 -1 -3 5 3 6 7 5
1 3 -1 -3 5 3 6 7 5
1 3 -1 -3 5 3 6 7 6
1 3 -1 -3 5 3 6 7 7
Example 2:
Input: nums = 1, k = 1
Output: 1
Constraints:1 <= nums.length <= 105
-104 <= numsi <= 104
1 <= k <= nums.length
java
import java.util.*;
class MonotonicQueue {
private Deque<Integer> deque = new LinkedList<>();
// Push a new element into the queue
public void push(int n) {
while (!deque.isEmpty() && deque.peekLast() < n) {
deque.pollLast();
}
deque.offerLast(n);
}
// Get the maximum element from the queue
public int max() {
return deque.peekFirst();
}
// Pop an element from the queue
public void pop(int n) {
if (!deque.isEmpty() && deque.peekFirst() == n) {
deque.pollFirst();
}
}
}
public class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if (nums == null || nums.length == 0) {
return new int[0];
}
MonotonicQueue window = new MonotonicQueue();
List<Integer> res = new ArrayList<>();
for (int i = 0; i < nums.length; i++) {
if (i < k - 1) {
window.push(nums[i]);
} else {
window.push(nums[i]);
res.add(window.max());
window.pop(nums[i - k + 1]);
}
}
return res.stream().mapToInt(i -> i).toArray();
}
public static void main(String[] args) {
Solution solution = new Solution();
int[] nums = {1,3,-1,-3,5,3,6,7};
int k = 3;
int[] result = solution.maxSlidingWindow(nums, k);
System.ou
t.println(Arrays.toString(result));
}
}354. Russian Doll Envelopes
You are given a 2D array of integers envelopes where envelopesi = wi, hi represents the width and the height of an envelope.
One envelope can fit into another if and only if both the width and height of one envelope are greater than the other envelope's width and height.
Return the maximum number of envelopes you can Russian doll (i.e., put one inside the other).
Note: You cannot rotate an envelope.
Example 1:Input: envelopes = \[5,4,6,4,6,7,2,3]
Output: 3
Explanation: The maximum number of envelopes you can Russian doll is 3 (2,3 => 5,4 => 6,7).
Example 2:
Input: envelopes = \[1,1,1,1,1,1]
Output: 1
Constraints:1 <= envelopes.length <= 105
envelopesi.length == 2
1 <= wi, hi <= 105
这道题⽬其实是**最⻓递增⼦序列(Longes Increasing Subsequence,简写为LIS)**的⼀个变种,因为很显然,每次合法的嵌套是⼤的套⼩的,相当于找⼀个最⻓递增的⼦序列,其⻓度就是最多能嵌套的信封个数。
Each legal nesting is a large nesting of small ones, which is equivalent to finding the longest increasing subsequence, the length of which is the maximum number of envelopes that can be nested.
但是难点在于,标准的 LIS 算法只能在数组中寻找最⻓⼦序列,⽽我们的信封是由 (w, h) 这样的⼆维数对形式表⽰的,如何把 LIS 算法运⽤过来呢?
先对宽度 w 进⾏升序排序,如果遇到 w 相同的情况,则按照⾼度 h 降序排序。之后把所有的 h 作为⼀个数组,在这个数组上计算 LIS 的⻓度就是答案。
First sort the width w in ascending order. If w is the same, sort by height h in descending order.
对于宽度 w 相同的数对,要对其⾼度 h 进⾏降序排序。
因为两个宽度相同的信封不能相互包含的,逆序排序保证在 w 相同的数对中最多只选取⼀个。
java
// envelopes = [[w, h], [w, h]...]
public int maxEnvelopes(int[][] envelopes) {
int n = envelopes.length;
// 按宽度升序排列,如果宽度⼀样,则按⾼度降序排列
Arrays.sort(envelopes, new Comparator<int[]>()
{
public int compare(int[] a, int[] b) {
return a[0] == b[0] ?
b[1] - a[1] : a[0] - b[0];
}
});
// 对⾼度数组寻找 LIS
int[] height = new int[n];
for (int i = 0; i < n; i++)
height[i] = envelopes[i][1];
return lengthOfLIS(height);
}
/* 返回 nums 中 LIS 的⻓度 */
public int lengthOfLIS(int[] nums) {
int piles = 0, n = nums.length;
int[] top = new int[n];
for (int i = 0; i < n; i++) {
// 要处理的扑克牌
int poker = nums[i];
int left = 0, right = piles;
// ⼆分查找插⼊位置
while (left < right) {
int mid = (left + right) / 2;
if (top[mid] >= poker)
right = mid;
else
left = mid + 1;
}
if (left == piles) piles++;
// 把这张牌放到牌堆顶
top[left] = poker;
}
// 牌堆数就是 LIS ⻓度
return piles;
}355. Design Twitter
Design a simplified version of Twitter where users can post tweets, follow/unfollow another user, and is able to see the 10 most recent tweets in the user's news feed.
Implement the Twitter class:Twitter() Initializes your twitter object.
void postTweet(int userId, int tweetId) Composes a new tweet with ID tweetId by the user userId. Each call to this function will be made with a unique tweetId.
List getNewsFeed(int userId) Retrieves the 10 most recent tweet IDs in the user's news feed. Each item in the news feed must be posted by users who the user followed or by the user themself. Tweets must be ordered from most recent to least recent.
void follow(int followerId, int followeeId) The user with ID followerId started following the user with ID followeeId.
void unfollow(int followerId, int followeeId) The user with ID followerId started unfollowing the user with ID followeeId.
Example 1:Input
"Twitter", "postTweet", "getNewsFeed", "follow", "postTweet", "getNewsFeed", "unfollow", "getNewsFeed"
\[\], \[1, 5\], \[1\], \[1, 2\], \[2, 6\], \[1\], \[1, 2\], \[1\]
Output
null, null, \[5\], null, null, \[6, 5\], null, \[5\]
Explanation
Twitter twitter = new Twitter();
twitter.postTweet(1, 5); // User 1 posts a new tweet (id = 5).
twitter.getNewsFeed(1); // User 1's news feed should return a list with 1 tweet id -> 5. return 5
twitter.follow(1, 2); // User 1 follows user 2.
twitter.postTweet(2, 6); // User 2 posts a new tweet (id = 6).
twitter.getNewsFeed(1); // User 1's news feed should return a list with 2 tweet ids -> 6, 5. Tweet id 6 should precede tweet id 5 because it is posted after tweet id 5.
twitter.unfollow(1, 2); // User 1 unfollows user 2.
twitter.getNewsFeed(1); // User 1's news feed should return a list with 1 tweet id -> 5, since user 1 is no longer following user 2.
Constraints:1 <= userId, followerId, followeeId <= 500
0 <= tweetId <= 104
All the tweets have unique IDs.
At most 3 * 104 calls will be made to postTweet, getNewsFeed, follow, and unfollow.
twitter list
Stack< Pair<userId,twitterId>> order(newest to oldest): Use ArrayDeque for stack
follow list
HashMap<followerId,HashSet> HashMap HashSet for O(1) get set check existed
java
class Twitter {
Deque<Pair<Integer,Integer>> twitterList;
HashMap<Integer,HashSet<Integer>> followList;
public Twitter() {
twitterList = new ArrayDeque<>();
followList = new HashMap<>();
}
public void postTweet(int userId, int tweetId) {
Pair<Integer,Integer> newPost = new Pair<>(userId,tweetId);
twitterList.push(newPost);
}
public List<Integer> getNewsFeed(int userId) {
List<Integer> newsFeed = new ArrayList<>();// 10
int count = 0;
for(Pair<Integer,Integer> twitter:twitterList){
if(count==10){
break;
}
if(twitter.getKey()==userId || (followList.containsKey(userId) &&followList.get(userId).contains(twitter.getKey()))){
newsFeed.add(twitter.getValue());
count++;
}
}
return newsFeed;
}
public void follow(int followerId, int followeeId) {
if(followList.containsKey(followerId)){
followList.get(followerId).add(followeeId);
}else{
HashSet<Integer> set = new HashSet<>();
set.add(followeeId);
followList.put(followerId,set);
}
}
public void unfollow(int followerId, int followeeId) {
if(followList.containsKey(followerId)){
followList.get(followerId).remove(followeeId);
}
}
}
/**
* Your Twitter object will be instantiated and called as such:
* Twitter obj = new Twitter();
* obj.postTweet(userId,tweetId);
* List<Integer> param_2 = obj.getNewsFeed(userId);
* obj.follow(followerId,followeeId);
* obj.unfollow(followerId,followeeId);
*/7ms 100.00% 41.97MB 13.92%
O(N) O(N)
Object Design
Add a time
create object Tweet, User
Maintain a tweet list
User maintain a follow set
Use Priority queue for time order
java
class Twitter {
private static int timestamp = 0;
private static class Tweet {}
private static class User {}
...
}
java
class Tweet {
private int id;
private int time;
private Tweet next;
// 需要传⼊推⽂内容(id)和发⽂时间
public Tweet(int id, int time) {
this.id = id;
this.time = time;
this.next = null;
}
}
// static int timestamp = 0
class User {
private int id;
public Set<Integer> followed;
// ⽤户发表的推⽂链表头结点
public Tweet head;
public User(int userId) {
followed = new HashSet<>();
this.id = userId;
this.head = null;
// 关注⼀下⾃⼰
follow(id);
}
public void follow(int userId) {
followed.add(userId);
}
public void unfollow(int userId) {
// 不可以取关⾃⼰
if (userId != this.id)
followed.remove(userId);
}
public void post(int tweetId) {
Tweet twt = new Tweet(tweetId, timestamp);
timestamp++;
// 将新建的推⽂插⼊链表头
// 越靠前的推⽂ time 值越⼤
twt.next = head;
head = twt;
}
}
java
public List<Integer> getNewsFeed(int userId) {
List<Integer> res = new ArrayList<>();
if (!userMap.containsKey(userId)) return res;
// 关注列表的⽤户 Id
Set<Integer> users = userMap.get(userId).followed;
// ⾃动通过 time 属性从⼤到⼩排序,容量为 users 的⼤⼩
PriorityQueue<Tweet> pq = new PriorityQueue<>(users.size(), (a, b)->(b.time - a.time));
// 先将所有链表头节点插⼊优先级队列
for (int id : users) {
Tweet twt = userMap.get(id).head;
if (twt == null) continue;
pq.add(twt);
}
while (!pq.isEmpty()) {
// 最多返回 10 条就够了
if (res.size() == 10) break;
// 弹出 time 值最⼤的(最近发表的)
Tweet twt = pq.poll();
res.add(twt.id);
// 将下⼀篇 Tweet 插⼊进⾏排序
if (twt.next != null)
pq.add(twt.next);
}
return res;
}399. Evaluate Division
https://leetcode.com/problems/evaluate-division/description/
You are given an array of variable pairs equations and an array of real numbers values, where equationsi = Ai, Bi and valuesi represent the equation Ai / Bi = valuesi. Each Ai or Bi is a string that represents a single variable.
You are also given some queries, where queriesj = Cj, Dj represents the jth query where you must find the answer for Cj / Dj = ?.
Return the answers to all queries. If a single answer cannot be determined, return -1.0.
Note: The input is always valid. You may assume that evaluating the queries will not result in division by zero and that there is no contradiction.
Note: The variables that do not occur in the list of equations are undefined, so the answer cannot be determined for them.
Example 1:Input: equations = \["a","b","b","c"], values = 2.0,3.0, queries = \["a","c","b","a","a","e","a","a","x","x"]
Output: 6.00000,0.50000,-1.00000,1.00000,-1.00000
Explanation:
Given: a / b = 2.0, b / c = 3.0
queries are: a / c = ?, b / a = ?, a / e = ?, a / a = ?, x / x = ?
return: 6.0, 0.5, -1.0, 1.0, -1.0
note: x is undefined => -1.0
Example 2:
Input: equations = \["a","b","b","c","bc","cd"], values = 1.5,2.5,5.0, queries = \["a","c","c","b","bc","cd","cd","bc"]
Output: 3.75000,0.40000,5.00000,0.20000
Example 3:
Input: equations = \["a","b"], values = 0.5, queries = \["a","b","b","a","a","c","x","y"]
Output: 0.50000,2.00000,-1.00000,-1.00000
Constraints:1 <= equations.length <= 20
equationsi.length == 2
1 <= Ai.length, Bi.length <= 5
values.length == equations.length
0.0 < valuesi <= 20.0
1 <= queries.length <= 20
queriesi.length == 2
1 <= Cj.length, Dj.length <= 5
Ai, Bi, Cj, Dj consist of lower case English letters and digits.
java
class Solution {
//java.lang.StackOverflowError
private double dfs(Map<String,Map<String,Double>> graph, String from,String to,HashSet<String> visited){
if(visited.contains(from)){
return -1;
}
if(!graph.containsKey(from) || !graph.containsKey(to)){
return -1;
}
visited.add(from);
if(graph.get(from).containsKey(to)){
return graph.get(from).get(to);
}
for(Map.Entry<String,Double> entry:graph.get(from).entrySet()){
String neighbor = entry.getKey();
if(!visited.contains(neighbor)){//if neighbor is not visited
double result = dfs(graph,neighbor,to,visited);
if(result!=-1){
return entry.getValue()*result;
}
}
}
visited.remove(from);
return -1;
}
public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) {
//node is string use Map<> for node,weighted edge use Map<>
Map<String,Map<String,Double>> graph = new HashMap<>();
int edgeNum = values.length;
for(int i = 0; i < edgeNum; i++){
String from = equations.get(i).get(0);
String to = equations.get(i).get(1);
graph.putIfAbsent(from,new HashMap<>());
graph.putIfAbsent(to,new HashMap<>());
graph.get(from).put(to,values[i]);
graph.get(to).put(from,1/values[i]);
}
int len = queries.size();
double[] result = new double[len];
for(int i = 0; i < len; i++){
// 每次搜索时都初始化一个新的访问节点集合
HashSet<String> visited = new HashSet<>();
result[i] = dfs(graph,queries.get(i).get(0),queries.get(i).get(1),visited);
}
return result;
}
}错误
java
class Solution {
private double dfs(Map<String,Map<String,Double>> graph, String from,String to){
if(!graph.containsKey(from) || !graph.containsKey(to)){
return -1;
}
if(graph.get(from).containsKey(to)){
return graph.get(from).get(to);
}else{
for(Map.Entry<String,Double> entry:graph.get(from).entrySet()){
if(dfs(graph,from,entry.getKey())!=-1){
return entry.getValue()*dfs(graph,entry.getKey(),to);
}
}
}
return -1;
}
public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) {
//node is string use Map<> for node,weighted edge use Map<>
Map<String,Map<String,Double>> graph = new HashMap<>();
int edgeNum = values.length;
for(int i = 0; i < edgeNum; i++){
String from = equations.get(i).get(0);
String to = equations.get(i).get(1);
graph.putIfAbsent(from,new HashMap<>());
graph.putIfAbsent(to,new HashMap<>());
graph.get(from).put(to,values[i]);
graph.get(to).put(from,1/values[i]);
}
int len = queries.size();
double[] result = new double[len];
for(int i = 0; i < len; i++){
result[i] = dfs(graph,queries.get(i).get(0),queries.get(i).get(1));
}
return result;
}
}你的代码出现 java.lang.StackOverflowError 主要是由于递归调用 dfs 函数时,没有适当地处理已经访问过的节点,导致了无限递归。特别是在图的遍历中,如果没有标记已经访问的节点,很容易陷入循环,导致栈溢出。
如何修复 StackOverflowError:
为了避免重复访问相同的节点,可以使用一个 Set 来跟踪当前递归路径中已经访问过的节点
DFS 访问邻接表,HashSet visited,回溯,在dfs最后将当前访问节点移除,确保在访问每一条线路时,不会重复循环
java
if(dfs(graph,from,entry.getKey(),visited)!=-1){
return entry.getValue() * dfs(graph,entry.getKey(),to,visited);
}这里你在 if 条件中递归调用了一次 dfs,然后在 return 中又递归调用了一次 dfs。这意味着你会进行不必要的多次递归调用,可能导致递归深度过深,并且会对性能产生负面影响。
1091. Shortest Path in Binary Matrix
https://leetcode.com/problems/shortest-path-in-binary-matrix/
Given an n x n binary matrix grid, return the length of the shortest clear path in the matrix. If there is no clear path, return -1.
A clear path in a binary matrix is a path from the top-left cell (i.e., (0, 0)) to the bottom-right cell (i.e., (n - 1, n - 1)) such that:
All the visited cells of the path are 0.All the adjacent cells of the path are 8-directionally connected (i.e., they are different and they share an edge or a corner).
The length of a clear path is the number of visited cells of this path.
Example 1:Input: grid = \[0,1,1,0]
Output: 2
Example 2:
Input: grid = \[0,0,0,1,1,0,1,1,0]
Output: 4
Example 3:
Input: grid = \[1,0,0,1,1,0,1,1,0]
Output: -1
Constraints:n == grid.length
n == gridi.length
1 <= n <= 100
gridij is 0 or 1
In the problem, you're given a binary matrix (grid) where 0 represents a passable cell (you can walk through it), and 1 represents an obstacle (you cannot walk through it).
BFS implement Queue interface with LinkedList
visited current node, then push all its neighborhood into queue.
matrix grid, int\[\]\[\] grid we store the coordinate into the queue
Use the grid\[\]\[\] array itself to store the distance, 0 represent path can be visited, when visited a new node add one based on the previous store in grid.
If the grid\[\]\[\] is not 0, means it already visited
edge condition:
error: if the start or end cell is not 0 , no available path, return -1
success: meet length-1length-1
java
class Solution {
public int shortestPathBinaryMatrix(int[][] grid) {
int n = grid.length;
if (grid[0][0] != 0 || grid[n - 1][n - 1] != 0) {
return -1; // If start or end is blocked
}
Queue<int[]> queue = new LinkedList<>(); // store the coordinate [x,y]
//define the direction in two-dimensional array {{,},{,},{,},{,}}
int[][] direction = new int[][]{{0,-1},{0,1},{-1,0},{1,0},{-1,-1},{1,1},{-1,1},{1,-1}};
queue.offer(new int[]{0, 0});
grid[0][0] = 1;
while(queue.size()>0){
int[] cell = queue.poll();
int x = cell[0];
int y = cell[1];
if(x == n-1 && y == n-1){
return grid[x][y];
}
for(int i = 0; i < 8; i++){
int nextX = x + direction[i][0];
int nextY = y + direction[i][1];
//validate next step
if(nextX>=0 && nextY>=0 && nextX < n && nextY < n && grid[nextX][nextY] == 0){
// store the path length in grid, if grid[x][y] == 0 : unvisited, update when visit new cell
queue.offer(new int[]{nextX, nextY});
grid[nextX][nextY] = grid[x][y]+1;
}
}
}
return -1;
}
}438. Find All Anagrams in a String
https://leetcode.com/problems/find-all-anagrams-in-a-string/description/
Given two strings s and p, return an array of all the start indices of p's anagrams in s. You may return the answer in any order.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
Example 1:Input: s = "cbaebabacd", p = "abc"
Output: 0,6
Explanation:
The substring with start index = 0 is "cba", which is an anagram of "abc".
The substring with start index = 6 is "bac", which is an anagram of "abc".
Example 2:
Input: s = "abab", p = "ab"
Output: 0,1,2
Explanation:
The substring with start index = 0 is "ab", which is an anagram of "ab".
The substring with start index = 1 is "ba", which is an anagram of "ab".
The substring with start index = 2 is "ab", which is an anagram of "ab".
Constraints:1 <= s.length, p.length <= 3 * 104
s and p consist of lowercase English letters.
edge p.length()>s.length()
java
class Solution {
public boolean check(int[] dict){
for(int i:dict){
if(i!=0){
return false;
}
}
return true;
}
public List<Integer> findAnagrams(String s, String p) {
List<Integer> result = new ArrayList<>();
int[] dict = new int[26];
for(char c:p.toCharArray()){
dict[c-'a']++;
}
int pLen = p.length();
int sLen = s.length();
if(pLen > sLen){
return result;
}
for(int i = 0; i < pLen; i++){
char c = s.charAt(i);
dict[c-'a']--;
}
if(check(dict)){
result.add(0);
}
for(int i = 1; i <= sLen - pLen; i++){
char right = s.charAt(i + pLen-1);
char left = s.charAt(i-1);
dict[right-'a']--;
dict[left-'a']++;
if(check(dict)){
result.add(i);
}
}
return result;
}
}474
https://leetcode.com/problems/ones-and-zeroes/
567. Permutation in String
Given two strings s1 and s2, return true if s2 contains a permutation of s1, or false otherwise.
In other words, return true if one of s1's permutations is the substring of s2.
Example 1:Input: s1 = "ab", s2 = "eidbaooo"
Output: true
Explanation: s2 contains one permutation of s1 ("ba").
Example 2:
Input: s1 = "ab", s2 = "eidboaoo"
Output: false
Constraints:1 <= s1.length, s2.length <= 104
s1 and s2 consist of lowercase English letters.
不是backtracking 因为不需要全部可行permutation,只需要一个
permutation of s1 -> 说明s2的子串为s1的排列,即和s1有相同的字符频率
Sliding Window
fixed length sliding window
length = s1.length()
java
class Solution {
public boolean check(int[] dict){
for(int i:dict){
if(i!=0){
return false;
}
}
return true;
}
public boolean checkInclusion(String s1, String s2) {
int[] dict = new int[26];
for(char c:s1.toCharArray()){
dict[c-'a']++;
}
int len1 = s1.length();
int len2 = s2.length();
if(len2 < len1){
return false;
}
for(int i = 0; i < len1; i++){
char c = s2.charAt(i);
dict[c-'a']--;
}
if(check(dict)){
return true;
}
for(int i = len1; i < len2; i++){
char right = s2.charAt(i);
char left = s2.charAt(i-len1);
dict[right-'a']--;
dict[left-'a']++;
if(check(dict)){
return true;
}
}
return false;
}
}整个算法的时间复杂度为 O(26 * n),其中 n 是 s2 的长度。因为字母表的大小是常数(26),所以实际复杂度接近 O(n)。
647. Palindromic Substrings
https://leetcode.com/problems/palindromic-substrings/description/
Given a string s, return the number of palindromic substrings in it.
A string is a palindrome when it reads the same backward as forward.
A substring is a contiguous sequence of characters within the string.
Example 1:Input: s = "abc"
Output: 3
Explanation: Three palindromic strings: "a", "b", "c".
Example 2:
Input: s = "aaa"
Output: 6
Explanation: Six palindromic strings: "a", "a", "a", "aa", "aa", "aaa".
Constraints:1 <= s.length <= 1000
s consists of lowercase English letters.
expand from center
java
class Solution {
int count = 0;
public void helper(String s,int left, int right){
while(left >= 0 && right < s.length() && s.charAt(left)==s.charAt(right)){
count++;
left--;
right++;
}
}
public int countSubstrings(String s) {
for(int i = 0; i < s.length(); i++){
helper(s,i,i);
helper(s,i,i+1);
}
return count;
}
}DP
DP遍历是回文的不同情况
一个字符:是
两个字符:相等是
三个及以上字符:两端是,看中间
遍历 0...n 把每一个字符当两端起始进行检测
java
class Solution {
public int countSubstrings(String s) {
int len = s.length();
boolean[][] dp = new boolean[len][len];
int count = 0;
for(int i = 0; i < len; i++){
dp[i][i] = true;
}
for(int i = 0; i < len - 1; i++){
if(s.charAt(i)==s.charAt(i + 1)){
dp[i][i + 1] = true;
}
}
for(int length = 2; length < len; length++ ){
for(int i = 0; i + length < len; i++){
if(s.charAt(i)==s.charAt(i+length)){
dp[i][i+length] = dp[i+1][i+length-1];
}
}
}
for(int i = 0; i < len; i++){
for(int j = 0; j < len; j++)
if(dp[i][j] == true)
count++;
}
return count;
}
}692. Top K Frequent Words
Given an array of strings words and an integer k, return the k most frequent strings.
Return the answer sorted by the frequency from highest to lowest. Sort the words with the same frequency by their lexicographical order.
Example 1:Input: words = "i","love","leetcode","i","love","coding", k = 2
Output: "i","love"
Explanation: "i" and "love" are the two most frequent words.
Note that "i" comes before "love" due to a lower alphabetical order.
Example 2:
Input: words = "the","day","is","sunny","the","the","the","sunny","is","is", k = 4
Output: "the","is","sunny","day"
Explanation: "the", "is", "sunny" and "day" are the four most frequent words, with the number of occurrence being 4, 3, 2 and 1 respectively.
Constraints:1 <= words.length <= 500
1 <= wordsi.length <= 10
wordsi consists of lowercase English letters.
k is in the range 1, The number of unique words\[i]
Follow-up: Could you solve it in O(n log(k)) time and O(n) extra space?
traverse the given string array to count the frequency of the words
Use Map<String,Integer> to store
Get the top K Frequent Words, use Max Heap/PriorityQueue
java
class Solution {
public List<String> topKFrequent(String[] words, int k) {
// Step 1: Count the frequency of each word
Map<String, Integer> frequencyMap = new HashMap<>();
for (String word : words) {
frequencyMap.put(word, frequencyMap.getOrDefault(word, 0) + 1);
}
// Step 2: Use a PriorityQueue to keep the top k frequent words
//priority queue min heap by default, customize comparator
//lambda ()->{}
PriorityQueue<Map.Entry<String, Integer>> maxHeap = new PriorityQueue<>(
(a, b) -> {
if (a.getValue().equals(b.getValue())) {
return a.getKey().compareTo(b.getKey()); // lexicographically order
}
return b.getValue() - a.getValue(); // frequency order
}
);
// Step 3: Add elements to the heap
for (Map.Entry<String, Integer> entry : frequencyMap.entrySet()) {
maxHeap.offer(entry);
}
// Step 4: Extract the top k frequent words from the heap
List<String> result = new ArrayList<>();
for (int i = 0; i < k; i++) {
result.add(maxHeap.poll().getKey());
}
return result;
}
}- map.getOrDefault(key,default value)
- map vs map.entry()
A Map<String, Integer> represents the entire map , which is a collection of key-value pairs.
A Map.Entry<String, Integer> represents a single key-value pair from the map.
Since the priority queue is supposed to order individual key-value pairs (entries), it is defined to store Map.Entry<String, Integer> objects.
priority queue in java is min heap by default
Customize comparator
java
(a,b)->{
//return a-b; // increasing
//return b-a; //decreasing
if(a.getValue()!=b.getValue()){
return a.getValue()- b.getValue();
}
return a.getKey()-b.getKey();
}== Operator
Usage: Compares references (memory addresses) of two objects.
equals() Method
Usage: Compares the actual content (characters) of two strings.
compareTo() Method
Usage: Compares two strings lexicographically. Returns:
A negative integer if the first string is lexicographically less than the second.
Zero if the strings are equal.
A positive integer if the first string is lexicographically greater than the second.
PriorityQueue, TreeSet, or when sorting collections using Collections.sort(). This is done by implementing the Comparator interface or overriding the compareTo method when implementing the Comparable interface.
Custom Ordering with Comparator
The Comparator interface provides a way to define custom ordering for objects without modifying the objects themselves. You can create a Comparator by implementing its compare method, which compares two objects and returns an integer based on their relative order.
Basic Example
Let's say you have a Person class and you want to sort a list of Person objects by age.
java
import java.util.*;
class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return name + " (" + age + ")";
}
}
public class CustomOrderingExample {
public static void main(String[] args) {
List<Person> people = new ArrayList<>();
people.add(new Person("Alice", 30));
people.add(new Person("Bob", 25));
people.add(new Person("Charlie", 35));
// Custom ordering by age using Comparator
Comparator<Person> ageComparator = new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
return p1.age - p2.age; // Ascending order by age
}
};
Collections.sort(people, ageComparator);
// Print the sorted list
System.out.println(people);
}
}Using Lambda Expressions for Simplicity
Java 8 introduced lambda expressions, which allow you to write more concise code. The above comparator can be written using a lambda expression:
java
Comparator<Person> ageComparator = (p1, p2) -> p1.age - p2.age;Custom Ordering with Multiple Criteria
Often, you might need to sort by multiple criteria. For example, if two Person objects have the same age, you might want to further sort them by name in alphabetical order:
java
Comparator<Person> ageThenNameComparator = (p1, p2) -> {
if (p1.age == p2.age) {
return p1.name.compareTo(p2.name); // Sort by name if ages are the same
}
return p1.age - p2.age; // Otherwise, sort by age
};Custom Ordering in a PriorityQueue
You can also use custom ordering in a PriorityQueue to determine how elements are prioritized:
java
PriorityQueue<Person> queue = new PriorityQueue<>(ageThenNameComparator);
queue.add(new Person("Alice", 30));
queue.add(new Person("Bob", 25));
queue.add(new Person("Charlie", 25));
// The person with the lowest age and then by name will be at the front
while (!queue.isEmpty()) {
System.out.println(queue.poll()); // Removes and prints the head of the queue
}Explanation:
Comparator Interface:
The Comparator interface requires implementing the compare method, which takes two objects and returns an integer:
Negative if the first object should come before the second.
Zero if they are equal in order.
Positive if the first object should come after the second.
752. Open the Lock
You have a lock in front of you with 4 circular wheels. Each wheel has 10 slots: '0', '1', '2', '3', '4', '5', '6', '7', '8', '9'. The wheels can rotate freely and wrap around: for example we can turn '9' to be '0', or '0' to be '9'. Each move consists of turning one wheel one slot.
The lock initially starts at '0000', a string representing the state of the 4 wheels.
You are given a list of deadends dead ends, meaning if the lock displays any of these codes, the wheels of the lock will stop turning and you will be unable to open it.
Given a target representing the value of the wheels that will unlock the lock, return the minimum total number of turns required to open the lock, or -1 if it is impossible.
Example 1:Input: deadends = "0201","0101","0102","1212","2002", target = "0202"
Output: 6
Explanation:
A sequence of valid moves would be "0000" -> "1000" -> "1100" -> "1200" -> "1201" -> "1202" -> "0202".
Note that a sequence like "0000" -> "0001" -> "0002" -> "0102" -> "0202" would be invalid,
because the wheels of the lock become stuck after the display becomes the dead end "0102".
Example 2:
Input: deadends = "8888", target = "0009"
Output: 1
Explanation: We can turn the last wheel in reverse to move from "0000" -> "0009".
Example 3:
Input: deadends = "8887","8889","8878","8898","8788","8988","7888","9888", target = "8888"
Output: -1
Explanation: We cannot reach the target without getting stuck.
Constraints:1 <= deadends.length <= 500
deadendsi.length == 4
target.length == 4
target will not be in the list deadends.
target and deadendsi consist of digits only.
deadends 相当于对应的路径是堵死的,不能到达,等于图/树中的障碍
四位密码锁,从0000到指定数字,中间不能经过给定的数字组合,最短的路径
是一个无权图最短路径问题 ,使用BFS
分析从0000开始有多少可能的转移方式
1000 0100 0010 0001 9000 0900 0090 0009
及每一位都可以进行+1或者-1,总共有四个可以变换的位置,即从一个状态出发,有八个可能的下一步状态可供选择
Key Point:
- BFS (Queue)
- Use Visited Set to skip duplicate. When add item into queue, add into set
- Four digits, each has two action add or subtract
- Check deadend
- If find target, return
java
class Solution {
private String add(String str,int index){
char[] ch = str.toCharArray();
if(ch[index]=='9'){
ch[index]='0';
}else{
ch[index] += 1;
}
return new String(ch);
}
private String minus(String str,int index){
char[] ch = str.toCharArray();
if(ch[index]=='0'){
ch[index]='9';
}else{
ch[index] -= 1;
}
return new String(ch);
}
public int openLock(String[] deadends, String target) {
Queue<String> queue = new LinkedList<>();
Set<String> visited = new HashSet<>();
Set<String> dead = new HashSet<>();
for(String deadend:deadends){
dead.add(deadend);
}
queue.offer("0000");
visited.add("0000");
int step = 0;
while(!queue.isEmpty()){
int size = queue.size();
for(int i = 0; i < size; i++){
String str = queue.poll();
if(dead.contains(str)){
continue;
}
if(str.equals(target)){
return step;
}
for(int index = 0; index < 4; index++){
String addStr = add(str,index);
String minusStr = minus(str,index);
if(!visited.contains(addStr)){
queue.offer(addStr);
visited.add(addStr);
}
if(!visited.contains(minusStr)){
queue.offer(minusStr);
visited.add(minusStr);
}
}
}
step++;
}
return -1;
}
}
java
char[] ch = str.toCharArray();
return new String(ch);双向BFS 优化
同时从start和end开始搜索,看start和end是否相交
双向 BFS 还是遵循 BFS 算法框架的,只是不再使⽤队列,⽽是使⽤HashSet ⽅便快速判断两个集合是否有交集。
另外的⼀个技巧点就是 while 循环的最后交换 q1 和 q2 的内容,所以只要默认扩散 q1 就相当于轮流扩散 q1 和 q2 。
java
int openLock(String[] deadends, String target) {
Set<String> deads = new HashSet<>();
for (String s : deadends) deads.add(s);
// ⽤集合不⽤队列,可以快速判断元素是否存在
Set<String> q1 = new HashSet<>();
Set<String> q2 = new HashSet<>();
Set<String> visited = new HashSet<>();
int step = 0;
q1.add("0000");
q2.add(target);
while (!q1.isEmpty() && !q2.isEmpty()) {
// 哈希集合在遍历的过程中不能修改,⽤ temp 存储扩散结果
Set<String> temp = new HashSet<>();
/* 将 q1 中的所有节点向周围扩散 */
for (String cur : q1) {
/* 判断是否到达终点 */
if (deads.contains(cur))
continue;
if (q2.contains(cur))
return step;
visited.add(cur);
/* 将⼀个节点的未遍历相邻节点加⼊集合 */
for (int j = 0; j < 4; j++) {
String up = plusOne(cur, j);
if (!visited.contains(up))
temp.add(up);
String down = minusOne(cur, j);
if (!visited.contains(down))
temp.add(down);
}
}
/* 在这⾥增加步数 */
step++;
// temp 相当于 q1
// 这⾥交换 q1 q2,下⼀轮 while 就是扩散 q2
q1 = q2;
q2 = temp;
}
return -1;
}⽆论传统 BFS 还是双向 BFS,⽆论做不做优化,从 Big O衡量标准来看,时间复杂度都是⼀样的
875. Koko Eating Bananas
Koko loves to eat bananas. There are n piles of bananas, the ith pile has pilesi bananas. The guards have gone and will come back in h hours.
Koko can decide her bananas-per-hour eating speed of k. Each hour, she chooses some pile of bananas and eats k bananas from that pile. If the pile has less than k bananas, she eats all of them instead and will not eat any more bananas during this hour.
Koko likes to eat slowly but still wants to finish eating all the bananas before the guards return.
Return the minimum integer k such that she can eat all the bananas within h hours.
Example 1:Input: piles = 3,6,7,11, h = 8
Output: 4
Example 2:
Input: piles = 30,11,23,4,20, h = 5
Output: 30
Example 3:
Input: piles = 30,11,23,4,20, h = 6
Output: 23
Constraints:1 <= piles.length <= 104
piles.length <= h <= 109
1 <= pilesi <= 109
Time exceeded
java
class Solution {
public int minEatingSpeed(int[] piles, int h) {
int sum = 0;
int min = 0;
int max = -1;
for(int pile:piles){
sum += pile;
if(pile>max){
max = pile;
}
}
if(sum%h!=0)
min = sum/h + 1;
else
min = sum/h;
for(int i = min; i <= max; i++){
int count = 0;
for(int pile:piles){
while(pile>0){
if(pile<i)
pile = 0;
}else
pile -= i;
count++;
}
}
if(count<=h){
return i;
}
}
return max;
}
}Optimize with binary search
二叉搜索查找边界
java
class Solution {
private boolean valid(int[] piles,int speed,int h){
int count = 0;
for(int pile:piles){
count += (pile / speed) + ((pile % speed > 0) ? 1 : 0);
}
if(count<=h){
return true;
}
return false;
}
public int minEatingSpeed(int[] piles, int h) {
int max = -1;
for(int pile:piles){
if(pile>max){
max = pile;
}
}
int low = 1;
int high = max + 1;
while(low<high){
int mid = (high-low)/2 + low;
if(valid(piles,mid,h)){
high = mid;
}else{
low = mid + 1;
}
}
return low;
}
}12ms 80.86% 45.14 MB 35.65%
886. Possible Bipartition
https://leetcode.com/problems/possible-bipartition/description/
We want to split a group of n people (labeled from 1 to n) into two groups of any size. Each person may dislike some other people, and they should not go into the same group.
Given the integer n and the array dislikes where dislikesi = ai, bi indicates that the person labeled ai does not like the person labeled bi, return true if it is possible to split everyone into two groups in this way.
Example 1:Input: n = 4, dislikes = \[1,2,1,3,2,4]
Output: true
Explanation: The first group has 1,4, and the second group has 2,3.
Example 2:
Input: n = 3, dislikes = \[1,2,1,3,2,3]
Output: false
Explanation: We need at least 3 groups to divide them. We cannot put them in two groups.
Constraints:1 <= n <= 2000
0 <= dislikes.length <= 104
dislikesi.length == 2
1 <= ai < bi <= n
All the pairs of dislikes are unique.
二分图 Graph Bipartite
相连的结点不属于一组
给定一组讨厌关系(无向图中的边),判断是否可以将这些人分为两组,使得每组内部没有讨厌关系。
Union Find
二分图
A和B dislike,说明AB不能再一起,如果在一起了false
又因为只能分成两组,所以,A只能和B的敌人在一起(A不和B,A不和A敌,B不和B敌,所以A和B敌,B和A敌相连)
使用HashMap存储节点的敌人,存储一个就够了,剩下的敌人直接和已经存储的相连
java
class Solution {
class UnionFind {
private int[] parent;
public UnionFind(int n){
parent = new int[n+1];
for(int i = 0; i <= n; i++){
parent[i] = i;
}
}
public int find(int i){
if(parent[i]!=i){
parent[i] = find(parent[i]);
}
return parent[i];
}
public void union(int x,int y){
int px = find(x);
int py = find(y);
// parent[py] = px;
if(px != py) {
parent[py] = px;
}
}
}
public boolean possibleBipartition(int n, int[][] dislikes) {
UnionFind uf = new UnionFind(n);
Map<Integer, Integer> enemyMap = new HashMap<>();
for (int[] dislike : dislikes) {
int a = dislike[0];
int b = dislike[1];
if (!enemyMap.containsKey(a)) {
enemyMap.put(a, b);
} else {
uf.union(b, enemyMap.get(a));
}
if (!enemyMap.containsKey(b)) {
enemyMap.put(b, a);
} else {
uf.union(a, enemyMap.get(b));
}
// Check if a and b are in the same set, which would be an error
if (uf.find(a) == uf.find(b)) {
return false;
}
}
return true;
}
}DFS/BFS
将结点相连,连成图
使用DFS或者BFS遍历,染色/0 1,当前节点与相邻节点的颜色必须是相反的,满足二分图,否则不成立
**在对结点进行DFS遍历时,只遍历未访问过的
在添加结点到邻接链表时,因为是无向图,所以要双向添加
在对邻接结点进行dfs访问时,
错误
java
for(int neighbor : adjList.get(i)) {
if(color[neighbor] == 0) {
dfs(adjList, neighbor, color, -flag);
} else if(color[neighbor] == flag) {
return false;
}
}冲突检测不充分:颜色标记的逻辑依赖于每个节点的颜色都是唯一且不变的,如果没有正确处理节点是否已经访问过,当遇到一个已经访问过的节点时,程序可能不会及时检测到冲突(即两个相邻节点被标记为同一颜色),这会导致错误的结果。
8
\[1,2\],\[1,3\],\[4,5\],\[4,6\],\[3,5\],\[3,7\],\[5,7\]
Expected: false
java
class Solution {
private boolean dfs(List<List<Integer>> adjList,int i,int[] color,int flag){
color[i] = flag;
for(int neighbor:adjList.get(i)){
if(color[neighbor]==0){
if(!dfs(adjList,neighbor,color,-flag)){
return false;
} //dfs(adjList,neighbor,color,-flag) wrong
}else if(color[neighbor]==flag){
return false;
}
}
return true;
}
public boolean possibleBipartition(int n, int[][] dislikes) {
List<List<Integer>> adjList = new ArrayList<>(n+1);
int[] color = new int[n+1]; //node [1-n] 1 -1 for two group 0 for unvisited
adjList.add(new ArrayList<Integer>());//for index = 0
for(int i = 1; i <= n; i++){
adjList.add(new ArrayList<Integer>());
}
for(int[] dislike:dislikes){
adjList.get(dislike[0]).add(dislike[1]);//add [1] to [0]'s adjList as well as add [0] to [1]'s
adjList.get(dislike[1]).add(dislike[0]);
}
for(int i = 1; i <= n; i++){
if(color[i]==0 && !dfs(adjList,i,color,1)){ //check visited
return false;
}
}
return true;
}
}1091. Shortest Path in Binary Matrix
https://leetcode.com/problems/shortest-path-in-binary-matrix/
Given an n x n binary matrix grid, return the length of the shortest clear path in the matrix. If there is no clear path, return -1.
A clear path in a binary matrix is a path from the top-left cell (i.e., (0, 0)) to the bottom-right cell (i.e., (n - 1, n - 1)) such that:
All the visited cells of the path are 0.All the adjacent cells of the path are 8-directionally connected (i.e., they are different and they share an edge or a corner).
The length of a clear path is the number of visited cells of this path.
In the problem, you're given a binary matrix (grid) where 0 represents a passable cell (you can walk through it), and 1 represents an obstacle (you cannot walk through it).
BFS implement Queue interface with LinkedList
visited current node, then push all its neighborhood into queue.
matrix grid, int\[\]\[\] grid we store the coordinate into the queue
Use the grid\[\]\[\] array itself to store the distance, 0 represent path can be visited, when visited a new node add one based on the previous store in grid.
If the grid\[\]\[\] is not 0, means it already visited
edge condition:
error: if the start or end cell is not 0 , no available path, return -1
success: meet length-1length-1
java
class Solution {
public int shortestPathBinaryMatrix(int[][] grid) {
int n = grid.length;
if (grid[0][0] != 0 || grid[n - 1][n - 1] != 0) {
return -1; // If start or end is blocked
}
Queue<int[]> queue = new LinkedList<>(); // store the coordinate [x,y]
//define the direction in two-dimensional array {{,},{,},{,},{,}}
int[][] direction = new int[][]{{0,-1},{0,1},{-1,0},{1,0},{-1,-1},{1,1},{-1,1},{1,-1}};
queue.offer(new int[]{0, 0});
grid[0][0] = 1;
while(queue.size()>0){
int[] cell = queue.poll();
int x = cell[0];
int y = cell[1];
if(x == n-1 && y == n-1){
return grid[x][y];
}
for(int i = 0; i < 8; i++){
int nextX = x + direction[i][0];
int nextY = y + direction[i][1];
//validate next step
if(nextX>=0 && nextY>=0 && nextX < n && nextY < n && grid[nextX][nextY] == 0){
// store the path length in grid, if grid[x][y] == 0 : unvisited, update when visit new cell
queue.offer(new int[]{nextX, nextY});
grid[nextX][nextY] = grid[x][y]+1;
}
}
}
return -1;
}
}1143. Longest Common Subsequence
https://leetcode.com/problems/longest-common-subsequence/description/
Given two strings text1 and text2, return the length of their longest common subsequence. If there is no common subsequence, return 0.
A subsequence of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
For example, "ace" is a subsequence of "abcde".
A common subsequence of two strings is a subsequence that is common to both strings.
Example 1:Input: text1 = "abcde", text2 = "ace"
Output: 3
Explanation: The longest common subsequence is "ace" and its length is 3.
Example 2:
Input: text1 = "abc", text2 = "abc"
Output: 3
Explanation: The longest common subsequence is "abc" and its length is 3.
Example 3:
Input: text1 = "abc", text2 = "def"
Output: 0
Explanation: There is no such common subsequence, so the result is 0.
Constraints:1 <= text1.length, text2.length <= 1000
text1 and text2 consist of only lowercase English characters.
DP on string
java
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
//keep same order can delete char
//dp[i][j] for (0,i) (0,j) longest common subsequence
//t1[i] == t2[j] : dp[i][j] = dp[i-1][j-1] + 1
//t1[i] != t2[j] : dp[i][j] = 1. remove 1 dp[i-1][j] 2.remove 2 dp[i][j-1]
//base case dp[0][0] = 0 = dp[0][i] = dp[i][0]
int len1 = text1.length();
int len2 = text2.length();
int[][] dp = new int[len1+1][len2+1];
for(int i = 0; i <= len1; i++){
dp[i][0] = 0;
}
for(int i = 0; i <= len2; i++){
dp[0][i] = 0;
}
for(int i = 1; i <= len1; i++){
for(int j = 1; j <= len2; j++){
if(text1.charAt(i-1)==text2.charAt(j-1)){
dp[i][j] = dp[i-1][j-1] + 1;
}
else{
dp[i][j] = Math.max(dp[i-1][j],dp[i][j-1]);
}
}
}
return dp[len1][len2];
}
}