引言
在工业 4.0 浪潮推动下,工厂制造正朝着智能化、无人化方向加速转型,而目标检测技术作为机器视觉的核心,成为实现生产过程监控、质量管控与安全保障的关键支撑。
现在市面的主流技术分2种,一种是老派的基于cnn神经卷积网络实现的,以yolo为代表 ,已经发展到yolo11版本;另一种是最新出来的基于transformer的DERT方案,以d-fine和deim代表,性能比较高,而且能够识别细小缺陷、模糊物体。
D-Fine:当需求聚焦于高精度工业缺陷检测(如芯片、精密零件)、或面临复杂干扰环境(如强反光、高速运动)时。
YOLOv11:当需要通用目标检测(如安全监控中的人员、设备检测)、追求快速部署与低成本,或场景灵活多变(如同时检测人员违规和简单产品缺陷)时。
工厂制造应用场景
核心场景应用集中于两大方向:
一是安全行为检测 ,实时识别员工违规操作(如未佩戴防护装备、进入危险区域),规避安全事故;
二是产品缺陷检测 ,精准定位生产过程中的外观瑕疵(如零件裂纹、表面划痕),提升产品合格率。本文将围绕这两大应用场景,结合实际案例与技术实现代码,全面解析在工厂制造中的落地价值。
安全行为检测中的应用
工厂生产环境中,设备高速运转、危险区域(如机床周围、高压电箱旁)分布广泛,员工的不规范行为(如未戴安全帽、违规跨越护栏)是引发安全事故的主要诱因。传统人工巡检存在 "监控盲区多、响应不及时" 的问题,而 目标检测技术 可通过实时分析车间摄像头画面 ,实现违规行为的秒级识别与预警。
案例场景:汽车零部件车间安全监控
某汽车零部件工厂拥有 20 条冲压生产线,车间内机床设备密集,且存在 "员工未戴安全帽操作""非授权人员进入冲压区域" 等安全隐患。工厂引入 YOLOv11 目标检测系统后,通过以下方案实现安全管控:
**1、硬件部署:**在车间关键位置(生产线入口、机床操作台、危险区域边界)安装 4K 高清摄像头,摄像头通过边缘计算设备(NVIDIA Jetson AGX Orin)与 YOLOv11 模型联动,降低数据传输延迟,其部署示意图如图 1 所示:

**2、检测目标定义:**将 "安全帽(红色 / 黄色)""员工人体""危险区域标识线" 作为核心检测目标,标注 5000 张车间违规 / 合规场景图片,构建专属数据集;
**3、预警机制:**当系统检测到 "员工未佩戴安全帽" 或 "人体跨越危险区域标识线" 时,立即触发三级预警 ------ 本地边缘设备发出声光警报、车间管理终端推送实时画面、后台系统记录违规时间与位置,形成闭环管理。
该方案实施后,车间安全违规事件发生率下降 82%,平均预警响应时间缩短至 0.8 秒,有效保障了生产安全。
核心代码实现(基于 Ultralytics 框架)
YOLOv11 的安全行为检测可通过 Ultralytics 库快速实现,以下为关键代码片段,包含模型加载、实时摄像头检测与违规预警逻辑,代码运行界面截图如图 2 所示:

图 2:YOLOv11 安全行为检测代码运行界面截图
from ultralytics import YOLO
import cv2
import numpy as np
import time
from playsound import playsound # 用于声光预警
# 1. 加载预训练YOLOv11模型(可替换为工厂自定义训练的模型)
model = YOLO('yolov11n.pt') # 轻量化模型n版,适合边缘设备;高精度场景可使用yolov11x.pt
# 2. 定义检测目标与违规判定规则
# 目标类别映射(参考COCO数据集,可根据自定义数据集调整)
class_names = model.names
SAFETY_HELMET = 39 # 安全帽在COCO数据集中的类别ID(可自定义标注)
PERSON = 0 # 人体类别ID
DANGER_ZONE = [(200, 300), (600, 300), (600, 500), (200, 500)] # 危险区域坐标(需根据实际场景校准)
# 报警控制参数
last_helmet_warning_time = 0
last_danger_warning_time = 0
WARNING_INTERVAL = 3 # 报警间隔(秒),避免频繁报警
# 3. 初始化摄像头(0为本地摄像头,可替换为网络摄像头RTSP地址)
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
# 4. 辅助函数
def is_in_danger_zone(person_center, danger_zone):
"""判断人体中心是否在危险区域内(基于多边形点-in-区域算法)"""
x, y = person_center
n = len(danger_zone)
inside = False
for i in range(n):
j = (i + 1) % n
xi, yi = danger_zone[i]
xj, yj = danger_zone[j]
if ((yi > y) != (yj > y)) and (x < (xj - xi) * (y - yi) / (yj - yi) + xi):
inside = not inside
return inside
def is_helmet_on_person(helmet_box, person_box, iou_threshold=0.1):
"""判断安全帽是否戴在人身上(基于IOU和相对位置)"""
# 计算安全帽和人头区域的IOU
h_x1, h_y1, h_x2, h_y2 = helmet_box
p_x1, p_y1, p_x2, p_y2 = person_box
# 只考虑人体上半部分(头部区域)
head_region_y2 = p_y1 + (p_y2 - p_y1) * 0.3 # 头部约占人体高度的30%
# 计算交集区域
inter_x1 = max(h_x1, p_x1)
inter_y1 = max(h_y1, p_y1)
inter_x2 = min(h_x2, p_x2)
inter_y2 = min(h_y2, head_region_y2)
if inter_x1 >= inter_x2 or inter_y1 >= inter_y2:
return False
# 计算IOU
inter_area = (inter_x2 - inter_x1) * (inter_y2 - inter_y1)
helmet_area = (h_x2 - h_x1) * (h_y2 - h_y1)
# 如果安全帽大部分在头部区域内,则认为佩戴了安全帽
return (inter_area / helmet_area) > iou_threshold
# 5. 实时检测与违规预警
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
current_time = time.time()
no_helmet_persons = [] # 未戴安全帽的人
danger_persons = [] # 处于危险区域的人
# 模型推理(conf=0.5为置信度阈值,可根据场景调整)
results = model(frame, conf=0.5, imgsz=640)
# 解析检测结果,分离人体和安全帽
persons = []
helmets = []
for result in results:
boxes = result.boxes # 检测框信息
for box in boxes:
cls = int(box.cls[0])
conf = float(box.conf[0])
x1, y1, x2, y2 = map(int, box.xyxy[0]) # 检测框坐标(左上、右下)
center_x = (x1 + x2) // 2
center_y = (y1 + y2) // 2
if cls == PERSON:
persons.append({
"box": (x1, y1, x2, y2),
"center": (center_x, center_y),
"confidence": conf,
"wearing_helmet": False
})
elif cls == SAFETY_HELMET:
helmets.append({
"box": (x1, y1, x2, y2),
"confidence": conf
})
# 匹配人与安全帽,判断是否佩戴
for person in persons:
person_box = person["box"]
# 检查是否有安全帽戴在这个人身上
for helmet in helmets:
if is_helmet_on_person(helmet["box"], person_box):
person["wearing_helmet"] = True
break # 找到匹配的安全帽就可以停止检查
# 判断是否在危险区域
if is_in_danger_zone(person["center"], DANGER_ZONE):
danger_persons.append(person)
# 记录未戴安全帽的人
if not person["wearing_helmet"]:
no_helmet_persons.append(person)
# 绘制检测结果
for person in persons:
x1, y1, x2, y2 = person["box"]
# 根据是否戴安全帽和是否在危险区域设置不同颜色
if person in danger_persons:
color = (0, 0, 255) # 危险区域:红色
thickness = 3
else:
color = (0, 255, 0) # 安全区域:绿色
thickness = 2
cv2.rectangle(frame, (x1, y1), (x2, y2), color, thickness)
# 显示是否佩戴安全帽
helmet_status = "With Helmet" if person["wearing_helmet"] else "No Helmet"
cv2.putText(frame, f"Person {helmet_status}", (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
# 绘制安全帽
for helmet in helmets:
x1, y1, x2, y2 = helmet["box"]
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 255, 0), 2)
cv2.putText(frame, f"Helmet {helmet['confidence']:.2f}", (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
# 绘制危险区域
cv2.polylines(frame, [np.array(DANGER_ZONE, np.int32)], True, (0, 255, 255), 2)
cv2.putText(frame, "Danger Zone", (DANGER_ZONE[0][0], DANGER_ZONE[0][1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 255), 2)
# 违规预警逻辑 - 未戴安全帽
if no_helmet_persons and (current_time - last_helmet_warning_time) > WARNING_INTERVAL:
cv2.putText(frame, f"WARNING: {len(no_helmet_persons)} Person(s) Without Helmet!",
(50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 3)
try:
playsound("warning_alarm.mp3") # 播放预警音效(需提前准备音频文件)
last_helmet_warning_time = current_time
except:
print("Warning: Could not play alarm sound")
# 违规预警逻辑 - 进入危险区域
if danger_persons and (current_time - last_danger_warning_time) > WARNING_INTERVAL:
cv2.putText(frame, f"WARNING: {len(danger_persons)} Person(s) in Danger Zone!",
(50, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 3)
try:
playsound("danger_alarm.mp3")
last_danger_warning_time = current_time
except:
print("Warning: Could not play danger sound")
# 显示实时画面
cv2.imshow("YOLOv11 Factory Safety Detection", frame)
# 退出逻辑(按下q键关闭)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()代码说明:上述代码实现了 "安全帽检测""人体危险区域入侵检测" 两大核心功能,可通过替换yolov11n.pt为工厂自定义训练的模型(基于自有数据集训练),进一步提升检测精度;同时,DANGER_ZONE坐标需根据车间摄像头视角校准,确保区域判定准确。
产品缺陷检测中的应用
产品缺陷检测是工厂质量管控的核心环节,传统人工检测依赖员工经验,存在 "漏检率高、效率低" 的问题 ------ 例如电子元件的微小裂纹、塑料零件的表面划痕,人工肉眼难以精准识别。目标检测技术 凭借对小目标的高灵敏度检测能力,可实现产品缺陷的自动化、高精度筛查,尤其适用于流水线高速生产场景。
案例场景:电子元件外壳缺陷检测
某电子设备工厂生产路由器外壳(ABS 塑料材质),外壳常见缺陷包括 "表面划痕""边角缺料""注塑气泡" 三类,此前采用人工抽检(抽检率 30%),漏检率达 15%,且每条生产线需配置 3 名检测员工,成本较高。引入 YOLOv11 缺陷检测系统后,工厂实现了全流程自动化检测,生产线布局如图 3 所示:

- **检测流程设计:**在外壳生产线末端安装 "传送带 + 工业相机(2000 万像素)",外壳随传送带匀速移动(速度 0.5m/s),相机每 0.3 秒拍摄 1 张图片,图片实时传输至 YOLOv11 检测服务器;
- **数据集构建:**收集 10000 张包含 "正常外壳""划痕缺陷""缺料缺陷""气泡缺陷" 的图片,使用 LabelImg 工具标注缺陷位置,按 8:2 比例划分为训练集与验证集,基于 YOLOv11 进行模型微调;
- **缺陷处理机制:**若系统检测到缺陷(置信度≥0.7),立即发送信号至传送带分拣装置,将缺陷产品推至 "不合格品区域",同时记录缺陷类型、生产时间与设备编号,便于后续质量追溯。
该方案实施后,缺陷检测漏检率降至 0.8%,检测效率提升 3 倍,每条生产线减少 2 名检测员工,年节约人力成本约 40 万元。
核心代码实现(缺陷检测与分拣联动)
以下代码基于 YOLOv11 实现电子元件外壳缺陷检测,
from ultralytics import YOLO
import cv2
import numpy as np
import serial # 用于与分拣装置PLC通信(需安装pyserial库)
# 1. 加载自定义训练的缺陷检测模型(基于工厂数据集训练)
model = YOLO('yolov11_defect_detection.pt') # 自定义缺陷检测模型
# 缺陷类别定义(与训练数据集一致)
defect_classes = {0: "normal", 1: "scratch", 2: "missing_material", 3: "bubble"}
# 2. 初始化工业相机(替换为相机实际参数,如分辨率、帧率)
cap = cv2.VideoCapture(1) # 工业相机通常为外接设备,索引为1
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 2048)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 1536)
cap.set(cv2.CAP_PROP_FPS, 5) # 按生产线速度设置帧率
# 3. 初始化与分拣装置的串口通信(实际波特率、端口需与PLC匹配)
try:
ser = serial.Serial('COM3', 9600, timeout=1) # Windows端口;Linux为/dev/ttyUSB0
print("Successfully connected to sorting device.")
except Exception as e:
print(f"Failed to connect to sorting device: {e}")
ser = None
# 4. 缺陷检测与分拣逻辑
def send_sort_signal(defect_type):
"""向分拣装置发送信号:0=正常(不分拣),1=划痕,2=缺料,3=气泡"""
if ser and ser.isOpen():
ser.write(str(defect_type).encode('utf-8'))
print(f"Sent sort signal: {defect_type} ({defect_classes[defect_type]})")
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("Failed to read frame from camera.")
break
# 图像预处理(裁剪ROI区域,聚焦产品,减少背景干扰)
roi = frame[300:1200, 500:1500] # 感兴趣区域(需根据相机视角校准)
# 模型推理(imgsz=640适配多数硬件,可根据精度需求调整)
results = model(roi, conf=0.7, imgsz=640)
# 解析检测结果
main_defect = 0 # 默认正常(0)
for result in results:
boxes = result.boxes
if len(boxes) > 0:
# 取置信度最高的缺陷作为主要缺陷
max_conf_idx = np.argmax(boxes.conf.numpy())
main_defect = int(boxes.cls[max_conf_idx])
x1, y1, x2, y2 = map(int, boxes.xyxy[max_conf_idx])
conf = float(boxes.conf[max_conf_idx])
# 绘制缺陷框与标签
color = (0, 255, 0) if main_defect == 0 else (0, 0, 255)
label = f"{defect_classes[main_defect]} {conf:.2f}"
cv2.rectangle(roi, (x1, y1), (x2, y2), color, 2)
cv2.putText(roi, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# 发送分拣信号(仅当检测到缺陷时发送)
if main_defect != 0:
send_sort_signal(main_defect)
# 记录缺陷信息(可写入数据库或日志文件)
with open("defect_log.txt", "a") as f:
log_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
f.write(f"{log_time} - Defect Type: {defect_classes[main_defect]}, Confidence: {conf:.2f}\n")
# 显示检测结果(缩放至适合屏幕大小)
display_roi = cv2.resize(roi, (800, 600))
cv2.imshow("YOLOv11 Electronic Shell Defect Detection", display_roi)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
if ser:
ser.close()自定义模型
我们看看怎么自定义模型:
5 个核心步骤:
数据采集
按 "场景全覆盖" 原则收集(如缺陷检测需包含 "不同光照、不同角度、不同批次产品" 的图片)
数据标注
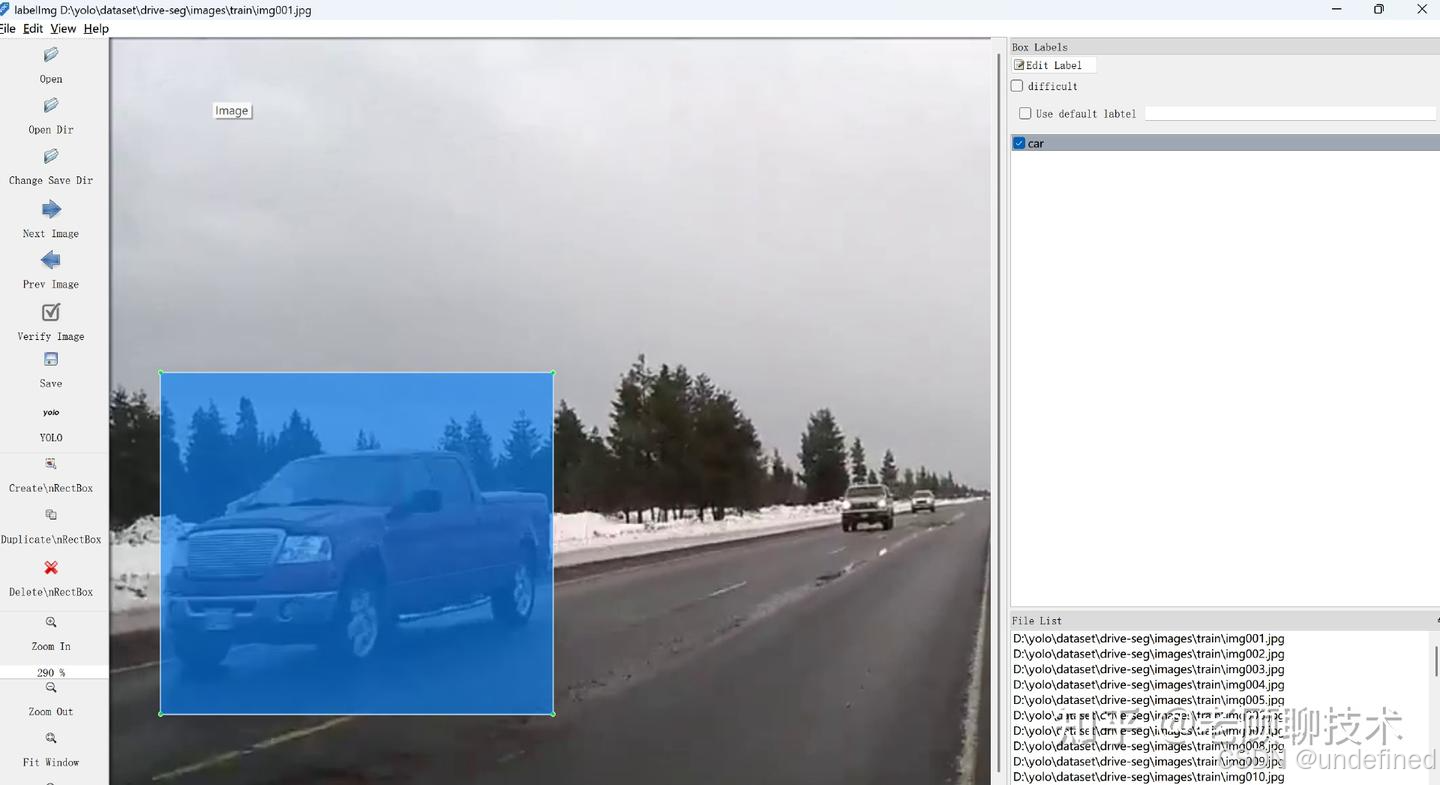
用 LabelImg 标注后,按 8:2 划分训练 / 验证集,同时检查 "标注准确率"(比如随机抽 100 张,人工复核标注错误率≤5%);
标注工具
每张图片都会有相应的标注文件
具体标注内容格式

前面的序号代表不同的实体

模型训练
加载 YOLOv11 预训练模型,调整关键参数(如 Epoch=50、Batch Size=16),训练中监控 "损失曲线"(确保验证集损失不持续上升,避免过拟合);
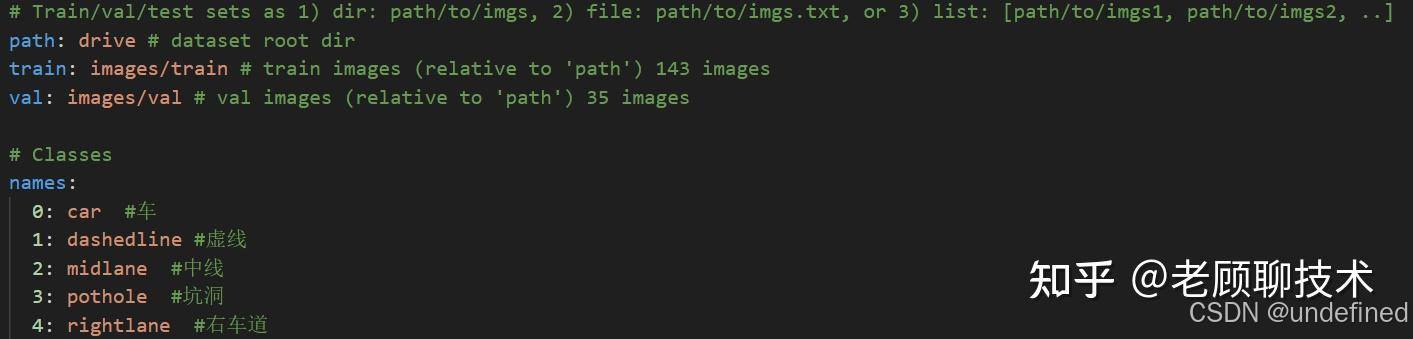
yaml配置文件
执行python train.py
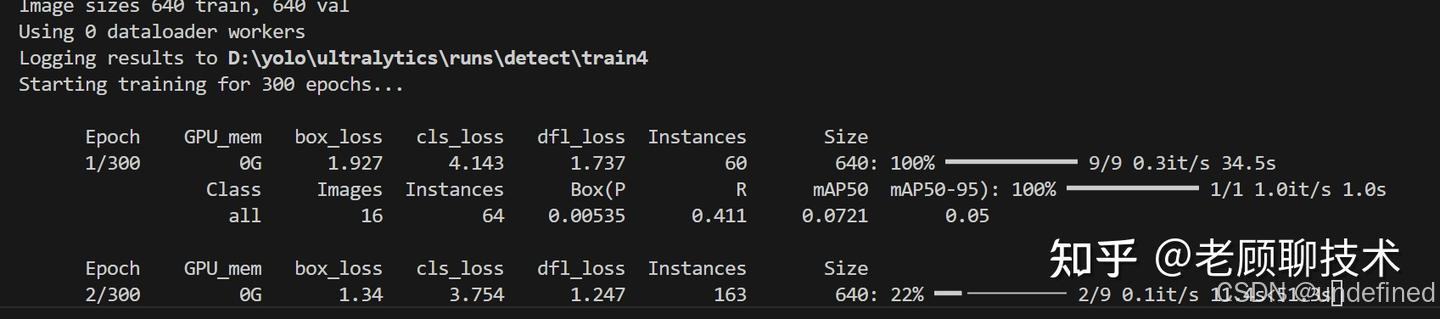
等待几个小时;训练出来的结果
best.pt就是我们想要的模型
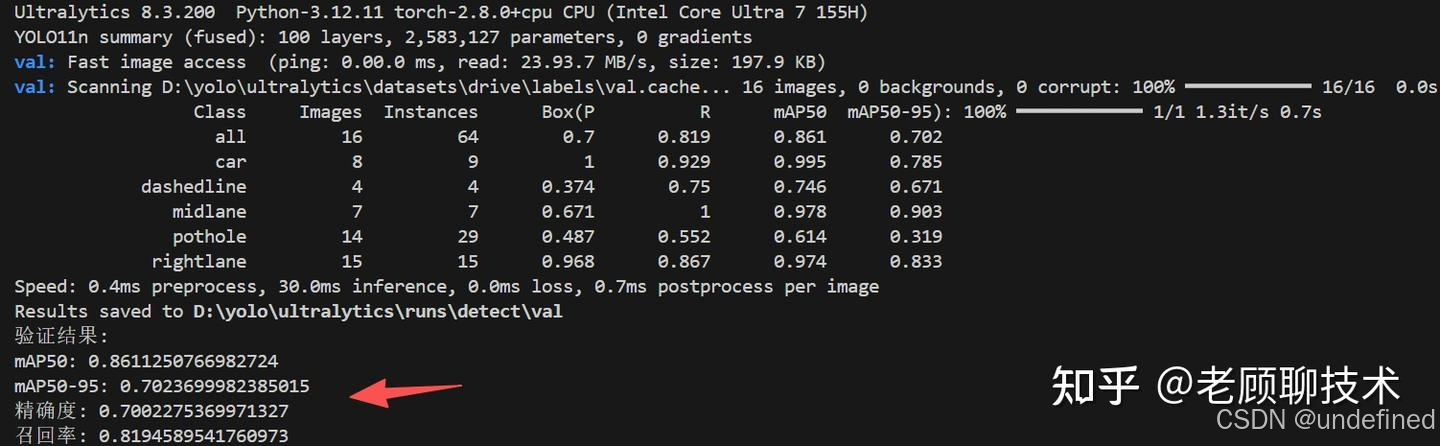
模型评估
用验证集评估精确度,召回率
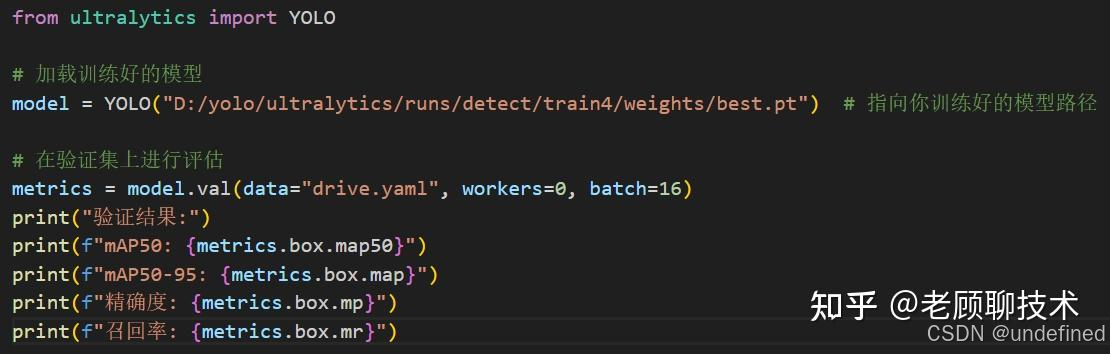
执行python val.py
模型导出
导出为工业格式(如 ONNX或TensorRT),导出时可以设置一些参数
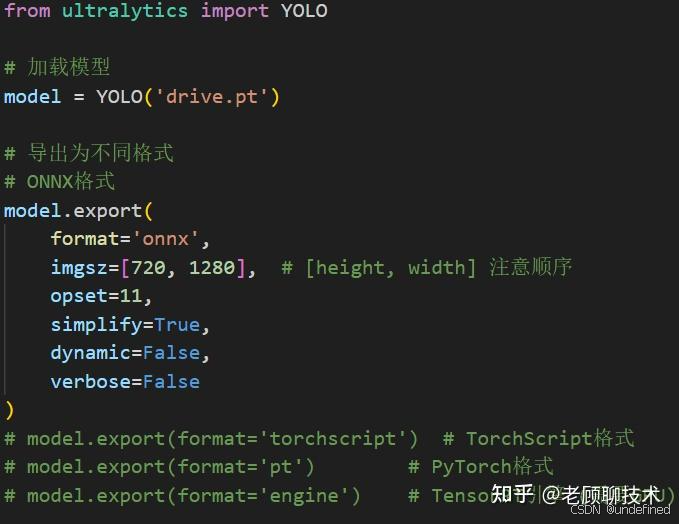
格式说明
ONNX: 通用格式,可在多种平台部署
TorchScript: PyTorch优化格式,便于在生产环境部署
TensorRT (.engine): NVIDIA GPU优化格式,推理速度最快
CoreML: Apple设备部署
OpenVINO: Intel硬件优化格式执行预测推理

总结
到此把如何自定义模型,以及如何在工厂制造场景如何用目标检测都已经介绍了 ,现在市面上有一些商业化产品,把采集、标注、训练、评估、导出、部署集成在一个产品中,一站式的解决方案 ;非常方便了让我们业务方进行使用,非常傻瓜式;业务方不需要了解太专业的知识,只需要按照步骤进行使用即可。他们的产品的核心思想其实就是老顾介绍的那些。
好的,就介绍到这里,下次再见