一般,我们说把业务系统数据库如 MySQL、Oracle、MongoDB 的库表数据、日志如埋点等数据以及第三方等其他数据同步至数据仓库之中,称为数据同步,一般同步过来的数据直接原封不动的存放在 ODS(Operational Data Store)贴源层。数据接入是数据入仓的第一关,数据接入后一般可以开发一些数据对账任务(对账系统就是要及时发现哪些数据表缺失,然后系统或者业务人员根据这些缺失数据表及时进行干预处理,确保同步前后保证数据的一致性。),或者配置一些数据质量监控规则,在数据入仓后就做好第一道数据质量防线。
数据同步的方案
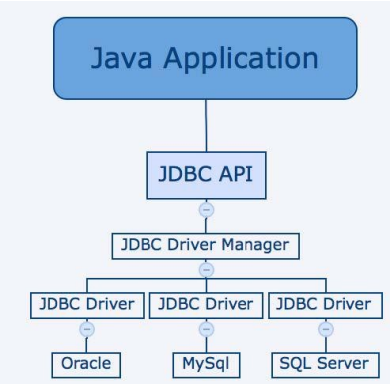
1. 直连(JDBC)
object MysqlToHive {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local")
.appName("mysql to hive")
.enableHiveSupport()
.getOrCreate()
// 隐式转换
import spark.implicits._
// 配置 mysql 数据源
val df = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://localhost:3306/ds_test?useSSl=false")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "ds_read")
.option("password", "ds#readA0906")
.option("dbtable", "stud")
.load()
// 创建一个临时视图
df.createTempView("stud")
// hive 先创建动态分区表
spark.sql("create table ds_spark.stud1(name string, age int)")
// 动态分区表建好之后就要往里面导入数据
spark.sql("insert overwrite table ds_spark.stud1 select name,age from stud")
}
}以上是企业中连接 mysql 的方式,如果你需要连接 Oracle、SQLServer 等数据库,只需要将上述的 jdbc 换成指定的数据库协议即可。
直连同步这也是目前大数据平台离线同步数据的主要手段,但该方式对业务源系统的性能影响可能会较大(因为读取数据表的同时会影响业务库的 qps),比如涉及到大批量数据同步时会拖垮业务系统的性能,如果业务数据库有采用主从库策略的话,那么我们从数据库抽取数据还可以避免对业务系统的影响,但是对于数据量大的表同步,效率将不会太高。
-
优点:实现简单,是大数据平台离线同步的主要手段。
-
缺点:同步数据量大的表,会影响业务系统的性能,谨慎操作,数据库若有主从库策略则要从从库抽数避免对业务系统直接影响,而且还要制定数据接入规范,避免业务高峰期大批量抽数操作,不然随时会带来影响线上服务的风险。
2. 数据文件同步
互联网是不安全的,很多涉密的数据是没有办法直接从公网进行直接拉的,这个时候数据就要以数据文件的形式进行线上或者线下传输。数据文件同步通过约定好的文件编码、大小、格式等,直接从源系统生成数据的文本文件,由专门的文件服务器,如 FTP 服务器传输到目标系统后,加载到目标数据库系统中;甚至涉密级别更高的一些数据直接走线下的 U 盘、硬盘进行来回拷贝。
互联网的日志类数据通常是以文件形式保存的,适合这种同步方式。不过如果通过文件服务器上传下载的话难免会有丢包或者错误的风险,所以在传输数据文件的同时,为了确保数据文件同步的完整性,会一并传输一个校验文件,该校验文件记录了数据文件的数据量以及文件大小等校验信息,以供下游目标系统验证数据同步的准确性。目前在大数据的下载平台上支持三种文件校验算法:asc、md5 及 sha1。
object CsvSource {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local")
.appName("csv")
.getOrCreate()
// 隐式转换
import spark.implicits._
// 使用 header 选项
// 使用 schema 参数
val schema =
"""
|name string,
|age int,
|height int
|""".stripMargin
val df = spark.read
// .option("header",true)
.schema(schema)
.csv("src/main/resources/data/people.csv")
df.write.csv("src/main/resources/data/people1.csv")
}
}- 优点:当数据源包含多个异构的数据库系统时,用这种方式比较简单、实用。另外,日志类数据通常是以文本文件形式存在的,也适合使用数据文件同步方式。
- 缺点:通过服务器上传和下载的话难免会出现丢包或者错误的风险,保证数据文件同步的完整性和安全性以及传输效率,可在传输数据文件的同时需要一并传输一个校验文件供目标系统校验,同时在传输存储较大文件时需要对数据文件进行加密和压缩操作
3. 数据库日志解析同步(偏实时)
大多数主流数据库都已经实现了使用日志文件(binlog)进行系统恢复,因为日志文件信息足够丰富,而且数据格式也很稳定,完全可以通过解析日志文件获取发生变更的数据(CDC:Change Database Capture)。因此有了这一机制,我们可以通过监控该文件,通过该文件的变动从而满足全量或者增量数据同步的需求,比如 mysql,一般是通过解析 binlog 日志方式来获取增量的数据更新,并通过消息订阅模式来实现数据的实时同步。
Mysql 的 binlog 一般的产生如下:
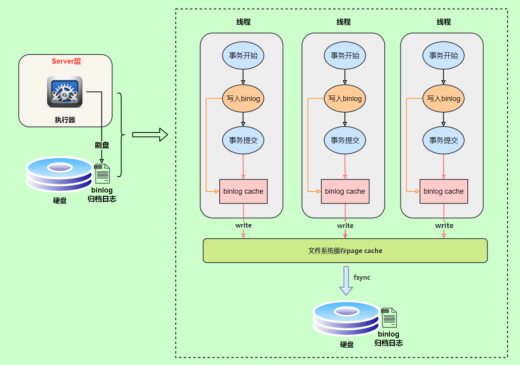
优点:
- 日志文件信息足够丰富,数据格式稳定,通过解析日志文件满足增量数据同步的需求。
- 通过网络协议,确保数据文件的正确接收,提供网络传输冗余,保证数据的完整性。
- 实现了实时与准实时同步的能力,延迟控制在毫秒级别。
缺点:
- 当数据更新量超出系统处理峰值,会导致数据延迟。
- 投入较大,需要在源数据库和目标数据库之前部署一个实时数据同步系统。
- 数据漂移和遗漏。
数据同步方式
1. 增量同步
增量同步,就是每天只将业务数据中的新增及变化数据同步到数据仓库。采用每日增量同步的表,通常需要在首日先进行一次全量同步。
insert overwrite table ods.table_in partition (dt='${yyyy-MMdd}')
select *
from table_source -- 业务源表
where create_time >= '调度当日时间'
or update_time >= '调度当日时间'这样每日增量同步过来的数据都放在增量分区表的每日分区内,可以保存数据的历史变更状态,不过要取历史全量数据的数仓最新状态数据对于增量分区表的话就会取数麻烦些。比如要取全量订单记录当前最新状态,需要先扫描增量分区表历史全部分区得到全量订单数据,再取每笔订单数仓最新的那条状态记录。
2. 全量同步
全量同步,就是每天都将业务数据库中的全部数据同步一份到数据仓库,这是保证两侧数据同步的最简单的方式。
-- 方式一,很少使用
insert overwrite table ods.table_tm
select *
from table_source -- 业务源表
-- 方式二,分区全量表(又称为快照表)
insert overwrite table ods.table_tm partition (dt='${yyyy-MM-dd}')
select *
from table_source -- 业务源表不过全量同步这种抽取数据的方式不建议使用,数据量小还行,因为每日分区存储一份历史全量数据会对 HDFS 存储造成浪费是一方面,当数据量大的话这样做是绝不可行的,会拖垮业务源系统数据库,对业务源数据库造成压力负载,严重时还会造成线上故障。所以建议一般对于小数据量可以选择全量同步,而对于大数据量的数据则选择增量同步。
3. 增量合并全量同步
基于以上增量同步和全量同步 2 种同步数据方式的利弊,结合起来形成一种同步 T+1的增量数据,再合并历史 T+2 的全量数据的抽取数据的方式,这样就在最新分区表里即满足了数仓的全量最新快照数据,同时也降低了对存储的浪费以及对业务源数据库的压力负载,兼容了上述 2 种策略。
-- 增量合并全量方案一:union all,推荐
insert overwrite table 全量表 partition (dt = '${yyyy-MM-dd}')
select *
from
(
select
* ,
row_number() over (partition by 去重主键 order by 时间字段
desc) as rk
from
(
select *
from 增量分区表
where 1 = 1
and dt = '${yyyy-MM-dd}' -- 增量表 T+1 当前增量数据
union all
select *
from 全量分区表
where 1 = 1
and dt = '${yyyy-MM-dd,-1d}' -- 全量表 T+2 历史全量数据
) a
) b
where rk = 1; -- 取最新状态数据
-- 增量合并全量方案二:full outer join
insert overwrite table 全量表 partition (dt = '${yyyy-MM-dd}')
select
-- 优先取增量表最新数据更新覆盖
coalesce(a.主键,b.主键) as 主键
,...
from
(
select *
from 增量分区表
where dt = '${yyyy-MM-dd}' -- 增量表 T+1 当前增量数据
) a
full outer join
(
select *
from 全量分区表
where dt = '${yyyy-MM-dd,-1d}' -- 全量表 T+2 历史全量数据
) b
on a.主键 = b.主键方案一和方案二这 2 种解决方案的本质上都是用增量数据来更新覆盖历史全量数据,不过通过 full outer join 方式合并前要确保记录是唯一的,这样关联时才不会发生数据发散。
若说 2 种解决方案的性能对比的话就大差不差吧,数据量大的话方案一可能发生的性能瓶颈主要在合并过程的全局排序去重,方案二可能发生的性能瓶颈主要在合并过程的大表关联上,目前在行业中离线数据接入大致也是这种思路-增量合并全量。
数据同步相关技术
离线
sqoop
Sqoop 工作机制是将导入或导出命令翻译成 MapReduce 程序来实现。
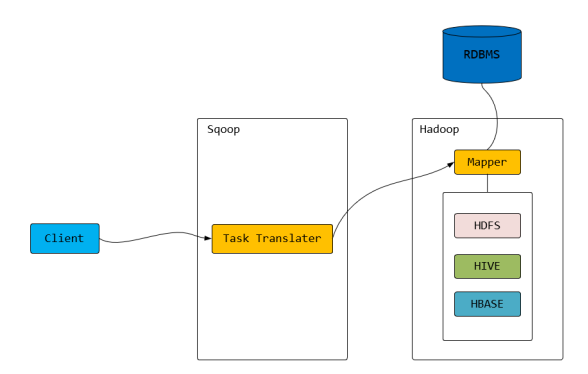
Hadoop 生态系统包括:HDFS、Hive、Hbase 等
RDBMS(关系型数据库) 体系包括:Mysql、Oracle、DB2 等
Sqoop 可以理解为:"SQL 到 Hadoop 和 Hadoop 到 SQL 的工具"。
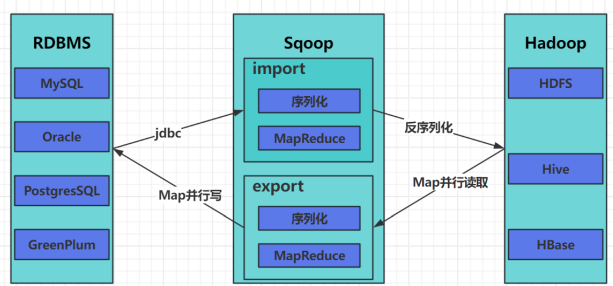
Sqoop 执行的整个过程只有 map 阶段,没有 reduce阶段。
启动验证
#本命令会列出所有 mysql 的数据库。
sqoop list-databases \
--connect jdbc:mysql://localhost:3306/ \
--username root
--password 123456
#本命令会列出所有 mysql 的数据库。
sqoop list-tables \
--connect jdbc:mysql://localhost:3306/ds_test \
--username root \
--password 123456 \全量导入 mysql 表数据到 HDFS
sqoop import \
--connect jdbc:mysql://localhost:3306/ds_test \
--username root\
--password 123456 \
--delete-target-dir \
--target-dir /test_demo/sqoop_test/ \
--fields-terminated-by '\t' \
--table stud \
--m 1- delete-target-dir:如果路径存在就自动删除
- target-dir:可以用来指定导出数据存放至 HDFS 的目录;
- m:是--num-mappers 的缩写,表示启动 N 个 mapper 任务并行,默认 4
默认用逗号,分隔,可以用--fields-terminated-by '\t':来指定分隔符
全量导入 mysql 表数据到 HIVE
-- 先在hive中创建表
sqoop create-hive-table \
--connect jdbc:mysql://localhost:3306/ds_test \
--username root\
--password 123456 \
--table stud \
--hive-table stud
-- 同步
sqoop import \
--connect jdbc:mysql://localhost:3306/ds_test \
--username root\
--password 123456 \
--table stud \
--hive-table stud \
--hive-import \
--m 1如果hive目标表已经存在了,那么创建任务失败。
导入表数据子集(where 过滤)
where 可以指定从关系数据库导入数据时的查询条件。它执行在数据库服务器相应的SQL 查询,并将结果存储在 HDFS 的目标目录。
sqoop import \
--connect jdbc:mysql://localhost:3306/ds_test \
--username root\
--password 123456 \
--table stud \
--where "name ='Tom'" \
--hive-table stud \
--hive-import \
--m 1默认是是 append 的模式,可以指定--hive-overwrite 进行数据覆盖
增量导入
在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,并不需要将表中的数据每次都全部导入到 hive 或者 hdfs 当中去,这样会造成数据重复的问题。因此一般都是选用一些字段进行增量的导入,sqoop 支持增量的导入数据,用于只导入比已经导入行新的数据行。
-
--check-column col
用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系型数据库中的自增字段及时间戳类似。
注意:这些被指定的列的类型不能使任意字符类型,如 char、varchar 等类型都是不可以的,同时-- check-column 可以去指定多个列。
-
--incremental mode
增量导入数据分为两种方式:
i、append:基于递增列的增量数据导入,必须为数值型
Ii、lastmodified:基于时间列的数据增量导入,必须为时间戳类型
-
--last-value value
指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值
append 模式
sqoop import \
--connect jdbc:mysql://localhost:3306/ds_test \
--username root\
--password 123456 \
--table stu_inc \
--m 1 \
--target-dir /test_demo/sqoop_test1 \
--incremental append \
--check-column id \
--last-value 3 // 同步时不包含词条数据- 注意点: --append and --delete-target-dir can not be used together.
lastmodified 模式
sqoop import \
--connect jdbc:mysql://localhost:3306/ds_test \
--username root\
--password 123456 \
--table stu_last \
--target-dir /test_demo/sqoop_test2 \
--m 1 \
--check-column last_modified \
--incremental lastmodified \
--last-value "2023-11-18 20:52:02" \ // 同步时包含此条数据sqoop 到处 export
默认情况下,sqoop export 将每行输入记录转换成一条 INSERT 语句,添加到目标数据库表中。如果数据库中的表具有约束条件(例如,其值必须唯一的主键列)并且已有数据存在,则必须注意避免插入违反这些约束条件的记录。如果 INSERT 语句失败,导出过程将失败。此模式主要用于将记录导出到可以接收这些结果的空表中。通常用于全表数据导出。
sqoop export \
--connect jdbc:mysql://localhost:3306/ds_test \
--username root\
--password 123456 \
--table employee \
--export-dir /test_demo/emp_data.txtsqoop缺点
1、Sqoop 属于 Hadoop 生态圈中一员,和 Hadoop 深度的绑定,深受青睐。但随着新的基于内存计算的批处理框架 Spark 的诞生,传统的 MapReduce 逐渐的淡出人们的视野,而 Sqoop 底层与 MapReduce 又是强耦合,不是解耦的。因此,随着企业逐渐 Spark 化,不能与 Spark 结合的 Sqoop 也是被历史淘汰的最大原因之一。
2、Apache Sqoop 在更新最后一个版本 1.4.7 之后就永久从 Apache 退役了,因此如果在使用的过程中如果遇到什么非常棘手的问题,很大可能找不到相应的解决办法,只能通过自己去研读源码,自己去解决相应的问题。这在快速便捷式开发的今天,可能也是被弃用的最大原因之一。
3、只支持常见的 RDBMS 如 MySQL、Oracle 等和常见的 Hadoop 生态圈的 HDFS、Hive 等 , 对于目前上市面上追捧火热的数据分析工具如 StarRocks 、 Doris 、ClickHouse 等的支持为零,主要还是停更的原因。
DataX
https://github.com/alibaba/DataX/blob/master/README.md
https://gitee.com/mirrors/DataX/blob/master/README.md
DataX 是阿里云 DataWorks 数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台,它是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。
为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源。
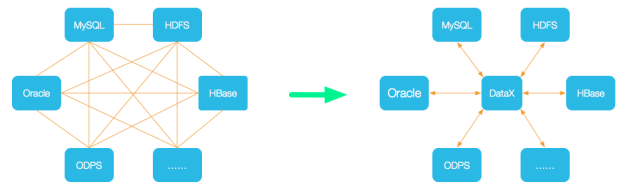
当需要接入一个新的数据源的时候,只需要将此数据源对接到 DataX,便能跟已有的数据源做到无缝数据同步。DataX 目前已经有了比较全面的插件体系,主流的 RDBMS 数据库、NOSQL、大数据计算系统都已经接入。DataX 支持目前市面上几乎所有的数据库类型,也是让他在国内大展头角的原因。
作为离线数据同步框架,采用 Framework + plugin 架构。将数据源读取、写入抽象成为 Reader/Writer 插件,纳入到整个同步框架:

- Reader:数据采集模块,采集数据源的数据,将数据发送给 Framework
- Writer: 数据写入模块,不断向 Framework 取数据,并将数据写入到目的端
- Framework:连接 reader 和 writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术
相关概念
DataX 完成单个数据同步的作业,称为== Job==,DataX 接受到一个 Job 后,将启动一个进程完成整个作业同步过程。DataX Job 模块是单个作业的中枢管理节点,承担数据清理、子任务切分(将单一作业计算转化为多个子 Task)、TaskGroup 管理等功能
DataX Job 启动后,会根据不同的源端切分策略,将 Job 切分成多个小的 Task(子任务),以便并发执行。Task 便是 DataX 作业的最小单元,每一个 Task 都会负责一部分数据的同步工作
切分多个 Task 之后,DataX Job 会调用 Scheduler 模块,根据配置的并发数据量,将拆分成的 Task 重新组合,组装成 TaskGroup(任务组)。每一个 TaskGroup 负责以一定的并发运行完毕分配好的所有 Task,默认单个任务组的并发数量为 5。
每一个 Task 都由 TaskGroup 负责启动,Task 启动后,会固定启动 Reader---
Channel---Writer 的线程来完成任务同步工作
DataX 作业运行起来之后, Job 监控并等待多个 TaskGroup 模块任务完成,等待所有 TaskGroup 任务完成后 Job 成功退出。否则,异常退出,进程退出值非 0
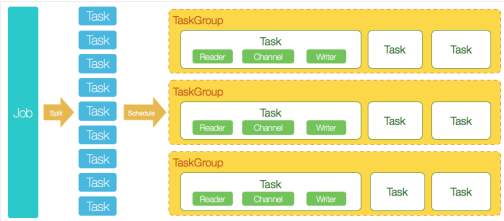
举例来说,用户提交了一个 DataX 作业,并且配置了 20 个并发,目的是将一个 100张分表的 mysql 数据同步到 ods 里面。DataX 的调度决策思路是:
- DataXJob 根据分库分表切分成了 100 个 Task。
- 根据 20 个并发,DataX 计算共需要分配 4 个 TaskGroup。
- 4 个 TaskGroup 平分切分好的 100 个 Task,每一个 TaskGroup 负责以 5 个并发共计运行 25 个 Task
使用案例
任务提交命令:用户需要根据同步数据的数据源和目的地选择相应的 Reader 和Writer,并将 Reader 和 Writer 的信息配置在一个 json 文件中,然后执行命令提交数据同步任务即可,即:python datax.py youPath/job.json
配置文件格式:查看 DataX 配置文件模板可以通过以下命令,如将 mysql 中的数据同步到 hdfs 中可以使用: python datax.py -r mysqlreader -whdfswriter

json 最外层是一个 job,job 包含 setting 和 content 两部分,其中 setting 用于对整个 job 进行配置,content 用户配置数据源和目的地。
读取 MySQL 中的数据存放到 HDFS
MySQLReader 具有两种模式,分别是 TableMode 和 QuerySQLMode,前者使用table,column,where 等属性声明需要同步的数据;后者使用一条 SQL 查询语句声明需要同步的数据。
TableMode
首先创建配置文件:.../job/stud_datax.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id", "name", "age"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://localhost:3306/test_demo"],
"table": ["student"]
}
],
"password": "123456",
"username": "root",
"where": "name = 'Alice' "
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
}
],
"compress": "gzip",
"defaultFS": "hdfs://localhost:8020",
"fieldDelimiter": "\t",
"fileName": "stud_datax",
"fileType": "text",
"path": "/test_demo/mysql_to_datax/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}注意:HFDS Writer 并未提供 nullFormat 参数:也就是用户并不能自定义 null 值写到 HFDS 文件中的存储格式。默认情况下,HFDS Writer 会将 null 值存储为空字符串(''),而 Hive 默认的 null 值存储格式为\N。所以后期将 DataX 同步的文件导入 Hive表就会出现问题。
解决方案:
一是修改 DataX HDFS Writer 的源码,增加自定义 null 值存储格式的逻辑,参考
https://blog.csdn.net/u010834071/article/details/105506580
二是在 Hive 中建表时指定 null 值存储格式为空字符串(''),例如:
DROP TABLE IF EXISTS stud;
CREATE EXTERNAL TABLE stud
(
`name` STRING ',
`age` INT
) COMMENT '学生表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/test_demo/stud';然后就可以提交任务了
- 在 HDFS 创建/test_demo/目录,使用 DataX 向 HDFS 同步数据时,需确保目标路径已存在
- 进入 DataX 的 bin 目录
- 执行命令 python datax.py .../job/stud_datax.json
QuerySQLMode
首先创建配置文件:.../job/stud_datax.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://localhost:3306/ds_test"
],
"querySql": [
"select name,age from stud where name = 'Alice'"
]
}
],
"password": "root",
"username": "123456 "
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
}
],
"compress": "gzip",
"defaultFS": "hdfs://ds-bigdata-001:8020",
"fieldDelimiter": "\t",
"fileName": "stud_datax",
"fileType": "text",
"path": "/test_demo/mysql_to_datax/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}其他操作和 TableMode 中类似,不在赘述。
DataX 的性能优化
速度控制
DataX3.0 提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制作业速度,让作业在数据库可承受的范围内达到最佳的同步速度。
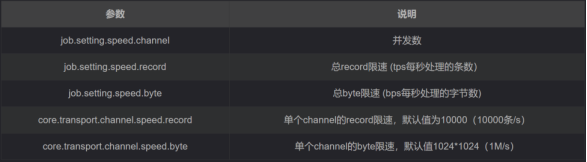
注意事项:
-
若配置了总 record 限速,则必须配置单个 channel 的 record 限速
-
若配置了总 byte 限速,则必须配置单个 channe 的 byte 限速
-
若配置了总 record 限速和总 byte 限速,channel 并发数参数就会失效。因为配置了总 record 限速和总 byte 限速之后,实际 channel 并发数是通过计算得到的,计算公式为如下:

{
"core": {
"transport": {
"channel": {
"speed": {
"byte": 1048576 //单个 channel byte 限速 1M/s
}
}
}
},
"job": {
"setting": {
"speed": {
"byte": 5242880 //总 byte 限速 5M/s
}
},
...
}
}
内存调整
当提升 DataX Job 内 Channel 并发数时,内存的占用会显著增加,因为 DataX作为数据交换通道,在内存中会缓存较多的数据。例如 Channel 中会有一个 Buffer,作为临时的数据交换的缓冲区,而在部分 Reader 和 Writer 的中,也会存在一些Buffer,为了防止 OOM 等错误,需调大 JVM 的堆内存。
建议将内存设置为 4G 或者 8G,这个也可以根据实际情况来调整。
调整 JVM xms xmx 参数的两种方式:
一种是直接更改 datax.py 脚本;
另一种是在启动的时候,加上对应的参数,如下:
python datax.py --jvm="-Xms8G -Xmx8G" yourPath/job.json实时
Maxwell
Maxwell 是由美国 Zendesk 开源,用 Java 编写的 MySQL 实时抓取工具。实时读取MySQL 二进制日志 Binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。
官网地址:http://maxwells-daemon.io/
Maxwell 的工作原理很简单,就是把自己伪装成 MySQL 的一个 slave,然后以slave 的身份假装从 MySQL(master)复制数据。
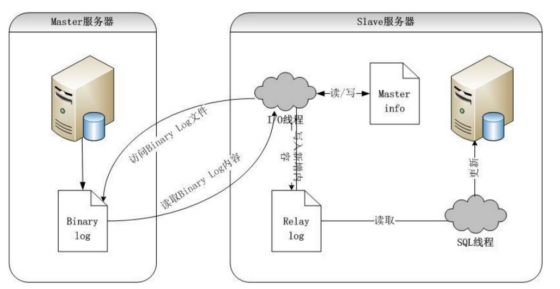
MySQL 的二进制日志可以说 MySQL 最重要的日志了,它记录了所有的 DDL 和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL 的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有 1%的性能损耗。二进制有两个最重要的使用场景:
- MySQL Replication 在 Master 端开启 binlog,Master 把它的二进制日志
传递给 slaves 来达到 master-slave 数据一致的目的。 - 自然就是数据恢复了,通过使用 mysqlbinlog 工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的 DDL 和DML(除了数据查询语句)语句事件
Maxwell 进程启动
Maxwell 进程启动方式有如下两种:
一、使用命令行参数启动 Maxwell 进程
./maxwell --user='root' --password='123456' --host='localhost' --producer=stdout其中:--producer 生产者模式(stdout:控制台,kafka:kafka 集群)
备注:在实操的时候发现以下错误,因为就是在 maxwell 1.30.0 开始,对 jdk 最低的要求已经是 11。
上述执行的前提是 mysql 已经开启 binlog,且相关的配置如下:
[client]
default_character_set=utf8
[mysqld]
server-id=1
collation_server=utf8_general_ci
character_set_server=utf8
log-bin=mysql-bin
binlog_format=row
expire_logs_days=30二、修改配置文件,定制化启动 Maxwell
[root@localhost bin]$ cp config.properties.exampleconfig.properties
[root@localhost bin]$ vim config.properties
[root@localhost bin]$ bin/maxwell --config ./config.propertiesMaxwell 的缺点
1、对 jdk 的要求比较高,目前 maxwell 的版本是 1.40.6,但是从 1.30 开始对 jdk的支持就已经上升到 11,而目前企业中用的最多的还是 jdk8,因此对企业的实际的生产环境有一定的要求
2、maxwell 对数据是无差别的监控,maxwell 的参数并没有提供类似于 database和 table 这样的参数,意味着就监控这某个源的所有数据库和所有的表,因为不适用于大数据量的环境下,只适合使用数据量比较小的情况
3、只能读取 mysql 源,因此对于目前企业中多源异构的数据源的情况并不能做很好的支撑;并且对输出端的支持也不够多,如果要写入 hive 或者 hdfs 之中,需要借助kafka 作为中间件进行转发
Flink CDC
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来(binlog),写入到消息中间件中以供其他服务进行订阅及消费。
传统上,数据源的变化通常通过周期性地轮询整个数据集进行检查来实现。但是,这种轮询的方式效率低下且不能实时反应变化。而== CDC 技术则通过在数据源上设置一种机制,使得变化的数据可以被实时捕获并传递给下游处理系统,从而实现了实时的数据变动监控==。
CDC 主要分为基于查询和基于 Binlog 两种方式,先主要了解一下这两种之间的区别:
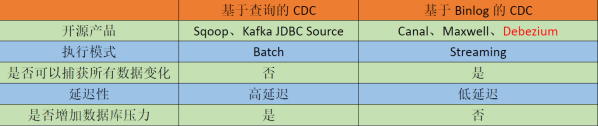
Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。目前也已开源,开源地址:https://github.com/ververica/flink-cdc-connectors。
使用 Flink CDC,我们可以轻松地构建实时数据管道,对数据变动进行实时响应和处理,为实时分析、实时报表和实时决策等场景提供强大的支持。
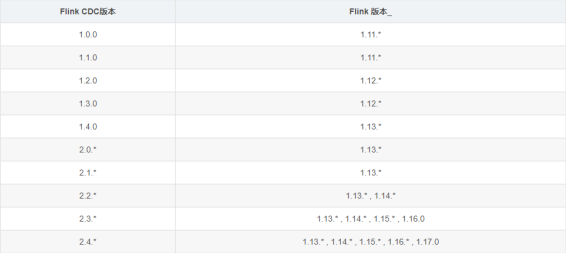
flink 与 flink cdc 的版本对应
CDC 实现的原理
通常来讲,CDC 分为主动查询和事件接收两种技术实现模式。
对于主动查询 而言,用户通常会在数据源表的某个字段中,保存上次更新的时间戳或版本号等信息,然后下游通过不断的查询和与上次的记录做对比,来确定数据是否有变动,是否需要同步。
- 优点:不涉及数据库底层特性,实现比较通用;
- 缺点:要对业务表做改造,且实时性不高,不能确保跟踪到所有的变更记录,且持续的频繁查询对数据库的压力较大。
事件接收 模式可以通过触发器(Trigger)或者日志(例如 Transaction log、Binary log、Write-ahead log 等)来实现。当数据源表发生变动时,会通过附加在表上的触发器或者 binlog 等途径,将操作记录下来。下游可以通过数据库底层的协议,订阅并消费这些事件,然后对数据库变动记录做重放,从而实现同步。
- 优点:实时性高,可以精确捕捉上游的各种变动;
- 缺点:部署数据库的事件接收和解析器(例如 Debezium、Canal、Maxwell 等),有一定的学习和运维成本,对一些冷门的数据库支持不够。
综合来看,事件接收模式整体在实时性、吞吐量方面占优,如果数据源是 MySQL、PostgreSQL、MongoDB 等常见的数据库实现,建议使用 Debezium 来实现变更数据的捕获(下图来自 Debezium 官方文档如果使用的只有 MySQL,则还可以用 Canal)。
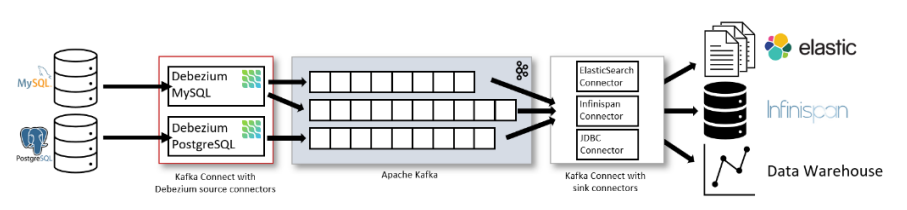
为什么选择 Flink
上图可以看到,Debezium 官方架构图中,是通过 Kafka Streams 直接实现的 CDC 功能。而我们这里更建议使用 Flink CDC 模块,因为 Flink 相对 Kafka Streams 而言,有如下优势:
- 强大的流处理引擎 : Flink 是一个强大的流处理引擎,具备高吞吐量、低延迟、Exactly-Once 语义等特性。它通过基于事件时间的处理模型,支持准确和有序的数据处理,适用于实时数据处理和分析场景。这使得 Flink 成为实现 CDC 的理想选择。
- 内置的 CDC 功能: Flink 提供了内置的 CDC 功能,可以直接连接到各种数据源,捕获数据变化,并将其作为数据流进行处理。这消除了我们自行开发或集成 CDC 解决方案的需要,使得实现 CDC 变得更加简单和高效,开箱即用。
- 多种数据源的支持: Flink CDC 支持与各种数据源进行集成,如关系型数据库(如MySQL、PostgreSQL)、消息队列(如 Kafka、RabbitMQ)、文件系统等。这意味着无论你的数据存储在哪里,Flink 都能够轻松地捕获其中的数据变化,并进行进一步的实时处理和分析。
- 灵活的数据处理能力: Flink 提供了灵活且强大的数据处理能力,可以通过编写自定义的转换函数、处理函数等来对 CDC 数据进行各种实时计算和分析。同时,Flink 还集成了 SQL 和 Table API,为用户提供了使用 SQL 查询语句或 Table API 进行简单查询和分析的方式
- 完善的生态系统: Flink 拥有活跃的社区和庞大的生态系统,这意味着你可以轻松地获取到丰富的文档、教程、示例代码和解决方案。此外,Flink 还与其他流行的开源项目(如 Apache Kafka、Elasticsearch)深度集成,提供了更多的功能和灵活性。
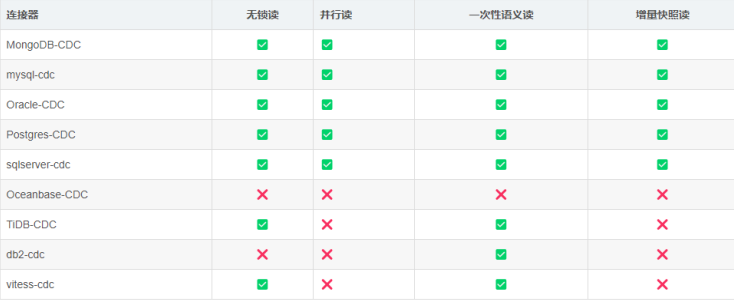
Flink CDC 特性
- 支持读取数据库快照,即使出现故障也能继续读取 binlog,并进行 Exactly-once 处理
- DataStream API 的 CDC 连接器,用户可以在单个作业中使用多个数据库和表的更改,而无需部署 Debezium 和 Kafka(已经嵌套)
- Table/SQL API 的 CDC 连接器,用户可以使用 SQL DDL 创建 CDC 源来监视单个表上的更改。

下表显示了连接器的当前特性
用法实例
在使用 flink cdc 开发数据同步时,需要一定的编程基础,相关的依赖如下:
<properties>
<flink.version>1.13.0</flink.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink 核心 API -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>并在开发前,mysql 已经开启 binlog,且相关的配置如下:
[client]
default_character_set=utf8
[mysqld]
server-id=1
collation_server=utf8_general_ci
character_set_server=utf8
log-bin=mysql-bin
binlog_format=row
expire_logs_days=30DataStream API 的用法
public class CDCDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(3000);
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("localhost")
.port(3306)
.username("root")
.password("123456")
.databaseList("lili")
// 这里一定要是 db.table 的形式
.tableList("lili.test_cdc")
.deserializer(new StringDebeziumDeserializationSchema())
.startupOptions(StartupOptions.initial()) // 全量
.build();
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
dataStreamSource.print();
env.execute("CDCDemo");
}
}Flink SQL API 的用法
public class FlinkSQLCDC {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(3000);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.executeSql("CREATE TABLE test_cdc (" +
" id int primary key," +
" name STRING," +
" age int" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'hostname' = 'localhost'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = '123456'," +
" 'database-name' = 'lili'," +
" 'table-name' = 'test_cdc'" +
")");
Table table = tableEnv.sqlQuery("select * from test_cdc");
// 回撤流
DataStream<Tuple2<Boolean, Row>> dataStreamSource = tableEnv.toRetractStream(table, Row.class);
dataStreamSource.print();
env.execute("FlinkSQLCDC");
}
}生产案例:MySQLToMySQL
public class MySQLToMySQL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(3000);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 如果原表有主键,则需要声明主键
tableEnv.executeSql("CREATE TABLE my_source (\n" +
" id INT primary key,\n" +
" name STRING,\n" +
" age INT\n" +
") WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = 'localhost',\n" +
" 'port' = '3306',\n" +
" 'username' = 'root',\n" +
" 'password' = '123456',\n" +
" 'scan.startup.mode' = 'initial'," +
" 'database-name' = 'lili',\n" +
" 'table-name' = 'test_cdc',\n" +
" 'scan.incremental.snapshot.enabled' = 'false'\n" +
" )");
// 表必须要提前创建好,这里是要写入的mysql
tableEnv.executeSql("CREATE TABLE my_sink (\n" +
" id INT primary key,\n" +
" name STRING,\n" +
" age INT\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://localhost:3306/lili?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=false',\n" +
" 'username' = 'root',\n" +
" 'password' = '123456',\n" +
" 'driver' = 'com.mysql.cj.jdbc.Driver',\n" +
" 'table-name' = 'test_cdc1'\n" +
" )");
tableEnv.executeSql("INSERT INTO my_sink\n" +
" SELECT id, name, age\n" +
" FROM my_source");
}
}Flume
Flume 是 Cloudera 提供的一个高可用 的,高可靠 的,分布式 的海量日志采集、聚合和传输的系统。
Flume 基于流式架构,灵活简单。Flume 最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到 HDFS 等。
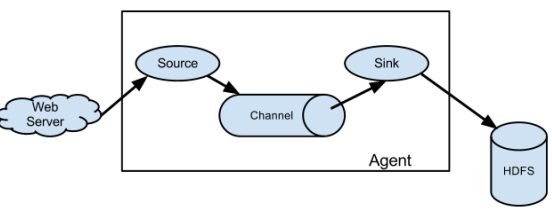
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。Agent 主要有 3个部分组成,Source、Channel、Sink。
-
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、taildir、sequence generator、syslog、http、legacy。在企业中使用最广泛的就是日志文件 ,企业中重点使用两个 Source: SpoolingDirSource 和 TailDirSource
- SpoolingDirSource:监控一个目录,读取目录中新增的文件,将文件的内容封装为event。
- TailDirSource:监控一个或者多个文件,读取多个文件最新追加写入的内容。不会丢数据(可靠的)即使 flume 出现了故障或挂掉。Taildir Source 在工作时,会将读取文件的最后的位置记录在一个 json 文件中,一旦 agent 重启,会从之前已经记录的位置,继续执行 tail 操作。Json 文件中位置是可以修改,修改后 Taildir Source 会从修改的位置进行 tail 操作。如果 JSON 文件丢失了,此时会重新从每个文件的第一行重新读取,这会造成数据的重复。TailDirSource 采集的文件,不能随意重命名。如果日志正在写入时,名称为 xxxx.tmp,写入完成后改名为 xxx.log,此时一旦匹配规则可以匹配上述名称,就会发生数据的重复采集。
-
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个 Sink 的读取操作。
Flume 自带三种 Channel:Memory Channel、File Channel 及 Kafka Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
Flume+Kafka 联合优势:
- 可靠性:Flume 可以将数据从不同 source 采集,并通过 Kafka Channel 传输到Kafka,确保数据不丢失。Kafka 本身也提供了副本机制来保证数据的可靠性。
- 弹性伸缩:由于 Flume 和 Kafka 都是分布式系统,它们可以根据需求进行横向扩展,以适应大规模数据传输和处理的需求。
- 高吞吐量:Kafka 的高吞吐量特性可以满足大量数据的传输需求,而 Flume 提供了丰富的 sources 和 sinks,使得数据流转更加灵活和高效。
-
Sink 不断地轮询 Channel 中的事件(Event,每一条记录都叫做一个事件)且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
除了上面说的 source->channel->sink 的流程,其实在 flume 中支持多种组合的流程,如下:
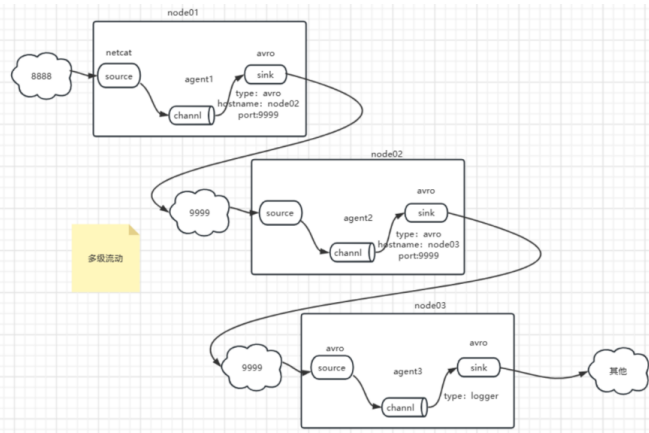
多级联动 :
多级流动是指数据通过多个 Flume 代理(Agent)传输的模式。每个 Agent 在数据传输过程中既可以作为上游代理(Upstream Agent),又可以作为下游代理(Downstream Agent)。上游 agent 将数据发送到下游 agent 的 Source,并通过 Channel 进行缓冲和存储,然后由下游 agent 的 Sink 将数据传输到目标系统。这种模式可以用于构建复杂的数据流水线,使数据在多个 agent 之间进行分发和处理。
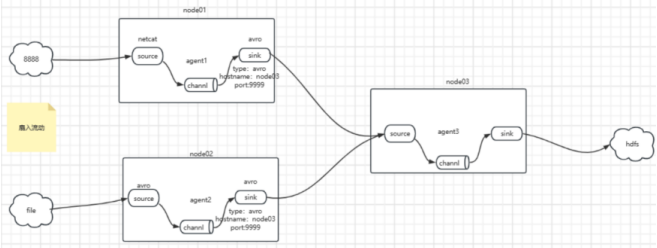
扇入流动 :
扇入流动是指多个上游数据源将数据发送到同一个下游 agent 的模式。不同的数据源可以是不同的 Flume agent,也可以是同一个 agent 的不同 Source。下游agent 的 Source 负责接收和收集来自多个数据源的数据,通过 Channel 进行缓冲和存储,然后将数据传输到目标系统的 Sink。扇入流动可以用于聚合来自不同数据源的数据,将其合并成一个数据流,然后进行进一步的处理或存储。
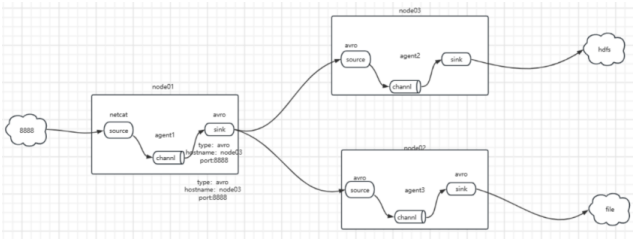
扇出流动 :
扇出流动是指一个上游数据源将数据发送到多个下游 agent 的模式。上游数据源可以是一个 Flume agent 的 Source,而下游 agent 可以是不同的 Flume agent或同一个 agent 的不同 Sink。上游数据源通过 Channel 将数据发送到多个下游代理的 Sink,从而实现数据的复制或分发。扇出流动可以用于将同一份数据发送到不同的目标系统,以实现数据备份、冗余或并行处理
模拟端口发送数据
编写 agent 文件(netcat-logger.conf)
# 定义这个 agent 中各组件的名字,前面的 a1 是 agent 的名字,该名字可以随便命名
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 9999
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = logger
# 描述和配置 channel 组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 组装
# source 和 channel 关联
a1.sources.r1.channels = c1
# sink 也要关联 channel
a1.sinks.k1.channel = c1启动 flume-ng 服务
flume-ng agent -n a1 -c conf -f netcat-logger.conf -Dflume.root.logger=INFO,console使用 telnet 工具模拟客户端发送数据,然后就可以在界面看到发送过来的数据

可以添加参数在页面上看到 flume 相关的 metrics
flume-ng agent -n a1 \
-c conf \
-f netcat-logger.conf \
-Dflume.monitoring.type=http \
-Dflume.monitoring.port=34345 \
-Dflume.root.logger=INFO,console监控文件的变化写到 HDFS 中
编写 agent 文件(tail-to-hdfs.conf)
# Name the components on this agent
taildir-hdfs-agent.sources = taildir-source
taildir-hdfs-agent.sinks = hdfs-sink
taildir-hdfs-agent.channels = memory-channel
# Describe/configure the source
taildir-hdfs-agent.sources.taildir-source.type = TAILDIR
taildir-hdfs-agent.sources.taildir-source.filegroups = f1
taildir-hdfs-agent.sources.taildir-source.filegroups.f1 =/opt/software/flume-data/.*
taildir-hdfs-agent.sources.taildir-source.positionFile =/opt/software/taildir/taildir_position.json
# Describe the sink
taildir-hdfs-agent.sinks.hdfs-sink.type = hdfs
taildir-hdfs-agent.sinks.hdfs-sink.hdfs.path = hdfs://localhost:8020/tmp/taildir/%Y%m%d%H%M
taildir-hdfs-agent.sinks.hdfs-sink.hdfs.useLocalTimeStamp = true
taildir-hdfs-agent.sinks.hdfs-sink.hdfs.fileType = CompressedStream
taildir-hdfs-agent.sinks.hdfs-sink.hdfs.writeFormat = Text
taildir-hdfs-agent.sinks.hdfs-sink.hdfs.codeC = gzip
taildir-hdfs-agent.sinks.hdfs-sink.hdfs.filePrefix = wsk
taildir-hdfs-agent.sinks.hdfs-sink.hdfs.rollInterval = 30
taildir-hdfs-agent.sinks.hdfs-sink.hdfs.rollSize = 1024
taildir-hdfs-agent.sinks.hdfs-sink.hdfs.rollCount = 0
# Use a channel which buffers events in memory
taildir-hdfs-agent.channels.memory-channel.type = memory
taildir-hdfs-agent.channels.memory-channel.capacity = 1000
taildir-hdfs-agent.channels.memory-channel.transactionCapacity = 100
# Bind the source and sink to the channel
taildir-hdfs-agent.sources.taildir-source.channels = memory-channel
taildir-hdfs-agent.sinks.hdfs-sink.channel = memory-channel启动 flime-ng 服务
flume-ng agent --conf conf --conf-file tair-to-hdfs.conf --name taildirhdfs-agent -Dflume.root.logger=INFO,console观察现像
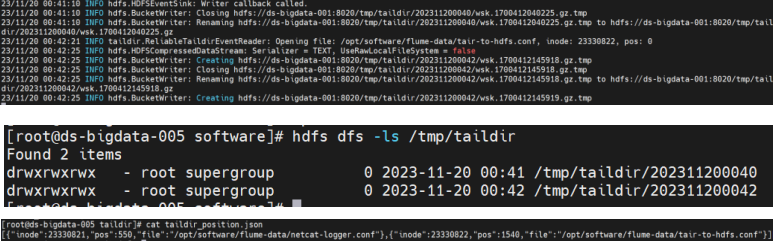
关于 KafkaChannel
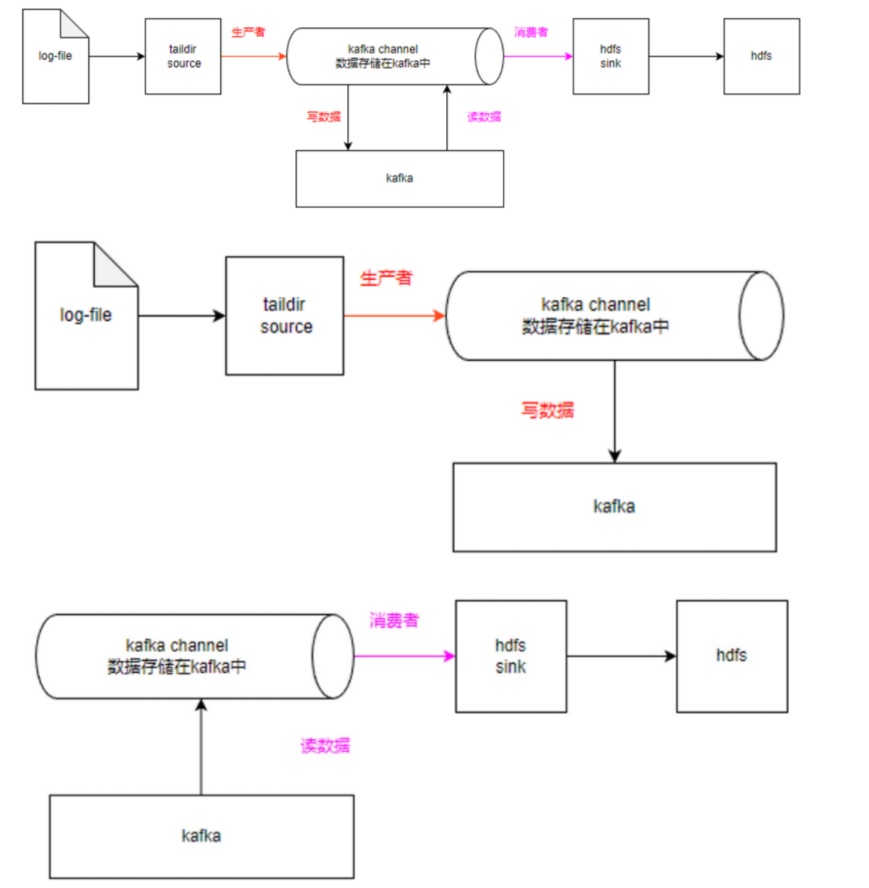
KafkaChannel 可以看作是 MemeoryChannel 和 FileChannel 的折中版本,既兼顾了 FileChannel 的持久化数据,又兼顾了 Memeory 的处理性能,但是又摒弃了二者的缺点,可以说 KafkaChannel 是目前企业中用的最多的 Channel。常见的拓扑结构有一下三种:
案例:监控一个文件的变化,然后通过 kafka 输入
#定义 agent 名, source、channel 的名称
a0.sources = r1
a0.channels = c1
#具体定义 source
a0.sources.r1.type = exec
a0.sources.r1.command = tail -F /opt/software/logs.txt
a0.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a0.channels.c1.brokerList = host2:9092,host3:9092,host4:9092
a0.channels.c1.zookeeperConnect=ds-bigdata-001:2181/kafka
a0.channels.c1.topic = test-zzz
#false 表示是以纯文本的形式写进入的,true 是以 event 的形式写进入的,以event 写进入时,会出现乱码, 默认是 true
a0.channels.c1.parseAsFlumeEvent = false
a0.sources.r1.channels = c1这样只要 logs.txt 文件发生任何变化,都是实时的输入到 kafka 的 topic 之中,可以通过以下命令查看。
kafka-console-consumer --bootstrap-server host1:9092,host2:9092,host3:9092 --topic test-zzz --frombeginning企业面试题
-
如何实现 Flume 数据传输的监控
使用第三方框架 Ganglia 实时监控 Flume。监控到 Flume 尝试提交的次数远远大于最终成功的次数,说明 Flume 运行比较差。主要是内存不够导致的。
-
Flume 参数调优
1)source:
batchSize:source 一次批量运输到 Channel 的 event 条数,适当调大这个参数可以提高 Source 搬运 Event 到 Channel 时的性能。
2)channel
type : 选择 memory 时 channel 的性能最好,但是如果 Flume 进程意外挂掉可能会丢失数据。选择 file 时 channel 的容错性更好,但是性能上会比 memorychannel 差。
capacity :channel 可容纳最大的 event 条数
transactionCapacity :每次 Source 往 channel 里面写的最大 event 条数和每次 Sink 从 channel 里面读的最大 event 条数3)sink
batchSize:Sink 一次批量从 Channel 读取的 event 条数。适当调大这个参数可以提高 Sink 从 Channel 搬出 event 的性能。
-
Flume 的事务机制
Flume 使用两个独立的事务分别负责从 Source 到 Channel,从 Channel 到Sink 的事件传递。如 spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到 Channel 且提交成功,那么 Soucrce 就将该文件标记为完成。
同理,事务以类似的方式处理从 Channel 到 Sink 的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到 Channel 中,等待重新传递。
-
Flume 采集数据会丢失吗?
生产环境中使用 TailDirSource + FileChannel 所有没有出现丢数据的情况。根据 Flume 的架构原理,Flume 本身是不可能丢失数据的,其内部有完善的事务机制,Source 到 Channel 是事务性的,Channel 到 Sink 是事务性的,因此这两个环节不会出现数据的丢失。
可能丢失数据的情况是 Channel 采用 memoryChannel,agent 宕机导致数据丢失,或者 Channel 存储数据已满,导致 Source 不再写入,未写入的数据丢失。
Flume 不会丢失数据,但是有可能造成数据的重复,例如数据已经成功由 Sink发出,但是没有接收到响应,Sink 会再次发送数据,此时可能会导致数据的重复。
Seatunnel
官方网址:https://seatunnel.apache.org/zh-CN/
SeaTunnel 是一个简单易用的数据集成框架,在企业中,由于开发时间或开发部门不通用,往往有多个异构的、运行在不同的软硬件平台上的信息系统同时运行。数据集成是把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享。SeaTunnel 支持海量数据的离线(BATCH)与实时(STREAMING)同步。它每天可以稳定高效地同步数百亿数据。并已用于近 100 家公司的生产。
SeaTunnel 可以选择自研的 SeaTunnel Zeta 引擎上运行,也可以选择在 Apache Flink 或 Spark 引擎上运行。Seaunnel 为实时(CDC)和批量数据提供高性能数据同步能力。本质上,SeaTunnel 不是对 Spark 和 Flink 的内部修改,而是在 Spark 和 Flink 的基础上做了一层包装。它主要运用了控制反转的设计模式,这也是 SeaTunnel 实现的基本思想。
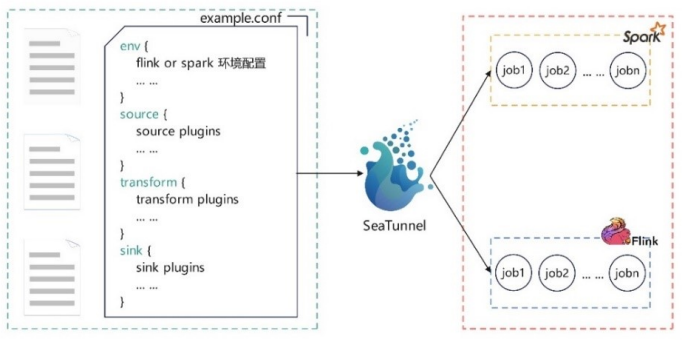
SeaTunnel 的日常使用,就是编辑配置文件。编辑好的配置文件由 SeaTunnel 转换为具体的 Spark 或 Flink 任务。如图所示。
特点及使用场景:
- 丰富且可扩展的连接器:SeaTunnel 提供了一个不依赖于特定执行引擎的连接器 API。
基于此 API 开发的连接器(源 Source、转换 Transform、接收器 Sink)可以在许多不同
的引擎上运行,例如当前支持的 SeaTunnel Zeta 引擎、Flink、Spark。 - 连接器插件:插件设计允许用户轻松开发自己的连接器并将其集成到 SeaTunnel 项目中。目前,SeaTunnel 已经支持 100 多个连接器,而且数量还在激增。
- 批流集成:基于 SeaTunnel 连接器 API 开发的连接器,完美兼容离线同步、实时同步、全同步、增量同步等场景。它大大降低了管理数据集成任务的难度。
- 多引擎支持:SeaTunnel 默认使用 SeaTunnel 引擎进行数据同步。同时,SeaTunnel 还支持使用 Flink 或 Spark 作为连接器的执行引擎,以适应企业现有的技术组件。SeaTunnel 支持多个版本的 Spark 和 Flink。
- JDBC 多路复用,数据库日志多表解析:SeaTunnel 支持多表或全数据库同步,解决了 JDBC 连接过多的问题;支持多表或全库日志读写解析,解决了 CDC 多表同步场景重复读取解析日志的问题。
- 高吞吐、低时延:SeaTunnel 支持并行读写,提供稳定可靠的数据同步能力,高吞吐、低时延。
- 完善的实时监控:SeaTunnel 支持数据同步过程中每个步骤的详细监控信息,让用户轻松了解同步任务读写的数据数量、数据大小、QPS 等信息。

目前 SeaTunnel 的长板是它有丰富的连接器,又因为它以 Spark 和 Flink 为引擎。所以可以很好地进行分布式的海量数据同步。通常 SeaTunnel 会被用来做出仓入仓工具,或者被用来进行数据集成。比如,唯品会就选择用 SeaTunnel 来解决数据孤岛问题,让ClickHouse 集成到了企业中先前的数据系统之中。
SeaTunnel 设计的核心是利用设计模式中的"控制翻转"或者叫"依赖注入",主要概括为以下两点:
- 上层不依赖底层,两者都依赖抽象;
- 流程代码与业务逻辑应该分离。整个数据处理过程,大致可以分为以下几个流程:输入(Source) -> 转换(Transform) -> 输出(Sink),对于更复杂的数据处理,实质上也是这几种行为的组合:
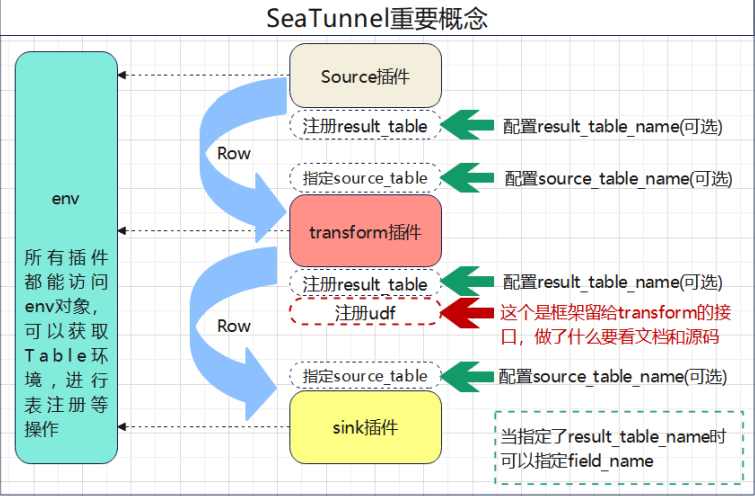
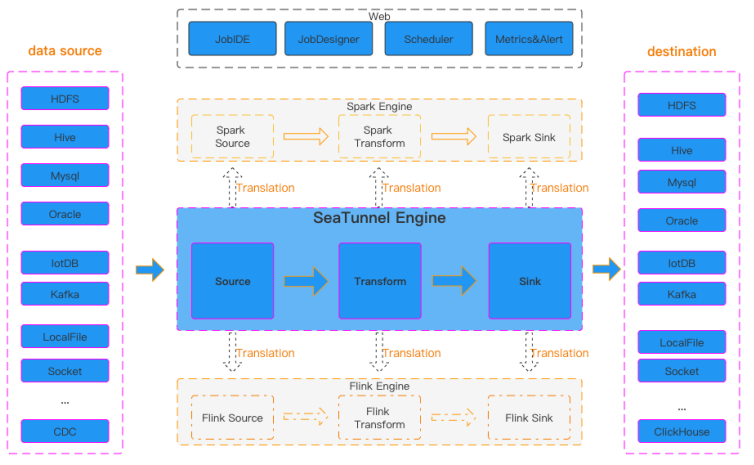
下图是 SeaTunnel 的工作流程:
入门项目
编写任务 demo.conf
env {
execution.parallelism = 1
job.mode = "BATCH"
}
source {
FakeSource {
result_table_name = "fake"
row.num = 16
schema = {
fields {
name = "string"
age = "int"
}
}
}
}
transform {
}
sink {
Console {}
}使用本地模式运行该程序并查看结果
/seatunnel.sh --config ../config/demo.conf -e local使用 spark 引擎运行该程序并查看结果
/start-seatunnel-spark-3-connector-v2.sh --master local[4] --deploymode client --config ../config/demo.conf使用 flink 引擎运行该程序并查看结果
./start-seatunnel-flink-15-connector-v2.sh -m yarn-cluster -ynm seatunnel-first --config ../config/demo.conf备注:如果指定 job.mode = "BATCH",flink 执行完之后就会立即结束,需要将job.mode = "STREAMING"之后,才可以是常驻任务。
transform Split
编写任务 split.conf
env {
execution.parallelism = 1
job.mode = "STREAMING"
}
source {
Socket {
host = "ds-bigdata-005"
port = 9990
result_table_name = "fake"
field_name = "info"
}
}
transform {
Split {
source_table_name = "fake"
result_table_name = "fake1"
separator = "#"
split_field = "info"
output_fields = [first_name, second_name]
}
}
sink {
Console {
source_table_name = "fake1"
}
}因为以上的任务是需要监控要给端口,因此可以使用 nc 先启动一个固定端口
nc -l 9990使用 flink 引擎运行该程序并查看结果
/start-seatunnel-flink-15-connector-v2.sh -m yarn-cluster -ynm seatunnel-first --config ../config/split.conf数据同步常见问题
数据源多、可选组件多的问题
一般我们说的数据同步的方法通常的步骤就是先创建目标表,再通过同步工具的填写数据库连接、表、字段等各种配置信息后测试完成数据同步。
但是这其中有很多的问题:
- 业务发展,数据量增大,传统方法完成工作的工作量增大,而且,相似并重复的操作降低开发人员的工作热情;
- 数据仓库的数据源种类特别丰富,遇到不同类型的数据同步,开发人员需要去了解其特色配置;
- 市面上可用的组件过多,如何甄别这些组件是否真正的满足需求
- 部分真正的数据需求方,如 Java 开发和业务运营,由于存在相关数据同步的专业技能部门,往往需要将需求提交给数据开发方来完成,额外增加了沟通和流程成本;
解决方案以阿里集团为例:数据仓库研发了OneClick 产品;
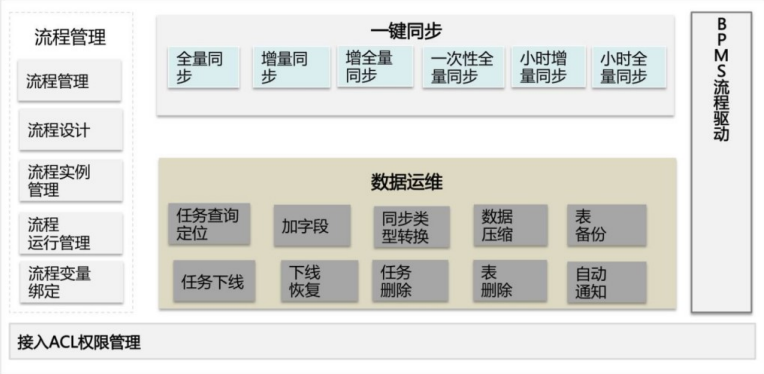
在 OneData 体系里,让数据研发更高效的工具有 OneClick。OneClick 顾名思义,就是通过一键点击的方式,来提高数据研发的效率。目前 OneClick 主要覆盖的场景有两个:一是数据同步,另一个是存量数据日常维护。OneClick 的思路实际上就是将数据研发一些日常的操作,通过一个可复用的流程,一键点击、一键完成。在上述两块数据处理的场景中,所有的功能都是基于某一事先配置好任务流去实现,每个任务流都是不同的API 接口按照一定顺序的排列组合。
通常我们可以这么做:
- 对不同数据源的数据同步配置透明化,可以通过库名和表名唯一定位,通过 IDB(Interface DataBase) 接口获取源数据信息自动生成配合信息;
- 简化了数据同步操作步骤,实现了与数据同步相关的建表、配置任务、发布、测试操作一键化处理,并且封装成 Web 接口进一步达到批量化的效果;
- 降低了数据同步的技能门槛,让数据需求方更加方便地获取和使用数据。
因此 OneClick 实现了数据的一键化和批量化同步,一键完成 DDL 和 DML 的生成、数据的冒烟测试(冒烟测试就是完成一个新版本的开发后,对该版本最基本的功能进行测试,保证基本的功能和流程能走通)以及在生成环境中测试等。
备注:IDB:阿里集团用于统一管理 MySQL、OceanBase、PostgreSQL、Oracle、SQL Server 等关系型数据库的平台,是一种集数据管理、结构管理、诊断优化、实时监控和系统管理与一体的数据管理服务。(在对集团数据库表统一管服务过程中,IDB 产出了数据库、表、字段各个级别元数据信息,并提供了元数据接口服务)
零点漂移的问题
数据零点漂移指的是数据同步过程中,ODS 表按时间字段分区时,同一个业务日期(分区)包含前一天的数据或丢失了当天的数据、或者包含后一天凌晨附近的数据,一般是对增量表的情况而言。
由于 ODS 需要承接面向历史的细节数据查询需求,这就需要物理落地到数据仓库的ODS 表按时间段来切分进行分区存储,通常的做法是按某些时间戳字段来分区,而实际上往往由于时间戳字段的准确性问题导致发生数据漂移。
原因分析
当数仓 ODS 采用按时间段分区的方式存储数据,时间字段的选择会导致不同类型的
数据漂移现象。通常,时间戳字段分为四类:
- 数据库表 中用来标识数据记录更新时间的时间戳字段(modified_time)
- 数据库日志 中用来标识数据记录更新时间的时间戳字段·(log_time)
- 数据库表中用来记录具体业务过程发生时间的时间戳字段(proc_time)
- 标识数据记录被抽取到时间的时间戳字段(extract_time)
理论上,上述四个时间戳应该是一致的,即 proc_time = log_time =modified_time = extract_time,但实际生产中,这几个时间往往会出现差异。
在现实中,四个时间戳的大小关系为:
poc_time<log_time<modified_time<extract_time
造成这些差异的原因有:
- 数据产生后才能抽数,并且很难做到数据实时产生实时抽取,所以extract_time 一般会晚于其他三个时间。
- 关系型数据库采用预写日志方式(WAL,Write Ahead Log)来更新数据,所以更新时间 modified_time 会晚于 log_time。
- 网络或系统压力问题,会导致数据延迟写入数据延迟更新。log_time 或者 modified_time 会晚于 proc_time。
根据其中的某一个时间字段来切分 ODS 表,这就导致产生数据漂移。下面来具体看下数据漂移的几种场景:
- extract_time 抽取时间分区,这种情况数据漂移的问题最明显。
- modified_time 更新时间分区。在实际生产中这种情况最常见,但是往往会发生不更新 modified_time 而导致的数据遗漏,或者凌晨时间产生的数据记录漂移到后一天。
- log_time 分区。由于网络或者系统压力问题,log_time 会晚于 proc_time,从而导致凌晨时间产生的数据记录漂移到后一天。例如,在淘宝"双 11"大促期间凌晨时间产生的数据量非常大,用户支付需要调用多个接口,从而导致 log_time 晚于实际的支付时
间。根据 proc_time 业务过程分区。仅仅根据 proc_time 限制,所获取的 ODS 表只是包含一个业务过程所产生的记录,会遗漏很多其他过程的变化记录。
解决方案
-
多获取后一天的数据:既然很难解决数据漂移的问题,那么就在 ODS 每个时间分区中向后多冗余一些数据,在 ods 每个时间分区中向后多冗余一天数据,保障数据只会多,不会少,而具体的数据区分则可以让下游根据自身不同的业务场景用不同的业务时间
proc_time 来限制。但这种方式会有一些数据误差,因为后一天的数据可能已经更新多次,直接获取到的那条记录已经是更新多次后的状态了,此时可以创建拉链表,用时间来约束获取记录的状态。
-
多个时间戳字段限制时间:通过多个时间戳字段限制时间,来获取相对准确的数据,常见的操作步骤如下:
i、首先根据 log_time 分别冗余前一天最后 15 分钟的数据和后一天凌晨开始 15 分钟的数据,并用 modified_time 过滤非当天数据,确保数据不会因为系统问题而遗漏。
ii、然后根据 log_time 获取后一天 15 分钟的数据,针对此数据,按照主键根据log_time 做升序排列去重。因为我们需要获取的是最接近当天记录变化的数据(数据库日志将保留所有变化的数据,但是落地到 ODS 表的是根据主键去重获取最后状态变化的数
据)。
iii、最后将前两步的结果数据做全外连接,通过限制业务时间 proc_time 来获取我们所需要的数据。
下面来看处理淘宝交易订单的数据漂移的实际案例。在处理交易订单时发现,有大批在 11 月 11 日 23:59:59 左右支付的交易订单漂移到了 11 月 12 日 。主要原因是用户下单支付后系统需要调用支付宝的接口而有所延迟,从而导致这些订单最终生成的时间跨天了。即 modified_time 和 log_time 都晚于 proc_time。如果订单只有一个支付业务过程,则可以用支付时间来限制就能获取到正确的数据。但是往往实际订单有多个业务过程:下单、支付、成功,每个业务过程都有相应的时间戳字段,并不只有支付数据会漂移。因此,可以根据实际情况获取后 15 分钟的数据,并限制各个业务过程的时间戳字段(下单、支付、成功)都是"双 11 "当天的,然后对这些数据按照订单的 modified time 升序排列,获取每个订单首次数据变更的那条记录。此外,还可以根据 log_time 分别冗余前一天最后 15 分钟的数据和当天凌晨开始 15 分钟的数据,并用 modified time 过滤非当天数据,针对每个订单按照 log time 进行降序排列 ,取每个订单当天最后一次数据变更的那条记录。最后将两份数据根据订单做全外连接,将漂移数据回补到当天数据中。
总而言之,在生产中数据漂移问题是存在的,只能通过一些规则限制获取相对准确的数据。比如约定通过修改时间来分区、这个字段如果存在不更新的情况就需要业务系统治理。
数据倾斜
Hadoop 能够进行对海量数据进行批处理的核心,在于它的分布式思想,通过多台服务器(节点)组成集群,共同完成任务,进行分布式的数据处理。
理想状态下,一个任务是由集群下所有机器共同承担执行任务,每个节点承担的任务应该相近,但实际上在并行处理过程中,分配到每台节点的数据量并不是均匀的,当大量的数据分配到某一个节点时(假设 10 个节点,5 亿数据),那么原本只需要 1 小时完成的工作,变成了其中 9 个节点不到 1 小时就完成了工作,而分配到了大量数据的节点,花了5 个小时才完成。
从最终结果来看,就是这个处理 10 亿数据的任务,集群花了 5 个小时才最终得出结果。大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均计算速度,导致整个计算过程过慢,这种情况就是发生了数据倾斜。
原因分析
- key 分布不均匀,某些 key 的数量过于集中,存在大量相同值的数据例如存在大量异常值或空值。
- 业务数据本身的特性,例如某个分公司或某个城市订单量大幅提升几十倍甚至几百倍,对该城市的订单统计聚合时,容易发生数据倾斜。
- 建表时考虑不周。
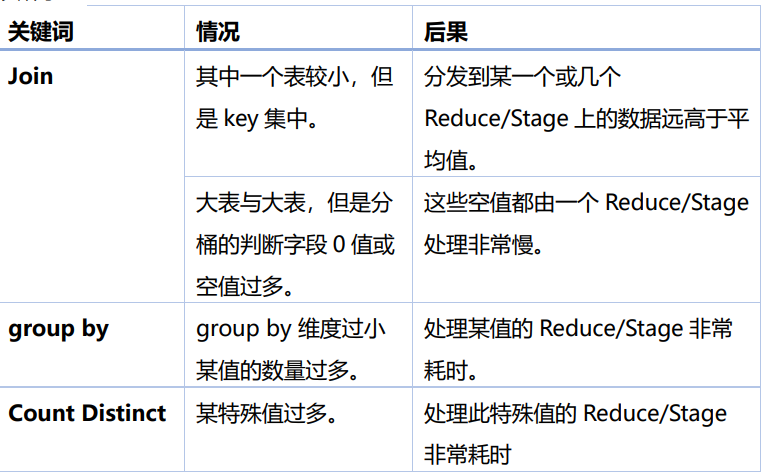
- 某些 SQL 语句本身就有数据倾斜,两个表中关联字段存在大量空值,或是关联字段的数据不统一,例如在 A 表中值是大写,B 表中值是小写等情况。发生数据倾斜的 SQL操作如下表所示:
数据倾斜现象
MapReduce 任务:主要表现在 ruduce 阶段卡在 99.99%,一直 99.99%不能结束。有一个多几个 reduce 卡住,各种 container 报错 OOM,读写的数据量极大,至少远远超过其它正常的 reduce 伴随着数据倾斜,会出现任务被 kill 等各种诡异的表现。
Spark 任务:绝大多数 task 执行得都非常快,但个别 task 执行的极慢。单个Executor 执行时间特别久,整体任务卡在某个 stage 不能结束。Executor lost,OOM,Shuffle 过程出错,正常运行的任务突然失败。一直会有 executor 出现 OOM 的错误,但是其余的 executor 内存使用率却很低。
数据倾斜的危害
- 任务长时间挂起,资源利用率下降
在分阶段执行任务的场景下,阶段与阶段之间通常存在数据上的依赖关系,后一阶段任务需要等前一阶段执行完成才能开始,举个例子 Stage1 在 Stage0 之后执行,假如Stage1 依赖 Stage0 产生的数据结果,那么 Stage1 必须等待 Stage0 执行完成后才能开
始,如果这时 Stage0 因为数据倾斜问题,导致任务执行时长过长,或者直接挂起,那么Stage1 将一直处于等待状态,整个作业也就一直挂起。这个时候,资源被这个作业占据,但是却只有极少数 task 在执行,造成计算资源的严重浪费,利用率下降 - 引发内存溢出,导致任务失败
数据发生倾斜时,可能导致大量数据集中在少数几个节点上,在计算执行中由于要处理的数据超出了单个节点的能力范围,最终导致内存被撑爆,报 OOM 异常,直接导致任务失败。 - 作业执行时间超出预期,导致后续依赖数据结果的作业出错
有时候作业与作业之间,并没有构建强依赖关系,而是通过执行时间的前后时间差来调度,当前置作业未在预期时间范围内完成执行,那么当后续作业启动时便无法读取到其所需要的最新数据,从而导致连续出错
处理方案
参数优化
见另一篇博客《Hive调优》
SQL优化
1、count(distinct)优化,慎用 distinct,先用 group 去重,再 count 子查询。
SELECT
app_id,
COUNT(DISTINCT user_id)
FROM tb
GROUP BY app_id;优化后:
SELECT
app_id,
SUM(uv) AS uv
FROM (
SELECT
app_id,
user_id,
1 AS uv
FROM tb
GROUP BY app_id, user_id
) a
GROUP BY app_id;2、聚合类操作,发生数据倾斜,解决方法:阶段拆分-两阶段聚合
select
app_id,
count(user_id)
from tb
group by app_id;优化后
select
substring_index(tmp_app_id,"_",1) app_id,
sum(pv) as pv
from (
select
concat(app_id, "_", round(rand()*10)) tmp_app_id,
count(user_id) as pv
from tb
group by concat(app_id,"_",round(rand()*10))
) a
group by substring_index(tmp_app_id,"_",1);3、大表 join 大表发生数据倾斜,大表拆分,倾斜部分单独处理,中间表分桶排序后join。
举例:假设有有两张表 table_a 表是一张近 3 个月买家交易明细表,字段如下,数据量较大。

table_b 表是一张所有卖家信息表,数据量也很大,不满足 mapjoin 的条件。

SELECT
t1.buyer_id
,sum(case when t2.seller_level = 'A' then order_num end) as a_num
,sum(case when t2.seller_level = 'B' then order_num end) as b_num
,sum(case when t2.seller_level = 'C' then order_num end) as c_num
FROM table_a t1 --买家交易明细表
INNER JOIN table_b t2 --卖家信息表
ON t1.seller_id = t2.seller_id
GROUP BY t1.buyer_id;但因为二八法则,某些卖家会拥有成千上万的买家,而大部分卖家的买家数量是较少的,两个表关联会发生数据倾斜。
优化方案 1(降数量级):转为 map join 避免 shuffle,table_b 由于数据量较大,无法直接 map join ,所以考虑通过过滤 3 个月内没有发生交易的卖家,来减少 table_b 的数据量,使其达到满足 map join 的情况。
SELECT
t1.buyer_id,
SUM(CASE WHEN t4.seller_level = 'A' THEN order_num END) AS a_num,
SUM(CASE WHEN t4.seller_level = 'B' THEN order_num END) AS b_num,
SUM(CASE WHEN t4.seller_level = 'C' THEN order_num END) AS c_num
FROM table_a t1
INNER JOIN (
SELECT
t2.seller_id,
t2.seller_level
FROM table_b t2
INNER JOIN (
SELECT
seller_id
FROM table_a
GROUP BY seller_id
) t3
ON t2.seller_id = t3.seller_id
) t4 -- 过滤掉 table_b 中没有出现在 table_a 中的 seller_id
ON t1.seller_id = t4.seller_id
GROUP BY t1.buyer_id;此方案在有些时候能够起作用,但大部分情况并不能解决问题,比如 table_b 经过过滤后,数量依然很大,还是不满足 map join 的条件。
优化方案 2(拆表):拆表一分为二,倾斜部分单独处理,首先创建一个临时表temp_b,存放大卖家(买家超过 1 万个)的名单,然后 table_a 分别 join temp_b 和table_b,结果 union all 起来即可。此方案的适用情况最多,且最有效。
-- 临时表存放 90 天内买家超过 10000 的大卖家
INSERT OVERWRITE TABLE temp_b
SELECT
t1.seller_id,
t2.seller_level
FROM (
SELECT
seller_id
FROM table_a
GROUP BY seller_id
) t1
LEFT JOIN (
SELECT
seller_id,
seller_level
FROM table_b
) t2
ON t1.seller_id = t2.seller_id
AND count(buyer_id) > 10000;
-- 获取最终结果
SELECT
t7.buyer_id,
SUM(CASE WHEN t7.seller_level = 'A' THEN t7.order_num END) AS a_num,
SUM(CASE WHEN t7.seller_level = 'B' THEN t7.order_num END) AS b_num,
SUM(CASE WHEN t7.seller_level = 'C' THEN t7.order_num END) AS c_num
FROM (
SELECT
/*+mapjoin(t2)*/
t1.buyer_id,
t1.seller_id,
t1.order_num,
t2.seller_level
FROM table_a t1
LEFT JOIN temp_b t2
ON t1.seller_id = t2.seller_id
UNION ALL -- 针对大卖家 map join 其他卖家正常 join
SELECT
t3.buyer_id,
t3.seller_id,
t3.order_num,
t6.seller_level
FROM table_a t3
LEFT JOIN (
SELECT
seller_id,
seller_level
FROM table_b t4
LEFT JOIN temp_b t5
ON t4.seller_id = t5.seller_id
WHERE t5.seller_id IS NULL
) t6
ON t3.seller_id = t6.seller_id
) t7
GROUP BY t7.buyer_id;4、空值处理
例如埋点日志经常丢失 user_id,存在大量空值。所以空值到一个 reduce 中发生倾斜。
解决方法:空值赋新的 key 值。
select *
from logs a
left join users b
on
case
when a.user_id is null then concat('hive',rand() )
else a.user_id
end
= b.user_id;