
论文发布时间: 2025年7月13日
1.摘要
background
处理长时程视频(如电影、在线直播等)是多模态大语言模型(MLLM)的一项关键能力,但目前仍极具挑战性。其核心困难在于,长视频会产生海量的视觉Token(例如,Gemini 1.5-Pro处理一小时视频会产生近百万Token),这带来了巨大的计算和内存开销,使得模型难以高效地理解和处理长视频的上下文信息。
innovation
为了解决这一挑战,本文提出了一个名为 VideoChat-Flash 的全新视频MLLM,其贡献是系统性的,涵盖了模型架构、训练数据、训练策略和评估基准。
1.分层视频Token压缩 (HiCo):这是核心的架构创新。它将视频压缩分为两个层级:
片段级 (Clip-level) :在视频编码阶段,利用视频帧间的时空冗余,通过视频编码器(UMT)和相似Token合并技术,实现对每个视频片段的极致压缩,压缩比高达约 1/50,且几乎没有性能损失。
视频级 (Video-level):在LLM推理阶段,利用LLM处理长视频时注意力(Attention)的稀疏性,在浅层网络中均匀丢弃部分视觉Token,在深层网络中根据文本引导保留关键Token,进一步降低计算量。
2.多阶段"从短到长"的学习策略:设计了一套课程学习方案,让模型先从图像和短视频中学习基础的视觉感知能力,再通过与长视频数据的联合训练,逐步扩展其处理长时程上下文的能力。
3.大规模长视频数据集 (LongVid):为解决长视频训练数据不足的问题,构建了一个包含30万小时视频和20亿单词文本标注的大规模数据集。
4.更具挑战性的评估基准 ("Multi-Hop Needle-In-A-Video-Haystack"):提出了一个新的"大海捞针"测试,它要求模型在视频中根据一系列线索进行多步推理才能找到最终的"针",比传统的单步检索任务更能评估模型的复杂推理能力。
- 方法 Method
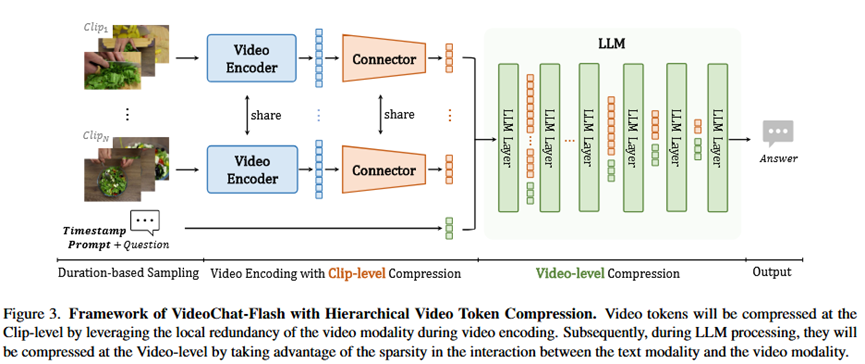
总体流程 (Pipeline):
VideoChat-Flash的流程如图3所示,是一个高效处理长视频的流水线。首先,对输入的长视频进行基于时长的采样 (短视频采得密,长视频采得疏);然后,将采样后的帧序列分割成多个片段 (Clips) ;每个片段独立地经过一个共享的视频编码器 和一个连接器 进行片段级压缩 ,将大量帧信息压缩成极少量的Token;所有片段的压缩Token被拼接起来,送入大语言模型(LLM);在LLM的推理过程中,再进行视频级压缩(即渐进式视觉Token丢弃),最终根据用户的问题生成回答。
各模块详解:
输入 (Input):原始长视频文件 + 用户提出的自然语言问题。
片段级压缩 (Clip-level Compression):
输入:一个视频片段(例如4帧图像)。
做法 :使用一个带有时空注意力 机制的视频编码器(UMT-L)来聚合帧间信息,然后通过一个无参数的相似Token合并操作,将高度相似的Token融合成一个。
输出:每个片段的高度浓缩的视觉Token序列(例如,平均每帧只用16个Token表示)。
视频级压缩 (Video-level Compression / Progressive Visual Dropout):
输入:拼接好的、来自所有片段的视觉Token序列。
做法 :这是一个在LLM内部进行的动态压缩。在LLM的浅层(例如前4层),均匀随机 地丢弃一部分Token以减少计算量,同时保留视频的整体时空结构;在LLM的深层(例如第18层之后),根据文本Token对视觉Token的注意力得分来保留最相关的Token。
输出:在LLM深层中,一个更短、更聚焦于任务相关信息的视觉Token序列。
多阶段短到长学习:
阶段一:视觉-语言对齐。冻结视觉编码器和LLM,只训练连接器,对齐视觉特征和语言空间。
阶段二:短视频预训练。在大量图像和短视频数据上进行预训练,增强模型的基础视觉理解能力。
阶段三:长短视频联合指令微调。混合短视频和长视频数据,让模型同时保持对细节的感知和对长上下文的理解。
阶段四:高效高分辨率后微调。在少量数据上对视觉编码器进行高分辨率微调,提升模型对高清视频的感知能力。
输出 (Output):针对问题的自然语言回答。
- 实验 Experimental Results
实验数据集:
通用视频理解基准:使用了包括MVBench, Perception Test (短视频), LongVideoBench, MLVU, LVBench (长视频) 以及综合性的VideoMME在内的多个主流基准。
特定任务基准:Charades-STA (时序定位), AuroraCap (视频字幕)。
长上下文评估基准:Needle-in-A-Video-Haystack (NIAH) 和本文提出的 Multi-Hop NIAH。
实验结论:
1.性能领先:在各大视频问答基准上,VideoChat-Flash的7B模型在开源模型中取得了最佳性能,甚至在多个任务上超过了更大规模的闭源模型,如Gemini 1.5-Pro和GPT-4o(见Table 1)。
2.极致的效率:实验证明,HiCo压缩机制极其有效。在处理10000帧的长视频时,VideoChat-Flash的计算量(FLOPs)比LongVILA低了两个数量级,并且是唯一一个能在一张A100-80G显卡上完成推理的模型,而其他模型均因显存溢出(oom)而失败(见Table 6)。
3.各设计模块的有效性:消融实验(见Table 2)清晰地证明了HiCo压缩、时长自适应采样、短到长学习策略等每一个设计都对最终的性能提升做出了关键贡献。
4.强大的长上下文推理能力:在单步NIAH测试中,VideoChat-Flash在10000帧的视频中实现了99.1%的检索准确率。在更难的多步MH-NIAH测试中,其性能也远超基线模型,证明了其强大的长程逻辑推理能力。
- 总结 Conclusion
本文提供了一个解决长视频理解挑战的全栈式解决方案 。其核心思想是,通过智能且极致的分层压缩,可以在几乎不牺牲性能的前提下,将长视频的视觉信息压缩到极低的水平,从而根本性地解决了计算和内存瓶颈,使得高效、深入地理解长达数小时的视频成为可能。