1 大模型使用的方式
- 1 得到dataset, sampler, collate_fn
- 2 得到dataloder
- 3 设置trainer
- 4 训练
python
# 1 得到dataset
# 通过create方式
train_dataset = create_rl_dataset(self.config.data.train_files, self.config.data, self.tokenizer, self.processor)
# 通过load方式
train_dataset = datasets.load_dataset("parquet", data_files=parquet_file)["train"]
train_sampler = create_rl_sampler(self.config.data, self.train_dataset)
collate_fn = default_collate
# 2 得到dataloder
self.train_dataloader = StatefulDataLoader(
dataset=self.train_dataset,
batch_size=self.config.data.get("gen_batch_size", self.config.data.train_batch_size),
num_workers=num_workers,
drop_last=True,
collate_fn=collate_fn,
sampler=train_sampler,
)
# 3 设置trainer
trainer = RayDAPOTrainer(
config=config,
tokenizer=tokenizer,
processor=processor,
role_worker_mapping=role_worker_mapping,
resource_pool_manager=resource_pool_manager,
ray_worker_group_cls=ray_worker_group_cls,
reward_fn=reward_fn,
val_reward_fn=val_reward_fn,
)
# 4 训练
trainer.fit()2 dataset
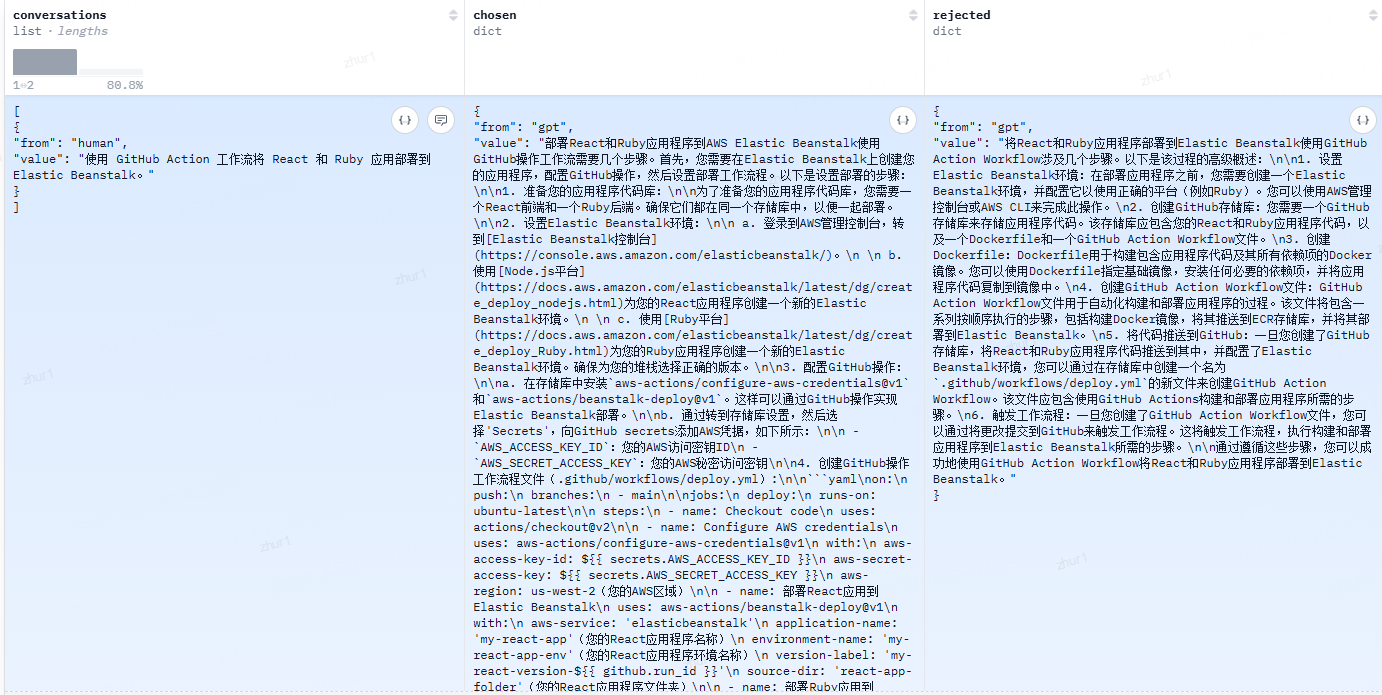
数据示例
可以是json, jsonl格式:一行是一个数据
也可以是txt格式,一行是一个json格式数据
也可以是csv格式
也可以是parquet格式
https://huggingface.co/datasets/llamafactory/DPO-En-Zh-20k/viewer/zh
例如
{"A":"this is A", "B":"this is B"}
{"A":"this is A1", "B":"this is B1"}
{"A":"this is A2", "B":"this is B2"}
python
def create_rl_dataset(data_paths, data_config, tokenizer, processor):
"""Create a dataset.
Arguments:
data_config: The data config.
tokenizer (Tokenizer): The tokenizer.
processor (Processor): The processor.
Returns:
dataset (Dataset): The dataset.
"""
from torch.utils.data import Dataset
from verl.utils.dataset.rl_dataset import RLHFDataset
dataset_cls = RLHFDataset
print(f"Using dataset class: {dataset_cls.__name__}")
dataset = dataset_cls(
data_files=data_paths,
tokenizer=tokenizer,
processor=processor,
config=data_config,
)
return dataset
class RLHFDataset(Dataset):
def __init__(
self,
data_files: str | list[str],
tokenizer: PreTrainedTokenizer,
config: DictConfig,
processor: Optional[ProcessorMixin] = None,
):
self._download()
self._read_files_and_tokenize()
def _download(self, use_origin_parquet=False):
from verl.utils.fs import copy_to_local
data_files = self.data_files if not use_origin_parquet else self.original_data_files
for i, parquet_file in enumerate(data_files):
self.data_files[i] = copy_to_local(src=parquet_file, cache_dir=self.cache_dir, use_shm=self.use_shm)
def _read_files_and_tokenize(self):
dataframes = []
for parquet_file in self.data_files:
# read parquet files and cache
dataframe = datasets.load_dataset("parquet", data_files=parquet_file)["train"]
dataframes.append(dataframe)
self.dataframe: datasets.Dataset = datasets.concatenate_datasets(dataframes)
print(f"dataset len: {len(self.dataframe)}")
self.dataframe = self.maybe_filter_out_long_prompts(self.dataframe)
def _build_messages(self, example: dict):
messages: list = example.pop(self.prompt_key)
if self.image_key in example or self.video_key in example:
for message in messages:
content = message["content"]
content_list = []
segments = re.split("(<image>|<video>)", content)
segments = [item for item in segments if item != ""]
for segment in segments:
if segment == "<image>":
content_list.append({"type": "image"})
elif segment == "<video>":
content_list.append({"type": "video"})
else:
content_list.append({"type": "text", "text": segment})
message["content"] = content_list
return messages
def __getitem__(self, item):
"""
Note that we also return the raw_input_ids so that it can be combined with other chat template
"""
row_dict: dict = self.dataframe[item]
messages = self._build_messages(row_dict)
model_inputs = {}
if self.processor is not None:
from verl.utils.dataset.vision_utils import process_image, process_video
raw_prompt = self.processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=False, **self.apply_chat_template_kwargs
)
multi_modal_data = {}
images = None
row_dict_images = row_dict.pop(self.image_key, None)
if row_dict_images:
images = [process_image(image) for image in row_dict_images]
# due to the image key is "image" instead of "images" in vllm, we need to use "image" here
# link: https://github.com/vllm-project/vllm/blob/3c545c0c3b98ee642373a308197d750d0e449403/vllm/multimodal/parse.py#L205
multi_modal_data["image"] = images
videos = None
row_dict_videos = row_dict.pop(self.video_key, None)
if row_dict_videos:
videos = [process_video(video) for video in row_dict_videos]
# due to the video key is "video" instead of "videos" in vllm, we need to use "video" here
# link: https://github.com/vllm-project/vllm/blob/3c545c0c3b98ee642373a308197d750d0e449403/vllm/multimodal/parse.py#L205
multi_modal_data["video"] = [video.numpy() for video in videos]
model_inputs = self.processor(text=[raw_prompt], images=images, videos=videos, return_tensors="pt")
input_ids = model_inputs.pop("input_ids")
attention_mask = model_inputs.pop("attention_mask")
if "second_per_grid_ts" in model_inputs:
model_inputs.pop("second_per_grid_ts")
# There's a trap here, multi_modal_inputs has to be a dict, not BatchFeature
row_dict["multi_modal_data"] = multi_modal_data
# We will do batch.union() in the trainer,
# so we cannot have "multi_modal_inputs" in row_dict if rollout generates new multi_modal_inputs
if self.return_multi_modal_inputs:
row_dict["multi_modal_inputs"] = dict(model_inputs)
# second_per_grid_ts isn't used for training, just for mrope
row_dict["multi_modal_inputs"].pop("second_per_grid_ts", None)
else:
if self.apply_chat_template_kwargs.get("chat_template") is None:
assert hasattr(self.tokenizer, "chat_template"), (
"chat_template should be provided in apply_chat_template_kwargs or tokenizer config, "
"models like GLM can copy chat_template.jinja from instruct models"
)
raw_prompt = self.tokenizer.apply_chat_template(
messages, add_generation_prompt=True, tokenize=False, **self.apply_chat_template_kwargs
)
model_inputs = self.tokenizer(raw_prompt, return_tensors="pt", add_special_tokens=False)
input_ids = model_inputs.pop("input_ids")
attention_mask = model_inputs.pop("attention_mask")
## 在这里做padding补齐,
input_ids, attention_mask = verl.utils.torch_functional.postprocess_data(
input_ids=input_ids,
attention_mask=attention_mask,
max_length=self.max_prompt_length,
pad_token_id=self.tokenizer.pad_token_id,
left_pad=True,
truncation=self.truncation,
)
if self.processor is not None and "Qwen2VLImageProcessor" in self.processor.image_processor.__class__.__name__:
from verl.models.transformers.qwen2_vl import get_rope_index
vision_position_ids = get_rope_index(
self.processor,
input_ids=input_ids[0],
image_grid_thw=model_inputs.get("image_grid_thw"),
video_grid_thw=model_inputs.get("video_grid_thw"),
second_per_grid_ts=model_inputs.get("second_per_grid_ts"),
attention_mask=attention_mask[0],
) # (3, seq_length)
valid_mask = attention_mask[0].bool()
text_position_ids = torch.ones((1, len(input_ids[0])), dtype=torch.long)
text_position_ids[0, valid_mask] = torch.arange(valid_mask.sum().item())
position_ids = [torch.cat((text_position_ids, vision_position_ids), dim=0)] # (1, 4, seq_length)
else:
position_ids = compute_position_id_with_mask(attention_mask)
row_dict["input_ids"] = input_ids[0]
row_dict["attention_mask"] = attention_mask[0]
row_dict["position_ids"] = position_ids[0]
raw_prompt_ids = self.tokenizer.encode(raw_prompt, add_special_tokens=False)
if len(raw_prompt_ids) > self.max_prompt_length:
if self.truncation == "left":
raw_prompt_ids = raw_prompt_ids[-self.max_prompt_length :]
elif self.truncation == "right":
raw_prompt_ids = raw_prompt_ids[: self.max_prompt_length]
elif self.truncation == "middle":
left_half = self.max_prompt_length // 2
right_half = self.max_prompt_length - left_half
raw_prompt_ids = raw_prompt_ids[:left_half] + raw_prompt_ids[-right_half:]
elif self.truncation == "error":
raise RuntimeError(f"Prompt length {len(raw_prompt_ids)} is longer than {self.max_prompt_length}.")
row_dict["raw_prompt_ids"] = raw_prompt_ids
# encode prompts without chat template
if self.return_raw_chat:
row_dict["raw_prompt"] = messages
# get prompts with chat template
if self.return_full_prompt:
row_dict["full_prompts"] = raw_prompt # array of strings
# add index for each prompt
if "extra_info" not in row_dict or row_dict["extra_info"] is None:
row_dict["extra_info"] = dict()
index = row_dict.get("extra_info", {}).get("index", 0)
tools_kwargs = row_dict.get("extra_info", {}).get("tools_kwargs", {})
interaction_kwargs = row_dict.get("extra_info", {}).get("interaction_kwargs", {})
need_tools_kwargs = row_dict.get("extra_info", {}).get("need_tools_kwargs", self.need_tools_kwargs)
if need_tools_kwargs and not tools_kwargs:
logger.warning("tools_kwargs is empty for index {}, data source: {}", index, row_dict["data_source"])
row_dict["index"] = index
row_dict["tools_kwargs"] = tools_kwargs
row_dict["interaction_kwargs"] = interaction_kwargs
return row_dict
## padding补齐
def postprocess_data(
input_ids: torch.Tensor,
attention_mask: torch.Tensor,
max_length: int,
pad_token_id: int,
left_pad=True,
truncation="error",
):
"""Process tokenizer outputs to consistent shapes via padding/truncation.
Args:
input_ids: Token indices [batch_size, seq_len]
attention_mask: Mask [batch_size, seq_len]
max_length: Target sequence length
pad_token_id: Padding token ID
left_pad: Pad left if True
truncation: "left", "right", "middle" or "error"
Returns:
(input_ids, attention_mask) padded/truncated to max_length
"""
assert truncation in ["left", "right", "middle", "error"]
assert input_ids.ndim == 2
sequence_length = input_ids.shape[-1]
if sequence_length < max_length:
input_ids = pad_sequence_to_length(
input_ids, max_seq_len=max_length, pad_token_id=pad_token_id, left_pad=left_pad
)
attention_mask = pad_sequence_to_length(
attention_mask, max_seq_len=max_length, pad_token_id=0, left_pad=left_pad
)
elif sequence_length > max_length:
if truncation == "left":
# actually, left truncation may not be reasonable
input_ids = input_ids[:, -max_length:]
attention_mask = attention_mask[:, -max_length:]
elif truncation == "right":
input_ids = input_ids[:, :max_length]
attention_mask = attention_mask[:, :max_length]
elif truncation == "middle":
left_half = max_length // 2
right_half = max_length - left_half
input_ids = torch.cat([input_ids[:, :left_half], input_ids[:, -right_half:]], dim=-1)
attention_mask = torch.cat([attention_mask[:, :left_half], attention_mask[:, -right_half:]], dim=-1)
elif truncation == "error":
raise NotImplementedError(f"{sequence_length=} is larger than {max_length=}")
else:
raise NotImplementedError(f"Unknown truncation method {truncation}")
return input_ids, attention_mask
def pad_sequence_to_length(tensors, max_seq_len, pad_token_id, left_pad=False):
"""
pad a 2D tensors (e.g. responses, logprobs) in the last dim to max_seq_length.
input shape: [bs, seq_length]
output shape: [bs, max_seq_length]
"""
if tensors.shape[-1] >= max_seq_len:
return tensors
# (0, max_seq_len - tensors.shape[-1]) means right pad to max_seq_length and no left pad
pad_tuple = (max_seq_len - tensors.shape[-1], 0) if left_pad else (0, max_seq_len - tensors.shape[-1])
return F.pad(tensors, pad_tuple, "constant", pad_token_id)3 sampler
作用是用来随机抽取所需要的数据,每行代表一条数据,做一些sample的事情
例如:原本按顺序抽取
{"A":"this is A", "B":"this is B"}
{"A":"this is A1", "B":"this is B1"}
{"A":"this is A2", "B":"this is B2"}
打乱顺序后,第一次就可能抽出来{"A":"this is A1", "B":"this is B1"}
python
## train_sampler = create_rl_sampler(self.config.data, self.train_dataset)
def create_rl_sampler(data_config, dataset):
"""Create a sampler for the dataset.
Arguments:
data_config: The data config.
dataset (Dataset): The dataset.
Returns:
sampler (Sampler): The sampler.
"""
import torch
from torch.utils.data import RandomSampler, SequentialSampler
# use sampler for better ckpt resume
if data_config.shuffle:
train_dataloader_generator = torch.Generator()
train_dataloader_generator.manual_seed(data_config.get("seed", 1))
sampler = RandomSampler(data_source=dataset, generator=train_dataloader_generator)
else:
sampler = SequentialSampler(data_source=dataset)
return sampler
## sampler重写iter方法, 返回的是数据的index列表
class RandomSampler(Sampler[int]):
def __iter__(self) -> Iterator[int]:
n = len(self.data_source)
if self.generator is None:
seed = int(torch.empty((), dtype=torch.int64).random_().item())
generator = torch.Generator()
generator.manual_seed(seed)
else:
generator = self.generator
if self.replacement:
for _ in range(self.num_samples // 32):
yield from torch.randint(
high=n, size=(32,), dtype=torch.int64, generator=generator
).tolist()
yield from torch.randint(
high=n,
size=(self.num_samples % 32,),
dtype=torch.int64,
generator=generator,
).tolist()
else:
for _ in range(self.num_samples // n):
yield from torch.randperm(n, generator=generator).tolist()
yield from torch.randperm(n, generator=generator).tolist()[
: self.num_samples % n
]4 collate_fn
python
def default_collate(batch):
r"""
Take in a batch of data and put the elements within the batch into a tensor with an additional outer dimension - batch size.
The exact output type can be a :class:`torch.Tensor`, a `Sequence` of :class:`torch.Tensor`, a
Collection of :class:`torch.Tensor`, or left unchanged, depending on the input type.
This is used as the default function for collation when
`batch_size` or `batch_sampler` is defined in :class:`~torch.utils.data.DataLoader`.
Here is the general input type (based on the type of the element within the batch) to output type mapping:
* :class:`torch.Tensor` -> :class:`torch.Tensor` (with an added outer dimension batch size)
* NumPy Arrays -> :class:`torch.Tensor`
* `float` -> :class:`torch.Tensor`
* `int` -> :class:`torch.Tensor`
* `str` -> `str` (unchanged)
* `bytes` -> `bytes` (unchanged)
* `Mapping[K, V_i]` -> `Mapping[K, default_collate([V_1, V_2, ...])]`
* `NamedTuple[V1_i, V2_i, ...]` -> `NamedTuple[default_collate([V1_1, V1_2, ...]),
default_collate([V2_1, V2_2, ...]), ...]`
* `Sequence[V1_i, V2_i, ...]` -> `Sequence[default_collate([V1_1, V1_2, ...]),
default_collate([V2_1, V2_2, ...]), ...]`
Args:
batch: a single batch to be collated
Examples:
>>> # xdoctest: +SKIP
>>> # Example with a batch of `int`s:
>>> default_collate([0, 1, 2, 3])
tensor([0, 1, 2, 3])
>>> # Example with a batch of `str`s:
>>> default_collate(["a", "b", "c"])
['a', 'b', 'c']
>>> # Example with `Map` inside the batch:
>>> default_collate([{"A": 0, "B": 1}, {"A": 100, "B": 100}])
{'A': tensor([ 0, 100]), 'B': tensor([ 1, 100])}
>>> # Example with `NamedTuple` inside the batch:
>>> Point = namedtuple("Point", ["x", "y"])
>>> default_collate([Point(0, 0), Point(1, 1)])
Point(x=tensor([0, 1]), y=tensor([0, 1]))
>>> # Example with `Tuple` inside the batch:
>>> default_collate([(0, 1), (2, 3)])
[tensor([0, 2]), tensor([1, 3])]
>>> # Example with `List` inside the batch:
>>> default_collate([[0, 1], [2, 3]])
[tensor([0, 2]), tensor([1, 3])]
>>> # Two options to extend `default_collate` to handle specific type
>>> # Option 1: Write custom collate function and invoke `default_collate`
>>> def custom_collate(batch):
... elem = batch[0]
... if isinstance(elem, CustomType): # Some custom condition
... return ...
... else: # Fall back to `default_collate`
... return default_collate(batch)
>>> # Option 2: In-place modify `default_collate_fn_map`
>>> def collate_customtype_fn(batch, *, collate_fn_map=None):
... return ...
>>> default_collate_fn_map.update(CustomType, collate_customtype_fn)
>>> default_collate(batch) # Handle `CustomType` automatically
"""
return collate(batch, collate_fn_map=default_collate_fn_map)5 dataloader
python
#### dataloader根据dataset和sampler, 以及collate_fn构建数据
class DataLoader(Generic[_T_co]):
def __init__():
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
collate_fn = _utils.collate.default_collate
def _get_iterator(self) -> _BaseDataLoaderIter:
if self.num_workers == 0:
return _SingleProcessDataLoaderIter(self)
else:
self.check_worker_number_rationality()
return _MultiProcessingDataLoaderIter(self)
class _SingleProcessDataLoaderIter(_BaseDataLoaderIter):
def __init__(self, loader):
self._dataset_fetcher = _DatasetKind.create_fetcher(
self._dataset_kind,
self._dataset,
self._auto_collation,
self._collate_fn,
self._drop_last,
)
def _next_data(self):
index = self._next_index() # may raise StopIteration
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
if self._pin_memory:
data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
return data
class _DatasetKind:
Map = 0
Iterable = 1
@staticmethod
def create_fetcher(kind, dataset, auto_collation, collate_fn, drop_last):
if kind == _DatasetKind.Map:
return _utils.fetch._MapDatasetFetcher(
dataset, auto_collation, collate_fn, drop_last
)
else:
return _utils.fetch._IterableDatasetFetcher(
dataset, auto_collation, collate_fn, drop_last
)
class _IterableDatasetFetcher(_BaseDatasetFetcher):
def __init__(self, dataset, auto_collation, collate_fn, drop_last):
super().__init__(dataset, auto_collation, collate_fn, drop_last)
self.dataset_iter = iter(dataset)
self.ended = False
def fetch(self, possibly_batched_index):
## 随机抽选几个数据到list,再整合结果
if self.auto_collation:
data = []
for _ in possibly_batched_index:
try:
data.append(next(self.dataset_iter))
except StopIteration:
self.ended = True
break
if len(data) == 0 or (
self.drop_last and len(data) < len(possibly_batched_index)
):
raise StopIteration
else:
data = next(self.dataset_iter)
return self.collate_fn(data)