背景:MoE模型的机遇和挑战
近年来,混合专家模型(Mixture of Experts,MoE) 在大型语言模型领域展现出巨大潜力。MoE架构是一种高效扩展模型规模的新技术,利用了"分而治之"的思想,设计了一系列不同的子网络(称为"专家"),通过门控网络来动态决定当前的输入应该交由哪几个专家来处理。
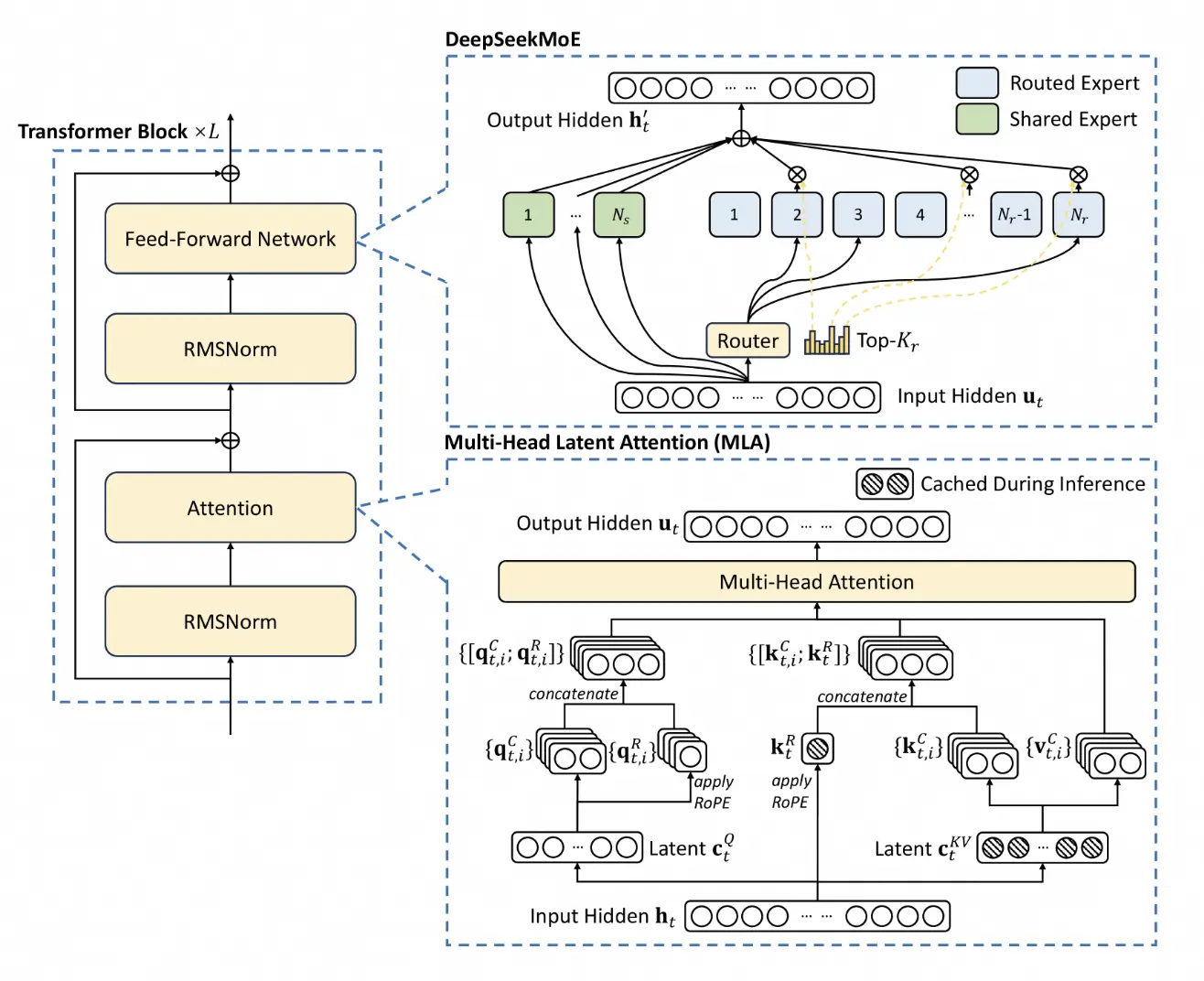
MoE最关键的特性在于"稀疏激活"。以Kimi K2模型为例,模型参数量高达1.04T,包含了384个专家网络,而每次推理仅激活8+1个专家。这意味着模型的总参数量巨大,但激活参数仅有32.6B。
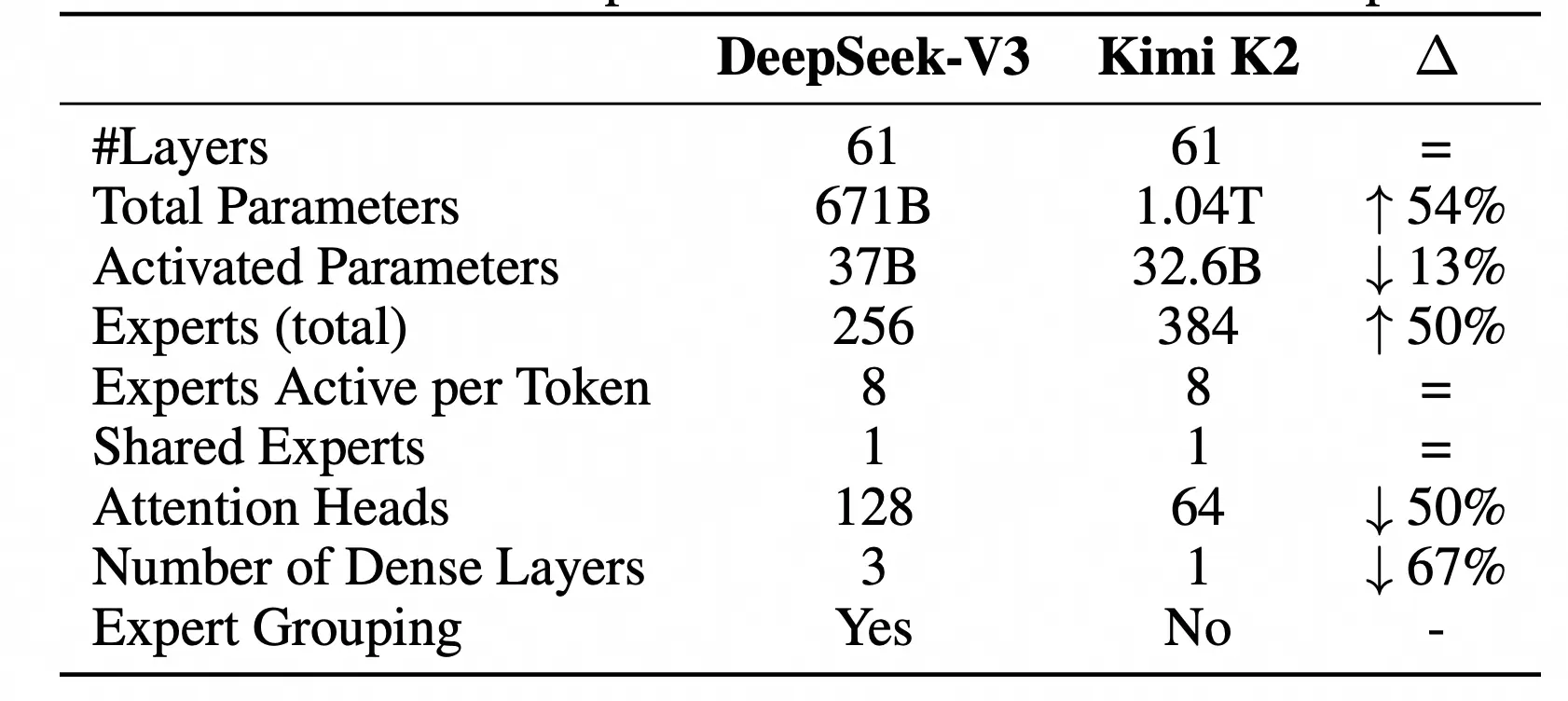
"稀疏激活"的特性使得MoE模型能够在参数规模达到万亿级别的同时,大幅降低计算和训练成本。不过,MoE模型对推理系统提出了前所未有的新挑战。传统的Tensor Parallelism(张量并行)或Pipeline Parallelism(流水线并行)方案在部署MoE模型时面临显著瓶颈,存在资源利用率低、通信开销大、成本高昂等问题。
专家并行EP:MoE模型的最佳拍档
专家并行(Expert Parallelism, EP) 是一种专门为MoE架构设计的分布式推理策略。传统方案是将所有专家都复制到每张GPU上,导致显存成为最大瓶颈。
而专家并行将不同的专家分布式部署到跨机多卡上。当请求到来时,路由门控网络动态决策该请求应该由哪几个专家处理,系统则仅将请求动态路由到对应的专家设备上,并将结果汇总返回。
这种设计带来了三大核心优势:
- 极致显存优化:彻底打破了单卡显存对模型规模的限制,使得千亿、万亿参数的MoE模型在有限显存的GPU集群上部署成为可能。
- 超高性能表现:每个专家都独立运行在自己的设备上,可独立利用单卡显存带宽,实现了真正的计算并行化,大幅提升了吞吐量。
- 显著成本降低:无需为每个设备加载全部模型参数,极大地提高了硬件资源利用率,从而降低了总体拥有成本(TCO)。
阿里云PAI-EAS:开箱即用的企业级EP解决方案
阿里云人工智能平台PAI的模型在线服务(EAS) 提供了生产级EP的部署支持,将**PD分离、大规模EP、计算-通信协同优化、MTP**等技术融为一体,形成多维度联合优化的新范式。
我们的核心能力有:
EP定制化部署和管理
- 客户部署MoE模型的首要挑战是如何科学地配置服务。PAI-EAS为主流的MoE模型提供了EP部署模版 ,内置了镜像、可选资源、运行命令等,将复杂的分布式部署过程简化为一键点击。客户无需关注复杂的底层实现,即可轻松享受EP技术带来的红利。
- PD分离中包含Prefill、Decode和LLM智能路由等多个子服务,PAI-EAS实现了聚合服务管理,支持对每个子服务进行独立的生命周期管理,包括查看日志和监控、自动扩缩容等。
- 平台提供了LLM服务自动压测功能,客户可以根据实际业务的流量形态(如输入输出长度等),来模拟压测性能表现,从而更加高效地调整Prefill和Decode的配比关系。
智能资源调度与编排
- 平台提供了优化版EPLB,既解决了"稀疏激活"带来的负载不均衡问题,同时显著降低了专家迁移重排时的额外开销,实现TPOT指标无卡顿。
- **LLM智能路由**实现了大规模集群的智能调度,支持高效的PD分离调度,保证后端实例处理的算力和显存尽可能均匀,提升集群资源使用水位。
企业级稳定性保障
- PAI-EAS提供了深度的服务监控体系,包括完善的GPU监控指标,网络与IO性能监控和健康状态监控(实时监控掉卡、Xid错误、驱动挂起等)。
- PAI-EAS的**算力健康检查**功能,会对参与推理的资源进行全面检测,自动隔离故障节点,并触发后台自动化运维流程,有效减少服务推理初期遇到问题的可能性,提升推理部署成功率。
- PAI-EAS有强大的**自愈与容错机制**,当进程崩溃导致实例不可用时,系统会自动检测并重启恢复。当发生硬件故障时,系统自动完成故障节点更换,EAS服务层自动重启实例,实现跨层联动的高可用保障。
灵活的生命周期管理
- PAI提供了灵活的扩缩容策略,Prefill和Decode服务可独立进行实例数调整和资源配置变更。用户可根据流量特征动态调整PD配比,实现极致的成本优化与性能平衡。
- EP一体化服务(含智能路由、Prefill、Decode),支持整体服务的**灰度发布**和流量调配,保障大型更新平稳上线。
动手实践:部署和使用DeepSeek-R1 EP服务
部署EP服务
- 打开PAI控制台(pai.console.aliyun.com/),点击左侧菜单栏「模型在线服务(EAS)」。点击「部署服务」,选择「LLM大语言模型部署」。
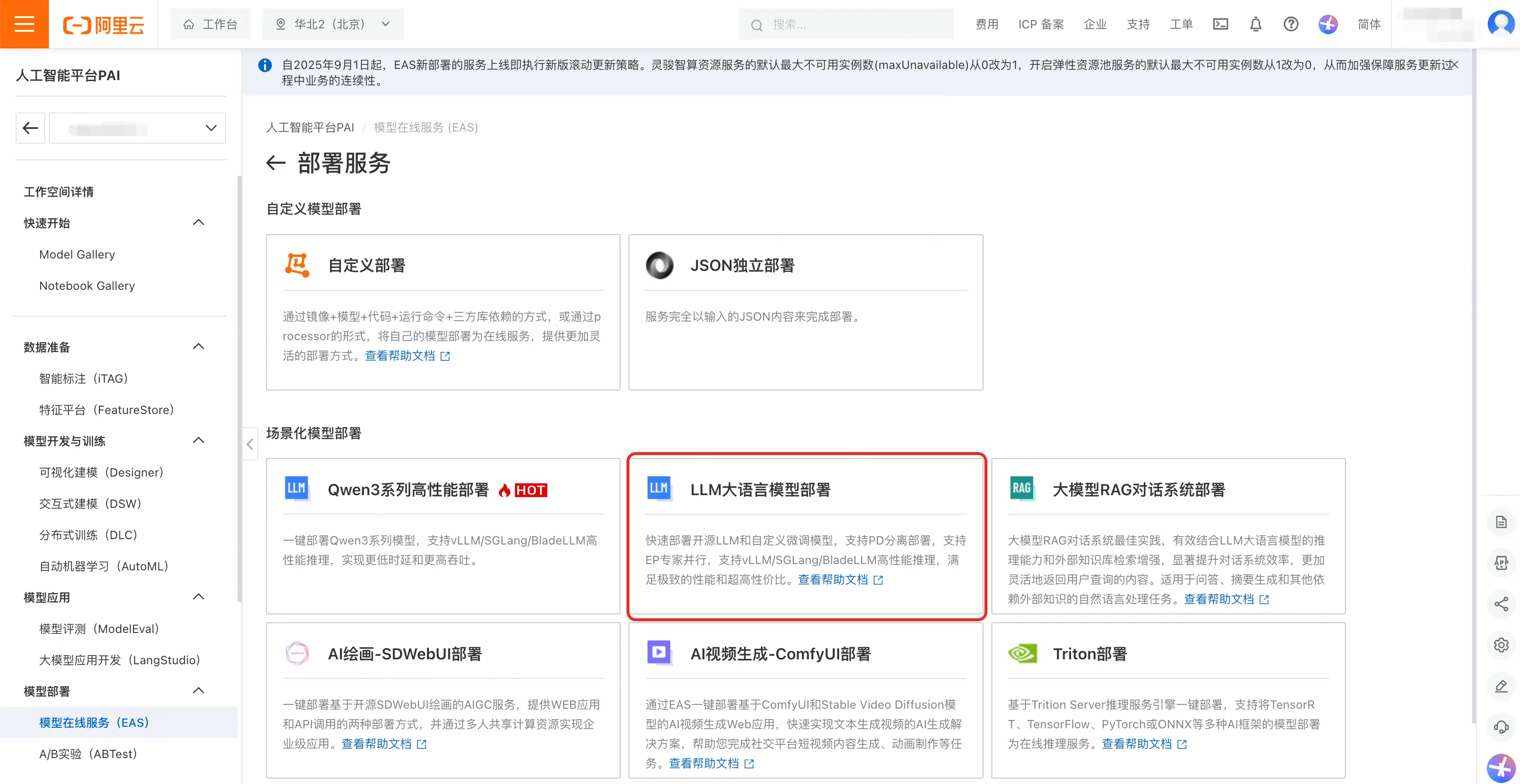
- 以DeepSeek为例,选择DeepSeek-R1-0528-PAI-optimized。该模型是PAI优化版模型,能够支持更高的吞吐和更低的时延。
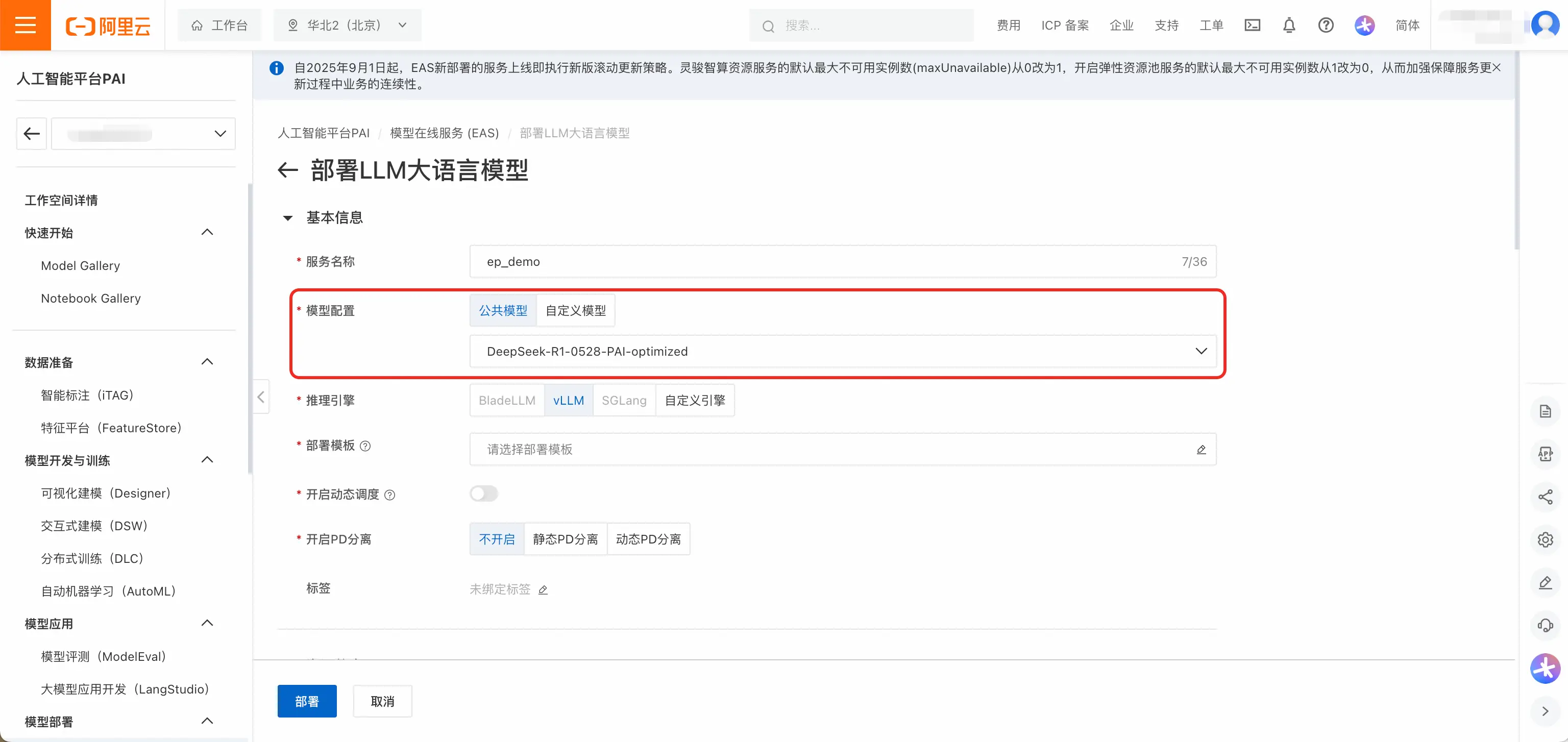
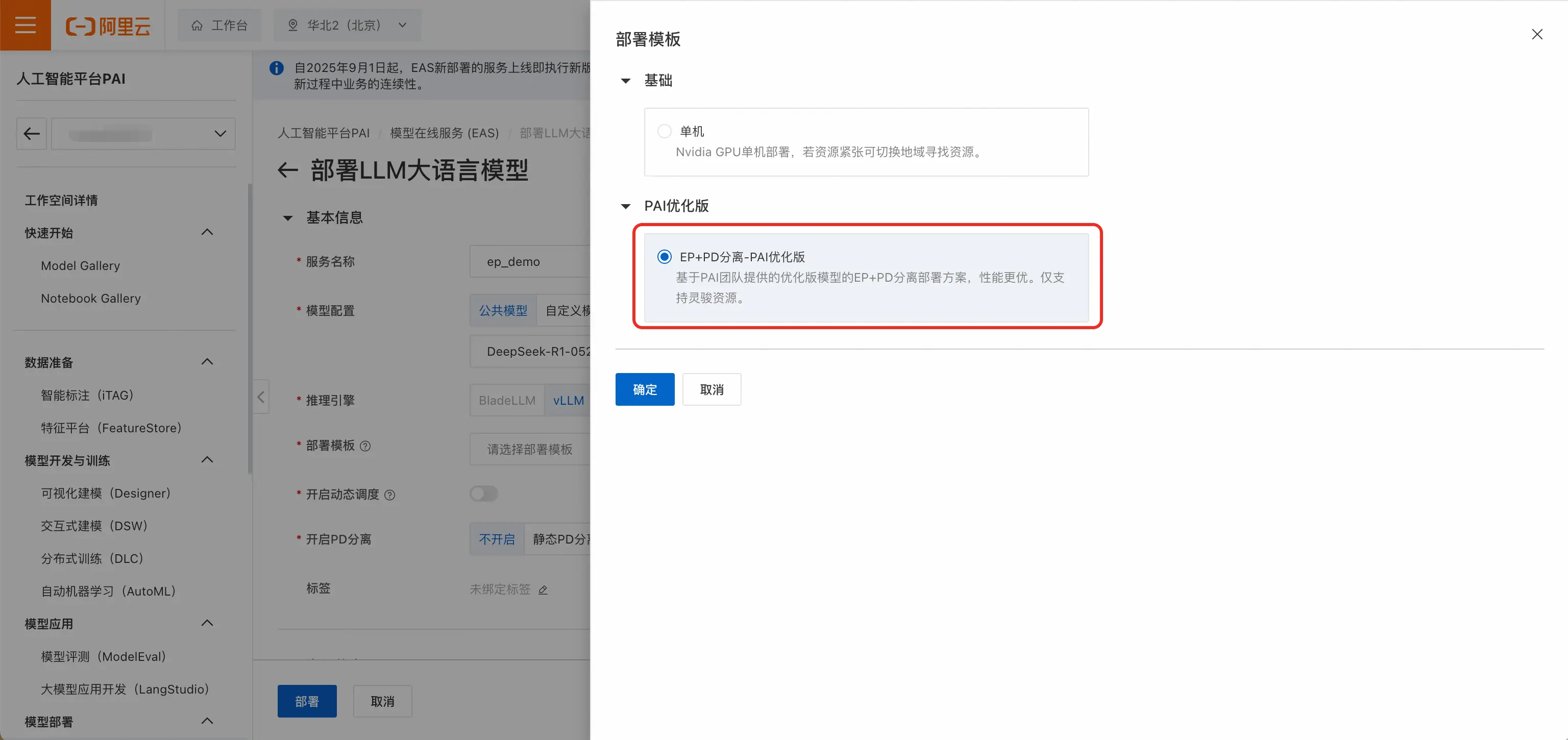
- 推理引擎选择vLLM,部署模版选择EP+PD分离-PAI优化版 。
- 接下来需要为Prefill和Decode配置部署资源,可以使用「公共资源」或者「资源配额」。公共资源的可用规格有「ml.gu8tea.8.48xlarge」或「ml.gu8tef.8.46xlarge」。
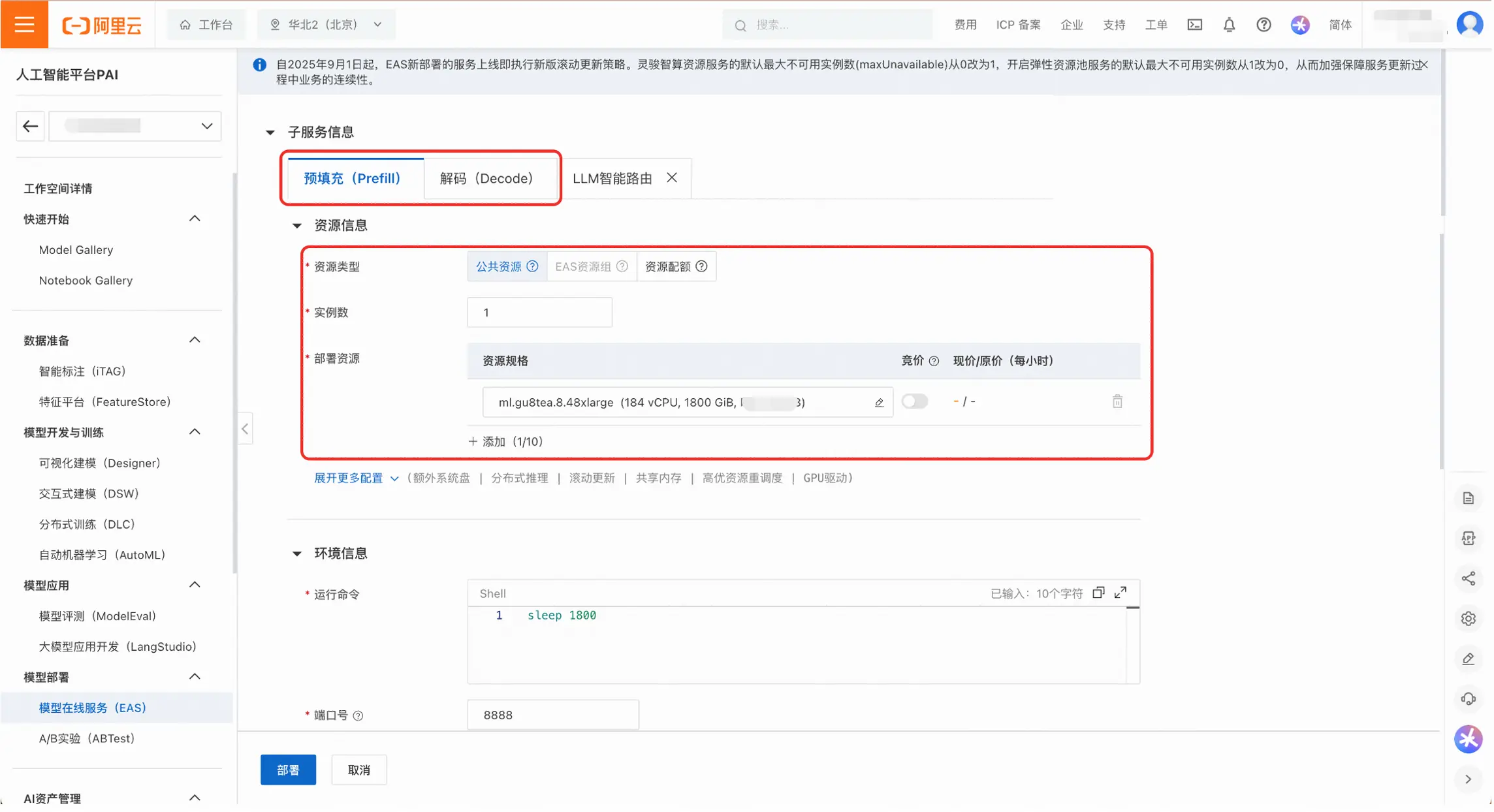
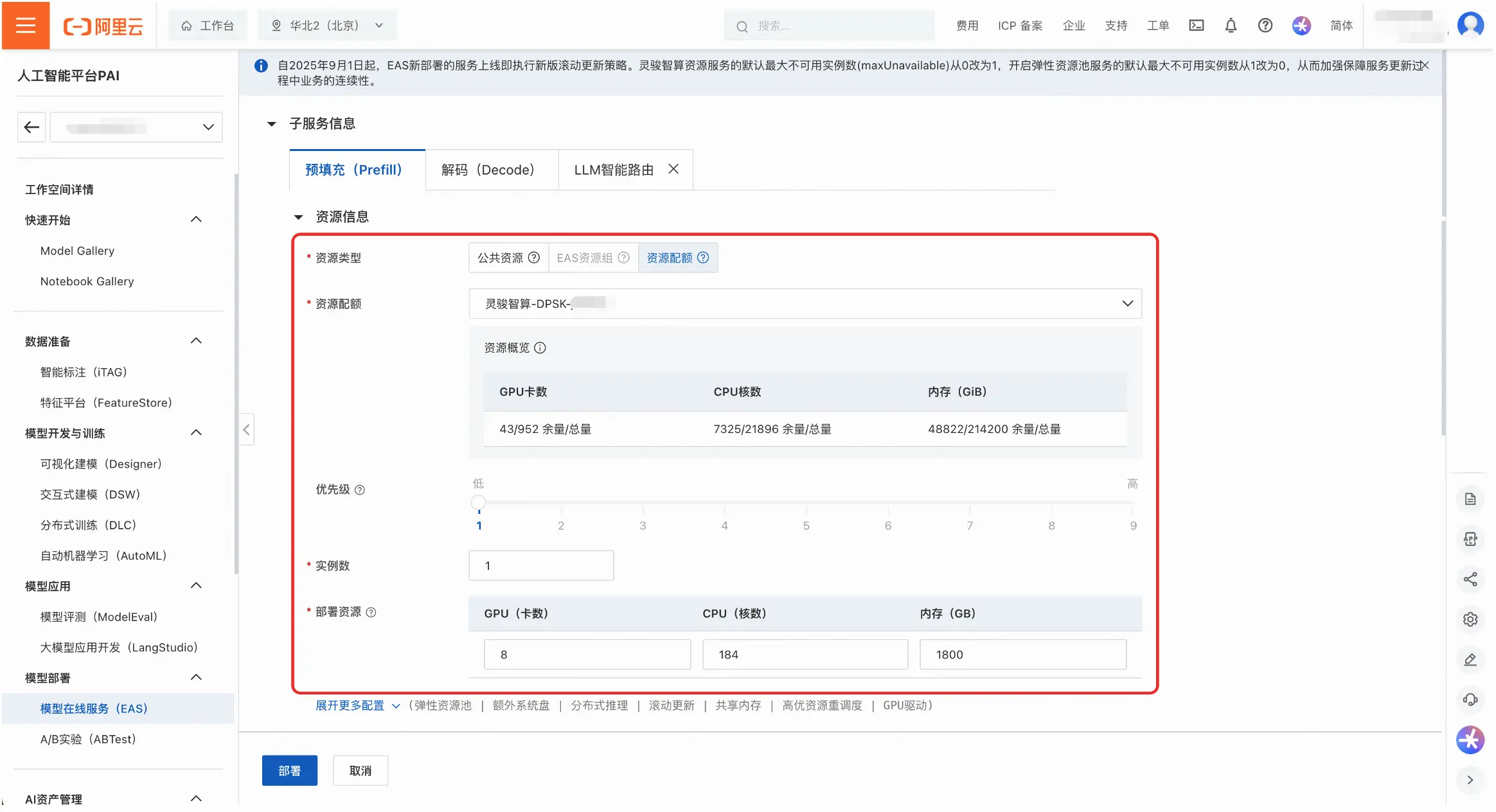
- 用户可以根据实际情况**调整部署参数;",以达到更佳的服务性能。如果无需调整,可以跳过这一步。
- 通过设置Prefill和Decode的实例数,可以调整PD分离的实际配比。部署模版中实例数的默认设置为1。
- 用户可以在环境变量中调整Prefill和Decode的EP_SIZE DP_SIZE 和TP_SIZE。部署模版中的默认值为:Prefill的TP_SIZE为8,Decode的EP_SIZE和DP_SIZE为8。
说明:为了保护「DeepSeek-R1-0528-PAI-optimized」的模型权重,平台未透出推理引擎的运行命令,用户可以通过环境变量修改重要参数。
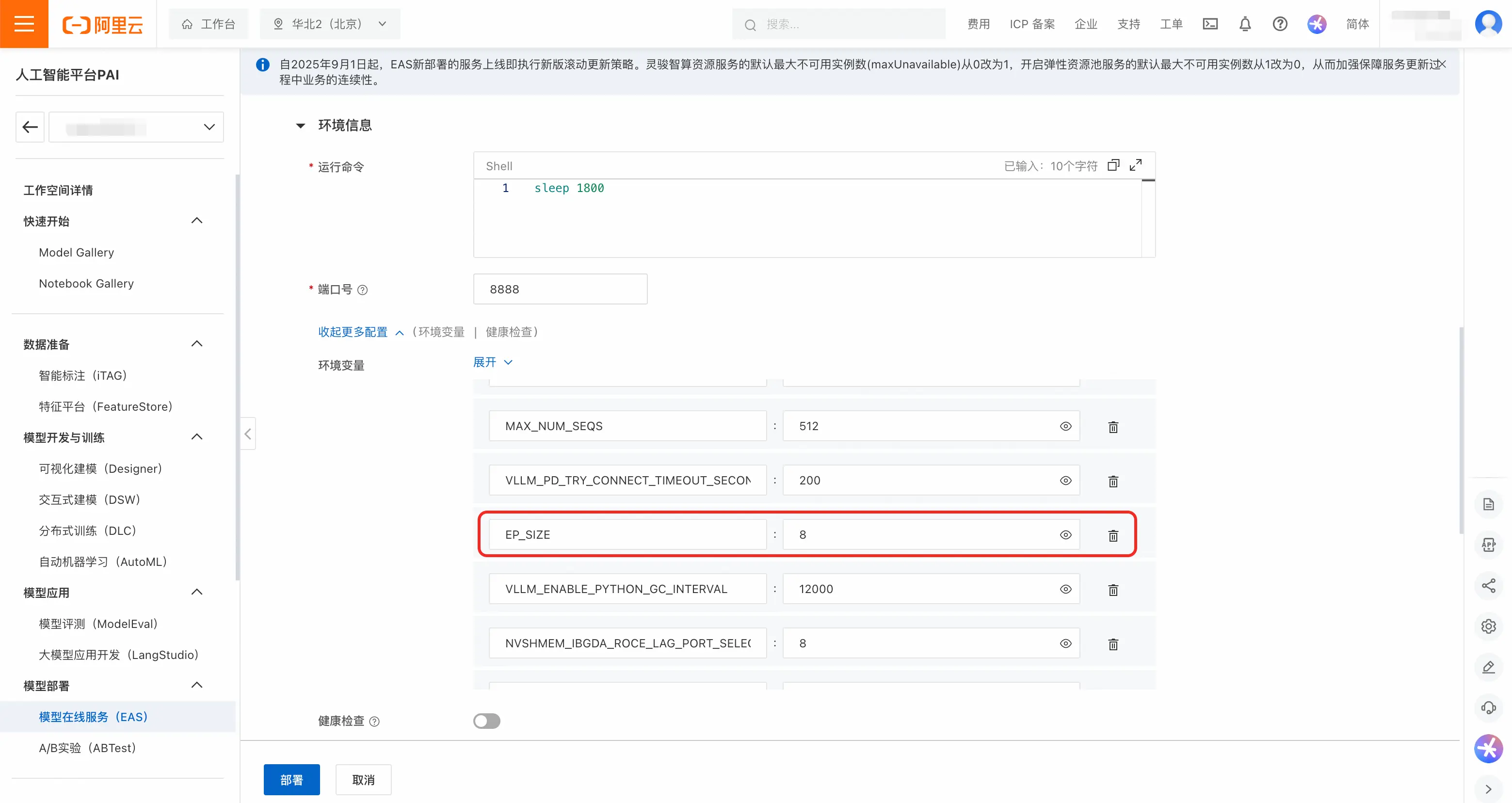
- 点击「部署」,等待约20分钟,EP服务即可成功运行。
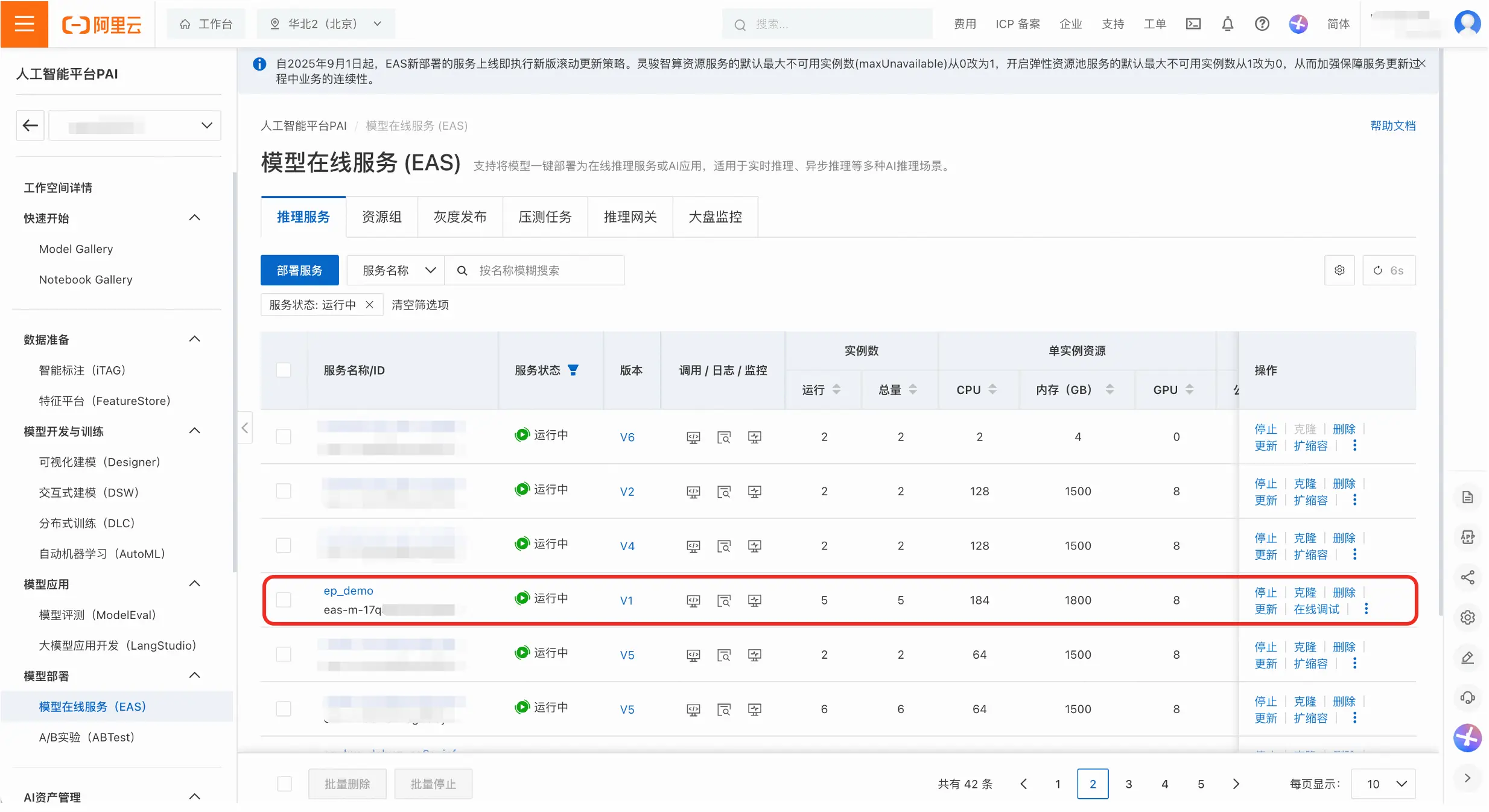
管理EP服务
- 在服务列表页,点击服务名称进入详情页,可以对服务进行精细化管理。查看维度既包含整体服务(即聚合服务),也包含Prefill、Decode和LLM智能路由等子服务。
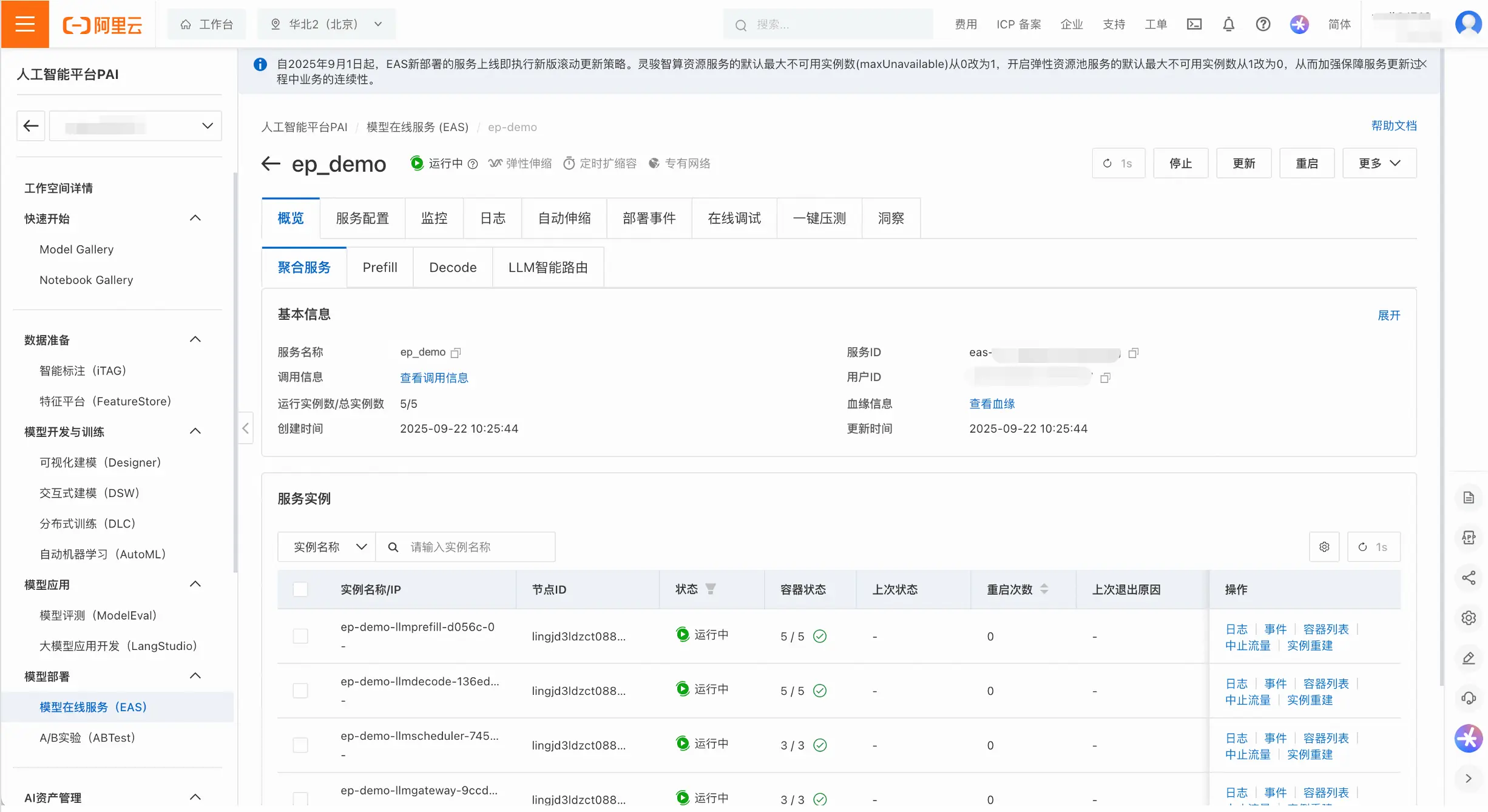
- 用户可以查看服务的监控和日志,以及配置自动伸缩策略。
- 用户可以**「在线调试」**页面快速测试服务是否正常运行。以下提供了一个示例:url后拼接
/v1/chat/completions,请求体为:
json
{
"model": "",
"messages": [
{
"role": "user",
"content": "Hello!"
}
],
"max_tokens": 1024
}点击「发送请求」,可以看到响应结果为200,模型成功输出回答,表示服务正常运行。
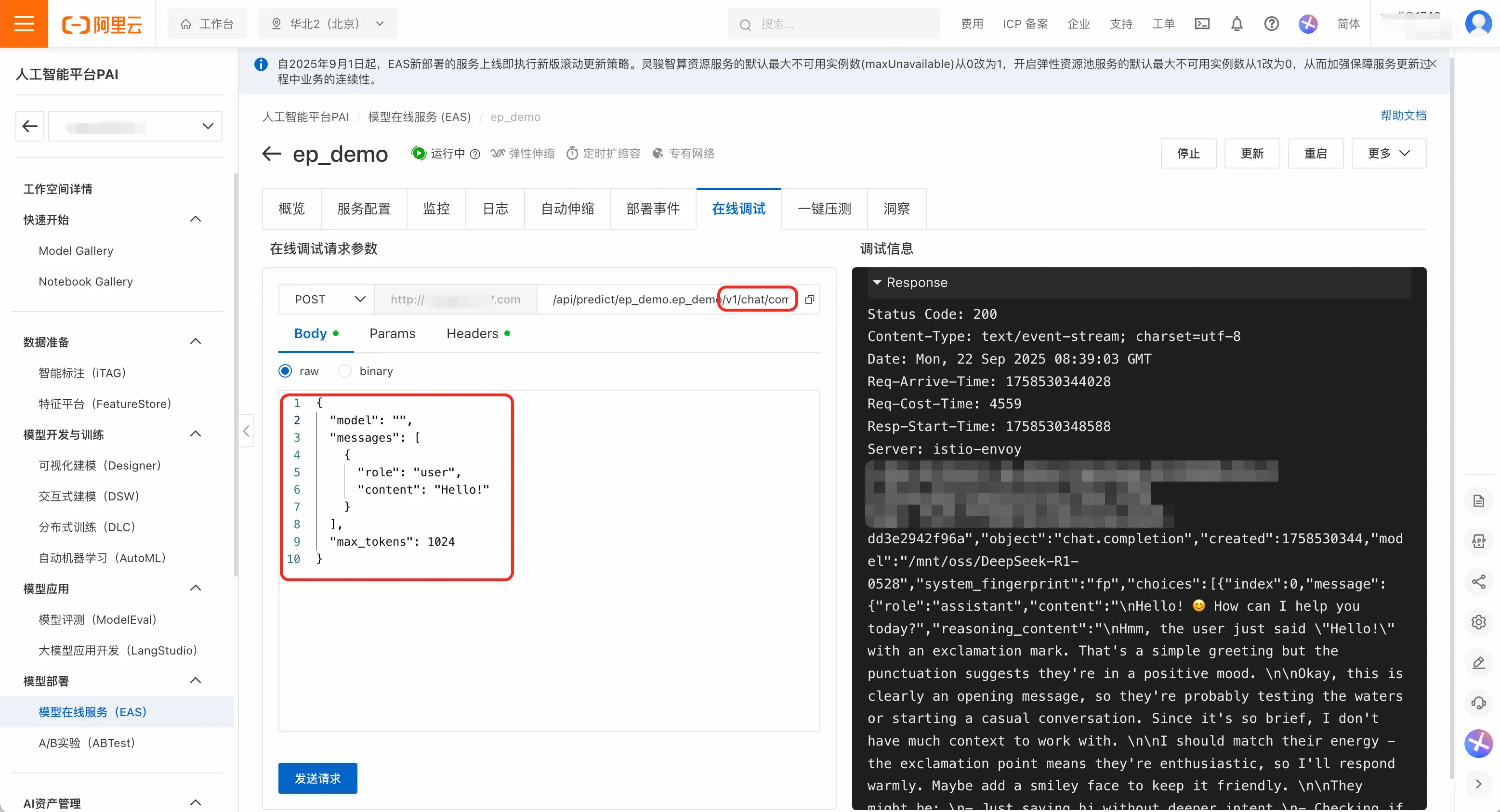
推理EP服务
- 在服务列表页或者服务详情页点击**「查看调用信息」**,右侧会显示调用地址和token。根据实际情况,用户可以选择公网调用或者VPC调用。
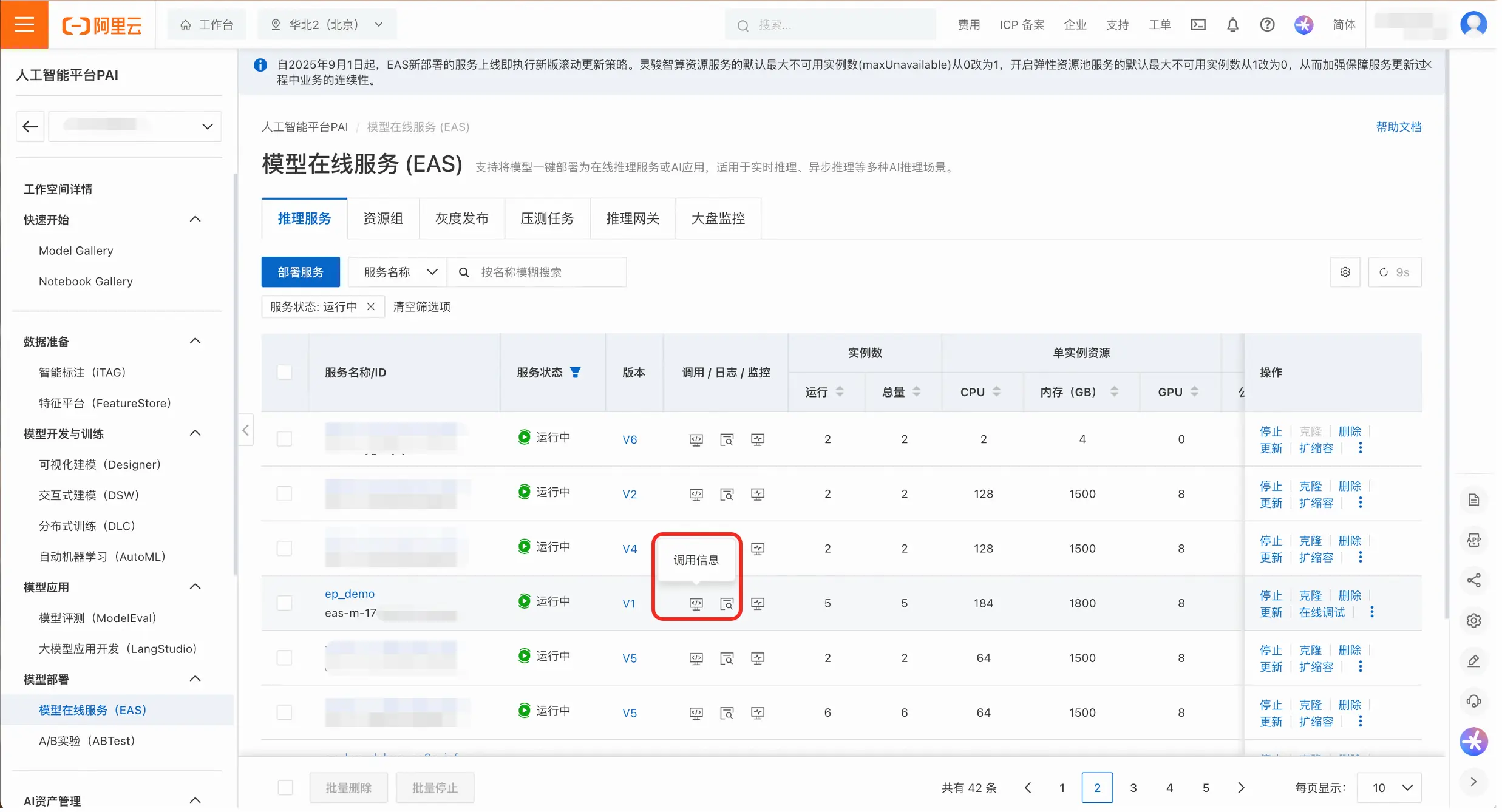
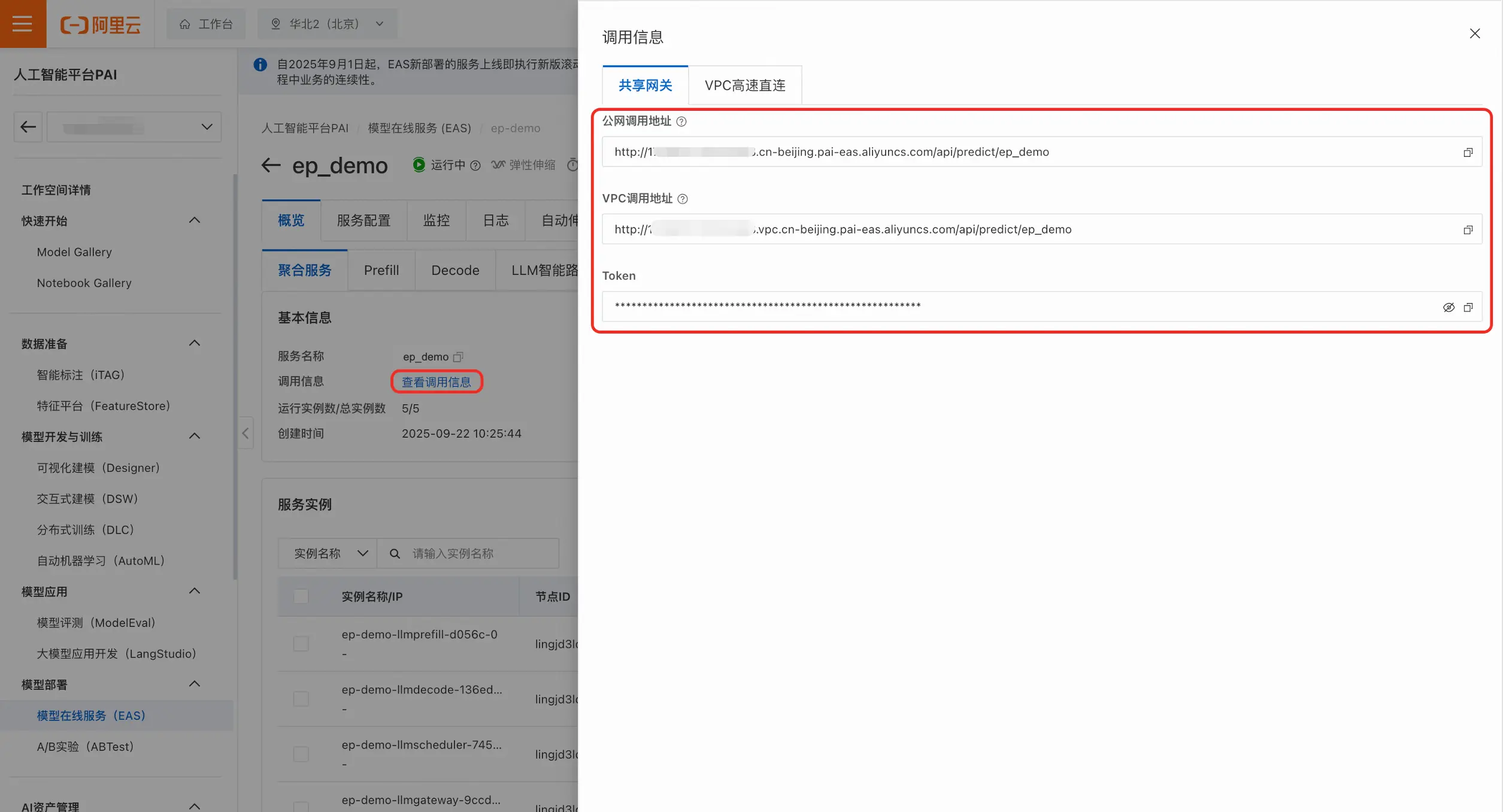
- 将调用地址和token填入到请求中。这里提供了curl和python两种示例代码:
curl:
shell
curl -X POST <EAS_ENDPOINT>/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: <EAS_TOKEN>" \
-d '{
"model": "<model_name>",
"messages": [
{"role": "system", "content": "You are a helpful and harmless assistant."},
{
"role": "user",
"content": [
{
"type": "text",
"text": "hello"
}
]
}
]
}'python:
shell
import json
import requests
# <EAS_ENDPOINT>需替换为部署服务的访问地址,<EAS_TOKEN>需替换为部署服务的Token。
EAS_ENDPOINT = "<EAS_ENDPOINT>"
EAS_TOKEN = "<EAS_TOKEN>"
url = f"{EAS_ENDPOINT}/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": EAS_TOKEN,
}
# <model_name>请替换为模型列表接口<EAS_ENDPOINT>/v1/models获取的模型名称。
model = "<model_name>"
stream = True
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "hello"},
]
req = {
"messages": messages,
"stream": stream,
"temperature": 0.0,
"top_p": 0.5,
"top_k": 10,
"max_tokens": 300,
"model": model,
}
response = requests.post(
url,
json=req,
headers=headers,
stream=stream,
)
if stream:
for chunk in response.iter_lines(chunk_size=8192, decode_unicode=False):
msg = chunk.decode("utf-8")
if msg.startswith("data"):
info = msg[6:]
if info == "[DONE]":
break
else:
resp = json.loads(info)
print(resp["choices"][0]["delta"]["content"], end="", flush=True)
else:
resp = json.loads(response.text)
print(resp["choices"][0]["message"]["content"])- 确认服务响应符合预期后,即可部署代码,将服务无缝接入到核心业务流程中。
立即体验DeepSeek-R1 EP部署 登录PAI控制台,开启您的千亿模型高效部署之旅。