学习目标:
springboot的分页功能TableDataInfo,有时候需要复杂的分页实现,怎么办呢?
简单的分页功能的实现:
java
/**
* 查询水库闸门矩阵信息列表
*/
@ApiOperation("查询水库闸门矩阵信息列表")
@GetMapping("/list")
public TableDataInfo list(ModelEngineeringRelSectionZamenMatrix modelEngineeringRelSectionZamenMatrix)
{
startPage();
List<ModelEngineeringRelSectionZamenMatrix> list = modelEngineeringRelSectionZamenMatrixService.selectModelEngineeringRelSectionZamenMatrixList(modelEngineeringRelSectionZamenMatrix);
return getDataTable(list);
}重点:startPage()只对紧随其后的第一个查询有效。当其后面是一系列复杂的查询的时候,那么分页功能就失效了。
但是,在实际工作中,我们难免会有很复杂的逻辑查询,比如切换不同的数据源进行数据的查询,查询之后,再进行数据的组装。这时候就需要我们自己是实现数据的组装,之后再按照TableDataInfo的格式返回正确的数据。
学习内容:
示例代码:
1.Controller层代码:
java
/**
* 预报:查询累积降水量列表
*/
@ApiOperation("查询累积降水量列表")
@GetMapping("/rainfallSumListByForecastByPage")
public TableDataInfo rainfallSumListByForecastByPage(StPptnRForecast stPptnRForecast)
{
// 获取分页参数
PageDomain pageDomain = TableSupport.buildPageRequest();
//查询用户信息
LoginUser loginUser = tokenService.getLoginUser();
/** edit by helj 20250317 添加第三方数据源判断 **/
/*** 是否使用第三方数据源forecast_data_source*/
String forecastDataSource = "false";
if(loginUser != null ){
if(loginUser.getForecastDataSource() != null && !loginUser.getForecastDataSource().equals("")){
forecastDataSource = loginUser.getForecastDataSource();
}
}
//查询降雨量数据
List<StPptnRWithSumDrp> list = new ArrayList<>();
if(stPptnRForecast.getParams().get("beginTm") != null && !stPptnRForecast.getParams().get("beginTm").equals("")
&& stPptnRForecast.getParams().get("endTm") != null && !stPptnRForecast.getParams().get("endTm").equals("")
&& stPptnRForecast.getPubtime() != null && !stPptnRForecast.getPubtime().equals("")
&& stPptnRForecast.getRainBindingType() != null
&& ((stPptnRForecast.getBasinCode() != null && !stPptnRForecast.getBasinCode().equals(""))
|| (stPptnRForecast.getRegionCode() != null && !stPptnRForecast.getRegionCode().equals("")))){
if(stPptnRForecast.getParams().get("isStartPage") != null && Boolean.parseBoolean(stPptnRForecast.getParams().get("isStartPage").toString())){
if (StringUtils.isNotBlank(forecastDataSource) && forecastDataSource.equals("true")) {
//预报第三方数据源
list = selectRainfallSumListByForecastTrdDataSource(stPptnRForecast, true);
//是否分页-内存分页
if(list.size() > 0){
int total = list.size();
List<StPptnRWithSumDrp> pageList = handleMemoryPagination(list, pageDomain);
//自定义一个TableDataInfo返回给前端
TableDataInfo tableDataInfo = new TableDataInfo();
tableDataInfo.setCode(200);
tableDataInfo.setMsg("查询成功");
tableDataInfo.setRows(pageList);
tableDataInfo.setTotal(total);
return tableDataInfo;
} else {
// 无数据情况
TableDataInfo tableDataInfo = new TableDataInfo();
tableDataInfo.setCode(200);
tableDataInfo.setMsg("查询成功,无数据");
tableDataInfo.setRows(new ArrayList<>());
tableDataInfo.setTotal(0);
return tableDataInfo;
}
}else{
list = stPptnRForecastService.selectRainfallSumListByForecast(stPptnRForecast, true);
}
}
}
return getDataTable(list);
}重点:自己实现内存分页处理
java
/**
* 内存分页处理
*/
private List<StPptnRWithSumDrp> handleMemoryPagination(List<StPptnRWithSumDrp> allList, PageDomain pageDomain) {
int pageNum = pageDomain.getPageNum();
int pageSize = pageDomain.getPageSize();
// 计算分页范围
int startIndex = (pageNum - 1) * pageSize;
if (startIndex >= allList.size()) {
return new ArrayList<>();
}
int endIndex = Math.min(startIndex + pageSize, allList.size());
return allList.subList(startIndex, endIndex);
}学习产出:
1.内存分页处理实现
2.如果 TableDataInfo 需要更多参数
如果您的 TableDataInfo 类需要更多分页信息,可以这样实现:
java
// 自定义TableDataInfo返回给前端
TableDataInfo tableDataInfo = new TableDataInfo();
tableDataInfo.setCode(HttpStatus.SUCCESS);
tableDataInfo.setMsg("查询成功");
tableDataInfo.setRows(pageList);
tableDataInfo.setTotal(total);
tableDataInfo.setPageNum(pageDomain.getPageNum()); // 当前页码
tableDataInfo.setPageSize(pageDomain.getPageSize()); // 每页大小
tableDataInfo.setPages((total + pageDomain.getPageSize() - 1) / pageDomain.getPageSize()); // 总页数
return tableDataInfo;3.两个list数据,基于相同的stcd字段,进行高效快速匹配的实现方法。
使用Map优化方案
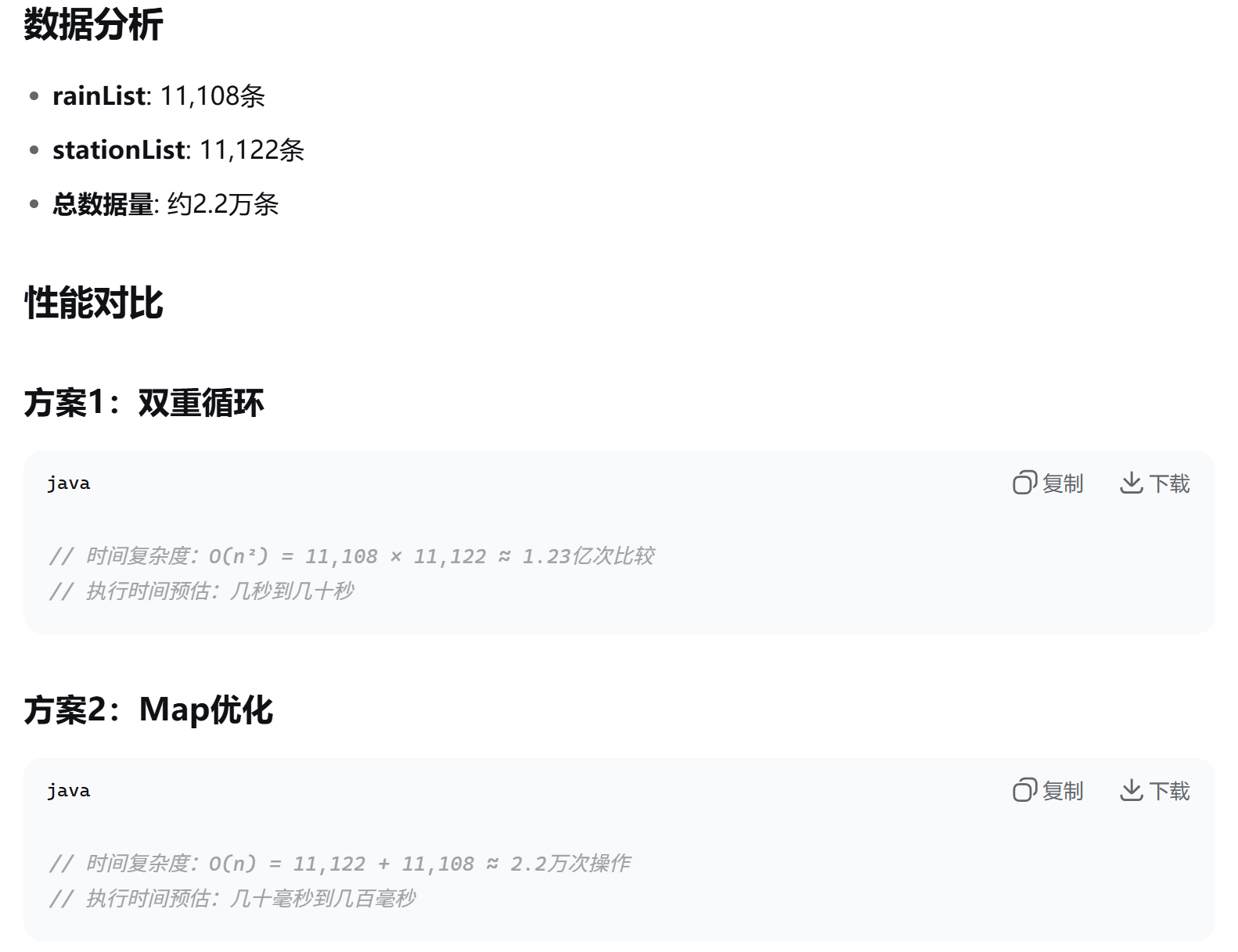
结论
坚决选择方案2(Map优化),因为:
性能差异巨大:1.23亿次 vs 2.2万次操作
用户体验:毫秒级响应 vs 可能卡顿几秒
系统资源:避免不必要的CPU和内存消耗
对于万级数据,双重循环会产生上亿次比较,这在生产环境中是不可接受的。
代码实现:
java
//数据均存在,循环数据判断stcd相等,将数据组装存储到list中
if(rainList.size() > 0 && stationList.size() > 0){
// 使用Map优化方案 - 推荐!
Map<String, StStbprpB> stationMap = stationList.stream()
.collect(Collectors.toMap(StStbprpB::getStcd, station -> station, (oldVal, newVal) -> oldVal));
for(StPptnRWithSumDrp rainData : rainList){
StStbprpB station = stationMap.get(rainData.getStcd());
if(station != null){
StPptnRWithSumDrp vo = new StPptnRWithSumDrp();
// 组装数据
vo.setStcd(rainData.getStcd());
vo.setDrp(rainData.getDrp());
vo.setLgtd(station.getLgtd());
vo.setLttd(station.getLttd());
list.add(vo);
}
}
//list按照drp降序排列
if (!list.isEmpty()) {
list.sort(Comparator.comparing(StPptnRWithSumDrp::getDrp, Comparator.reverseOrder()));
}
// 打印输出
System.out.println("数据组装完成:降雨数据" + rainList.size() + "条," + "站点数据" + stationList.size() + "条,成功组装" + list.size() + "条");