前言:在浏览器中点击一个链接或输入一个网址时,背后是HTTP协议在默默地协调着客户端与服务器之间的每一次对话。作为应用层最核心的协议之一,HTTP定义了Web通信的基本规则。本文将深入解析HTTP协议的报文格式、关键机制,并通过实践搭建一个简单的HTTP服务器,来揭示网页从请求到展现的完整过程。
文章目录
- 一、HTTP协议简介
- 二、HTTP请求报文格式
- 三、HTTP响应报文格式
- 四、HTTP服务搭建
-
- [4.1 uri资源获取](#4.1 uri资源获取)
- [4.2 头部字段](#4.2 头部字段)
- [4.3 状态码与状态描述](#4.3 状态码与状态描述)
- [4.4 GET和POST](#4.4 GET和POST)
- 五、源码
一、HTTP协议简介
HTTP协议是应用层 一个重要的协议。数据本质是二进制 ,也可以把它们++看做++ 是字符,而要完成各种业务逻辑需要通信双方约定一个固定的数据格式,完成业务的分用,像传输层、网络层、数据链路层等一样。不过应用层没有标准的协议规定,而是让程序员根据具体的需求自行设计。不过已经有大佬们设计出了很多优秀的协议,我们可以直接使用,比如HTTP协议。
HTTP协议全称超文本传输协议,是客户端与服务器之间通信的基础。客户端通过HTTP协议向服务器发送请求,服务器收到请求后处理并返回响应。
- 注1:HTTP协议是⼀个⽆连接、⽆状态的协议,即每次请求都需要建⽴新的连接,且服务器不会保存客户端的状态信息。
- 注2:HTTP协议的客户端通常不用我们自己写,直接使用浏览器即可。
认识URL

要在全网内访问某个唯一进程,需要知道该进程所在服务器的 IP 地址和端口号(port),如上http就代表了80端口,https代表了443端口。而www.example.jp是域名,到时候会被转化为服务器端的ip地址。(域名+协议即ip地址+端口号)
在上网时事实上只有两种行为,即:
- 从远端获取资源
- 把本地资源上传到远端
那么什么是资源呢?
资源在远端服务器里,以文件形式存在。如上/dir/index.html就是linux路径下的一个文件。
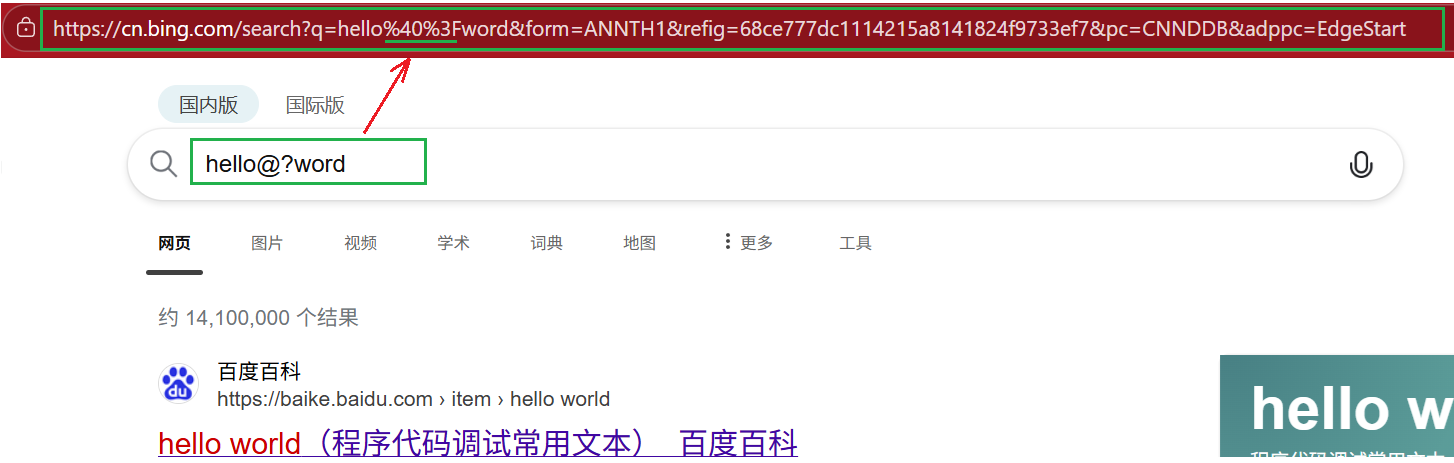
如上在url中像@?等字符已经被用作特殊含义,如果在搜索框中出现,最后在url中会被转义,转义规则:
- 将需要转义的字符转为16进制,然后从右往左,取4位(不足4位直接处理),每2位前加上%,编码成%XY格式
二、HTTP请求报文格式
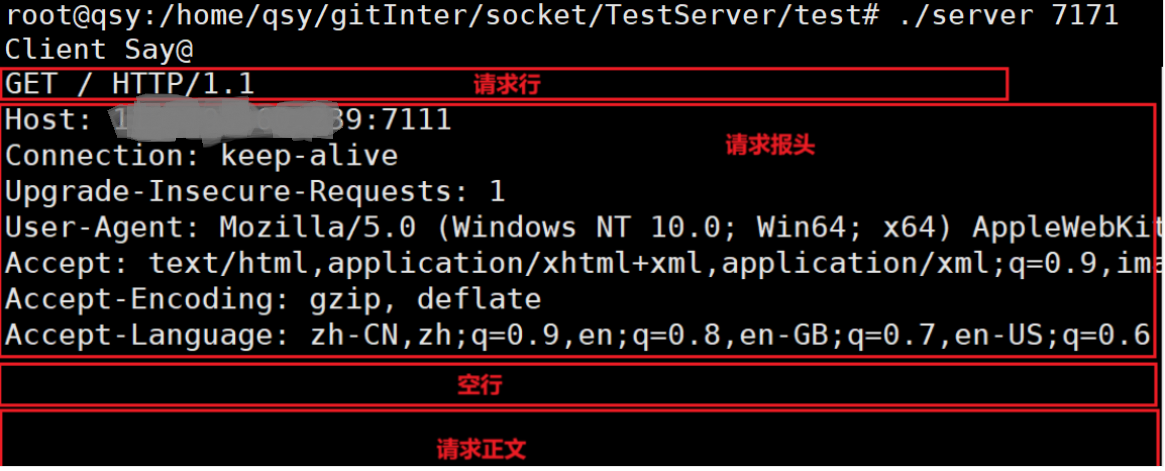
HTTP请求报头格式如下:

请求行:
- 请求方法:最常用的是GET和POST,GET表示获取资源(它也能上传资源),POST表示上传资源。
- URI:资源的路径。服务器会根据路径找到并读取资源返回给客户端。
- HTTP版本:客户端会在请求中携带自身支持的 HTTP 版本,服务器据此为客户端提供对应版本的服务。
头部字段:
- 以key: value的形式,传输各个属性信息。
空行:
- 把报头与有效载荷分开。空行以上为报头,空行以下为有效载荷。
请求正文:
- 本质是一个长字符串。(可以是
json格式)该部分可有可无。
注意:
- HTTP 协议的序列化与反序列化,是通过特殊字符(如 \r\n、空格)进行字段拼接实现的,不依赖任何第三方库。
- HTTP是基于TCP协议的。
如何让报头与有效载荷分离?通过空行。
如何让报文与报文之间分离?在头部字段中有一个参数Content-Length标记正文部分的长度,方便我们进行报文分离。
接下来我们快速搭建一个TCP服务,接收并打印一个HTTP请求报头:
快速搭建TCP服务
目录结构:
test
├── main.cc
├── server.hpp
└── Makefileserver.hpp文件
cpp
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netinet/ip.h>
#include <arpa/inet.h>
class Server
{
public:
Server(int port)
: _port(port), _isrunning(false)
{
/*打开套接字*/
_listenfd = socket(AF_INET, SOCK_STREAM, 0);
/*绑定端口*/
sockaddr_in server_addr;
server_addr.sin_family = AF_INET; // 设置为IPv4
// 主机序列->网络序列
server_addr.sin_port = htons(_port);
server_addr.sin_addr.s_addr = INADDR_ANY;
int n = bind(_listenfd, (sockaddr *)&server_addr, sizeof(server_addr));
/*打开监听*/
static const int backlog = 10; // 允许10个客户端连接
n = listen(_listenfd, backlog);
}
void Run()
{
_isrunning = true;
while (_isrunning)
{
sockaddr_in client_addr;
socklen_t len = sizeof(client_addr);
int socketfd = accept(_listenfd, (sockaddr *)&client_addr, &len);
pid_t pid = fork();
if (pid == 0)
{
close(_listenfd);
if (fork() > 0)
exit(0);
work(socketfd);
exit(0);
}
else
close(socketfd);
}
_isrunning = false;
}
void work(int sockfd)
{
while (true)
{
char buffer[1024];
int n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n <= 0)
{
close(sockfd);
return;
}
else
{
buffer[n] = '\0';
std::cout << "Client Say@ \n" << buffer;
}
}
}
~Server(){}
private:
uint16_t _port;
int _listenfd;
bool _isrunning;
};注意:以上代码只列出来核心部分,省略了返回值的有效性判断,在实战开发中不可省。
cpp
#include "server.hpp"
#include <memory>
int main(int argc,char* argv[])
{
if(argc!=2)
{
std::cout<<"Usage "<<argv[0]<<" port"<<std::endl;
return 1;
}
std::unique_ptr<Server> sv(new Server(std::stoi(argv[1])));
sv->Run();
return 0;
}Makefile:
shell
server:main.cc
g++ -o $@ $^ -std=c++17
.PHONY:clean
clean:
rm -rf server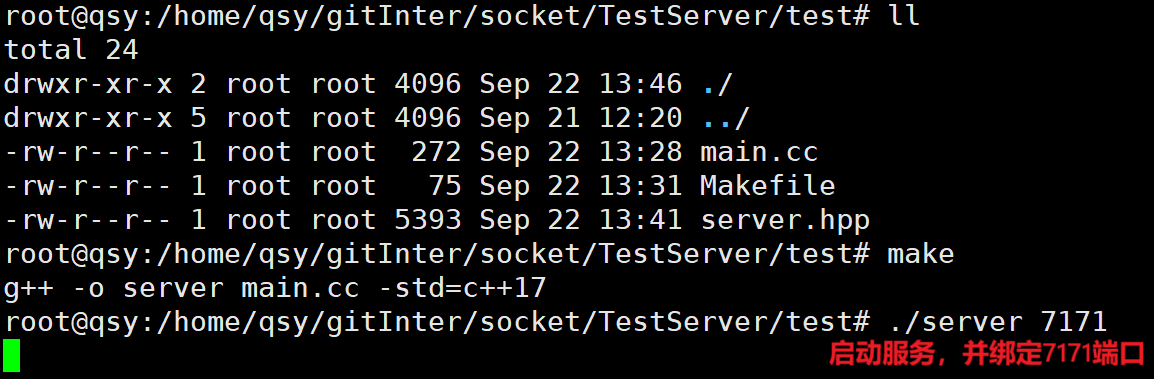
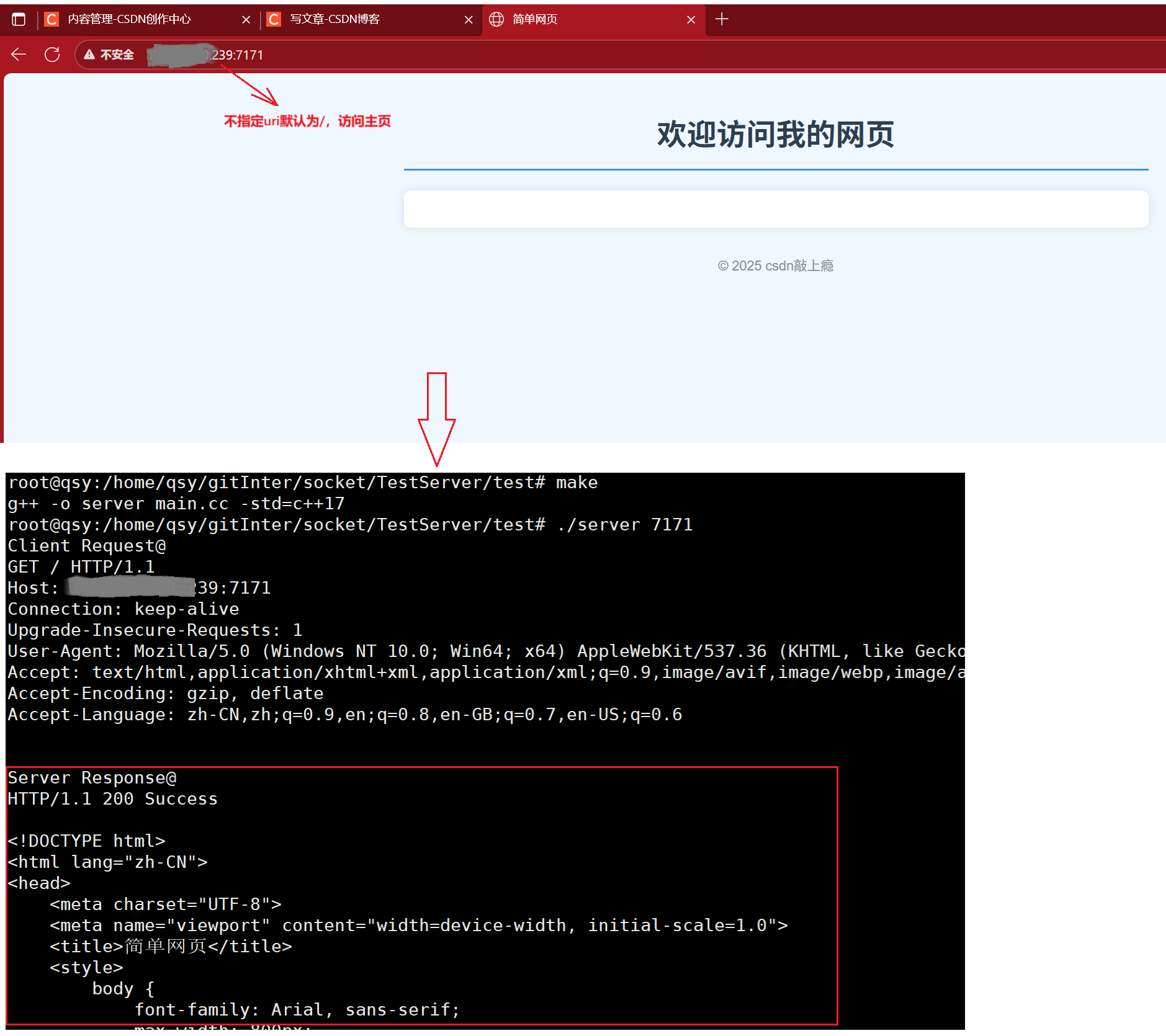
这里可以不用makefile工具,直接执行指令g++ -o server main.cc -std=c++17,服务启动后到浏览器搜索网址:服务器ip:端口号,如:117.199.66.239:7171。
因为在以上函数work中我们将从客户端的请求接收后进行输出,所以在终端我们可以看到这样的结果:
三、HTTP响应报文格式
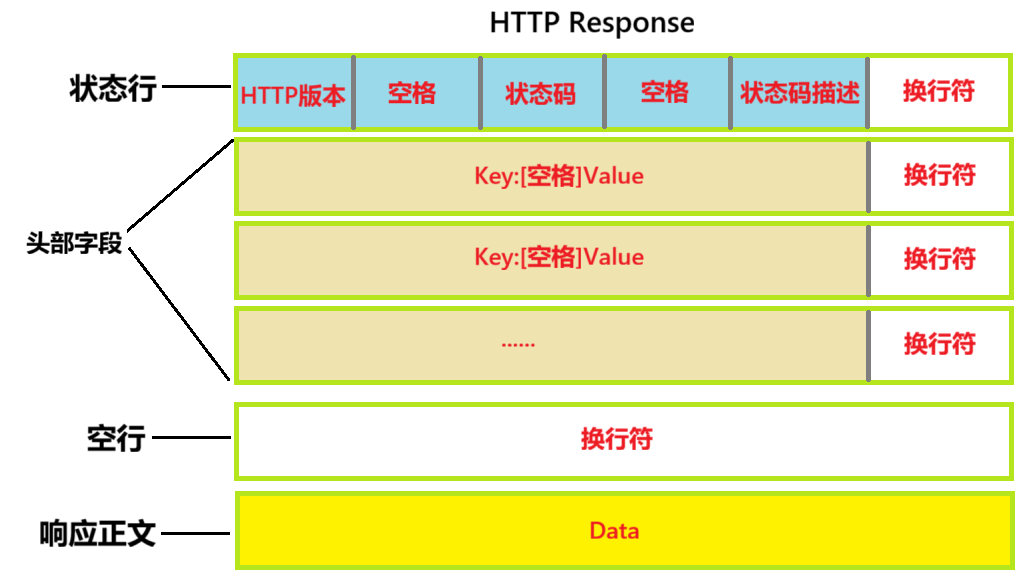
状态行:
- HTTP版本:客户端会与服务器做HTTP版本交换,服务器方便给客户端提供对应版本的服务。
- 状态码 :标记请求的处理情况,比如
200表示成功、404表示找不到资源... - 状态码描述 :描述请求的处理情况,比如
"Success"、"Not Found"...
后面的响应报头,空行和响应正文的作用和HTTP请求报文相同。
以上是HTTP协议请求和应答的报文格式,接下来我们通过程序设计的过程,详细了解里面的每一个元素:
四、HTTP服务搭建
在上面TCP服务的基础上添加文件http.hpp,用来做协议相关的类方法的实现。接下来的操作都是在该文件中完成。
首先准备一个类或结构体用来储存报文中的各个元素:
cpp
typedef struct httpRequest //请求报文
{
//请求行
string _method;
string _uri;
string _versions;
//头部字段
unordered_map<string, string> _head_data;
//请求正文
string _text;
} httpRequest;
typedef struct httpResponse //响应报文
{
//状态行
string _versions;
int _state_code;
string _state;
//头部字段
unordered_map<string, string> _head_data;
//响应正文
string _text;
} httpResponse;接下来封装http类,主要的结构如下:
cpp
class Http
{
public:
bool Deserilize(string src) //解包(反序列化)
{}
string Serilize() //封包(序列化)
{}
//报头各个元素的设置方法和获取方法.....
httpRequest _req;// 请求报头
httpResponse _rsp;// 响应报头
};解包(反序列化):
cpp
const string blank = " ";
const string mark = "\r\n";
const string kv_mark = ": ";
inline bool GetOneline(string &out, string &src)
{
int pos = src.find(mark);
if (pos == string::npos)
return false;
out = src.substr(0, pos);
src = src.erase(0, pos + mark.size());
return true;
}
bool Deserilize(string src) // 传入一个完整的http报文
{
// 提取请求行
string out;
GetOneline(out, src);
// 解包请求行
stringstream ss(out);
ss >> _req._method >> _req._uri >> _req._versions;
// 提取并解包头部字段
out.clear();
while (out != "")
{
int pos = out.find(kv_mark);
if (pos == string::npos)
return false;
_req._head_data[out.substr(0, pos)] = out.substr(pos + kv_mark.size());
out.clear();
GetOneline(out, src);
}
// 提取请求正文
_req._text = src;
return true;
}封包(序列化)
cpp
string Serilize()
{
// 响应行
string out;
out += _rsp._versions + blank + to_string(_rsp._state_code) + blank + _rsp._state;
out += mark;
// 头部字段
for (auto [key, val] : _rsp._head_data)
out += key + kv_mark + val + mark;
out += mark; // 空行
// 响应正文
out += _rsp._text;
return out;
}4.1 uri资源获取
我们从请求报文中提取到uri后需要做的是把uri对应下的文件资源读取并发送给客户端。该资源通常是.html格式的一个网页信息,或者图片,或视频。
访问服务器时若未指明具体 uri,则默认 uri 为'/';注意此处的'/'不指向 Linux 系统的根目录,而是指向我们自定义的 Web 根目录(即存放网页资源的目录)。
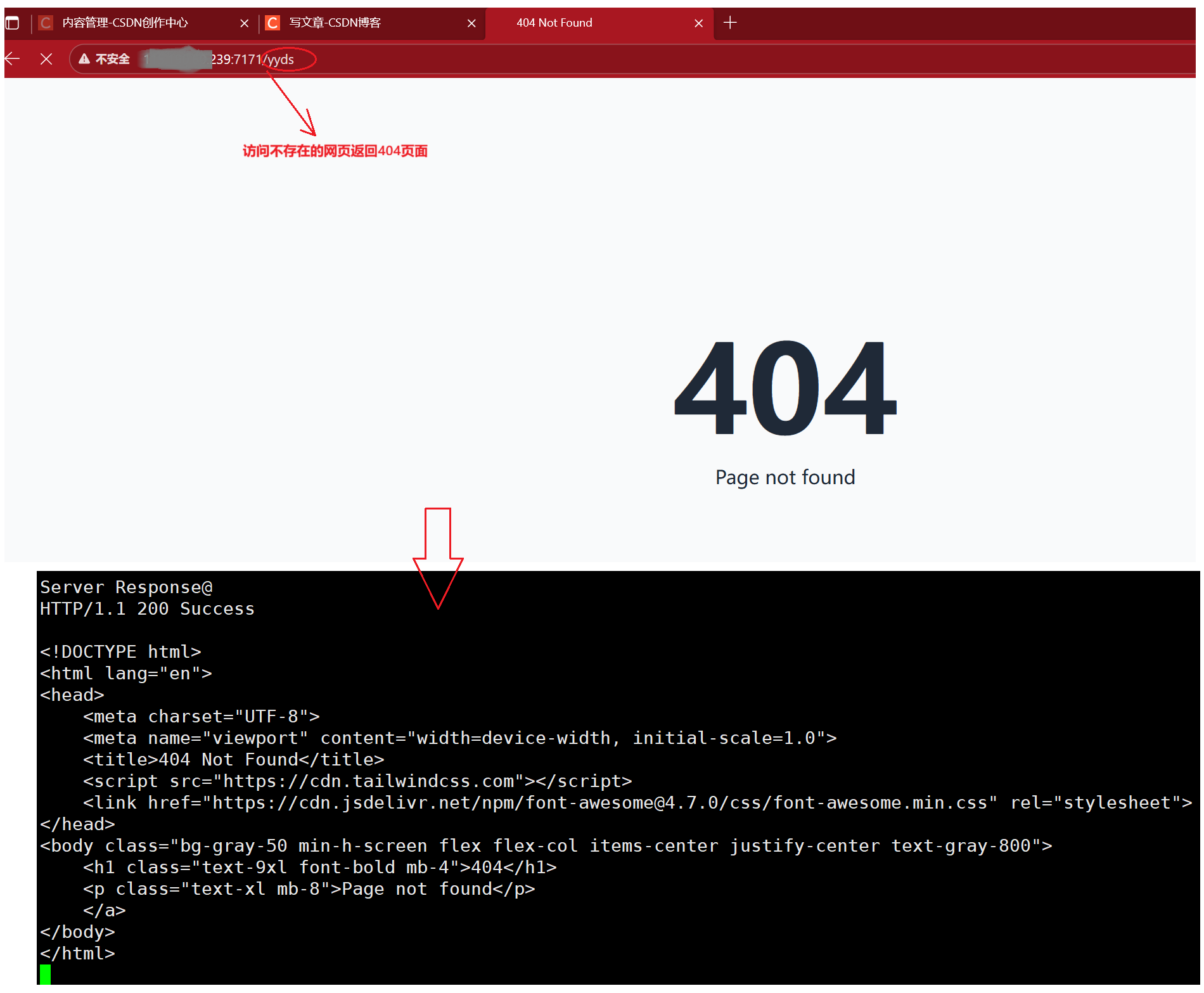
如果用户访问一个不存在的uri资源呢?该情况我们通常会返回给用户一个404页面,表示该资源找不到。
cpp
const string webroot = "./wwwroot";//设置web根目录,这里设为当前目录下的wwwroot目录
const string home_page = "index.html";//把这个当做网页首页(即默认资源)
const string login_page = "login.html";
const string register_page = "register.html";
const string errofile = "404.html";目录结构:
.
├── http.hpp
├── Makefile
├── server.cc
├── server.hpp
└── wwwroot
├── 404.html
├── index.html
├── login.html
└── register.html这些页面我们只是拿来做测试,直接让AI生成即可。
业务处理的本质,就是构建并填写 HTTP 响应报文,接下来我们分别做出HTTP协议的各字段的函数。
下面会给出响应正文的设置逻辑,关于HTTP版本我们默认使用HTTP/1.1,状态码仅考虑200和404,而关于头部字段和其他状态码在后文进行讲解和设置。
cpp
string setText()
{
string file;
if (_req._uri == "/")
file = webroot + _req._uri + homepage;
else
file = webroot + _req._uri;
// 检查uri文件是否存在
ifstream in(file);
if (!in.is_open())
{ //不存在则返回给用户404页面
file = webroot + '/' + errofile;
_req._uri = errofile;
ifstream in(file);
if(!in.is_open()) return;
}
// 将文件内容写入响应正文
in.seekg(0, in.end);
int size = in.tellg();
in.seekg(0, in.beg);
_rsp._text.resize(size);
in.read((char *)(_rsp._text.c_str()), size);
in.close();
return file;
}
void setVersion(string ver = "HTTP/1.1")
{
_rsp._versions = ver;
}
void setCode(int code)
{
_rsp._state_code = code;
if (code == 200)
_rsp._state = "Success";
else
_rsp._state = "Not Found";
}新增文件task.hpp用来做任务分配:
cpp
#include "http.hpp"
#include <iostream>
#include <unistd.h>
class Task
{
public:
Task(int clientfd)
: _clientfd(clientfd)
{}
void task()
{
while (true)
{
// 接收报文
char buffer[1024];
int n = recv(_clientfd, buffer, sizeof(buffer)-1, 0);
if (n <= 0)
{
// 客户端退出或读取错误
close(_clientfd);
return;
}
else
{
buffer[n] = '\0';
std::cout << "Client Request@ \n" << buffer;
_recvBuffer += buffer;
}
// 报文完整性检查,并提取一个完整报文
// 省略......
// 解包,这里应该从_recvBuffer中提取单个完整的报文,这里就省略
_http.Deserilize(_recvBuffer);
// 业务分发处理(本质填_http._rsp成员)
// ......
_http.setVersion("HTTP/1.1");
string file = _http.setText();
if(_http._req._uri == errofile) _http.setCode(404);
else _http.setCode(200);
// 封包
string out = _http.Serilize();
_sendBuffer += out;
// 发送报文
std::cout << "\n" << "Server Response@ \n" << _sendBuffer << std::endl;
send(_clientfd, _sendBuffer.c_str(), _sendBuffer.size(), 0);
}
}
private:
Http _http;
// 发送缓冲区
string _sendBuffer;
// 接收缓冲区
string _recvBuffer;
int _clientfd;
};
4.2 头部字段
Content-Length
Content-Length:用来标记正文部分的长度,通常都要被设置,方便报文之间分离。上文中没有设置也能被浏览器解析,是因为浏览器太强大了。
函数设计:
cpp
void setHeader(string key, string val)
{
_rsp._head_data.insert({key, val});
}设置Content-Length字段:
_http.setHeader("Content-Length",to_string(_http._rsp._text.size()));
Content-Type
现在我们尝试让网页显示图片,把本地图片上传的服务器,然后在index.html中添加相应的代码。
目录结构变化:
.
├── http.hpp
├── main.cc
├── Makefile
├── server.hpp
├── task.hpp
└── wwwroot
├── 404.html
├── image
│ ├── 1.png
│ └── 2.jpg
├── index.html
├── login.html
└── register.html添加标签:
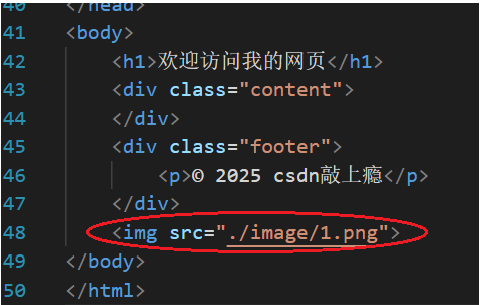
重新启动服务,再次访问网页,可以发现图片是无法正常显示的。
主要有两点:
- 图片属于二进制文件(而非文本文件),读取时需以二进制模式打开文件;TCP 协议本身是面向字节流的,传输时不区分文本与二进制。
- 在浏览器解析响应正文时默认把它当做文本进行解析。所以需要告诉客户端这个属于什么类型的资源,是图片,文本,还是视频,这样客户端就能做出正确的解析。
以上代码使用read函数读取文件字节流,恰好满足二进制文件的传输需求;资源类型是通过文件名后缀来确定的,如.png,.jpg是图片,.html是文本。然后通过Content-Type字段来告诉客户端,如果没有该字段,默认为文本资源即text/html。
Content-Type对照表:https://tool.oschina.net/commons
部分截图:
判断资源类型:
cpp
std::string UriSuffix(std::string &targetfile)
{
int pos = targetfile.rfind(".");
if (pos == string::npos)
return "text/html";
string str = targetfile.substr(pos);
if (str == ".html" || str == ".htm")
return "text/html";
else if (str == ".txt")
return ".txt";
else if (str == ".png")
return "image/png";
else if (str == ".jpg" || str == ".jpeg")
return "image/jpeg";
//......
else
return "";
}在实战开发中需要把整个对应表填写到代码中,这里只是提取了一部分。
设置响应正文后设置资源类型:
string file = _http.setText();_http.setHeader("Content-Type", _http.UriSuffix(file));
效果:
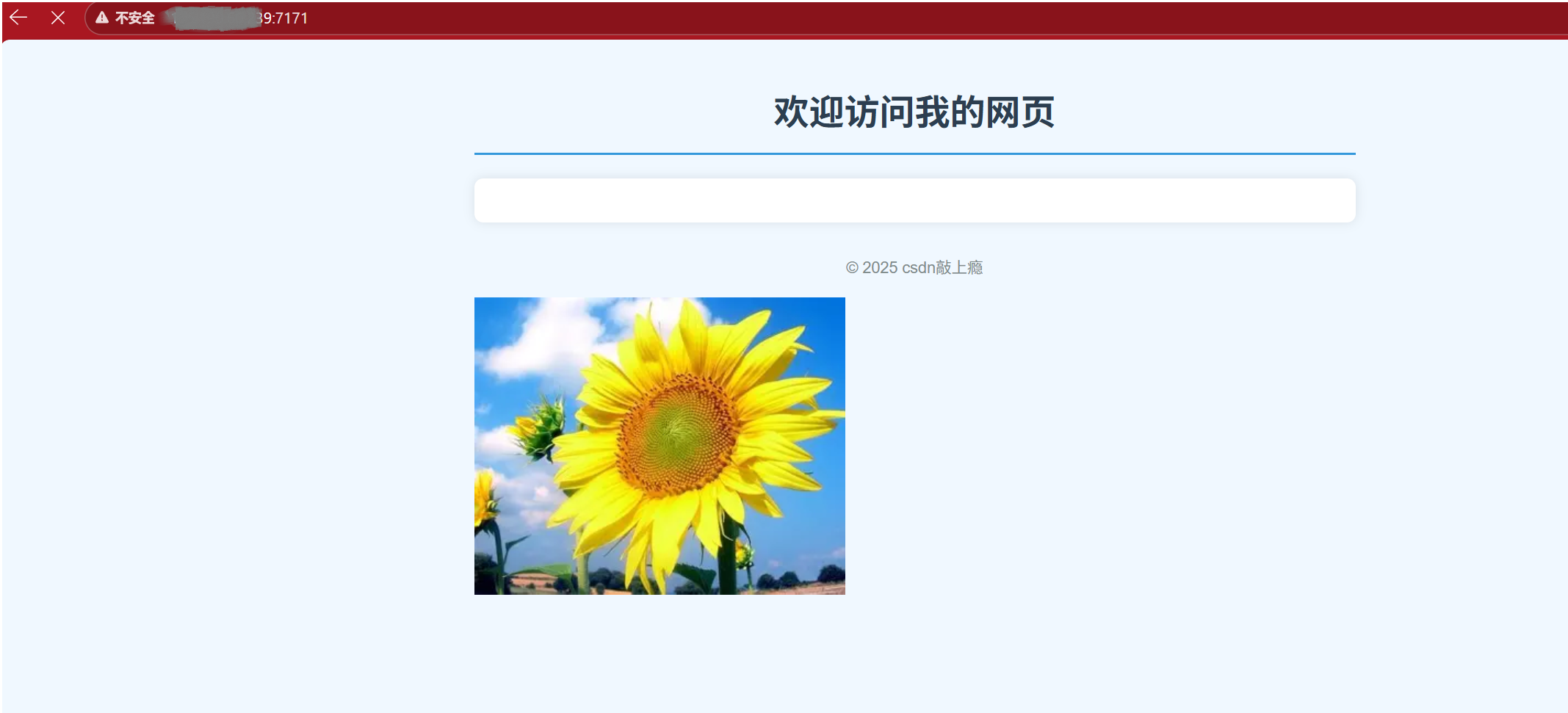
这样就能正常访问图片,视频等非文本资源了。
- 注意:在访问一个网页中如果有图片或视频等特殊资源,浏览器会再次为此单独发起请求。例如一个网页中有3张图片,那么浏览器会向服务器发起4次请求。
Connection
在早期HTTP协议中,客户端与服务器使用短连接(短服务)的形式进行交互的,也就是完成一次交互(请求)就会断开连接,如果要发起新的请求,就需要重新建立连接。如果网页有10张图片,那么就需要进行11次三次握手,和11次四次挥手。那么有更多图片或其他资源呢?
可以看出来短连接的交互方式非常繁琐。不过在HTTP/1.1版本的默认交互方式变成了长连接 ,也可以通过字段Connection来表示是否支持长连接。
Connection:keep-alive表示支持长连接Connection:close表示不支持长连接
对于服务器来说是否支持长连接是我们自己决定的,在拿到客户端套接字后,给他分配执行流等待循环等待客户端请求到来不断开就是长连接。拿到客户端套接字后,处理完一次请求就断开连接,这种方式就是短连接。
- 注意:HTTP协议是一个无连接,无状态的协议,即每次请求都要建立新的理解,服务器不会记录客户端状态信息。所以某个资源无论你是否已经获取到了,只有你继续访问服务器还是会返回给你。
这种无连接,无状态的特点也会给用户带来困扰,比如一个网站每次访问都要输入账号和密码或验证码,很繁琐。如何解决呢?
虽然HTTP协议无状态,但浏览器不是,浏览器可以把你频繁访问的资源进行缓存,不用每次都去访问服务器,也提供了一种cookie-session功能,会帮你记录某个网站的登录状态信息,不至于你每次访问都需要输入账号和密码。
关于cookie-session也需要是通过头部字段来完成信息交互的,这里就不扩展,我们继续往下学习:
Referer
浏览器的"后退 / 前进"按钮功能,是通过维护历史访问的 uri 记录实现的,当浏览器从该页面点击访问服务器时,请求报文的头部字段会带上Referer:当前uri路径来告诉服务器该请求是来源于那个网页的。
User-Agent
通常客户端请求会携带User-Agent字段,该字段包含了客户端浏览器和版本信息、引擎信息、操作系统信息、设备类型等。服务器可能会据此提供不同的服务,比如服务器识别你的设备是手机就给你app下载包,而不是windows下载包。
- 注意:一些钓鱼网站可能会利用这些信息,要注意防范。
最简单的请求仅需一个请求行即可完成,这意味着在减少信息暴露的前提下,可通过客户端实现网页抓取。
- 爬虫的本质:模拟浏览器行为,获取指定连接下的网页。
- 反爬机制 :部分服务器会校验 HTTP 请求的完整性(如是否携带
User-Agent、Referer等字段),若请求不完整(例如缺少User-Agent),则会判定为非法请求并拒绝响应。 - 绕过防爬机制 :伪造
User-Agent等信息。
搜索引擎本质就是爬虫,把首页连接和里面的部分信息留下来呈现给用户。
Location
该字段用来做重定向地址,在下文讲解
4.3 状态码与状态描述
在状态码中1开头,2开头,...,它们代表着不同的类别,如下:
| - | 类别 | 原因短语 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
状态码对照表:https://tool.oschina.net/commons?type=5
部分截图: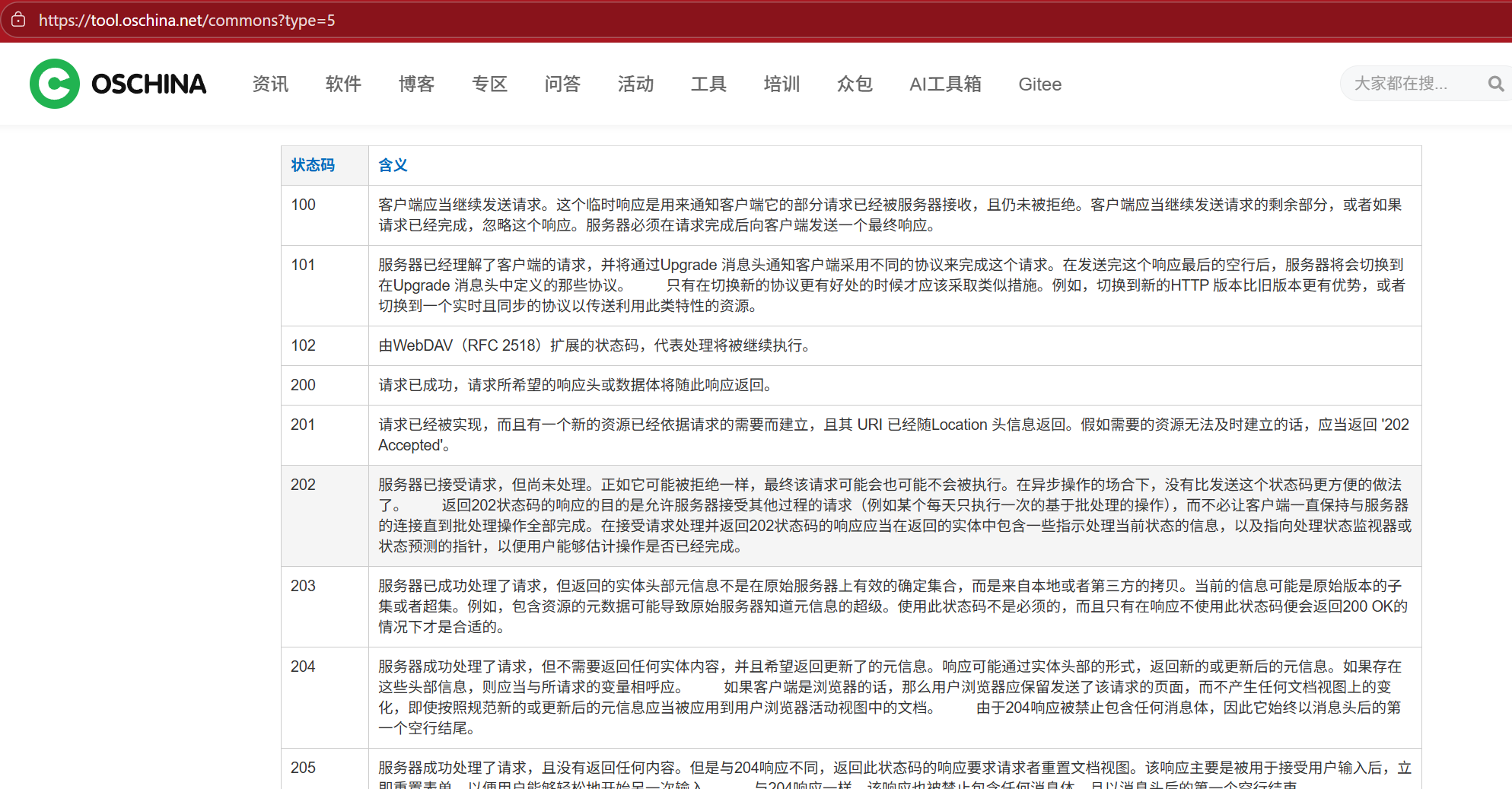
常用状态码即含义:
| 状态码 | 状态描述 | 应用样例 |
|---|---|---|
| 100 | Continue | 上传大文件时,服务器告诉客户端可以继续上传 |
| 200 | OK | 访问网站首页,服务器返回网页内容 |
| 201 | Created | 发布新文章,服务器返回文章创建成功的信息 |
| 204 | No Content | 删除文章后,服务器返回"无内容"表示操作成功 |
| 301 | Moved Permanently | 网站换域名后自动跳转到新域名;搜索引擎更新网站链接时使用 |
| 302 | Found 或 See Other | 用户登录成功后重定向到用户首页 |
| 304 | Not Modified | 浏览器缓存机制,对未修改的资源返回304状态码 |
| 400 | Bad Request | 填写表单时格式不正确导致提交失败 |
| 401 | Unauthorized | 访问需要登录的页面时未登录或认证失败 |
| 403 | Forbidden | 尝试访问你没有权限查看的页面 |
| 404 | Not Found | 访问不存在的网页链接 |
| 500 | Internal Server Error | 服务器崩溃或数据库错误导致页面无法加载 |
| 502 | Bad Gateway | 使用代理服务器时,代理服务器无法从上游服务器获取有效响应 |
| 503 | Service Unavailable | 服务器维护或过载,暂时无法处理请求 |
优化setCode函数:
cpp
void setCode(int code)
{
_rsp._state_code = code;
switch (code)
{
case 200:
_rsp._state = "Success";
break;
case 404:
_rsp._state = "Not Found";
break;
// 永久重定向
case 301:
_rsp._state = "Moved Permanently";
// 临时重定向
case 302:
_rsp._state = "See Other";
//......
default:
_rsp._state = "None";
break;
}
}这里我们重点来学习一下重定向功能:
- 临时重定向:这个地址临时改变,以后还会回来。如注册登录或csdn等各app平台上刚点进去就进行广告跳转。下一次访问还是去原地址。
- 永久重定向:地址永久改变。第一次访问进行跳转,再次访问就直接去改变后的地址。
临时重定向和永久重定向在用户使用上是感受不出来区别的。那么区分两种重定向的意义在于什么?永久重定向最大的价值就是用来给搜索引擎(浏览器)更新网址,下一次搜索时,搜索引擎就会直接提供新地址的链接。
换一个角度来说,临时重定向主要作用于用户,永久重定向主要作用于浏览器。
重定向操作只需要我们将响应报文的状态码设置为301或302,然后添加头部字段Location:新uri来提供新地址。但客户端收到报文后检查状态码,发现是3xx后会提取Location字段,用新地址再次发起请求。因此重定向的响应报文通常都没有正文部分。
客户端发起一个无效的uri资源路径请求时,我们就不用做哪些复杂的操作,直接重定向到404页面即可。
- 注意1:一个浏览器页面就像以首页为根的多叉树,请求的再次发起通常是通过点击页面链接,而不是直接输入
uri地址,所以404情况很少出现。 - 注意2:在部分开发场景中,状态码的规范使用可能未被严格重视,存在不按标准填写的情况,因此排查网页问题时,不能仅以状态码作为唯一依据,还需结合请求日志、响应内容等进一步分析。而且
5开头的状态码会很少见,尽管确实是服务器出问题。因为这会暴露自己服务器短板,被黑客利用。
4.4 GET和POST
GET:从远端获取内容,也可以把资源上传到远端。POST:把资源上传到远端。
如上,GET和POST都能把资源上传到远端,那么它们的区别是什么,POST的意义何在?
事实上它们上传的方式是不同的,GET通过uri上传,而POST通过请求正文上传。所以GET上传不了大的资源,通常是登陆和注册的时候用。
测试:
接下来我们往首页里添加登陆和注册功能,完善login.html文件做一个提交表单 。(这一部交给AI即可)
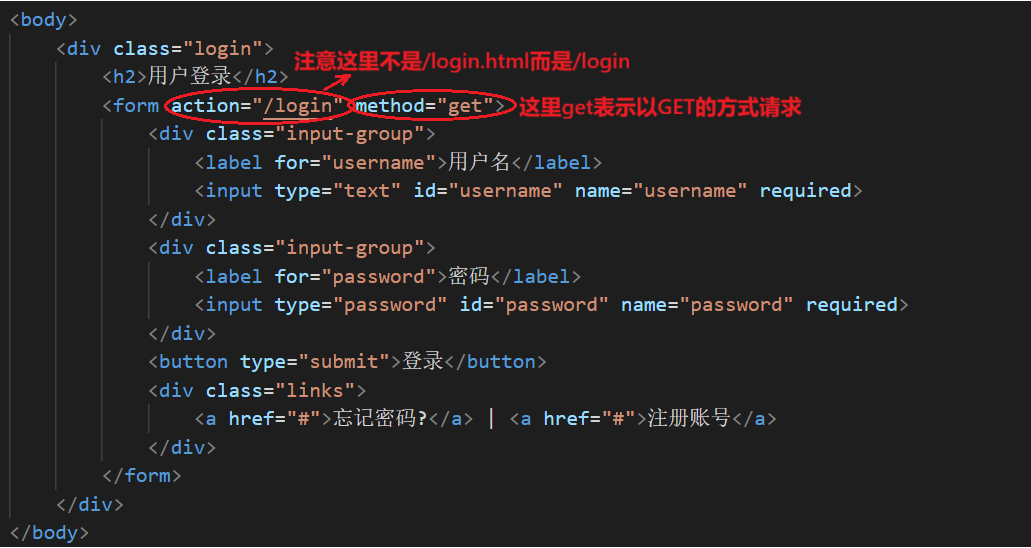
访问网站,跳转到登陆页面,提交登陆信息:
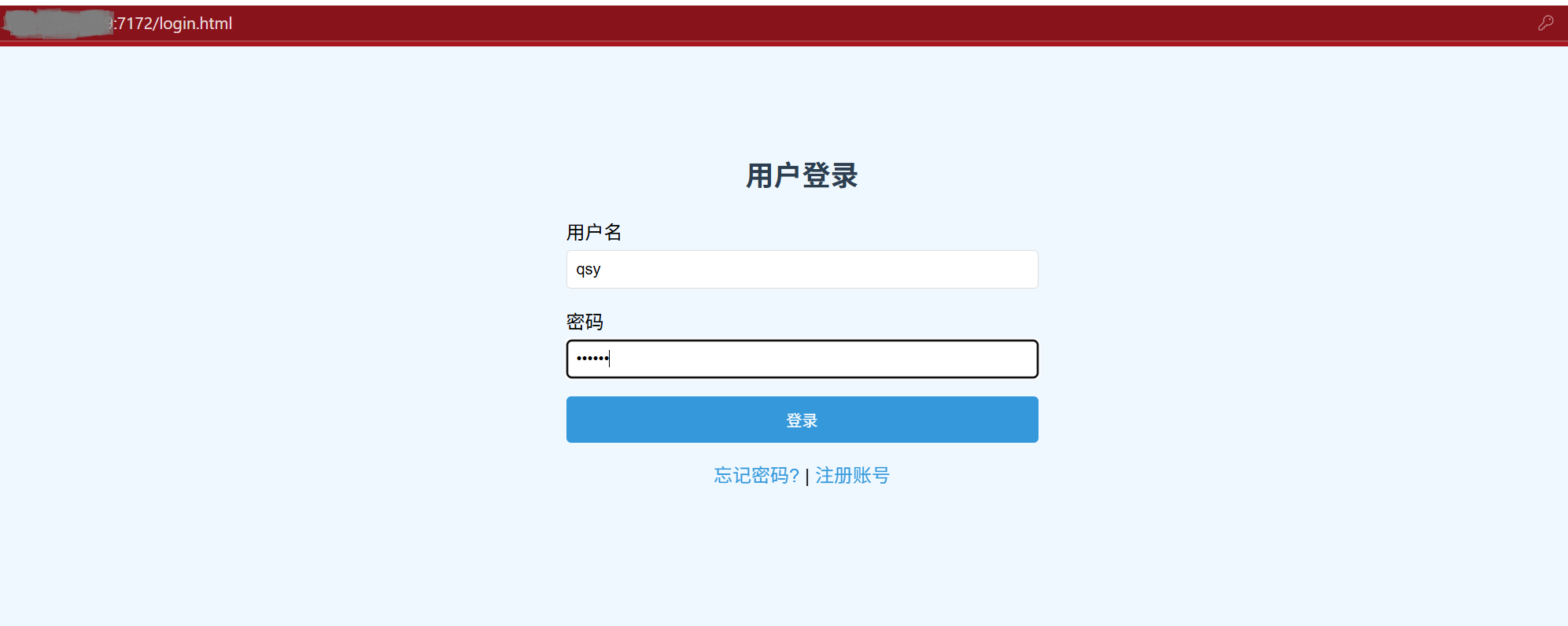
POST方法:
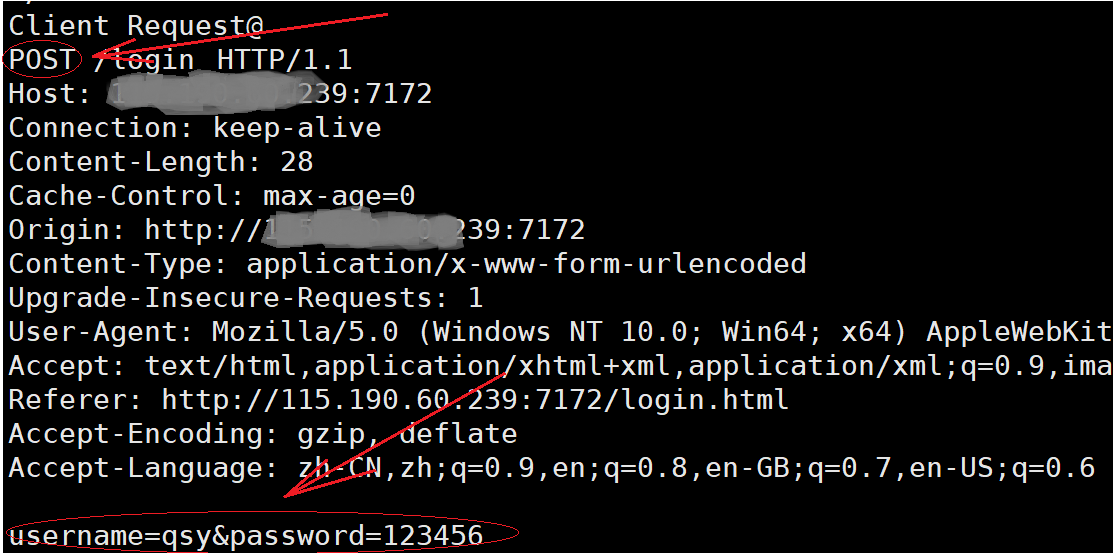
GET方法:
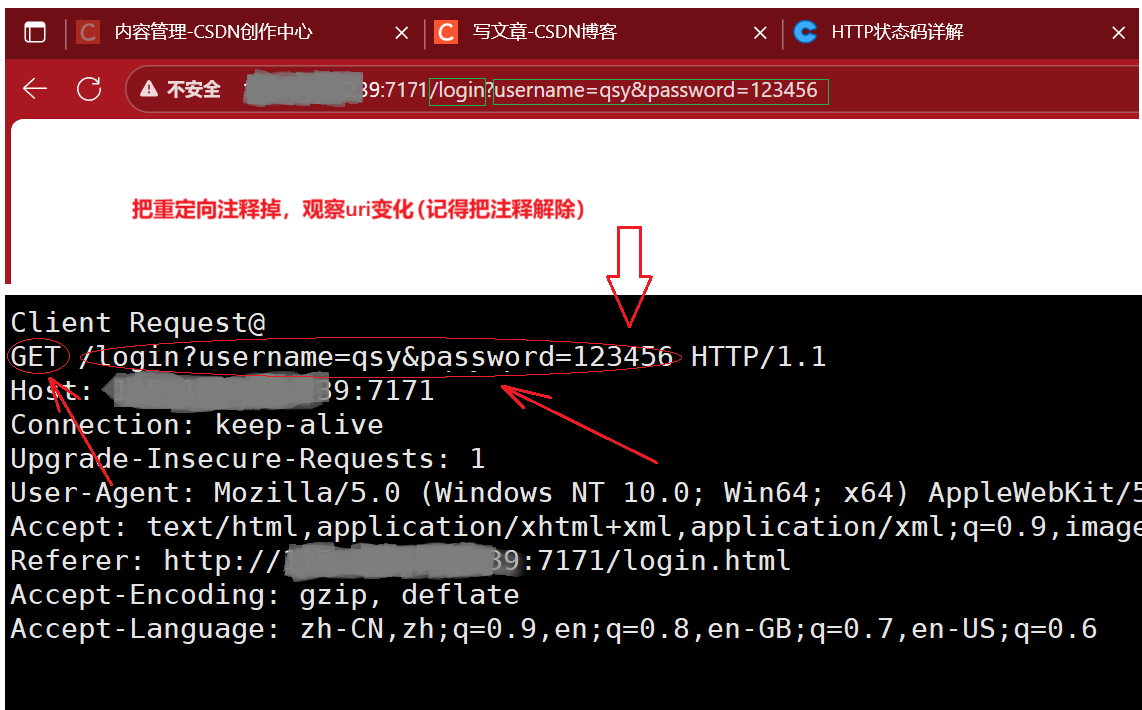
关于action参数这里填写了login,也可以填资源地址,取决于自己怎么处理。示例login相当于一个微服务 ,怎么理解呢?
可以做一个用来管理各个服务的数据结构(类似函数指针管理),然后提前注册一个login服务(把函数添加到管理结构中),主要做账号密码与数据库比对,然后根据不同的结果重定向到不同的资源路径。
服务器接收到请求后提取到login,判断不是资源路径,然后去匹配服务调用对应的接口。register等服务也是类似的操作。
- 注意:如上图片,用
GET请求方法时,账号和密码是回显在搜索窗口的,HTTP协议并不安全,相当于数据在网络中裸奔。基本上没人用了,而是使用HTTPS协议,HTTPS是HTTP的安全升级版,其本质是在HTTP下层加入了一个安全层(SSL/TLS协议),为数据传输提供加密、认证和完整性校验。
HTTPS协议学习:
从明文裸奔到密钥长城:HTTPS加密全链路攻防与CA信任锚点构建
非常感谢您能耐心读完这篇文章。倘若您从中有所收获,还望多多支持呀!
五、源码
- http.hpp
cpp
#include <unordered_map>
#include <string>
#include <sstream>
#include <fstream>
#include <sys/socket.h>
using namespace std;
const string blank = " ";
const string mark = "\r\n";
const string kv_mark = ": ";
const string webroot = "./wwwroot";
const string homepage = "index.html";
const string errofile = "404.html";
typedef struct httpRequest
{
string _method;
string _uri;
string _versions;
unordered_map<string, string> _head_data;
string _text;
} httpRequest;
typedef struct httpResponse
{
string _versions;
int _state_code;
string _state;
unordered_map<string, string> _head_data;
string _text;
} httpResponse;
class Http
{
public:
// 解包(反序列化)
inline bool GetOneline(string &out, string &src)
{
int pos = src.find(mark);
if (pos == string::npos)
return false;
out = src.substr(0, pos);
src = src.erase(0, pos + mark.size());
return true;
}
bool Deserilize(string src) // 只有一个完整的http报头
{
// 提取请求行
string out;
GetOneline(out, src);
// 解包请求行
stringstream ss(out);
ss >> _req._method >> _req._uri >> _req._versions;
// 提取并解包请求报头
out.clear();
while (out != "")
{
int pos = out.find(kv_mark);
if (pos == string::npos)
return false;
_req._head_data[out.substr(0, pos)] = out.substr(pos + kv_mark.size());
out.clear();
GetOneline(out, src);
}
// 提取请求正文
_req._text = src;
return true;
}
// 封包(序列化)
string Serilize()
{
// 响应行
string out;
out += _rsp._versions + blank + to_string(_rsp._state_code) + blank + _rsp._state;
out += mark;
// 响应报头
for (auto [key, val] : _rsp._head_data)
{
out += key + kv_mark + val + mark;
}
out += mark; // 空行
// 响应正文
out += _rsp._text;
return out;
}
std::string UriSuffix(std::string &targetfile)
{
int pos = targetfile.rfind(".");
if (pos == string::npos)
return "text/html";
string str = targetfile.substr(pos);
if (str == ".html" || str == ".htm")
return "text/html";
else if (str == ".txt")
return ".txt";
else if (str == ".png")
return "image/png";
else if (str == ".jpg" || str == ".jpeg")
return "image/jpeg";
else
//......
return "";
}
string setText()
{
string file;
if (_req._uri == "/")
file = webroot + _req._uri + homepage;
else
file = webroot + _req._uri;
// 检查uri文件是否存在
ifstream in(file);
// if (!in.is_open())
// {
// file = webroot + '/' + errofile;
// _req._uri = errofile;
// ifstream in(file);
// if(!in.is_open()) return "";
// }
if (!in.is_open())
return "";
// 将文件内容写入响应正文
in.seekg(0, in.end);
int size = in.tellg();
in.seekg(0, in.beg);
_rsp._text.resize(size);
in.read((char *)(_rsp._text.c_str()), size);
in.close();
return file;
}
void setVersion(string ver = "HTTP/1.1")
{
_rsp._versions = ver;
}
void setCode(int code)
{
_rsp._state_code = code;
switch (code)
{
case 200:
_rsp._state = "Success";
break;
case 404:
_rsp._state = "Not Found";
break;
// 永久重定向
case 301:
_rsp._state = "Moved Permanently";
// 临时重定向
case 302:
_rsp._state = "See Other";
//......
default:
_rsp._state = "None";
break;
}
}
void setHeader(string key, string val)
{
_rsp._head_data.insert({key, val});
}
httpRequest _req;// 请求报头
httpResponse _rsp;// 响应报头
};
cpp
#include "server.hpp"
#include <memory>
int main(int argc,char* argv[])
{
if(argc!=2)
{
std::cout<<"Usage "<<argv[0]<<" port"<<std::endl;
return 1;
}
std::unique_ptr<Server> sv(new Server(std::stoi(argv[1])));
sv->Run();
return 0;
}- Makefile
cpp
server:main.cc
g++ -o $@ $^ -std=c++17
.PHONY:clean
clean:
rm -rf server- server.hpp
cpp
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netinet/ip.h>
#include <arpa/inet.h>
#include "task.hpp"
class Server
{
public:
Server(int port)
: _port(port), _isrunning(false)
{
/*打开套接字*/
_listenfd = socket(AF_INET, SOCK_STREAM, 0);
/*绑定端口*/
sockaddr_in server_addr;
server_addr.sin_family = AF_INET; // 设置为IPv4
// 主机序列->网络序列
server_addr.sin_port = htons(_port);
server_addr.sin_addr.s_addr = INADDR_ANY;
int n = bind(_listenfd, (sockaddr *)&server_addr, sizeof(server_addr));
/*打开监听*/
static const int backlog = 10; // 允许10个客户端连接
n = listen(_listenfd, backlog);
}
void Run()
{
_isrunning = true;
while (_isrunning)
{
sockaddr_in client_addr;
socklen_t len = sizeof(client_addr);
int socketfd = accept(_listenfd, (sockaddr *)&client_addr, &len);
pid_t pid = fork();
if (pid == 0)
{
close(_listenfd);
if (fork() > 0)
exit(0);
Task tk(socketfd);
tk.task();
//work(socketfd);
exit(0);
}
else
close(socketfd);
}
_isrunning = false;
}
// void work(int sockfd)
// {
// while (true)
// {
// char buffer[1024];
// int n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
// if (n <= 0)
// {
// close(sockfd);
// return;
// }
// else
// {
// buffer[n] = '\0';
// std::cout << "Client Say@ \n" << buffer;
// }
// }
// }
~Server(){}
private:
uint16_t _port;
int _listenfd;
bool _isrunning;
};- task.hpp
cpp
#include "http.hpp"
#include <iostream>
#include <unistd.h>
class Task
{
public:
Task(int clientfd)
: _clientfd(clientfd)
{
}
void task()
{
while (true)
{
// 接收报文
char buffer[1024];
int n = recv(_clientfd, buffer, sizeof(buffer) - 1, 0);
if (n <= 0)
{
// 客户端退出或读取错误
close(_clientfd);
return;
}
else
{
buffer[n] = '\0';
std::cout << "Client Request@ \n" << buffer;
_recvBuffer += buffer;
}
// 报文完整性检查,并提取一个完整报文
// 省略......
// 解包,这里应该从_recvBuffer中提取单个完整的报文,这里就省略
_http.Deserilize(_recvBuffer);
// 业务分发处理(本质填_http._rsp成员)
// ......
_http.setVersion("HTTP/1.1");
string file = _http.setText();
// if(_http._req._uri == errofile) _http.setCode(404);
// else _http.setCode(200);
if(file.empty())
{
_http.setHeader("Location", "/404.html");
_http.setCode(302);
}
//else if......
else _http.setCode(200);
_http.setHeader("Content-Length", _http.UriSuffix(file));
_http.setHeader("Content-Type",to_string(_http._rsp._text.size()));
// 封包
string out = _http.Serilize();
_sendBuffer += out;
// 发送报文
std::cout << "\n" << "Server Response@ \n" << _sendBuffer << std::endl;
send(_clientfd, _sendBuffer.c_str(), _sendBuffer.size(), 0);
}
}
private:
Http _http;
// 发送缓冲区
string _sendBuffer;
// 接收缓冲区
string _recvBuffer;
int _clientfd;
};- wwwroot/404.html
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>404 Not Found</title>
<script src="https://cdn.tailwindcss.com"></script>
<link href="https://cdn.jsdelivr.net/npm/font-awesome@4.7.0/css/font-awesome.min.css" rel="stylesheet">
</head>
<body class="bg-gray-50 min-h-screen flex flex-col items-center justify-center text-gray-800">
<h1 class="text-9xl font-bold mb-4">404</h1>
<p class="text-xl mb-8">Page not found</p>
</a>
</body>
</html>- wwwroot/index.html
html
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>简单网页</title>
<style>
body {
font-family: Arial, sans-serif;
max-width: 800px;
margin: 0 auto;
padding: 20px;
background-color: #f0f8ff;
color: #333;
line-height: 1.6;
}
h1 {
color: #2c3e50;
text-align: center;
border-bottom: 2px solid #3498db;
padding-bottom: 10px;
}
.auth-links {
text-align: right;
margin-bottom: 20px;
}
.auth-links a {
margin-left: 15px;
color: #3498db;
text-decoration: none;
}
.auth-links a:hover {
text-decoration: underline;
}
.content {
background: white;
padding: 20px;
border-radius: 8px;
box-shadow: 0 0 10px rgba(0,0,0,0.1);
margin-top: 20px;
}
.footer {
text-align: center;
margin-top: 30px;
color: #7f8c8d;
font-size: 0.9em;
}
</style>
</head>
<body>
<div class="auth-links">
<a href="login.html">登录</a>
<a href="#">注册</a>
</div>
<h1>欢迎访问我的网页</h1>
<div class="footer">
<p>© 2025 csdn敲上瘾</p>
</div>
</body>
</html>- wwwroot/login.html
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>登录</title>
<style>
body {
font-family: Arial, sans-serif;
max-width: 400px;
margin: 50px auto;
padding: 20px;
background-color: #f0f8ff;
}
.login-box {
background: white;
padding: 30px;
border-radius: 8px;
box-shadow: 0 0 10px rgba(0,0,0,0.1);
}
h2 {
text-align: center;
color: #2c3e50;
}
.input-group {
margin-bottom: 15px;
}
label {
display: block;
margin-bottom: 5px;
}
input {
width: 100%;
padding: 8px;
box-sizing: border-box;
border: 1px solid #ddd;
border-radius: 4px;
}
button {
width: 100%;
padding: 10px;
background-color: #3498db;
color: white;
border: none;
border-radius: 4px;
cursor: pointer;
}
button:hover {
background-color: #2980b9;
}
.links {
text-align: center;
margin-top: 15px;
}
a {
color: #3498db;
text-decoration: none;
}
</style>
</head>
<body>
<div class="login-box">
<h2>用户登录</h2>
<form action="/login" method="post">
<div class="input-group">
<label for="username">用户名</label>
<input type="text" id="username" name="username" required>
</div>
<div class="input-group">
<label for="password">密码</label>
<input type="password" id="password" name="password" required>
</div>
<button type="submit">登录</button>
<div class="links">
<a href="#">忘记密码?</a> | <a href="#">注册账号</a>
</div>
</form>
</div>
</body>
</html>- image/
省略