简介
本文将解读FreeLong以及FreeLong++两篇论文。整体而言,这两篇文论都是通过将视频生成过程中的低频分量与高频分量分开处理实现的。FreeLong和FreeLong++的唯一区别在于将这些分量划分为两层还是三层。
另外,本文写于2025年9月,所有下文存在的问题均是该时间点存在的问题,若后续有更好的方法进行长视频生成,则本文可不必阅读。
长视频生成存在的问题及原因
现有的长视频生成方法大多数只能生成5-10s的视频。例如wan 2.1换算成帧数的话大概在81帧。如果在指定生成的帧数时强行将其指定为更高的帧数,如324帧,那么视频的整体结构还算稳定,但是细节上会有很大的问题,可能会过度平滑,如下图:

学过数字图像处理话,应该会知道图片可以通过2D傅立叶变换转到频域。且低频分量可以体现出图像的整体特征,如背景,结构;高频分量则更能体现出图像的细节,如边缘、毛发等。视频也可以通过3D傅立叶转换到频域,且低频分量和高频分量与上述特征一致。为此,论文作者将低频分量与高频分量进行了可视化,发现随着生成视频的时长增加,低频分量变化稳定、高频分量则质量下降严重:
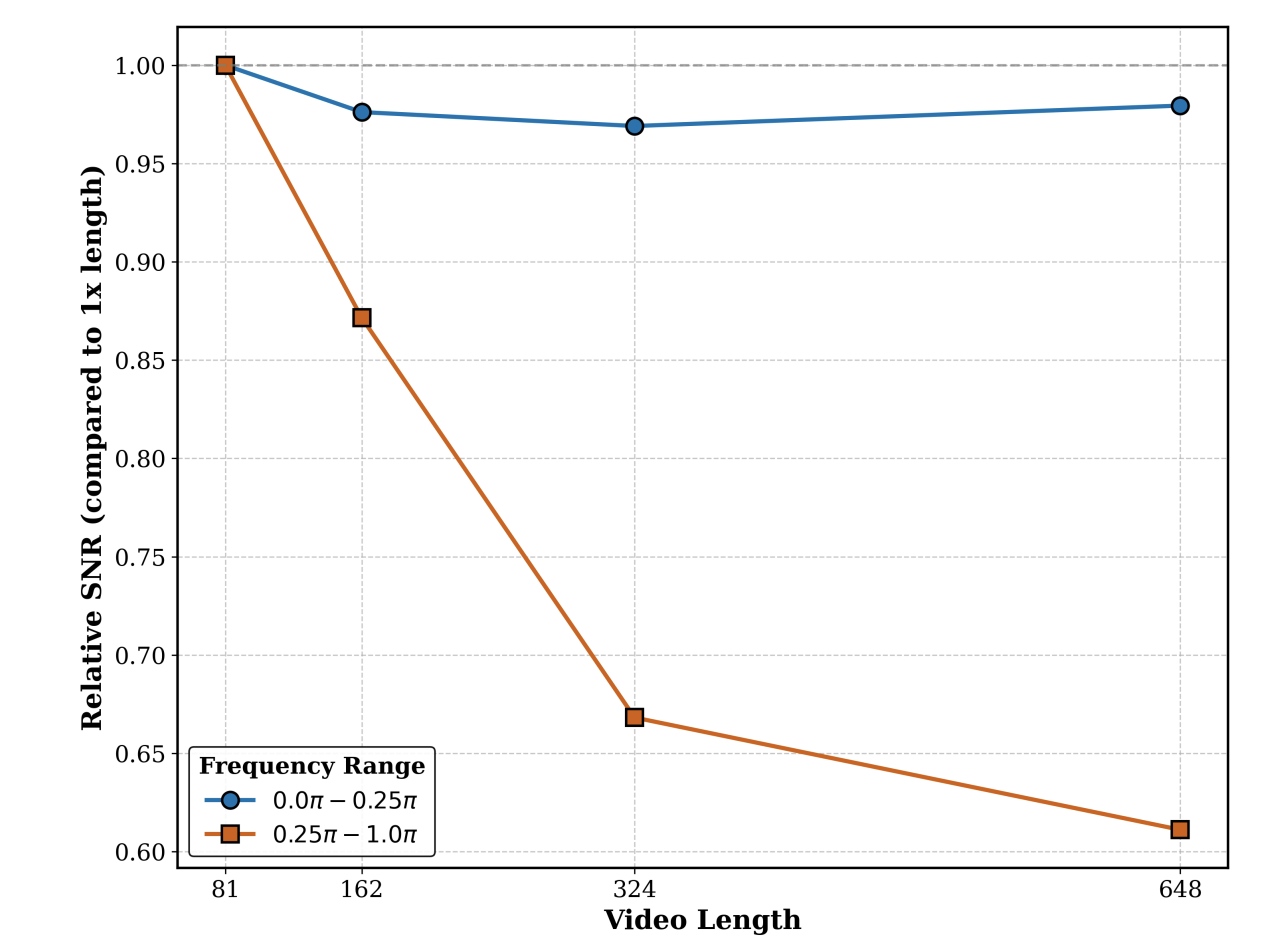
更进一步,论文作者认为这种变化与注意力机制有关,因此论文作者可视化了注意力图:
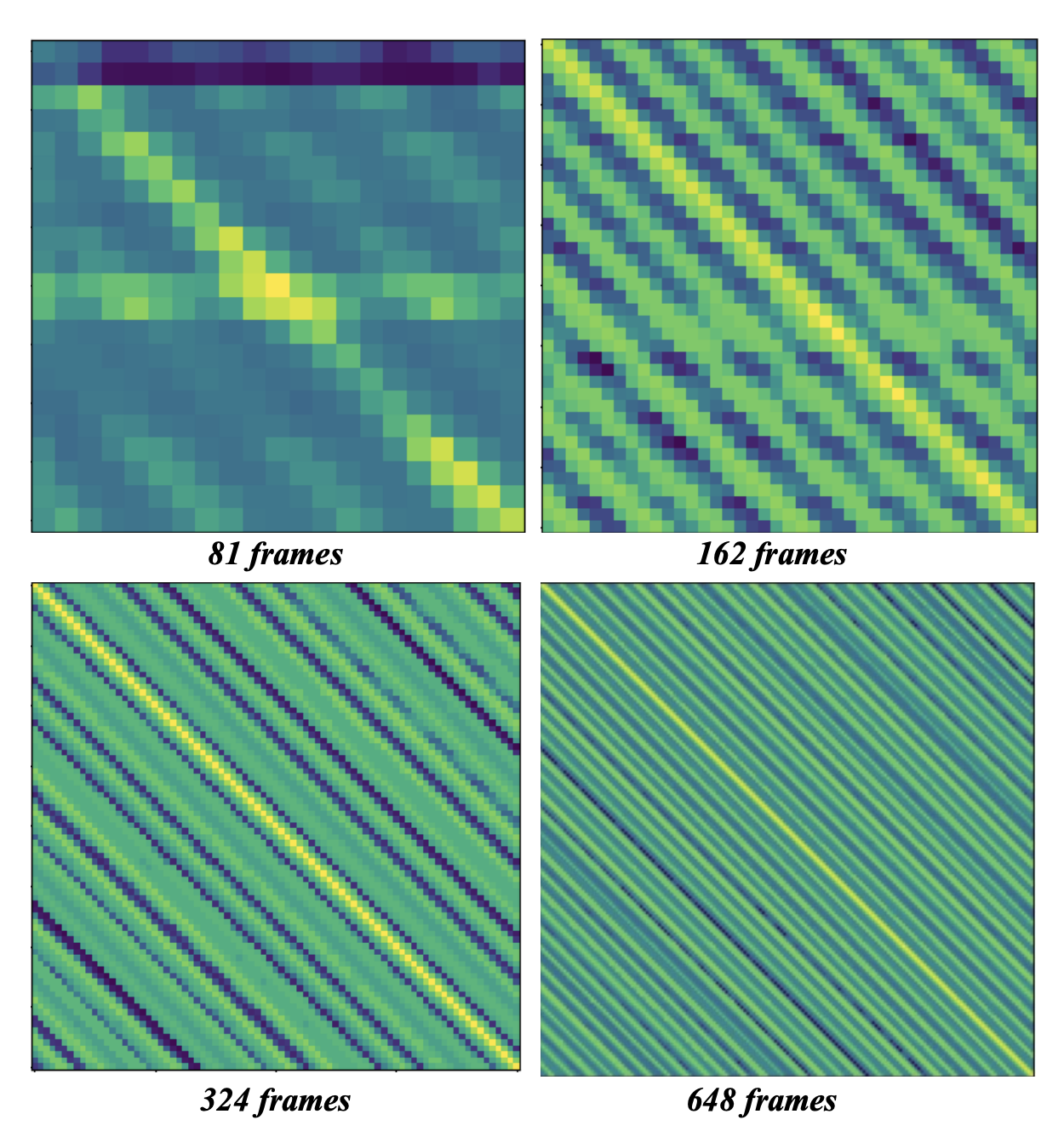
途中更亮的区域代表会有更高注意力得分。通常情况下,对角线区域的注意力得分应该最高,如81帧所示。但是随着帧数增加,模型会逐渐关注其他区域。论文作者认为这是导致长视频生成时过度平滑的根源。
笔者注:从笔者的视角来看的话,至少在wan2.1上,注意力图的问题应该是出在旋转位置编码,旋转位置编码虽然能够在没练过的长度上表现出一定的鲁棒性,但也是有其极限的。期待后续有更优秀的位置编码方案。本注释写于2025年9月。
解决方案
根据上一节的内容,我们已经知道了如下几件事:
- 长视频生成时整体结构还算稳定,但是细节模糊
- 长视频的低频分量稳定,高频分量失真
- 长视频的注意力图有问题
那么我们可以得到如下结论:
- 长视频的低频分量是可以直接用的
- 长视频的高频分量不能直接用,需要特殊处理
基于这个结论,作者提出了一种双分枝,或者说两层的结构,分别处理低频分量和高频分量:
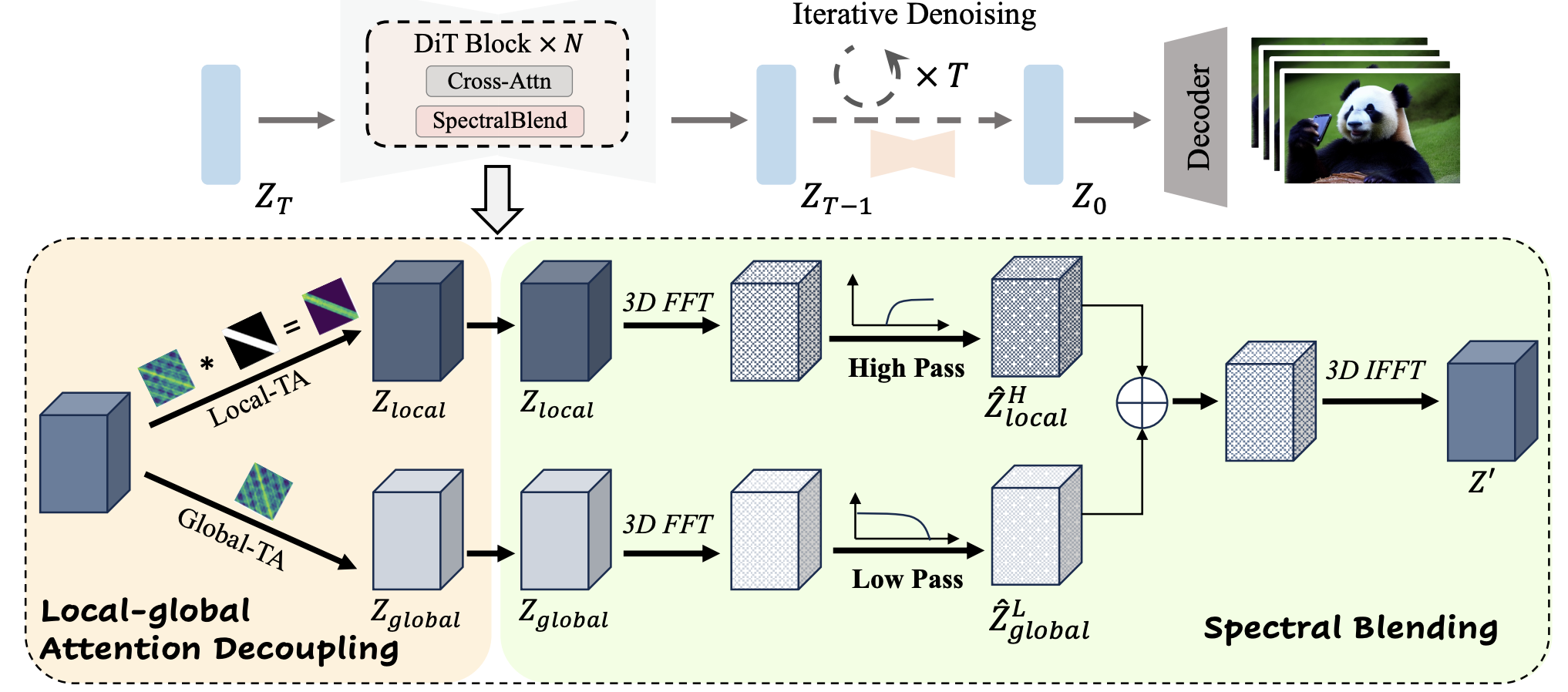
看起来挺复杂的,实质上就是在Dit层内,搞一个mask,mask整体上是对角线带的形式,如图中的Local-TA所示,然后这一部分会过3D傅立叶,并提取高频分量。另外一个分枝则不加mask,提取低频分量。然后将二者混合后恢复到空间域。
上述是freelong的主要结构。下面再看下freelong++。
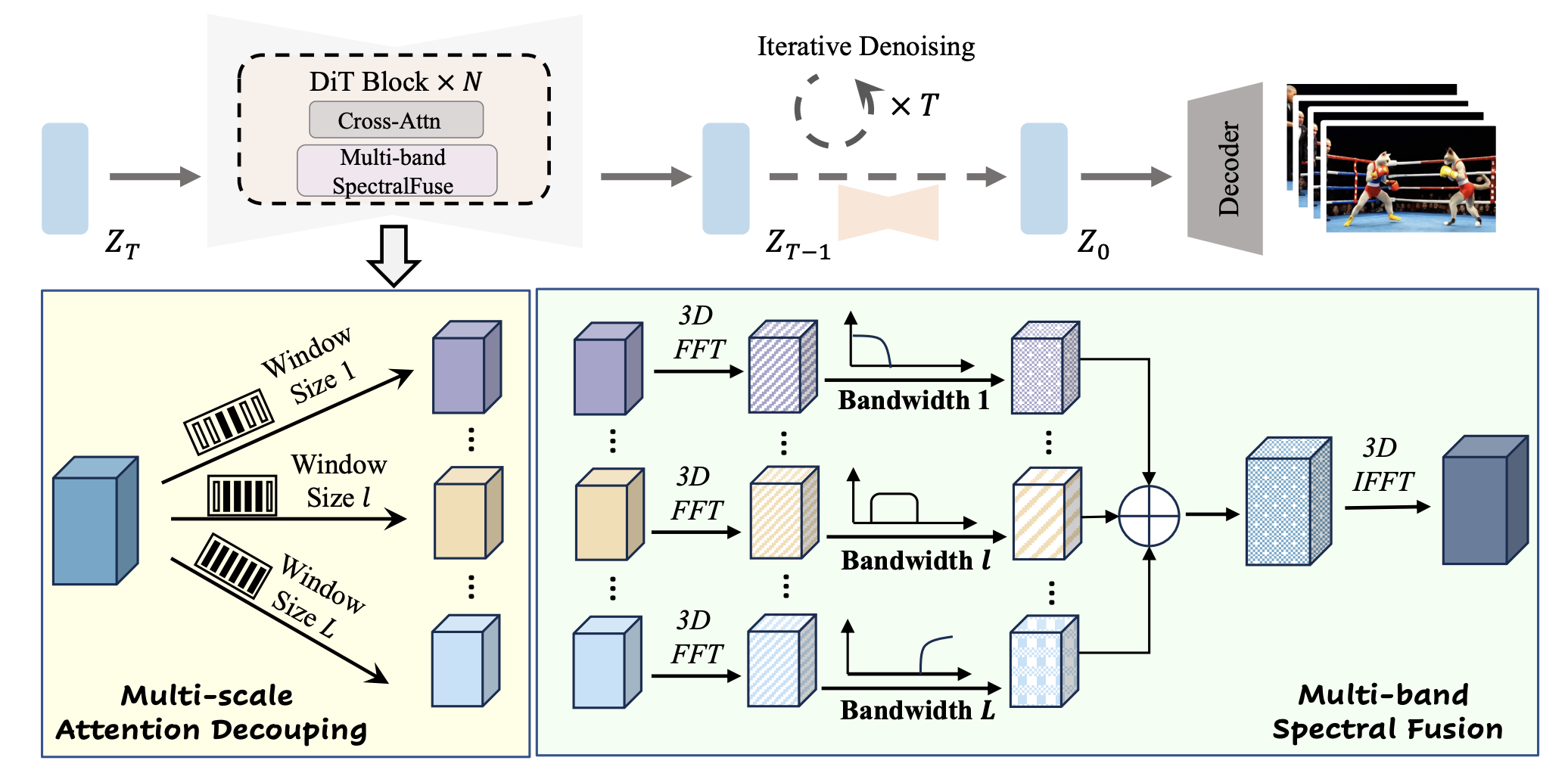
可以看到,应该只是单纯的把两层的结构换成了3层的结构,其余似乎并没有什么变化。截止到笔者写这篇文章时,FreeLong++的代码尚未开源,如果读者有兴趣的话,可以等代码开源后自行去查阅。
总结
效果就不展示了,论文中放出来的肯定都是好的效果。但是这篇论文讨论的原理看起来是非常有道理的。应该可以一定程度上解决长视频生成的问题。