目录
- 1、交叉熵损失 (Cross-Entropy Loss)
- 2、平滑L1损失 (Smooth L1 Loss)
- [3、Focal Loss](#3、Focal Loss)
- [4、IoU Loss (Intersection over Union Loss)](#4、IoU Loss (Intersection over Union Loss))
- [5、Generalized IoU Loss (GIoU)](#5、Generalized IoU Loss (GIoU))
- [6、DIoU Loss (Distance-IoU)](#6、DIoU Loss (Distance-IoU))
- [7、CIoU Loss](#7、CIoU Loss)
- [8、Distribution Focal Loss, DFL](#8、Distribution Focal Loss, DFL)
1、交叉熵损失 (Cross-Entropy Loss)
-
应用场景:用于分类任务,评估预测的类别分布与真实标签之间的差异。
-
在目标检测中,物体分类是一个重要的任务,交叉熵损失是广泛使用的分类损失函数。它通过计算预测概率分布与真实标签之间的差异来优化模型。
-
问题与方法
类别不平衡:在检测场景中,背景样本远多于前景,易导致模型偏向背景。
加权交叉熵:对不同类别分配权重 α c \alpha_{c} αc使得小众类别(或正样本)损失放大,常见于 SSD、RetinaNet 前期。
-
计算方式:对于每个锚点/位置的类别预测,令模型对类别 c c c的预测概率为 p c p_{c} pc,真实标签为one-hot向量,则
L C E = − ∑ c y c l o g ( p c ) L_{CE}=-\sum_{c}y_{c}log(p_{c}) LCE=−c∑yclog(pc)
python
import torch
import torch.nn as nn
criterion = nn.CrossEntropyLoss()
output = model(input) # 模型的输出
loss = criterion(output, target) # target为真实标签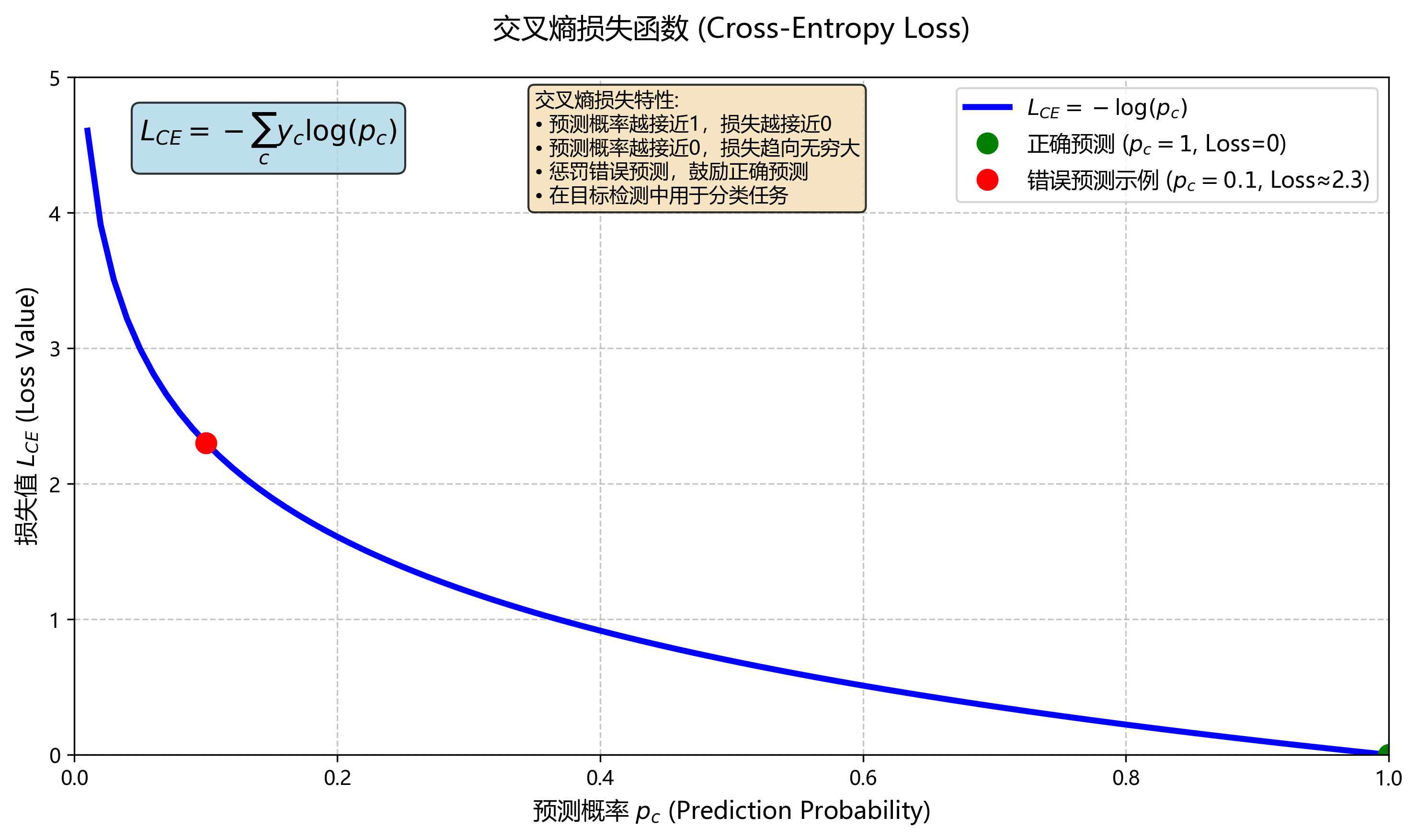
2、平滑L1损失 (Smooth L1 Loss)
-
应用场景:在目标检测中用于边界框回归,结合了L1和L2损失的特点,具有更好的鲁棒性。
-
Ren et al., "Faster R-CNN: Towards Real‑Time Object Detection with Region Proposal Networks" (2015)
-
问题与方法
在目标检测中,边界框回归需要优化边框的位置。传统的L1和L2损失在误差较大时会表现不佳,导致模型不稳定。传统 L2 对异常误差过于敏感,L1 在小误差时不够平滑。
-
Smooth L1 在小误差时接近 L2,保证收敛平稳;在大误差时退化为 L1,抑制异常点影响。
-
计算方式:Smooth L1损失结合了L1和L2的优点,使用了一个平滑的切换机制,在误差小于某个阈值时使用L2损失,大于该阈值时使用L1损失。这种方式可以减小对异常值的敏感性,同时保持收敛速度。 对边界框回归误差,定义 Δ = x p r e d − x g t Δ=x_{pred}-x_{gt} Δ=xpred−xgt,其中 x p r e d x_{pred} xpred为预测的边界框, x g t x_{gt} xgt为ground truth的边界框。
L S m o o t h L 1 ( Δ ) = 0.5 Δ 2 / β , ∣ Δ ∣ < 0.5 β , ∣ Δ ∣ − 0.5 β , o t h e r w i s e , L_{SmoothL1}(Δ)={0.5Δ^{2}/\beta, ∣Δ∣<0.5\beta,\\ ∣Δ∣-0.5\beta,otherwise}, LSmoothL1(Δ)=0.5Δ2/β,∣Δ∣<0.5β,∣Δ∣−0.5β,otherwise,常取 β = 1 \beta=1 β=1
python
import torch
import torch.nn as nn
smooth_l1_loss = nn.SmoothL1Loss()
loss = smooth_l1_loss(predicted_boxes, target_boxes)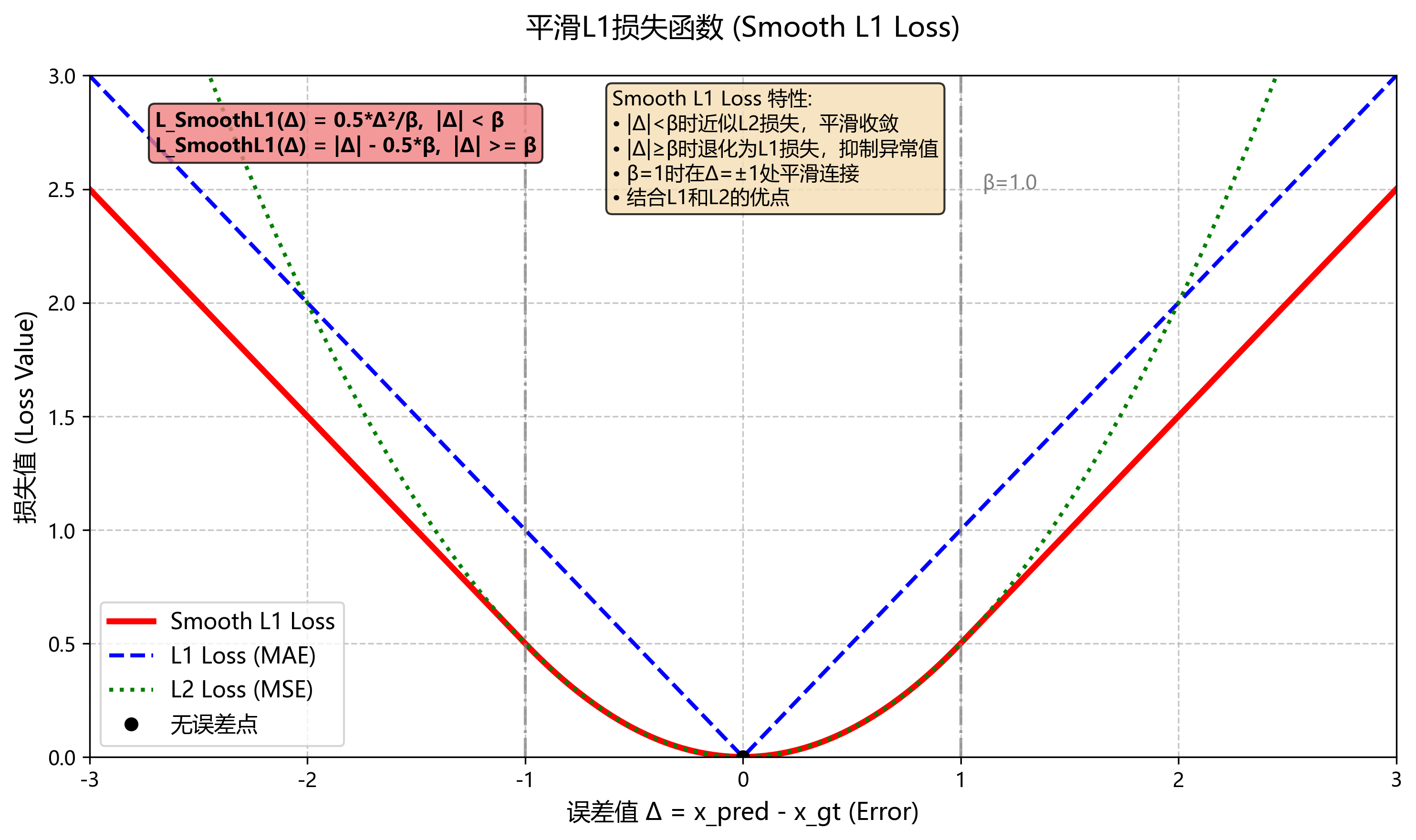
3、Focal Loss
-
Lin et al., "Focal Loss for Dense Object Detection" (RetinaNet, 2017)
-
问题与方法
在处理高度不平衡的数据集时,简单的交叉熵损失可能会导致模型对易分类样本的过拟合,而忽视难分类样本。
-
Focal Loss通过引入一个调制因子 ( 1 − p t ) γ (1 - p_{t})^{\gamma} (1−pt)γ,将难以分类的样本的损失放大,对难分类样本( p t p_{t} pt小)重点学习,易分类样本损失自动衰减,从而使得模型更加关注那些难以分类的样本。
-
计算方式:公式如下:
F L ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) FL(p_{t})=-\alpha_{t}(1 - p_{t})^{\gamma}log(p_{t}) FL(pt)=−αt(1−pt)γlog(pt)其中, p t p_{t} pt是预测的类别概率, α t \alpha_{t} αt是平衡因子,平衡正负样本比, γ \gamma γ是调制因子(常设置为2)。
python
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, reduction='mean'):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
def forward(self, inputs, targets):
BCE_loss = nn.CrossEntropyLoss(reduction='none')(inputs, targets)
pt = torch.exp(-BCE_loss) # 预测概率
F_loss = self.alpha * (1 - pt) ** self.gamma * BCE_loss
if self.reduction == 'mean':
return F_loss.mean()
elif self.reduction == 'sum':
return F_loss.sum()
return F_loss
criterion = FocalLoss()
loss = criterion(predicted_logits, target)
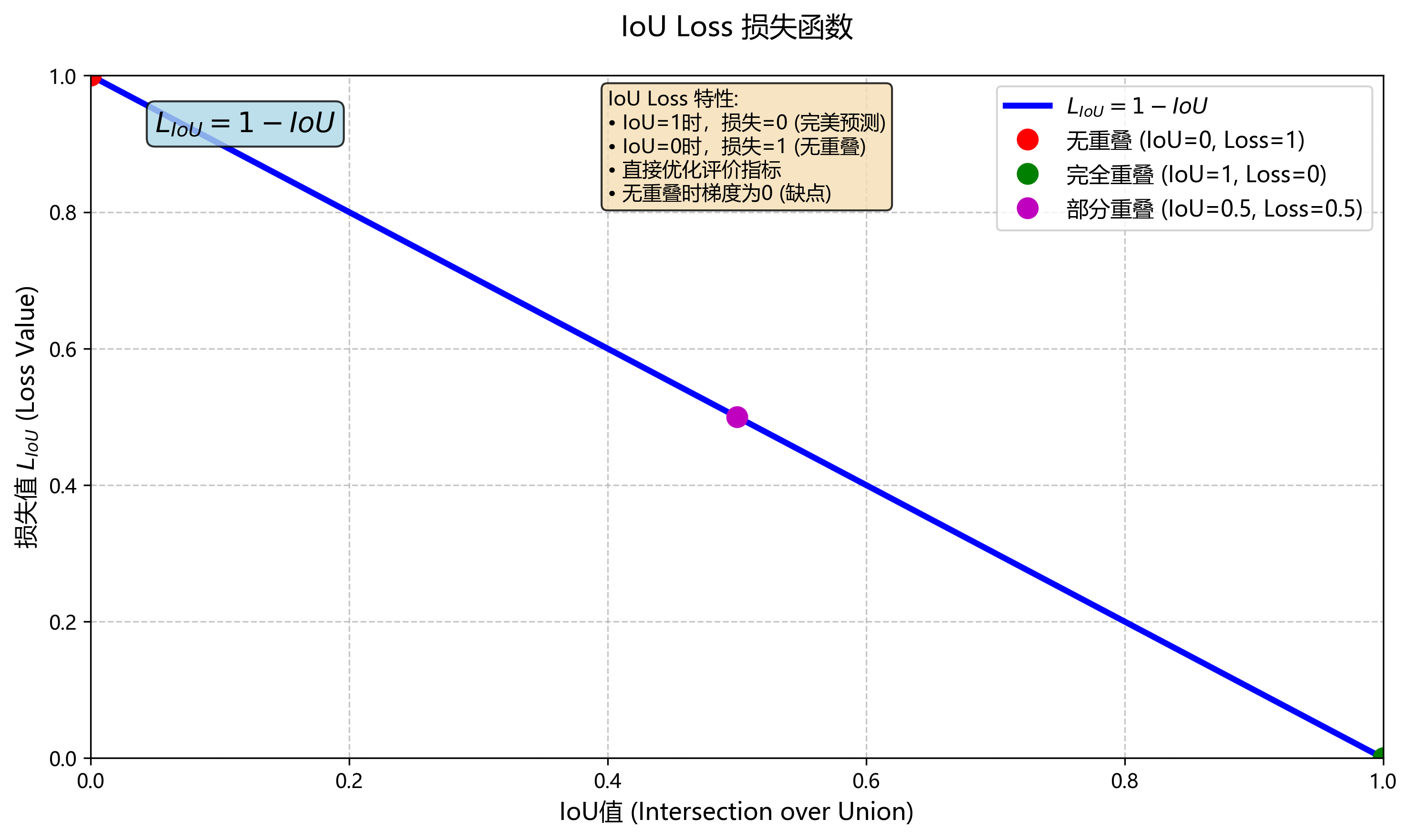
4、IoU Loss (Intersection over Union Loss)
-
问题与方法
(1)传统的边界框回归损失(如L1/L2损失)可能无法有效优化目标检测指标(如IoU);(2)直接优化IoU指标,适合边界框回归。
(3)IoU损失直接优化IoU,通过计算预测框和真实框的交并比来评估模型性能。该损失试图最大化IoU值,从而提高模型的准确性。IoU损失的缺点是可能在框重叠不多的情况下导致梯度消失,因此后续研究提出了改进版本。
(4)直接优化检测评价指标 IoU,比像素坐标回归损失更对齐目标。
-
不足:当框没有重叠时梯度为零,不利于优化。
-
计算方式: L I o U = 1 − I o U . L_{IoU}=1−IoU. LIoU=1−IoU.
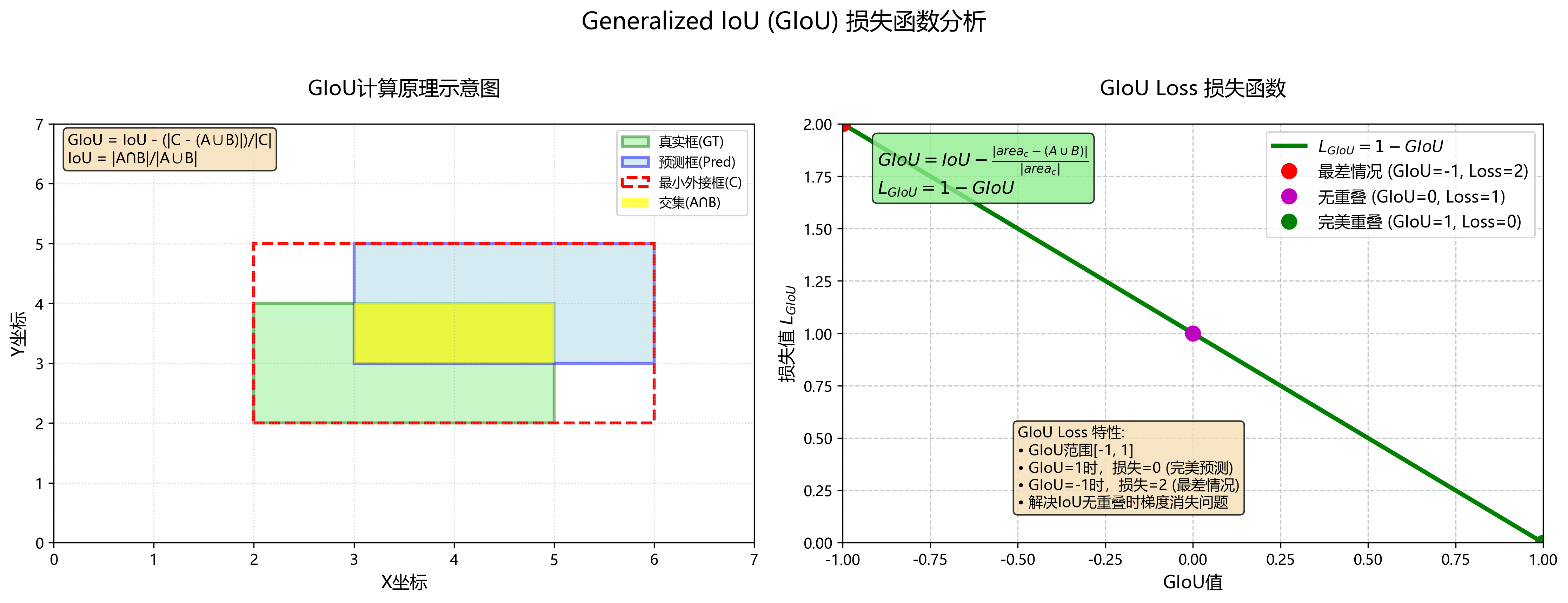
5、Generalized IoU Loss (GIoU)
-
改进了IoU损失,考虑了边界框之间的面积信息。
-
Rezatofighi et al., "Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression" (2019)
-
问题与方法
(1)传统的IoU损失在边界框之间的重叠很小或没有重叠的情况下,可能会导致效果不佳。IoU 在无重叠时无梯度;(2)借助最小外接框面积提供额外梯度信息,使无重叠也能收敛。
-
计算方式:GIoU通过考虑预测框和真实框的最小外接框的面积,引入了额外的信息来优化损失。GIoU损失计算公式为:
G I O U = I o U − ∣ a r e a c − ( A ∪ B ) ∣ ∣ a r e a c ∣ , L G I O U = 1 − G I O U GIOU = IoU - \frac{|area_c - (A \cup B)|}{|area_c|}, \\ L_{GIOU}=1-GIOU GIOU=IoU−∣areac∣∣areac−(A∪B)∣,LGIOU=1−GIOU
其中,C是最小外接框,A和B分别是真实框和预测框。这种改进使得模型在没有重叠的情况下仍能获得有意义的梯度信息。
6、DIoU Loss (Distance-IoU)
-
结合了IoU和中心点距离的损失函数,旨在加快收敛速度。
-
Zheng et al., "Distance-IoU Loss: A Fast IoU Loss for Bounding Box Regression" (2020)
-
问题与方法
(1)尽管GIoU在某些情况下表现良好,但它没有考虑边界框中心点的距离,因此在框位置不一致时仍然可能导致较差的性能;(2)DIoU在GIoU的基础上引入了中心点距离的概念,结合框的重叠程度和中心点距离,进一步提高了回归的准确性。
-
计算方式:DIoU损失的计算公式为:
D I o U = I o U − d 2 ( c p r e d , c g t ) c 2 , L D I O U = 1 − D I O U . DIoU = IoU - \frac{d^{2}(c_{pred},c_{gt})}{c^{2}}, \\ L_{DIOU} = 1 - DIOU. DIoU=IoU−c2d2(cpred,cgt),LDIOU=1−DIOU.
其中, d d d是预测框 c p r e d c_{pred} cpred和真实框中心点 c g t c_{gt} cgt之间的欧几里得距离, c c c是最小外接框的对角线长度。这种方法加速了模型的收敛并提高了准确性。

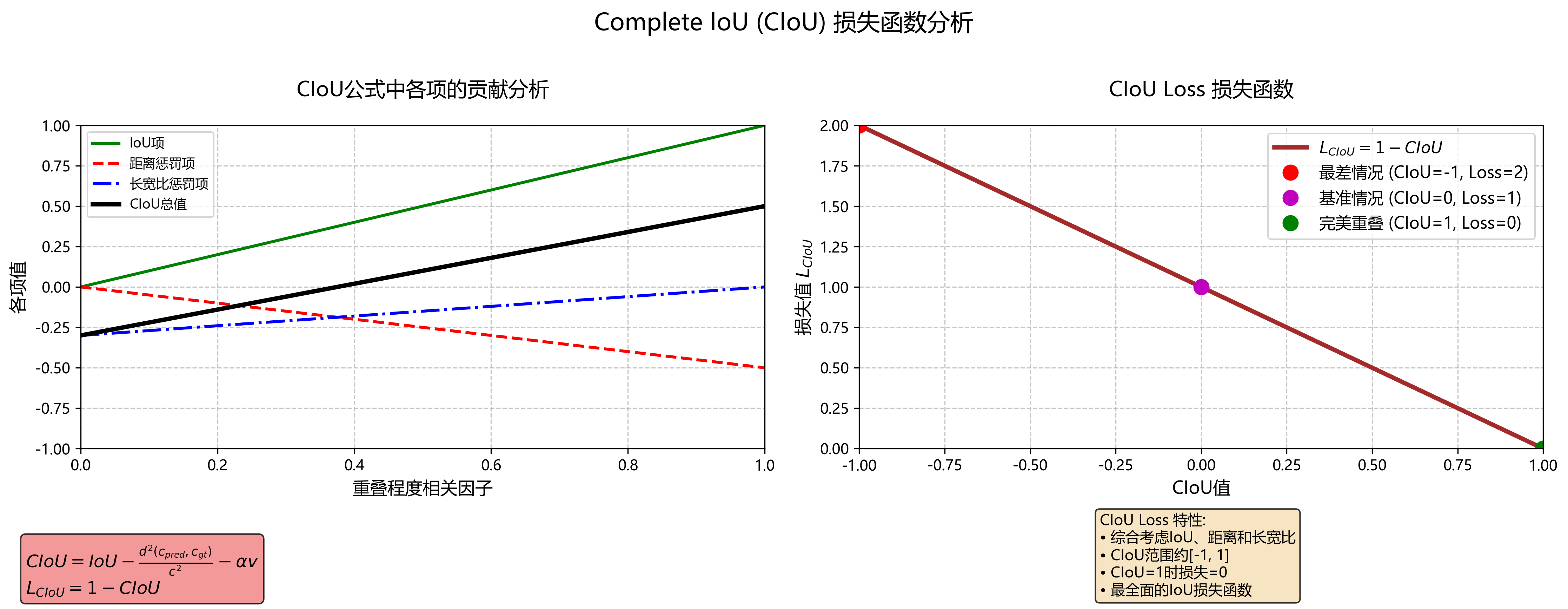
7、CIoU Loss
-
Zheng et al., "Distance-IoU Loss: A Fast IoU Loss for Bounding Box Regression" (2020)
-
问题与方法
(1)DIoU 仍未考虑长宽比一致性;(2)加入宽高比惩罚项,使回归更全面。
-
计算方式: 综合 IoU、中心点距离与宽高比一致性,定义
C I o U = I o U − d 2 ( c p r e d , c g t ) c 2 + α v , CIoU = IoU - \frac{d^{2}(c_{pred},c_{gt})}{c^{2}}+\alpha v, CIoU=IoU−c2d2(cpred,cgt)+αv,其中, v v v衡量宽高比差异, α \alpha α为平衡系数。
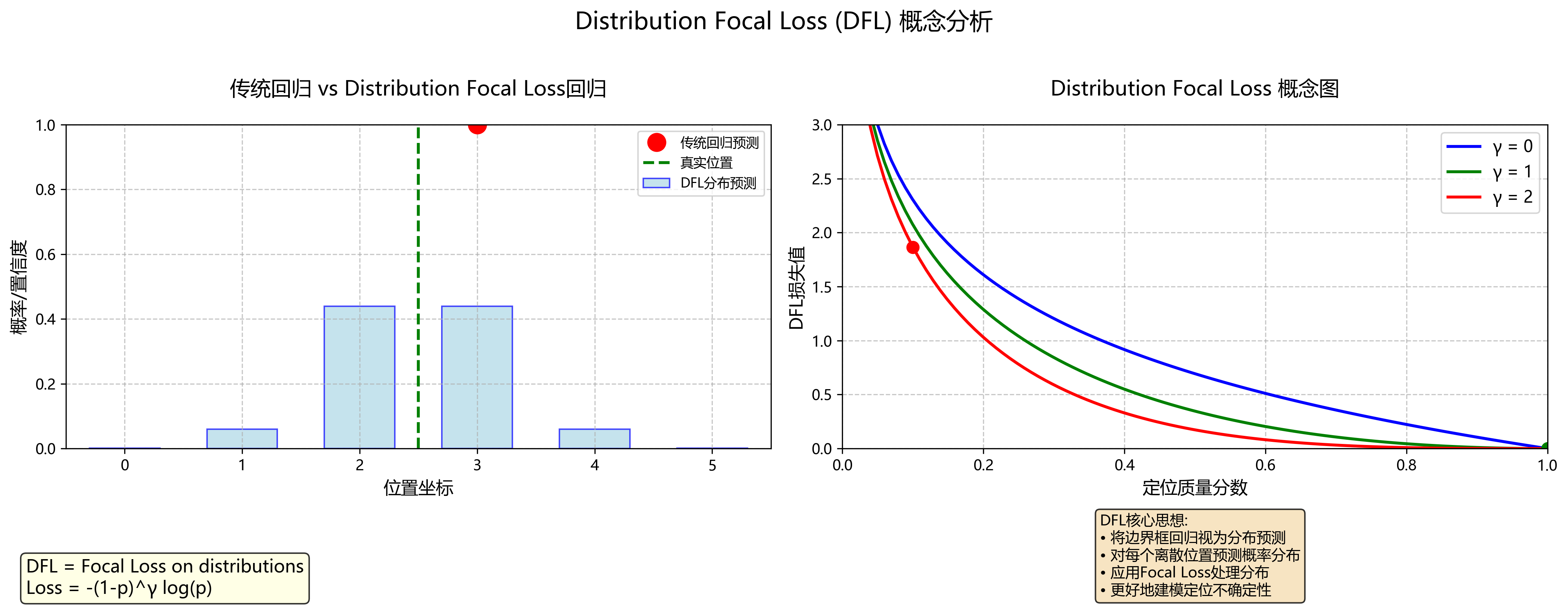
8、Distribution Focal Loss, DFL
-
Li et al., "Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation" (GFLV2, 2021)。
-
问题与方法
(1)传统回归直接预测坐标,忽略不确定性;(2)预测离散分布并施以 Focal Loss,更好地捕捉位置不确定性,提升定位质量。
-
计算方式:将边框回归视为离散分布回归,对每个离散偏移预测分类分布,用 Focal Loss 训练。