🚀 从零构建智能HTML转Markdown转换器:Python GUI开发实战
副标题: 用tkinter + BeautifulSoup4 + html2text打造专业级文档转换工具
成品截图
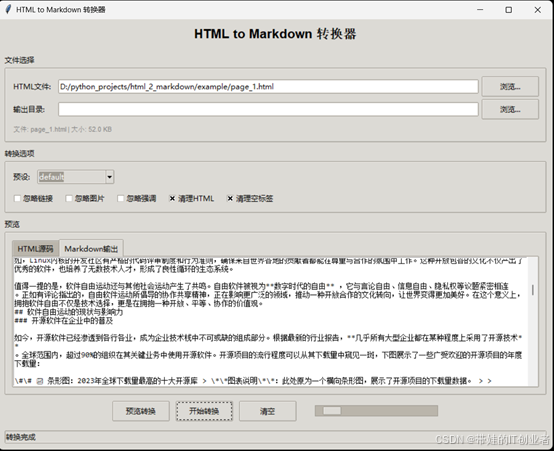
📖 项目背景
最近用了天工,天工在生成研究报告方面独树一帜,苦恼的是输出的是html文件(免费),其他格式需要消耗积分,不得已,自己开发了一个。今天,我将分享如何从零开始构建一个功能强大的HTML转Markdown转换器的完整过程。
项目亮点:
- 🎨 现代化tkinter GUI界面
- 🔍 智能HTML解析和格式识别
- 📊 复杂内容智能处理
- ⚡ 高性能批量转换
🏗️ 技术架构设计
核心技术栈
| 组件 | 选择理由 | 版本 |
|---|---|---|
| tkinter | Python内置,无需额外安装 | 3.6+ |
| BeautifulSoup4 | 强大的HTML解析能力 | 4.12.3+ |
| html2text | 专业的转换引擎 | 2024.2.26+ |
| chardet | 智能编码检测 | 最新版 |
项目结构
📁 html_2_markdown/
├── main.py # 🎨 GUI主程序
├── html_converter.py # 🔄 转换核心引擎
├── file_handler.py # 📁 文件处理模块
└── requirements.txt # 📦 依赖管理
💻 核心功能实现
1. 智能HTML解析引擎
转换器的核心是智能解析HTML内容并进行格式转换:
python
class HtmlToMarkdownConverter:
"""HTML到Markdown转换器核心类"""
def __init__(self):
self.h2t = html2text.HTML2Text()
self._setup_default_config()
def _setup_default_config(self):
"""配置转换器参数"""
self.h2t.ignore_links = False
self.h2t.ignore_images = False
self.h2t.body_width = 0 # 不限制行宽
self.h2t.unicode_snob = True # 支持中文
self.h2t.inline_links = True # 内联链接
self.h2t.ul_item_mark = '-' # 列表标记关键设计思路:
body_width = 0确保内容完整性unicode_snob = True优化中文处理- 灵活的配置系统支持不同场景
2. 特殊格式智能识别
这是项目的一大亮点 - 智能识别特殊CSS类并转换:
python
def _process_special_spans(self, soup):
"""处理特殊格式的span标签"""
# 🔆 高亮文本 → 行内代码
for span in soup.find_all('span', class_='highlight'):
span.name = 'code'
if 'class' in span.attrs:
del span.attrs['class']
# ⭐ 重要文本 → 粗体
for span in soup.find_all('span', class_='important'):
span.name = 'strong'
if 'class' in span.attrs:
del span.attrs['class']
# 📝 批量处理其他格式
special_classes = {
'emphasis': 'em',
'italic': 'em',
'bold': 'strong',
'code': 'code'
}
for class_name, tag_name in special_classes.items():
for span in soup.find_all('span', class_=class_name):
span.name = tag_name
if 'class' in span.attrs:
del span.attrs['class']转换效果对比:
原始HTML:
html
<p>这段文字包含<span class="highlight">高亮内容</span>和
<span class="important">重要信息</span>。</p>转换结果:
markdown
这段文字包含`高亮内容`和**重要信息**。3. 图表内容智能处理
对于复杂的图表内容,生成详细的占位符说明:
python
def _process_charts_and_scripts(self, soup):
"""处理图表内容,生成智能占位符"""
chart_containers = soup.find_all(['div'],
{'class': lambda x: x and 'chart' in str(x).lower()})
for container in chart_containers:
chart_id = container.get('id', 'unknown')
if 'chart1' in chart_id.lower():
placeholder = self._create_detailed_placeholder(
title="自由软件的四大核心自由",
description="展示软件自由理念的核心架构",
details=[
"**自由 0**:运行软件的自由",
"**自由 1**:研究和修改源代码的自由",
"**自由 2**:重新分发拷贝的自由",
"**自由 3**:发布改进版本的自由"
]
)
else:
placeholder = self._create_generic_placeholder(chart_id)
container.clear()
container.append(BeautifulSoup(placeholder, 'html.parser'))生成的占位符效果:
markdown
📊 交互式图表:自由软件的四大核心自由
下方图表展示了自由软件理念的核心架构,以"软件自由"为中心。
- **自由 0**:运行软件的自由
- **自由 1**:研究和修改源代码的自由
- **自由 2**:重新分发拷贝的自由
- **自由 3**:发布改进版本的自由4. 现代化GUI界面
使用tkinter构建专业的用户界面:
python
class HtmlToMarkdownApp:
def __init__(self, root):
self.root = root
self.converter = HtmlToMarkdownConverter()
self._setup_modern_ui()
def _setup_modern_ui(self):
"""设置现代化界面"""
self.root.title("HTML to Markdown 转换器")
self.root.geometry("900x700")
# 使用现代主题
style = ttk.Style()
style.theme_use('clam')
# 创建主要组件
self._create_file_selection()
self._create_options_panel()
self._create_preview_tabs()
self._create_control_buttons()
def _create_preview_tabs(self):
"""创建预览标签页"""
self.notebook = ttk.Notebook(self.preview_frame)
# HTML源码标签页
html_frame = ttk.Frame(self.notebook)
self.notebook.add(html_frame, text="HTML源码")
self.html_text = scrolledtext.ScrolledText(
html_frame, font=('Consolas', 9))
# Markdown输出标签页
md_frame = ttk.Frame(self.notebook)
self.notebook.add(md_frame, text="Markdown输出")
self.markdown_text = scrolledtext.ScrolledText(
md_frame, font=('Consolas', 9))界面特色:
- 📋 标签页式预览界面
- 🎨 现代化ttk组件
- 📝 代码编辑器风格的文本框
- ⚙️ 直观的选项配置面板
🧠 核心算法详解
空标签智能清理
空的强调标签会产生多余的Markdown标记,需要智能清理:
python
def _clean_empty_emphasis_tags(self, soup):
"""清理空的强调标签"""
emphasis_tags = ['em', 'i', 'strong', 'b', 'u', 'code']
for tag_name in emphasis_tags:
for tag in soup.find_all(tag_name):
if self._is_empty_tag(tag):
# 智能处理空格,避免单词连接
if tag.next_sibling and isinstance(tag.next_sibling, str):
replacement = ' ' if not tag.next_sibling.startswith(' ') else ''
tag.replace_with(replacement)
else:
tag.decompose()
def _is_empty_tag(self, tag) -> bool:
"""判断标签是否为空"""
text_content = tag.get_text(strip=True)
return not text_content or text_content.strip() in ['', '\n', '\t', '\r']多编码智能识别
处理不同编码的HTML文件:
python
def read_file_with_encoding_detection(self, file_path: str) -> Optional[str]:
"""智能编码检测读取"""
try:
# 读取原始字节数据
with open(file_path, 'rb') as f:
raw_data = f.read()
# 检测编码
detected = chardet.detect(raw_data)
encoding = detected['encoding']
# 使用检测到的编码读取
with open(file_path, 'r', encoding=encoding) as f:
return f.read()
except Exception as e:
# 降级处理:尝试常见编码
for encoding in ['utf-8', 'gbk', 'gb2312']:
try:
with open(file_path, 'r', encoding=encoding) as f:
return f.read()
except:
continue
return None🎯 开发中的关键挑战
挑战1:界面响应性
问题: 大文件转换时界面卡顿
解决方案: 多线程异步处理
python
def _start_conversion_async(self):
"""异步转换,避免UI卡顿"""
self.is_converting = True
self._update_ui_state()
# 后台线程执行转换
thread = threading.Thread(target=self._conversion_worker)
thread.daemon = True
thread.start()
def _conversion_worker(self):
"""转换工作线程"""
try:
success = self._perform_conversion()
# 安全更新UI
self.root.after(0, self._conversion_completed, success)
except Exception as e:
self.root.after(0, self._conversion_error, str(e))挑战2:复杂HTML结构
问题: 现实HTML文档结构复杂,包含大量无用元素
解决方案: 分层清理策略
python
def _clean_html_step_by_step(self, html_content: str) -> str:
"""分步骤清理HTML"""
soup = BeautifulSoup(html_content, 'html.parser')
# 第一步:处理特殊格式
self._process_special_spans(soup)
# 第二步:清理空标签
self._clean_empty_emphasis_tags(soup)
# 第三步:处理复杂内容
self._process_charts_and_scripts(soup)
# 第四步:移除无用元素
self._remove_unwanted_elements(soup)
return str(soup)📊 功能特性对比
| 功能特性 | 普通转换器 | 我们的转换器 | 优势 |
|---|---|---|---|
| 特殊格式识别 | ❌ | ✅ | 智能CSS类转换 |
| 图表处理 | ❌ | ✅ | 生成详细说明 |
| 内部链接 | 部分 | ✅ | 完美锚点支持 |
| 编码检测 | 基础 | ✅ | 智能多编码识别 |
| 实时预览 | ❌ | ✅ | 所见即所得 |
| 空标签清理 | ❌ | ✅ | 避免冗余标记 |
🎓 技术要点总结
Python GUI开发技巧
- 现代化界面设计:使用ttk组件和现代主题
- 响应式布局:合理使用grid和pack布局管理器
- 多线程编程:防止长时间操作阻塞UI
- 事件驱动设计:优雅的用户交互处理
HTML处理技术
- BeautifulSoup4高级用法:DOM树操作和元素查找
- 智能内容识别:基于CSS类的格式转换
- 编码处理:多编码自动检测和转换
- 性能优化:大文件的分块处理
软件工程实践
- 模块化设计:清晰的职责分离
- 错误处理:完善的异常捕获机制
- 用户体验:友好的进度提示和错误反馈
- 可扩展性:支持新格式和功能的架构设计
🚀 项目扩展方向
短期优化
- 🎨 添加深色主题支持
- ⚡ 缓存机制优化性能
- 📊 更多图表类型支持
- 🔧 自定义转换规则
长期发展
- 🌐 Web版本开发
- 📱 移动端适配
- 🤖 AI内容理解
- ☁️ 云端协作功能
💡 关键收获
通过这个项目,我们不仅构建了一个实用的工具,更重要的是掌握了:
- 系统性思考:从需求分析到架构设计的完整流程
- 技术整合:多个Python库的协同使用
- 用户体验:GUI应用的人性化设计
- 性能优化:大数据量处理的优化策略
这个HTML转Markdown转换器展示了Python在桌面应用开发中的强大能力。通过合理的架构设计和技术选择,我们可以用相对简单的代码实现复杂而实用的功能。
完整源码已开源,欢迎Star和贡献! 🌟
"""
HTML to Markdown 转换器 - 主应用程序
基于tkinter的图形用户界面
"""
import tkinter as tk
from tkinter import ttk, filedialog, messagebox, scrolledtext
import os
import sys
import threading
from pathlib import Path
from typing import Optional, Dict, Any
# 导入自定义模块
try:
from html_converter import HtmlToMarkdownConverter
from file_handler import FileHandler
except ImportError as e:
print(f"导入模块失败:{e}")
print("请先安装依赖:pip install -r requirements.txt")
sys.exit(1)
class HtmlToMarkdownApp:
"""HTML到Markdown转换器主应用类"""
def __init__(self, root):
"""初始化应用"""
self.root = root
self.converter = HtmlToMarkdownConverter()
self.file_handler = FileHandler()
# 应用状态
self.current_html_file = ""
self.current_output_dir = ""
self.is_converting = False
self._setup_window()
self._create_widgets()
self._bind_events()
def _setup_window(self):
"""设置主窗口"""
self.root.title("HTML to Markdown 转换器")
self.root.geometry("900x700")
self.root.minsize(800, 600)
# 设置窗口图标(如果有的话)
try:
# self.root.iconbitmap("icon.ico")
pass
except:
pass
# 配置样式
style = ttk.Style()
style.theme_use('clam')
def _create_widgets(self):
"""创建界面组件"""
# 创建主框架
main_frame = ttk.Frame(self.root, padding="10")
main_frame.grid(row=0, column=0, sticky="nsew")
# 配置权重
self.root.columnconfigure(0, weight=1)
self.root.rowconfigure(0, weight=1)
main_frame.columnconfigure(1, weight=1)
# 标题
title_label = ttk.Label(main_frame, text="HTML to Markdown 转换器",
font=('Arial', 16, 'bold'))
title_label.grid(row=0, column=0, columnspan=3, pady=(0, 20))
# 文件选择区域
self._create_file_selection_area(main_frame)
# 转换选项区域
self._create_conversion_options_area(main_frame)
# 预览区域
self._create_preview_area(main_frame)
# 控制按钮区域
self._create_control_buttons_area(main_frame)
# 状态栏
self._create_status_bar(main_frame)
def _create_file_selection_area(self, parent):
"""创建文件选择区域"""
# 文件选择框架
file_frame = ttk.LabelFrame(parent, text="文件选择", padding="10")
file_frame.grid(row=1, column=0, columnspan=3, sticky="ew", pady=(0, 10))
file_frame.columnconfigure(1, weight=1)
# HTML文件选择
ttk.Label(file_frame, text="HTML文件:").grid(row=0, column=0, sticky=tk.W, pady=2)
self.html_file_var = tk.StringVar()
html_entry = ttk.Entry(file_frame, textvariable=self.html_file_var, state='readonly')
html_entry.grid(row=0, column=1, sticky="ew", padx=(10, 5), pady=2)
ttk.Button(file_frame, text="浏览...",
command=self._select_html_file).grid(row=0, column=2, pady=2)
# 输出目录选择
ttk.Label(file_frame, text="输出目录:").grid(row=1, column=0, sticky=tk.W, pady=2)
self.output_dir_var = tk.StringVar()
output_entry = ttk.Entry(file_frame, textvariable=self.output_dir_var, state='readonly')
output_entry.grid(row=1, column=1, sticky="ew", padx=(10, 5), pady=2)
ttk.Button(file_frame, text="浏览...",
command=self._select_output_dir).grid(row=1, column=2, pady=2)
# 文件信息
self.file_info_var = tk.StringVar(value="请选择HTML文件")
info_label = ttk.Label(file_frame, textvariable=self.file_info_var,
foreground="gray", font=('Arial', 8))
info_label.grid(row=2, column=0, columnspan=3, sticky=tk.W, pady=(5, 0))
def _create_conversion_options_area(self, parent):
"""创建转换选项区域"""
options_frame = ttk.LabelFrame(parent, text="转换选项", padding="10")
options_frame.grid(row=2, column=0, columnspan=3, sticky="ew", pady=(0, 10))
options_frame.columnconfigure(1, weight=1)
# 预设选择
ttk.Label(options_frame, text="预设:").grid(row=0, column=0, sticky=tk.W, pady=2)
self.preset_var = tk.StringVar(value="default")
preset_combo = ttk.Combobox(options_frame, textvariable=self.preset_var,
values=["default", "simple", "github"],
state="readonly", width=15)
preset_combo.grid(row=0, column=1, sticky=tk.W, padx=(10, 0), pady=2)
preset_combo.bind('<<ComboboxSelected>>', self._on_preset_changed)
# 选项复选框
checkbox_frame = ttk.Frame(options_frame)
checkbox_frame.grid(row=1, column=0, columnspan=3, sticky="ew", pady=(10, 0))
# 创建选项变量
self.ignore_links_var = tk.BooleanVar()
self.ignore_images_var = tk.BooleanVar()
self.ignore_emphasis_var = tk.BooleanVar()
self.clean_html_var = tk.BooleanVar(value=True)
self.clean_empty_emphasis_var = tk.BooleanVar(value=True)
# 选项复选框
ttk.Checkbutton(checkbox_frame, text="忽略链接",
variable=self.ignore_links_var).grid(row=0, column=0, sticky=tk.W, padx=(0, 15))
ttk.Checkbutton(checkbox_frame, text="忽略图片",
variable=self.ignore_images_var).grid(row=0, column=1, sticky=tk.W, padx=(0, 15))
ttk.Checkbutton(checkbox_frame, text="忽略强调",
variable=self.ignore_emphasis_var).grid(row=0, column=2, sticky=tk.W, padx=(0, 15))
ttk.Checkbutton(checkbox_frame, text="清理HTML",
variable=self.clean_html_var).grid(row=0, column=3, sticky=tk.W, padx=(0, 15))
ttk.Checkbutton(checkbox_frame, text="清理空标签",
variable=self.clean_empty_emphasis_var).grid(row=0, column=4, sticky=tk.W)
def _create_preview_area(self, parent):
"""创建预览区域"""
preview_frame = ttk.LabelFrame(parent, text="预览", padding="10")
preview_frame.grid(row=3, column=0, columnspan=3, sticky="nsew", pady=(0, 10))
parent.rowconfigure(3, weight=1)
preview_frame.columnconfigure(0, weight=1)
preview_frame.rowconfigure(0, weight=1)
# 创建Notebook用于标签页
self.notebook = ttk.Notebook(preview_frame)
self.notebook.grid(row=0, column=0, sticky="nsew")
# HTML预览标签页
html_frame = ttk.Frame(self.notebook)
self.notebook.add(html_frame, text="HTML源码")
html_frame.columnconfigure(0, weight=1)
html_frame.rowconfigure(0, weight=1)
self.html_text = scrolledtext.ScrolledText(html_frame, wrap=tk.WORD,
height=15, font=('Consolas', 9))
self.html_text.grid(row=0, column=0, sticky="nsew")
# Markdown预览标签页
md_frame = ttk.Frame(self.notebook)
self.notebook.add(md_frame, text="Markdown输出")
md_frame.columnconfigure(0, weight=1)
md_frame.rowconfigure(0, weight=1)
self.markdown_text = scrolledtext.ScrolledText(md_frame, wrap=tk.WORD,
height=15, font=('Consolas', 9))
self.markdown_text.grid(row=0, column=0, sticky="nsew")
def _create_control_buttons_area(self, parent):
"""创建控制按钮区域"""
button_frame = ttk.Frame(parent)
button_frame.grid(row=4, column=0, columnspan=3, pady=(0, 10))
# 按钮
self.preview_btn = ttk.Button(button_frame, text="预览转换",
command=self._preview_conversion)
self.preview_btn.pack(side=tk.LEFT, padx=(0, 10))
self.convert_btn = ttk.Button(button_frame, text="开始转换",
command=self._start_conversion)
self.convert_btn.pack(side=tk.LEFT, padx=(0, 10))
self.clear_btn = ttk.Button(button_frame, text="清空",
command=self._clear_all)
self.clear_btn.pack(side=tk.LEFT, padx=(0, 10))
# 进度条
self.progress_var = tk.DoubleVar()
self.progress_bar = ttk.Progressbar(button_frame, variable=self.progress_var,
mode='indeterminate', length=200)
self.progress_bar.pack(side=tk.LEFT, padx=(20, 0))
def _create_status_bar(self, parent):
"""创建状态栏"""
self.status_var = tk.StringVar(value="就绪")
status_bar = ttk.Label(parent, textvariable=self.status_var,
relief=tk.SUNKEN, anchor=tk.W)
status_bar.grid(row=5, column=0, columnspan=3, sticky="ew", pady=(5, 0))
def _bind_events(self):
"""绑定事件"""
# 窗口关闭事件
self.root.protocol("WM_DELETE_WINDOW", self._on_closing)
# 注意:tkinter默认不支持文件拖拽,需要额外的库如tkinterdnd2
# 这里暂时移除拖拽功能,如需要可以安装tkinterdnd2库后重新启用
def _select_html_file(self):
"""选择HTML文件"""
filename = filedialog.askopenfilename(
title="选择HTML文件",
filetypes=[
("HTML文件", "*.html *.htm"),
("所有文件", "*.*")
]
)
if filename:
self.current_html_file = filename
self.html_file_var.set(filename)
self._update_file_info()
self._load_html_preview()
def _select_output_dir(self):
"""选择输出目录"""
dirname = filedialog.askdirectory(title="选择输出目录")
if dirname:
self.current_output_dir = dirname
self.output_dir_var.set(dirname)
def _update_file_info(self):
"""更新文件信息"""
if self.current_html_file:
size = self.file_handler.get_file_size(self.current_html_file)
filename = os.path.basename(self.current_html_file)
self.file_info_var.set(f"文件: {filename} | 大小: {size}")
else:
self.file_info_var.set("请选择HTML文件")
def _load_html_preview(self):
"""加载HTML预览"""
if not self.current_html_file:
return
content = self.file_handler.read_html_file(self.current_html_file)
if content:
self.html_text.delete(1.0, tk.END)
self.html_text.insert(1.0, content)
self.status_var.set("HTML文件加载完成")
def _on_preset_changed(self, event=None):
"""预设改变事件"""
preset = self.preset_var.get()
config = self.converter.create_preset_config(preset)
# 更新复选框状态
self.ignore_links_var.set(config.get('ignore_links', False))
self.ignore_images_var.set(config.get('ignore_images', False))
self.ignore_emphasis_var.set(config.get('ignore_emphasis', False))
def _get_current_config(self) -> Dict[str, Any]:
"""获取当前配置"""
return {
'ignore_links': self.ignore_links_var.get(),
'ignore_images': self.ignore_images_var.get(),
'ignore_emphasis': self.ignore_emphasis_var.get(),
'body_width': 0,
'inline_links': True,
'ul_item_mark': '-'
}
def _preview_conversion(self):
"""预览转换"""
if not self.current_html_file:
messagebox.showwarning("警告", "请先选择HTML文件")
return
self._set_ui_state(False)
self.status_var.set("正在预览转换...")
self.progress_bar.start(10)
# 在线程中执行转换
thread = threading.Thread(target=self._do_preview_conversion)
thread.daemon = True
thread.start()
def _do_preview_conversion(self):
"""执行预览转换(在线程中)"""
try:
# 读取HTML内容
html_content = self.file_handler.read_html_file(self.current_html_file)
if not html_content:
return
# 配置转换器
config = self._get_current_config()
self.converter.configure(config)
# 执行转换
markdown_content = self.converter.convert(
html_content,
clean_html=self.clean_html_var.get(),
clean_empty_emphasis=self.clean_empty_emphasis_var.get()
)
if markdown_content:
# 在主线程中更新UI
self.root.after(0, self._update_preview, markdown_content)
except Exception as e:
self.root.after(0, lambda: messagebox.showerror("预览错误", f"预览转换失败:{str(e)}"))
finally:
self.root.after(0, self._preview_complete)
def _update_preview(self, markdown_content: str):
"""更新预览内容"""
self.markdown_text.delete(1.0, tk.END)
self.markdown_text.insert(1.0, markdown_content)
self.notebook.select(1) # 切换到Markdown标签页
def _preview_complete(self):
"""预览完成"""
self.progress_bar.stop()
self._set_ui_state(True)
self.status_var.set("预览完成")
def _start_conversion(self):
"""开始转换"""
if not self.current_html_file:
messagebox.showwarning("警告", "请先选择HTML文件")
return
# 确定输出路径
if self.current_output_dir:
output_file = self.file_handler.get_output_path(
self.current_html_file, self.current_output_dir
)
else:
output_file = self.file_handler.get_output_path(self.current_html_file)
# 确认覆盖
if os.path.exists(output_file):
if not messagebox.askyesno("确认", f"文件已存在,是否覆盖?\n{output_file}"):
return
self._set_ui_state(False)
self.status_var.set("正在转换...")
self.progress_bar.start(10)
# 在线程中执行转换
thread = threading.Thread(target=self._do_conversion, args=(output_file,))
thread.daemon = True
thread.start()
def _do_conversion(self, output_file: str):
"""执行转换(在线程中)"""
try:
# 读取HTML内容
html_content = self.file_handler.read_html_file(self.current_html_file)
if not html_content:
return
# 配置转换器
config = self._get_current_config()
self.converter.configure(config)
# 执行转换
markdown_content = self.converter.convert(
html_content,
clean_html=self.clean_html_var.get(),
clean_empty_emphasis=self.clean_empty_emphasis_var.get()
)
if markdown_content:
# 写入文件
success = self.file_handler.write_markdown_file(output_file, markdown_content)
if success:
self.root.after(0, lambda: self._conversion_success(output_file))
else:
self.root.after(0, lambda: messagebox.showerror("错误", "写入文件失败"))
except Exception as e:
self.root.after(0, lambda: messagebox.showerror("转换错误", f"转换失败:{str(e)}"))
finally:
self.root.after(0, self._conversion_complete)
def _conversion_success(self, output_file: str):
"""转换成功"""
messagebox.showinfo("成功", f"转换完成!\n输出文件:{output_file}")
# 询问是否打开文件
if messagebox.askyesno("打开文件", "是否打开生成的Markdown文件?"):
try:
os.startfile(output_file) # Windows
except:
try:
os.system(f'open "{output_file}"') # macOS
except:
try:
os.system(f'xdg-open "{output_file}"') # Linux
except:
pass
def _conversion_complete(self):
"""转换完成"""
self.progress_bar.stop()
self._set_ui_state(True)
self.status_var.set("转换完成")
def _set_ui_state(self, enabled: bool):
"""设置UI状态"""
state = tk.NORMAL if enabled else tk.DISABLED
self.preview_btn.config(state=state)
self.convert_btn.config(state=state)
self.is_converting = not enabled
def _clear_all(self):
"""清空所有内容"""
if self.is_converting:
messagebox.showwarning("警告", "转换进行中,无法清空")
return
self.current_html_file = ""
self.current_output_dir = ""
self.html_file_var.set("")
self.output_dir_var.set("")
self.html_text.delete(1.0, tk.END)
self.markdown_text.delete(1.0, tk.END)
self._update_file_info()
self.status_var.set("已清空")
def _on_closing(self):
"""窗口关闭事件"""
if self.is_converting:
if not messagebox.askyesno("确认", "转换正在进行中,确定要退出吗?"):
return
self.root.destroy()
def main():
"""主函数"""
# 检查依赖
try:
import html2text
import bs4
except ImportError as e:
print(f"缺少依赖模块:{e}")
print("请运行:pip install -r requirements.txt")
input("按Enter键退出...")
return
# 创建应用
root = tk.Tk()
app = HtmlToMarkdownApp(root)
# 运行应用
try:
root.mainloop()
except KeyboardInterrupt:
print("应用被用户中断")
except Exception as e:
print(f"应用运行错误:{e}")
if __name__ == "__main__":
main()html_converter.py
"""
HTML到Markdown转换模块
使用html2text和BeautifulSoup进行HTML到Markdown的转换
"""
import html2text
from bs4 import BeautifulSoup
import re
from typing import Optional, Dict, Any
import tkinter.messagebox as messagebox
class HtmlToMarkdownConverter:
"""HTML到Markdown转换器"""
def __init__(self):
"""初始化转换器"""
self.h2t = html2text.HTML2Text()
self._setup_default_config()
def _setup_default_config(self):
"""设置默认配置"""
# 基本设置
self.h2t.ignore_links = False
self.h2t.ignore_images = False
self.h2t.ignore_emphasis = False
self.h2t.body_width = 0 # 不限制行宽
self.h2t.unicode_snob = True # 使用Unicode字符
self.h2t.escape_snob = True # 转义特殊字符
# 链接处理
self.h2t.inline_links = True # 内联链接
self.h2t.protect_links = True # 保护链接
# 列表处理
self.h2t.ul_item_mark = '-' # 无序列表标记
# 表格处理
self.h2t.ignore_tables = False
# 其他设置
self.h2t.unicode_snob = True # 使用Unicode字符
def configure(self, config: Dict[str, Any]):
"""
配置转换器选项
Args:
config: 配置字典
"""
for key, value in config.items():
if hasattr(self.h2t, key):
setattr(self.h2t, key, value)
def convert(self, html_content: str, clean_html: bool = True, clean_empty_emphasis: bool = True) -> Optional[str]:
"""
将HTML转换为Markdown
Args:
html_content: HTML内容
clean_html: 是否清理HTML内容
clean_empty_emphasis: 是否清理空的强调标签
Returns:
转换后的Markdown内容,失败返回None
"""
try:
if clean_html:
html_content = self._clean_html(html_content, clean_empty_emphasis)
# 执行转换
markdown_content = self.h2t.handle(html_content)
# 后处理
markdown_content = self._post_process_markdown(markdown_content)
return markdown_content
except Exception as e:
messagebox.showerror("转换错误", f"HTML转换失败:{str(e)}")
return None
def _clean_html(self, html_content: str, clean_empty_emphasis: bool = True) -> str:
"""
清理HTML内容
Args:
html_content: 原始HTML内容
clean_empty_emphasis: 是否清理空的强调标签
Returns:
清理后的HTML内容
"""
try:
# 使用BeautifulSoup解析和清理HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 先处理特殊class的span标签,转换为对应的Markdown格式
self._process_special_spans(soup)
# 清理空的强调标签,避免产生多余的格式标记
if clean_empty_emphasis:
self._clean_empty_emphasis_tags(soup)
# 处理图表区域,为不可转换的内容添加说明
self._process_charts_and_scripts(soup)
# 移除不需要的标签
unwanted_tags = ['script', 'style', 'meta', 'link', 'noscript']
for tag in unwanted_tags:
for element in soup.find_all(tag):
element.decompose()
# 移除注释
for comment in soup.find_all(string=lambda text: isinstance(text, str) and text.strip().startswith('<!--')):
comment.extract()
# 清理属性(保留重要的)
for tag in soup.find_all():
# 保留重要属性
important_attrs = ['href', 'src', 'alt', 'title', 'id', 'class']
attrs_to_remove = []
for attr in tag.attrs:
if attr not in important_attrs:
attrs_to_remove.append(attr)
for attr in attrs_to_remove:
del tag.attrs[attr]
return str(soup)
except Exception as e:
# 如果清理失败,返回原内容
print(f"HTML清理失败:{e}")
return html_content
def _process_special_spans(self, soup):
"""
处理特殊class的span标签,转换为对应的Markdown格式
Args:
soup: BeautifulSoup对象
"""
# 处理高亮文本(highlight class)
for span in soup.find_all('span', class_='highlight'):
# 将高亮文本转换为行内代码样式(反引号)
span.name = 'code'
if 'class' in span.attrs:
del span.attrs['class']
# 处理重要文本(important class)
for span in soup.find_all('span', class_='important'):
# 将重要文本转换为粗体样式
span.name = 'strong'
if 'class' in span.attrs:
del span.attrs['class']
# 处理其他可能的特殊class
special_classes = {
'emphasis': 'em',
'italic': 'em',
'bold': 'strong',
'underline': 'u',
'code': 'code'
}
for class_name, tag_name in special_classes.items():
for span in soup.find_all('span', class_=class_name):
span.name = tag_name
if 'class' in span.attrs:
del span.attrs['class']
# 处理内部锦点链接,确保正确转换
self._process_internal_links(soup)
def _clean_empty_emphasis_tags(self, soup):
"""
清理空的强调标签,避免产生多余的格式标记
Args:
soup: BeautifulSoup对象
"""
# 要清理的空标签类型
emphasis_tags = ['em', 'i', 'strong', 'b', 'u', 'code']
for tag_name in emphasis_tags:
# 查找所有该类型的标签
for tag in soup.find_all(tag_name):
# 检查标签是否为空(没有文本内容且没有子元素包含文本)
if self._is_empty_tag(tag):
# 移除空标签,但保留其可能的尾随空格
if tag.next_sibling and isinstance(tag.next_sibling, str):
# 如果后面紧跟文本,保留一个空格
tag.replace_with(' ' if not tag.next_sibling.startswith(' ') else '')
else:
tag.decompose()
def _is_empty_tag(self, tag) -> bool:
"""
检查标签是否为空(没有有意义的文本内容)
Args:
tag: BeautifulSoup标签对象
Returns:
bool: 如果标签为空则返回True
"""
# 获取标签的文本内容,去除空白字符
text_content = tag.get_text(strip=True)
# 如果没有文本内容,认为是空标签
if not text_content:
return True
# 如果只包含空白字符或特殊字符,也认为是空标签
if text_content.strip() in ['', '\n', '\t', '\r']:
return True
return False
def _process_internal_links(self, soup):
"""
处理内部锦点链接,确保正确转换为Markdown格式
Args:
soup: BeautifulSoup对象
"""
# 处理锦点链接(href以#开头的链接)
for link in soup.find_all('a', href=True):
href = link.get('href')
if href and href.startswith('#'):
# 确保链接属性保留,但清理其他不必要的属性
# 保留href属性用于内部链接
attrs_to_keep = {'href': href}
if 'title' in link.attrs:
attrs_to_keep['title'] = link.attrs['title']
# 清除所有属性并重新设置
link.attrs.clear()
link.attrs.update(attrs_to_keep)
# 为内部链接添加标识(可选)
# 这样html2text就能正确识别并转换为Markdown格式
pass
# 处理标题中的id属性,确保锦点目标存在
for heading in soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6'], id=True):
# 保留id属性用于锦点定位
heading_id = heading.get('id')
if heading_id:
# 确保标题的id属性被保留
heading.attrs = {'id': heading_id}
def _process_charts_and_scripts(self, soup):
"""
处理图表区域和脚本,为不可转换的内容添加说明
Args:
soup: BeautifulSoup对象
"""
# 处理ECharts图表区域
chart_wrappers = soup.find_all('div', class_='chart-wrapper')
for wrapper in chart_wrappers:
chart_id = wrapper.get('id', '未知')
# 创建替换内容,根据图表ID提供更具体的说明
if chart_id == 'chart1':
replacement_text = """
## 📊 交互式图表:自由软件的四大核心自由
> **图表说明**:此处原为一个交互式关系图,展示了自由软件的四大核心自由之间的关系。
>
> **图表内容**:
> - 🔵 **中心节点**:软件自由
> - 🔶 **自由 0**:运行软件的自由
> - 🟢 **自由 1**:研究和修改源代码的自由
> - 🟡 **自由 2**:重新分发拷贝的自由
> - 🟠 **自由 3**:发布改进版本的自由
>
> **查看完整图表**:请参阅原始HTML文件中的交互式版本
"""
elif chart_id == 'chart3':
replacement_text = """
## 📈 条形图:2023年全球下载量最高的十大开源库
> **图表说明**:此处原为一个横向条形图,展示了开源项目的下载量数据。
>
> **排名前五的开源库**:
> 1. **React** - 3,190M 下载量
> 2. **Vue** - 2,270M 下载量
> 3. **Lodash** - 1,900M 下载量
> 4. **jQuery** - 1,800M 下载量
> 5. **Angular** - 1,780M 下载量
>
> **查看完整图表**:请参阅原始HTML文件中的交互式版本
"""
else:
replacement_text = f"""
> 📈 **图表占位符**
>
> 原文件包含一个交互式图表 (ID: {chart_id})
> 该图表由JavaScript生成,无法直接转换为Markdown格式
> 请查看原始HTML文件以获取完整图表信息
"""
# 创建替换元素
replacement = soup.new_tag('div')
replacement.string = replacement_text
# 替换图表包装器
wrapper.replace_with(replacement)
# 处理其他可能的图表类型
chart_elements = soup.find_all(['canvas', 'svg'])
for element in chart_elements:
replacement = soup.new_tag('div')
replacement.string = f"\n\n> 📊 **图形元素占位符** \n> \n> 原文件包含一个{element.name.upper()}图形元素\n> 该元素无法转换为Markdown格式\n\n"
element.replace_with(replacement)
# 处理内联JavaScript
script_tags = soup.find_all('script')
for script in script_tags:
if script.string and 'chart' in script.string.lower():
replacement = soup.new_tag('div')
replacement.string = "\n\n> ⚡ **JavaScript代码占位符** \n> \n> 原文件包含图表相关的JavaScript代码\n> 该代码用于生成交互式图表,无法转换为Markdown\n\n"
script.replace_with(replacement)
def _post_process_markdown(self, markdown_content: str) -> str:
"""
后处理Markdown内容
Args:
markdown_content: 原始Markdown内容
Returns:
处理后的Markdown内容
"""
# 移除多余的空行
markdown_content = re.sub(r'\n{3,}', '\n\n', markdown_content)
# 修复列表格式
markdown_content = re.sub(r'\n\s*\n\s*-', '\n-', markdown_content)
markdown_content = re.sub(r'\n\s*\n\s*(\d+\.)', r'\n\1', markdown_content)
# 修复标题格式
markdown_content = re.sub(r'\n\s*\n\s*#', '\n#', markdown_content)
# 修复代码块格式
markdown_content = re.sub(r'\n\s*\n\s*```', '\n```', markdown_content)
# 修复引用块格式
markdown_content = re.sub(r'\n\s*\n\s*>', '\n>', markdown_content)
# 处理内部链接和目录结构
markdown_content = self._fix_internal_links(markdown_content)
# 处理特殊字符的转义
markdown_content = self._fix_special_characters(markdown_content)
# 移除行尾空格
lines = markdown_content.split('\n')
lines = [line.rstrip() for line in lines]
markdown_content = '\n'.join(lines)
# 确保文件末尾有换行符
if not markdown_content.endswith('\n'):
markdown_content += '\n'
return markdown_content
def _fix_special_characters(self, content: str) -> str:
"""
修复特殊字符的转义
Args:
content: Markdown内容
Returns:
修复后的内容
"""
# 修复HTML实体的转换
entity_map = {
'<': '<',
'>': '>',
'&': '&',
'"': '"',
''': "'",
' ': ' '
}
for entity, char in entity_map.items():
content = content.replace(entity, char)
return content
def _fix_internal_links(self, content: str) -> str:
"""
修复内部链接的格式
Args:
content: Markdown内容
Returns:
修复后的内容
"""
# 修复目录结构中的内部链接格式
# 确保锦点链接格式正确:[text](#anchor)
# 处理嵌套列表中的链接格式
# 将多行的链接合并为单行
content = re.sub(r'\[([^\]]+)\]\(\s*\n\s*([^)]+)\)', r'[\1](\2)', content)
# 修复链接中的空格
content = re.sub(r'\[([^\]]+)\]\(\s*([^)\s]+)\s*\)', r'[\1](\2)', content)
# 保证锦点ID的格式正确
# 如果发现破损的锦点链接,尝试修复
content = re.sub(r'\[(.*?)\]\(#([^)]*?)\)',
lambda m: f'[{m.group(1)}](#{m.group(2).strip()})',
content)
return content
def get_conversion_options(self) -> Dict[str, Dict[str, Any]]:
"""
获取可用的转换选项
Returns:
转换选项字典
"""
return {
"基本选项": {
"ignore_links": {"type": "bool", "default": False, "desc": "忽略链接"},
"ignore_images": {"type": "bool", "default": False, "desc": "忽略图片"},
"ignore_emphasis": {"type": "bool", "default": False, "desc": "忽略强调格式(包括空em标签)"},
"body_width": {"type": "int", "default": 0, "desc": "行宽限制(0为不限制)"}
},
"链接选项": {
"inline_links": {"type": "bool", "default": True, "desc": "使用内联链接"},
"protect_links": {"type": "bool", "default": True, "desc": "保护链接格式"}
},
"列表选项": {
"ul_item_mark": {"type": "str", "default": "-", "desc": "无序列表标记"}
},
"表格选项": {
"ignore_tables": {"type": "bool", "default": False, "desc": "忽略表格"}
},
"高级选项": {
"clean_empty_emphasis": {"type": "bool", "default": True, "desc": "清理空的强调标签(em,i,strong等)"}
}
}
def create_preset_config(self, preset_name: str) -> Dict[str, Any]:
"""
创建预设配置
Args:
preset_name: 预设名称
Returns:
配置字典
"""
presets = {
"default": {
"ignore_links": False,
"ignore_images": False,
"ignore_emphasis": False,
"body_width": 0,
"inline_links": True,
"ul_item_mark": "-"
},
"simple": {
"ignore_links": True,
"ignore_images": True,
"ignore_emphasis": True,
"body_width": 80,
"inline_links": False,
"ul_item_mark": "*"
},
"github": {
"ignore_links": False,
"ignore_images": False,
"ignore_emphasis": False,
"body_width": 0,
"inline_links": True,
"ul_item_mark": "-",
"ignore_tables": False
}
}
return presets.get(preset_name, presets["default"])file_hander.py
"""
文件处理模块
负责HTML和Markdown文件的读写操作
"""
import os
from pathlib import Path
from typing import Optional, Tuple
import tkinter.messagebox as messagebox
class FileHandler:
"""文件处理类"""
@staticmethod
def read_html_file(file_path: str) -> Optional[str]:
"""
读取HTML文件内容
Args:
file_path: HTML文件路径
Returns:
文件内容字符串,失败返回None
"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
return content
except UnicodeDecodeError:
# 尝试其他编码
try:
with open(file_path, 'r', encoding='gbk') as f:
content = f.read()
return content
except UnicodeDecodeError:
try:
with open(file_path, 'r', encoding='latin-1') as f:
content = f.read()
return content
except Exception as e:
messagebox.showerror("编码错误", f"无法读取文件,编码不支持:{str(e)}")
return None
except FileNotFoundError:
messagebox.showerror("文件错误", f"找不到文件:{file_path}")
return None
except Exception as e:
messagebox.showerror("读取错误", f"读取文件时发生错误:{str(e)}")
return None
@staticmethod
def write_markdown_file(file_path: str, content: str) -> bool:
"""
写入Markdown文件
Args:
file_path: 输出文件路径
content: Markdown内容
Returns:
写入成功返回True,失败返回False
"""
try:
# 确保目录存在
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
return True
except Exception as e:
messagebox.showerror("写入错误", f"写入文件时发生错误:{str(e)}")
return False
@staticmethod
def get_output_path(input_path: str, output_dir: Optional[str] = None) -> str:
"""
根据输入文件路径生成输出文件路径
Args:
input_path: 输入HTML文件路径
output_dir: 输出目录,如果为None则使用输入文件所在目录
Returns:
输出的Markdown文件路径
"""
input_file = Path(input_path)
filename_without_ext = input_file.stem
if output_dir:
output_path = Path(output_dir) / f"{filename_without_ext}.md"
else:
output_path = input_file.parent / f"{filename_without_ext}.md"
return str(output_path)
@staticmethod
def validate_file_path(file_path: str, file_type: str = "HTML") -> Tuple[bool, str]:
"""
验证文件路径的有效性
Args:
file_path: 文件路径
file_type: 文件类型描述
Returns:
(是否有效, 错误信息)
"""
if not file_path:
return False, f"请选择{file_type}文件"
if not os.path.exists(file_path):
return False, f"{file_type}文件不存在"
if not os.path.isfile(file_path):
return False, f"所选路径不是文件"
return True, ""
@staticmethod
def get_file_size(file_path: str) -> str:
"""
获取文件大小的人性化显示
Args:
file_path: 文件路径
Returns:
文件大小字符串
"""
try:
size = os.path.getsize(file_path)
if size < 1024:
return f"{size} B"
elif size < 1024 * 1024:
return f"{size / 1024:.1f} KB"
else:
return f"{size / (1024 * 1024):.1f} MB"
except:
return "未知大小"