CogNav框架,解决具身 AI 中目标物体导航 任务(智能体在未知环境定位目标物体)的认知过程建模难题。
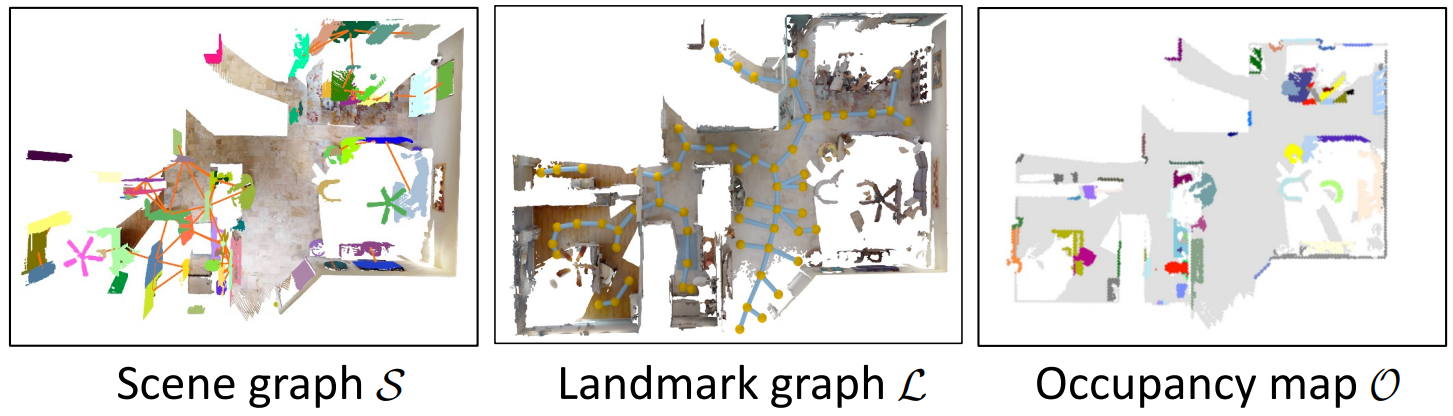
通过构建场景图、导航地标图、俯视图占用图,整合形成异质认知地图,并实现 在线构建+动态更新。
异质认知地图 通过VLM生成文字描述,结合提示词设计,通过LLM实现认知过程建模。
论文地址:CogNav: Cognitive Process Modeling for Object Goal Navigation with LLMs
代码地址:https://github.com/yhanCao/CogNav_ObjNav
看一下示例效果:
一、模型框架
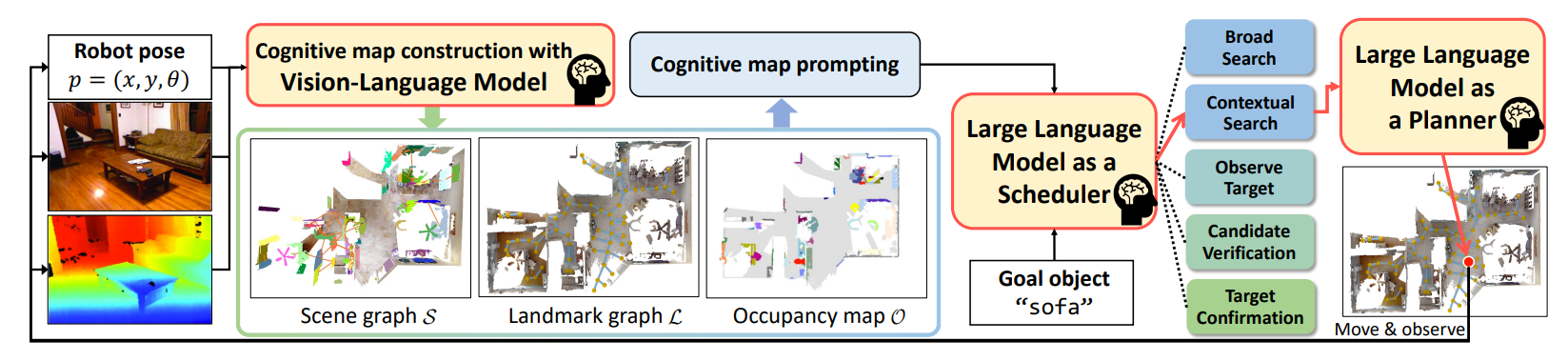
如下图所示,是CogNav 框架从 "环境感知" 到 "导航决策与执行" 的完整流程:
核心是用VLM构建认知地图,并通过LLM模拟人类认知过程(状态调度 + 动作规划),实现零样本目标物体导航
1. 感知输入:环境与目标的初始信息
左侧输入包含三类关键信息,为后续认知建模提供基础:
- 机器人位姿:表示智能体在环境中的平面坐标(x,y)与朝向;
- RGB-D 图像:RGB 图像提供视觉语义信息,深度图像提供空间距离信息,共同描述环境的 "视觉 - 空间" 特征。
2. 认知地图构建:多模态信息的结构化整合(VLM 驱动)
该模块通过VLM 处理感知输入,生成三类互补的认知地图,解决 "语义与空间信息割裂" 的问题:
- 场景图(Scene graph) :编码环境中的物体实例 (如沙发、桌子)及其语义关系(如 "沙发旁边有桌子"),为 LLM 提供 "物体是什么、如何关联" 的语义认知;
- 地标图(Landmark graph ) :提取环境中的关键导航锚点(如房间角落、物体位置),将连续空间离散为 "可导航的地标",为 LLM 决策提供 "去哪里" 的空间锚点;
- 占用图(Occupancy map ) :表示环境的空间布局(已探索区域、未探索区域、障碍物),为路径规划提供 "哪里能走" 的空间约束。
3. 认知地图提示:结构化信息→文本提示(LLM 的 "环境接口")
由于 LLM 仅能处理文本输入,需将 "场景图、地标图、占用图" 的结构化信息转化为自然语言提示。例如:
- 场景图提示:"当前区域有一张沙发,沙发位于客厅,旁边有一张木质茶几";
- 地标图提示:"地标 A 距离当前位置 5 米,未探索过,附近有疑似目标物体";
- 占用图提示:"前方 3 米为已探索区域,右侧存在障碍物"。这一步是 "接地(Grounding)" 的关键,让 LLM 能理解环境的视觉与空间信息。
4. 认知状态调度:LLM 模拟人类认知阶段(Scheduler)
LLM 接收两部分输入:认知地图的文本提示、目标物体(如 "sofa")。
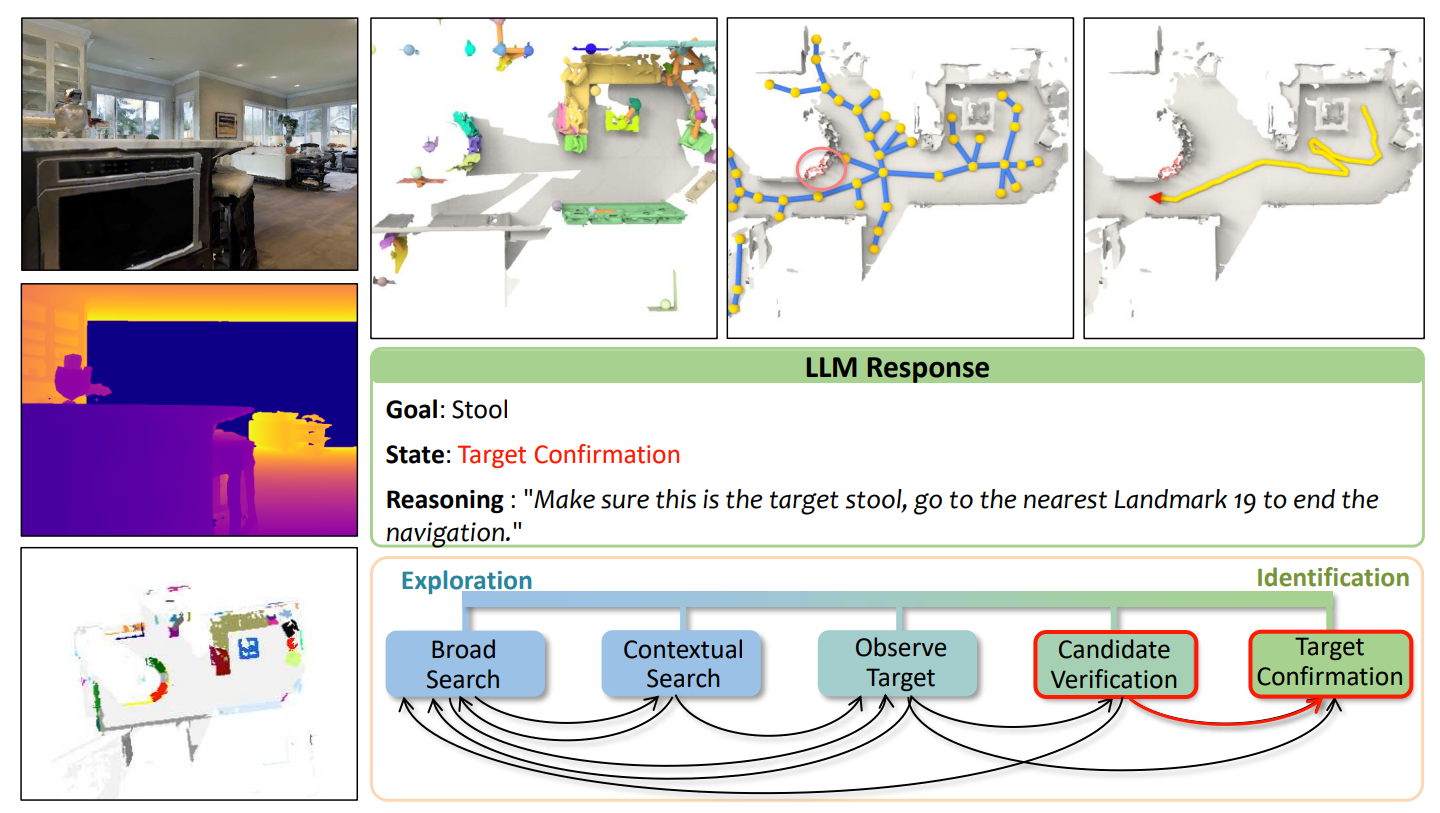
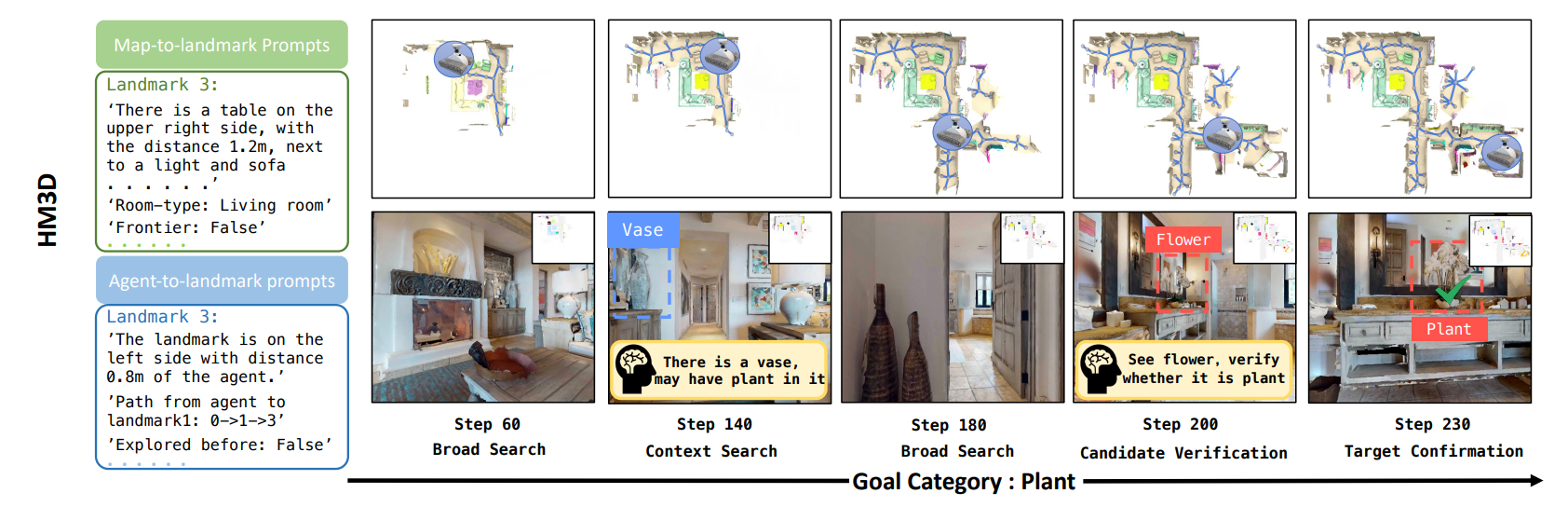
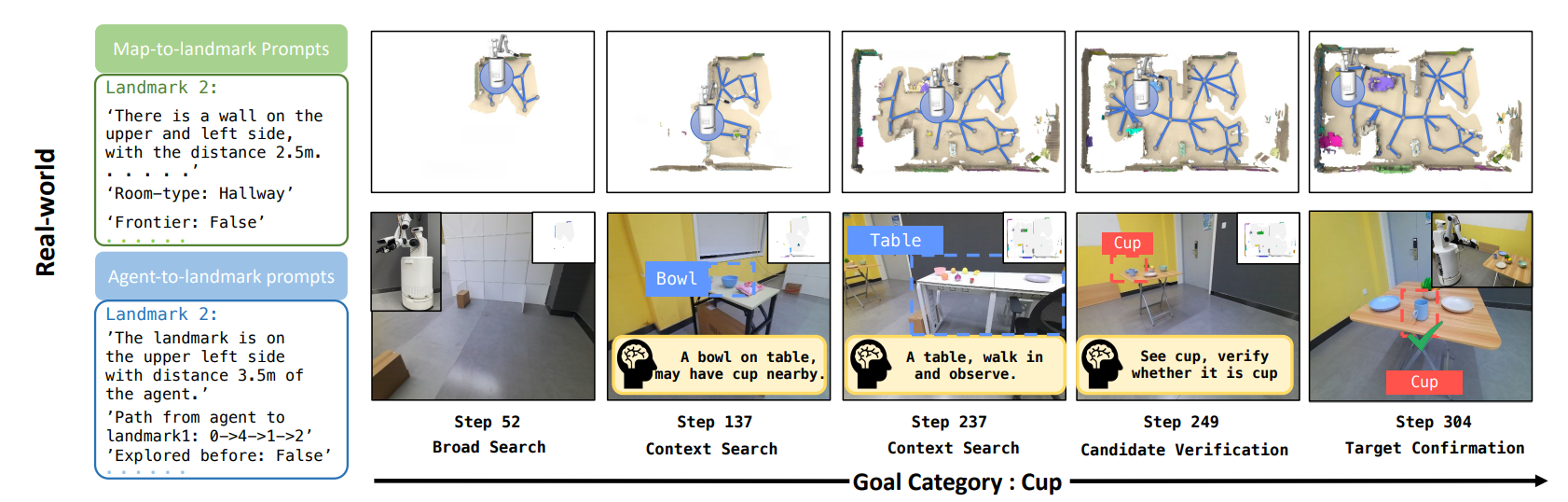
- 基于这些输入,LLM 决策当前应处于哪一类认知状态(模拟人类导航时的 "思考阶段")。图中定义了 5 个渐进式状态:
- Broad Search(广泛搜索):无目标聚焦,优先探索未知区域;
- Contextual Search(上下文搜索):利用场景上下文(如 "卧室通常有床")缩小搜索范围;
- Observe Target(观察目标):接近基础模型检测到的疑似目标;
- Candidate Verification(候选验证):多视角验证疑似目标,修正误判;
- Target Confirmation(目标确认):确认目标后,准备结束导航。
5. 动作规划与执行:LLM 生成导航指令(Planner)
根据选定的认知状态,LLM 进一步规划具体导航动作(如 "移动到地标 B""左转 30 度并观察"),并驱动智能体执行。
执行后,新的感知输入(位姿、RGB-D)会再次反馈到 "认知地图构建" 模块,形成闭环的感知 - 决策 - 执行流程,直到智能体确认目标并停止。
小结:
通过 VLM 构建 "语义 + 空间" 的异质认知地图,再以 LLM 为 "调度器 + 规划器",动态切换认知状态并生成导航动作,
既解决了传统方法 "泛化性差"(无需针对场景 / 物体训练),又弥补了 "认知粒度粗糙"(5 类状态覆盖全流程)的缺陷,实现零样本、开放词汇的目标物体导航。
二、认知地图构建
认知地图构建是 CogNav框架的感知基础模块,核心是通过在线构建 + 动态更新 "异质地图集合,
为后续LLM的认知决策提供 "语义 + 空间 + 导航" 的多模态环境信息。
CogNav 的认知地图并非单一结构,而是由三类互补的子地图构成,共同覆盖 "语义理解、空间布局、导航锚点" 三大维度:
- Scene Graph(场景图)→ 编码语义与物体空间关系;
- Occupancy Map(俯视图占用图)→ 编码全局空间布局;
- Landmark Graph(地标图)→ 提供离散化的导航锚点。
2.1 场景图:语义与关系的 "结构化载体"
- 核心功能:让 LLM 理解 "环境中有什么物体,物体间如何空间关联",是语义认知的核心。
- 实例节点(N_t) :
- 基础分割:用OpenSEED(开放词汇分割模型)从 RGB-D 图像中提取 2D 物体实例,结合深度信息与位姿 p_t,反投影生成 3D 实例;
- 聚类融合:用DBSCAN 算法将当前帧 3D 实例与历史实例 (N_{t-1}) 融合,避免重复标注;
- 语义优化:因分割易产生噪声(如小物体漏检、类别误判),引入GPT-4v(视觉 - 语言模型)+SoM 技术.
- 用 SoM 在图像中标记实例编号,让 GPT-4v 重新判断实例类别、边界及所在房间类型(如 "客厅""卧室"),每 10 步更新一次(平衡精度与计算效率)。
- 空间关系边(E_t) :
- 关系类型:限定为 5 类常用空间关系 next to "相邻"、on top of "在... 上"、inside of "在... 内"、under"在... 下"、hang on "悬挂于",无关联时标记为none;
- 推理方式:可通过 3D 坐标直接判断的关系on top of直接计算;
- 难以直观判断的关系next to,由 GPT-4v 基于双视角图像推理(降低单视角误判率)。

2.2 俯视图占用图:空间布局的 "全局视角"
- 核心功能:提供 "已探索 / 未探索区域、障碍物、智能体位置" 的全局空间信息,为 "前沿区域检测""路径规划" 提供基础。
- 技术细节 :
- 规格:地图分辨率为5cm(平衡精度与计算量),尺寸为M×M;
- 通道设计:含 4 个通道,分别标记 "占用区域(障碍物,如墙壁、家具)""已探索区域""智能体当前位置""3D 实例节点的 2D 投影";
- 更新频率:每步更新(实时反映智能体的探索进度与位置变化)。

2.3. 地标图:导航锚点的 "离散化表达"
- 核心功能 :将连续环境空间离散为 "可导航的地标点",关联场景图的语义信息 与占用图的空间信息,解决 "LLM 决策无法直接映射到连续空间" 的问题。
- 技术细节 :
- 地标来源:基于广义 Voronoi 图(GVD) 提取两类关键位置:
- 前沿点(Frontier Locations):从占用图中聚类得到,代表 "未探索区域的边界",支撑 "广泛搜索(BS)" 状态;
- 实例点(Instance Locations):场景图实例节点 \(N_t\) 在占用图上的投影,代表 "有物体的关键区域",支撑 "目标相关搜索(CS/OT)" 状态;
- 优化策略:
- 生成简化 Voronoi 图(RVD):仅保留 GVD 的交点与叶节点,移除冗余节点,降低导航复杂度;
- 地标 - 实例映射(\(D_t\)):为每个地标绑定对应的实例节点或前沿区域,确保 LLM 能通过地标关联语义(如 "地标 46 对应沙发实例");
- 更新频率:每 10 步更新(与场景图同步,平衡精度与计算开销)。
- 地标来源:基于广义 Voronoi 图(GVD) 提取两类关键位置:
三、认知地图提示生成
通过 "多模态地图结构化表征环境 → 文本提示转化为 LLM 可理解的语言",
实现 "环境感知" 到 "LLM 认知决策" 的桥梁搭建,让 LLM 能基于这些提示,推理认知状态转换与导航策略。
第一步:认知地图构建(左侧,多模态环境表征)
通过三类异质子地图,从 "语义、空间、导航锚点" 维度结构化描述环境:
- 场景图(Scene Graph) :聚焦物体实例(Instances),记录环境中的物体(如沙发、橱柜、椅子等)及其语义类别、相互空间关系(如 "沙发旁边有椅子")。
- 地标图(Landmark Graph) :将连续空间离散为地标(Landmark),作为导航的核心锚点,连接 "场景图的语义实例" 与 "占用图的空间布局"。
- 占用图(Occupancy Map) :编码环境布局(Layout),包括已探索 / 未探索区域、障碍物等空间结构信息。
三者互补,共同构建 "语义 + 空间 + 导航" 的异质认知地图,为后续提示生成提供多维度、结构化的环境信息。
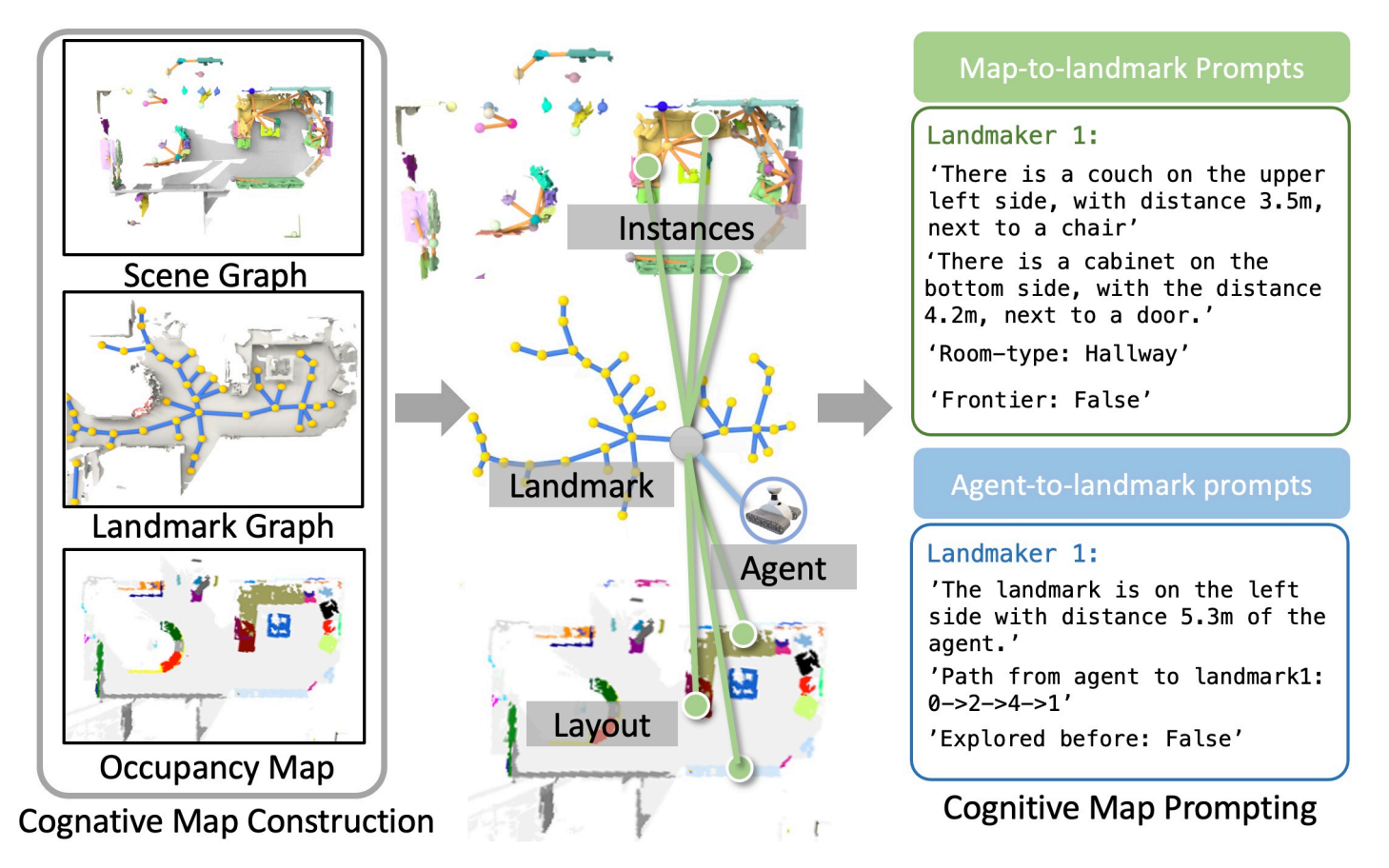
第二步:认知地图提示(右侧,文本化环境信息)
由于 LLM 仅能理解自然语言,需将 "结构化的认知地图" 转化为文本提示,分为两类,让 LLM 掌握 "地标周边环境" 与 "智能体和地标的关系":
-
地图到地标提示(Map-to-landmark Prompts):描述 "地标周围有什么",包括:
- 周边物体与空间关系:周边物体与距离(如 "左上角有沙发,距离 3.5 米,旁边是椅子");
- 房间类型:如 "Room-type: Hallway";
- 前沿属性:从占用图中判断地标是否属于 "前沿区域(未探索边界)"(如 "Frontier: False"),辅助 LLM 决策是否需要探索新区域。
-
智能体到地标提示(Agent-to-landmark Prompts):描述 "智能体(Agent)与地标是什么关系",包括:
- 相对位置与距离: Dijkstra 算法计算智能体到地标的直线 / 路径距离。地标相对智能体的位置与距离(如 "地标 1 在智能体左侧,距离 5.3 米");
- 导航路径:生成智能体到地标的最短路径,(如 "Path: 0→2→4→1");
- 是否已探索过该地标(如 "Explored before: False")。作用:帮助 LLM 判断 "导航到该地标的可行性、效率(是否重复探索)"。
四、认知过程建模
建模灵感 ------人类大脑在物体搜索中的动态认知机制:人类会通过 "利用场景上下文(如 "床通常在卧室")""多视角观察验证(如 "走近确认疑似目标是否为杯子")" 等行为,
持续更新自身的 "精细认知状态",而非仅停留在 "探索" 或 "识别" 两个粗阶段。
基于此,CogNav 需解决两个关键问题:
- 如何定义覆盖导航全流程的 "合理认知状态集合"?
- 如何实现 "跨目标 / 跨场景泛化" 的状态转换逻辑(避免传统方法依赖预定义阈值的局限性)?
核心组件 1:五类精细认知状态 ------ 覆盖 "探索→确认" 全流程
为完整模拟人类从 "未知环境探索" 到 "目标确认" 的思考过程,CogNav 定义5 个渐进式认知状态,
每个状态对应明确的 "目标、适用场景、候选地标",填补了传统方法 "仅 2 类粗状态" 的认知缺口:
| 认知状态 (中文 / 英文缩写) | 核心目标 | 适用场景 | 候选地标来源 | 关键作用 |
|---|---|---|---|---|
| 广泛搜索(BS) | 最大化环境探索,快速构建全局认知 | 任务初期,未获取任何目标相关信息(如刚进入陌生房间) | 前沿地标集合(占用图中未探索区域的边界) | 解决 "未知环境开局" 问题,避免遗漏潜在目标区域 |
| 上下文搜索(CS) | 缩小搜索范围,聚焦 "可能含目标" 的区域 | 已获取部分场景上下文(如通过 LLM 常识推理 "植物可能在客厅") | 目标相关地标集合(绑定目标相关实例 / 房间类型,如 "客厅内的地标") | 利用常识减少无效探索,提升导航效率 |
| 观察目标(OT) | 接近 "疑似目标",获取更清晰观测 | 基础模型(如 OpenSEED)检测到潜在目标实例(如 "检测到疑似沙发") | 潜在目标地标集合(绑定检测到的目标类别实例) | 从 "大范围搜索" 转向 "小范围聚焦",为后续验证做准备 |
| 候选验证(CV) | 多视角验证疑似目标,修正误判 | 疑似目标观测存在歧义(如单视角下 "沙发被误判为床") | 待验证地标集合中未探索过的地标) | 解决 "目标误判" 痛点,是提升成功率的关键(消融实验显示:移除 CV 状态后 HM3D 成功率下降 3.7%) |
| 目标确认(TC) | 确认目标后,直接接近并终止任务 | LLM 基于多视角观测 + 环境上下文,确认疑似目标为真实目标 | 距离目标最近的地标为目标实例) | 完成 "识别→终止" 的最后一步,确保导航任务闭环 |
核心组件 2:LLM 驱动的状态转换 ------ 替代 "预定义阈值" 的自适应决策
传统 ObjectNav 方法依赖 "硬阈值" 触发状态转换(如 "目标检测置信度 > 0.8 则进入识别状态"),泛化性差(如 "检测沙发的阈值不适用于检测小植物")。
CogNav 的突破在于:用 LLM 的常识推理能力替代阈值,实现 "环境自适应" 的状态转换。
1. 转换输入:认知地图提示
LLM 的决策依据是上面生成的 "认知地图提示",包含两类关键信息:
- 环境上下文:地标周边的物体 / 关系、房间类型(如 "地标46 位于客厅,周围有沙发");
- 智能体状态:与地标的距离、探索历史(如 "地标46 未探索,距离当前位置 5 米")。
例如,若提示中包含 "客厅内发现疑似沙发实例,但当前视角仅能看到部分轮廓",LLM 会推理 "需要多视角验证",触发从 "OT" 到 "CV" 的转换。
2. 转换优势:跨目标 / 跨场景的泛化性
通过实验验证了该机制的适应性:
- 搜索 "沙发 / 床" 等易识别、场景固定的目标时,状态转换更有序(如 "BS→CS→OT→TC");
- 搜索 "植物 / 马桶" 等场景灵活、易误判的目标时,状态转换更动态(如 "BS→CS→OT→CV→BS→CS→OT→TC"),体现 LLM 根据目标特性调整决策的能力。
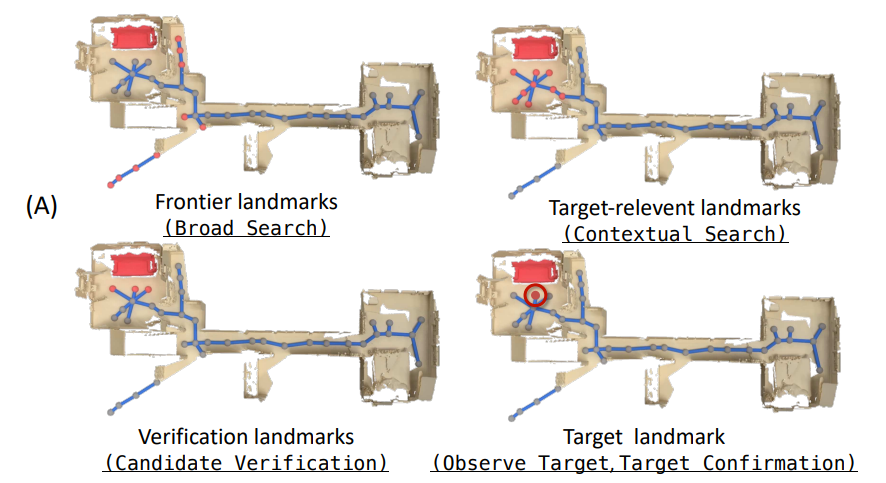
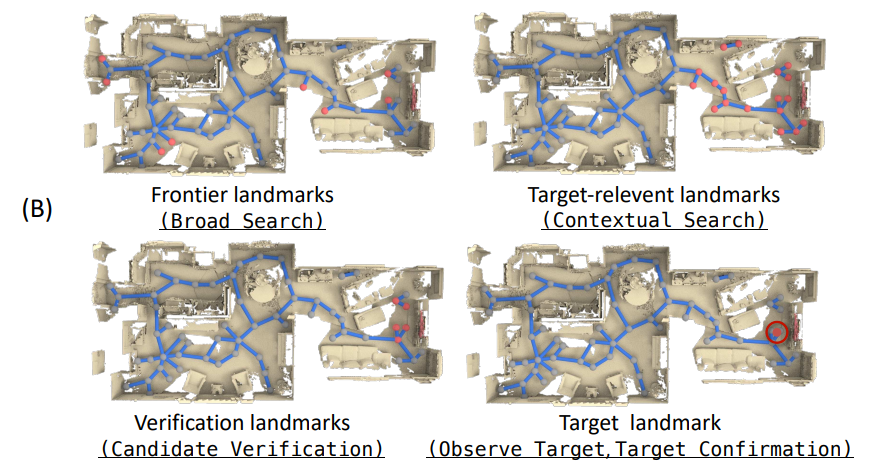
如下图所示,展示了CogNav 框架中 "认知状态→地标选择→导航路径" 的动态演变过程,
通过 (A)(狭长环境)和 (B)(复杂多房间环境)两组场景,验证 "从广泛探索到目标确认" 的认知递进逻辑:
下面是 (B)(复杂多房间环境)
核心组件 3:状态引导的导航策略 ------ 从 "认知状态" 到 "动作执行" 的落地
每个认知状态对应定制化的导航策略,核心是 "LLM 选择适配地标 + 局部规划生成动作",确保认知决策能转化为具身导航行为:
1. 地标选择逻辑
LLM 基于当前认知状态,从 "候选地标集合" 中筛选最优地标:
- BS 状态:优先选 "距离最近的前沿地标"(最大化探索效率);
- CS 状态:优先选 "与目标关联度高的地标"(如 "找植物时优先选'花盆附近的地标'");
- CV 状态:优先选 "能提供新视角的未探索地标"(如 "疑似目标的侧面 / 正面地标");
- TC 状态:直接选 "距离目标实例最近的地标"(确保停止时满足 "1 米内" 的成功条件)。
2. 局部路径规划:Fast Marching Method(FMM)
地标确定后,采用快速推进法(FMM) 生成离散动作(前进、转向等):
- FMM 基于 "俯视图占用图",将 "目标地标" 作为终点,计算智能体当前位置到终点的 "最小代价场";
- 每步选择 "代价最小" 的方向执行动作,确保路径避开障碍物,且能适应动态更新的占用图(如探索中发现新障碍物)。
3. 闭环修正机制
若导航过程中,LLM 通过新的认知地图提示发现 "之前的目标判断错误"(如 "CV 状态验证后发现疑似目标是椅子而非沙发"),
会触发 "状态回溯"(如从 "CV" 退回 "CS" 甚至 "BS"),实现 "错误修正"
这也是 CogNav 成功率高于传统方法的关键(如 HM3D 成功率较 SOTA 提升 10.5%)。
"认知过程建模" 是 CogNav 区别于传统 ObjectNav 方法的核心创新点,其价值体现在三方面:
- 认知粒度的精细化:5 类状态覆盖 "探索→筛选→验证→确认" 全流程,解决传统方法 "认知缺口"(如目标验证环节缺失);
- 决策逻辑的泛化性:LLM 驱动的状态转换无需预定义阈值,适配不同目标类别(如沙发 / 植物)与场景(如 HM3D/MP3D),支持零样本设置;
- 感知 - 决策 - 执行的闭环:连接 "异质认知地图(感知)" 与 "局部路径规划(执行)",让 LLM 的 "类人思考" 能真正落地为高效的导航行为。
五、细节补充
如下图所示,用 "Segment Anything Model(SoM)+ GPT-4v" 解决认知地图构建中的两大核心问题**:实例融合(修正分割错误)与空间关系生成**
是CogNav场景图(Scene Graph)精准构建的关键技术。

(a):实例融合(解决 "过分割 / 欠分割" 问题)
问题背景
基础分割模型(如 OpenSEED)在处理复杂场景时,易出现过分割(同一物体被错误拆分为多个实例,如图中窗户被拆为 "实例 14" 和 "实例 40")
或欠分割(多个不同物体被错误合并为一个实例,如图中沙发与枕头可能被误判为同一物体)。这类错误会导致场景图的 "实例节点(\(\mathcal{N}_t\))" 失真,影响后续认知决策的准确性。
解决方法
通过SoM 标记 + GPT-4v 推理实现 "实例正确性修正":
- 用 SoM 在图像上标记 "疑似错误的实例区域"(如过分割的多个子区域、欠分割的疑似多物体区域);
- 向 GPT-4v 输入带标记的图像,并 prompt 提问(如 "实例 14 和 40 是否为同一物体,能否融合?""实例 2 和 3 是否为不同物体?");
- GPT-4v 基于视觉理解 + 常识推理输出判断(如 "窗户的两部分属于同一物体,应融合""沙发和枕头是不同物体,应拆分"),指导场景图的实例节点更新。
(b):空间关系生成(解决 "物体间语义关系推理" 问题)
问题背景
场景图的 "关系边" 需表示物体间的空间关系(如 "悬挂于""在... 之上"),但纯几何计算(如 3D 坐标距离)难以捕捉语义层面的关系
(如 "灯挂在墙上" 的 "hanged on" 关系,需结合场景语义理解)。
解决方法
同样通过SoM 标记 + GPT-4v 推理实现 "空间关系精准生成":
- 用 SoM 标记需判断关系的两个物体(如图中 "灯与墙""花瓶与橱柜");
- 向 GPT-4v 输入带标记的图像,并 prompt 提问(如 "分析图像语义,判断物体 6 和墙的关系""物体 0 和 2 的关系是什么?");
- GPT-4v 基于视觉语义理解输出关系标签(如 "灯 hanged on 墙""花瓶 on top of 橱柜"),作为场景图的 "关系边"。
等待编写.......................
六、实验验证
如下表所示,比较 HM3D、MP3D和 RoboTHOR数据集,在不同方法的成功率
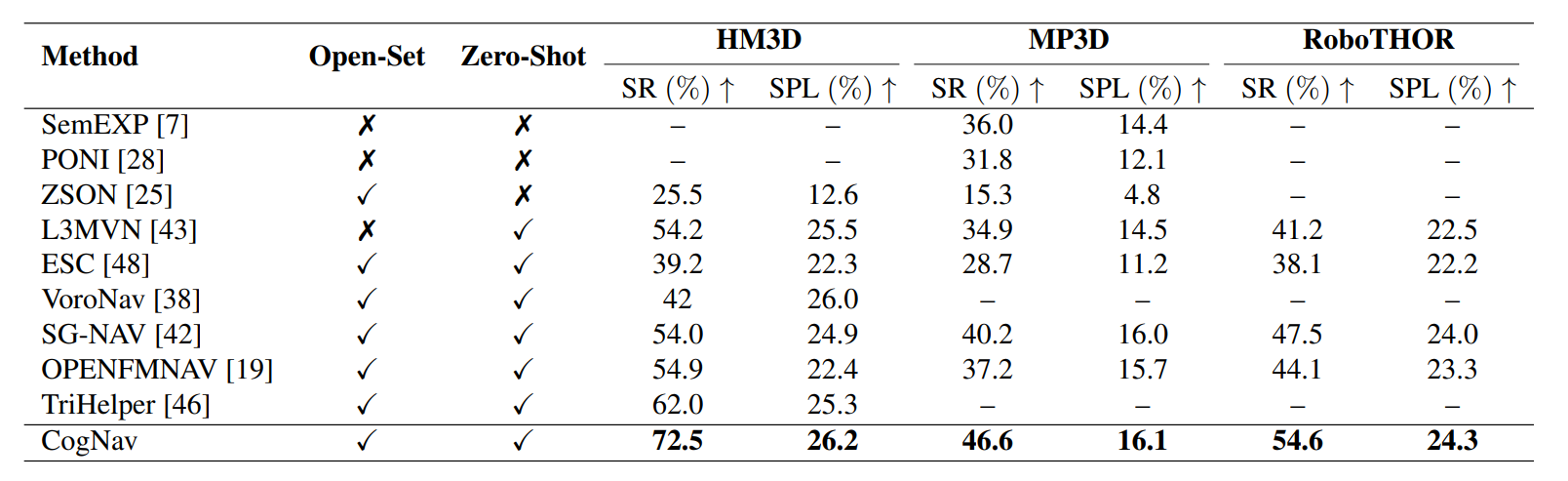
HM3D数据集中,进行目标导航,效果展示:
真实环境中,进行目标导航,效果展示:
分享完成~