【Java八股文】12-分布式面试篇
分布式理论
CAP理论
CAP 原则又称 CAP 定理,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)这 3 个基本需求,最多只能同时满足其中的 2 个。
| 选项 | 描述 |
|---|---|
| Consistency(一致性) | 指数据在多个副本之间能够保持一致的特性(严格的一致性) |
| Availability(可用性) | 指系统提供的服务必须一直处于可用的状态,每次请求都能获取到非错的响应(不保证获取的数据为最新数据) |
| Partition tolerance(分区容错性) | 分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境都发生了故障 |
为什么CAP不可兼得
CAP 定理 告诉我们,在分布式系统中,不可能同时完美地满足 一致性 、可用性 和 分区容忍性 三个条件。你只能在这三者中选两个来做得最好,另一个可能会被妥协。
- 一致性:所有节点的数据都必须一致。
- 可用性:每个请求都会得到响应。
- 分区容忍性:系统即使在网络分区的情况下也能继续工作。
由于网络分区无法避免,所以大部分系统会选择 分区容忍性 ,然后在 一致性 和 可用性 中做权衡。例如,有的系统会牺牲一致性来提高可用性,有的则会牺牲可用性来确保一致性。
CAP对应模型及应用
- CA(一致性 + 可用性)
- 传统的单节点数据库或集群中没有网络分区的情况。
- 例如,MySQL、PostgreSQL 通过主从复制可以保证一致性和可用性,但如果网络出现问题,它们会丢失一些请求。
- CP(一致性 + 分区容错性) :
- 放弃 A(可用),相当于每个请求都需要在 Server 之间强一致,而 P(分区)会导致同步时间无限延长,如此 CP 也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
- HBase、Zookeeper 等,它们会在网络分区时牺牲可用性,保证数据的一致性。某些请求会被延迟或丢失,但数据的正确性是被保证的。
- AP(可用性 + 分区容错性) :
- 要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的 NoSQL 都属于此类。
- MongoDB**、Eureka、DNS、**Couchbase 等,优先保证系统始终能够响应请求,即使在网络分区发生时,数据也可能是最终一致的。这些系统通常会容忍数据不一致,直到网络恢复后进行数据同步。
BASE理论
BASE 的主要含义:
- Basically Available(基本可用)
什么是基本可用呢?假设系统出现了不可预知的故障,但还是能用,只是相比较正常的系统而言,可能会有响应时间上的损失,或者功能上的降级。
- Soft State(软状态)
什么是硬状态呢?要求多个节点的数据副本都是一致的,这是一种"硬状态"。
软状态也称为弱状态,相比较硬状态而言,允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
- Eventually Consistent(最终一致性)
上面说了软状态,但是不应该一直都是软状态。在一定时间后,应该到达一个最终的状态,保证所有副本保持数据一致性,从而达到数据的最终一致性。这个时间取决于网络延时、系统负载、数据复制方案设计等等因素。
分布式锁
MySQL如何实现分布式锁?
用数据库实现分布式锁比较简单,就是创建一张锁表,数据库对字段作唯一性约束。
- 创建锁表:在数据库中创建一个表,存储锁的状态(比如锁名和锁的时间)。
- 加锁:当一个进程想获得锁时,它尝试向表中插入一条记录。如果插入成功,就表示成功获得了锁。如果表中已有记录,说明锁已被其他进程占用。
- 释放锁:当进程完成任务后,删除表中的记录,从而释放锁。
- 超时机制:为了避免死锁,可以设置锁的过期时间,定期清理过期的锁。
优点:
- 简单易实现,适合小型项目。
缺点:
- 性能较差,频繁的数据库操作会影响系统效率。
- 在高并发下可能会成为性能瓶颈。
ZooKeeper如何实现分布式锁?
- 创建锁节点 :
- 我们创建一个父节点(如
/lock),表示锁的目录。 - 当一个客户端想要获取锁时,它会在该目录下创建一个临时有序节点。这个节点的名字由 ZooKeeper 自动生成,并且会包含一个递增的序号。比如,客户端 A 创建的节点可能是
/lock/lock-00000001,客户端 B 创建的节点可能是/lock/lock-00000002,依此类推。
- 我们创建一个父节点(如
- 获取锁 :
- 每个客户端会检查自己创建的节点在
/lock目录下的顺序。客户端会读取/lock目录下所有子节点,并比较自己节点的序号。 - 如果当前节点的序号是最小的(即没有其他节点在它之前),则表示该客户端可以获得锁。如果它的序号不是最小的,它就必须等待。
- 每个客户端会检查自己创建的节点在
- 等待和释放锁 :
- 如果某个客户端的节点不是最小的,它需要监听比自己序号小的节点的删除事件(即监听它的前驱节点)。
- 一旦前驱节点被删除,表示获得锁的客户端释放了锁,这时该客户端可以尝试重新检查自己是否可以获得锁。
- 当客户端获取到锁后,它可以执行需要保护的操作。
- 执行完操作后,客户端删除自己创建的节点,以释放锁。删除节点时,ZooKeeper 会自动删除该节点的所有子节点。
优势:
- 高可靠性:ZooKeeper 提供了强一致性,确保了锁的准确性。它保证了即使某些节点发生故障,也不会导致锁丢失或死锁。
- 顺序性:ZooKeeper 保证了创建的节点是有序的,通过序号判断谁应该获取锁,避免了竞争条件。
- 临时节点:客户端的节点是临时节点,即使客户端崩溃,锁也会自动释放,避免了死锁的情况。
劣势:
- 性能瓶颈:ZooKeeper 的性能相对较低,尤其在高并发场景下,ZooKeeper 的分布式锁可能成为系统的瓶颈。
- 依赖性高:ZooKeeper 是一个比较重的组件,增加了系统的复杂性。需要确保 ZooKeeper 集群的高可用性,否则可能会影响分布式锁的可用性。
- 监控和清理:客户端必须显式地监控和清理节点,如果节点被意外删除或未能正确清理,可能导致锁无法被释放。
Redis怎么实现分布式锁?
Redis 实现分布式锁,是当前应用最广泛的分布式锁实现方式。
Redis 执行命令是单线程的,Redis 实现分布式锁就是利用这个特性。
实现分布式锁最简单的一个命令:setNx(set if not exist),如果不存在则更新:
java
setNx resourceName value加锁了之后如果机器宕机,那我这个锁就无法释放,所以需要加入过期时间,而且过期时间需要和 setNx 同一个原子操作,在 Redis2.8 之前需要用 lua 脚本,但是 redis2.8 之后 redis 支持 nx 和 ex 操作是同一原子操作。
Redisson怎么实现分布式锁
Redisson 是 Redis 的客户端,它提供了分布式锁的实现,利用 Redis 实现高效的分布式锁。Redisson 的分布式锁实现可以通过 看门狗 机制(WatchDog)来避免锁丢失的情况。
Redisson 分布式锁的实现步骤:
- 加锁 :
- Redisson 提供了一个名为
RLock的接口来获取分布式锁,调用lock()方法即可加锁。 - Redisson 会在 Redis 中设置一个唯一的锁标识(通常是一个唯一的值),同时设置锁的超时时间。
- Redisson 提供了一个名为
- 看门狗延续 :
- Redisson 使用 看门狗机制 来保证锁不会被意外释放。看门狗会定期延长锁的过期时间,以防止锁在持有过程中被自动释放。
- 如果进程持有锁并执行操作较长时间,Redisson 会定期更新锁的过期时间。
- 解锁 :
- 操作完成后,调用
unlock()方法释放锁。如果锁被过期或自动延长了过期时间,Redisson 会自动处理。
- 操作完成后,调用
java
RedissonClient redisson = Redisson.create();// 获取 Redisson 客户端实例
RLock lock = redisson.getLock("myLock");// 获取一个分布式锁
lock.lock();// 加锁,默认锁定时间为 30 秒
// 执行业务逻辑
try {
// 业务逻辑
} finally {
// 解锁
lock.unlock();
}看门狗机制:
Redisson的"看门狗机制"(Watchdog)是一种用于监测和维护锁的超时时间的机制,它可以确保在任务没有完成时对锁的过期时间进行自动续期,以避免任务没有完成时锁自动释放的问题。
- 开启看门狗后针对当前锁创建一个线程执行延迟任务,默认每隔10秒将锁的过期时间重新续期为30秒。
- 看门狗线程会首先判断锁是否存在,如果不存在将不再续期,当程序执行unlock()方法释放锁时会将该锁的对应的延迟任务取消,此时看门狗线程结束任务。
java
tryLock(long waitTime, -1,TimeUnit unit)Redisson基本使用时用的方法,传入leaseTime参数为-1可以开启看门狗。
分布式事务
分布式事务实现方案?
- 二阶段提交(2PC):通过准备和提交阶段保证一致性,但性能较差。
- 三阶段提交(3PC):在 2PC 的基础上增加了一个超时机制,降低了阻塞,但依旧存在数据不一致的风险。
- TCC:根据业务逻辑拆分为 Try、Confirm 和 Cancel 三个阶段,适合锁定资源的业务场景。
- 本地消息表:在数据库中存储事务事件,通过定时任务处理消息。
- 基于 MQ 的分布式事务:通过消息队列来实现异步确保,利用重试机制保障最终一致性,适用于对实时性要求不高的场景。
说说Seata的XA模式
XA 模式 基于传统的 两阶段提交协议(2PC),是一种标准的分布式事务协议,支持多数据源的分布式事务。
工作原理:
- 阶段 1(准备阶段):每个参与者(即各个分支事务)先执行本地事务,并将操作结果(即事务的预提交状态)发送给协调者。
- 阶段 2(提交阶段):如果所有参与者都返回准备好的状态,协调者就会发起提交操作;如果有任何一个参与者返回失败,协调者则发起回滚操作。
特点:
- 强一致性:确保分布式系统中的所有参与者要么全部提交,要么全部回滚,保证了事务的一致性。
- 较高的性能开销:因为需要多次的网络通信和事务日志,因此性能较差,适合事务性强、对一致性要求高的场景。
缺点:
- 容错性差:如果协调者发生故障,可能会导致事务状态不一致。
- 需要支持 XA 规范的数据库,且涉及的数据库和资源管理器必须支持两阶段提交协议。
说说Seata的AT模式
AT 模式 (也称为 自动提交模式)是 Seata 提供的一个更高效的分布式事务模式。AT 模式简化了事务的处理,不需要参与者手动处理事务的提交和回滚,而是由 Seata 自动进行。
工作原理:
- 在 AT 模式下,Seata 会为每个分支事务生成一个事务日志,并在事务提交时记录所有更改操作。
- Seata 会在事务提交时自动将这些操作进行提交,或在回滚时通过补偿机制恢复到原始状态。
特点:
- 较低的性能开销:与 XA 模式相比,AT 模式性能更高,因为它减少了需要执行的协议步骤和网络交互。
- 自动化:事务的提交和回滚由 Seata 自动管理,开发者无需进行额外的事务控制。
缺点:
- 事务补偿能力较弱:如果某个分支事务执行失败,AT 模式的补偿机制需要通过一定的补偿日志来恢复,比较复杂。
- 依赖数据库支持:必须使用支持 AT 模式的数据库,如 MySQL、PostgreSQL 等。
说说Seata的TCC模式
TCC 模式 是一种基于补偿的分布式事务协议,适用于需要精细控制和补偿的场景。TCC 模式通过将事务拆分为三个阶段:Try (尝试)、Confirm (确认)和 Cancel(取消),实现高效的分布式事务控制。
工作原理:
- Try 阶段:资源锁定和业务检查,即尝试执行业务操作,并锁定资源。
- Confirm 阶段:确认操作,执行实际的业务提交。
- Cancel 阶段:取消操作,若事务需要回滚,执行补偿逻辑来恢复到初始状态。
特点:
- 高可控性:开发者可以自己控制每个阶段的执行逻辑,非常适合精细控制的场景。
- 灵活性强:支持更多的业务场景,适用于需要补偿的操作,如支付、库存扣减等。
- 最终一致性:通过补偿机制,能够处理一些未能成功完成的操作,确保最终的一致性。
缺点:
- 开发复杂:开发者需要为每个分支事务分别实现 Try、Confirm、Cancel 逻辑,增加了代码的复杂度。
- 对业务要求较高:需要根据具体的业务场景定义补偿逻辑,因此适用的场景较为有限。
TCC的预留资源有哪些方式?
- 状态标记 (Status Field): 这是最常见的方式。给相关的业务数据(如订单、账户、库存商品)增加一个状态字段。
- Try: 将状态从未处理(如 INITIAL)修改为中间状态(如 TRYING, PENDING, LOCKED, FROZEN)。例如,订单状态从 CREATED 改为 PAYMENT_PENDING。账户 TCC 冻结金额:在账户表中增加 frozen_amount 字段,Try 阶段将要操作的金额从 available_amount 移到 frozen_amount。
- Confirm: 将状态改为最终成功状态(如 CONFIRMED, SUCCESS, PAID)。例如,订单状态改为 PAID。账户 TCC:将 frozen_amount 清零,并实际扣减 total_amount。
- Cancel: 将状态改回初始状态或标记为失败状态(如 CANCELLED, FAILED)。例如,订单状态改回 CREATED 或改为 PAYMENT_FAILED。账户 TCC:将 frozen_amount 的金额移回 available_amount。
- 预留/冻结数量 (Quantity Fields): 对于库存、配额等资源。
- Try: 在库存表中,将需要数量从 available_quantity(可用库存)字段扣减,并增加到 frozen_quantity(冻结库存)字段。检查 available_quantity 是否足够是 Try 的关键逻辑。
- Confirm: 将 frozen_quantity 字段中对应的数量扣减(表示已被实际消耗)。
- Cancel: 将 frozen_quantity 字段中对应的数量加回到 available_quantity 字段。
- 插入预留记录 (Reservation Record): 创建一个单独的"资源预留表"。
- Try: 向预留表中插入一条记录,包含事务 ID (XID)、资源类型、资源标识、预留数量/信息、状态(如 RESERVING)等。
- Confirm: 更新预留表中的记录状态为 CONFIRMED。
- Cancel: 更新预留表中的记录状态为 CANCELLED 或直接删除该记录。
Try阶段失败了怎么办
Try 阶段失败是分布式事务处理中的一种正常(虽然不期望)情况,其处理机制如下:
- Try操作的原子性:
- Try 阶段的操作(例如:检查库存、扣减可用库存、增加冻结库存)本身通常应该在一个本地事务中执行。
- 这意味着,如果 Try 过程中的任何一步失败(比如状态字段更新失败、冻结金额时数据库连接断开、或者业务检查发现资源不足),这个本地事务就会回滚。
- 结果: Try 操作要么完全成功(所有数据库修改都完成),要么完全失败(数据库状态恢复到 Try 操作之前的样子),保证了 Try 阶段操作本身的原子性。
- 失败后的处理流程:
- RM 层面: 当 RM 执行 Try 操作的本地事务失败回滚后,该 RM 就知道了这个分支事务的 Try 阶段失败了。
- 报告给 TC: 这个 RM 会向 TC (事务协调器) 报告其分支事务的状态为 失败 (Failed/Aborted)。
- TC 决策: TC 在收集所有分支事务的状态时,只要收到了任何一个 分支事务的失败报告(或者某个分支超时未响应),它就会做出全局回滚 (Global Rollback) 的决策。
- 触发 Cancel: TC 会向所有参与该全局事务的 RM(包括那些可能已经成功完成了 Try 操作的 RM)发送 Cancel 指令。
- 执行 Cancel:
- 成功完成 Try 的 RM 会执行 Cancel 逻辑,释放之前预留的资源(比如把冻结金额加回可用金额,把冻结库存恢复为可用库存,或者删除预留记录)。
- 执行 Try 失败的 RM,由于其本地事务已经回滚,资源并未被预留,它的 Cancel 操作通常需要设计成幂等的空操作,或者执行一些清理逻辑(如果有的话),但核心的资源状态已经通过本地事务回滚恢复了。
分布式事务具体怎么做的?
为了方便理解,我们引入几个角色:
- TC (Transaction Coordinator):事务协调器,负责全局事务的协调,驱动全局事务的提交或回滚。通常是一个独立的服务。
- TM (Transaction Manager):事务管理器,负责开启、提交或回滚全局事务。它通常嵌入在发起全局事务的那个业务服务(应用)中。
- RM (Resource Manager):资源管理器,负责管理具体分支事务上的资源(如数据库连接)。它通常嵌入在每个参与全局事务的业务服务(应用)中,与具体的数据库等资源交互。
具体操作:
- 全局事务注册:
- TM (Transaction Manager) 首先向 TC 注册一个全局事务, TC 会生成一个全局唯一的 XID (全局事务 ID)。
- 分支事务注册:
- 每个参与全局事务的服务 (RM - Resource Manager) 在执行本地事务之前, 会向 TC 注册一个分支事务, 并将 XID 传递给下游服务。
- TC 维护全局事务与分支事务的关系。
- 资源准备 (Try 阶段, 如果是 TCC 模式):
- 如果是 TCC 模式, 各 RM 执行 Try 阶段, 尝试预留资源。
- 报告分支事务状态:
- 每个 RM 在完成本地事务后, 会将分支事务的状态 (成功或失败) 报告给 TC。
- 全局事务决策:
- TC 收集所有分支事务的状态, 做出全局事务的决策:
- 全部成功: 如果所有分支事务都成功, TC 决定提交全局事务。
- 存在失败: 如果有任何一个分支事务失败, TC 决定回滚全局事务。
- TC 收集所有分支事务的状态, 做出全局事务的决策:
- 全局事务提交/回滚:
- TC 向所有参与全局事务的 RM 发送提交或回滚指令。
- 分支事务提交/回滚执行:
- 各 RM 收到 TC 的指令后, 执行相应的提交或回滚操作。
- AT 模式: 提交分支事务, 清理 undo log; 回滚分支事务, 使用 undo log 恢复数据。
- TCC 模式: 如果提交, 执行 Confirm 阶段; 如果回滚, 执行 Cancel 阶段。
- SAGA 模式: 如果回滚, 执行相应的补偿事务。
- XA 模式: 根据 TC 指令, 提交或回滚资源。
- 各 RM 收到 TC 的指令后, 执行相应的提交或回滚操作。
- 事务结束:
- TC 释放全局事务资源, 完成事务协调过程。
实际用过这些模式吗
XA和AT都是直接修改Seata的配置即可:<font style="background-color:rgb(250, 250, 250);">data-source-proxy-mode: AT</font>
TCC则是需要一些侵入式修改,要根据具体场景进行选择,有些模块不适合TCC,比如下单,新增订单这种,不需要预留,不需要直接删了就好,而像扣余额扣库存这种,才需要预留。
具体实现步骤
- 声明接口 :
- 使用
@LocalTCC注解声明一个 TCC 事务接口。接口内包含三个方法:deduct(Try 阶段)、confirm(Confirm 阶段)、cancel(Cancel 阶段)。 - 其中,
@TwoPhaseBusinessAction注解定义了事务的名称,以及提交和回滚方法。
- 使用
- 创建冻结表 :
- 在数据库中创建一个表(如
account_freeze_tbl),用于记录冻结的金额和事务状态。 - 表中包含事务 ID(
xid)、用户 ID(userId)、冻结金额(freezeMoney)和状态(如 TRY、CONFIRM、CANCEL)等字段。
- 在数据库中创建一个表(如
- 实现服务接口 :
- 实现
AccountTCCService接口,具体处理 Try、Confirm 和 Cancel 操作。- 在
deduct方法中,首先执行扣减操作并记录冻结金额,在数据库中插入冻结记录。 - 在
confirm方法中,确认操作,删除冻结记录。 - 在
cancel方法中,回滚操作,恢复资金并修改冻结记录的状态。
- 在
- 实现
- 幂等性处理 :
- 在
cancel方法中,需要进行空回滚和幂等性判断。如果冻结记录不存在,则认为 Try 操作没有执行过,执行空回滚;如果已经执行过 Cancel 操作,直接返回,避免重复操作。
- 在
- 业务悬挂 :
- 在 Try 阶段,若冻结记录已经存在,说明事务可能已经在其他地方被执行过,业务应该挂起,拒绝当前操作。
- 修改 Controller 层 :
- 控制器层调用 TCC 服务接口的方法,而不是直接调用原始的业务逻辑。
分布式算法
Paxos算法
Paxos 算法是 基于消息传递 且具有 高效容错特性 的一致性算法,目前公认的解决 分布式一致性问题 最有效的算法之一。
在 Paxos 中有这么几个角色:
- Proposer(提议者) : 提议者提出提案,用于投票表决。
- Accecptor(接受者) : 对提案进行投票,并接受达成共识的提案。
- Learner(学习者) : 被告知投票的结果,接受达成共识的提案。
在实际中,一个节点可以同时充当不同角色。
提议者提出提案,提案=编号+value,可以表示为M,V,每个提案都有唯一编号,而且编号的大小是趋势递增的。
Paxos的基本过程
Paxos算法主要分为三个阶段:
- Prepare阶段:一个节点(提议者)向集群中的所有节点(接受者)发送一个准备请求,并附带一个提议编号。接受者会对请求做出响应,告知提议者是否愿意接受这个请求,且可能会返回之前接受的提议编号和提议值。
- Propose阶段:在接收到多数节点的响应后,提议者会选择一个提议值,并向集群中的所有节点提出该提议。如果多数节点接受这个提议,那么提议就被认为是"已接受"。
- Accept阶段:如果多数节点接受了提议,系统达成一致,所有节点都会接受这个值作为最终的决定。
Paxos的挑战
- 网络延迟和分区:Paxos要求所有节点都能在一个有效的时间窗口内进行沟通,然而实际应用中网络问题(如延迟和分区)可能导致难以保证一致性。
- 节点失败:Paxos要求有多数节点(通常是n/2+1个节点)同意某个提议,因此,即使部分节点失效,系统依然能够继续运行。
- 复杂性:Paxos的实现较为复杂,理解和调试上可能存在困难。
Raft算法
Raft 也是一个 一致性算法 ,和 Paxos 目标相同。但它还有另一个名字 - 易于理解的一致性算法 。Paxos 和 Raft 都是为了实现 一致性 产生的。这个过程如同选举一样,参选者 需要说服 大多数选民 (Server) 投票给他,一旦选定后就跟随其操作。Paxos 和 Raft 的区别在于选举的 具体过程 不同。
Raft的基本过程
Raft通过将集群中的节点分为三种角色:领导者 (Leader)、追随者 (Follower)和候选者(Candidate)。其工作过程如下:
- 领导者选举:当Raft集群启动时,首先会进行领导者选举,选举过程通过投票来确定一个集群中的领导者。领导者负责处理所有的客户端请求和日志条目的复制工作。
- 日志复制:客户端请求会被领导者接收,并将请求写入日志。然后,领导者会将日志条目复制到其他追随者节点。如果多数节点(包括领导者)都成功接收到该日志条目,那么该条目就被认为是"已提交"。提交的日志会在所有节点上应用,确保一致性。
- 心跳机制:领导者定期发送心跳信号(空日志条目)给追随者,确保它们不发起选举请求。如果在规定时间内没有收到领导者的心跳信号,追随者会进入候选状态并重新发起选举。
- 日志一致性:每个日志条目都有一个唯一的索引和任期号。Raft保证所有的日志条目在多数节点之间是一致的。
- 安全性:Raft保证领导者只会提交它已经复制到大多数节点的日志条目。此外,Raft确保只有一个领导者能够存在,避免了Paxos中的冲突问题。
Paxos和Raft的对比
| 特性 | Paxos | Raft |
|---|---|---|
| 理论背景 | 最早的分布式一致性算法 | Raft旨在简化Paxos,设计上易于理解 |
| 节点角色 | 提议者、接受者、学习者 | 领导者、追随者、候选者 |
| 一致性保证 | 需要所有节点对提议达成一致 | 领导者控制一致性,简化日志复制过程 |
| 领导者角色 | 无领导者 | 领导者负责所有客户端请求与日志复制 |
| 网络容忍度 | 容忍网络分区和部分节点故障 | 容忍领导者故障,通过选举恢复 |
| 实现复杂度 | 实现复杂,调试困难 | 实现简洁,易于理解 |
| 主要缺点 | 实现复杂、性能问题 | 领导者瓶颈,系统可用性依赖领导者 |
分布式设计
什么是幂等性?
幂等性是一个数学概念,用在接口上:用在接口上就可以理解为:同一个接口,多次发出同一个请求,请求的结果是一致的。
在系统的运行中,可能会出现这样的问题:
- 用户在填写某些form表单时,保存按钮不小心快速点了两次,表中竟然产生了两条重复的数据,只是 id 不一样。
- 开发人员在项目中为了解决接口超时问题,通常会引入了重试机制。第一次请求接口超时了,请求方没能及时获取返回结果(此时有可能已经成功了),于是会对该请求重试几次,这样也会产生重复的数据。
- mq 消费者在读取消息时,有时候会读取到重复消息,也会产生重复的数据。
这些都是常见的幂等性问题。
在分布式系统里,只要下游服务有写(保存、更新)的操作,都有可能会产生幂等性问题。
PS:幂等和防重有些不同,防重强调的防止数据重复,幂等强调的是多次调用如一次,防重包含幂等。
怎么保证接口的幂等性
- 使用唯一标识符:给每个请求加个唯一的ID,服务器根据这个ID来判断是否已经处理过,如果处理过就直接返回结果。
- 检查资源是否已存在:比如创建订单时,检查订单是否已经存在,避免重复创建。
- 数据库唯一约束:用数据库的唯一性约束来确保某些字段(比如订单号)不会重复。
- 版本号/时间戳:对于更新操作,检查资源的版本号或时间戳,避免重复更新。
- 限制重试:限制请求的重试次数,防止网络问题导致的重复请求。
如何设计一个分布式ID?
- 如果对性能和顺序性有较高要求,且有分布式系统的需求,Snowflake算法是一个常用且有效的方案。
- 如果只需要保证全局唯一性,并且ID长度不敏感,可以选择UUID。
- 如果希望数据库生成ID并且控制分布式锁的使用,可以选择数据库自增ID + 分布式锁。
雪花算法是如何生成分布式ID的?

雪花算法生成步骤:
- 获取当前时间戳:记录当前时间(精确到毫秒)。
- 时间回拨处理:如果当前时间小于上次生成 ID 的时间,发生了回拨(时钟回退)。
- 计算 ID 生成的各个部分 :
- 时间戳 :计算当前时间与自定义起始时间(Epoch)之间的差值,得到时间戳。41位
- 机器 ID+服务ID :由机器/节点的标识决定,通常是由配置文件或其他方式分配的。这个可以自由组合,只要能区分开就行。
- 序列号 :如果同一毫秒内生成多个 ID,序列号会递增。当同一毫秒内生成超过最大数量时,算法会等待下一毫秒。12位
- 拼接生成唯一 ID:将以上的各个部分拼接起来,形成一个 64 位的唯一 ID。
UUID是如何生成分布式ID的?
UUID(通用唯一识别码)通常是 128 位长,表示为 32 个十六进制数字,通常以五个部分形式呈现:8+4+4+4+12
其中每个 x 是一个十六进制数字(0-9, a-f)。UUID 的总长度是 128 位,即 16 字节。
uuid不同的生成方法:
- 基于时间(Time-based UUID)
- 基于名称 (Name-based UUID):通过对某些输入数据(如域名)进行哈希计算来生成,确保相同的输入数据每次生成的 UUID 相同。
- UUID 的
Version 3使用 MD5 哈希算法 Version 5使用 SHA-1 哈希算法。
- UUID 的
- 随机生成 (Random-based UUID):UUID 的
Version 4,即使用 122 位的随机数生成。
Java Hutool UUID 生成方法 :Hutool 默认采用 UUID Version 4(随机生成) 的方式来生成 UUID。
分布式限流
你知道那些限流算法?
- 计数器
计数器比较简单粗暴,比如我们要限制 1s 能够通过的请求数,实现的思路就是从第一个请求进来开始计时,在接下来的 1s 内,每个请求进来请求数就+1,超过最大请求数的请求会被拒绝,等到 1s 结束后计数清零,重新开始计数。
这种方式有个很大的弊端:比如前 10ms 已经通过了最大的请求数,那么后面的 990ms 的请求只能拒绝,这种现象叫做"突刺现象"。
- 漏桶算法
就是桶底出水的速度恒定,进水的速度可能快慢不一,但是当进水量大于出水量的时候,水会被装在桶里,不会直接被丢弃;但是桶也是有容量限制的,当桶装满水后溢出的部分还是会被丢弃的。
算法实现:可以准备一个队列来保存暂时处理不了的请求,然后通过一个线程池定期从队列中获取请求来执行。
- 令牌桶算法
令牌桶就是生产访问令牌的一个地方,生产的速度恒定,用户访问的时候当桶中有令牌时就可以访问,否则将触发限流。
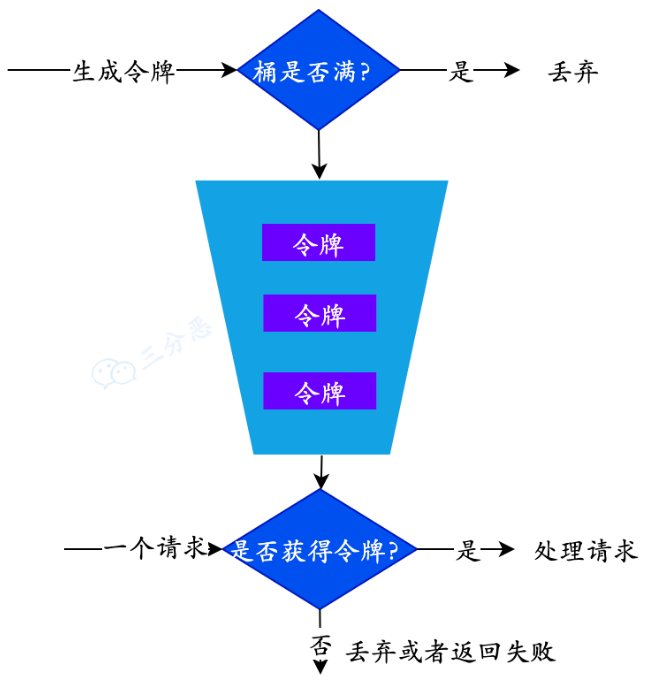
令牌桶算法的具体实践参照Redis篇《如何设计秒杀场景处理限流?》