声明:自己的学习笔记,仅供交流分享。
注意其中JDK版本的切换!
目录
[1. 清除数据库中的所有数据](#1. 清除数据库中的所有数据)
[2. 初始化 RDF 导入配置](#2. 初始化 RDF 导入配置)
[3. 导入 RDF 数据](#3. 导入 RDF 数据)
1、工具下载
1.1protege的安装
版本说明:Protégé-5.5.0
知识图谱_protege的安装_protege下载-CSDN博客
了解其基本使用
protege基本使用【小记】_protege使用-CSDN博客
1.2Neo4j的安装
1.梳理一下neo4j的安装的过程以及错误_错误: 找不到或无法加载主类 org.neo4j.server.startup.neo4jcomma-CSDN博客
2、Neo4j导入protege文件
2.1启动Neo4j
版本:JDK11
win+R 输入cmd
neo4j.bat console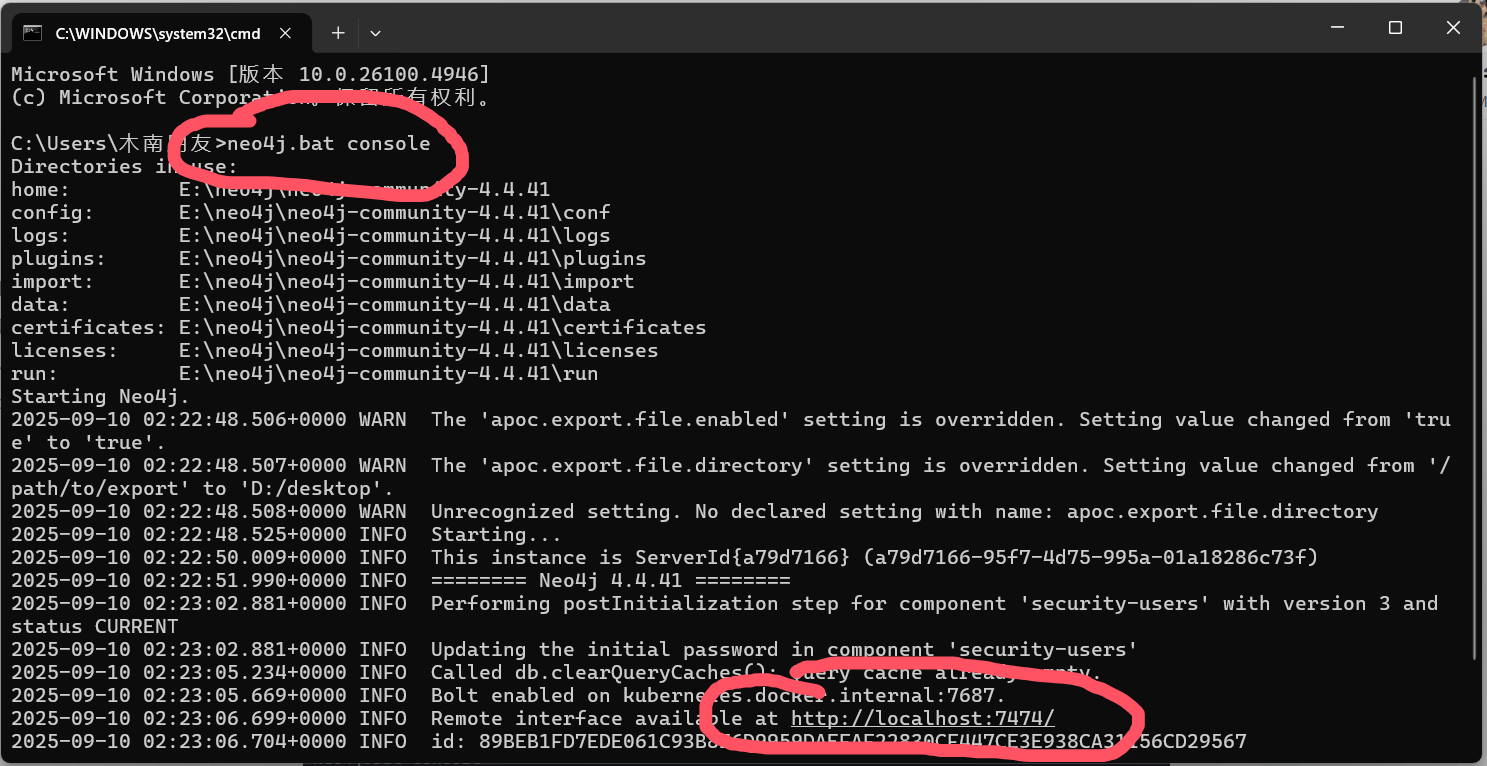
2.2protege导出owl文件转turtle文件
我在跟这个教程的时候,不是无法生成turtle文件就是生成的turtle文件为0KB,所以下面就进行自己的一些经验分享。
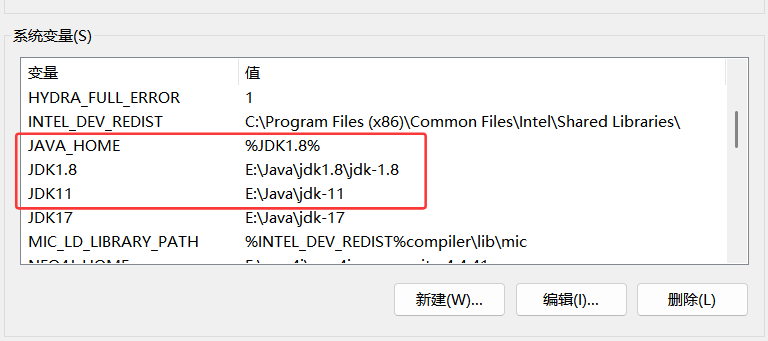
首先是JDK的版本,与启动Neo4j的Java版本不一样,所以这里又涉及到关于如何在电脑上配置多个Java的版本并实现切换。可以参考下面的这篇文章进行配置。简单来说,就是从官网上下载想要的两个Java版本,然后分别去配置系统变量。最后主要是通过修改JAVA_HOME这个的变量的变量值**%JDK1.8%**(这里表示的是变量JDK1.8),如果想切换为JDK11,则修改变量值为%JDK11%
windows安装两个或多个JDK,并实现自由切换_windows安装两个jdk-CSDN博客

其次再打开那位B站博主分享的文件,在他的视频简介里。将其下载存储倒本地。但不过我按照视频里面的教程做的时候,遇到了很多问题,要么就是转化之后的turtle文件的大小变为0KB,要么就是无法正常生成turtle文件。所以我采用了下面的方法,大家可以参考。
在这个文件夹里面,shift+鼠标右键会出现这个窗口,然后打开powershell,输入这串指令。后面的两个文件名可以替换,源文件为creature.owl,输出为creature.turtle。
java -jar rdf2rdf-1.0.1-2.3.1.jar creature.owl creature.turtle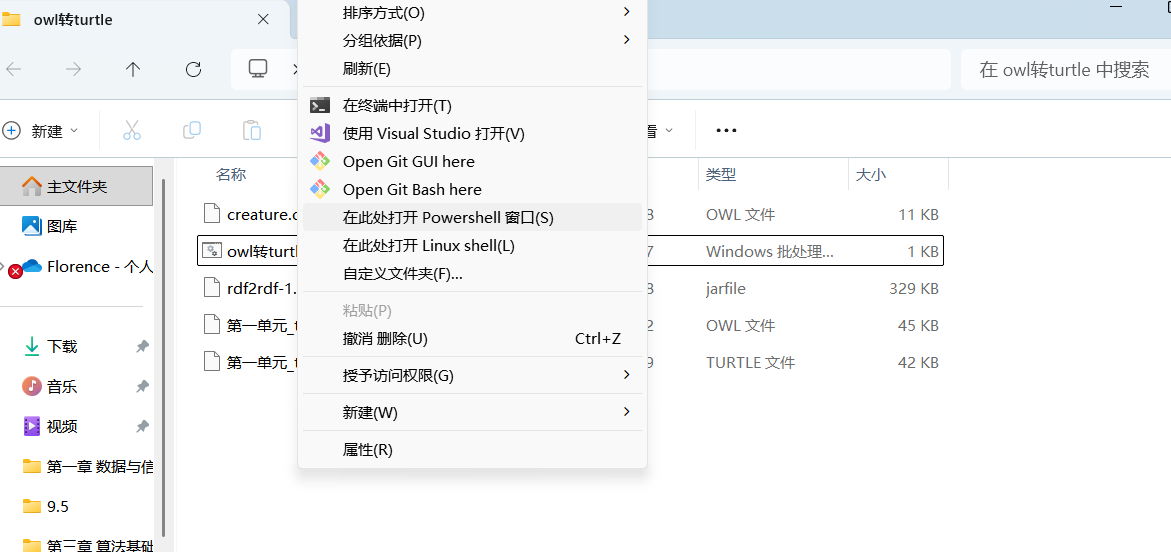
然后会提示已经完成了转化,所以在文件夹我们就可以看到转化后的文件了。
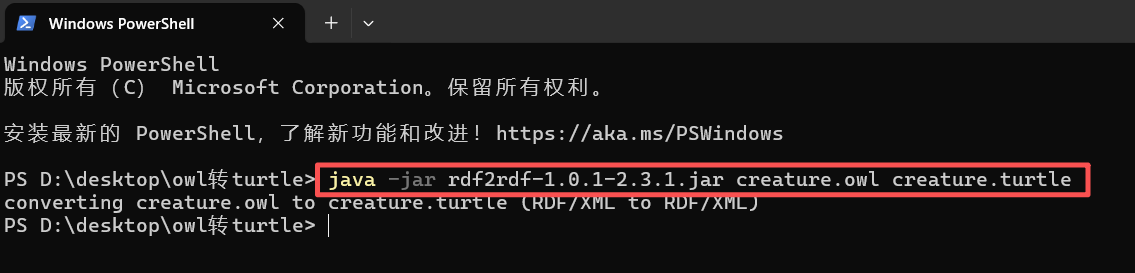
注意看转化后的文件大小是不是0KB,不是的话就说明转化成功了。
2.3导入Neo4j
1. 清除数据库中的所有数据
MATCH (n)
DETACH DELETE n;2. 初始化 RDF 导入配置
CALL n10s.graphconfig.init();3. 导入 RDF 数据
CALL n10s.rdf.import.fetch("file:///E:/BaiduNetdiskDownload/owl导入neo4j/第一单元_test.turtle", "RDF/XML", {handleVocabUris: "IGNORE"})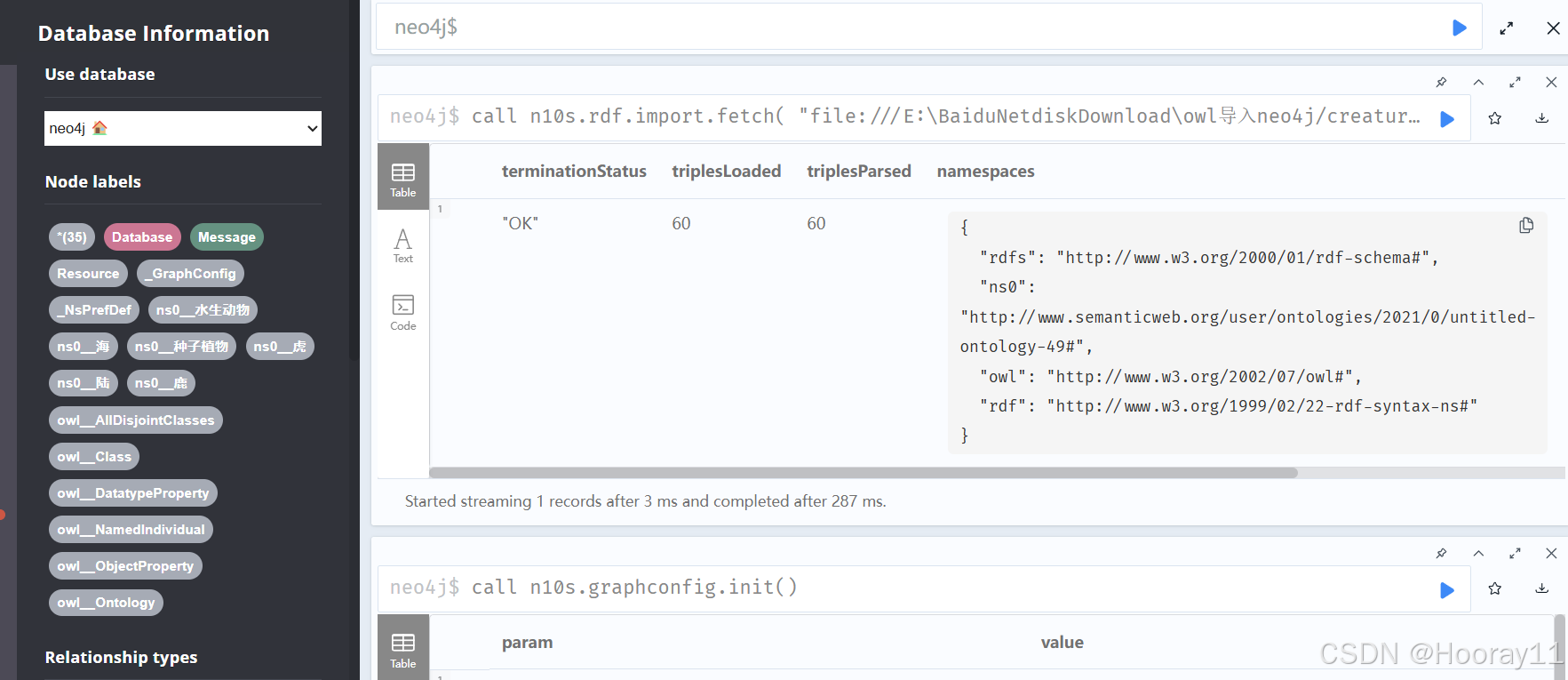
注意修改你自己的文件地址
4.查询所有(部分)数据
MATCH (n)
WHERE n:`节点名称1` OR n:`节点名称2` OR n:`节点名称3`
RETURN n LIMIT 500;5.查询边关系
MATCH ()-[r]->()
RETURN DISTINCT type(r) AS relationshipType6.一些细节
节点信息的uri有很长的前缀,怎么删除,用下面的指令。
MATCH (n)
SET n.uri = REPLACE(n.uri, 'http://www.semanticweb.org/florence/ontologies/2025/1/untitled-ontology-9#', '')
RETURN n注意更换你自己的uri前缀。下面的uri就没有前缀了。

3、Neo4j导出JSON文件
导出JSON文件的目的是方便后面利用Echarts进行可视化。需要借用到APOC库。关于他的下载可以自己去网上搜搜,如果后面找到了我当时看的文章,会再更新的。
所以先下载APOC库,再进行后续操作。
这一步可以检验是否下载成功。
RETURN apoc.version()导出文件。
CALL apoc.export.json.query(
"MATCH (n) WHERE n:`节点名称1` OR n:`节点名称2` OR n:`节点名称3` OPTIONAL MATCH (n)-[r]->(m) RETURN n, r, m LIMIT 500",
"file:///E:/neo4j/neo4j-community-4.4.41/import/output_3.0.json",
{format: 'PLAIN'}
)这个代码的主体包括
第一行:查询所有节点+匹配关系+返回所有信息
第二行:导出文件路径及文件名称
第三行:指定导出的格式为 PLAIN,即简单的 JSON 格式
至此,原始数据已经获得。下面将进行数据的处理,然后利用Echarts和VUE实现前端可视化,由于该项目主要与教育领域有关,所有后面这个案例就是教育领域的了,如果大家已经成功完成了上述的所有尝试,那么可以尝试形成自己的文件了。
4、可视化前的操作
4.1利用python对数据进行处理
在导入Echarts之前,我们发现从neo4j导出的JSON文件并不符合Echarts的数据格式,所以我们需要利用Python对数据进行处理。
以下是原始的JSON数据,是不符合Echarts的数据格式的。
Matlab
{
"n": {
"type": "node",
"id": "2",
"labels": [
"Resource",
"课名称",
"owl__NamedIndividual"
],
"properties": {
"描述": "算法的多分支结构,判断闰年的规则",
"编号": 3.3,
"名称": "闰年平年我知道(1)",
"所属知识单元": "用算法解决问题",
"对应课标内容": "(1)借助学习与生活中的实例,体验身边的算法,理解算法是通过明确的、可执行的操作步骤描述的问题求解方案, 能用自然语言、流程图等方式描述算法。(2)结合生活中的实例,了解算法的顺序、分支和循环三种基本控制结构,能分析简单算法的执行过程与结果。",
"所属类型": "课名称",
"uri": "闰年平年我知道(1)"
}
},
"r": {
"id": "69",
"type": "relationship",
"label": "父子",
"start": {
"id": "2",
"labels": [
"Resource",
"课名称",
"owl__NamedIndividual"
]
},
"end": {
"id": "101",
"labels": [
"Resource",
"知识元",
"owl__NamedIndividual"
]
}
},
"m":下面是python代码。记得修改输入和输出文件的地址
python
import json
def convert_to_echarts_data(file_path):
# 加载Neo4j导出的JSON数据
with open(file_path, 'r', encoding='utf-8') as f:
neo4j_data = json.load(f)
# 初始化ECharts数据
echarts_data = {
"nodes": [],
"links": []
}
# 节点处理
node_map = {} # 用于去重和避免重复添加节点
for item in neo4j_data:
node = item.get("n", None)
if node:
node_id = node.get("id")
node_labels = node.get("labels", [])
node_properties = node.get("properties", {})
node_name = node_properties.get("名称", node_properties.get("name", node_id))
node_uri = node_properties.get("uri", node_id)
# 创建或更新节点
if node_id not in node_map:
echarts_node = {
"id": node_id,
"name": node_name,
"category": node_labels[1] if node_labels else "其他",
"value": node_uri,
"properties":node_properties
}
echarts_data["nodes"].append(echarts_node)
node_map[node_id] = echarts_node
m_node = item.get("m", None)
if m_node:
node_id = m_node.get("id")
node_labels = m_node.get("labels", [])
node_properties = m_node.get("properties", {})
node_name = node_properties.get("名称", node_properties.get("name", node_id))
node_uri = node_properties.get("uri", node_id)
# 创建或更新节点
if node_id not in node_map:
echarts_node = {
"id": node_id,
"name": node_name,
"category": node_labels[1] if node_labels else "其他",
"value": node_uri,
"properties": node_properties
}
echarts_data["nodes"].append(echarts_node)
node_map[node_id] = echarts_node
# 边处理
for item in neo4j_data:
relationship = item.get("r", None)
if relationship:
start_node = item.get("r").get("start")
start_id = start_node.get("id")
end_node = item.get("r").get("end")
end_id = end_node.get("id")
relationship_label = relationship.get("label")
# 创建边对象
echarts_link = {
"source": start_id,
"target": end_id,
"value": relationship_label,
}
echarts_data["links"].append(echarts_link)
return echarts_data
# 将转换后的数据保存为文件
if __name__ == "__main__":
input_file = r"E:\neo4j\neo4j-community-4.4.41\import\output_4.0.json"
output_file = "converted_data2.0.json"
echarts_data = convert_to_echarts_data(input_file)
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(echarts_data, f, ensure_ascii=False, indent=4)
print(f"数据已成功转换并保存到 {output_file}")最后输出的是这样的JSON数据。
Erlang
"nodes": [
{
"id": "2",
"name": "闰年平年我知道(1)",
"category": "课名称",
"value": "闰年平年我知道(1)",
"properties": {
"描述": "算法的多分支结构,判断闰年的规则",
"编号": 3.3,
"名称": "闰年平年我知道(1)",
"所属知识单元": "用算法解决问题",
"对应课标内容": "(1)借助学习与生活中的实例,体验身边的算法,理解算法是通过明确的、可执行的操作步骤描述的问题求解方案, 能用自然语言、流程图等方式描述算法。(2)结合生活中的实例,了解算法的顺序、分支和循环三种基本控制结构,能分析简单算法的执行过程与结果。",
"所属类型": "课名称",
"uri": "闰年平年我知道(1)"
}
},
.....
"links": [
{
"source": "2",
"target": "101",
"value": "父子"
},4.2学习VUE&Echarts
250924
更新结束,下次有机会继续更新。