本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
近年来,大型语言模型 (LLM) 如雨后春笋般涌现,它们在各种任务中展现出惊人的能力。然而,即使是再强大的 LLM 也并非完美无缺。它们可能会缺乏特定领域的知识,或者在处理一些需要最新信息的任务时表现不佳。为了解决这些问题,RAG (检索增强生成) 和 Fine-tuning (微调) 成为提升 LLM 性能的关键技术。
由nano-banana生成
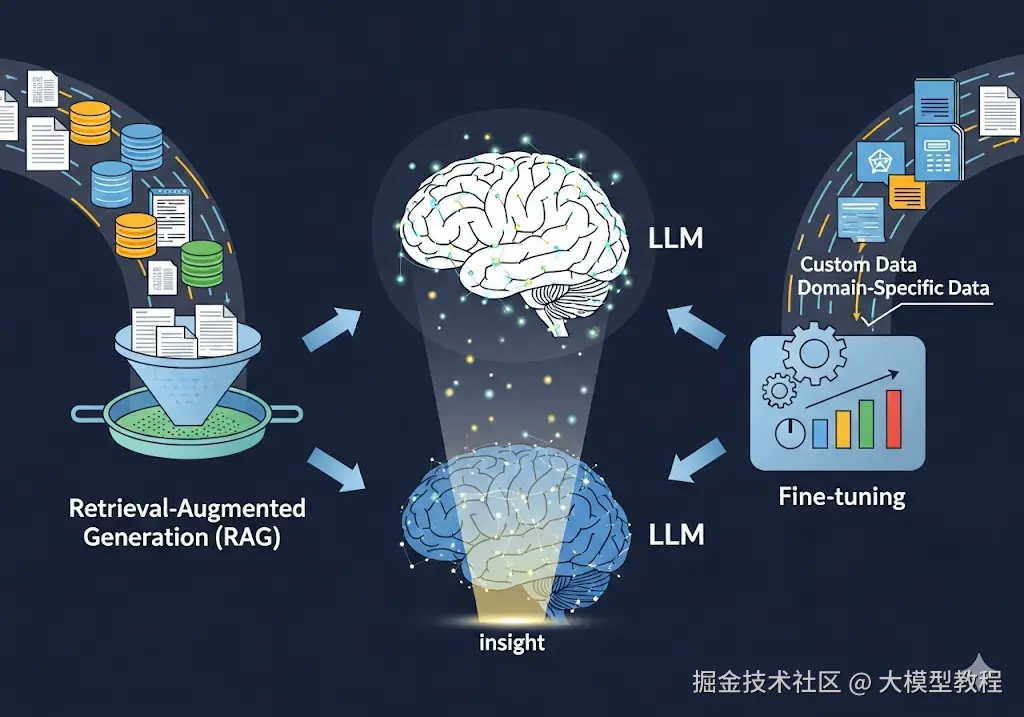
1 什么是RAG和Fine tuning?
RAG 即检索增强生成,它就像给 LLM 配备了一个巨大的外部知识库。当用户提出问题时,RAG 系统首先从知识库中检索相关的信息,然后将这些信息与用户的问题一起输入 LLM。LLM 利用检索到的信息来生成更准确、更相关的回答。RAG 的优势在于能够让 LLM 利用最新的信息,以及特定领域的信息。例如,如果我想知道某家公司的最新财报数据,传统的 LLM 可能无法提供准确的答案,因为它的知识可能过时了。但通过 RAG,LLM 可以从最新的财报文档中检索信息,并生成准确的回答。
scss
# 简单的 RAG 工作流程def rag_query(user_question): # Step 1: 检索相关文档 relevant_docs = vector_search(user_question, knowledge_base) # Step 2: 将上下文与问题结合 enhanced_prompt = f"Context: {relevant_docs}\nQuestion: {user_question}" # Step 3: 使用上下文生成回复 return llm.generate(enhanced_prompt)Fine-tuning即微调技术,它 则是一种更直接的方法,它通过使用特定的数据集来训练 LLM,让它更好地完成特定的任务。例如,我们可以使用医学领域的文本数据来 fine-tune 一个 LLM,让它更擅长处理医学相关的任务,如疾病诊断、药物推荐等。实际上是在用特定的数据重新训练神经网络的某些部分,从而永久地改变它的思考和反应方式。Fine-tuning 的优势在于能够提高 LLM 在特定领域的表现。与从头开始训练一个模型相比,Fine-tuning 更加高效、经济。
javascript
# 简单的微调工作流程from transformers import GPT2LMHeadModel, GPT2Tokenizer, TrainingArgumentsmodel = GPT2LMHeadModel.from_pretrained('gpt2')tokenizer = GPT2Tokenizer.from_pretrained('gpt2')# 特定领域训练数据training_args = TrainingArguments( output_dir='./fine-tuned-model', num_train_epochs=3, per_device_train_batch_size=4, warmup_steps=500,)2 RAG和Fine tuning的区别所在
2.1 处理速度
微调技术通过牺牲部分内存占用,实现了更快的推理速度,从而在响应时间上更具优势。相比之下,RAG系统由于需要在生成答案之前执行一个检索步骤,不可避免地会引入额外的延迟,导致整体响应时间变长。一般情况下的响应时间如下:
- 微调模型:50-200 毫秒
- RAG 系统:200-800 毫秒(包含检索)
因此,对于实时聊天或高流量 API 等需要快速响应的应用,微调通常在速度上更具优势。 这些应用场景对延迟非常敏感,即使是细微的延迟也会影响用户体验,所以微调带来的速度优势至关重要。
2.2 准确性
对于准确率而言,微调技术展现出了显著的优势,它能够有效地提升各种不同受欢迎程度实体的表现,并且这种提升在实体两端表现得尤为突出。 相比之下,微调在准确率上的表现也要优于其他各种方法。 不过,总体而言,在追求更高准确率的场景下,微调可能是一种更具合理的选择。
微调适用于:
- 需要一致的领域特定语言和术语
- 用例模式清晰、稳定
- 对特定任务的准确性要求极高
RAG 更适用于:
- 信息频繁更新
- 需要引用来源
- 需要整合跨领域知识
2.3 成本
微调 (Fine-tuning) 的成本:
- 前期成本较高:
-
数据准备:
需要准备高质量、与特定任务相关的数据集。 数据收集、清洗、标注都需要花费时间和精力,可能需要人工介入,成本较高。
-
计算资源:
微调通常需要大量的计算资源 (GPU 或 TPU)。 训练大型模型需要强大的硬件支持,以及相当长的训练时间,这导致成本的增加。
-
模型选择和实验存储:
可能需要尝试不同的预训练模型和微调策略,以找到最适合特定任务的模型。 这个过程需要时间和计算资源。
- 后期成本较低:
-
推理成本:
微调后的模型通常可以快速进行推理,推理成本相对较低。
-
维护成本:
模型一旦训练完成,维护成本相对较低,主要在于定期评估模型性能,并在必要时进行重新训练。
RAG (检索增强生成) 的成本:
- 前期成本较低:
-
数据准备:
RAG 可以利用现有的知识库或文档,无需进行大量的标注工作。 数据准备成本主要在于构建和维护知识库,例如建立向量索引。
-
计算资源:
RAG 对计算资源的要求相对较低,只需要足够的资源来运行检索和生成模型即可。
- 后期成本较高:
-
检索成本:
每次查询都需要进行检索,检索过程会占用计算资源,并可能产生一定的延迟。 当并发请求量较大时,检索成本会显著增加。
-
知识库维护:
知识库需要定期更新和维护,以保证信息的准确性和时效性。 知识库的维护包括数据更新、索引重建、错误修复等,需要持续投入资源。
-
存储成本:
需要存储知识库,尤其是当知识库规模较大时,存储成本会增加。
3 所以,如何进行最终的选择?
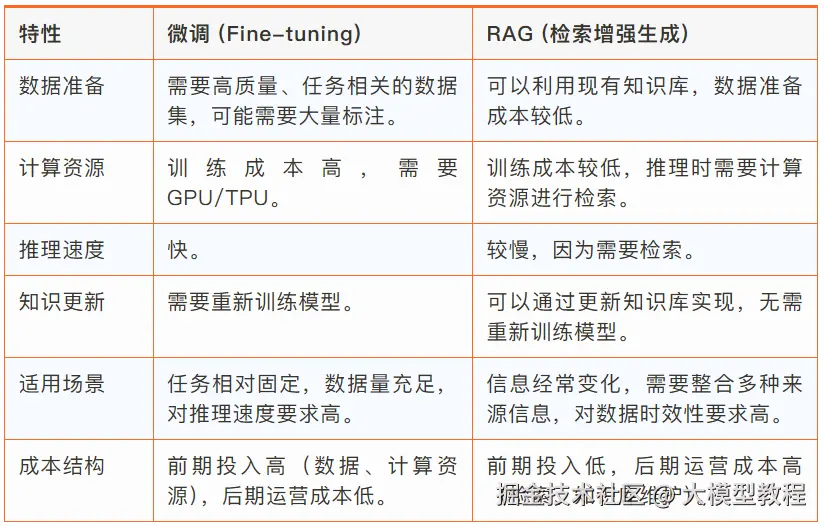
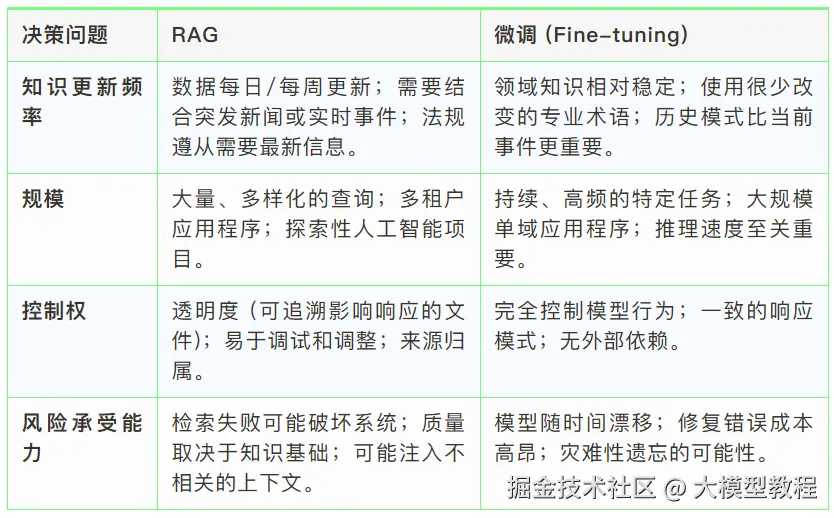
坦率地说,可能并没有一个适用于所有情况的、放之四海而皆准的绝对"正确"的选择方案。 任何技术或方法的优劣,都不能一概而论,最佳的策略选择实际上是高度情境化的。
也就是说,最适合你的方法,最终取决于你的特定情况、你所面临的各种实际限制条件,以及你希望达成的具体目标。 这些因素共同决定了哪种方案能够最大程度地满足你的需求并实现预期的效果。
因此,在做出任何决策之前,务必对自身的情况进行全面而深入的评估,充分考虑各种限制,并明确最终的目标,才能选择到最适合的解决方案。
希望上面的知识和表格可以对你的选择有些许的帮助......
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。