
🔥小陈又菜:个人主页
📖个人专栏:《MySQL:菜鸟教程》《小陈的C++之旅》《Java基础》
✨️想多了都是问题,做多了都是答案!

目录
[1. 数组模板实例和非类型模板参数](#1. 数组模板实例和非类型模板参数)
[2. 模板的特化](#2. 模板的特化)
[2.1. 什么是模板特化?](#2.1. 什么是模板特化?)
[2.2. 函数模板特化](#2.2. 函数模板特化)
[2.3. 类模板特化](#2.3. 类模板特化)
[2.3.1. 全特化](#2.3.1. 全特化)
[2.3.2. 偏特化](#2.3.2. 偏特化)
[3. 模板分离编译](#3. 模板分离编译)
[3.1. 什么是分离编译](#3.1. 什么是分离编译)
[3.2. 模板的分离编译](#3.2. 模板的分离编译)
[4. 模板总结](#4. 模板总结)
本篇内容主要包括非典型模板参数、类模板的特化、模板的分离编译。对于C++模板还不是很了解的小伙伴可以先看一下这篇文章:《C++模板:让你的代码更通用更优雅》
1. 数组模板实例和非类型模板参数
模板经常作为容器类,因为类型参数的概念就很适合将相同的储存方案用于不同种数据类型。
这一通过一个简单的,能够指定大小的数组模板来进行说明。有两种方式来实现这个数组模板:
- 在模板类中使用动态数组,通过构造函数传入参数来提供元素数量
- 通过模板参数来提供元素数量大小(数组大小)
C++新增的array采用的就是第二种方法:
// 定义一个模板类型的静态数组
template<class T, size_t N = 10>
class array
{
public:
T& operator[](size_t index) { return _array[index]; }
const T& operator[](size_t index)const { return _array[index]; }
size_t size()const { return _size; }
bool empty()const { return 0 == _size; }
private:
T _array[N];
size_t _size;
};我们可以看到上面的代码中,class关键字(或者是等价的typename)指定T是类型参数,但是后面的size_t指定N是一个无符号整数。这种参数(指定了数据类型而不是使用泛型名称)就叫做非类型参数(nontype)或者是表达式参数。
表达式参数的限制:
- 可以是整型,枚举,引用或指针(所以Double是不被允许的,但是Double*是被允许的)
- 模板代码不能修改表达式参数的值,也不能使用它的地址(所以不能出现N++、&N等)
- 在实例化参数模板时,作为表达式参数的值必须是常量参数
表达式参数的优点:
与前面提到的第一中使用构造函数相比,构造函数使用的是new和delete来管理堆内存,这种方法操作消耗大、容易造成内存碎片化、内存泄漏。与之相比,表达式参数的方法使用的是栈内存,这种方法无疑更快,尤其是在处理大量小型数组的时候。
表达式参数的缺点:
使用表达式参数,当模板实例化的时候会为每一个不同的N生成一个类(一份代码):
template<class T, size_t N>
class Array {
T data[N];
};
// 不同的N值会产生不同的类
Array<int, 5> arr5; // 生成 Array<int, 5> 类
Array<int, 10> arr10; // 生成 Array<int, 10> 类
// 编译器实际生成的代码:
class Array_int_5 { // Array<int, 5> 的特化
int data[5];
};
class Array_int_10 { // Array<int, 10> 的特化
int data[10];
};这样的后果就是:
- 代码膨胀
- 编译时间增加
- 二进制文件体积增大
而相比之下,使用构造函数的方法(动态数组)就显得更加灵活。
2. 模板的特化
2.1. 什么是模板特化?
我们知道,模板的使用就是为了代码的复用率更高,也就是说写一些与数据类型无关的代码,单是不能避免的是,对于一些特殊的类型就可能会得到一下错误的结果,我们通过一个例子来进行说明:
template<class T>
bool Less(T left, T right)
{
return left < right;
}
int main()
{
cout << Less(1, 2) << endl;//可以比较
return 0;
}运行结果:
除了内置类型,自定义类型也是可以通过模板来进行比较,例如我们之前实现的Date日期类:
但是我们来看一下下面这段代码还能够输出正确的结果吗?
Date d1(2025, 9, 21);
Date d2(2025, 9, 20);
Date* p1 = &d1;
Date* p2 = &d2;
cout << Less(p1, p2) << endl;
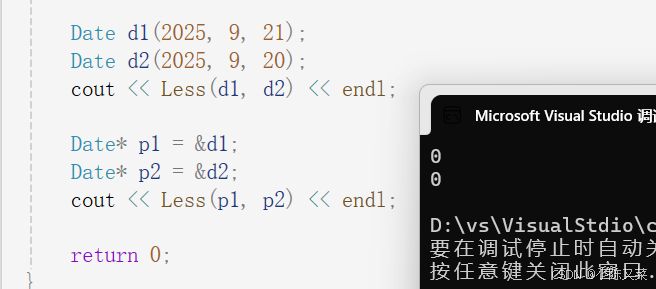
很显然它返回了一个错误的结果,因为p1指向的对象d1明显大于p2指向的对象d2,但是却依旧返回了true,这是因为传入的是p1和p2,此时比较的是两者的指针地址。
那么模板特化就有了用武之地,模板特化就是在原有的模板基础上,针对特殊的类型进行特殊化的实现方式,可分为函数模板特化、类模板特化。
2.2. 函数模板特化
函数模板特化过程:
-
必须先有一个基础模板(没有基础模板也就没有特化的对象)
-
template后面跟一个空的<>(尖括号)
template<> // 空的尖括号表示这是特化版本
void print(int value) {
cout << "int特化版本: " << value << endl;
} -
函数名后面跟一个<>尖括号指定特化的类型
void print
(int value) { // 指定特化类型
// 实现针对int的特化逻辑
} -
函数形参表必须完全相同(如果不同编译可能会报错)
// 基础模板
template
void print(T value); // 参数:T value// 正确特化 - 参数类型匹配
template<>
void print(int value); // 参数:int value ✅ // 错误特化 - 参数类型不匹配
template<>
void print(double value); // 错误!❌
我们还是那刚才的Date日期类做一个例子:
template<class T>
bool Less(T left, T right)
{
return left < right;
}
//日期类函数模板特化
template<>
bool Less<Date*>(Date* left, Date* right)
{
return *left < *right;
}
int main()
{
cout << Less(1, 2) << endl;//可以比较
Date d1(2022, 7, 7);
Date d2(2022, 7, 8);
cout << Less(d1, d2) << endl;
Date* p1 = &d1;
Date* p2 = &d2;
cout << Less(p1, p2) << endl;
return 0;
}这次我们就得到了正确的结果:
2.3. 类模板特化
2.3.1. 全特化
下面同样以Date类做一个举例:
////全特化
template<>
class Data<int, double>
{
public:
Data()
{
cout << "Date<int,double>"<<endl;
}
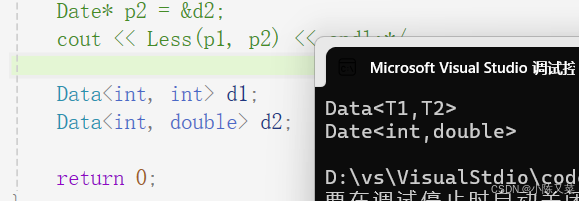
};我们发现在全特化同样是,
template<>这里要注意的几个容易混淆的点:
- 将类模板全特化之后,这个全特化的版本并不是类模板
- 并不是说类模板就不能接收int、double两种不同类型的参数,而是说我们在接收两种不同类型参数之后,我们希望有不同于原类模板的成员函数
通过全特化我就能在传入特定参数类型时,去特化函数中的相应的处理:
2.3.2. 偏特化
偏特化:是对类模板参数的进一步限制
可以将其分为两种形式:
- 将模板类型参数列表中的参数部分特化
- 将参数进行更进一步的限制
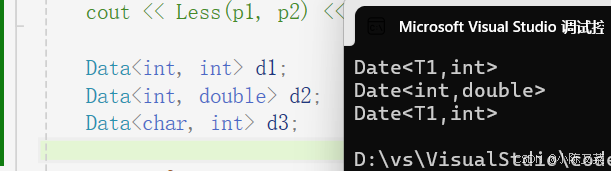
部分特化:
////半特化 第二个参数总是int类型
////1、将模板参数类表中的一部分参数特化。
template<class T1>
class Data<T1,int>
{
public:
Data()
{
cout << "Date<T1,int>"<<endl;
}
};
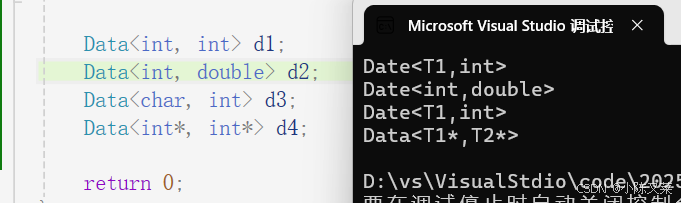
针对参数做进一步特化:
将参数偏特化为指针类型
//偏特化 参数给定了 两个指针类型 具体那种不确定
//2、偏特化并不仅仅是指特化部分参数,
// 而是针对模板参数更进一步的条件限制所设计出来的一个特化版本。
template<class T1, class T2>
class Data<T1*, T2*>
{
public:
Data()
{
cout << "Data<T1*,T2*>" << endl;
}
};
这个地方注意特化优先级的一个问题:
优先级 :全特化 > 半特化 > 默认
3. 模板分离编译
3.1. 什么是分离编译
程序是由许多个源文件组成的,编译器会将这多个源文件编译成为目标文件,然后由链接器形成单一的可执行文件,这个过程就叫做分离编译。
3.2. 模板的分离编译
在大多数情况下,模板的声明和定义是分开的,在头文件中声明,在源文件中定义:
// a.h
template<class T>
T Add(const T& left, const T& right);
// a.cpp
template<class T> T Add(const T& left, const T& right) {
return left + right;
}
// main.cpp
#include"a.h"
int main()
{
Add(1, 2);
Add(1.0, 2.0);
return 0;
}那么接下来我们来看一看根据这个步骤:预处理-->编译-->汇编-->链接 会有一些什么问题:

也就是说因为模板只有在传入了实际的类型参数之后才会生成实际的代码,那么在链接那一步的时候就会出现错误。
解决方式:
-
将声明和定义放到一个文件 "xxx.hpp" 里面或者 xxx.h 其实也是可以的 。推荐使用这种。
-
模板定义的位置显式实例化 。这种方法不实用,不推荐使用。
4. 模板总结
- 优点:
1.模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
2.增强了代码的灵活性,简化编程工作,提高程序的可靠性。
- 缺点:
1.模板会导致代码膨胀问题,也会导致编译时间变长
2.出现模板编译错误时,错误信息非常凌乱,不易定位错误
(本篇完)