一、序列模型(Sequence Model)

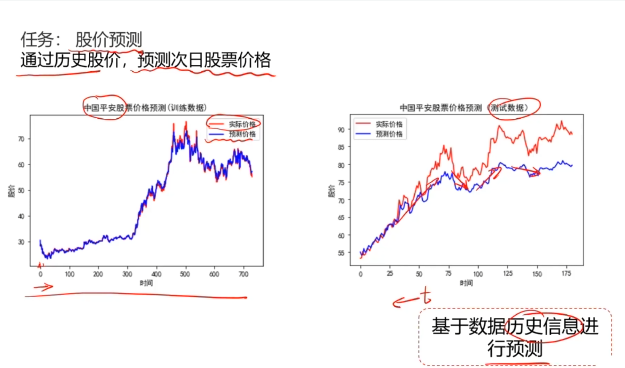
序列模型:输入或者输出中包含有序列数据的模型


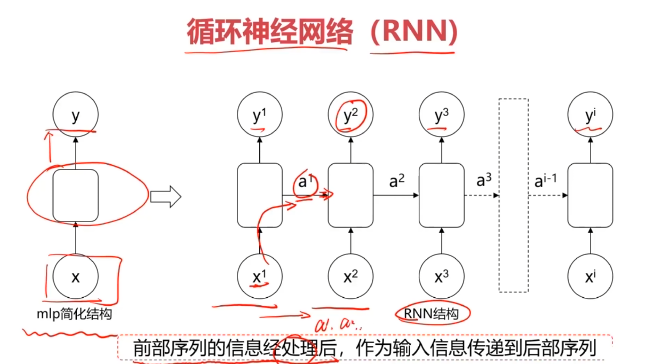
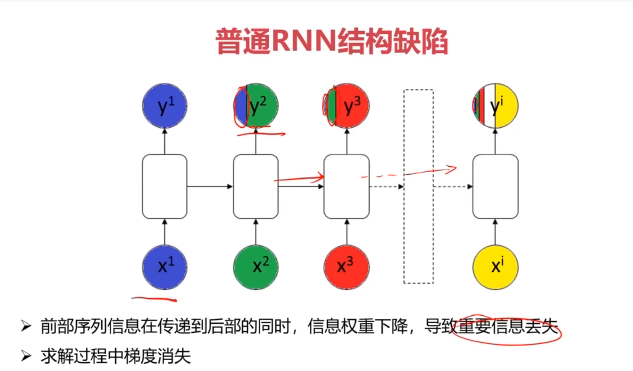
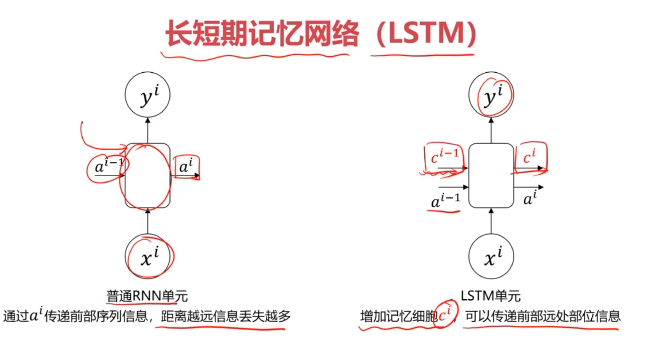
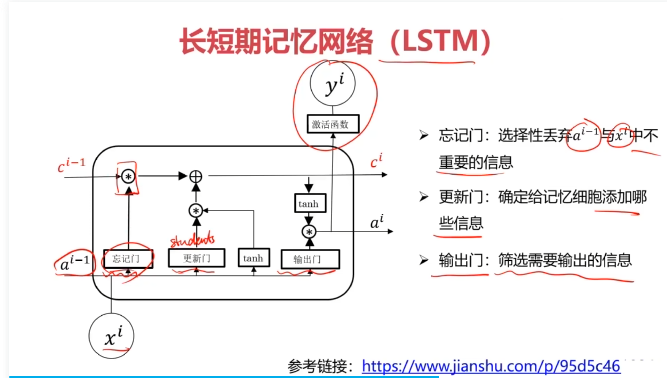
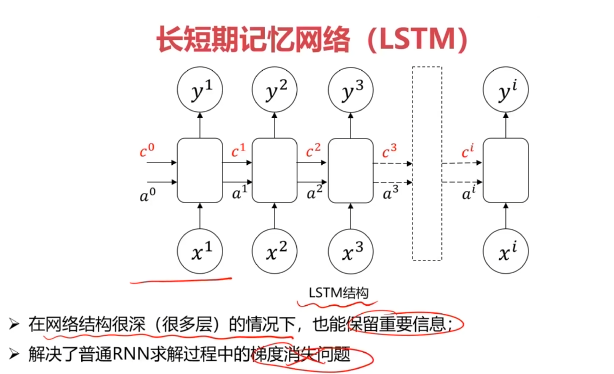
二、循环神经网络
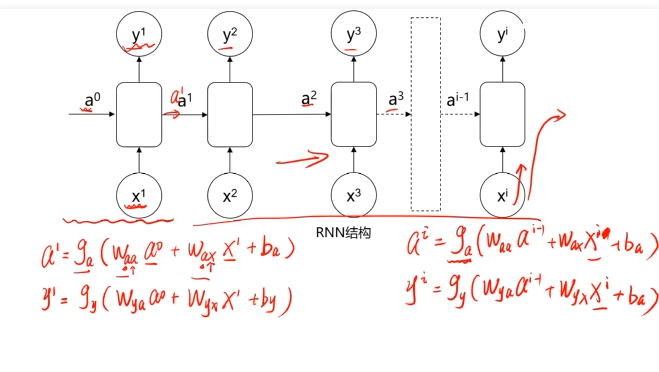

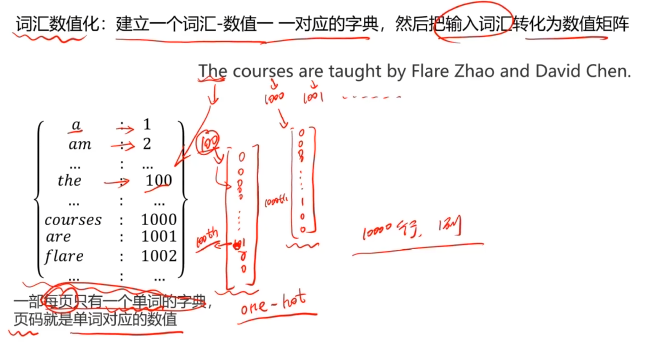
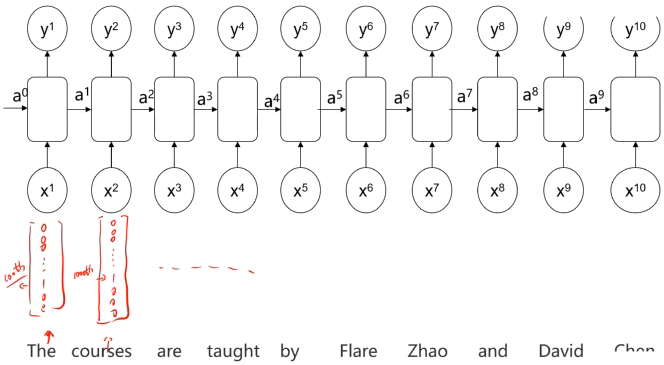
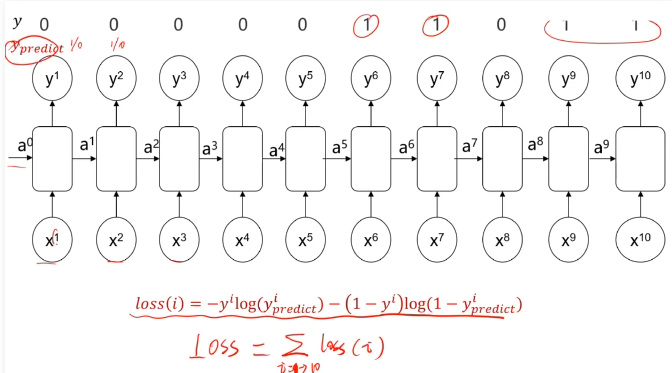
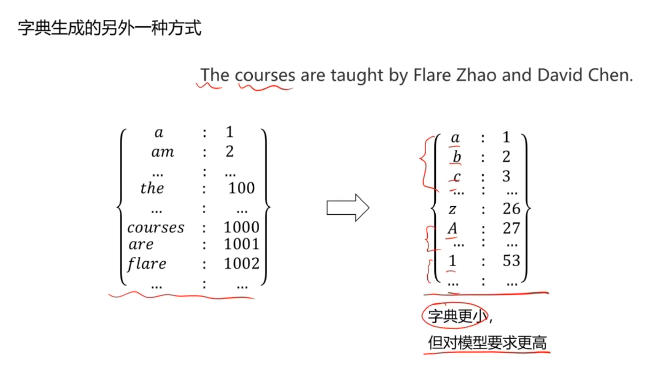
三、不同类型的RNN模型
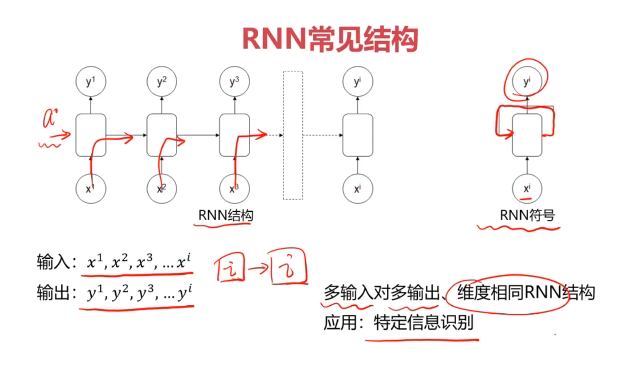
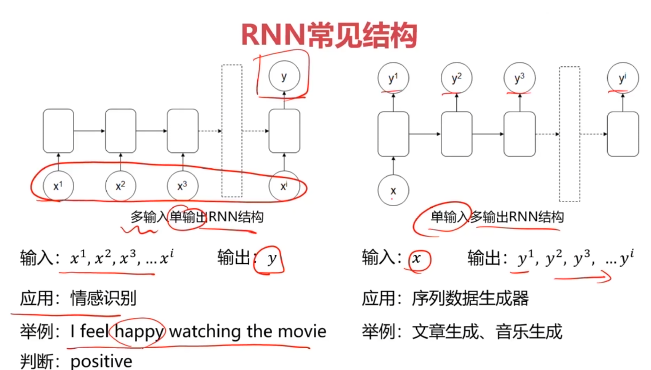
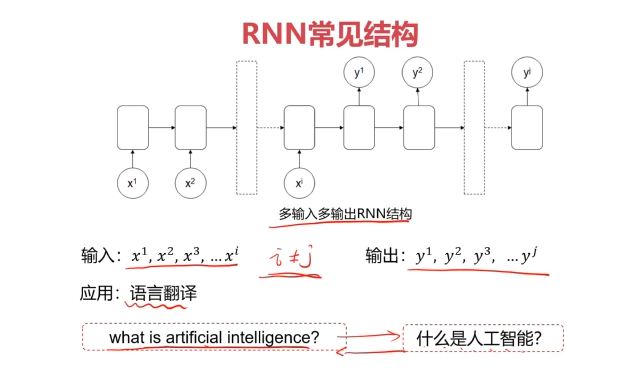

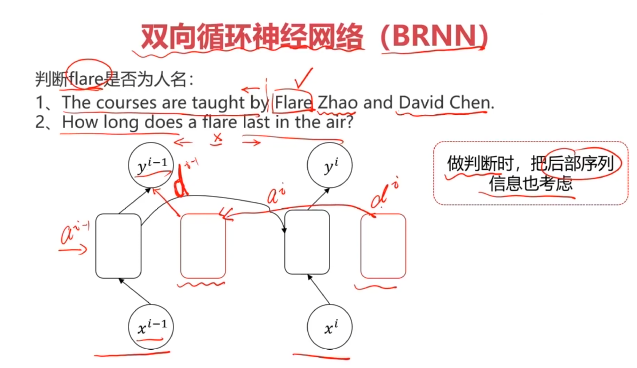
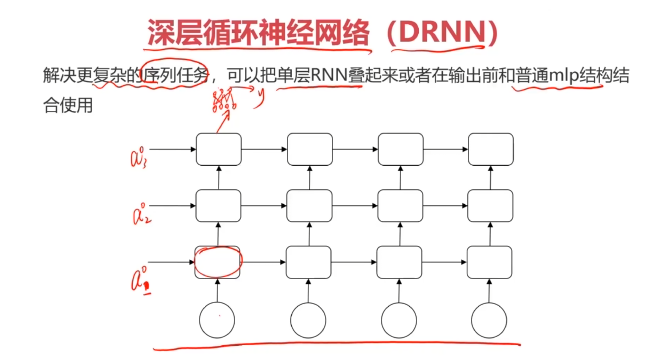
四、实战准备
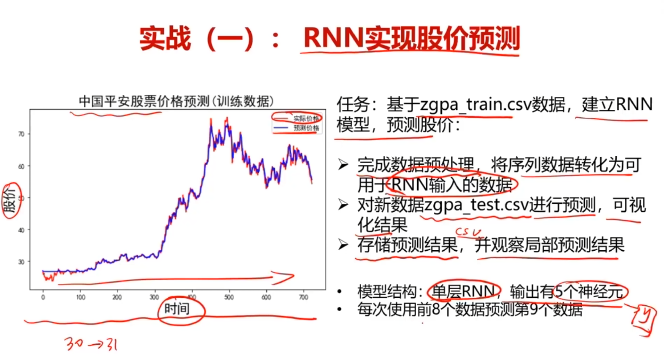




五、实战:RNN实现股价预测
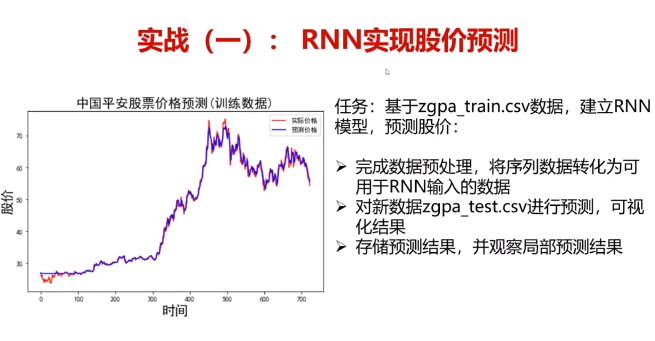
任务:基于zgpa_train.csv数据,建立RNN模型,预测股价:
1.完成数据预处理,将序列数据转化为可用于RNN输入的数据
2.对新数据zgRa_test.csv进行预测,可视化结果
3.存储预测结果,并观察局部预测结果
备注:模型结构:单层RNN,输出有5个神经元;每次使用前8个数据预测第9个数据
#加载数据
import pandas as pd
import numpy as np
data = pd.read_csv('zgpa_train.csv')
data.head()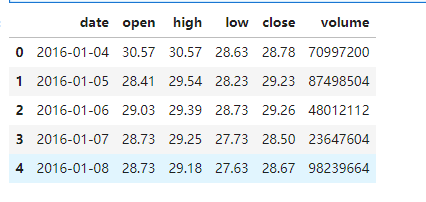
#获取收盘价
price = data.loc[:,'close']
price.head()
#对收盘价归一化处理
price_norm = price/max(price)
price_norm.head()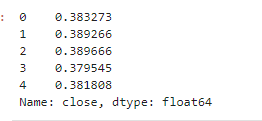
#可视化收盘价
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(3,3))
plt.plot(price)
plt.title('close price')
plt.xlabel('time')
plt.ylabel('price')
plt.show()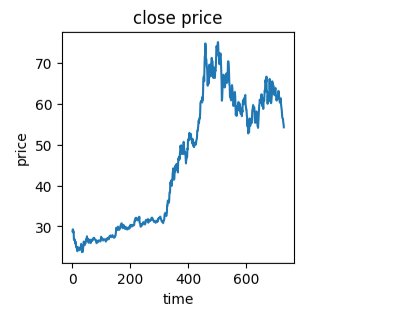
#对x,y赋值
def extract_data(data,time_step):
x = []
y = []
#0,1:2:3.....9:10个样本:time_step=8;0,1.....7;1,2.....8;2,3.....9三组(两组样本)
for i in range(len(data)-time_step):
x.append([a for a in data[i:i+time_step]])
y.append(data[i+time_step])
x = np.array(x)
x = x.reshape(x.shape[0],x.shape[1],1)
return x,y
#数据提取
time_step = 8
x,y = extract_data(price_norm, time_step)
print(x.shape,len(y))
print(x[0,:,:])
print(y)
#建立模型
from keras.models import Sequential
from keras.layers import Dense,SimpleRNN
model = Sequential()
#添加Rnn层
model.add(SimpleRNN(units=5,input_shape=(time_step,1),activation='relu'))
#输出层
model.add(Dense(units=1,activation='linear'))
#配置模型
model.compile(optimizer='adam',loss='mean_squared_error')
model.summary()
# 将 y 转换为 NumPy 数组并调整形状
y = np.array(y).reshape(-1, 1)
#模型训练
model.fit(x,y,batch_size=30,epochs=300)
#评估模型
y_train_predict = model.predict(x)*max(price)
y_train = [i*max(price) for i in y]
y_train = np.array(y_train).reshape(-1, 1)
print(y_train_predict,y_train)
#可视化
from matplotlib import pyplot as plt
fig2 = plt.figure(figsize=(3,3))
plt.plot(y_train,label='real price')
plt.plot(y_train_predict,label='predict price')
plt.title('close price')
plt.xlabel('time')
plt.ylabel('price')
plt.legend()
plt.show()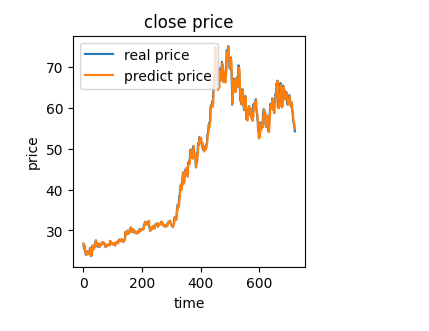
#对测试数据进行预测
data_test = pd.read_csv('zgpa_test.csv')
data_test.head()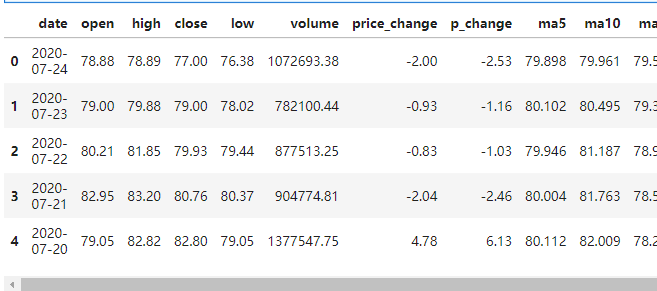
price_test = data_test.loc[:,'close']
price_test.head()
#归一化
price_test_norm = price_test/max(price)
#提取x,y
x_test_norm,y_test_norm = extract_data(price_test_norm,time_step)
print(x_test_norm.shape,len(y_test_norm))
#预测测试数据
y_test_predict = model.predict(x_test_norm)*max(price)
y_test = [i*max(price) for i in y_test_norm]
#可视化
from matplotlib import pyplot as plt
fig2 = plt.figure(figsize=(3,3))
plt.plot(y_test,label='real price')
plt.plot(y_test_predict,label='predict price')
plt.title('close price')
plt.xlabel('time')
plt.ylabel('price')
plt.legend()
plt.show()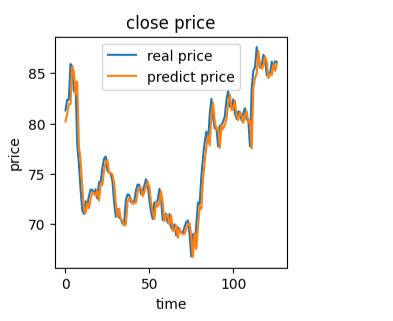
#存储数据
result_y_test = np.array(y_test).reshape(-1,1)
result_y_test_predict = y_test_predict
print(result_y_test.shape,result_y_test_predict.shape)
result = np.concatenate((result_y_test,result_y_test_predict),axis=1)
print(result.shape)
#保存数据
result = pd.DataFrame(result,columns=['real_price_test','predict_price_test'])
result.to_csv('zgpa_predict_test.csv')六、实战:基于fLare文本数据,建立LSTM模型,预测序列文字
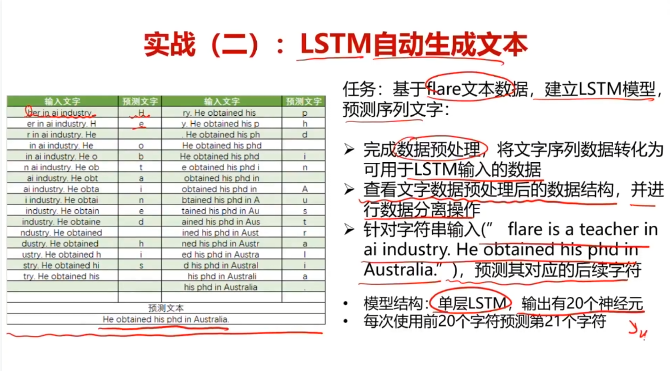
任务:基于fLare文本数据,建立LSTM模型,预测序列文字:
1.完成数据预处理,将文字序列数据转化为可用于LSTM输入的数据
2.查看文字数据预处理后的数据结构,并进行数据分离操作
3.针对字符串输入("flare is a teacher in ai industry.He obtained his phd in Australia."),预测其对应的后续字符
备注:模型结构:单层LSTM,输出有20个神经元;每次使用前20个字符预测第21个字符
#加载数据
data = open('LSTM_text.txt').read()
#移除换行符
data = data.replace('\n','').replace('\r','')
print(data)
#字符去重处理
letters = list(set(data))
print(letters)
num_letters = len(letters)
print(num_letters)
#建立字典
int_to_char = {a:b for a,b in enumerate(letters)}
print(int_to_char)
char_to_int = {b:a for a,b in enumerate(letters)}
print(char_to_int)
#每次使用前20个字符预测第21个字符
time_step = 20
#批量字符处理
import numpy as np
from keras.utils import to_categorical
#滑动窗口提取数据
def extract_data(data,slide):
x = []
y = []
for i in range(len(data)-slide):
x.append([a for a in data[i:i+slide]])
y.append(data[i+slide])
return x,y
#字符到数字的批量转化
def char_to_int_Data(x,y,char_to_int):
x_to_int = []
y_to_int = []
for i in range(len(x)):
x_to_int.append([char_to_int[char] for char in x[i]])
y_to_int.append([char_to_int[char] for char in y[i]])
return x_to_int,y_to_int
#实际输入字符文章的批量处理,输入整个字符、滑动窗口大小、转化字典
def data_preprocessing(data, slide, num_letters, char_to_int):
char_Data = extract_data(data, slide)
int_Data = char_to_int_Data(char_Data[0], char_Data[1], char_to_int)
Input = int_Data[0]
Output = list(np.array(int_Data[1]).flatten())
Input_RESHAPED = np.array(Input).reshape(len(Input), slide)
new = np.random.randint(0,10,size=[Input_RESHAPED.shape[0],Input_RESHAPED.shape[1],num_letters])
for i in range(Input_RESHAPED.shape[0]):
for j in range(Input_RESHAPED.shape[1]):
new[i,j,:] = to_categorical(Input_RESHAPED[i,j],num_classes=num_letters)
return new,Output
#提取x,y
x,y = data_preprocessing(data,time_step,num_letters,char_to_int)
print(x.shape)
print(len(y))
#数据分离
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size =0.1,random_state = 10)
print(x_train.shape,x_test.shape,x.shape)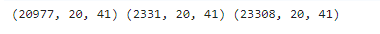
y_train_category = to_categorical(y_train,num_letters)
print(y_train_category)
#建立模型
from keras.models import Sequential
from keras.layers import Dense,LSTM
model = Sequential()
model.add(LSTM(units=20,input_shape=(x_train.shape[1],x_train.shape[2]),activation='relu'))
model.add(Dense(units=num_letters,activation='softmax'))
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
model.summary()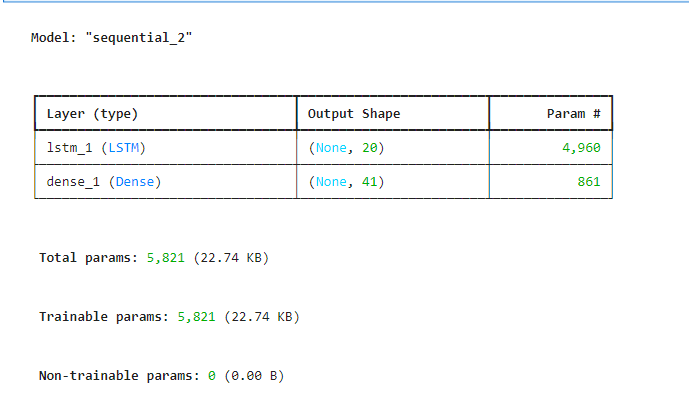
#模型训练
model.fit(x_train,y_train_category,batch_size=1000,epochs=50)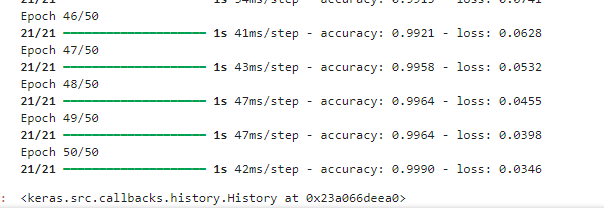
#预测训练集
probabilities = model.predict(x_train)
y_train_predict = np.argmax(probabilities, axis=1) # 取概率最大的类别
print(y_train_predict)
from sklearn.metrics import accuracy_score
accuracy_train = accuracy_score(y_train,y_train_predict)
print(accuracy_train)
#计算测试集准确率
probabilities = model.predict(x_test)
y_test_predict = np.argmax(probabilities, axis=1) # 取概率最大的类别
accuracy_test = accuracy_score(y_test,y_test_predict)
print(accuracy_test)
#预测新数据
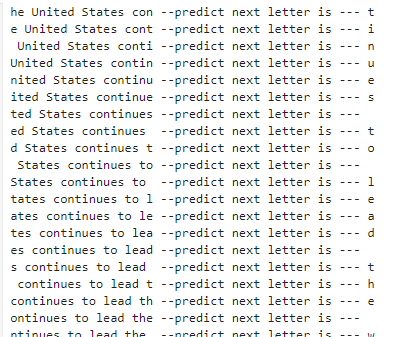
new_lettets = 'he United States continues to lead the world with more than 4 million'
x_new,y_new = data_preprocessing(new_lettets,time_step,num_letters,char_to_int)
probabilities = model.predict(x_new)
y_new_predict = np.argmax(probabilities, axis=1) # 取概率最大的类别
print(y_new_predict)
#转换为文本
y_new_predict_char = [int_to_char[i] for i in y_new_predict]
print(y_new_predict_char)
# 将列表转换为字符串
y_new_txt = ''.join(y_new_predict_char)
print(y_new_txt)
for i in range(0,x_new.shape[0]-20):
print(new_lettets[i:i+20],'--predict next letter is ---',y_new_predict_char[i])