任务:Using self-attention to predict speaker class from given speech
基准
- Simple public baseline: 0.60824
- Medium : 0.70375
- Strong : 0.77750
- Boss : 0.86500
结果
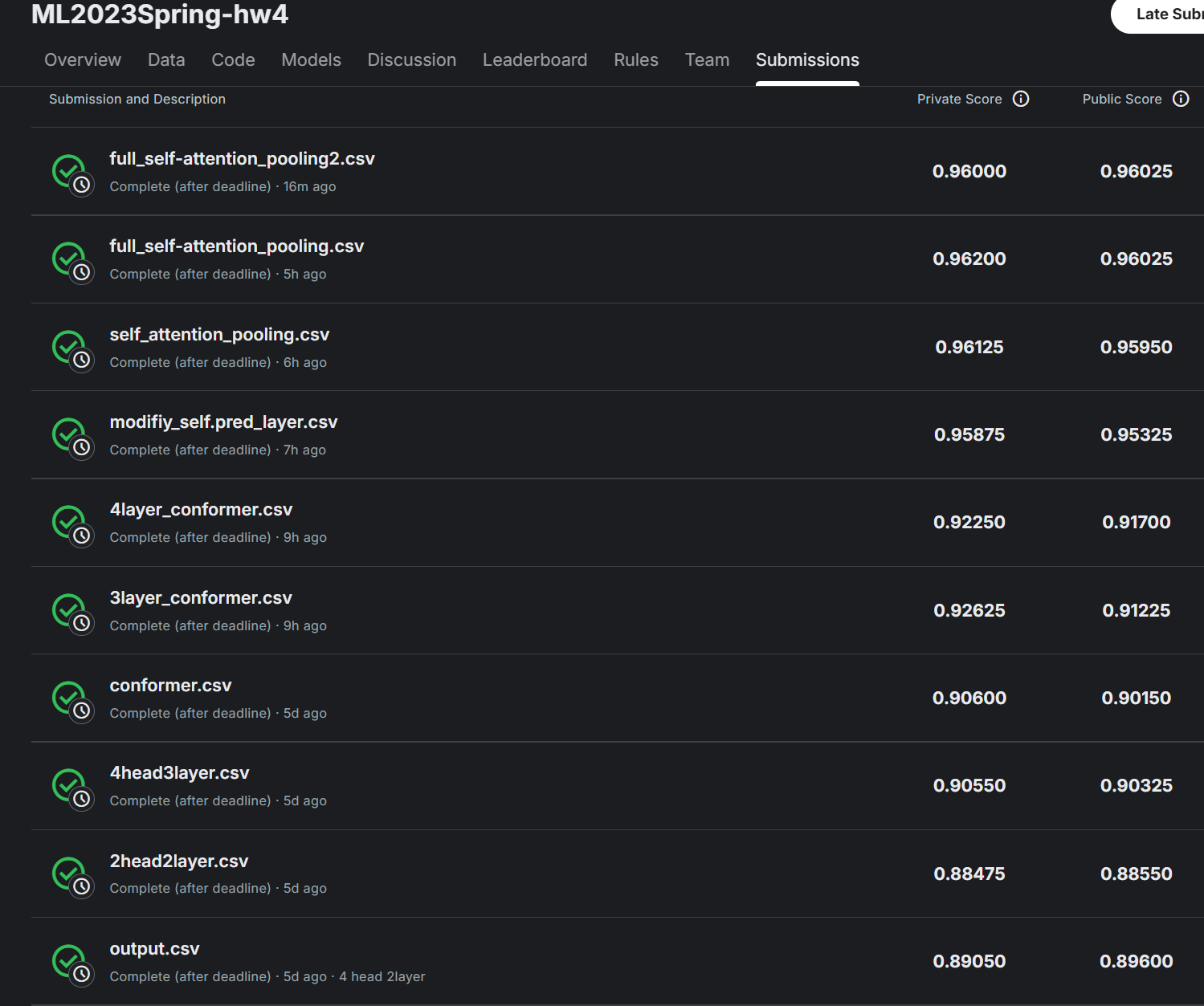
优化思路
- 增加transformer层数
- 使用multi-head
- 使用conformer
- self-attention pooling
实验过程
注意:原代码中数据集的链接已经失效了,可以加载kaggle上的数据集,代码如下
# 1. 上传 kaggle.json 文件(执行后会弹出上传框)
# kaggle.json文件:kaggle setting-account-API -> create new token生成
from google.colab import files
files.upload()
# 2. 把 kaggle.json 放到合适的位置
!mkdir -p ~/.kaggle
!mv kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
# 3. 安装 kaggle 包(如果没有安装)
!pip install -q kaggle
!kaggle competitions download -c ml2023springhw4
# 4. 解压缩
!unzip -q ml2023springhw4.zip-
直接运行sample code,accuracy=0.6716
-
把TransformerEncoder层数从1改为2,accuracy=0.7140,private score:0.88475,已经达到boss,此次作业未免太简单了。
-
修改
encoder_layer中nhead- 从2改为1,accuracy=0.7265
- 改为4,accuracy=0.7256,private score:0.89050,public score:0.89600。
-
encoder_layer = 4,TransformerEncoder层数改为3,accuracy=0.7451,private score:0.90550 -
使用两层conformer,accuracy=0.7493,private score:0.90600
self.conformer = Conformer( input_dim = d_model, num_layers=2, # Conformer层数 num_heads=4, ffn_dim=256, depthwise_conv_kernel_size=31 ) #forward()中修改为: # out: (batch size, length, d_model) out = self.prenet(mels) # (B,length,d_model) conformer必须传入的参数还有length,length是tensor,形状(batch_size,) lengths = torch.tensor([m.shape[0] for m in mels], dtype=torch.int32).to(mels.device) out, _ = self.conformer(out, lengths) # 返回 tensor(B,length,d_model) # mean pooling stats = out.mean(dim=1) -
调整conformer层数
- 3层,accuracy=0.7638,private score:0.92625
- 4层,accuracy=0.7744 ,private score:0.92250,出现了过拟合,所以后面使用3层
-
修改
self.pred_layer, accuracy = 0.8554, private score:0.95875。模型取得巨大进步!究其原因,self.pred_layer参数太多,反而引入了不必要的学习负担和噪声,使得模型难以优化。#原代码 self.pred_layer = nn.Sequential( nn.Linear(d_model, d_model), nn.ReLU(), nn.Linear(d_model, n_spks), ) #修改后 self.pred_layer = nn.Linear(d_model, n_spks) -
使用简化版的
self-attention pooling,accuracy = 0.8588, private score:0.96125。import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttentionPooling(nn.Module):# simplified version: no attention_dim
def init(self, in_dim):
super().init()
self.in_dim = in_dim
self.score = nn.Linear(in_dim, 1)def forward(self, x): """ x: Tensor(batch_size, seq_len, input_dim) """ score = self.score(x) #(batch_size, seq_len, 1) score=score.squeeze(-1) # (B, L) weights=F.softmax(score,dim=1) # (B, L) # Weighted sum pooled = torch.sum(x*weights.unsqueeze(-1),dim=1) # (B, input_dim) return pooled#修改Classifier.init()
self.attention_pooling = SelfAttentionPooling(in_dim=d_model)
#修改Classifier.forward(),删除mean_pooling
stats = self.attention_pooling(out) -
完全版
self-attention pooling:用tanh进行非线性变换,accuracy = 0.8616, private score:0.96200class SelfAttentionPooling(nn.Module):# full version
def init(self, in_dim,attention_dim=64):
super().init()
self.in_dim = in_dim
self.attention_proj=nn.Linear(in_dim,attention_dim)
self.score = nn.Linear(attention_dim, 1)def forward(self, x): """ x: Tensor(batch_size, seq_len, input_dim) """ score = torch.tanh(self.attention_proj(x)) score = self.score(x).squeeze(-1) # (B, L) weights=F.softmax(score,dim=1) # (B, L) # Weighted sum pooled = torch.sum(x*weights.unsqueeze(-1),dim=1) # (B, input_dim) return pooled -
self-attention pooling中改为attention_dim=128,accuracy = accuracy=0.8626, private score:0.96000,不仅没有提升,还略有下降,并且消耗的算力、时间更多。
部分代码解释
-
训练时,transformer不再像CNN等一样采用epoch,而是使用step(更新一次参数),这是因为Transformer / NLP 大模型的数据集非常大,完整遍历一遍数,一个 epoch 可能需要几天甚至几周,所以用step来控制。
try:
batch = next(train_iterator)
except StopIteration:
train_iterator = iter(train_loader)
batch = next(train_iterator)
从 train_iterator 获取一个 batch, 如果迭代器耗尽 (StopIteration),重新创建迭代器, 保证训练可以无限循环遍历数据集 。
- 测试时不需要再切分音频,直接全部给模型的原因:transformer可处理任意长度的输入 ,训练时使用data segmentation并不是因为模型必须切分,而是出于以下几个实用目的 :
-
统一输入长度,便于batch training
-
增加样本数量,提高数据利用率。一个长音频(比如 10 秒)可能只对应一个标签(说话人),切成 5 个 2 秒段,每段都可以作为一个训练样本
-
提升泛化能力,随机切分可以视为一种数据增强
相关技术
Conformer
Convolution-augmented Transformer,核心思想:结合 Transformer 的全局建模能力 + 卷积的局部建模能力,在序列建模上更适合连续信号(如语音)
- 优势
- 全局依赖建模:Transformer 的 self-attention
- 局部特征建模:卷积捕捉短时连续模式
- 序列平滑:相比纯 Transformer,对连续信号更稳定
Self-Attention Pooling
- Self-Attention Pooling = 带权重的池化。
- 传统方法如平均池化(Mean Pooling)、最大池化(Max Pooling)缺点在于对每个时间步的特征 一视同仁 ,没有区分重要性;而Self-Attention Pooling 的核心思想在于给序列中每个位置分配一个权重,重要的位置得到更高权重,通过自注意力机制学习权重,而不是固定平均或最大。
- Self-Attention Pooling 可以看作 Self-Attention 的简化版 :
- 没有完整的 Q/K/V 矩阵乘法
- 目标不是生成新序列,而是对序列做 加权聚合
总结
- 对于比较简单的任务,采用太复杂或参数过多神经网络,不一定能取得好结果:收敛慢,Overfitting风险变高。
- 适当简化模型或许有奇效 :
- 在此次作业中,简化
self.pred_layer后模型性能大幅度提高 - 使用简化版的
Self-Attention Pooling取得了很好的成果,与完整的Self-Attention Pooling效果几乎一致,且优于使用更多参数的Self-Attention Pooling
- 在此次作业中,简化