文章目录
-
- [一、ELK Stack 核心概念:是什么?为什么用?](#一、ELK Stack 核心概念:是什么?为什么用?)
-
- [1.1 什么是 ELK?](#1.1 什么是 ELK?)
- [1.2 为什么需要 ELK?](#1.2 为什么需要 ELK?)
- [二、ELK 三大组件深度解析](#二、ELK 三大组件深度解析)
- [三、实战:ELK Stack 部署步骤(CentOS 环境)](#三、实战:ELK Stack 部署步骤(CentOS 环境))
-
- [3.1 环境准备(所有节点通用)](#3.1 环境准备(所有节点通用))
-
- [1. 基础配置](#1. 基础配置)
- [2. 部署节点规划](#2. 部署节点规划)
- [3.2 部署 Elasticsearch 集群(Node1 + Node2)](#3.2 部署 Elasticsearch 集群(Node1 + Node2))
-
- [1. 安装 ES(两节点操作相同)](#1. 安装 ES(两节点操作相同))
- [2. 修改 ES 配置文件(关键!)](#2. 修改 ES 配置文件(关键!))
- [3. 创建数据目录并授权](#3. 创建数据目录并授权)
- [4. 启动 ES 并验证](#4. 启动 ES 并验证)
- [5. 安装 ES-Head 插件(可视化管理集群)](#5. 安装 ES-Head 插件(可视化管理集群))
- [3.3 部署 Logstash(Apache 节点:192.168.10.97)](#3.3 部署 Logstash(Apache 节点:192.168.10.97))
-
- [1. 安装 Logstash](#1. 安装 Logstash)
- [2. 测试 Logstash 功能](#2. 测试 Logstash 功能)
- [3. 配置 Logstash 收集 Apache 日志](#3. 配置 Logstash 收集 Apache 日志)
- [4. 启动 Logstash 并验证](#4. 启动 Logstash 并验证)
- [3.4 部署 Kibana(Node1 节点:192.168.10.98)](#3.4 部署 Kibana(Node1 节点:192.168.10.98))
-
- [1. 安装 Kibana](#1. 安装 Kibana)
- [2. 修改 Kibana 配置文件](#2. 修改 Kibana 配置文件)
- [3. 验证 Kibana 并添加索引](#3. 验证 Kibana 并添加索引)
- [3.5 扩展:Filebeat + ELK 部署(轻量日志收集)](#3.5 扩展:Filebeat + ELK 部署(轻量日志收集))
-
- [1. 环境规划](#1. 环境规划)
- [2. 安装 Filebeat(192.168.10.96)](#2. 安装 Filebeat(192.168.10.96))
- [3. 配置 Filebeat(收集系统日志,发送到 Logstash)](#3. 配置 Filebeat(收集系统日志,发送到 Logstash))
- [4. 配置 Logstash 接收 Filebeat 数据(Apache 节点)](#4. 配置 Logstash 接收 Filebeat 数据(Apache 节点))
- [5. 启动并验证](#5. 启动并验证)
- [四、总结:ELK 实战建议](#四、总结:ELK 实战建议)
在运维和开发工作中,你是否遇到过这样的痛点:数十上百台服务器的日志分散存储,排查问题时需要逐个登录机器用grep/awk检索,效率极低?面对海量日志,想做实时监控、异常报警却无从下手?
今天要介绍的ELK Stack,正是解决这些问题的企业级日志分析方案。它将 Elasticsearch(存储分析)、Logstash(数据收集)、Kibana(可视化)三个开源工具无缝整合,实现了日志从"分散存储"到"集中化、实时化、可视化分析"的闭环。
一、ELK Stack 核心概念:是什么?为什么用?
1.1 什么是 ELK?
ELK 是 Elasticsearch、Logstash、Kibana 三者的缩写,三者各司其职,共同构成完整的日志处理链路:
- Elasticsearch(ES):核心引擎,负责日志的存储、索引和快速检索,支持分布式架构,能应对海量数据。
- Logstash:数据管道,从日志文件、数据库、消息队列等来源收集数据,经过过滤、格式化后,发送到 ES。
- Kibana:可视化工具,通过 Web 界面展示 ES 中的数据,支持图表、仪表盘、日志搜索,让数据"看得见"。
简单说,ELK 就是一套"日志收集→处理→存储→分析→展示"的一体化工具包,除了日志分析,还能用于系统监控、业务数据分析等场景。
1.2 为什么需要 ELK?
传统日志管理的痛点,正是 ELK 的优势所在:
- 分散日志集中化:无需登录多台机器,所有日志统一存储到 ES 集群。
- 高效检索与分析:ES 支持全文搜索和实时分析,秒级定位关键日志(比如某条错误日志的出现时间、频率)。
- 可视化与监控:Kibana 生成折线图、饼图、仪表盘,直观展示系统状态,还能设置异常报警。
- 应对海量数据:分布式架构支持横向扩展,数据量增长时只需增加节点即可。
一套完整的日志系统需要具备"收集、传输、存储、分析、警告"5大特征,ELK 恰好完美覆盖。
二、ELK 三大组件深度解析
2.1 Elasticsearch:日志存储与检索的"大脑"
ES 是基于 Lucene 开发的分布式搜索引擎,用 Java 编写,通过 RESTful API 与外部交互,核心优势是"快"和"可扩展"。
核心功能
- 全文搜索:对日志中的文本内容(如错误信息、用户 ID)快速索引和检索,支持模糊匹配、关键词过滤。
- 实时分析:数据写入后立即可查,适合实时监控(比如实时统计接口报错次数)。
- 分布式架构:支持跨集群部署,数据自动分片存储,确保高可用和扩展性。
- RESTful API:用 HTTP 请求即可操作 ES(比如创建索引、查询数据),支持多语言集成。
关键架构组件
理解 ES 架构是部署和调优的基础,核心概念如下:
| 组件 | 作用说明 |
|---|---|
| 集群(Cluster) | 多个 ES 节点组成的集群,共享数据和负载,有唯一集群名(如 my-elk-cluster)。 |
| 节点(Node) | 单个 ES 实例,分主节点(管理集群)、数据节点(存储数据)等角色。 |
| 索引(Index) | 类似数据库的"表",存储一类日志(如 system-2024.05.20 表示5月20日的系统日志)。 |
| 文档(Document) | ES 中最小数据单元,每条日志就是一个文档,格式为 JSON。 |
| 分片(Shard) | 索引拆分后的片段,每个分片是独立的 Lucene 索引,实现并行处理和水平扩展。 |
| 副本(Replica) | 分片的备份,用于数据冗余(防止节点宕机丢失数据)和分担查询压力。 |
优缺点
- 优点:性能强(全文搜索快)、易扩展、支持复杂查询、开源免费。
- 缺点:内存消耗大(内存密集型应用)、学习曲线陡(复杂的查询 DSL 语言)、大型集群管理复杂。
2.2 Logstash:日志收集与处理的"管道"
Logstash 是用 Ruby 编写、运行在 JVM 上的数据处理工具,核心是"输入(Input)→过滤(Filter)→输出(Output)"的管道模型。
核心功能
- 多源数据收集:支持日志文件、数据库(MySQL)、消息队列(Kafka)、HTTP 等多种输入源,通过"输入插件"扩展。
- 灵活数据处理:用"过滤插件"清洗数据(比如提取日志中的 IP、时间字段)、格式转换(比如将字符串时间转为时间戳)、过滤无用日志。
- 多目标输出:处理后的数据可发送到 ES、数据库、文件系统,甚至 Kafka,通过"输出插件"适配。
- 实时处理:支持流数据实时处理,适合日志监控场景。
替代工具:为什么需要 Filebeat/Fluentd?
Logstash 虽强,但有个明显缺点------重量级(运行在 JVM 上,资源消耗高)。如果需要在大量客户端机器上收集日志,更推荐轻量级工具:
- Filebeat:ES 官方推出的轻量日志收集器,资源占用低,适合部署在客户端,可直接发送日志到 ES 或转发给 Logstash。
- Fluentd:比 Logstash 更轻量、性能更高,在 Kubernetes 集群中常用(组成 EFK 架构),支持更多数据格式。
2.3 Kibana:日志可视化的"窗口"
Kibana 是 ES 的可视化前端,无需写代码,通过界面就能实现日志分析和监控,是 ELK 中"最直观"的组件。
核心功能(必用)
- 日志搜索(Discovery):实时检索 ES 中的原始日志,支持按时间范围、关键词过滤,可快速定位错误日志。
- 数据可视化(Visualizations):生成折线图(趋势分析)、饼图(占比统计)、柱状图(对比分析),比如"按小时统计接口报错次数"。
- 仪表盘(Dashboards):将多个可视化图表组合成仪表盘,比如"系统监控仪表盘"包含 CPU 使用率、内存占用、日志报错数。
- 报警与监控:设置阈值报警(比如"5分钟内报错次数超过10次则告警"),支持邮件、短信等通知方式。
- 机器学习:自动检测数据异常(比如突然飙升的错误日志),适合无人值守监控。
工作原理
Kibana 本身不存储数据,所有数据都来自 ES:
- 用户在 Kibana 界面发起查询(比如搜索"ERROR"日志);
- Kibana 将查询请求转为 ES 支持的语法(KQL 或 Lucene),发送给 ES;
- ES 返回查询结果,Kibana 用图表或列表展示。
三、实战:ELK Stack 部署步骤(CentOS 环境)
接下来我们手把手部署一套 ELK 集群,包含 2 个 ES 节点、1 个 Logstash 节点、1 个 Kibana 节点,最后用 Filebeat 扩展日志收集。
3.1 环境准备(所有节点通用)
1. 基础配置
-
关闭防火墙和 SELinux(避免端口被拦截):
bashsystemctl stop firewalld && systemctl disable firewalld setenforce 0 && sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config -
配置主机名和域名解析(以 ES 节点为例):
bash# Node1 节点(192.168.10.98) hostnamectl set-hostname node1 # Node2 节点(192.168.10.99) hostnamectl set-hostname node2 # 所有节点添加解析 echo "192.168.10.98 node1" >> /etc/hosts echo "192.168.10.99 node2" >> /etc/hosts echo "192.168.10.97 apache" >> /etc/hosts # Logstash 节点(Apache 服务器) -
安装 Java 环境(ES/Logstash 依赖 Java):
bashyum -y install java-1.8.0-openjdk java -version # 验证,需显示 1.8.0 及以上
2. 部署节点规划
| 节点名称 | IP 地址 | 配置 | 部署服务 |
|---|---|---|---|
| Node1 | 192.168.10.98 | 2C/4G | Elasticsearch、Kibana |
| Node2 | 192.168.10.99 | 2C/4G | Elasticsearch |
| Apache(Logstash) | 192.168.10.97 | 1C/2G | Logstash、Apache(日志源) |
3.2 部署 Elasticsearch 集群(Node1 + Node2)
1. 安装 ES(两节点操作相同)
bash
# 下载 ES 6.6.1 RPM 包(版本需与 Logstash/Kibana 一致)
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.1.rpm
# 安装
rpm -ivh elasticsearch-6.6.1.rpm
# 设置开机启动
systemctl daemon-reload && systemctl enable elasticsearch2. 修改 ES 配置文件(关键!)
bash
# 备份默认配置
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
# 编辑配置文件
vim /etc/elasticsearch/elasticsearch.ymlNode1 节点配置 (Node2 节点只需修改 node.name 为 node2):
yaml
# 集群名称(所有节点必须一致)--17--取消注释
cluster.name: my-elk-cluster
# 节点名称(每个节点唯一)--23--取消注释
node.name: node1
# 数据存储路径(需手动创建)--33--取消注释
path.data: /data/elk_data
# 日志存储路径--37--取消注释
path.logs: /var/log/elasticsearch/
# 禁用内存锁定(避免内存不足报错)--43--取消注释
bootstrap.memory_lock: false
# 监听地址(0.0.0.0 允许所有机器访问)--55--取消注释
network.host: 0.0.0.0
# ES 默认端口(9200 用于 HTTP 通信,9300 用于节点间通信)--59--取消注释
http.port: 9200
# 集群发现节点(指定所有 ES 节点) --68--取消注释
discovery.zen.ping.unicast.hosts: ["node1", "node2"]3. 创建数据目录并授权
bash
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/ # 给 ES 用户权限4. 启动 ES 并验证
bash
# 启动 ES
systemctl start elasticsearch
# 验证端口(9200 端口监听则正常)
netstat -antp | grep 9200
-
浏览器访问
http://192.168.10.98:9200,看到以下信息说明 Node1 正常:json{ "name" : "node1", "cluster_name" : "my-elk-cluster", "version" : { "number" : "6.6.1" } } -
查看集群健康状态:访问
http://192.168.10.99:9200/_cluster/health?pretty,status为green表示集群健康(yellow表示副本未就绪,red表示数据丢失)。

5. 安装 ES-Head 插件(可视化管理集群)
ES-Head 是第三方插件,用于直观查看集群状态、索引信息:
bash
# 安装依赖(NodeJS + phantomjs)
yum -y install gcc gcc-c++ make
# 安装 NodeJS(需 8.x 版本,太高版本不兼容)
wget https://nodejs.org/dist/v8.2.1/node-v8.2.1.tar.gz
tar zxvf node-v8.2.1.tar.gz -C /opt && cd /opt/node-v8.2.1
./configure && make && make install
# 安装 phantomjs
wget https://bitbucket.org/ariya/phantomjs/downloads/phantomjs-2.1.1-linux-x86_64.tar.bz2
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
cp /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin/phantomjs /usr/local/bin/
# 安装 ES-Head
wget https://github.com/mobz/elasticsearch-head/archive/master.zip -O elasticsearch-head.tar.gz #该网址不在国内可能下载不了。需要找第三方安装包。
tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm install # 安装依赖
# 允许 ES 跨域访问(修改 ES 配置)
echo "http.cors.enabled: true" >> /etc/elasticsearch/elasticsearch.yml
echo "http.cors.allow-origin: \"*\"" >> /etc/elasticsearch/elasticsearch.yml
systemctl restart elasticsearch
# 启动 ES-Head
npm run start & # 后台运行- 浏览器访问
http://192.168.10.98:9100,在"连接"框输入http://192.168.10.98:9200,看到"集群健康值:green"即成功。
3.3 部署 Logstash(Apache 节点:192.168.10.97)
Logstash 用于收集 Apache 服务器的日志,发送到 ES 集群。
1. 安装 Logstash
bash
# 下载 RPM 包
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.6.1.rpm
# 安装
rpm -ivh logstash-6.6.1.rpm
# 设置开机启动
systemctl enable logstash && systemctl start logstash
# 创建软链接(方便命令行调用)
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/2. 测试 Logstash 功能
先通过简单命令测试 Logstash 的"输入→输出"管道:
bash
# 标准输入→标准输出(输入内容后按回车,会输出格式化日志)
logstash -e 'input { stdin{} } output { stdout{} }'
# 测试对接 ES:输入内容会发送到 ES(无标准输出,需在 ES-Head 查看)
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.10.98:9200"] } }'3. 配置 Logstash 收集 Apache 日志
创建 Logstash 配置文件,收集 Apache 的访问日志和错误日志:
bash
# 安装 Apache(生成日志源)
yum -y install httpd && systemctl start httpd
# 创建 Logstash 配置文件
vim /etc/logstash/conf.d/apache_log.conf配置内容:
yaml
# 输入:收集 Apache 日志
input {
file {
path => "/etc/httpd/logs/access_log" # Apache 访问日志路径
type => "apache_access" # 日志类型(用于区分输出)
start_position => "beginning" # 从日志开头收集
}
file {
path => "/etc/httpd/logs/error_log" # Apache 错误日志路径
type => "apache_error" # 日志类型
start_position => "beginning"
}
}
# 输出:根据日志类型发送到 ES 不同索引
output {
if [type] == "apache_access" {
elasticsearch {
hosts => ["192.168.10.98:9200"] # ES 地址
index => "apache_access-%{+YYYY.MM.dd}" # 索引名(按日期拆分)
}
}
if [type] == "apache_error" {
elasticsearch {
hosts => ["192.168.10.98:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}4. 启动 Logstash 并验证
bash
# 重启 Logstash(加载新配置)
systemctl restart logstash
# 在 ES-Head 查看:在索引栏会出现 apache_access-2024.05.20 等索引3.4 部署 Kibana(Node1 节点:192.168.10.98)
Kibana 对接 ES 集群,实现日志可视化。
1. 安装 Kibana
cd /opt
bash
# 下载 RPM 包
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.6.1-x86_64.rpm
# 安装
rpm -ivh kibana-6.6.1-x86_64.rpm
# 设置开机启动
systemctl enable kibana && systemctl start kibana2. 修改 Kibana 配置文件
bash
vim /etc/kibana/kibana.yml关键配置:
yaml
# Kibana 监听端口(默认 5601)--2--取消注释
server.port: 5601
# 监听地址(0.0.0.0 允许外部访问)--7--取消注释,
server.host: "0.0.0.0"
# 对接 ES 集群地址--28--取消注释,
elasticsearch.hosts: ["http://192.168.10.98:9200"]
# Kibana 在 ES 中创建的索引(存储 Kibana 配置)--37--取消注释
kibana.index: ".kibana"
systemctl start kibana.service #开启服务
systemctl enable kibana.service #设置开机自启动
netstat -natp | grep 5601 #查看端口状态3. 验证 Kibana 并添加索引
-
浏览器访问
http://192.168.10.98:5601,首次登录需添加 ES 索引:-
点击左侧 Management → Index Patterns → Create index pattern;
-
输入索引前缀(如
apache_access-*),点击 Next step; -
时间字段选择
@timestamp(日志时间),点击 Create index pattern ;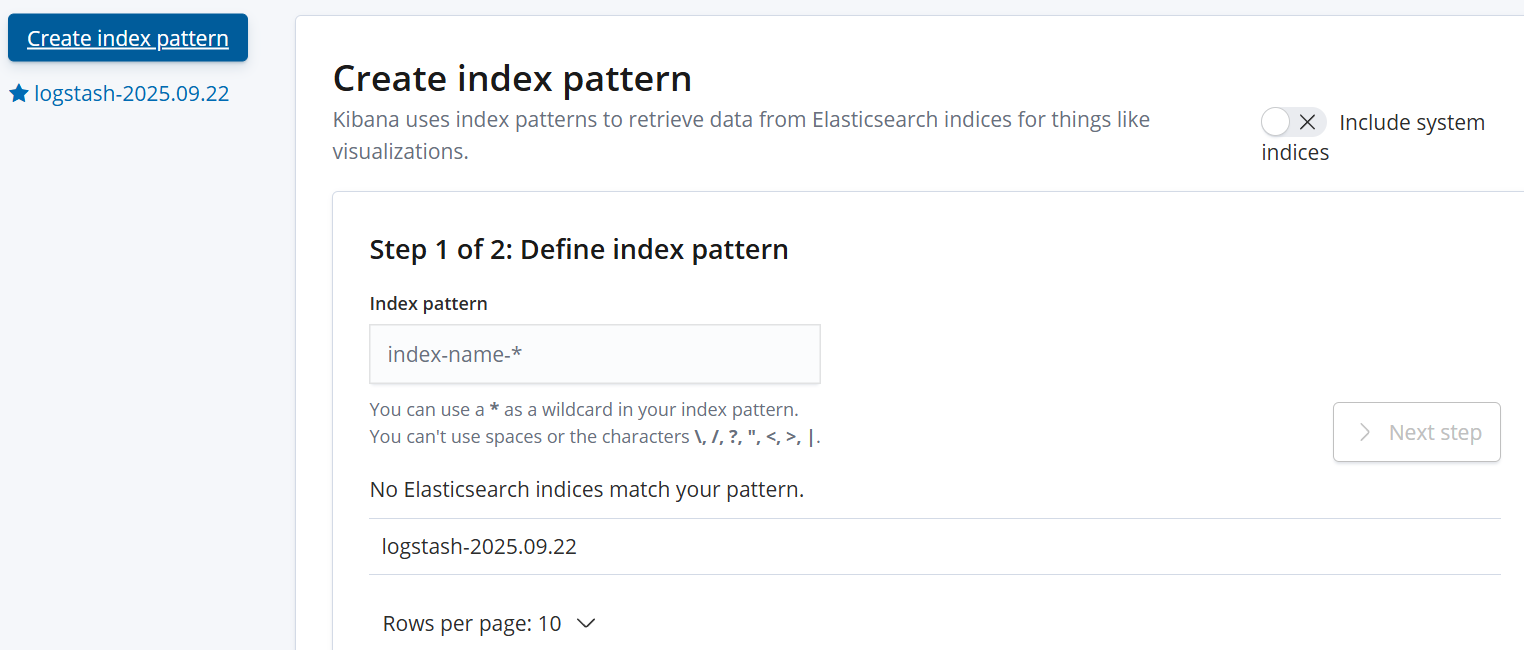
-
重复步骤添加
apache_error-*索引。
-
-
查看日志:点击左侧 Discover ,选择索引(如
apache_access-*),即可看到 Apache 访问日志,支持按时间、关键词过滤。
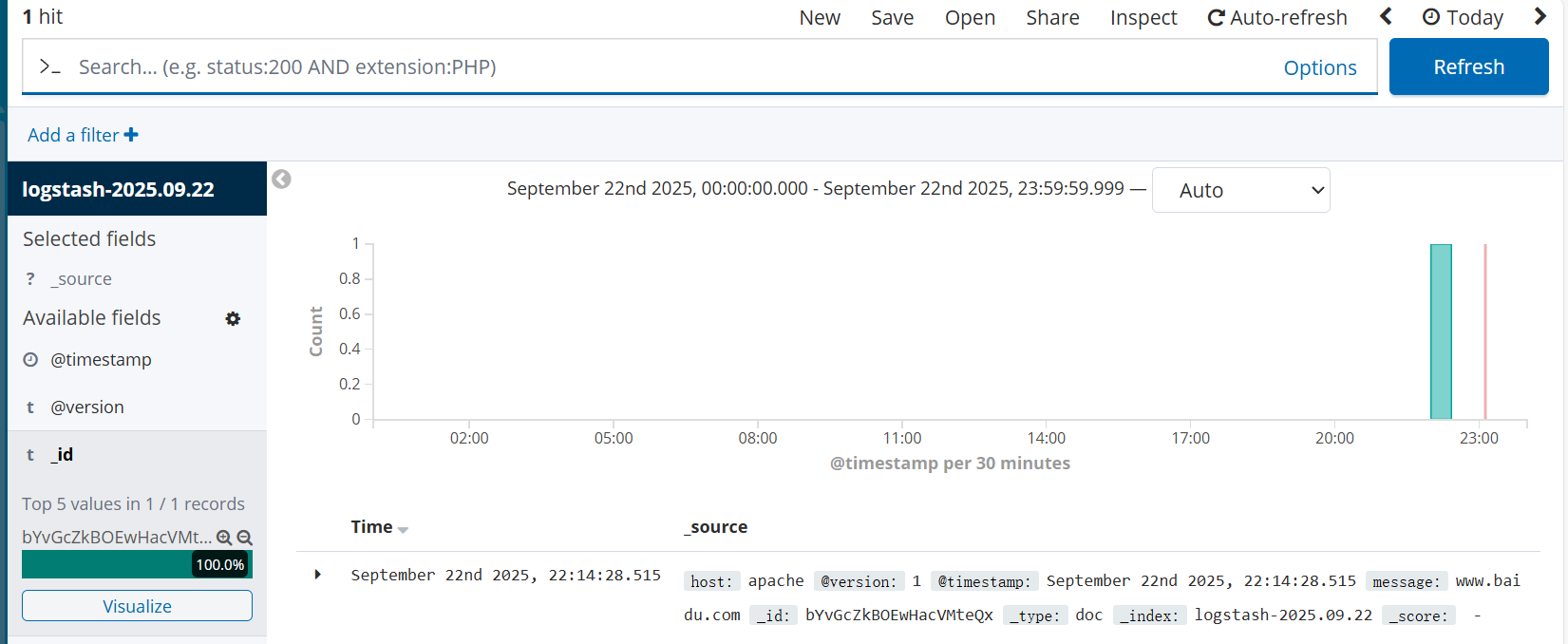
3.5 扩展:Filebeat + ELK 部署(轻量日志收集)
如果需要在多台客户端机器收集日志,用 Filebeat 替代 Logstash 作为前端收集器,资源消耗更低。
1. 环境规划
新增 Filebeat 节点:
| 节点名称 | IP 地址 | 配置 | 部署服务 |
|---|---|---|---|
| Filebeat | 192.168.10.16 | 1C/1G | Filebeat |
2. 安装 Filebeat(192.168.10.96)
bash
# 安装 RPM 包
cd /opt
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.6.1-x86_64.rpm
rpm -ivh filebeat-6.6.1-x86_64.rpm3. 配置 Filebeat(收集系统日志,发送到 Logstash)
bash
vim /etc/filebeat/filebeat.yml关键配置:
yaml
# 收集的日志路径
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/messages # 系统日志
- /var/log/*.log # 其他日志
# 输出到 Logstash(而非直接到 ES)
output.logstash:
hosts: ["192.168.10.97:5044"] # Logstash 地址和端口(5044 是 beats 输入默认端口)4. 配置 Logstash 接收 Filebeat 数据(Apache 节点)
bash
vim /etc/logstash/conf.d/logstash_beats.conf配置内容:
yaml
# 输入:接收 Filebeat 数据
input {
beats {
port => 5044 # 监听 5044 端口
}
}
# 输出:发送到 ES
output {
elasticsearch {
hosts => ["192.168.10.98:9200"]
index => "filebeat-%{+YYYY.MM.dd}" # 索引名
}
stdout { codec => rubydebug } # 同时输出到控制台(调试用)
}5. 启动并验证
bash
# 启动 Filebeat
systemctl start filebeat && systemctl enable filebeat
# 启动 Logstash(加载新配置)
logstash -f /etc/logstash/conf.d/logstash_beats.conf &
# 在 Kibana 添加索引 `filebeat-*`,查看系统日志四、总结:ELK 实战建议
- 版本一致性:ES、Logstash、Kibana、Filebeat 版本必须一致(如均用 6.6.1),否则可能出现兼容性问题。
- 资源配置:ES 对内存要求高,生产环境建议每个节点至少 4G 内存,且避免与其他服务混部署。
- 索引管理 :日志索引按日期拆分(如
apache_access-2024.05.20),定期删除旧索引(可用 ES 索引生命周期管理 ILM)。 - 监控 ELK 自身:用 Kibana 监控 ES 集群健康、Logstash 管道状态,避免 ELK 自身故障导致日志丢失。
- 安全加固:生产环境需开启 ES 认证(如 X-Pack)、限制 Kibana 访问 IP,防止未授权访问。
ELK Stack 是企业级日志分析的"标配",从入门到精通需要不断实践------比如用它监控微服务日志、分析用户行为数据。希望本文的部署教程能帮你快速搭建起第一套 ELK 系统,后续可根据业务需求逐步优化!