在深度学习领域,PyTorch 凭借其灵活的动态计算图和简洁的 API 设计,成为了科研人员和工程师的首选框架之一。无论是构建简单的全连接网络,还是复现复杂的深度学习模型,掌握 PyTorch 的核心工具和建模方法都至关重要。本文将从神经网络的核心组件出发,详细讲解 PyTorch 中构建模型的多种方式,并通过实战案例带你实现经典的 ResNet18 网络,帮助你快速上手 PyTorch 建模与训练。
一、神经网络核心组件:理解深度学习的 "积木"
要构建一个神经网络,首先需要明确其核心组成部分。就像搭积木需要不同形状的模块一样,神经网络的功能实现也依赖于以下 4 个关键组件:
|-------|-----------------------------|
| 层 | 神经网络的基本结构,将输入张量转换为输出张量。 |
| 模型 | 层构成的网络。 |
| 损失函数 | 参数学习的目标函数,通过最小化损失函数来学习各种参数。 |
| 优化器 | 如何使损失函数最小,这就涉及到优化器。 |
这 4 个组件的协作流程可概括为:输入数据经过模型的层变换得到预测值 → 损失函数计算预测值与真实值的误差 → 优化器根据误差更新模型参数,形成一个完整的训练闭环。
二、PyTorch 构建网络的两大核心工具:nn.Module vs nn.functional
PyTorch 提供了两种主要工具来构建神经网络:nn.Module和nn.functional。二者功能有重叠,但使用场景和特性差异显著,掌握其区别是高效建模的关键。
nn.Module
继承自Module类,可自动提取可学习的参数。
适用于卷积层、全连接层、dropout层。
nn.functional
更像是纯函数。
适用于激活函数、池化层。
本质上 :nn.Module是面向对象的类,需要实例化后使用;nn.functional是纯函数集合,可直接调用。
参数管理 :nn.Module会自动处理参数的创建、存储和更新,无需手动干预;nn.functional则需要手动定义和传递参数,不提供参数管理功能。
容器兼容性 :nn.Module可自然融入nn.Sequential等容器,便于构建复杂网络结构;nn.functional无法直接用于这些容器,代码复用性相对较弱。
状态切换 :nn.Module(如 Dropout、BatchNorm)调用model.eval()后自动切换训练 / 测试状态;nn.functional需要手动传入状态参数(如training=True)来控制行为。
适用场景 :nn.Module适合实现带可学习参数的层(如卷积层、全连接层);nn.functional更适合无参数的操作(如激活函数、池化)或需要手动控制参数的场景。
三、PyTorch 构建模型的 3 种常用方式
PyTorch 支持多种模型构建方式,可根据项目复杂度和灵活性需求选择。以下将以 "MNIST 手写数字分类" 任务为例(输入 28×28 像素图像,输出 10 个类别概率),详细讲解每种方式的实现步骤。
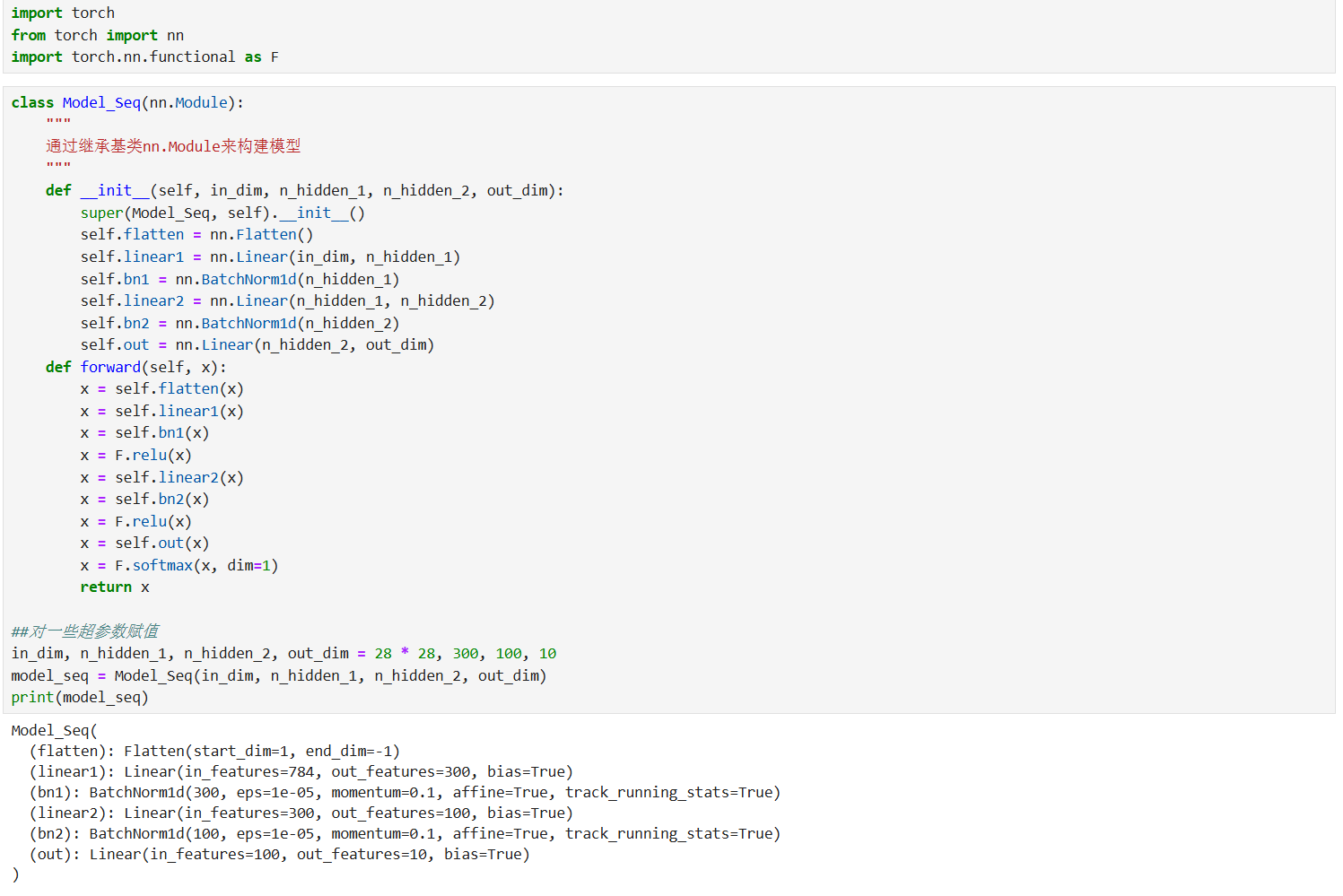
方式 1:继承 nn.Module 基类构建(最灵活)
这种方式通过自定义类继承nn.Module,在__init__方法中定义网络层,在forward方法中实现前向传播逻辑,适合构建复杂、自定义流程的模型。
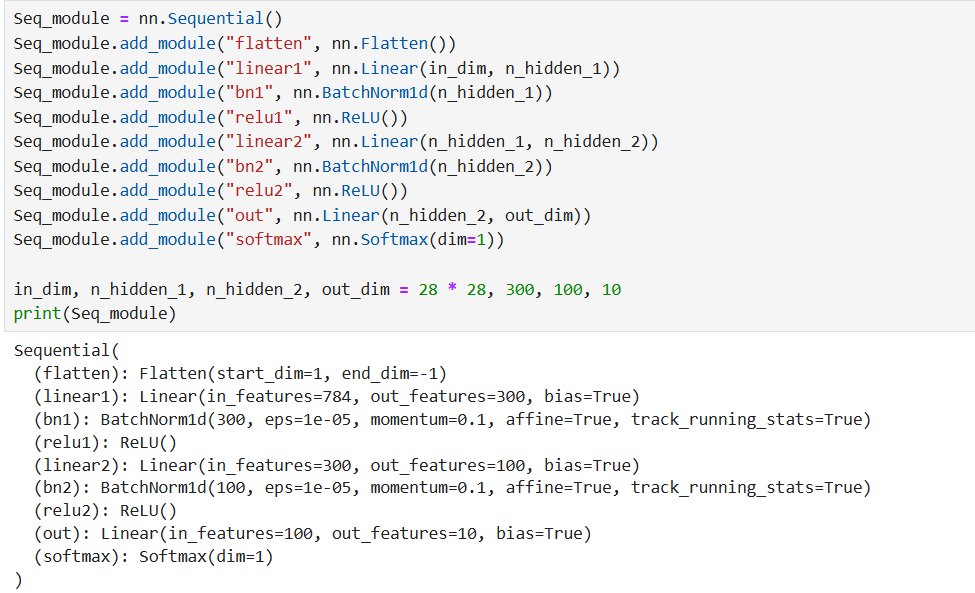
方式 2:使用 nn.Sequential 按层顺序构建(最简洁)
nn.Sequential是 PyTorch 提供的 "层容器",可按顺序封装多个层,自动实现前向传播(无需手动写forward方法),适合构建结构简单、层顺序明确的模型。其使用有 3 种常见形式:
1. 可变参数方式(快速构建,无层名称)

2. add_module 方法(自定义层名称)
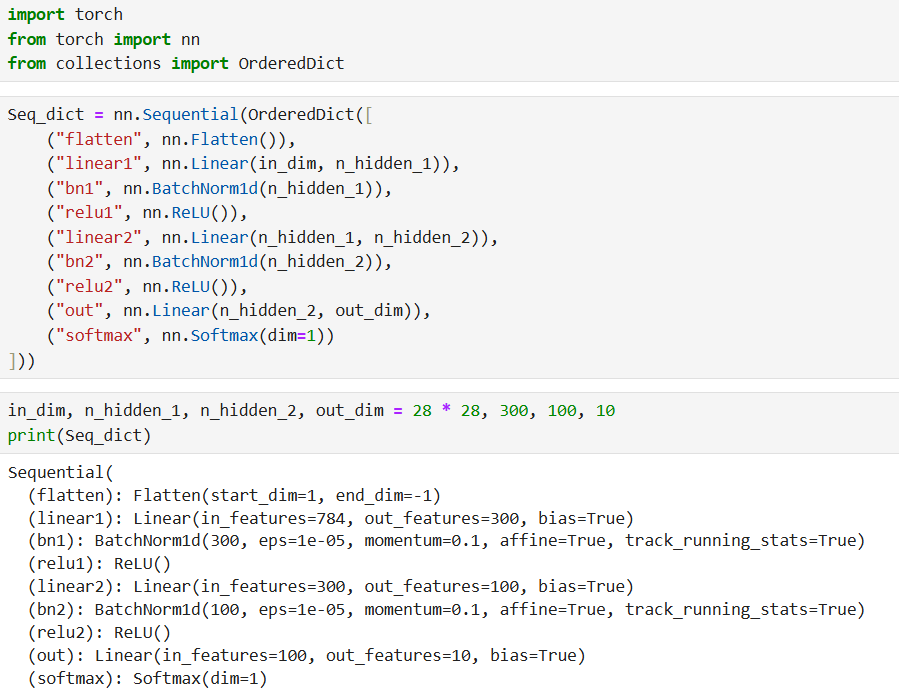
3. OrderedDict 方式(有序字典,自定义层名称)
方式 3:继承 nn.Module + 模型容器(灵活与简洁兼顾)
当模型结构较复杂(如多分支、多子模块)时,可结合nn.Module的自定义能力和nn.Sequential/nn.ModuleList/nn.ModuleDict的容器特性,将模型拆分为多个子模块,提升代码可读性和复用性。
1. 结合 nn.Sequential(子模块按顺序封装)

2. 结合 nn.ModuleList(列表式管理子模块)
nn.ModuleList类似 Python 的列表,可存储多个层对象,支持索引访问,适合需要动态调整层数量的场景:

3. 结合 nn.ModuleDict(字典式管理子模块)
nn.ModuleDict类似 Python 的字典,通过 "键值对" 存储层对象,适合需要按名称动态调用层的场景: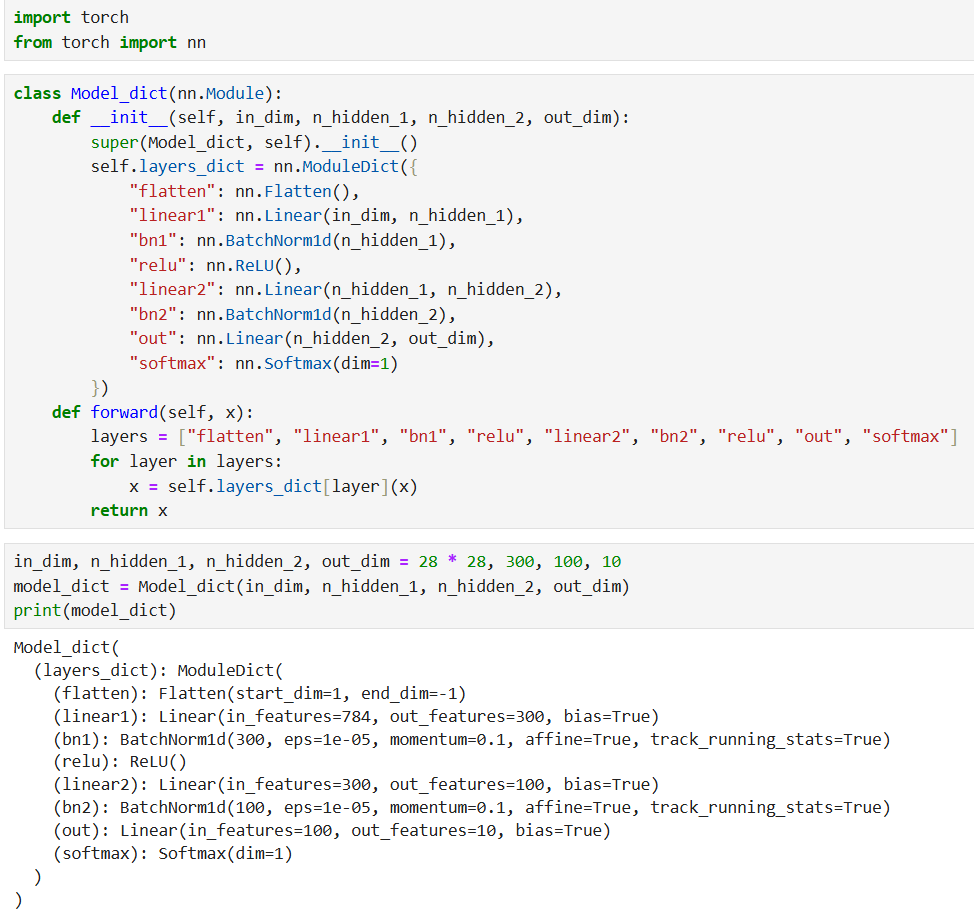
四、自定义 ResNet18 网络
ResNet(残差网络)通过引入 "残差连接" 解决了深层网络的梯度消失问题,是计算机视觉领域的经典模型。下面将基于 PyTorch 实现 ResNet18 的核心模块(残差块),并组合成完整网络。
1. 定义残差块(Residual Block)
ResNet18 包含两种残差块:
BasicBlock:正常残差块,输入与输出通道数相同,直接相加。
DownBlock:下采样残差块,通过 1×1 卷积调整输入通道数和分辨率,确保与输出形状一致。
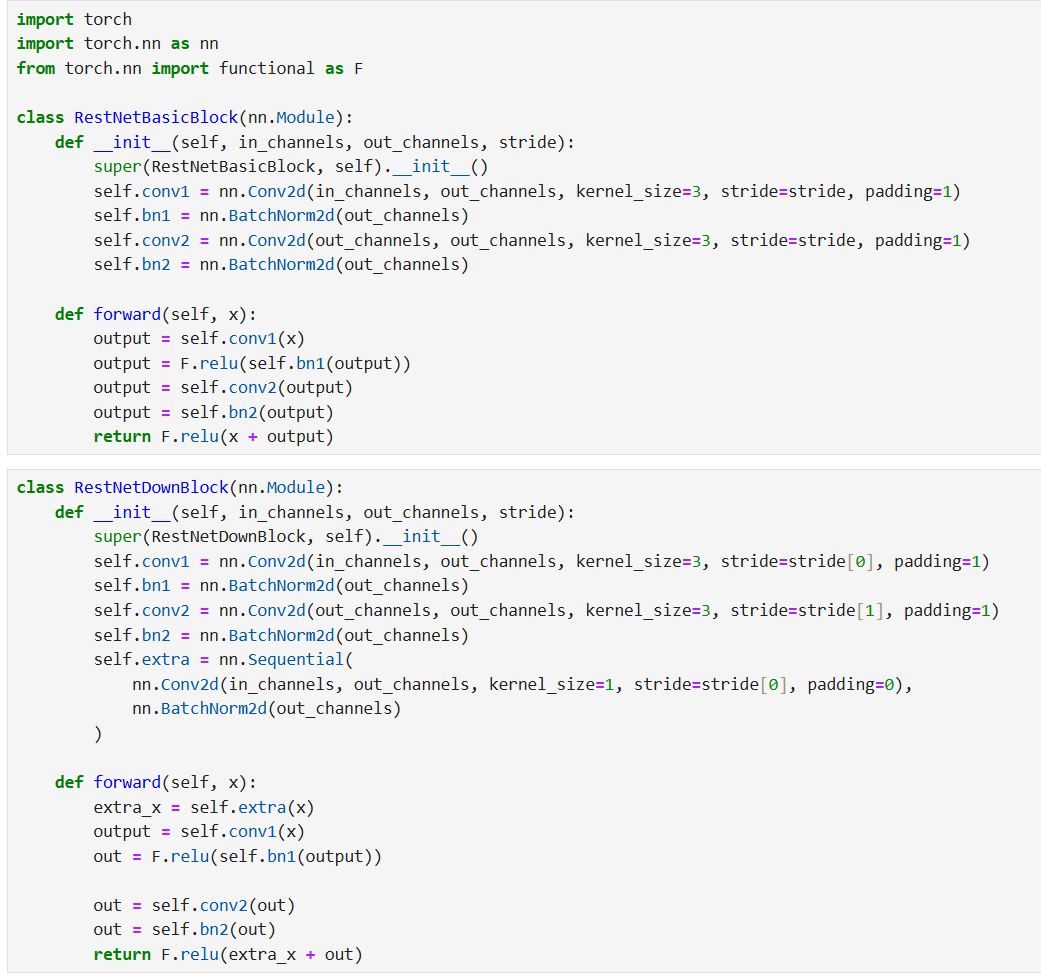
2. 组合残差块构建 ResNet18
ResNet18 的结构为:卷积层→BatchNorm→最大池化→4 个残差层→自适应平均池化→全连接层,其中每个残差层由 2 个残差块组成。

五、模型训练的完整流程
构建好模型后,还需要通过训练让模型学习数据规律。PyTorch 模型训练的核心流程可概括为以下 6 步:
1.加载预处理数据集
2.定义损失函数
3.定义优化方法
4.循环训练模型
5.循环测试或验证模型
6.可视化结果
六、总结
本文从神经网络的核心组件出发,详细讲解了 PyTorch 构建模型的 3 种方式(继承nn.Module、nn.Sequential、nn.Module+ 容器),并通过实战实现了经典的 ResNet18 网络,最后梳理了模型训练的完整流程。掌握这些内容后,你可以:
- 根据任务复杂度选择合适的建模方式;
- 自定义复杂网络(如 ResNet、Transformer);
- 独立完成从数据加载到模型训练、评估的全流程。
PyTorch 的灵活性在于其模块化设计,后续可进一步探索迁移学习、模型保存与加载、分布式训练等进阶内容,不断提升深度学习工程能力。