摘要
随着无人机技术在民用与商用领域的快速普及,其在禁飞区域的非法活动已成为公共安全与空域管理的重要挑战。本文提出一种基于计算机视觉与深度学习的自动化解决方案,通过改进YOLOv8模型实现对无人机的实时检测与轨迹跟踪。研究采用Roboflow平台的无人机专用数据集进行模型微调,构建了一套完整的从数据预处理、模型训练到实时推理的技术流程。实验结果表明,该系统在复杂场景下仍能保持87%的检测精确率与81%的召回率,可有效集成至安防监控系统,为低空域安全提供智能化预警支持。
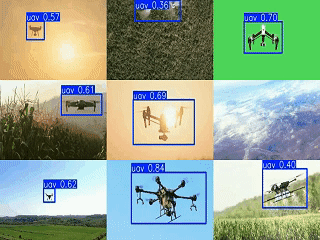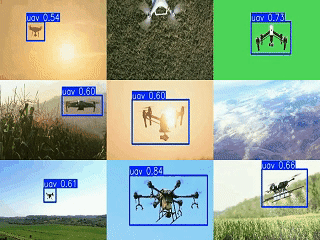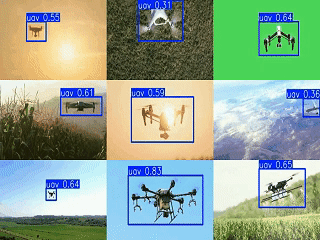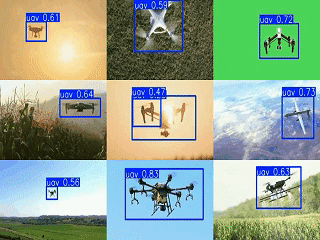
1. 引言
1.1 研究背景与意义
无人机技术的飞速发展使其在航拍测绘、物流运输、应急救援等领域得到广泛泛应用,但同时也带来了未经授权入侵敏感区域(如机场、军事基地、政府机关)的安全隐患。传统人工监控方式存在响应延迟、人力成本高、易疲劳误判等局限,亟需自动化的无人机检测与跟踪系统。
基于深度学习的目标检测技术为该问题提供了有效解决方案。YOLO(You Only Look Once)系列模型凭借其端到端的检测架构和优异的实时性能,已成为实时目标检测领域的主流选择。其中YOLOv8作为最新迭代版本,在精度与速度的平衡上实现了进一步突破,具备部署于安防监控场景的技术潜力。
1.2 研究目标与主要贡献
本文旨在构建一套基于YOLOv8的无人机检测与跟踪系统,主要贡献包括:
- 优化了针对无人机检测的模型训练策略,实现了预训练模型的高效微调
- 设计了多视频源实时监控的网格可视化方案,提升了安防监控的直观性
- 验证了系统在复杂环境下的鲁棒性,为实际安防场景的部署提供了技术参考
2. 系统环境配置与数据集准备
2.1 软硬件环境要求
本系统的运行依赖以下软硬件环境:
2.1.1 软件依赖
核心Python库包括计算机视觉处理、数值计算、深度学习框架等,具体列表如下:
- 图像处理:
opencv-python(OpenCV) - 数值计算:
numpy、pandas - 可视化工具:
matplotlib、imageio - 深度学习框架:
ultralytics(YOLOv8官方库)
安装命令如下:
bash
pip install opencv-python numpy pandas matplotlib imageio ultralytics2.1.2 硬件加速支持
为提升模型训练与推理效率,建议配置GPU加速:
- NVIDIA GPU:支持CUDA计算架构,可通过
torch.cuda.is_available()检测 - Apple Silicon(M1/M2系列):支持Metal Performance Shaders(MPS),可通过
torch.backends.mps.is_available()检测 - 若无GPU支持,可使用CPU运行(性能会显著下降)
2.2 数据集获取与预处理
2.2.1 数据集来源
实验采用Roboflow平台公开的无人机检测数据集(UAV Detection Dataset),该数据集包含4,950张带标注的无人机图像,标注信息采用归一化边界框坐标(范围0-1),可适应不同尺寸的图像输入。
2.2.2 数据集构成
数据集已预先划分为训练集与验证集,具体分布如下:
- 训练图像总数:3,958张
- 无无人机图像数:506张(12.8%)
- 单无人机图像数:3,180张(80.3%)
- 多无人机图像数:272张(6.9%)
- 每张图像平均无人机数:1.04个
这种数据分布设计增强了模型对复杂场景的适应能力,特别是对"无目标"情况的识别能力,可有效降低误报率。
2.2.3 数据集配置文件
从Roboflow下载数据集时需选择YOLOv8导出格式,获取的data.yaml配置文件需放置于项目根目录,内容如下:
yaml
train: ./data/train/images
val: ./data/valid/images
nc: 1
names: ['uav']
roboflow:
workspace: dronedetection-jkeyg
project: uav-detection-zlcin-1wcbm
version: 1
license: CC BY 4.0
url: https://universe.roboflow.com/dronedetection-jkeyg/uav-detection-zlcin-1wcbm/dataset/13. 模型训练与优化
3.1 YOLOv8模型选择
YOLOv8提供多种预训练模型变体,本研究考虑不同硬件条件下的部署需求,选择yolov8n.pt(纳米版)作为基础模型,其特点是模型体积小、推理速度快,适合边缘设备部署。各变体对比见表1:
| 模型变体 | 输入尺寸 | 参数量 | 推理速度 | 适用场景 |
|---|---|---|---|---|
| yolov8n.pt | 640×640 | 3.2M | 最快 | 边缘设备/实时监控 |
| yolov8s.pt | 640×640 | 11.2M | 快 | 平衡速度与精度 |
| yolov8m.pt | 640×640 | 25.9M | 中 | 中等性能设备 |
| yolov8l.pt | 640×640 | 43.7M | 慢 | 高性能GPU |
| yolov8x.pt | 640×640 | 68.2M | 最慢 | 服务器级GPU |
3.2 模型训练参数设置
采用迁移学习策略,基于预训练模型在无人机数据集上进行微调,训练代码如下:
python
from ultralytics import YOLO
import os
# 加载预训练模型
model = YOLO("yolov8n.pt") # 从互联网下载模型
# model = YOLO("./yolov8n.pt") # 使用本地模型
# 模型训练配置
results = model.train(
data="data.yaml", # 数据集配置文件路径
epochs=80, # 训练轮次
imgsz=120, # 输入图像尺寸(加速训练)
batch=16, # 批次大小
device="mps", # 计算设备('cpu'/'0'/'mps')
workers=max(1, os.cpu_count() - 1) # 数据加载进程数
)关键参数说明:
epochs=80:经过实验验证,80轮训练可在精度与训练时间间取得平衡imgsz=120:为加速训练采用的缩减尺寸,实际部署时可使用更大尺寸(如640×640)workers:设置为CPU核心数减1,避免系统资源耗尽
3.3 训练结果分析
在Apple MacBook M1设备上,80轮训练耗时约5.2小时。训练过程中主要监控以下指标:
- 损失函数:边界框损失(
box_loss)、分类损失(cls_loss)、分布焦点损失(dfl_loss) - 评估指标:精确率(Precision)、召回率(Recall)、平均精度均值(mAP@0.5、mAP@0.5:0.95)
最终训练结果:
- 精确率:0.87(预测为无人机的样本中实际为无人机的比例)
- 召回率:0.81(实际为无人机的样本中被正确检测的比例)
- mAP@0.5:0.86(IoU阈值为0.5时的平均精度)
训练曲线如图3所示,损失函数呈现持续下降趋势,表明模型仍有提升空间,可通过增加训练轮次或使用更大模型(如yolov8s.pt)进一步优化性能。
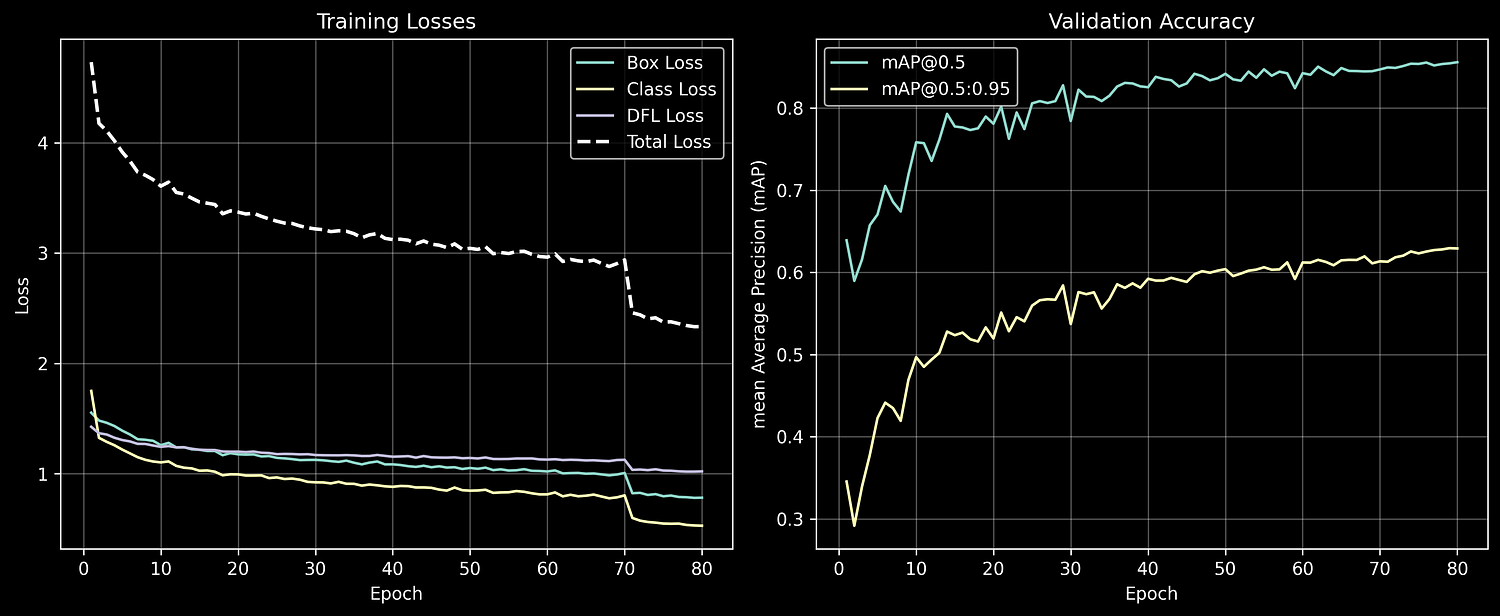
图3:训练指标图表(损失曲线与精度曲线)
4. 实时检测与跟踪实现
4.1 视频推理与结果保存
模型训练完成后,使用最优权重(best.pt)对测试视频进行推理,代码如下:
python
import os
from ultralytics import YOLO
# 指定模型版本与路径
TRAINING = "train7"
model = YOLO(f"runs/detect/{TRAINING}/weights/best.pt") # 加载最优权重
# 输入输出路径配置
input_folder = "./videos_resized_cropped"
output_folder = "./videos_pred"
os.makedirs(output_folder, exist_ok=True)
# 批量处理视频文件
for filename in os.listdir(input_folder):
if filename.endswith(".mov"):
input_path = os.path.join(input_folder, filename)
output_path = os.path.join(output_folder, filename)
# 视频推理
results = model.predict(
source=input_path,
save=True, # 保存带检测框的视频
save_txt=True, # 保存预测标签(YOLO格式)
project=output_folder,
name=filename.split(".")[0], # 为每个视频创建单独文件夹
exist_ok=True # 允许覆盖现有文件
)推理过程中,系统会自动在视频帧中绘制无人机边界框,并保存处理后的视频及详细预测数据(包括边界框坐标、置信度等)。
4.2 多视频源网格可视化
为实现多摄像头监控的集中展示,设计了3×3网格的视频汇总方案,将多个检测结果同步显示为GIF动画:
python
import cv2
import numpy as np
import imageio
import os
# 配置参数
input_folder = "./videos_pred"
output_file = "videos_grid_5s.gif"
frame_width, frame_height = 300, 225 # 单个视频帧尺寸
grid_width = frame_width * 3 # 网格宽度(3列)
grid_height = frame_height * 3 # 网格高度(3行)
fps = 10 # GIF帧率
max_frames = fps * 5 # 总时长5秒
# 收集视频文件
video_files = []
for root, dirs, files in os.walk(input_folder):
for file in files:
if file.endswith(".mp4"):
video_files.append(os.path.join(root, file))
# 取前9个视频构建网格
video_files = sorted(video_files)[:9]
num_videos = len(video_files)
caps = [cv2.VideoCapture(v) for v in video_files]
# 帧处理与网格合成
finished = [False] * num_videos
frames_list = []
while not all(finished) and len(frames_list) < max_frames:
frames = []
for i, cap in enumerate(caps):
if finished[i]:
# 视频结束后填充黑色帧
frames.append(np.zeros((frame_height, frame_width, 3), dtype=np.uint8))
continue
ret, frame = cap.read()
if not ret:
finished[i] = True
frames.append(np.zeros((frame_height, frame_width, 3), dtype=np.uint8))
else:
# 调整尺寸并转换色彩空间
frame = cv2.resize(frame, (frame_width, frame_height))
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frames.append(frame)
# 构建3×3网格
grid_rows = [np.hstack(frames[i:i+3]) for i in range(0, 9, 3)]
grid_frame = np.vstack(grid_rows)
frames_list.append(grid_frame)
# 释放资源
for cap in caps:
cap.release()
# 保存GIF
imageio.mimsave(output_file, frames_list, duration=1/fps, loop=0)
print(f"网格GIF已保存为 {output_file}")该方案通过同步多视频源帧、统一尺寸缩放和网格拼接,实现了多区域无人机活动的集中监控,便于安防人员快速掌握全局态势。
5. 系统应用与扩展
5.1 安防场景集成
本系统可与现有安防体系无缝集成,实现以下功能:
- 实时空域监控:对接多路摄像头,实现全天候无人机检测
- 自动警报触发:当检测到无人机进入禁飞区时,触发声光警报或通知管理人员
- 轨迹追踪与预测:记录无人机运动路径,预测其飞行轨迹,辅助决策响应措施
5.2 系统优化方向
未来可从以下方面提升系统性能:
- 模型优化:尝试更大的YOLOv8变体(如yolov8s.pt)或采用模型量化技术提升推理速度
- 数据增强:增加恶劣天气(雨、雾)、复杂背景下的无人机样本,提升模型鲁棒性
- 多目标跟踪:集成SORT或DeepSORT算法,实现无人机跨帧跟踪与ID分配
- 边缘部署:通过TensorRT或ONNX Runtime优化,部署于嵌入式边缘设备
6. 结论
本文提出的基于YOLOv8的无人机检测与跟踪系统,通过迁移学习实现了模型的高效训练,在测试数据集上取得了87%的精确率和81%的召回率。系统设计的多视频网格可视化方案为安防监控提供了直观的全局视图,具备实际应用价值。
随着无人机技术的持续发展,空域安全管理将面临更复杂的挑战。本研究为智能化无人机监控提供了可行方案,未来通过持续优化模型性能与扩展系统功能,有望在机场、核电站、大型活动场馆等敏感区域的安防体系中发挥重要作用。